

A Novel Actor—Critic Motor Reinforcement Learning for Continuum Soft Robots

 , , and
, , and
Abstract
:1. Introduction
Contribution and Organization
2. Preliminaries and Problem Statement
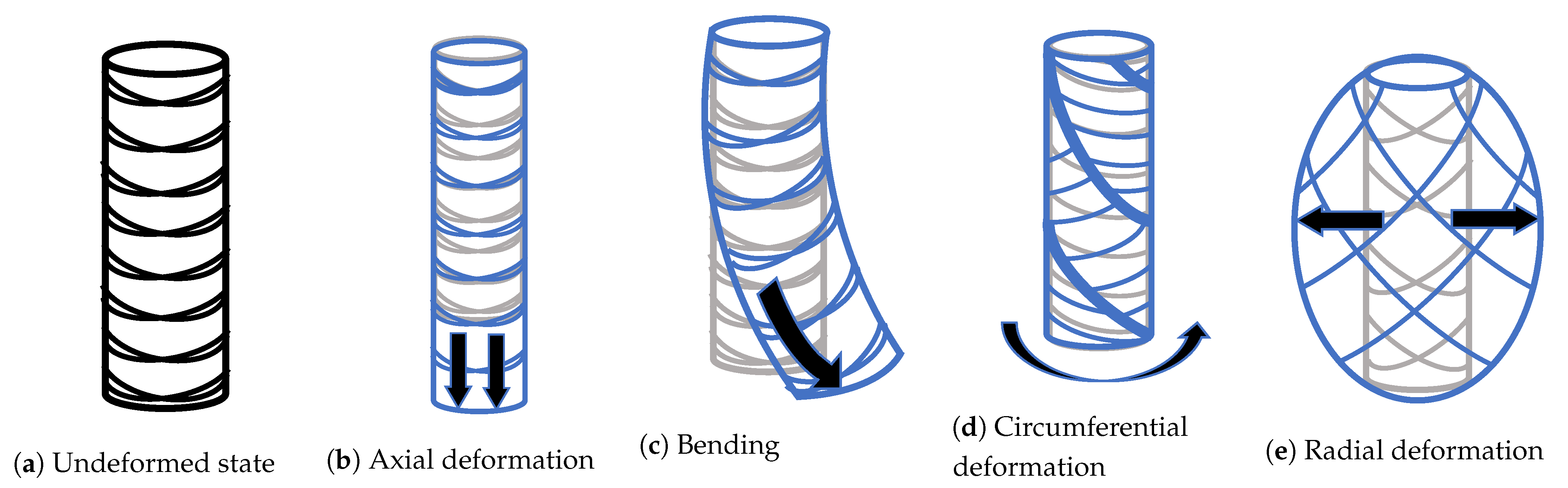
2.1. On Continuum Soft Robots
- Fluidic Elastomer soft robots (FESRs): This type of soft robots has pneumatic/hydraulic chambers embedded into their bodies, which induce body deformation when pressurized. It can generate movements such as bending, elongation, torsion, and a combination of these movements. For example, the STIFF-FLOP comprises a series of identical elastomeric soft actuators with internal pneumatic chambers to unlock three-dimensional movement and a central chamber for stiffness variation via granular interference phenomena [17].
- Cable-driven soft robots (CDSRs): The robot has external or internal cables that generate deformation by tension variation. However, the type of movement and workspace depend on the number and position of cables, which means that there are more control inputs and rigid elements where cables pivot. Furthermore, the exerted force of this type of actuator depends directly on cables tension and not on stiffness. An example is depicted in [18], where a four-cable-driven soft arm is presented.
- Shape-memory polymer soft robots (SMPSRs): This type encompasses robots composed of polymers with a thermally induced effect, which allows them to go from an initial state to a deformed state. However, SMPSRs do not produce high strain and are usually applied when small deformations are required.
- Dielectric/electroactive polymer soft robots (D/EPSRs): This type of robots are based on deformation phenomena in response to electricity. However, due to their high voltage amplification, their doped elastomer is the most disadvantageous and risky option.
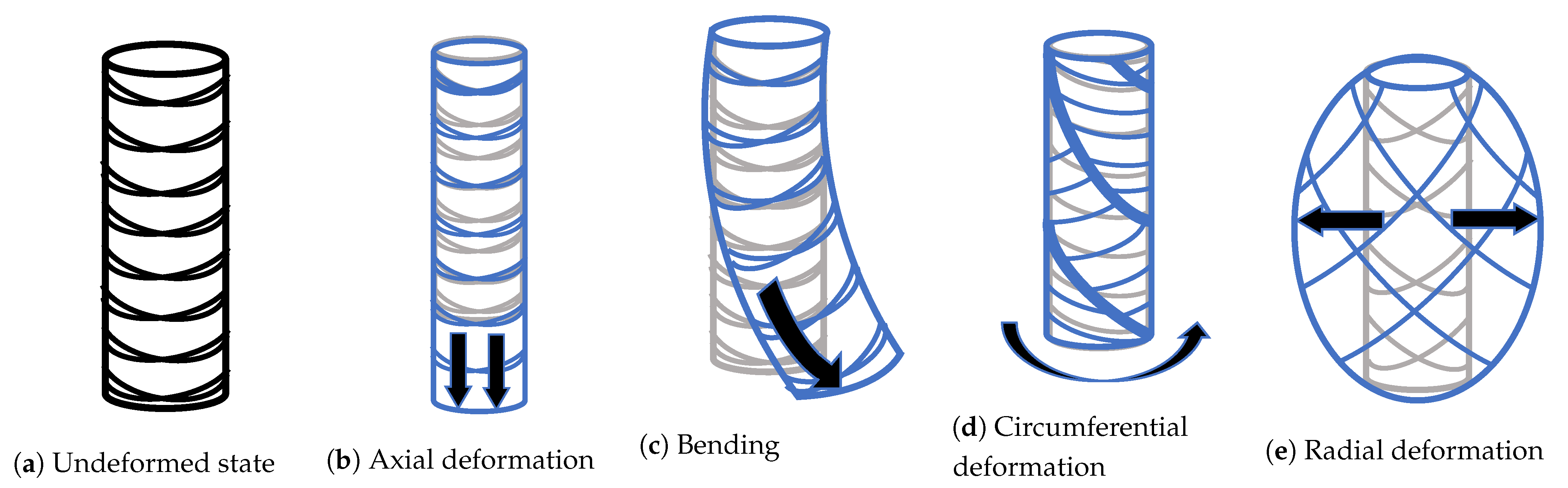
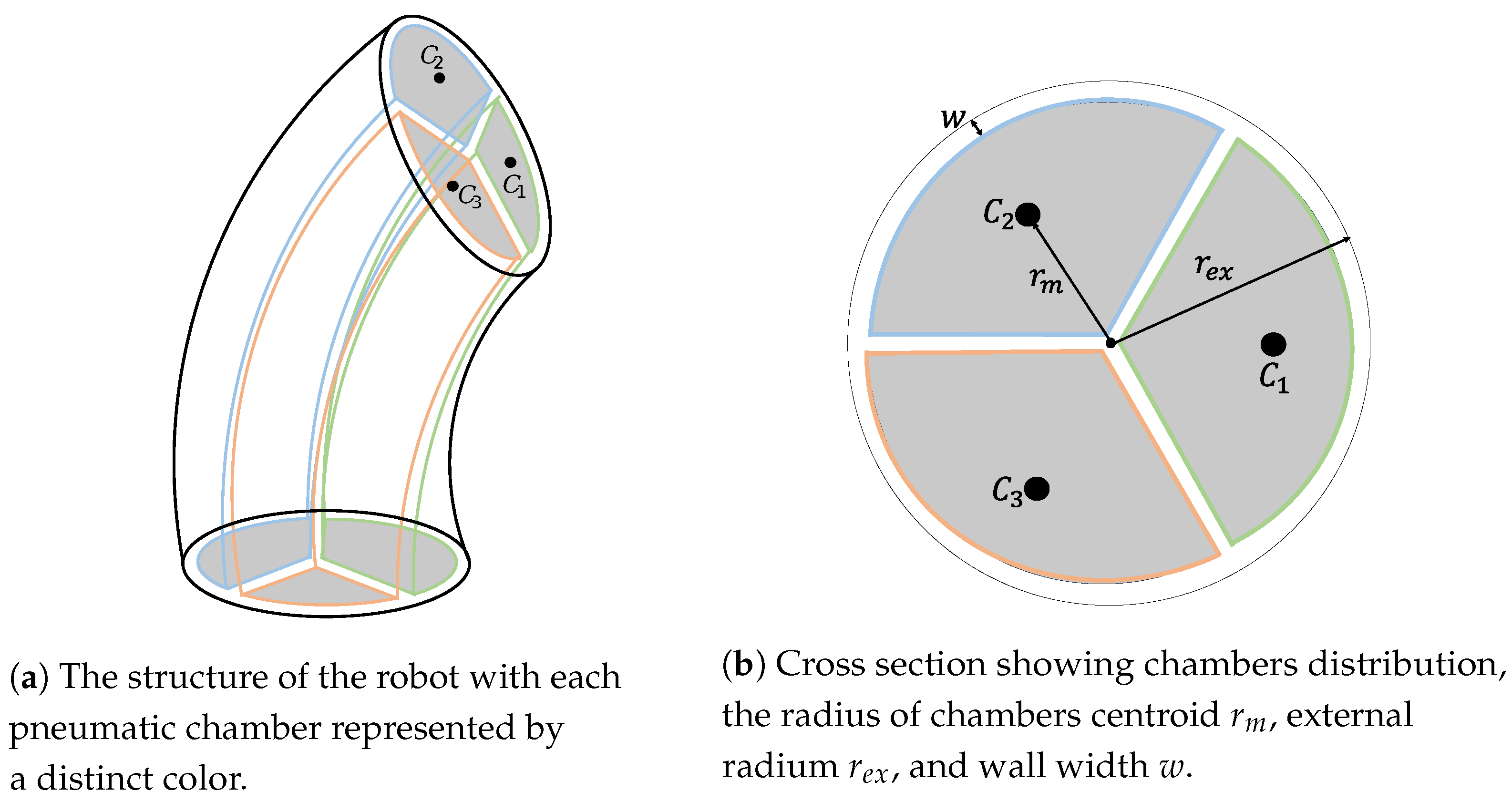
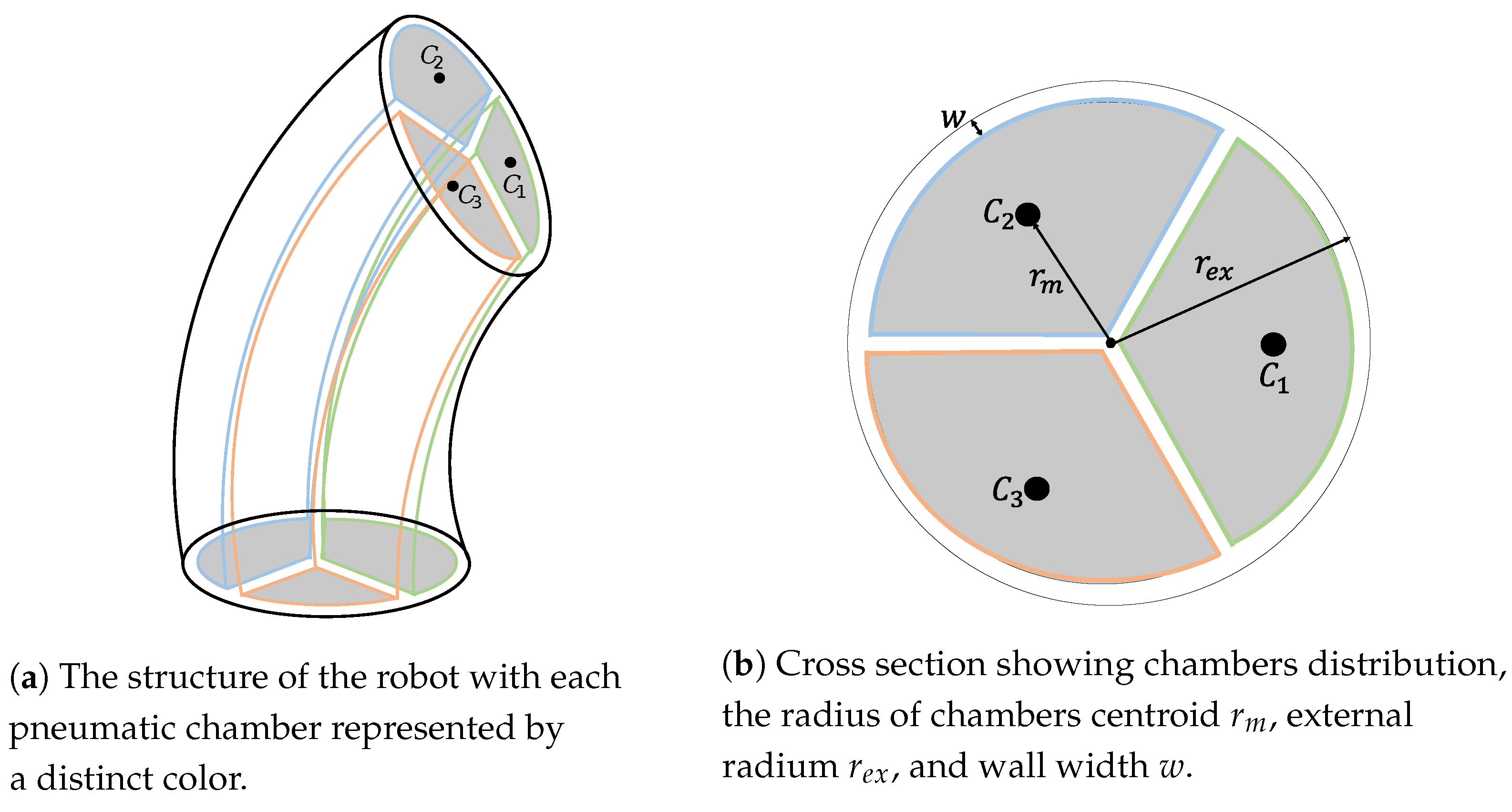
- Cylindrical morphology: The robot’s body is shaped like a cylinder of elastomeric material, with pressure inputs (chambers) radially distributed along an internal radius. When a chamber is pressurized, the body presents a controlled curvature along the extensible center of the robot. Usually, this morphology is built using inextensible braided threads to mitigate radial and circumferential deformations so that the robot’s configuration can be approximated with a minimum set of linearly independent variables principally used as control inputs actuated by pneumatic chambers.
