
A Robot Architecture Using ContextSLAM to Find Products in Unknown Crowded Retail Environments


Abstract
:1. Introduction
2. Related Work
2.1. Retail Robots
2.1.1. Inventory Management
2.1.2. Customer Service
2.2. Mapping and Localization Using Contextual Information
2.2.1. Localization
2.2.2. Map Annotation
2.2.3. SLAM Using Text Features
2.2.4. Semantic SLAM
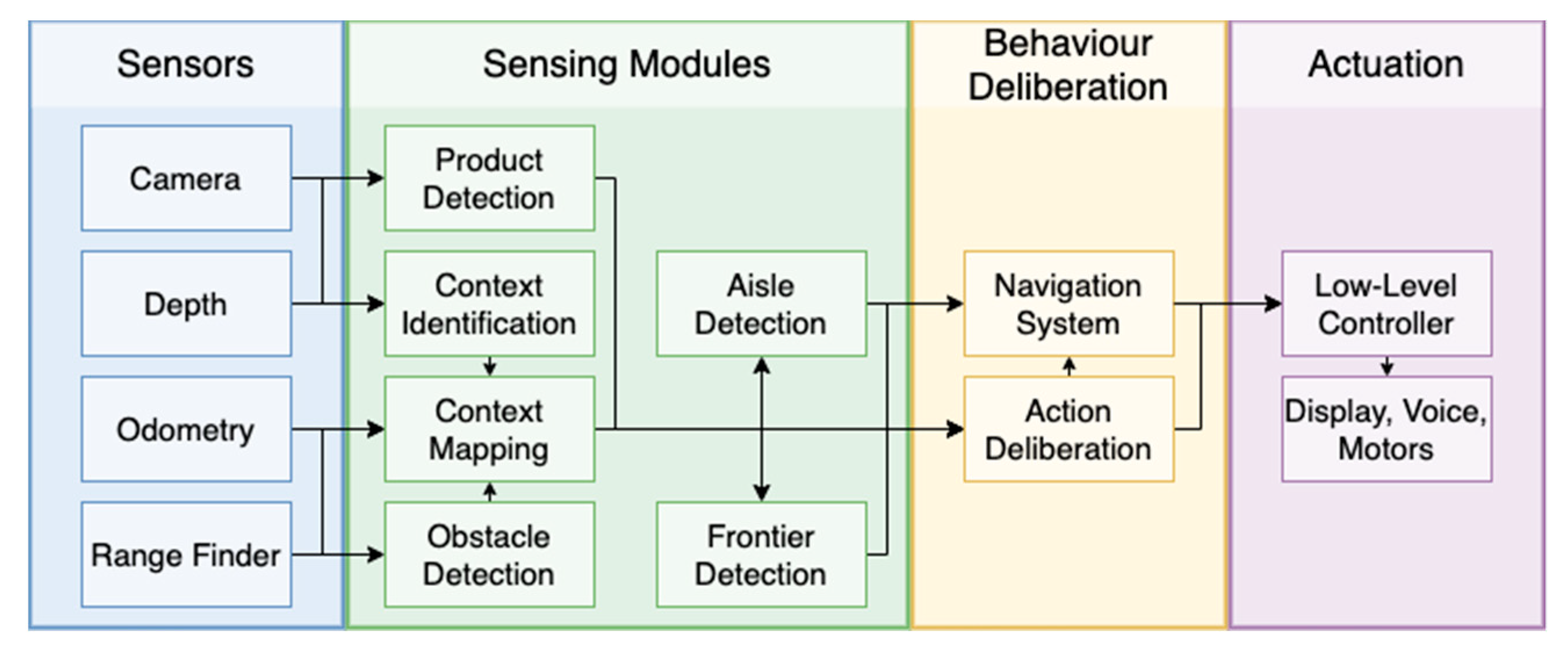
3. Grocery Robot System Architecture
3.1. Architecture Overview
3.2. Context Identification
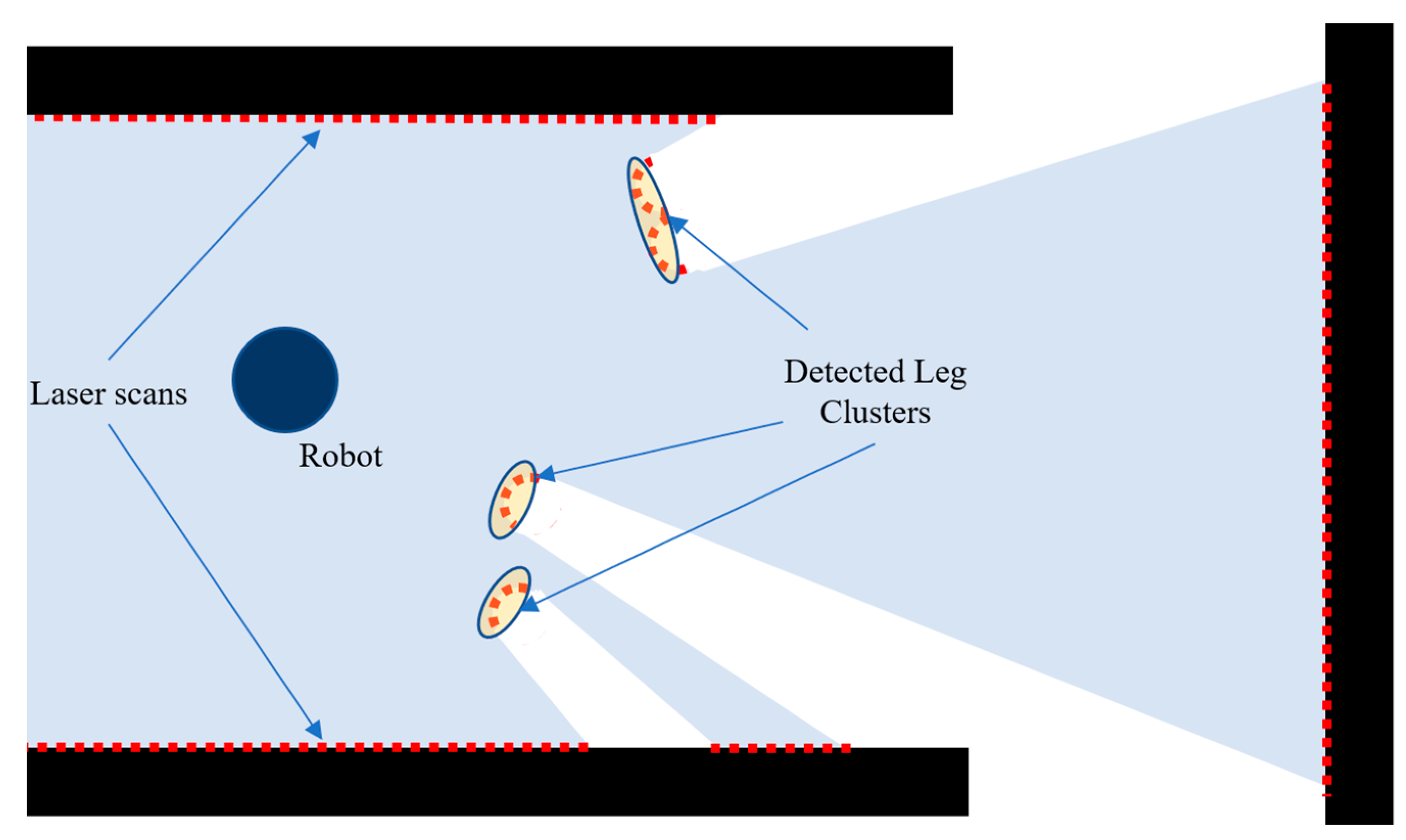
3.3. Obstacle Detection
3.4. Context Mapping
| Algorithm 1: contextSLAM: RBPF method extension to include context. |
| Require: the sample set of the previous time step; the current laser scan from Obstacle Detection; the current context observation from Context Identification; and the current odometry observation. Ensure: #The new sample set for do () #Expand context map into grid and context