
Bin Picking for Ship-Building Logistics Using Perception and Grasping Systems

 , , ,
, , ,  , and
, and 
Abstract
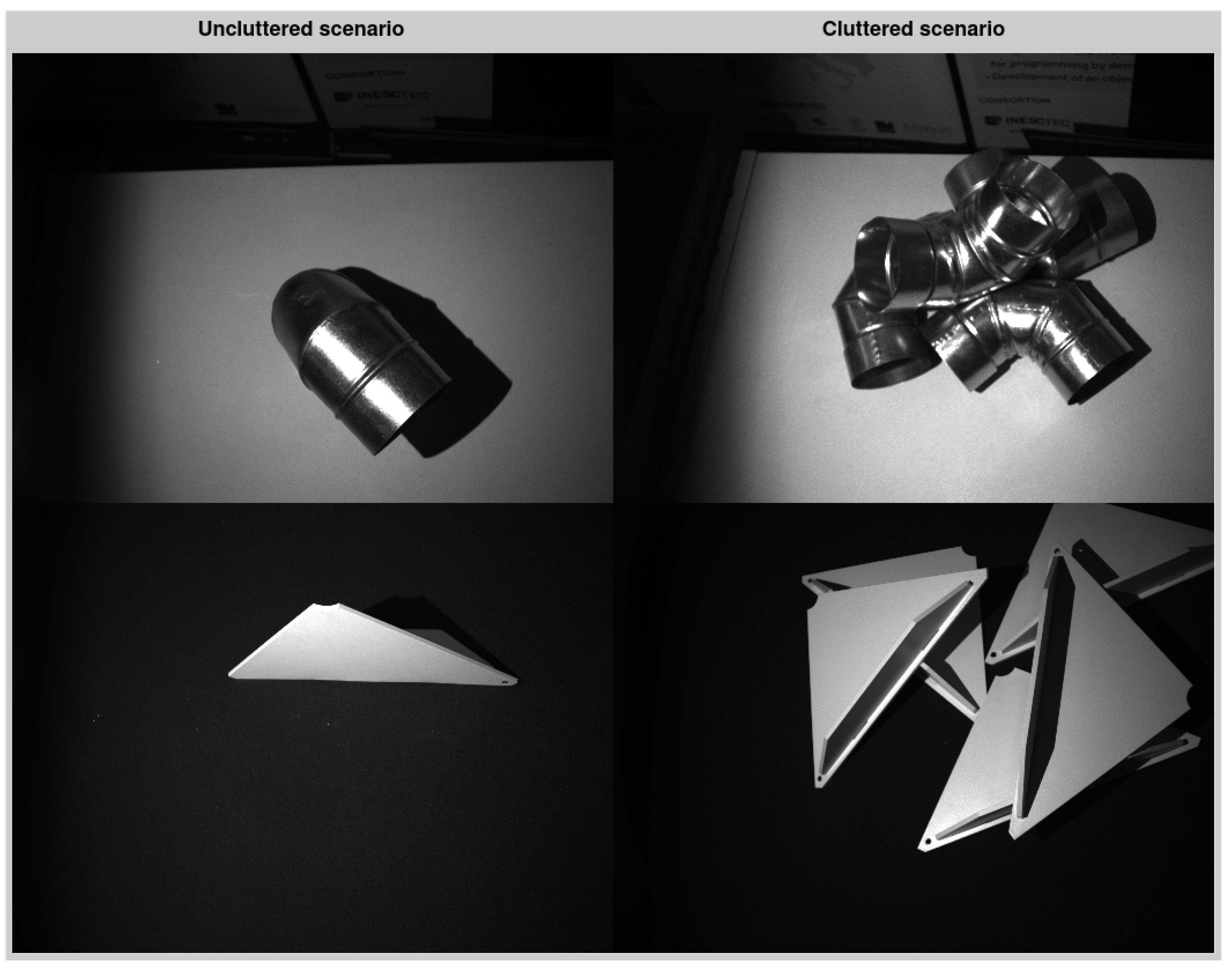
1. Introduction
- Segmenting individual object instances in highly cluttered and complex scenarios with precision and efficiency;
- Identifying and segmenting singular objects from environments composed of several layers of identical objects;
- Estimating the 6-DoF pose of the segmented object;
- Generating several grasp candidates and selecting a feasible grasp according to a set of heuristics;
- Working in different environment conditions, for example, various levels of illumination and various positions and orientations of the mobile manipulator in relation to the bin.