- Ribbed morphology: The robot is composed of three elastomer-based layers. The top and bottom layers have internal ribbed-like structures with multiple rectangular channels connected to fluid transmission lines, whereas the middle layer is a flexible but inextensible restriction. In an active state, where fluid pressurizes a group of chambers, bending is produced. An example is presented in [20] with a soft arm of six ribbed-like segments designed as a manipulation system.
- Pleated morphology: Consists of discrete sections (plates) of elastomeric materials evenly distributed and separated by gaps. At the bottom part, a high-stiffness silicon layer is used to work as an inextensible restriction. Additionally, the top part has hollow cavities (in each plate) connected to a central chamber. When it gets pressurized, each plate experiences balloon-like deformations translated into bending of the high-stiffness silicon layer along the direction of the layer with lower stiffness. An example is presented in [21], where a soft manipulator has six segments with cylindrical cavities, and a pleated-shaped soft gripper is used for grasping purposes.
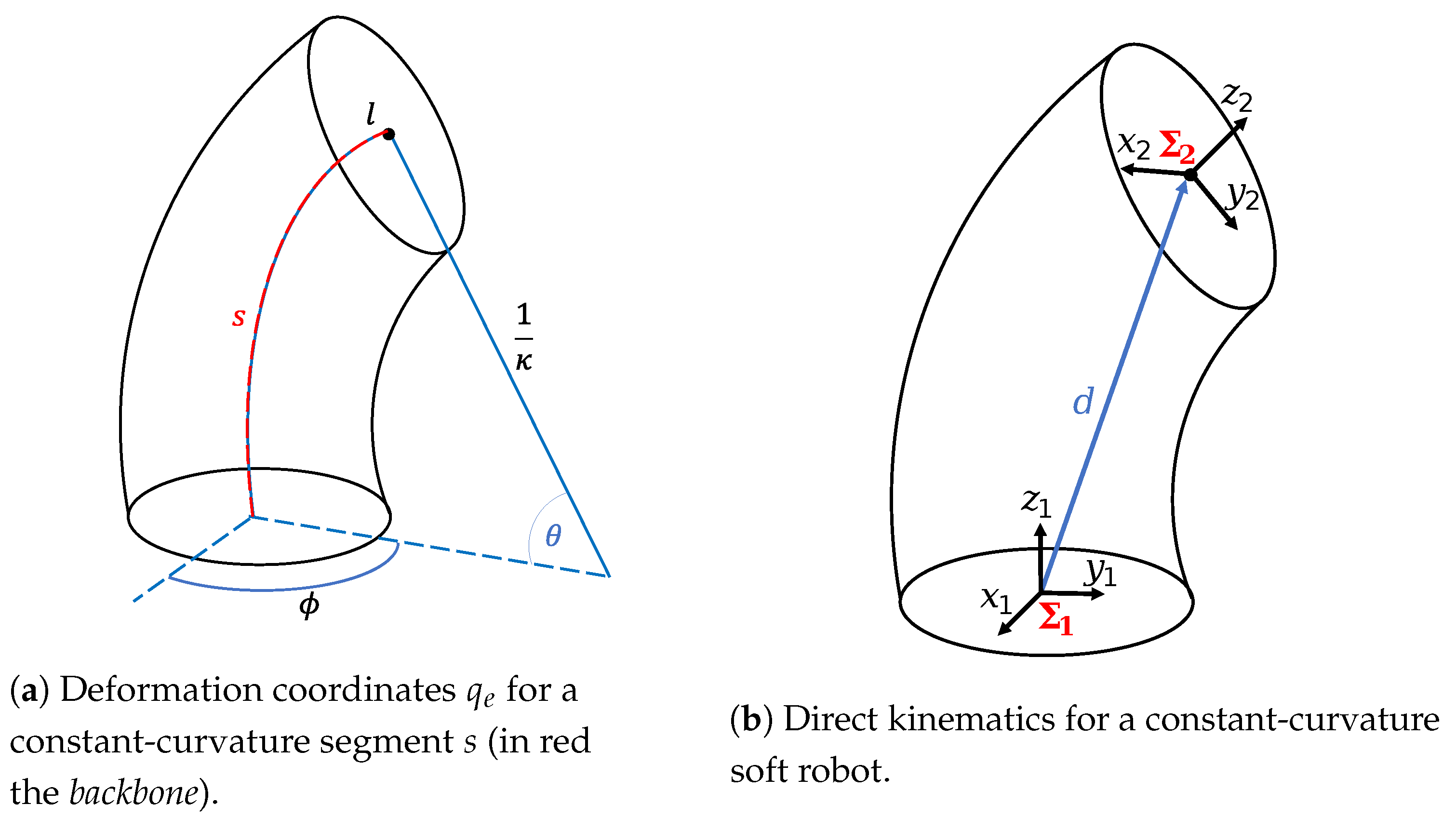
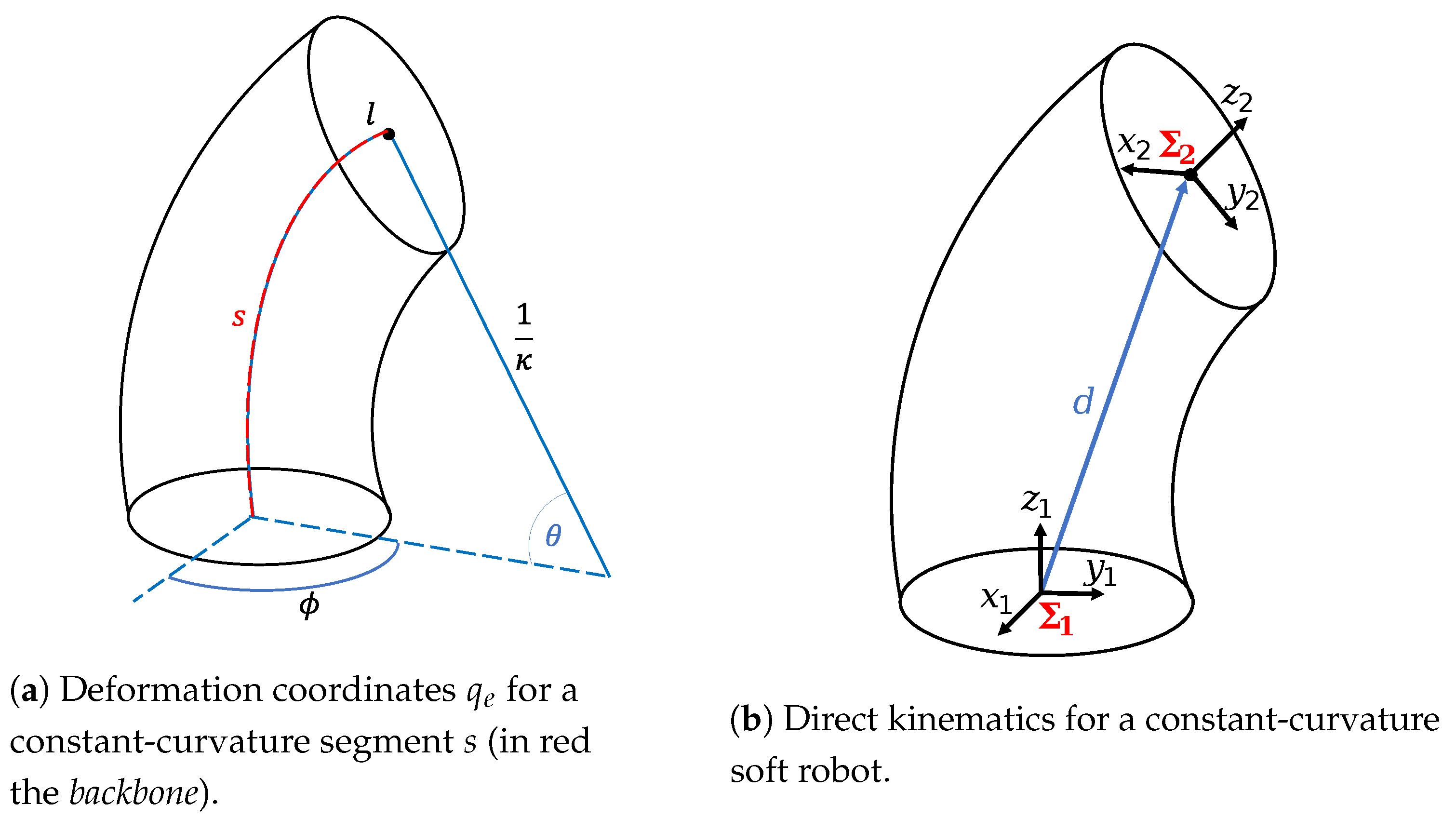
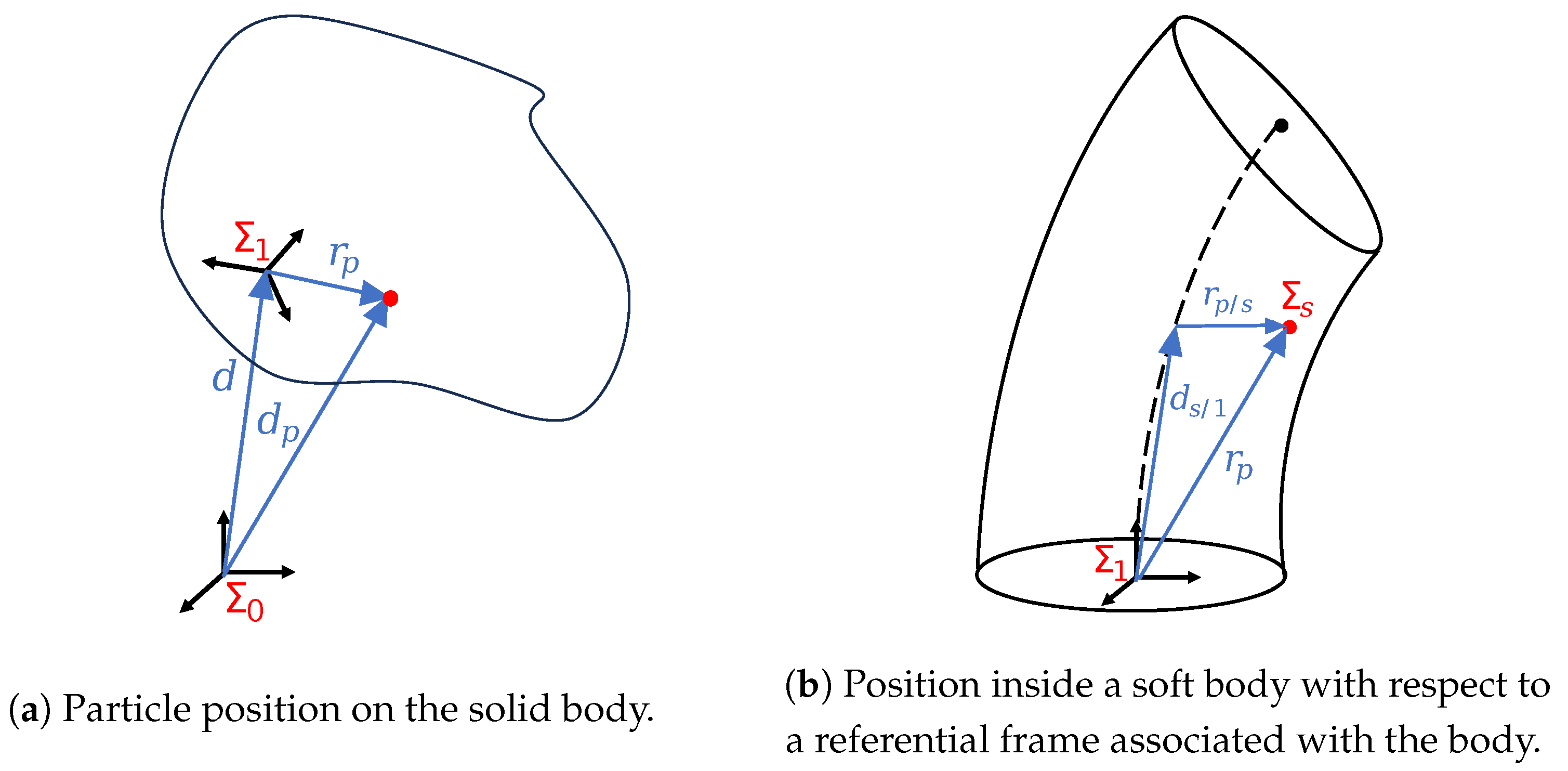
2.1.1. Deformation Coordinates
- From actuation space l to configuration space (), related to the actuation mechanism, which in this case is the length of chambers. It is also known as specific mapping.