EKFs. #Motion model #Max probability state of . If then #Next particle weights. Else for do #Sample around the node end for #Compute Gaussian proposal for all do end for for all do end for #Sample new pose #Update particle weights end if #Update occupancy grid #Update maps with context #Update sample set end for If then |
| end if |
3.5. Aisle Detection
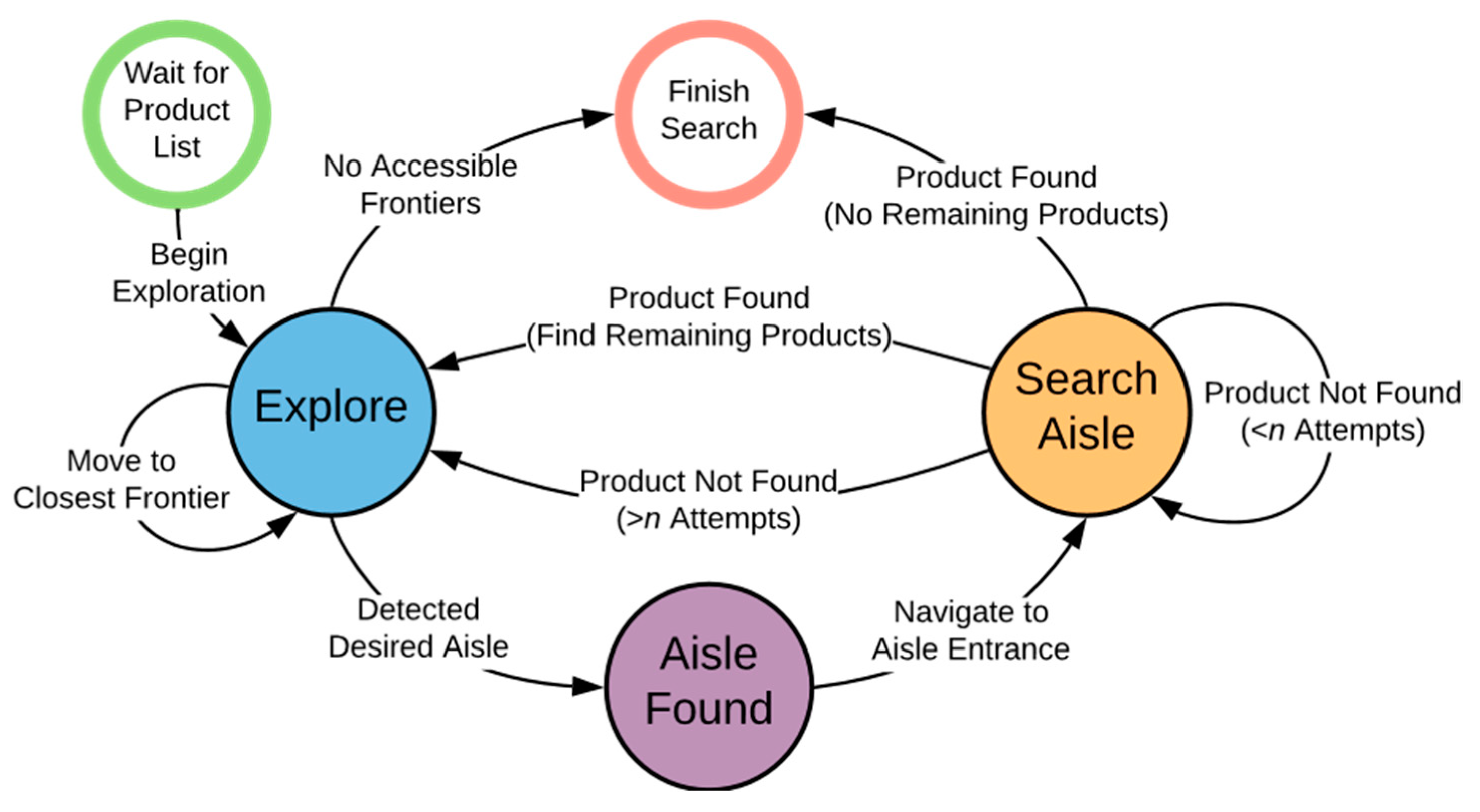
3.6. Action Deliberation
3.6.1. Explore
3.6.2. Aisle Found
3.6.3. Search Aisle
3.6.4. Finish Search
4. Blueberry Robot Implementation
5. Experiments
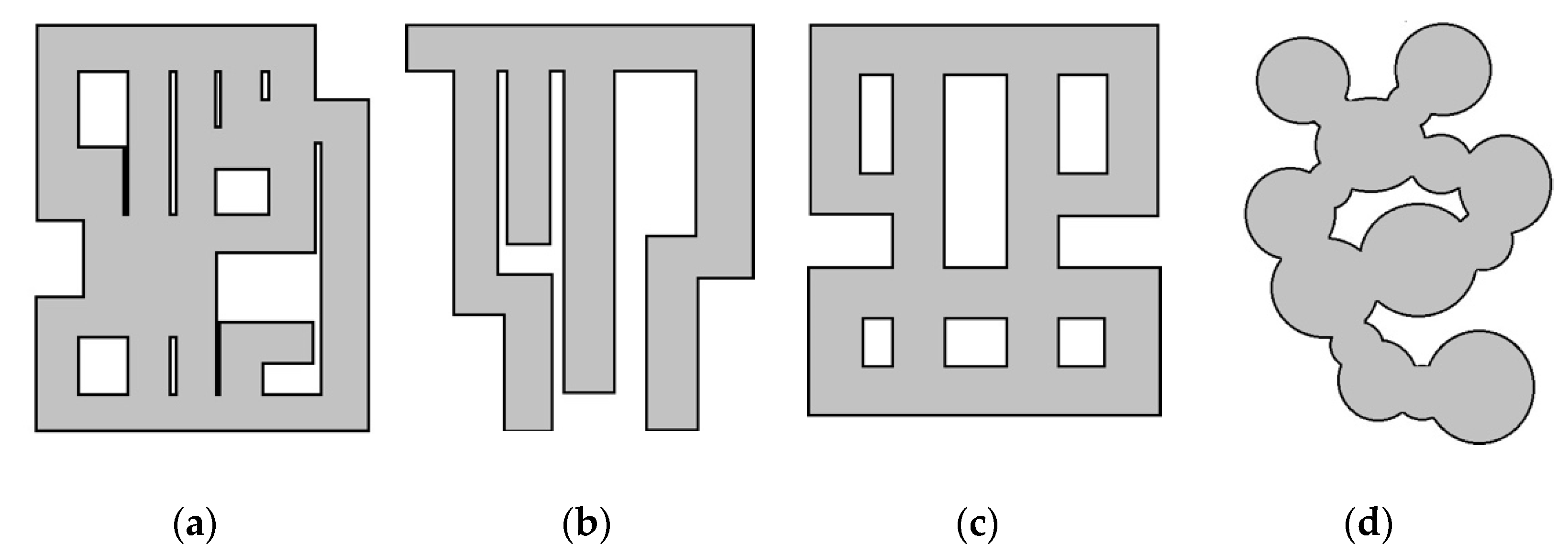
5.1. Map Performance
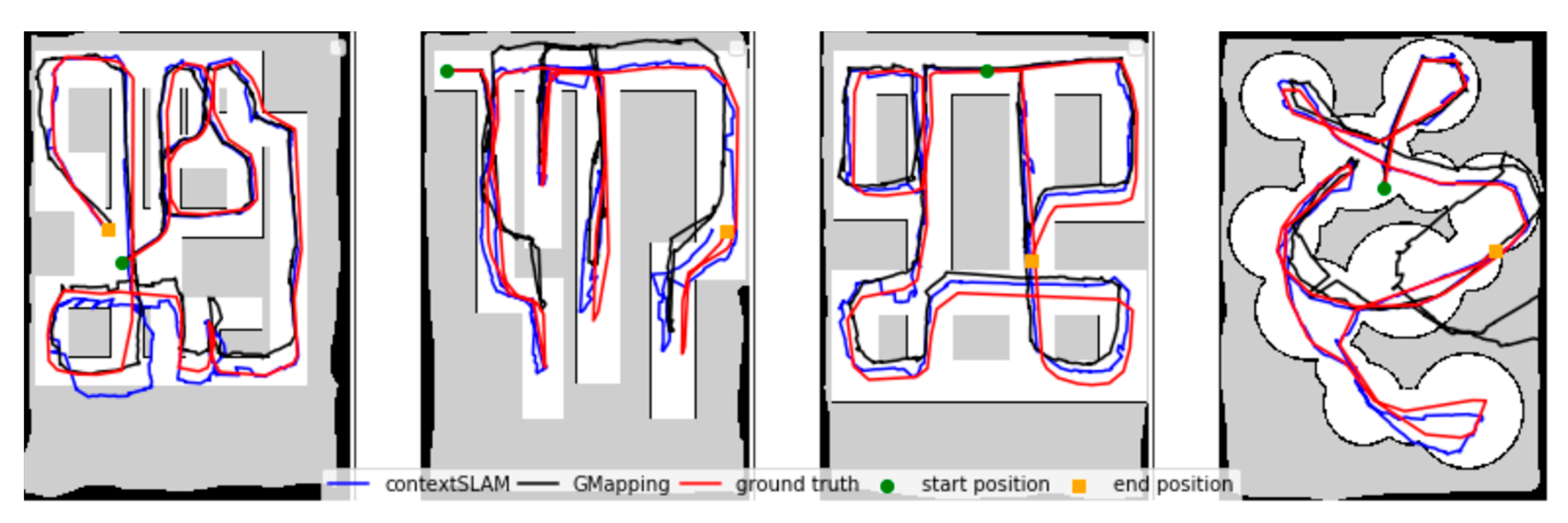
5.1.1. Trajectory Prediction Results
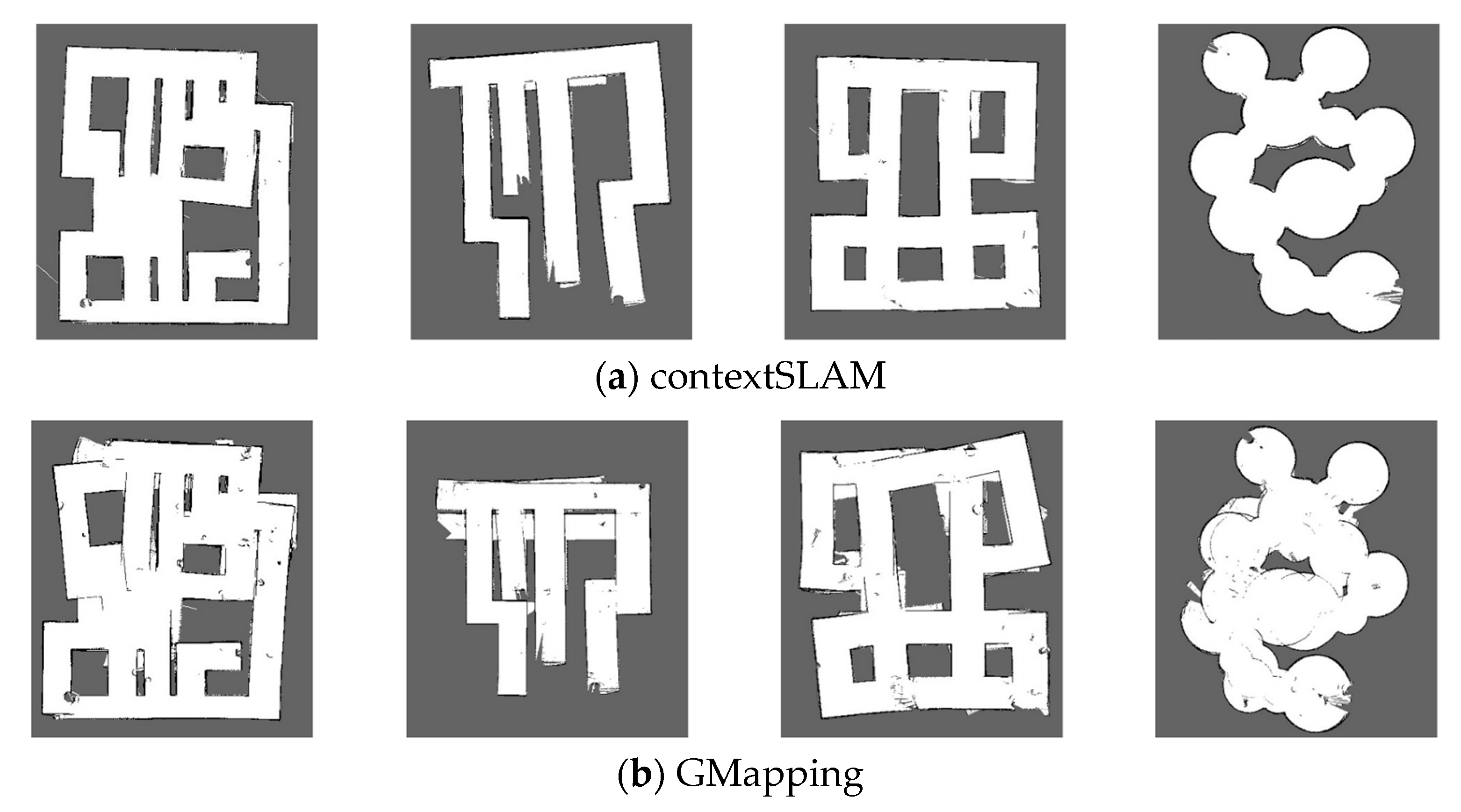
5.1.2. Map Generation Results
5.2. Using the Grocery Robot Architecture to Find Products
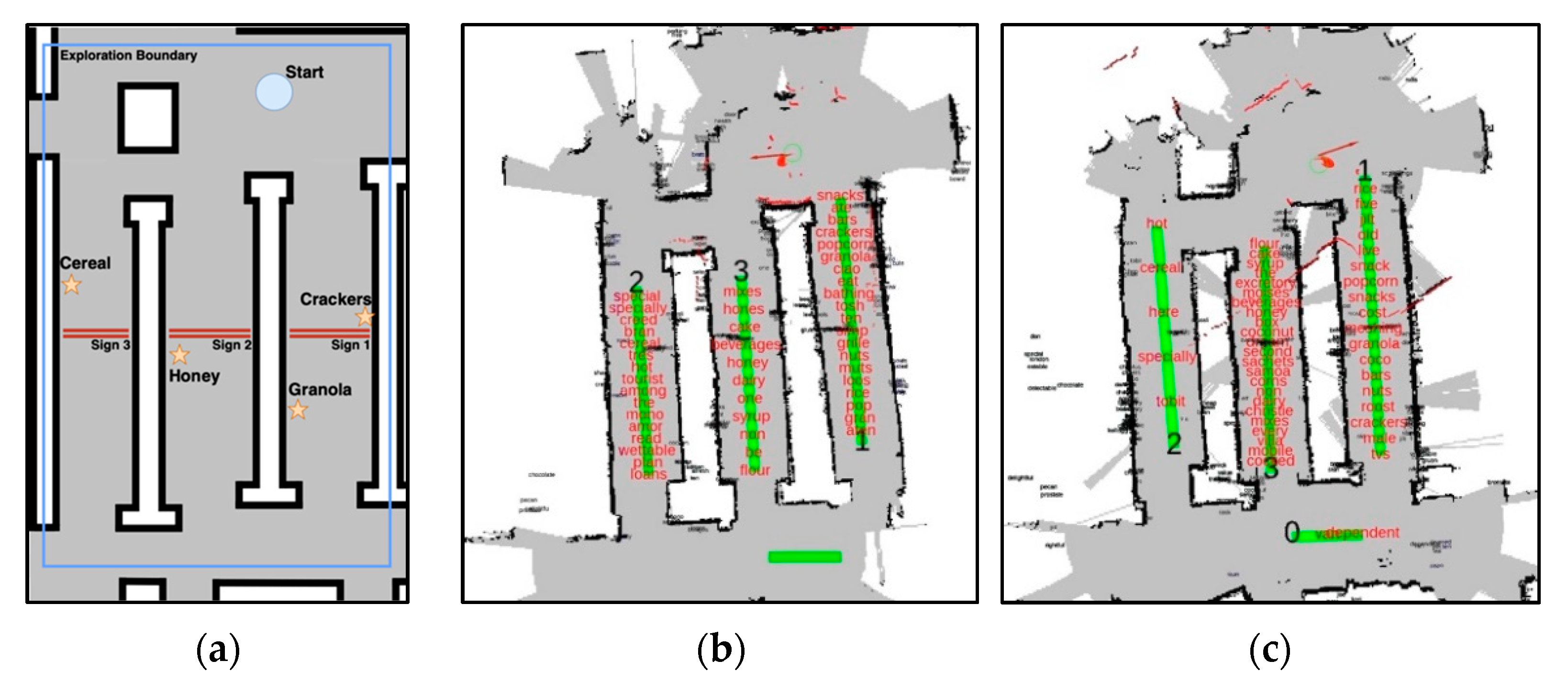
5.2.1. Store-Like Environment
Store-Like Environment Results and Discussions
