Immunoglobulins: 25 Years of Immunoinformatics and IMGT-ONTOLOGY

Abstract
:1. IMGT®: The Birth of Immunoinformatics
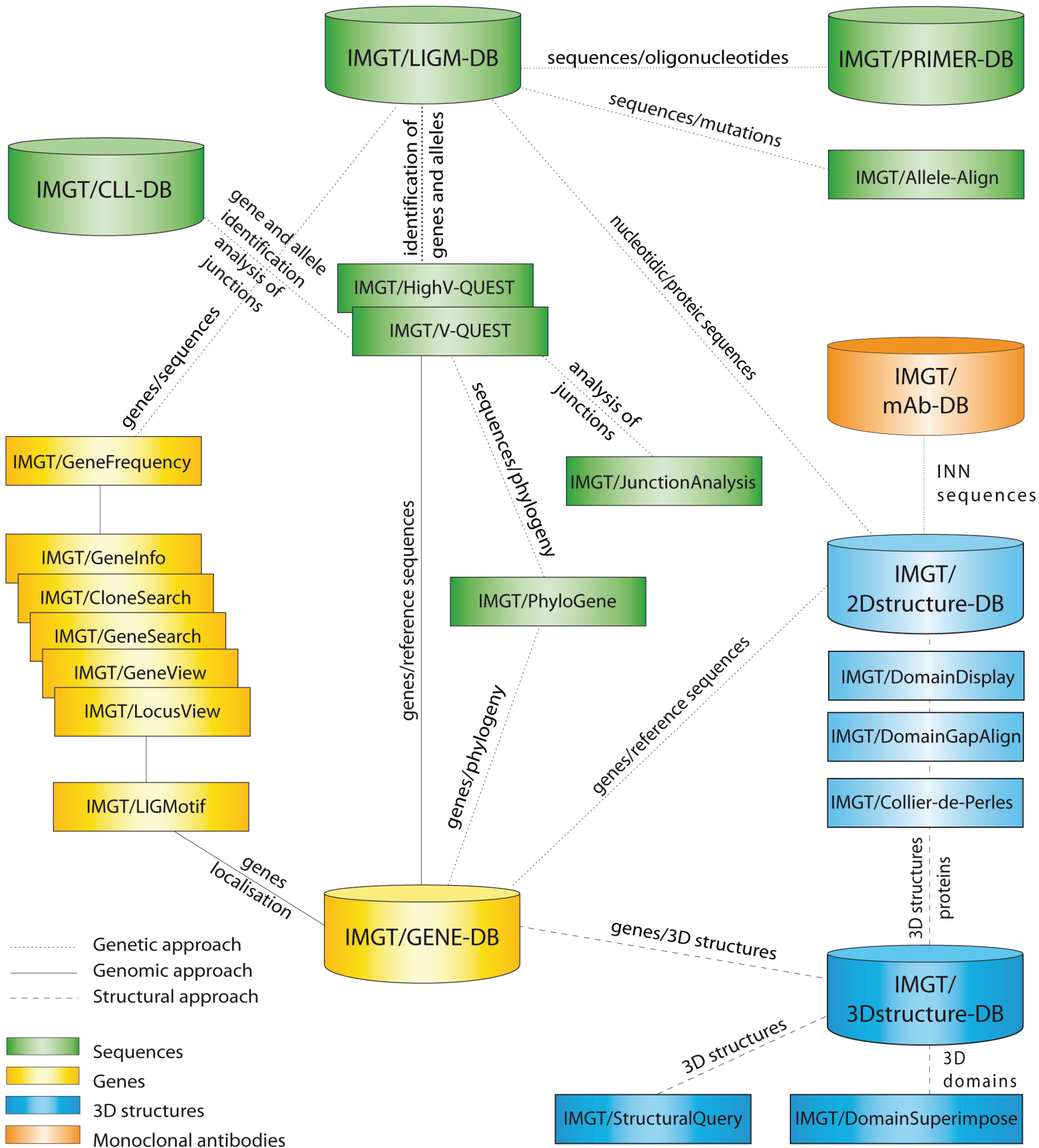
2. Fundamental Information from IMGT-ONTOLOGY Concepts
2.1. IDENTIFICATION: IMGT® Standardized Keywords
2.2. DESCRIPTION: IMGT® Standardized Labels
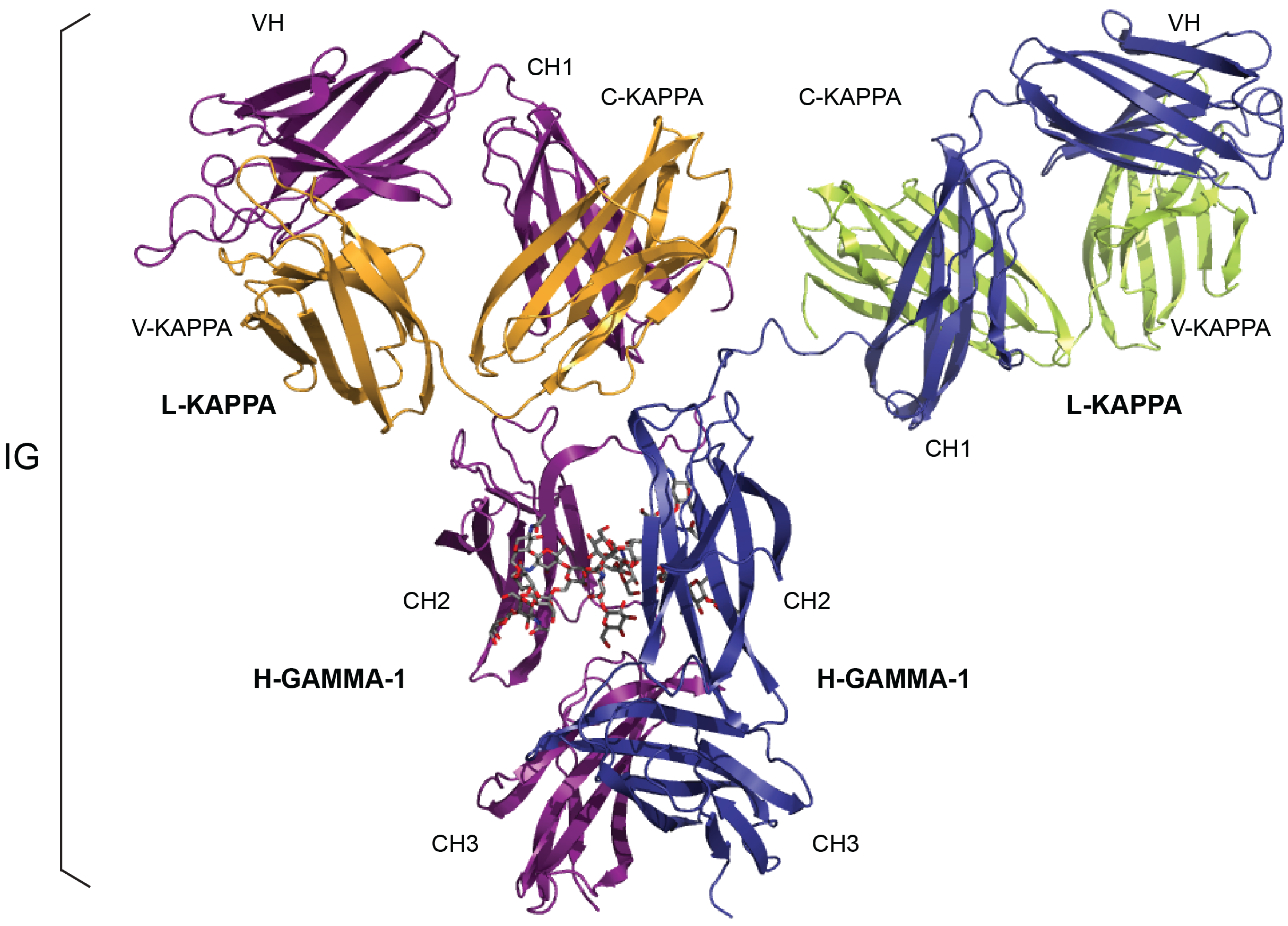

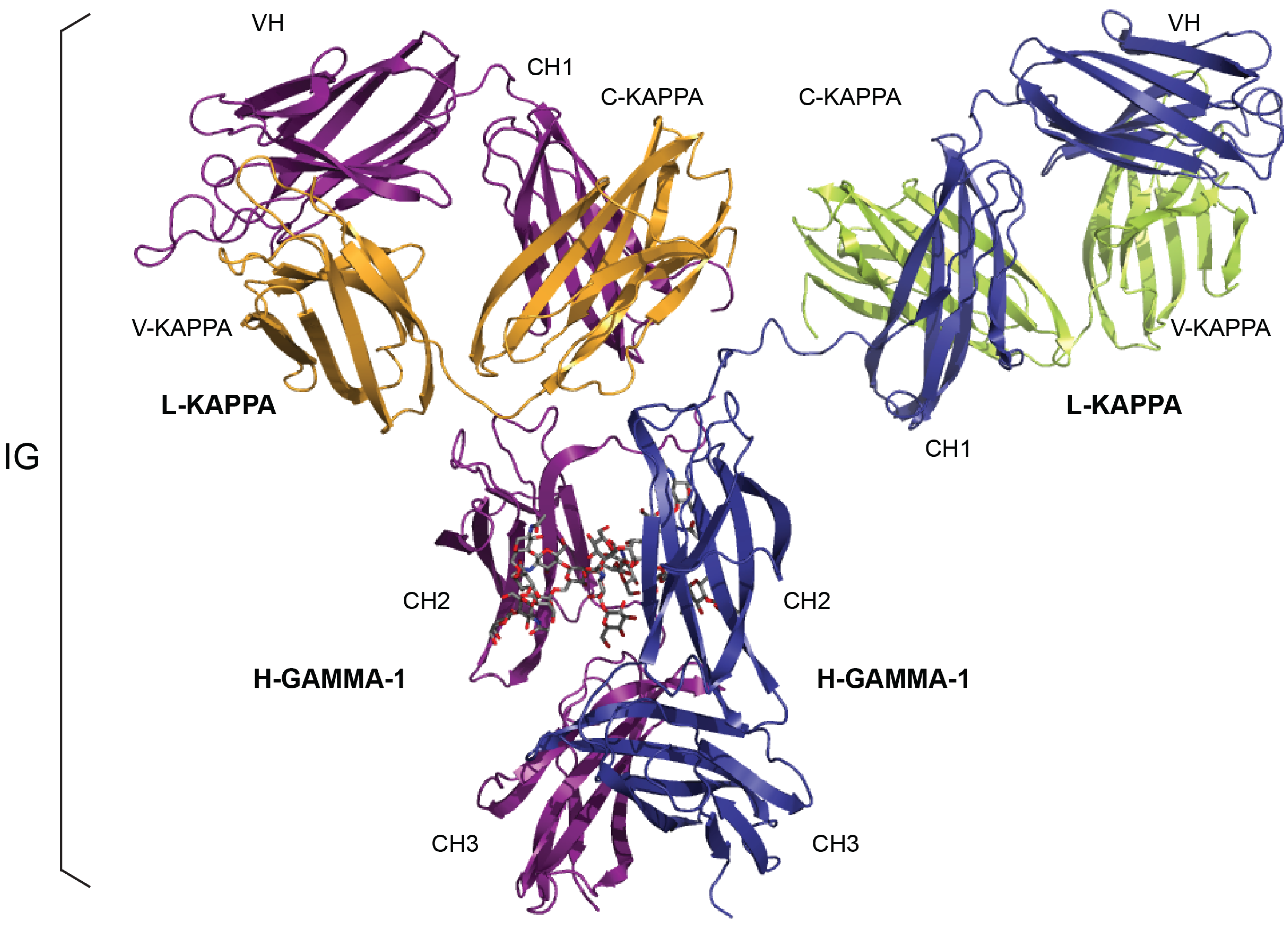
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IG Structure Labels (IMGT/3Dstructure-DB) | Sequence Labels (IMGT/LIGM-DB) | |||
|---|---|---|---|---|
| Receptor a | Chain b | Domain Description Type | Domain c | Region |