- From configuration space to operational space x (), better known as direct kinematics [25].
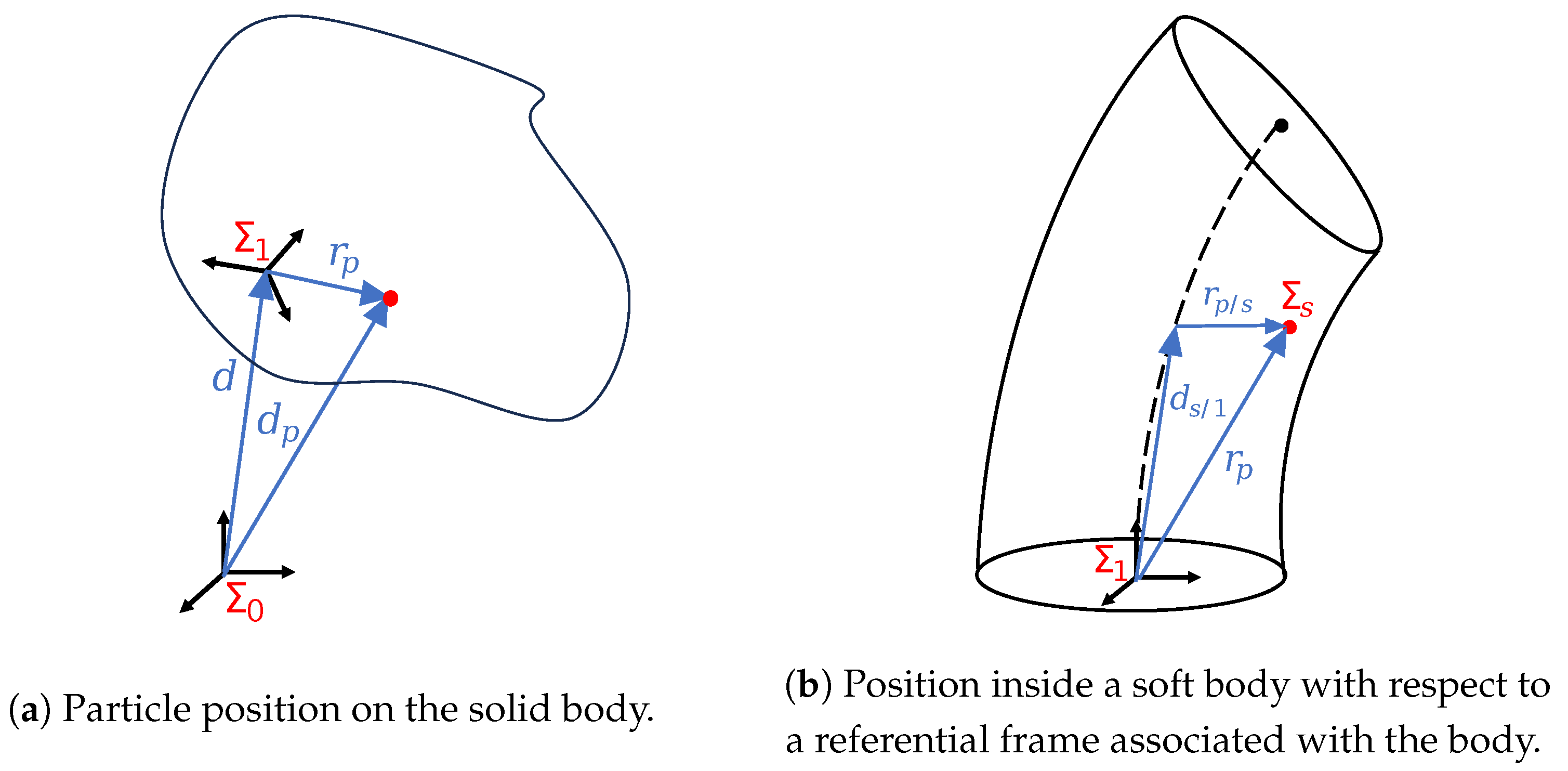
2.1.2. Kinematics
2.1.3. Dynamics
- Symmetry and definite positiveness of inertia matrix: .
- Skew symmetry of Coriolis matrix: .
- Passivity: , for any .
2.1.4. Affine Actuation
2.2. Open-Loop Error Equation
2.2.1. Nominal Reference Design to Induce Integral Sliding Modes
2.2.2. Control Design
2.3. Problem Statement
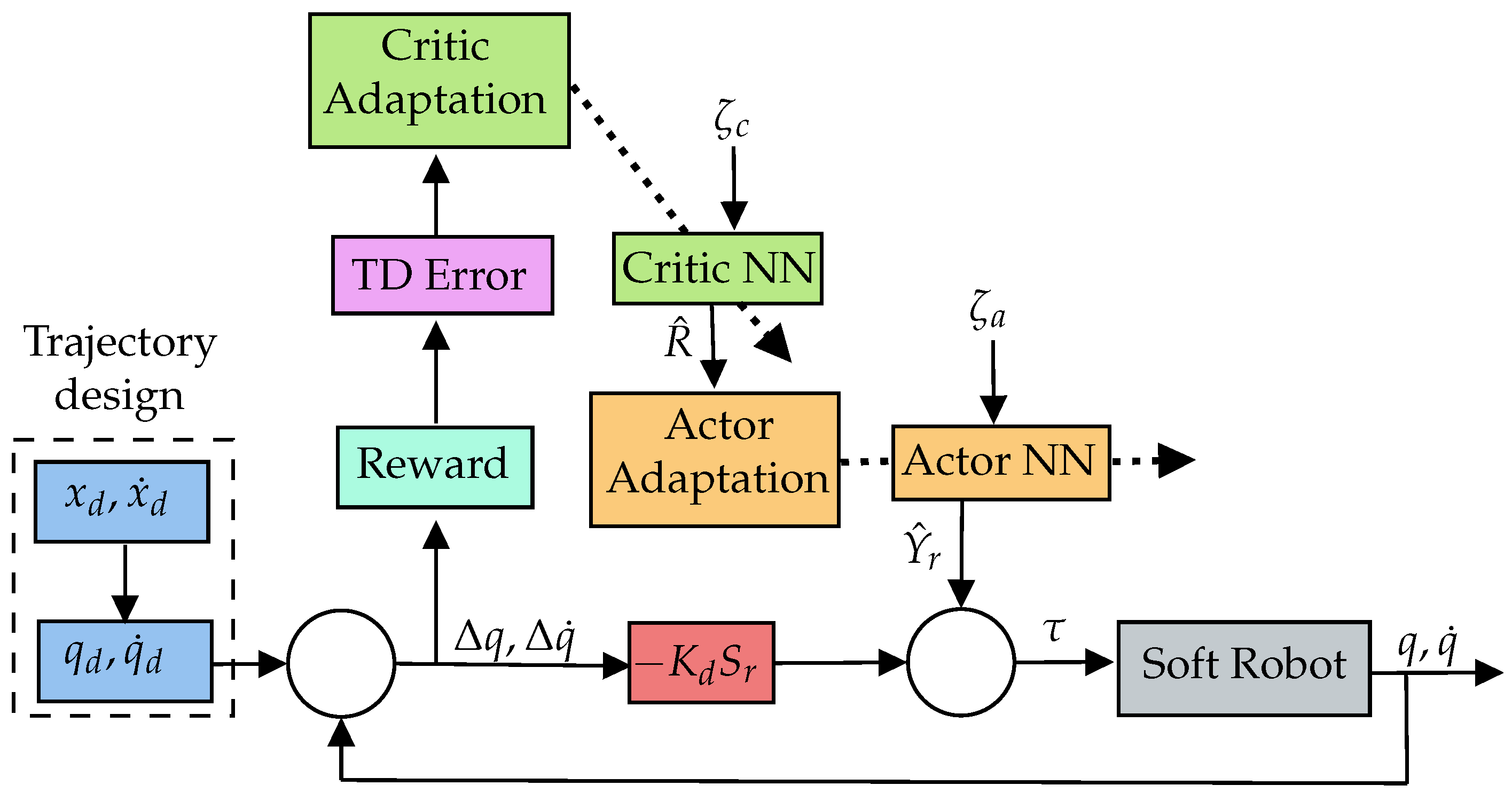
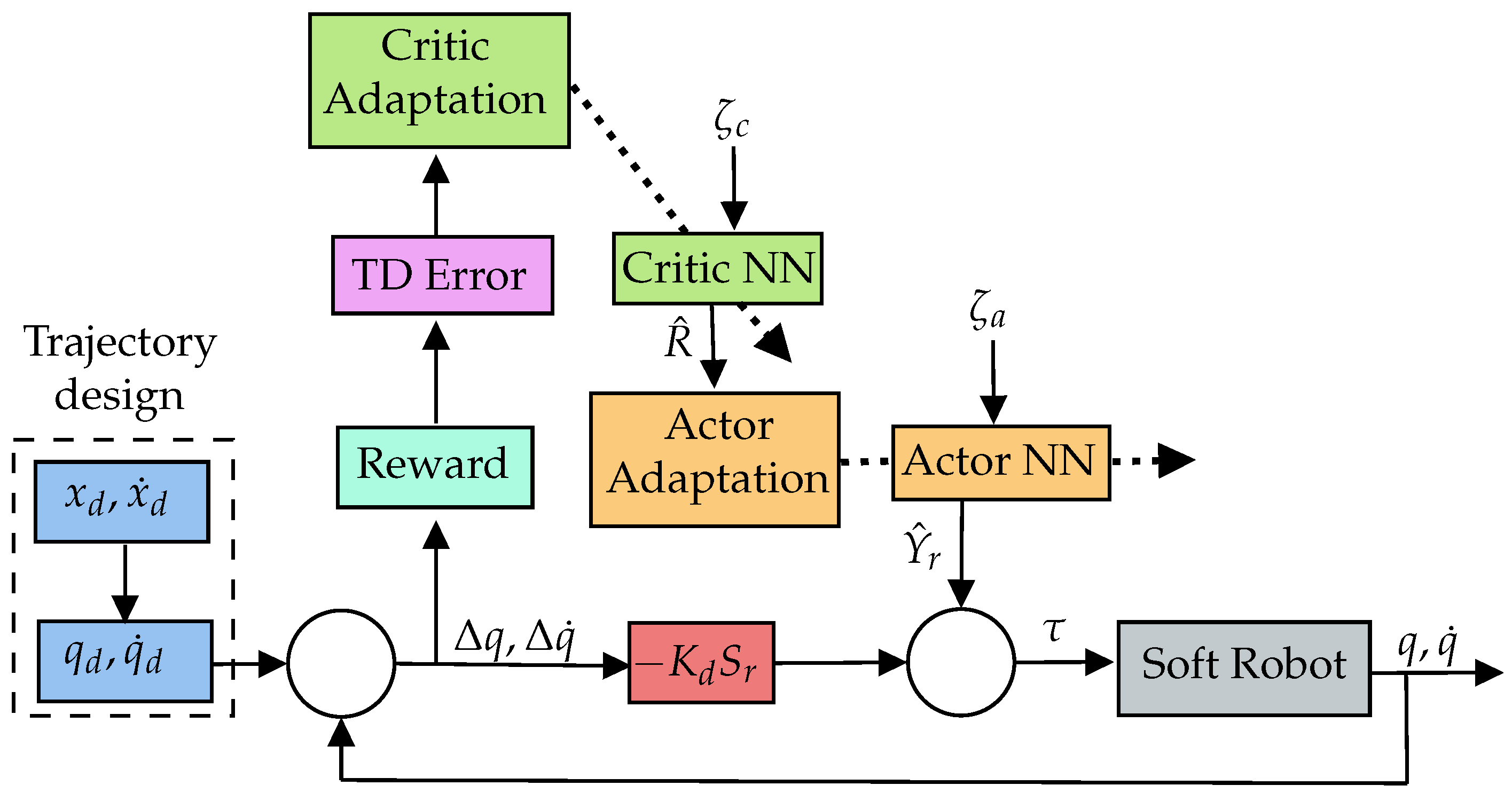
3. Actor–Critic Learning of Motor Control
3.1. Reward-Based Value Function and Temporal Difference Error
3.2. Critic NN
3.3. Actor NN
3.4. Passivity-Based Reinforced Neurocontroller
4. Numerical Simulations
4.1. The Simulator and Parameters
4.2. Neural Network Architectures
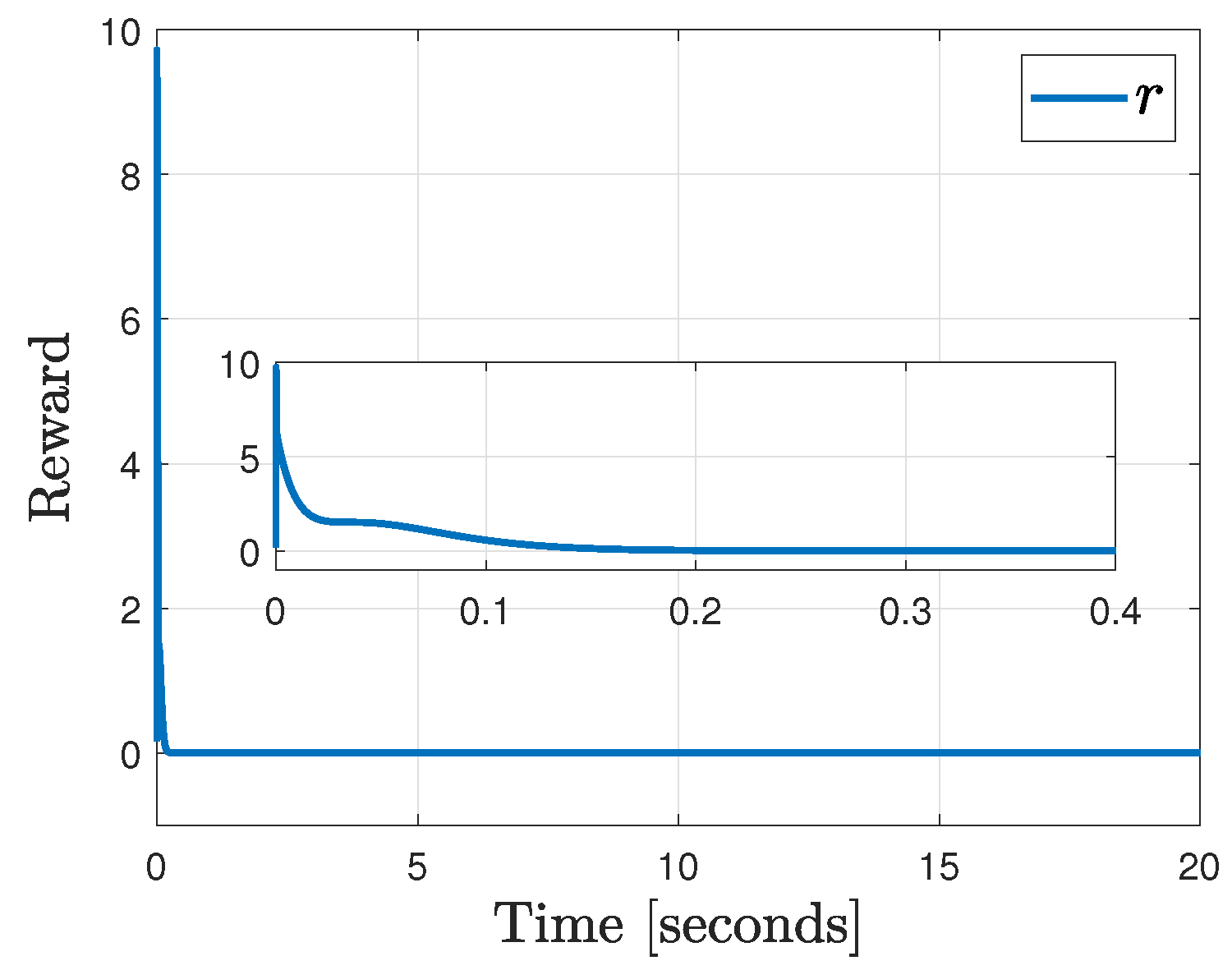
4.3. Reward Design
4.4. Feedback Control and Adaptation Gains
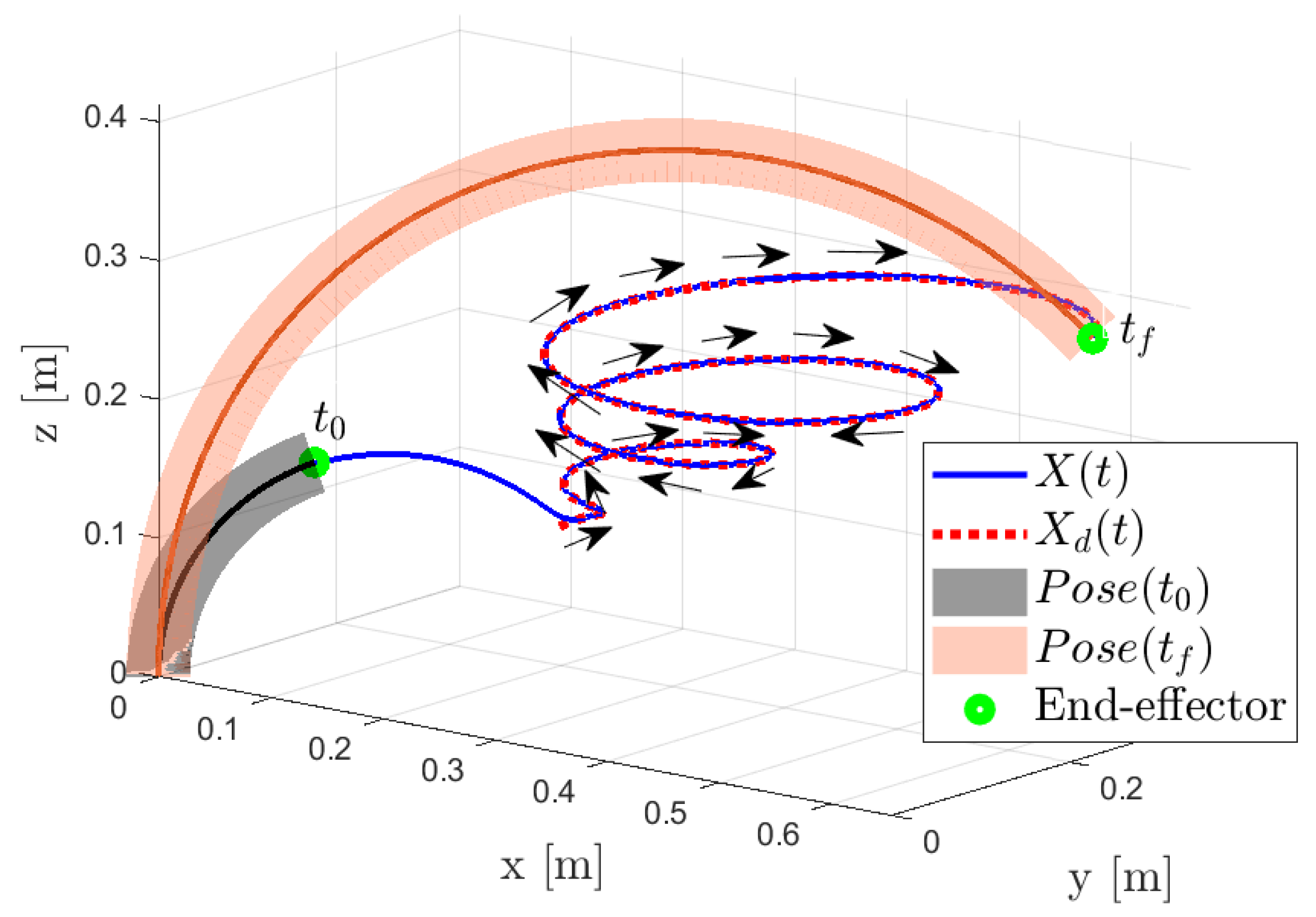
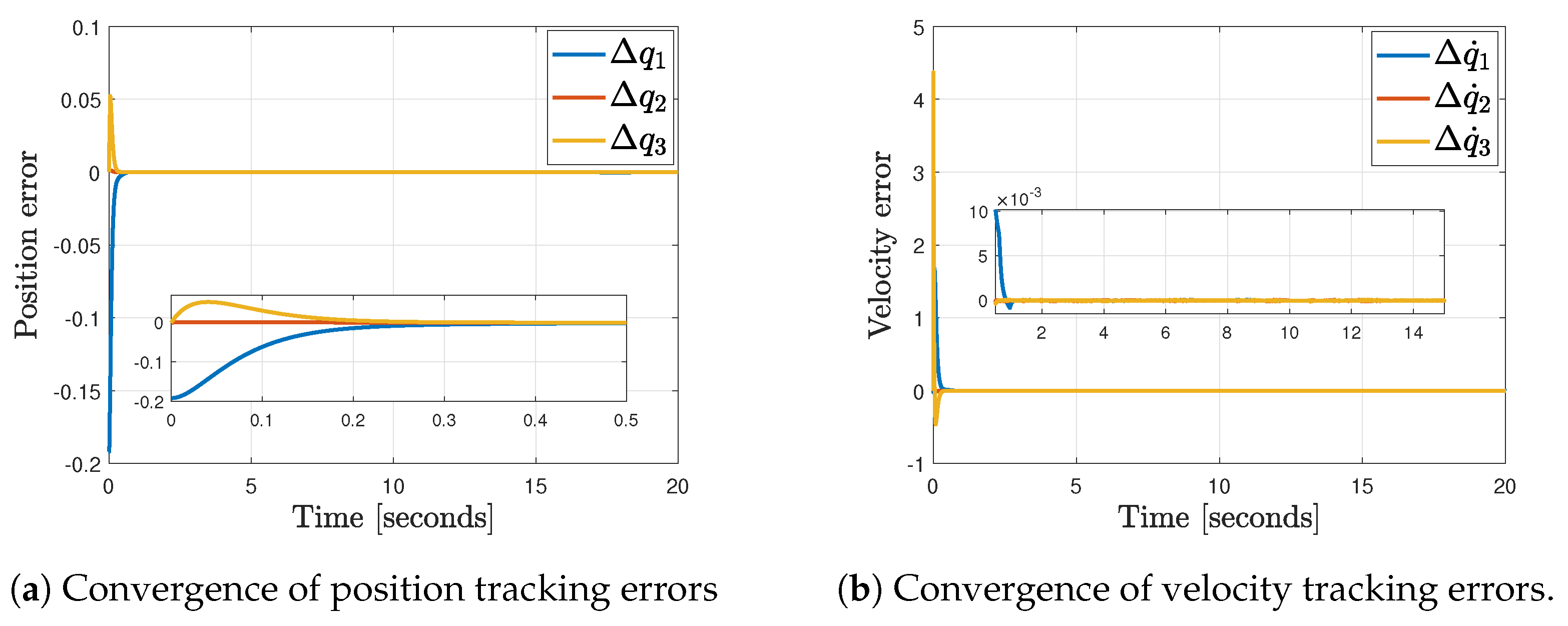
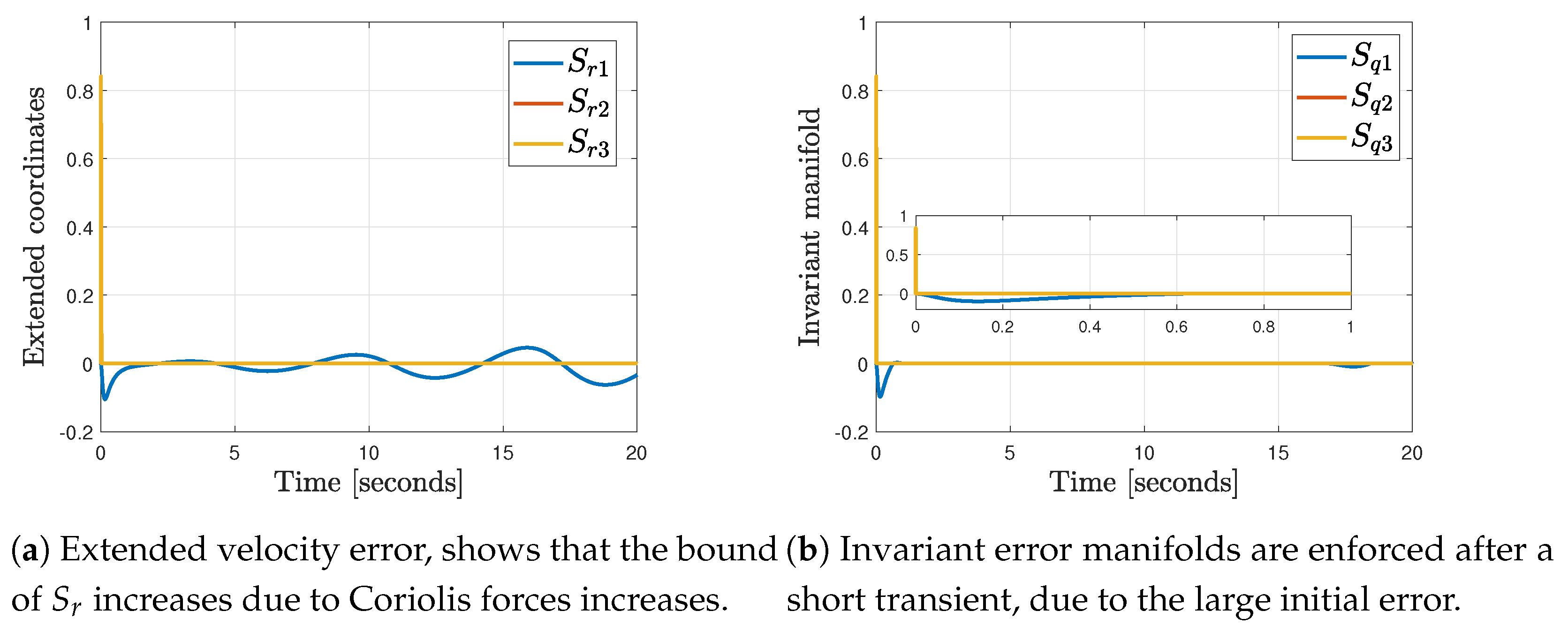
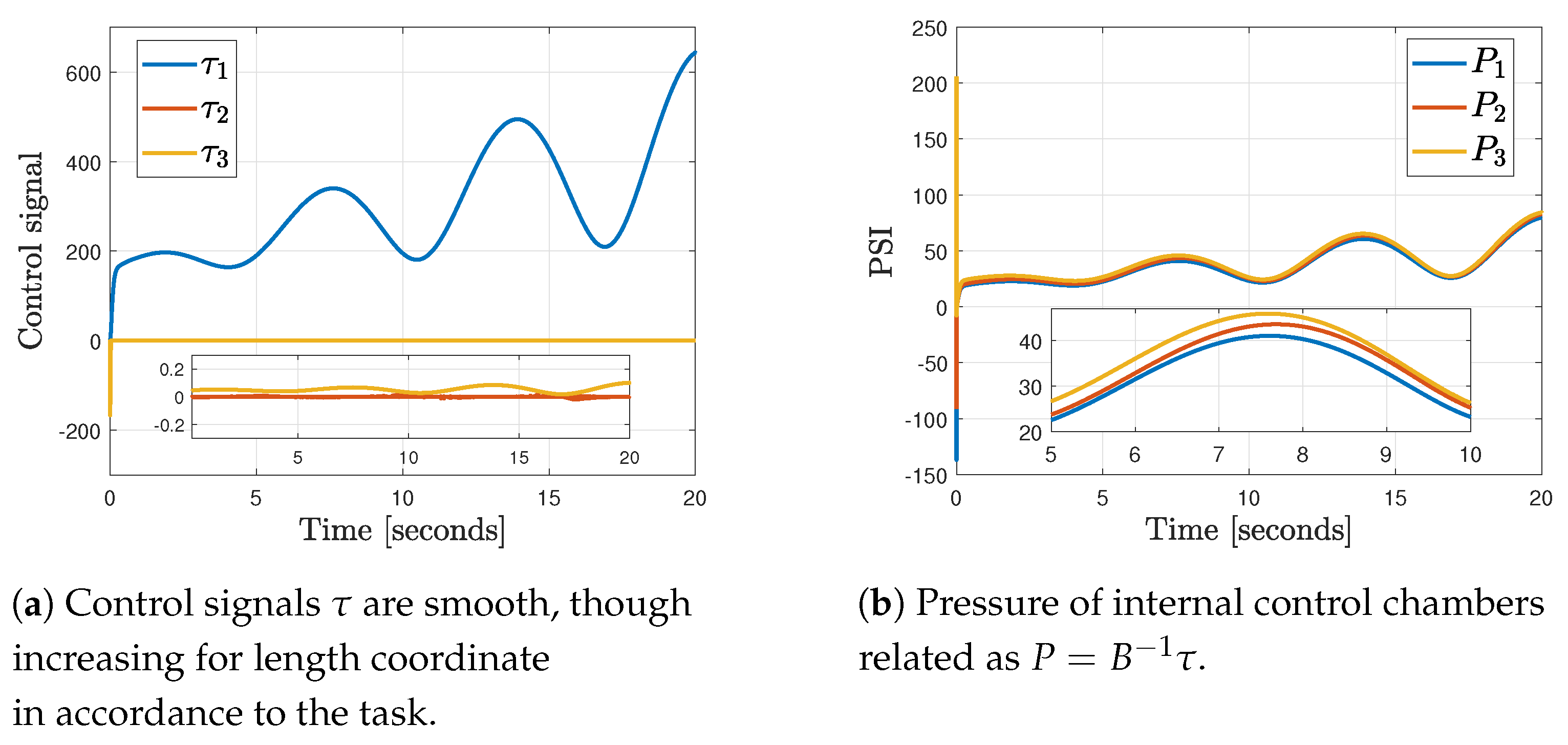
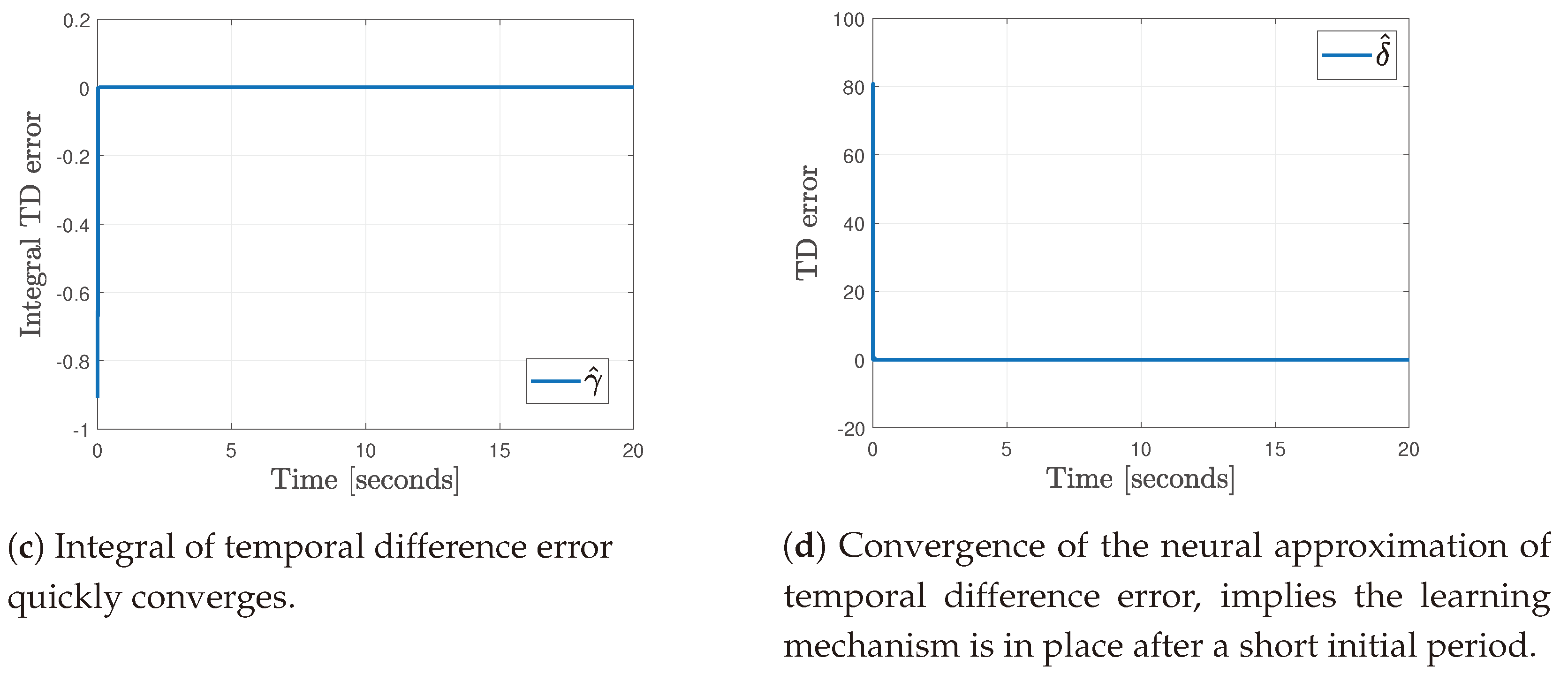
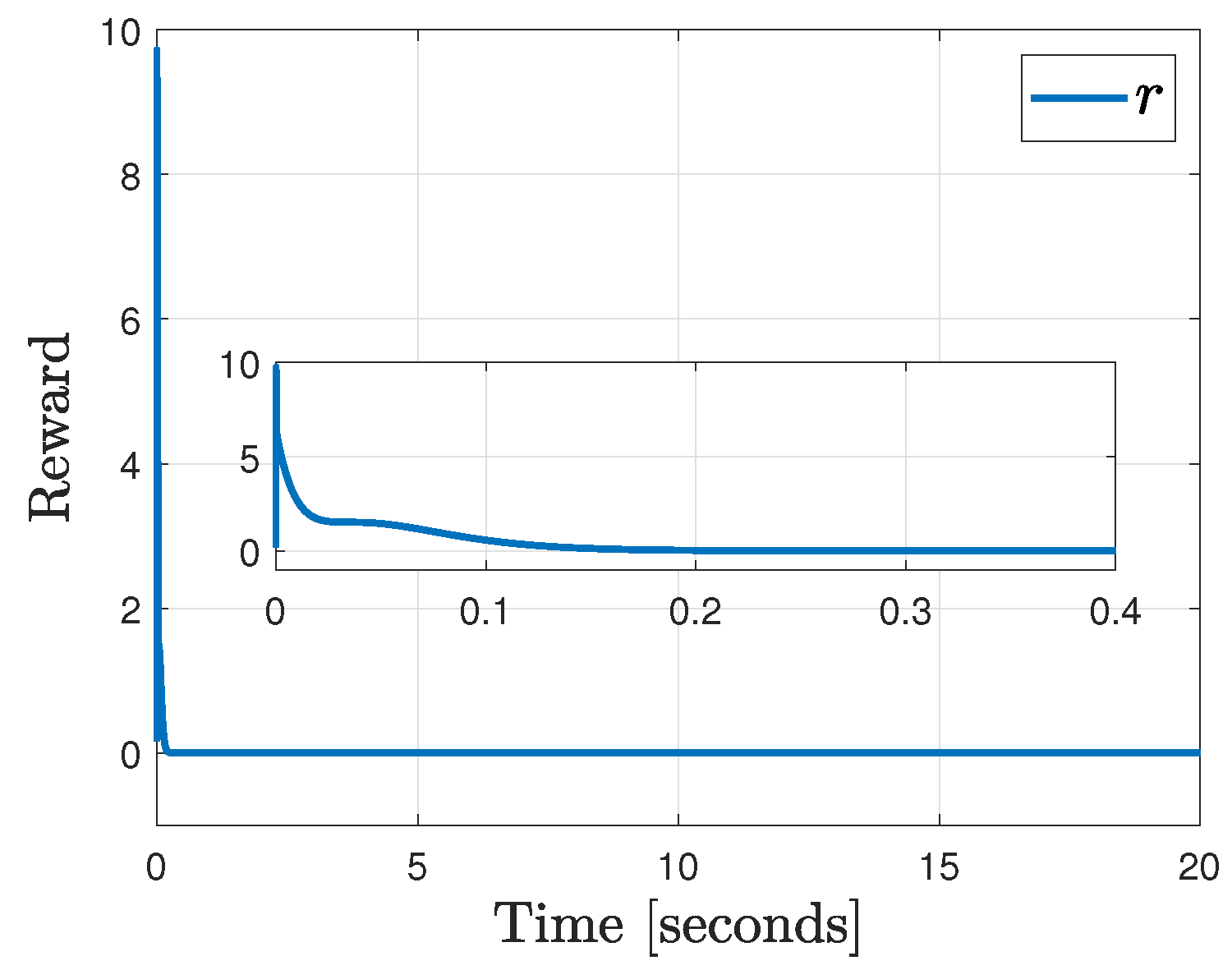
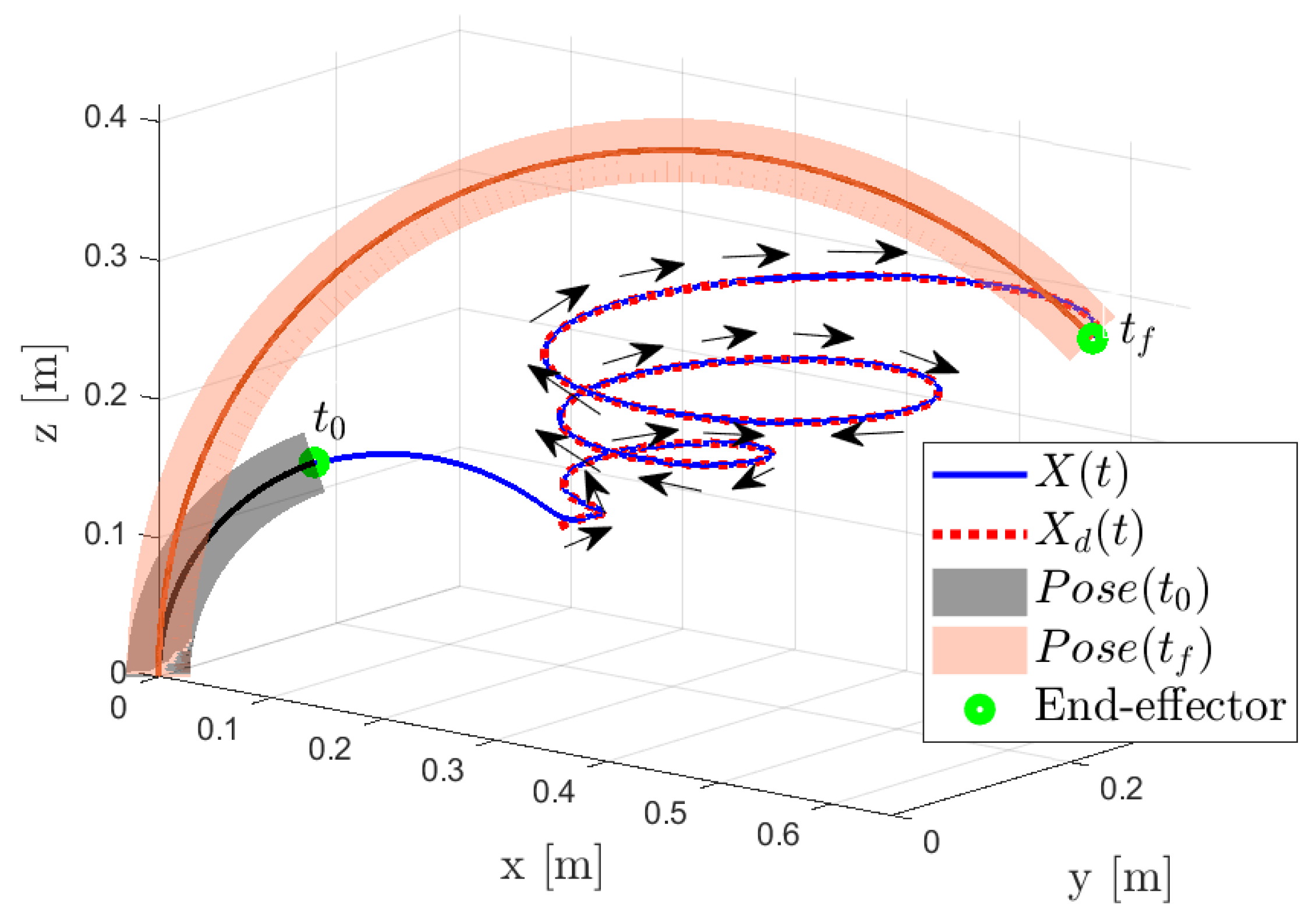
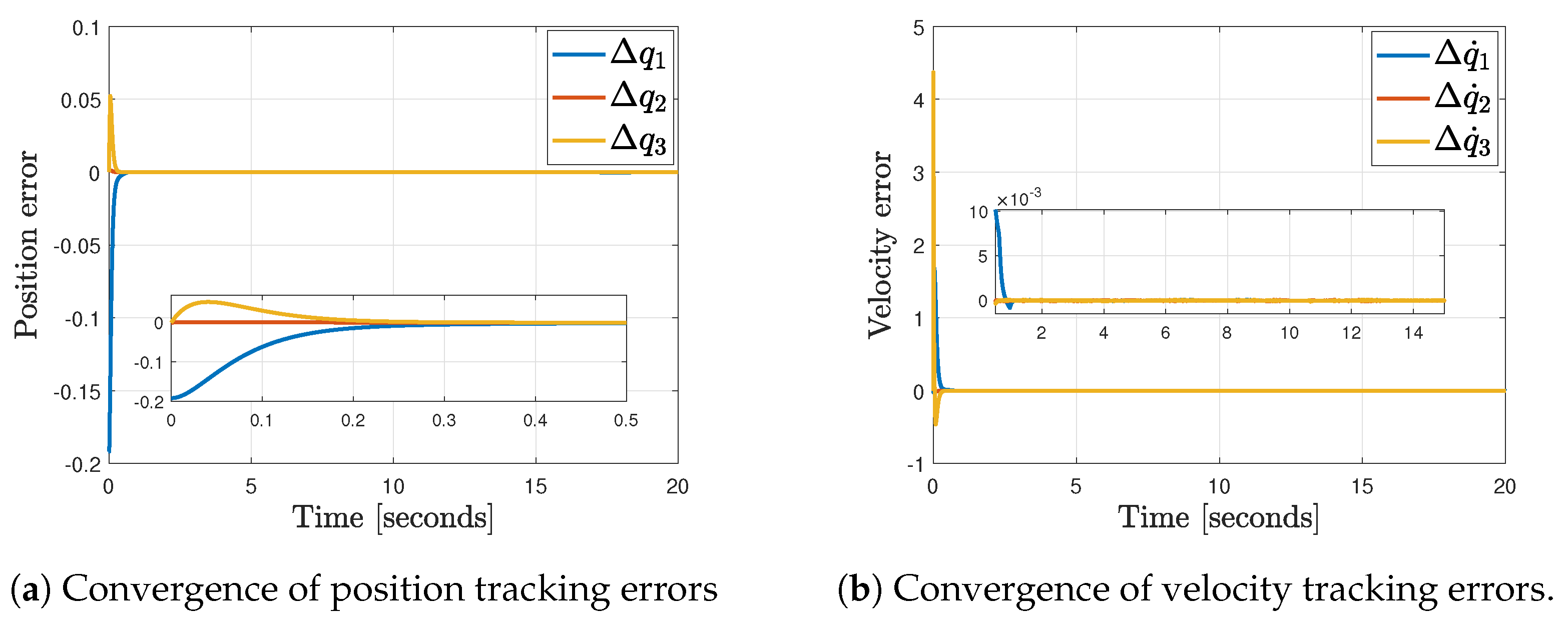
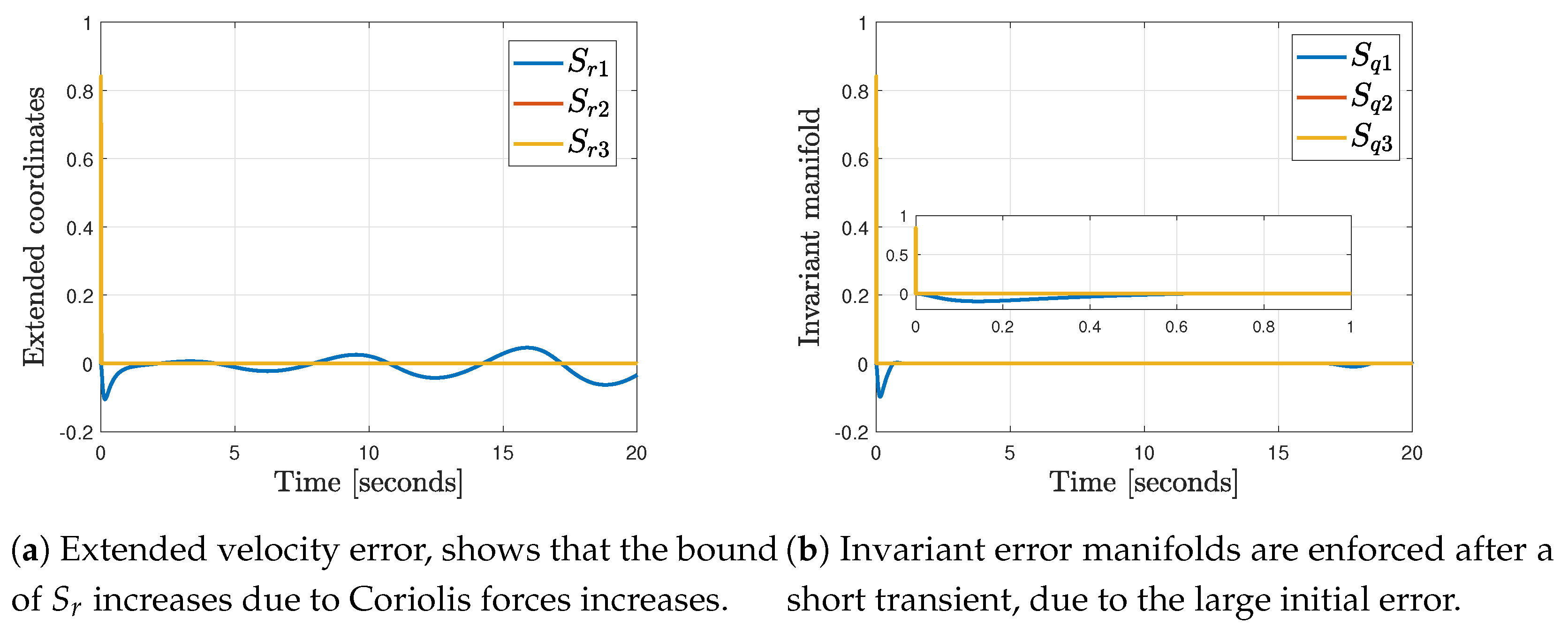
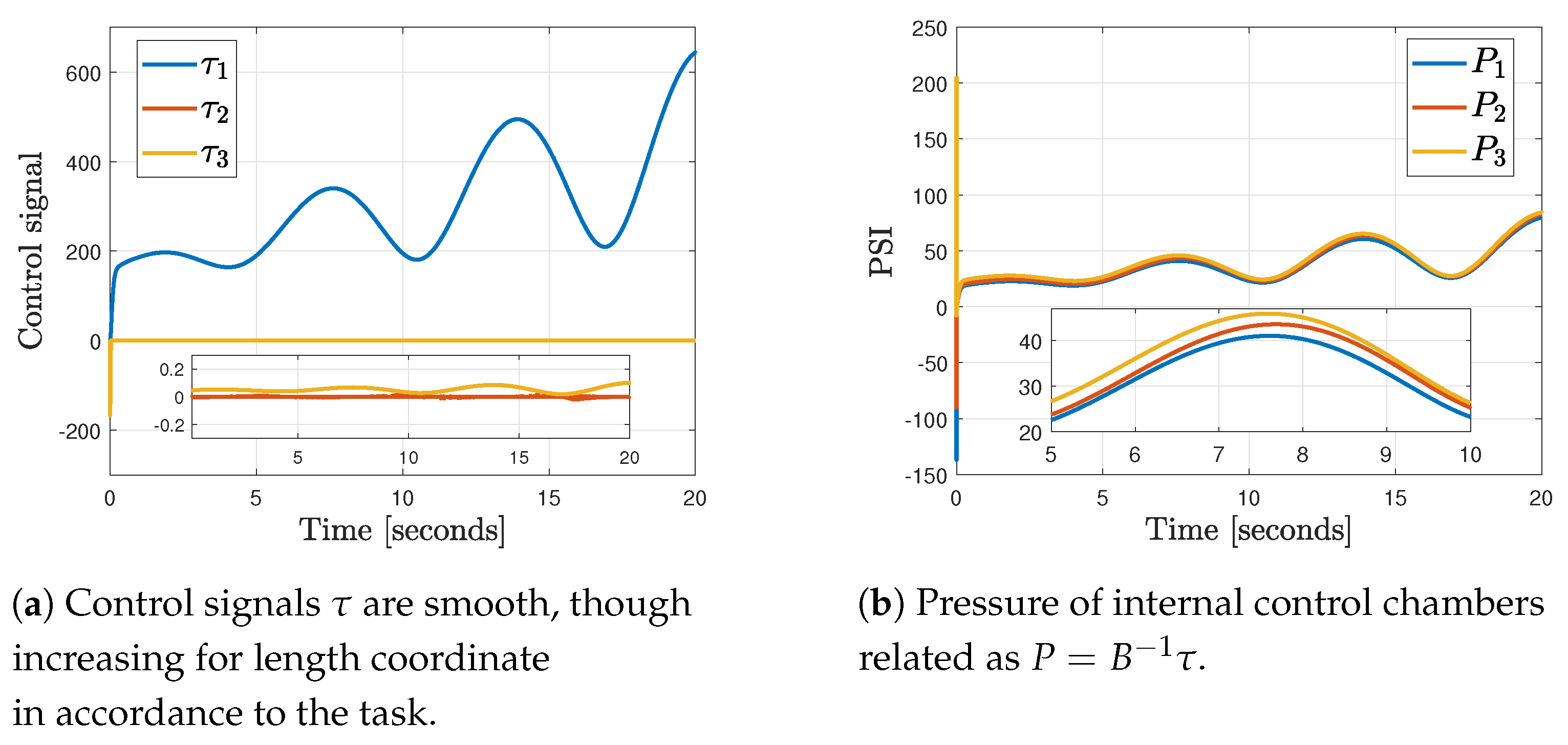
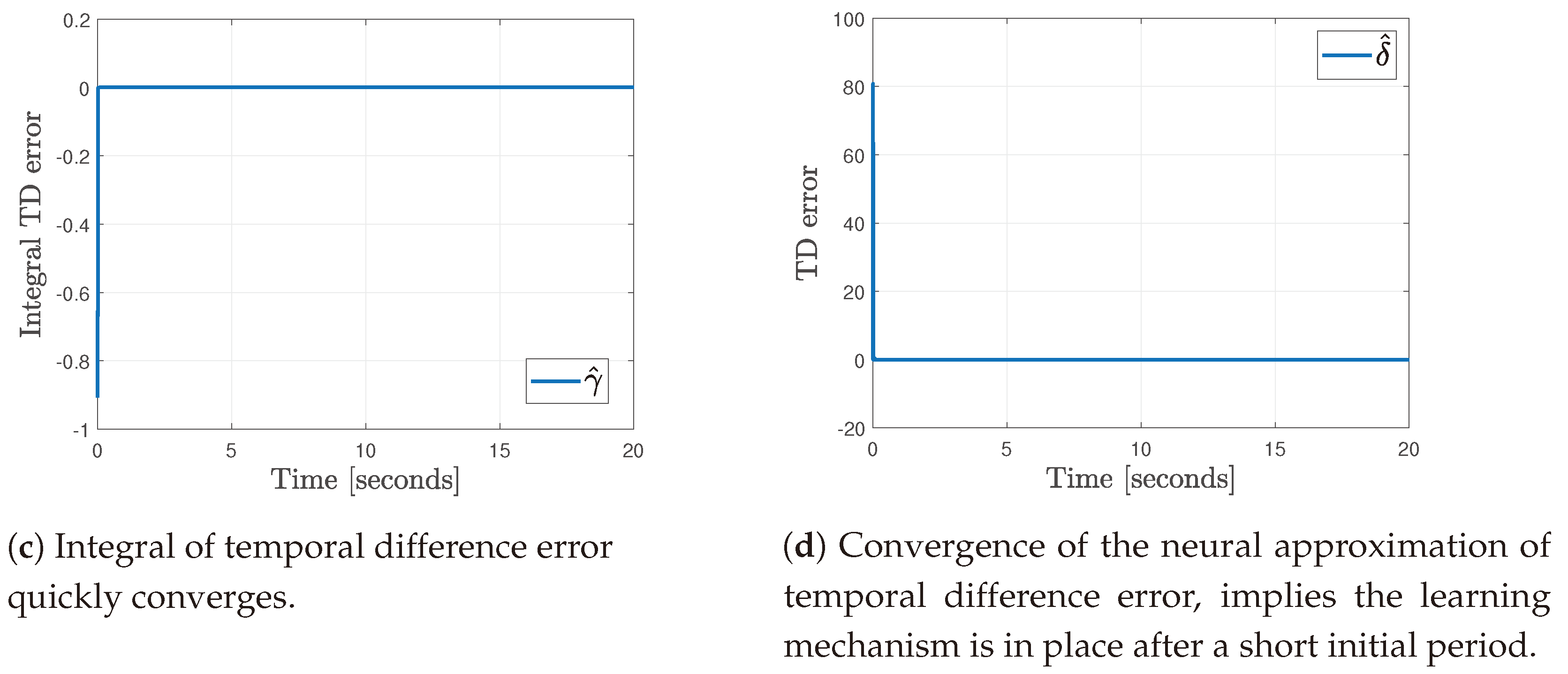
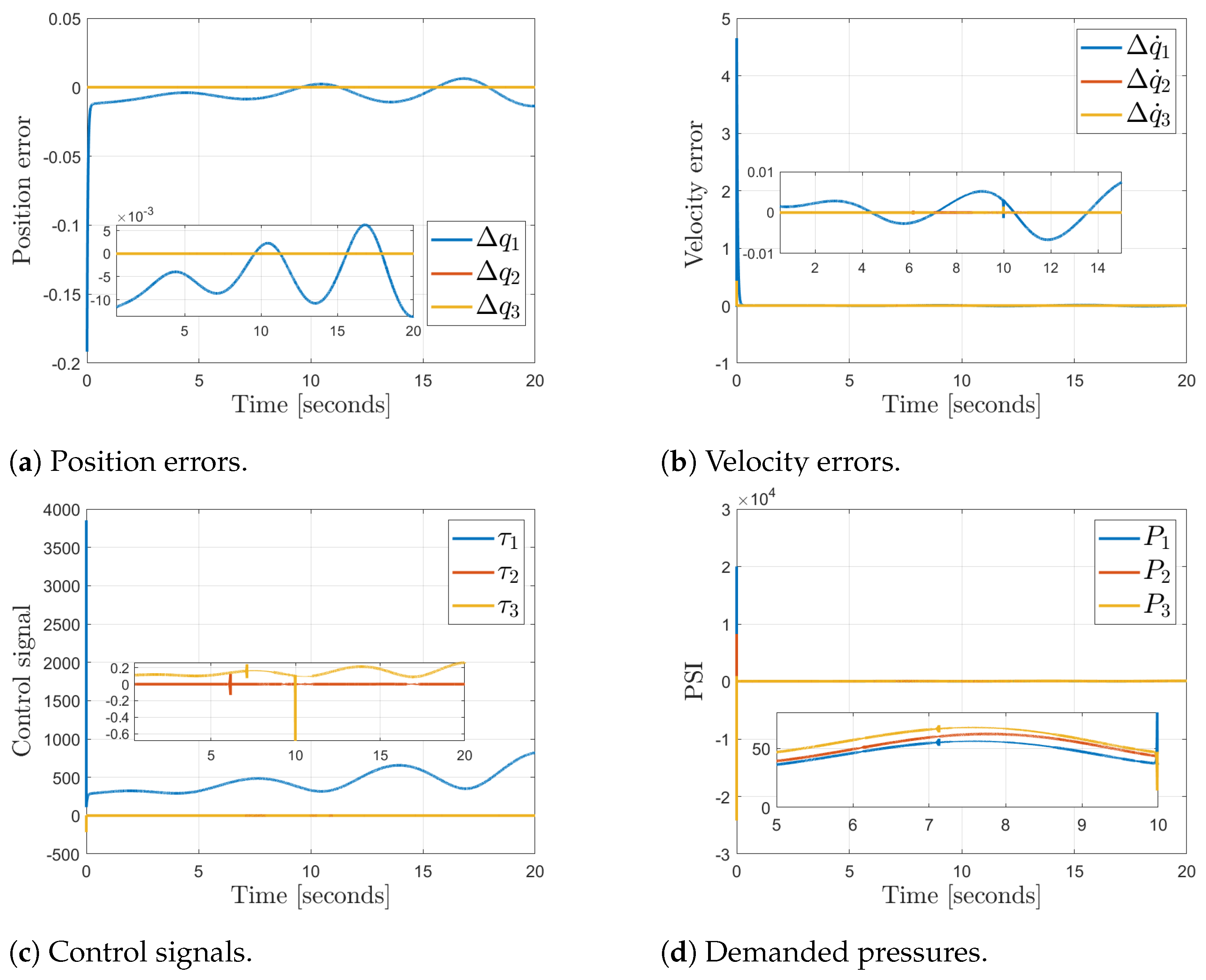
4.5. Results
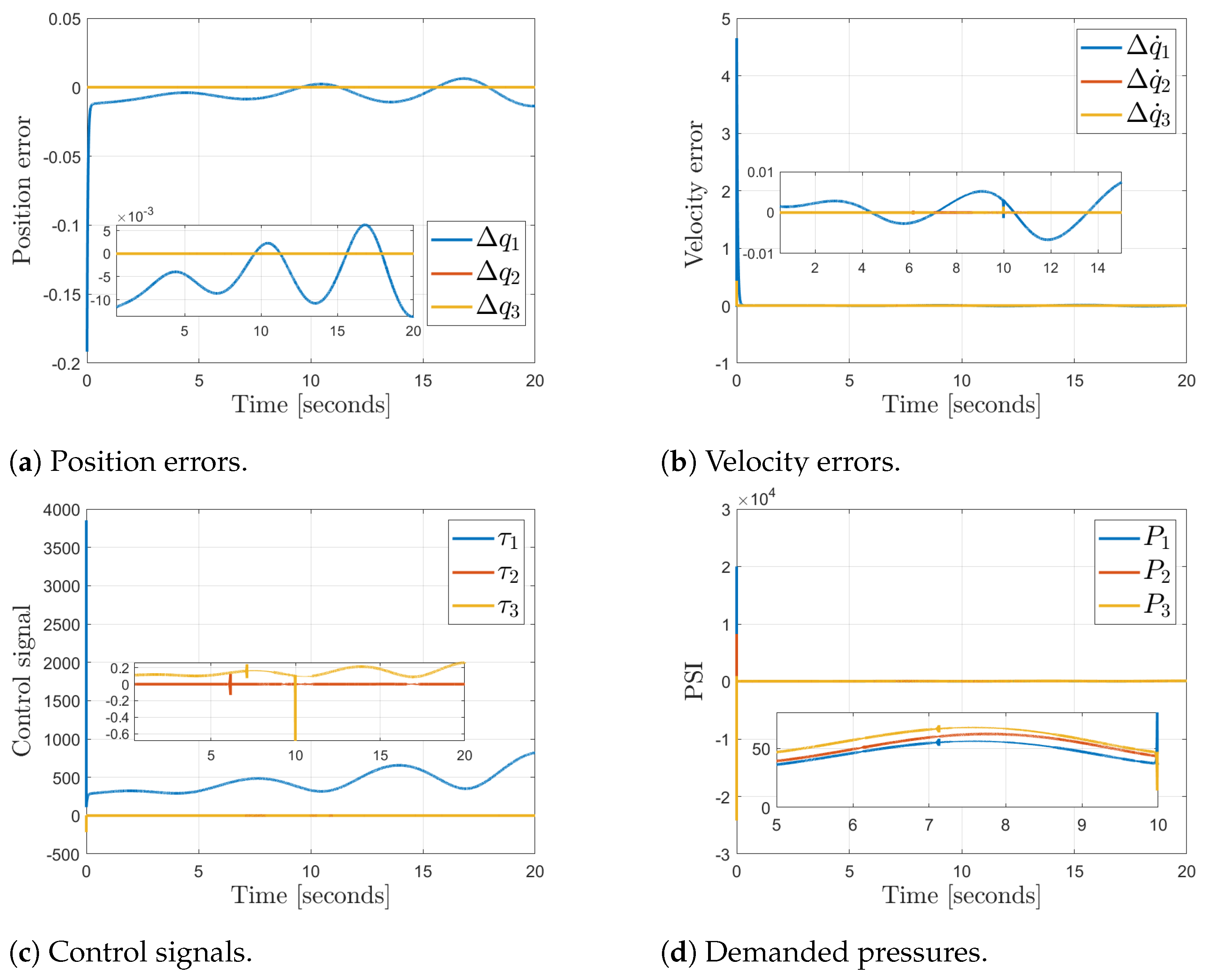
Comparative Results vs. Classical PID Controller
5. Discussions
5.1. On the Actor–Critic Architecture with Adaptive Neural Weights
5.2. On Simulation Study