2. Related Work
2.1. Object Segmentation and Pose Estimation
2.2. Grasping Planner
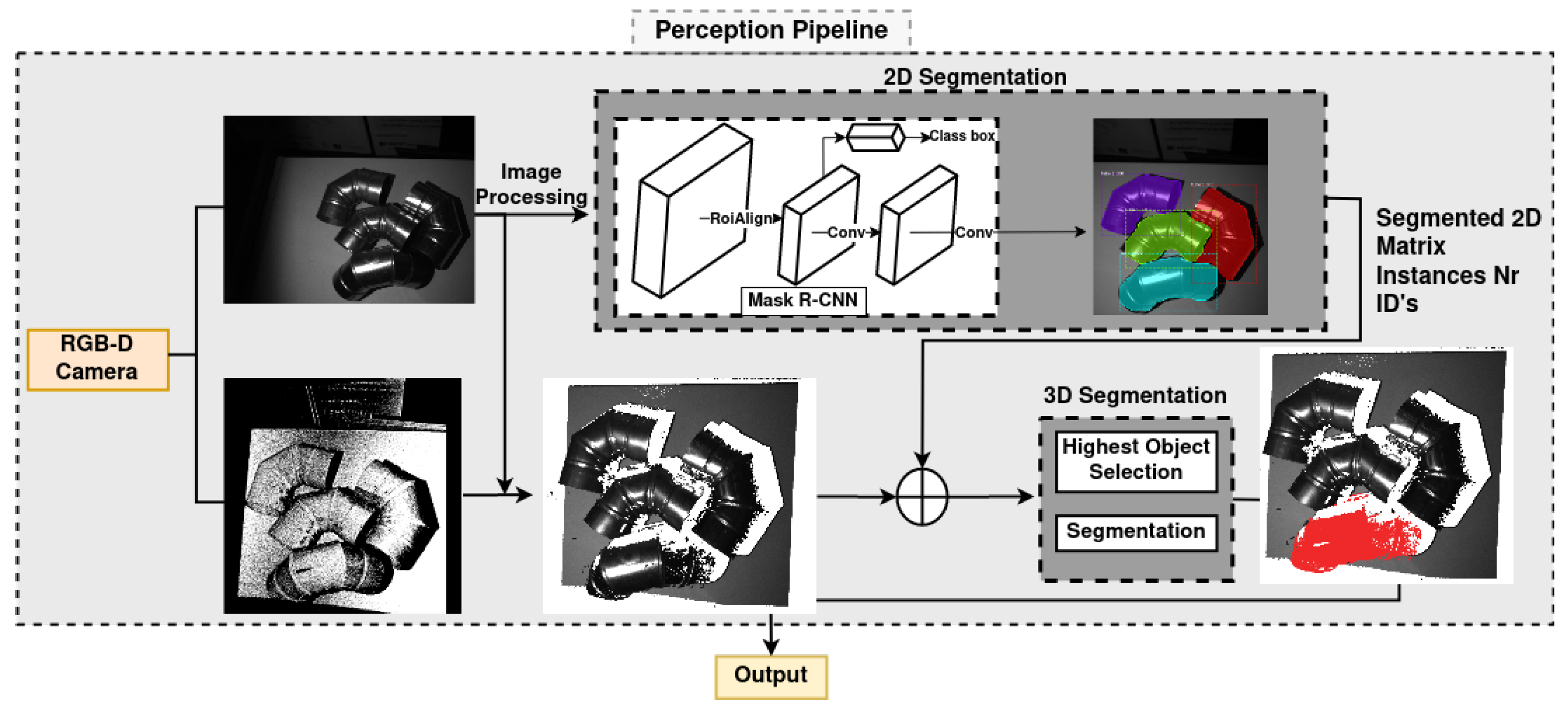
3. System Overview
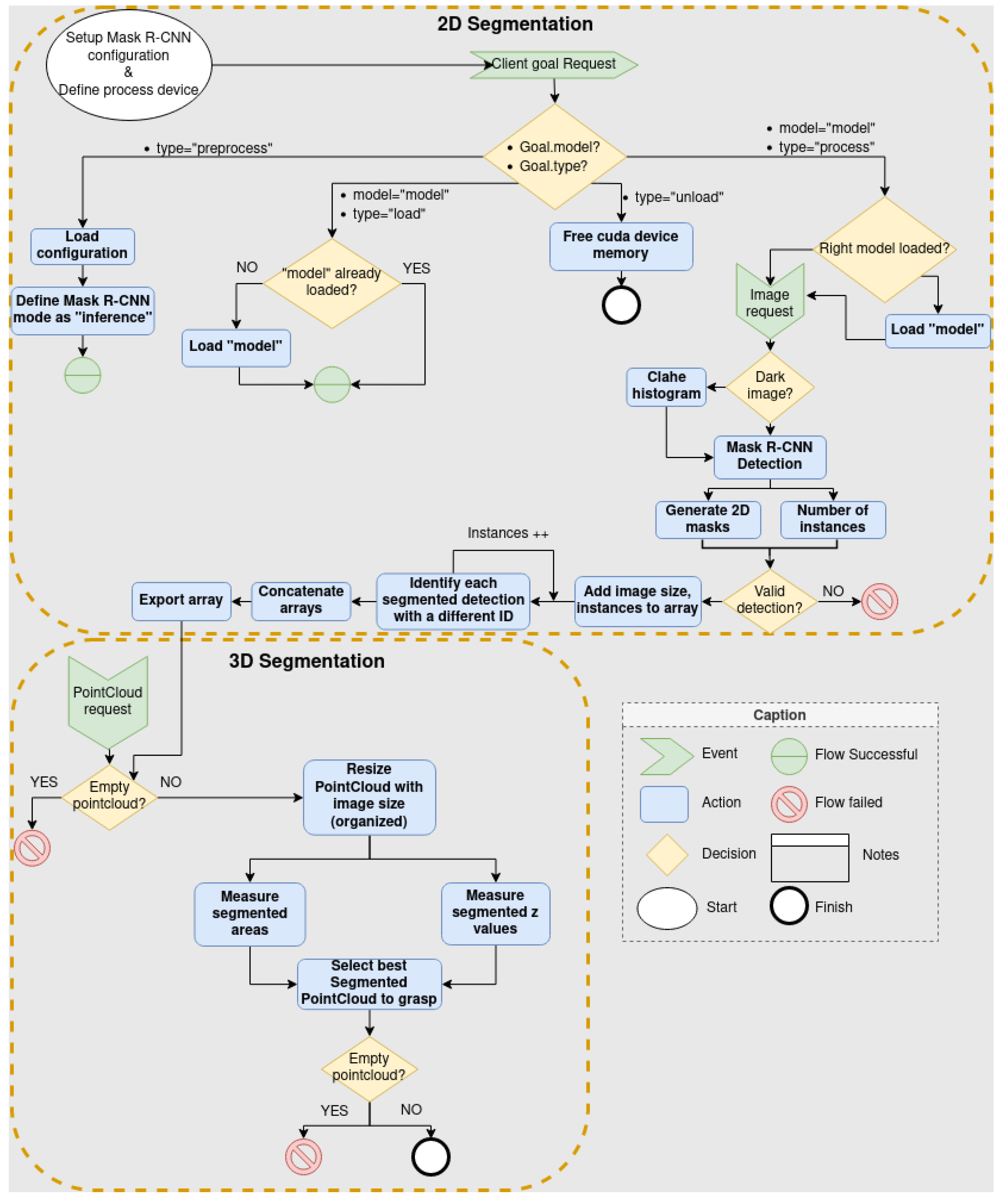