| IG-GAMMA-1_KAPPA | L-KAPPA | V-DOMAIN | V-KAPPA | V-J-REGION |
| C-DOMAIN | C-KAPPA | C-REGION | ||
| H-GAMMA-1 | V-DOMAIN | VH | V-D-J-REGION | |
| C-DOMAIN | CH1 | C-REGION d | ||
| C-DOMAIN | CH2 | |||
| C-DOMAIN | CH3 | |||
| IG-MU_LAMBDA | L-LAMBDA | V-DOMAIN | V-LAMBDA | V-J-REGION |
| C-DOMAIN | C-LAMBDA-1 | C-REGION | ||
| H-MU | V-DOMAIN | VH | V-D-J-REGION | |
| C-DOMAIN | CH1 | C-REGION d | ||
| C-DOMAIN | CH2 | |||
| C-DOMAIN | CH3 | |||
| C-DOMAIN | CH4 e | |||
2.3. CLASSIFICATION: IMGT® Standardized Genes and Alleles
2.4. NUMEROTATION: IMGT Unique Numbering and IMGT Collier de Perles
2.4.1. IG V-DOMAIN
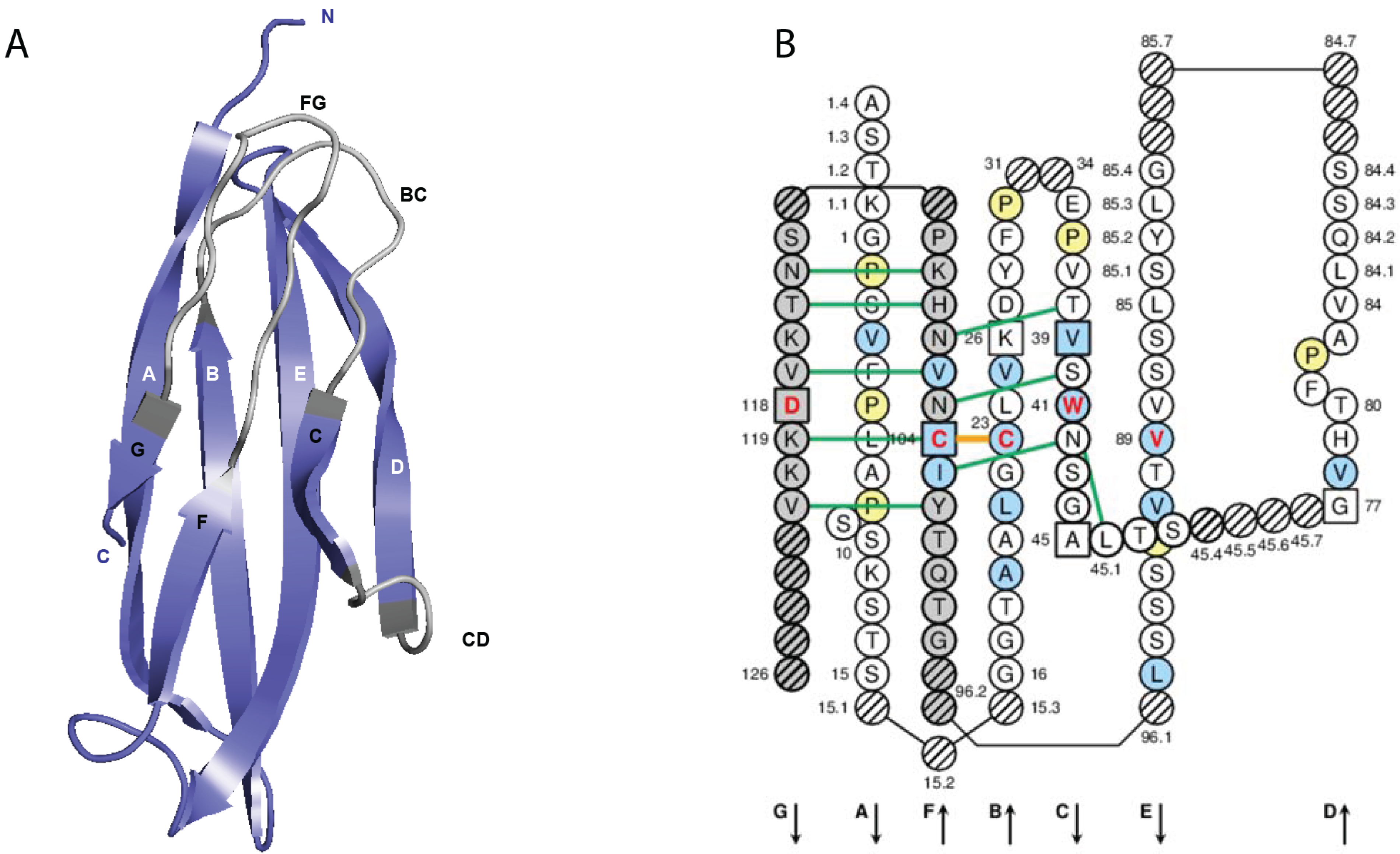
2.4.1.1. V-DOMAIN Definition and Main Characteristics
2.4.1.2. V-DOMAIN Strands and Loops (FR-IMGT and CDR-IMGT)

| V-DOMAIN Strands and Loops a | IMGT Position b | Lengths c | Characteristic IMGT Residue@ Position d | V-DOMAIN FR-IMGT and CDR-IMGT |
|---|---|---|---|---|
| A-STRAND | 1–15 | 15 (14 if gap at 10) | FR1-IMGT | |
| B-STRAND | 16–26 | 11 | 1st-CYS 23 | |
| BC-LOOP | 27–38 | 12 (or less) | CDR1-IMGT | |
| C-STRAND | 39–46 | 8 | CONSERVED-TRP 41 | FR2-IMGT |
| C’-STRAND | 47–55 | 9 | ||