5.3. Advantages, Disadvantages, and Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Stability Proof
Appendix A.1. Critic Neural Network
Appendix A.2. Proof of Theorem
References
- Barto, A.G.; Sutton, R.S.; Anderson, C.W. Looking Back on the Actor—Critic Architecture. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 40–50. [Google Scholar] [CrossRef]
- Wang, F.Y.; Zhang, H.; Liu, D. Adaptive Dynamic Programming: An Introduction. IEEE Comput. Intell. Mag. 2009, 4, 39–47. [Google Scholar] [CrossRef]
- Lewis, F.; Vrabie, D.; Syrmos, V. Optimal Control; EngineeringPro Collection; Wiley: Hoboken, NJ, USA, 2012. [Google Scholar]
- Guo, K.; Pan, Y. Composite adaptation and learning for robot control: A survey. Annu. Rev. Control. 2023, 55, 279–290. [Google Scholar] [CrossRef]
- Jin, L.; Li, S.; Yu, J.; He, J. Robot manipulator control using neural networks: A survey. Neurocomputing 2018, 285, 23–34. [Google Scholar] [CrossRef]
- He, W.; Chen, Y.; Yin, Z. Adaptive Neural Network Control of an Uncertain Robot with Full-State Constraints. IEEE Trans. Cybern. 2016, 46, 620–629. [Google Scholar] [CrossRef] [PubMed]
- Song, B.; Slotine, J.J.; Pham, Q.C. Stability Guarantees for Continuous RL Control. arXiv 2022, arXiv:cs.RO/2209.07324. [Google Scholar]
- Bhagat, S.; Banerjee, H.; Ho Tse, Z.T.; Ren, H. Deep reinforcement learning for soft, flexible robots: Brief review with impending challenges. Robotics 2019, 8, 4. [Google Scholar] [CrossRef]
- Trejo-Ramos, C.A.; Olguín-Díaz, E.; Parra-Vega, V. Lagrangian and Quasi-Lagrangian Models for Noninertial Pneumatic Soft Cylindrical Robots. J. Dyn. Syst. Meas. Control. 2022, 144, 121004. [Google Scholar] [CrossRef]