3.1. Proposed Segmentation Method
3.1.1. Mask R-CNN Training
3.1.2. Real/Simulated Dataset Generation
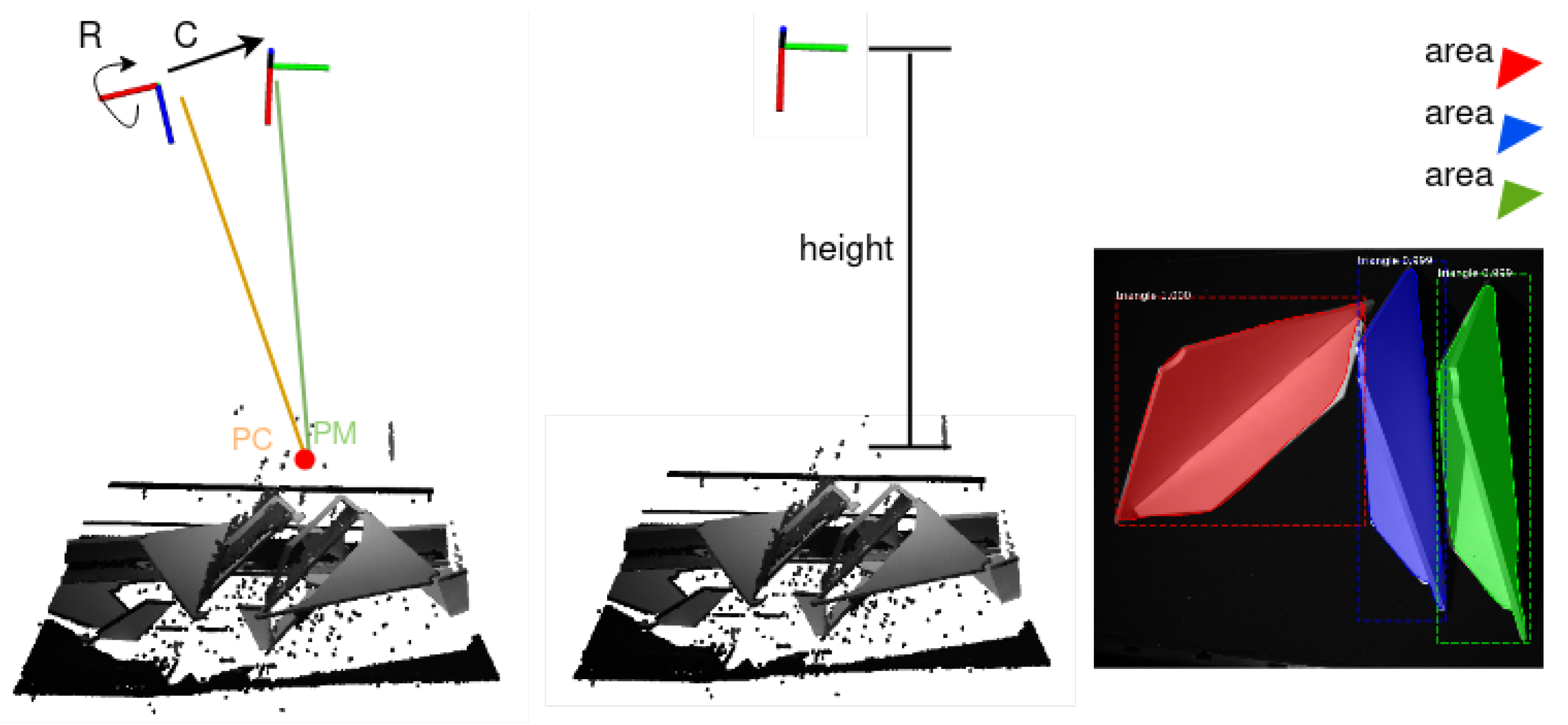
3.2. Object Pose Estimation
- The first image shows the raw point cloud.