5.2.2. Grocery Store Environment
Grocery Store Environment Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sommer, R.; Aitkens, S. Mental Mapping of Two Supermarkets. J. Consum. Res. 1982, 9, 211–215. [Google Scholar] [CrossRef]
- Binder, T. Walgreens’ Beverage Category Reset Leverages VR. Path Purch. IQ 2018. Available online: https://www.pathtopurchaseiq.com/walgreens-beverage-category-reset-leverages-vr (accessed on 29 September 2020).
- Why Does Costco Have a Treasure Hunt Atmosphere? Costco 2020. Available online: https://www.customerservice.costco.com/app/answers/detail/a_id/716/why-does-costco-have-a-treasure-hunt-atmosphere (accessed on 29 September 2020).
- USDA ERS-New Products. Available online: ers.usda.gov/topics/food-markets-prices/processing-marketing/new-products/ (accessed on 6 July 2020).
- Creighton, S.A.; Iii, J.H.B.; Froeb, L.; Kovacic, W.E.; Davis, A.H.; Straight, R.A. Slotting Allowances in the Retail Grocery Industry: Selected Case Studies in Five Product Categories; Federal Trade Commission: Washington, DC, USA, 2003. Available online: https://www.ftc.gov/sites/default/files/documents/reports/use-slotting-allowances-retail-grocery-industry/slottingallowancerpt031114.pdf (accessed on 19 September 2021).
- Aylott, R.; Mitchell, V.-W. An Exploratory Study of Grocery Shopping Stressors. Int. J. Retail Distrib. Manag. 1998, 26, 362–373. [Google Scholar] [CrossRef]
- Park, C.W.; Iyer, E.S.; Smith, D.C. The Effects of Situational Factors on In-Store Grocery Shopping Behavior: The Role of Store Environment and Time Available for Shopping. J. Consum. Res. 1989, 15, 422–433. [Google Scholar] [CrossRef]
- Nilsson, E.; Gärling, T.; Marell, A. Effects of Time Pressure, Type of Shopping, and Store Attributes on Consumers’ Satisfaction with Grocery Shopping. Int. Rev. Retail Distrib. Consum. Res. 2017, 27, 334–351. [Google Scholar] [CrossRef]
- Getting Availability Right. Oliver Wyman. 2012. Available online: https://www.oliverwyman.com/our-expertise/insights/2012/oct/getting-availability-right.html (accessed on 20 September 2020).
- Fisher, M.; Krishnan, J.; Netessine, S. Retail Store Execution: An Empirical Study; Social Science Research Network: Rochester, NY, USA, 2006. [Google Scholar]
- Redman, R. Supermarkets slip in customer satisfaction. Supermark. News 2019. Available online: https://www.supermarketnews.com/consumer-trends/supermarkets-slip-customer-satisfaction (accessed on 20 September 2020).
- Tonioni, A. Computer Vision and Deep Learning for Retail Store Management. Ph.D. Thesis, University Bologna, Bologna, Italy, 2019. [Google Scholar]
- Wiles, S.; Kumar, N.; Roy, B.; Rathore, U. Planogram Compliance: Making It Work. Cognizant 2013, 1–7. Available online: https://cupdf.com/document/planogram-compliance-making-it-work.html (accessed on 19 September 2021).