- Guan, Z.; Yamamoto, T. Design of a Reinforcement Learning PID controller. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–6. [Google Scholar] [CrossRef]
- He, W.; Gao, H.; Zhou, C.; Yang, C.; Li, Z. Reinforcement Learning Control of a Flexible Two-Link Manipulator: An Experimental Investigation. IEEE Trans. Syst. Man Cybern. Syst. 2021, 51, 7326–7336. [Google Scholar] [CrossRef]
- Vázquez-García, C.E.; Trejo-Ramos, C.A.; Parra-Vega, V.; Olguín-Díaz, E. Quasi-static Optimal Design of a Pneumatic Soft Robot to Maximize Pressure-to-Force Transference. In Proceedings of the 2021 Latin American Robotics Symposium (LARS), 2021 Brazilian Symposium on Robotics (SBR), and 2021 Workshop on Robotics in Education (WRE), Natal, Brazil, 11–15 October 2021; pp. 126–131. [Google Scholar]
- Parra-Vega, V.; Arimoto, S.; Liu, Y.H.; Hirzinger, G.; Akella, P. Dynamic sliding PID control for tracking of robot manipulators: Theory and experiments. IEEE Trans. Robot. Autom. 2003, 19, 967–976. [Google Scholar] [CrossRef]
- Yang, T.; Xiao, Y.; Zhang, Z.; Liang, Y.; Li, G.; Zhang, M.; Li, S.; Wong, T.W.; Wang, Y.; Li, T.; et al. A soft artificial muscle driven robot with reinforcement learning. Sci. Rep. 2018, 8, 14518. [Google Scholar] [CrossRef]
- Ishige, M.; Umedachi, T.; Taniguchi, T.; Kawahara, Y. Exploring Behaviors of Caterpillar-Like Soft Robots with a Central Pattern Generator-Based Controller and Reinforcement Learning. Soft Robot. 2019, 6, 579–594. [Google Scholar] [CrossRef] [PubMed]
- Boyraz, P.; Runge, G.; Raatz, A. An overview of novel actuators for soft robotics. Actuators 2018, 7, 48. [Google Scholar] [CrossRef]