- The second image introduces the segmented object with a blue point cloud.
- The third image presents the green reference point cloud before alignment.
- The fourth image shows the initial alignment between the filtered sensor data and the green reference point cloud using fast point feature histogram (FPFH) descriptors along with random sample consensus (RANSAC) matching.
- The fifth image shows the green reference point cloud after alignment using the iterative closest point (ICP) algorithm.
- The sixth image shows the comparison of the filtered sensor data with the matched green reference point cloud. Each point in the filtered sensor point cloud was given a color gradient between green and red based on the distance to the closest neighbor in the green reference point cloud. Green dots represent points with a very close neighbor and as such can be considered correctly matched, and red dots represent points with a far away neighbor and as such can be categorized as not having a matching point in the reference point cloud.
3.3. Grasping Planner
4. Results and Discussion
4.1. Data Generation
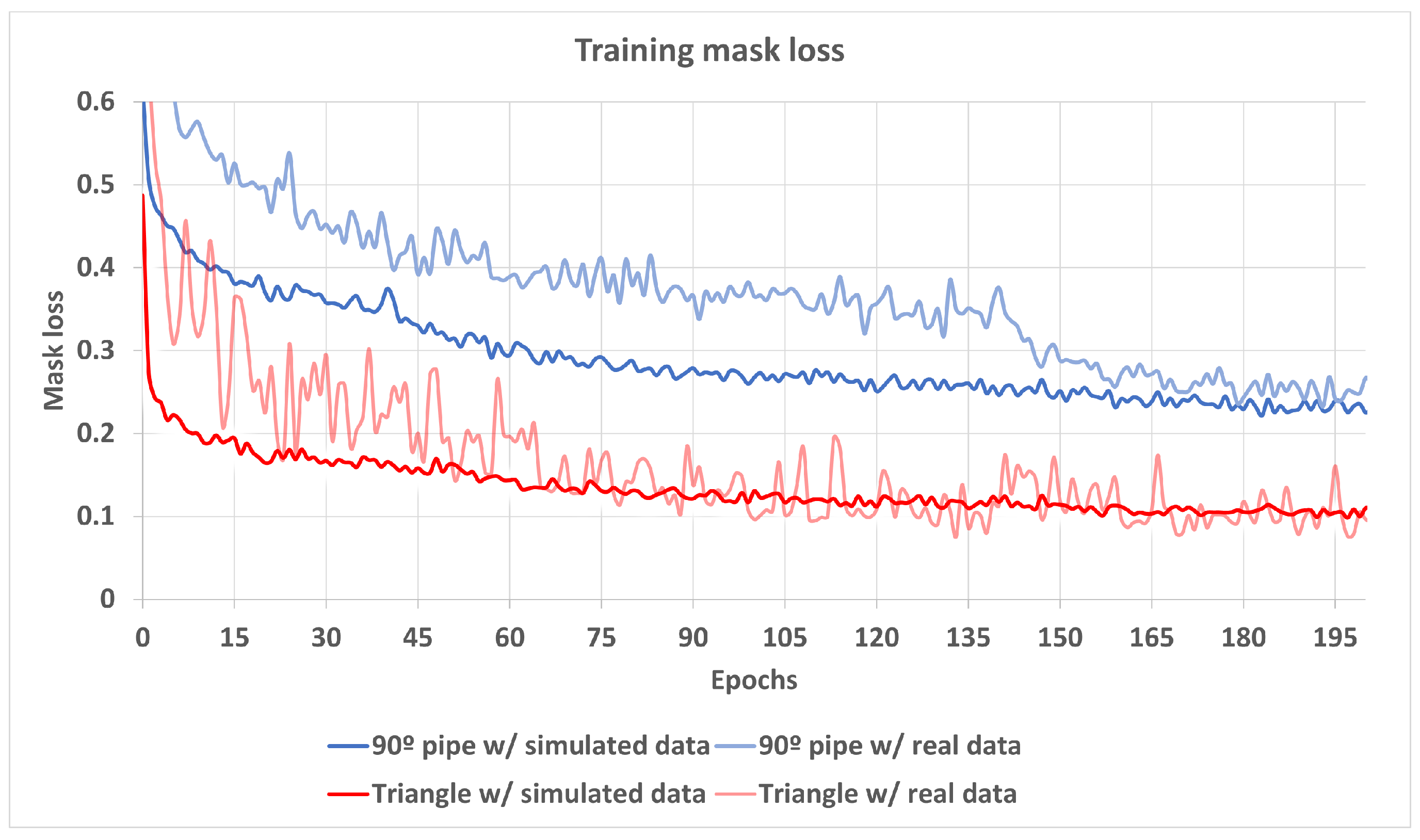
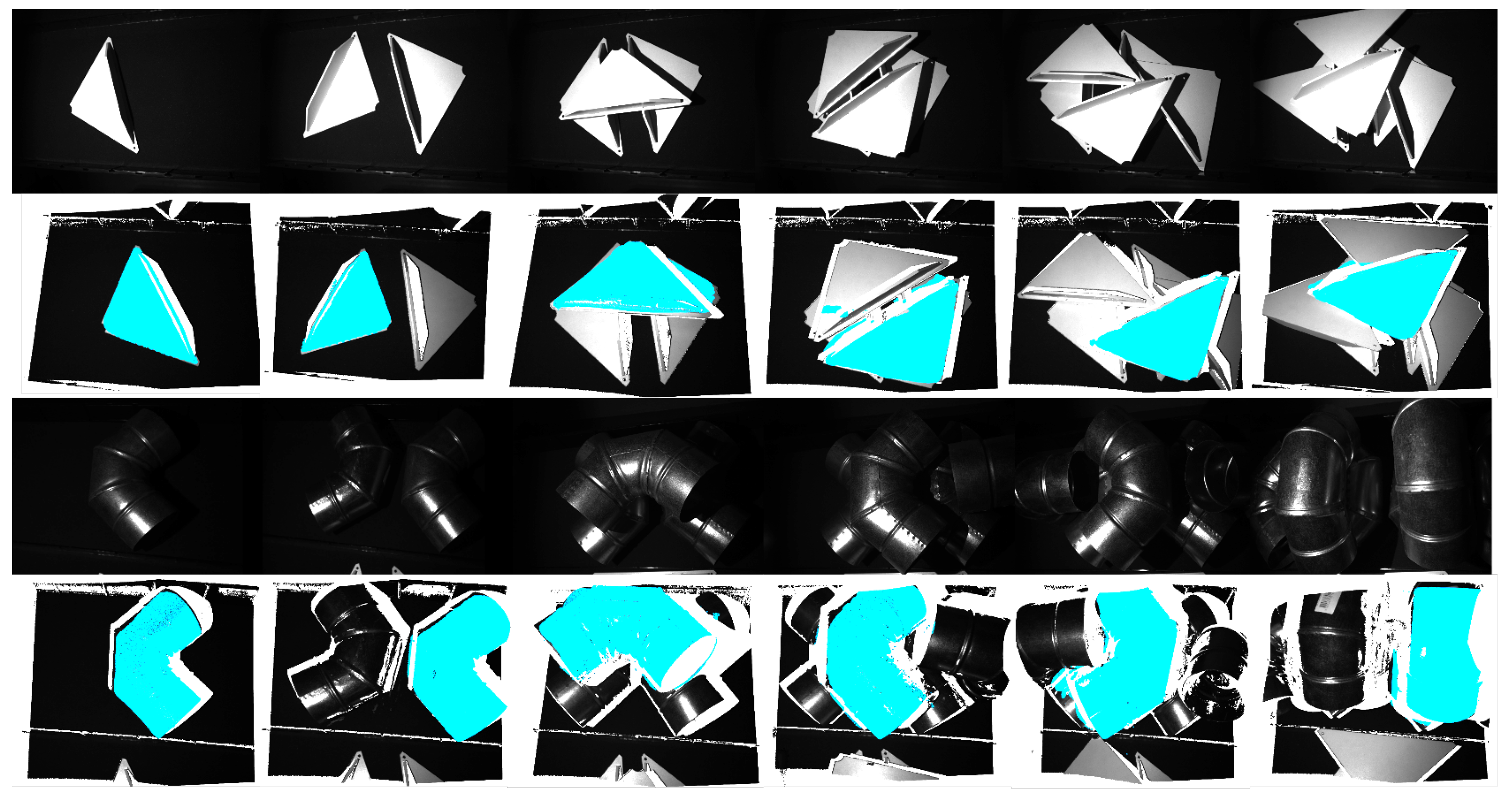
4.2. Mask R-CNN Training Results
4.3. Proposed Perception Pipeline Results
4.4. Intralogistics Experiments
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Boysen, N.; de Koster, R.; Weidinger, F. Warehousing in the e-commerce era: A survey. Eur. J. Oper. Res. 2019, 277, 396–411. [Google Scholar] [CrossRef]
- Ding, J.; Ni, C. Gird Based Line Segment Detector and Application: Vision System for Autonomous Ship Small Assembly Line. J. Mar. Sci. Eng. 2021, 9, 313. [Google Scholar] [CrossRef]
- Ferreira, L.A.; Figueira, Y.L.; Iglesias, I.F.; Álvarez Souto, M. Offline CAD-based Robot Programming and Welding Parametrization of a Flexible and Adaptive Robotic Cell Using Enriched CAD/CAM System for Shipbuilding. Procedia Manuf. 2017, 11, 215–223. [Google Scholar] [CrossRef]
- Liu, J.; Jiao, T.; Li, S.; Wu, Z.; Chen, Y.F. Automatic seam detection of welding robots using deep learning. Autom. Constr. 2022, 143, 104582. [Google Scholar] [CrossRef]
- Kershaw, J.; Yu, R.; Zhang, Y.; Wang, P. Hybrid machine learning-enabled adaptive welding speed control. J. Manuf. Process. 2021, 71, 374–383. [Google Scholar] [CrossRef]
- Gao, Y.; Ping, C.; Wang, L.; Wang, B. A Simplification Method for Point Cloud of T-Profile Steel Plate for Shipbuilding. Algorithms 2021, 14, 202. [Google Scholar] [CrossRef]