- Cameron, J.; Berg, M.; Derr, J.; Duncan, G.; Hyde, E.; Menin, B.; Stumpf, L.; Titzel, M.; Wright, F. PCoA State of Older Adults During COVID-19 Report. In Pennsylvania Council on Aging Report; 2020. Available online: aging.pa.gov/organization/pa-council-on-aging/Documents/State%20of%20Older%20Adults%20During%20COVID/PCoA%20State%20of%20Older%20Adults%20During%20COVID-19%20Report.pdf (accessed on 19 September 2021).
- Mohamed, S.C.; Rajaratnam, S.; Hong, S.T.; Nejat, G. Person Finding: An Autonomous Robot Search Method for Finding Multiple Dynamic Users in Human-Centered Environments. IEEE Trans. Autom. Sci. Eng. 2020, 17, 433–449. [Google Scholar] [CrossRef]
- Mišeikis, J.; Caroni, P.; Duchamp, P.; Gasser, A.; Marko, R.; Mišeikienė, N.; Zwilling, F.; de Castelbajac, C.; Eicher, L.; Früh, M.; et al. Lio-A Personal Robot Assistant for Human-Robot Interaction and Care Applications. IEEE Robot. Autom. Lett. 2020, 5, 5339–5346. [Google Scholar] [CrossRef]
- Kornatowski, P.M.; Bhaskaran, A.; Heitz, G.M.; Mintchev, S.; Floreano, D. Last-Centimeter Personal Drone Delivery: Field Deployment and User Interaction. IEEE Robot. Autom. Lett. 2018, 3, 3813–3820. [Google Scholar] [CrossRef]
- Scherer, J.; Rinner, B. Multi-UAV Surveillance With Minimum Information Idleness and Latency Constraints. IEEE Robot. Autom. Lett. 2020, 5, 4812–4819. [Google Scholar] [CrossRef]
- Buchanan, R. Employee Turnover in a Grocery. Chron 2010. Available online: Smallbusiness.chron.com/employee-turnover-grocery-15810.html (accessed on 20 September 2020).
- Matsuhira, N.; Ozaki, F.; Tokura, S.; Sonoura, T.; Tasaki, T.; Ogawa, H.; Sano, M.; Numata, A.; Hashimoto, N.; Komoriya, K. Development of Robotic Transportation System-Shopping Support System Collaborating with Environmental Cameras and Mobile Robots. In Proceedings of the ISR 2010 (41st International Symposium on Robotics) and ROBOTIK 2010 (6th German Conference on Robotics), Munich, Germany, 7–9 June 2010; IEEE: New York, NY, USA, 2010; pp. 893–898. [Google Scholar]
- Gross, H.-M.; Boehme, H.; Schroeter, C.; Mueller, S.; Koenig, A.; Einhorn, E.; Martin, C.; Merten, M.; Bley, A. TOOMAS: Interactive Shopping Guide Robots in Everyday Use—Final Implementation and Experiences from Long-Term Field Trials. In Proceedings of the 2009 IEEE/RSJ International Conference on Intelligent Robots and Systems, St. Louis, MO, USA, 10–15 October 2009; IEEE: New York, NY, USA, 2009; pp. 2005–2012. [Google Scholar]
- Cleveland, J.; Thakur, D.; Dames, P.; Phillips, C.; Kientz, T.; Daniilidis, K.; Bergstrom, J.; Kumar, V. Automated System for Semantic Object Labeling With Soft-Object Recognition and Dynamic Programming Segmentation. IEEE Trans. Autom. Sci. Eng. 2017, 14, 820–833. [Google Scholar] [CrossRef]
- Coppola, D. U.S.: Number Supermarket/Grocery Stores 2018. Statista. Available online: https://www.statista.com/statistics/240892/number-of-us-supermarket-stores-by-format/ (accessed on 19 September 2020).
- Durrant-Whyte, H.; Bailey, T. Simultaneous Localization and Mapping: Part I. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef] [Green Version]
- Bailey, T.; Durrant-Whyte, H. Simultaneous Localization and Mapping (SLAM): Part II. IEEE Robot. Autom. Mag. 2006, 13, 108–117. [Google Scholar] [CrossRef] [Green Version]
- Naudet-Collette, S.; Melbouci, K.; Gay-Bellile, V.; Ait-Aider, O.; Dhome, M. Constrained RGBD-SLAM. Robotica 2021, 39, 277–290. [Google Scholar] [CrossRef]
- Havangi, R. Robust Square-Root Cubature FastSLAM with Genetic Operators. Robotica 2021, 39, 665–685. [Google Scholar] [CrossRef]
- Taheri, H.; Xia, Z.C. SLAM; Definition and Evolution. Eng. Appl. Artif. Intell. 2021, 97, 104032. [Google Scholar] [CrossRef]
- Neto, O.D.A.R.; Lima Filho, A.C.; Nascimento, T.P. A Distributed Approach for the Implementation of Geometric Reconstruction-Based Visual SLAM Systems. Robotica 2021, 39, 749–771. [Google Scholar] [CrossRef]
- Liu, D. A Data Association Algorithm for SLAM Based on Central Difference Joint Compatibility Criterion and Clustering. Robotica 2021, 1–18. [Google Scholar] [CrossRef]
- Azzam, R.; Taha, T.; Huang, S.; Zweiri, Y. Feature-Based Visual Simultaneous Localization and Mapping: A Survey. SN Appl. Sci. 2020. [Google Scholar] [CrossRef] [Green Version]
- Kowalewski, S.; Maurin, A.L.; Andersen, J.C. Semantic Mapping and Object Detection for Indoor Mobile Robots. IOP Conf. Ser. Mater. Sci. Eng. 2019, 517, 012012. [Google Scholar] [CrossRef]
- Francis, J.; Drolia, U.; Mankodiya, K.; Martins, R.; Gandhi, R.; Narasimhan, P. MetaBot: Automated and Dynamically Schedulable Robotic Behaviors in Retail Environments. In Proceedings of the 2013 IEEE International Symposium on Robotic and Sensors Environments (ROSE), Washington, DC, USA, 21–23 October 2013; IEEE: New York, NY, USA, 2013; pp. 148–153. [Google Scholar]
- Thompson, C.; Khan, H.; Dworakowski, D.; Harrigan, K.; Nejat, G. An Autonomous Shopping Assistance Robot for Grocery Stores. In Proceedings of the Workshop on Robotic Co-workers 4.0: Human Safety and Comfort in Human-Robot Interactive Social Environments 2018 IEEE/RSJ, Madrid, Spain, 1–5 October 2018. [Google Scholar]