- Cianchetti, M.; Ranzani, T.; Gerboni, G.; De Falco, I.; Laschi, C.; Menciassi, A. STIFF-FLOP surgical manipulator: Mechanical design and experimental characterization of the single module. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots And Systems, Tokyo, Japan, 3–7 November 2013; pp. 3576–3581. [Google Scholar]
- Xu, F.; Wang, H.; Au, K.W.S.; Chen, W.; Miao, Y. Underwater dynamic modeling for a cable-driven soft robot arm. IEEE/ASME Trans. Mechatronics 2018, 23, 2726–2738. [Google Scholar] [CrossRef]
- Marchese, A.D.; Katzschmann, R.K.; Rus, D. A recipe for soft fluidic elastomer robots. Soft Robot. 2015, 2, 7–25. [Google Scholar] [CrossRef]
- Marchese, A.D.; Komorowski, K.; Onal, C.D.; Rus, D. Design and control of a soft and continuously deformable 2d robotic manipulation system. In Proceedings of the 2014 IEEE International Conference ON Robotics And Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 2189–2196. [Google Scholar]
- Katzschmann, R.K.; Marchese, A.D.; Rus, D. Autonomous object manipulation using a soft planar grasping manipulator. Soft Robot. 2015, 2, 155–164. [Google Scholar] [CrossRef]
- Connolly, F.; Walsh, C.J.; Bertoldi, K. Automatic design of fiber-reinforced soft actuators for trajectory matching. Proc. Natl. Acad. Sci. USA 2017, 114, 51–56. [Google Scholar] [CrossRef]
- Hannan, M.W.; Walker, I.D. Kinematics and the implementation of an elephant’s trunk manipulator and other continuum style robots. J. Robot. Syst. 2003, 20, 45–63. [Google Scholar] [CrossRef]