- Wada, K.; Murooka, M.; Okada, K.; Inaba, M. 3D Object Segmentation for Shelf Bin Picking by Humanoid with Deep Learning and Occupancy Voxel Grid Map. In Proceedings of the 2016 IEEE-RAS 16th International Conference on Humanoid Robots (Humanoids), Cancun, Mexico, 15–17 November 2016. [Google Scholar] [CrossRef]
- Blank, A.; Hiller, M.; Zhang, S.; Leser, A.; Metzner, M.; Lieret, M.; Thielecke, J.; Franke, J. 6DoF Pose-Estimation Pipeline for Texture-less Industrial Components in Bin Picking Applications. In Proceedings of the 2019 European Conference on Mobile Robots (ECMR), Prague, Czech Republic, 4–6 September 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Le, T.T.; Lin, C.Y. Bin-Picking for Planar Objects Based on a Deep Learning Network: A Case Study of USB Packs. Sensors 2019, 19, 3602. [Google Scholar] [CrossRef]
- Zhuang, C.; Wang, Z.; Zhao, H.; Ding, H. Semantic part segmentation method based 3D object pose estimation with RGB-D images for bin-picking. Robot. Comput.-Integr. Manuf. 2021, 68, 102086. [Google Scholar] [CrossRef]
- Höfer, T.; Shamsafar, F.; Benbarka, N.; Zell, A. Object detection and Autoencoder-based 6D pose estimation for highly cluttered Bin Picking. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021. [Google Scholar] [CrossRef]
- Dong, Z.; Liu, S.; Zhou, T.; Cheng, H.; Zeng, L.; Yu, X.; Liu, H. PPR-Net:Point-wise Pose Regression Network for Instance Segmentation and 6D Pose Estimation in Bin-picking Scenarios. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 1773–1780. [Google Scholar] [CrossRef]
- Xu, Y.; Arai, S.; Liu, D.; Lin, F.; Kosuge, K. FPCC: Fast point cloud clustering-based instance segmentation for industrial bin-picking. Neurocomputing 2022, 494, 255–268. [Google Scholar] [CrossRef]
- Buchholz, D.; Futterlieb, M.; Winkelbach, S.; Wahl, F.M. Efficient bin-picking and grasp planning based on depth data. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation, Karlsruhe, Germany, 6–10 May 2013; pp. 3245–3250. [Google Scholar] [CrossRef]
- He, T.; Aslam, S.; Tong, Z.; Seo, J. Scooping Manipulation Via Motion Control With a Two-Fingered Gripper and Its Application to Bin Picking. IEEE Robot. Autom. Lett. 2021, 6, 6394–6401. [Google Scholar] [CrossRef]
- Ichnowski, J.; Avigal, Y.; Liu, Y.; Goldberg, K. GOMP-FIT: Grasp-Optimized Motion Planning for Fast Inertial Transport. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022. [Google Scholar] [CrossRef]
- Leão, G.; Costa, C.M.; Sousa, A.; Veiga, G. Detecting and Solving Tube Entanglement in Bin Picking Operations. Appl. Sci. 2020, 10, 2264. [Google Scholar] [CrossRef]
- Iriondo, A.; Lazkano, E.; Ansuategi, A. Affordance-Based Grasping Point Detection Using Graph Convolutional Networks for Industrial Bin-Picking Applications. Sensors 2021, 21, 816. [Google Scholar] [CrossRef]