- Schroeter, C.; Gross, H.-M. A Sensor Independent Approach to RBPF SLAM Map Match SLAM Applied to Visual Mapping. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; IEEE: New York, NY, USA, 2008; pp. 2078–2083. [Google Scholar]
- Houben, S.; Droeschel, D.; Behnke, S. Joint 3D Laser and Visual Fiducial Marker Based SLAM for a Micro Aerial Vehicle. In Proceedings of the 2016 IEEE International Conference on Multisensor Fusion and Integration for Intelligent Systems (MFI), Baden, Germany, 19–21 September 2016; IEEE: New York, NY, USA, 2016; pp. 609–614. [Google Scholar]
- Wurm, K.M.; Stachniss, C.; Grisetti, G. Bridging the Gap between Feature and Grid Based SLAM. Robot. Auton. Syst. 2010, 58, 140–148. [Google Scholar] [CrossRef] [Green Version]
- Junior, R.P.; Petry, M.R. Robot Localization Through Optical Character Recognition of Signs. In Proceedings of the 2019 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Porto, Portugal, 24–26 April 2019; IEEE: New York, NY, USA, 2019; pp. 1–6. [Google Scholar]
- Nieto, J.I.; Guivant, J.E.; Nebot, E.M. The HYbrid Metric Maps (HYMMs): A Novel Map Representation for DenseSLAM. In Proceedings of the IEEE International Conference on Robotics and Automation, New Orleans, LA, USA, 26 April–1 May 2004; IEEE: New York, NY, USA, 2014; pp. 391–396. [Google Scholar]
- Lemus, R.; Díaz, S.; Gutiérrez, C.; Rodríguez, D.; Escobar, F. SLAM-R Algorithm of Simultaneous Localization and Mapping Using RFID for Obstacle Location and Recognition. J. Appl. Res. Technol. 2014, 12, 551–559. [Google Scholar] [CrossRef] [Green Version]
- Sim, R.; Little, J.J. Autonomous Vision-Based Exploration and Mapping Using Hybrid Maps and Rao-Blackwellised Particle Filters. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006; IEEE: New York, NY, USA, 2006; pp. 2082–2089. [Google Scholar]
- Schulz, R.; Talbot, B.; Lam, O.; Dayoub, F.; Corke, P.; Upcroft, B.; Wyeth, G. Robot Navigation Using Human Cues: A Robot Navigation System for Symbolic Goal-Directed Exploration. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; IEEE: New York, NY, USA, 2015; pp. 1100–1105. [Google Scholar]
- Case, C.; Suresh, B.; Coates, A.; Ng, A.Y. Autonomous Sign Reading for Semantic Mapping. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; IEEE: New York, NY, USA, 2011; pp. 3297–3303. [Google Scholar]
- Wang, H.; Finn, C.; Paull, L.; Kaess, M.; Rosenholtz, R.; Teller, S.; Leonard, J. Bridging Text Spotting and SLAM with Junction Features. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems, Hamburg, Germany, 28 September–2 October 2015; IEEE: New York, NY, USA, 2015; pp. 3701–3708. [Google Scholar]
- Li, B.; Zou, D.; Sartori, D.; Pei, L.; Yu, W. TextSLAM: Visual SLAM with Planar Text Features. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: New York, NY, USA, 2020; pp. 2102–2108. [Google Scholar]
- Han, S.; Xi, Z. Dynamic Scene Semantics SLAM Based on Semantic Segmentation. IEEE Access 2020, 8, 43563–43570. [Google Scholar] [CrossRef]
- Bavle, H.; De La Puente, P.; How, J.P.; Campoy, P. VPS-SLAM: Visual Planar Semantic SLAM for Aerial Robotic Systems. IEEE Access 2020, 8, 60704–60718. [Google Scholar] [CrossRef]
- Chen, X.; Milioto, A.; Palazzolo, E.; Giguere, P.; Behley, J.; Stachniss, C. SuMa++: Efficient LiDAR-based Semantic SLAM. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; IEEE: New York, NY, USA, 2019; pp. 4530–4537. [Google Scholar]
- Zhao, X.; Zuo, T.; Hu, X. OFM-SLAM: A Visual Semantic SLAM for Dynamic Indoor Environments. Math. Probl. Eng. 2021, 2021, 1–16. [Google Scholar] [CrossRef]
- Biederman, I. Recognition-by-Components: A Theory of Human Image Understanding. Psychol. Rev. 1987, 94, 115–147. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; IEEE: New York, NY, USA, 2017; pp. 2980–2988. [Google Scholar]
- Xie, S.; Girshick, R.; Dollár, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: New York, NY, USA, 2017; pp. 1492–1500. [Google Scholar]
- Shi, B.; Bai, X.; Yao, C. An End-To-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hahnel, D.; Triebel, R.; Burgard, W.; Thrun, S. Map Building with Mobile Robots in Dynamic Environments. In Proceedings of the 2003 IEEE International Conference on Robotics and Automation, Taipei, Taiwan, 14–19 September 2003; IEEE: New York, NY, USA, 2013; pp. 1557–1563. [Google Scholar]
- Leigh, A.; Pineau, J.; Olmedo, N.; Zhang, H. Person Tracking and Following with 2D Laser Scanners. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation, Seattle, WA, USA, 26–30 May 2015; IEEE: New York, NY, USA, 2015; pp. 726–733. [Google Scholar]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved Techniques for Grid Mapping With Rao-Blackwellized Particle Filters. IEEE Tran. Robot. 2007, 23, 34–46. [Google Scholar] [CrossRef] [Green Version]
- Yamauchi, B. A Frontier-Based Approach for Autonomous Exploration. In Proceedings of the 1997 IEEE International Symposium on Computational Intelligence in Robotics and Automation, Monterey, CA, USA, 10–11 July 1997; IEEE: New York, NY, USA, 1997; pp. 146–151. [Google Scholar]
- Move_Base. ROS.org. Available online: Wiki.ros.org/move_base (accessed on 29 September 2020).