- Sadati, S.H.; Naghibi, S.E.; Shiva, A.; Noh, Y.; Gupta, A.; Walker, I.D.; Althoefer, K.; Nanayakkara, T. A geometry deformation model for braided continuum manipulators. Front. Robot. AI 2017, 4, 22. [Google Scholar] [CrossRef]
- Webster, R.J., III; Jones, B.A. Design and kinematic modeling of constant curvature continuum robots: A review. Int. J. Robot. Res. 2010, 29, 1661–1683. [Google Scholar] [CrossRef]
- Godage, I.S.; Branson, D.T.; Guglielmino, E.; Medrano-Cerda, G.A.; Caldwell, D.G. Shape function-based kinematics and dynamics for variable length continuum robotic arms. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 3–9 May 2011; pp. 452–457. [Google Scholar]
- Odom, E.M.; Egelhoff, C.J. Teaching deflection of stepped shafts: Castigliano’s theorem, dummy loads, heaviside step functions and numerical integration. In Proceedings of the 2011 Frontiers in Education Conference (FIE), Rapid City, SD, USA, 12–15 October 2011; pp. F3H-1–F3H-6. [Google Scholar] [CrossRef]
- Garcia, R.; Parra-Vega, V. Tracking control of robot manipulators using second order neuro sliding mode. Lat. Am. Appl. Res. 2009, 39, 285–294. [Google Scholar]
- Doya, K. Temporal Difference Learning in Continuous Time and Space. In Advances in Neural Information Processing Systems; Touretzky, D., Mozer, M., Hasselmo, M., Eds.; MIT Press: Cambridge, MA, USA, 1995; Volume 8, pp. 1073–1079. [Google Scholar]
- Kandasamy, S.; Teo, M.; Ravichandran, N.; McDaid, A.; Jayaraman, K.; Aw, K. Body-powered and portable soft hydraulic actuators as prosthetic hands. Robotics 2022, 11, 71. [Google Scholar] [CrossRef]