- Jiang, P.; Ishihara, Y.; Sugiyama, N.; Oaki, J.; Tokura, S.; Sugahara, A.; Ogawa, A. Depth Image–Based Deep Learning of Grasp Planning for Textureless Planar-Faced Objects in Vision-Guided Robotic Bin-Picking. Sensors 2020, 20, 706. [Google Scholar] [CrossRef]
- Tang, B.; Corsaro, M.; Konidaris, G.D.; Nikolaidis, S.; Tellex, S. Learning Collaborative Pushing and Grasping Policies in Dense Clutter. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 6177–6184. [Google Scholar]
- Mahler, J.; Liang, J.; Niyaz, S.; Laskey, M.; Doan, R.; Liu, X.; Ojea, J.A.; Goldberg, K. Dex-Net 2.0: Deep Learning to Plan Robust Grasps with Synthetic Point Clouds and Analytic Grasp Metrics. arXiv 2017. [Google Scholar] [CrossRef]
- Kumra, S.; Joshi, S.; Sahin, F. Antipodal Robotic Grasping using Generative Residual Convolutional Neural Network. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–24 January 2021. [Google Scholar] [CrossRef]
- Breyer, M.; Chung, J.J.; Ott, L.; Siegwart, R.; Nieto, J. Volumetric Grasping Network: Real-time 6 DOF Grasp Detection in Clutter. arXiv 2021. [Google Scholar] [CrossRef]
- Asif, U.; Tang, J.; Harrer, S. GraspNet: An Efficient Convolutional Neural Network for Real-time Grasp Detection for Low-powered Devices. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI-18, Stockholm, Sweden, 13–19 July 2018; 2018; pp. 4875–4882. [Google Scholar] [CrossRef]
- Pinto, L.; Gupta, A. Supersizing Self-supervision: Learning to Grasp from 50K Tries and 700 Robot Hours. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016. [Google Scholar] [CrossRef]
- Shao, Q.; Hu, J.; Wang, W.; Fang, Y.; Liu, W.; Qi, J.; Ma, J. Suction Grasp Region Prediction using Self-supervised Learning for Object Picking in Dense Clutter. In Proceedings of the 2019 IEEE 5th International Conference on Mechatronics System and Robots (ICMSR), Singapore, 3–5 May 2019. [Google Scholar] [CrossRef]
- Jiang, P.; Oaki, J.; Ishihara, Y.; Ooga, J.; Han, H.; Sugahara, A.; Tokura, S.; Eto, H.; Komoda, K.; Ogawa, A. Learning suction graspability considering grasp quality and robot reachability for bin-picking. Front. Neurorobot. 2021, 16, 806898. [Google Scholar] [CrossRef]
- Kozák, V.; Sushkov, R.; Kulich, M.; Přeučil, L. Data-Driven Object Pose Estimation in a Practical Bin-Picking Application. Sensors 2021, 21, 6093. [Google Scholar] [CrossRef]
- Carvalho de Souza, J.P.; Costa, C.M.; Rocha, L.F.; Arrais, R.; Moreira, A.P.; Pires, E.S.; Boaventura-Cunha, J. Reconfigurable Grasp Planning Pipeline with Grasp Synthesis and Selection Applied to Picking Operations in Aerospace Factories. Robot. Comput.-Integr. Manuf. 2021, 67, 102032. [Google Scholar] [CrossRef]