- Wang, J.; Olson, E. AprilTag 2: Efficient and Robust Fiducial Detection. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems, Daejeon, Korea, 9–14 October 2016; IEEE: New York, NY, USA, 2016; pp. 4193–4198. [Google Scholar]
- Tonioni, A.; Di Stefano, L. Domain Invariant Hierarchical Embedding For Grocery Products Recognition. Comput. Vis. Image Underst. 2019, 182, 81–92. [Google Scholar] [CrossRef] [Green Version]
- Winlock, T.; Christiansen, E.; Belongie, S. Toward Real-Time Grocery Detection for the Visually Impaired. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition—Workshops, San Francisco, CA, USA, 13–18 June 2010; IEEE: New York, NY, USA, 2010; pp. 49–56. [Google Scholar]
- Leo, M.; Carcagni, P.; Distante, C. A Systematic Investigation on End-to-End Deep Recognition of Grocery Products in the Wild. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; IEEE: New York, NY, USA, 2021; pp. 7234–7241. [Google Scholar]
- Square Spiral Search (SSS) Algorithm for Cooperative Robots: Mars Exploration. Int. J. Res. Stud. Comput. Sci. Eng. 2020, 7. [CrossRef]
- Mu, B.; Giamou, M.; Paull, L.; Agha-mohammadi, A.; Leonard, J.; How, J. Information-Based Active SLAM via Topological Feature Graphs. In Proceedings of the 2016 IEEE 55th Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016; IEEE: New York, NY, USA, 2016; pp. 5583–5590. [Google Scholar]
- Vaughan, R. Massively Multi-Robot Simulation in Stage. Swarm Intell. 2008, 2, 189–208. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No People—Number of Attempts to Find a Product | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Product | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| Trial | |||||||||||
| Tea | 1 | 1 | N/A | N/A | 1 | 1 | 1 | 1 | 1 | 1 | |
| Cereal | 1 | 1 | 1 | 1 | N/A | N/A | 1 | 1 | 1 | 1 | |
| Pasta | 2 | 1 | 1 | 1 | 2 | 1 | N/A | N/A | 1 | 1 | |
| Household | N/A | N/A | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| Total Time (s) | 230 | 170 | 240 | 285 | 250 | 205 | 230 | 270 | 270 | 235 | |
| With Dynamic People—Number of Attempts to Find a Product | |||||||||||
| Tea | 1 | 1 | N/A | N/A | 1 | 1 | 1 | 1 | 1 | 1 | |
| Cereal | 1 | 1 | 1 | 2 | N/A | N/A | 2 | 2 | 1 | 1 | |
| Pasta | 1 | 1 | 3 | 3 | 1 | 2 | N/A | N/A | 1 | 1 | |
| Household | N/A | N/A | 1 | 1 | 3 | 2 | 1 | 1 | 1 | 1 | |
| Total Time (s) | 225 | 200 | 835 | 519 | 390 | 346 | 282 | 320 | 360 | 303 | |
| No People | Dynamic People | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Product | 1 | 2 | 3 | 4 | 5 | 1 | 2 | 3 | 4 | 5 | |
| Trial | |||||||||||
| Crackers | 1 | N/A | 1 | 1 | 1 | 2 | N/A | 2 | 1 | 1 | |
| Cereal | 1 | 1 | N/A | 1 | 1 | 2 | 1 | N/A | 2 | 2 | |
| Granola | 1 | 2 | 1 | N/A | 1 | 1 | 2 | 2 | N/A | 1 | |
| Honey | N/A | 1 | 1 | 1 | 1 | N/A | 1 | 1 | 1 | 1 | |
| Total Time (s) | 400 | 364 | 405 | 290 | 424 | 396 | 390 | 240 | 395 | 420 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dworakowski, D.; Thompson, C.; Pham-Hung, M.; Nejat, G. A Robot Architecture Using ContextSLAM to Find Products in Unknown Crowded Retail Environments. Robotics 2021, 10, 110. https://doi.org/10.3390/robotics10040110
Dworakowski D, Thompson C, Pham-Hung M, Nejat G. A Robot Architecture Using ContextSLAM to Find Products in Unknown Crowded Retail Environments. Robotics. 2021; 10(4):110. https://doi.org/10.3390/robotics10040110
Chicago/Turabian StyleDworakowski, Daniel, Christopher Thompson, Michael Pham-Hung, and Goldie Nejat. 2021. "A Robot Architecture Using ContextSLAM to Find Products in Unknown Crowded Retail Environments" Robotics 10, no. 4: 110. https://doi.org/10.3390/robotics10040110
APA StyleDworakowski, D., Thompson, C., Pham-Hung, M., & Nejat, G. (2021). A Robot Architecture Using ContextSLAM to Find Products in Unknown Crowded Retail Environments. Robotics, 10(4), 110. https://doi.org/10.3390/robotics10040110