- Bieze, T.M.; Largilliere, F.; Kruszewski, A.; Zhang, Z.; Merzouki, R.; Duriez, C. Finite Element Method-Based Kinematics and Closed-Loop Control of Soft, Continuum Manipulators. Soft Robot. 2018, 5, 348–364. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Zhang, D.; Liu, Y.; Lueth, T.C. FEM-Based Mechanics Modeling of Bio-Inspired Compliant Mechanisms for Medical Applications. IEEE Trans. Med. Robot. Bionics 2020, 2, 364–373. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Description | Value |
|---|---|---|
| External radius | m | |
| w | Wall width | m |
| Initial length | m | |
| Initial bending | rad | |
| E | Young’s modulus | MPa |
| Desired pose |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pantoja-Garcia, L.; Parra-Vega, V.; Garcia-Rodriguez, R.; Vázquez-García, C.E. A Novel Actor—Critic Motor Reinforcement Learning for Continuum Soft Robots. Robotics 2023, 12, 141. https://doi.org/10.3390/robotics12050141
Pantoja-Garcia L, Parra-Vega V, Garcia-Rodriguez R, Vázquez-García CE. A Novel Actor—Critic Motor Reinforcement Learning for Continuum Soft Robots. Robotics. 2023; 12(5):141. https://doi.org/10.3390/robotics12050141
Chicago/Turabian StylePantoja-Garcia, Luis, Vicente Parra-Vega, Rodolfo Garcia-Rodriguez, and Carlos Ernesto Vázquez-García. 2023. "A Novel Actor—Critic Motor Reinforcement Learning for Continuum Soft Robots" Robotics 12, no. 5: 141. https://doi.org/10.3390/robotics12050141
APA StylePantoja-Garcia, L., Parra-Vega, V., Garcia-Rodriguez, R., & Vázquez-García, C. E. (2023). A Novel Actor—Critic Motor Reinforcement Learning for Continuum Soft Robots. Robotics, 12(5), 141. https://doi.org/10.3390/robotics12050141