- Cordeiro, A.; Rocha, L.F.; Costa, C.; Silva, M.F. Object Segmentation for Bin Picking Using Deep Learning. In Proceedings of the ROBOT2022: Fifth Iberian Robotics Conference; Tardioli, D., Matellán, V., Heredia, G., Silva, M.F., Marques, L., Eds.; Springer International Publishing: Cham, Switzerland, 2023; pp. 53–66. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask Scoring R-CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Cordeiro, A.; Rocha, L.F.; Costa, C.; Costa, P.; Silva, M.F. Bin Picking Approaches Based on Deep Learning Techniques: A State-of-the-Art Survey. In Proceedings of the 2022 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Santa Maria da Feira, Portugal, 29–30 April 2022; pp. 110–117. [Google Scholar] [CrossRef]
- Sunwoo, H.; Choi, W.; Na, S.; Kim, C.; Heo, S. Comparison of the Performance of Artificial Intelligence Models Depending on the Labelled Image by Different User Levels. Appl. Sci. 2022, 12, 3136. [Google Scholar] [CrossRef]
- Abdulla, W. Mask R-CNN for object detection and instance segmentation on Keras and TensorFlow. 2017. Available online: https://github.com/matterport/Mask_RCNN (accessed on 10 October 2022).
- Ciaparrone, G.; Bardozzo, F.; Priscoli, M.D.; Londoño Kallewaard, J.; Zuluaga, M.R.; Tagliaferri, R. A comparative analysis of multi-backbone Mask R-CNN for surgical tools detection. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Community, B.O. Blender—A 3D Modelling and Rendering Package; Blender Foundation, Stichting Blender Foundation: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Bradski, G. The OpenCV Library. Dr. Dobb’s J. Softw. Tools 2000, 11, 120–123. [Google Scholar]
- Dutta, A.; Gupta, A.; Zissermann, A. VGG Image Annotator (VIA). Version: 2. 2016. Available online: http://www.robots.ox.ac.uk/~vgg/software/via/ (accessed on 19 September 2022).
- Brooks, J. COCO Annotator. 2019. Available online: https://github.com/jsbroks/coco-annotator/ (accessed on 13 October 2022).
- Kelly, A. Create Coco Annotations From Scratch. 2020. Available online: https://www.immersivelimit.com/tutorials/create-coco-annotations-from-scratch (accessed on 13 October 2022).
- Costa, C.M.; Sobreira, H.M.; Sousa, A.J.; Veiga, G.M. Robust 3/6 DoF self-localization system with selective map update for mobile robot platforms. Robot. Auton. Syst. 2016, 76, 113–140. [Google Scholar] [CrossRef]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: tensorflow.org (accessed on 11 October 2022).
- de Souza, J.P.C.; Rocha, L.F.; Oliveira, P.M.; Moreira, A.P.; Boaventura-Cunha, J. Robotic grasping: From wrench space heuristics to deep learning policies. Robot. Comput.-Integr. Manuf. 2021, 71, 102176. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| Pixel mean | 80.2 |
| Maximum image dimension | 512 |
| Maximum GT instances | 45 |
| Number of classes | 2 |
| Scales of rpn anchors | (64, 128, 256, 512,1024) |
| Learning rate | 0.001 |
| Mask R-CNN mask loss | 2.0 |
| Gradient norm clipping | 10.0 |
| Backbone | Resnet-101 |
| Batch size | 2 |
| Mask shape | [56, 56] |
| ID | Categories | Sub-Categories | Sub-Sub-Categories | Value (Examples) |
|---|---|---|---|---|
| image id | filename | “image_name.jpg” | ||
| size on the disk | 114,651 | |||
| regions | shape attributes | name | “polygon” | |
| array of “x” points | [112, 114, 117,…] | |||
| array of “y” points | [559, 551, 532,…] | |||
| region attributes | label | “label”:“model” | ||
| file attributes | “width”:1980, “height”:1080 |
| Dataset | Nr of Images | Data Acquisition Total Time (h:m) | Nr of Annotations | Time per Annotation (s) | Labeling Total Time (h:m) |
|---|---|---|---|---|---|
| Real (Model A) | 488 | 07:10 | 737 | 38 | 07:46 |
| Real (Model B) | 59 | 00:55 | 155 | 16 | 00:41 |
| Simulation (Model A) | 1600 | 02:36 | 10,593 | 3 | 08:32 |
| Simulation (Model B) | 1600 | 02:21 | 10,106 | 3 | 08:05 |
| Dataset Model | AP | AP | AP | mAP | mAR | mIOU | mF1 |
|---|---|---|---|---|---|---|---|
| 90 flow pipe | 0.976 | 0.968 | 0.897 | 0.872 | 0.976 | 0.916 | 0.943 |
| Triangular wall support | 0.980 | 0.955 | 0.902 | 0.914 | 0.980 | 0.937 | 0.849 |
| Dataset Model | AP | AP | AP | mAP | mAR | mIOU | mF1 |
|---|---|---|---|---|---|---|---|
| 90 flow pipe | 0.967 | 0.962 | 0.579 | 0.819 | 0.976 | 0.736 | 0.875 |
| Triangular wall support | 0.919 | 0.842 | 0.721 | 0.802 | 0.948 | 0.894 | 0.793 |
| Dataset Model | Pre-Process (Offline) [s] | Loading (Offline) [s] | 2D Segmentation (Online) [s] | 3D Segmentation (Online) [s] | Overall Object Segmentation [s] | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Mean | Std dev | Mean | Std dev | Mean | Std dev | Mean | Std dev | Mean | ||
| Knee tube | 8.5 | 0.6 | 0.25 | 0.2 | 0.33 | 0.4 | 0.11 | 0.04 | 0.47 | |
| Triangular wall support | 8.5 | 0.6 | 0.24 | 0.2 | 0.28 | 0.3 | 0.09 | 0.02 | 0.38 | |
| Parameters | 1 Object | 2 Objects | 3 Objects | 4 Objects | 5 Objects | 6 Objects |
|---|---|---|---|---|---|---|
| Iterations | 20 | 20 | 20 | 20 | 20 | 20 |
| GPSR | 95% | 85% | 80% | 95% | 85% | 85% |
| GRSR | 100% | 100% | 100% | 100% | 100% | 100% |
| GHSR | 100% | 100% | 100% | 95% | 100% | 100% |
| HGSR | 100% | 100% | 100% | 100% | 100% | 100% |
| Parameters | 90 Flow Pipe Model | Triangle Wall Support Model |
|---|---|---|
| Object quantity | 5 | 5 |
| GPSR | 100% | 80% |
| GRST | 100% | 100% |
| GHSR | 100% | 100% |
| HGSR | 100% | 100% |
| Parameters | 90 Flow Pipe Model | Triangle Wall Support Model |
|---|---|---|
| Object quantity | 6 | 6 |
| GPSR | 100% | 83.3% |
| GRST | 100% | 100% |
| GHSR | 100% | 100% |
| HGSR | 100% | 100% |
| Parameters | 90 Flow Pipe Model | Triangle Wall Support Model |
|---|---|---|
| Iterations | 71 | 71 |
| Segmentation success | 100% | 99.98% |
| Selection success | 99.98% | 95.71% |
| Matching success | 100% | 82.00% |
| Pose estimation success | 100% | 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cordeiro, A.; Souza, J.P.; Costa, C.M.; Filipe, V.; Rocha, L.F.; Silva, M.F. Bin Picking for Ship-Building Logistics Using Perception and Grasping Systems. Robotics 2023, 12, 15. https://doi.org/10.3390/robotics12010015
Cordeiro A, Souza JP, Costa CM, Filipe V, Rocha LF, Silva MF. Bin Picking for Ship-Building Logistics Using Perception and Grasping Systems. Robotics. 2023; 12(1):15. https://doi.org/10.3390/robotics12010015
Chicago/Turabian StyleCordeiro, Artur, João Pedro Souza, Carlos M. Costa, Vítor Filipe, Luís F. Rocha, and Manuel F. Silva. 2023. "Bin Picking for Ship-Building Logistics Using Perception and Grasping Systems" Robotics 12, no. 1: 15. https://doi.org/10.3390/robotics12010015
APA StyleCordeiro, A., Souza, J. P., Costa, C. M., Filipe, V., Rocha, L. F., & Silva, M. F. (2023). Bin Picking for Ship-Building Logistics Using Perception and Grasping Systems. Robotics, 12(1), 15. https://doi.org/10.3390/robotics12010015