| C’C”-LOOP | 56–65 | 10 (or less) | CDR2-IMGT | |
| C”-STRAND | 66–74 | 9 (or 8 if gap at 73) | FR3-IMGT | |
| D-STRAND | 75–84 | 10 (or 8 if gaps at 81, 82) | ||
| E-STRAND | 85–96 | 12 | hydrophobic 89 | |
| F-STRAND | 97–104 | 8 | 2nd-CYS 104 | |
| FG-LOOP | 105–117 | 13 (or less, or more) | CDR3-IMGT | |
| G-STRAND | 118–128 | 11 (or 10) | V-DOMAIN J-PHE 118 or J-TRP 118 e | FR4-IMGT |
| CDR3-IMGT Lengths | IMGT Additional Positions for CDR3-IMGT Length > 13 AA a | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| --- | ||||||||||
| 21 | 111 | 111.1 | 111.2 | 111.3 | 111.4 | 112.4 | 112.3 | 112.2 | 112.1 | 112 |
| 20 | 111 | 111.1 | 111.2 | 111.3 | - | 112.4 | 112.3 | 112.2 | 112.1 | 112 |
| 19 | 111 | 111.1 | 111.2 | 111.3 | - | - | 112.3 | 112.2 | 112.1 | 112 |
| 18 | 111 | 111.1 | 111.2 | - | - | - | 112.3 | 112.2 | 112.1 | 112 |
| 17 | 111 | 111.1 | 111.2 | - | - | - | - | 112.2 | 112.1 | 112 |
| 16 | 111 | 111.1 | - | - | - | - | - | 112.2 | 112.1 | 112 |
| 15 | 111 | 111.1 | - | - | - | - | - | - | 112.1 | 112 |
| 14 | 111 | - | - | - | - | - | - | - | 112.1 | 112 |
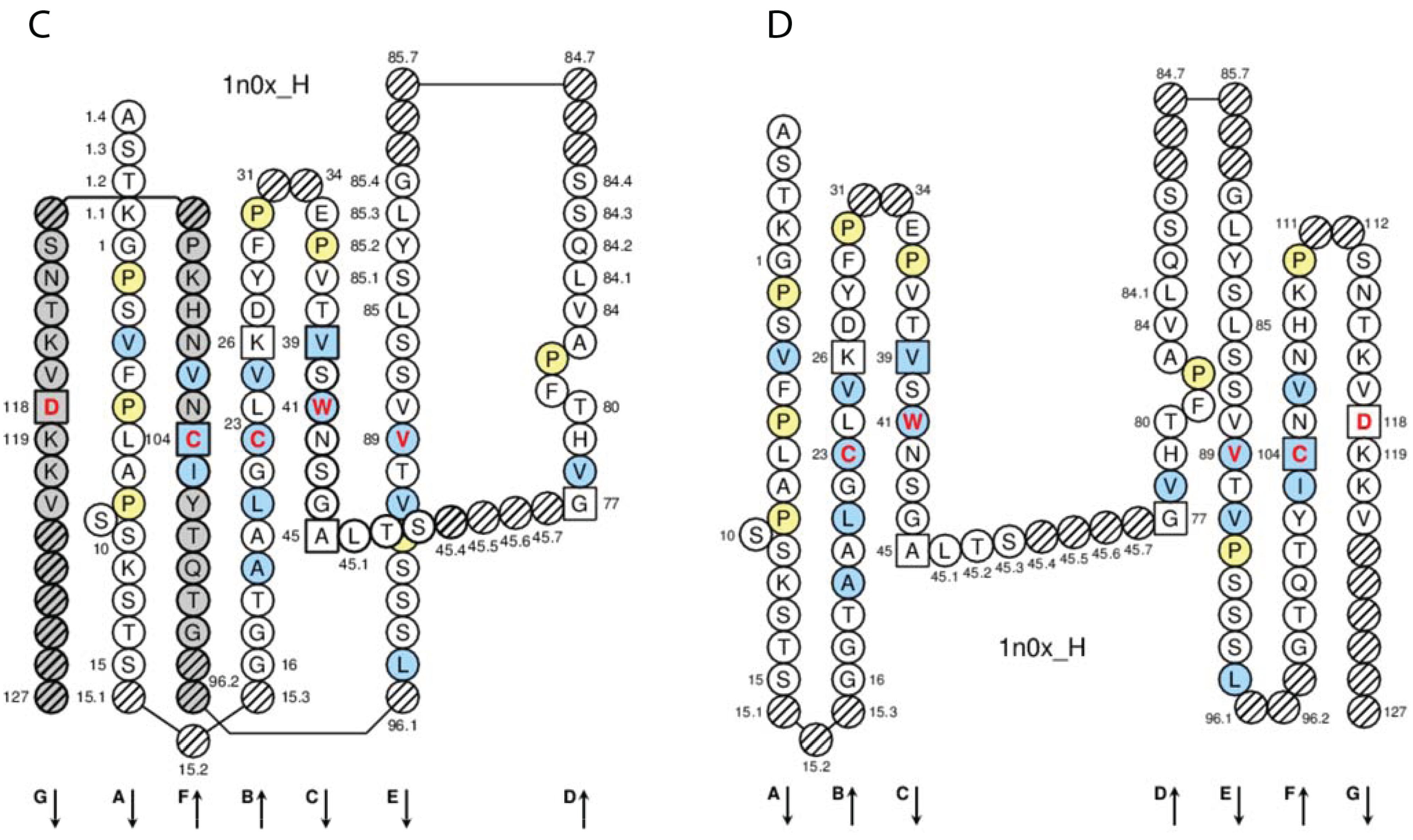
2.4.1.3. IMGT Colliers de Perles
2.4.1.4. Conserved Amino Acids
2.4.1.5. Genomic Delimitation
2.4.2. IG C-DOMAIN
2.4.2.1. C-DOMAIN Definition and Main Characteristics
2.4.2.2. C-DOMAIN Strands and Loops
2.4.2.3. IMGT Colliers de Perles
| C domain Strands, Turns and Loops a | IMGT Position b | Lengths c | Characteristic IMGT Residue@Position d |
|---|---|---|---|
| A-STRAND | 1–15 | 15 (14 if gap at 10) | |
| AB-TURN | 15.1–15.3 | 0–3 | |
| B-STRAND | 16–26 | 11 | 1st-CYS 23 |
| BC-LOOP | 27–31 | 10 (or less) | |
| C-STRAND | 39–45 | 7 | CONSERVED-TRP 41 |
| CD-STRAND | 45.1–45.9 | 0–9 | |
| D-STRAND | 77–84 | 8 (or 7 if gap at 82) | |
| DE-TURN | 84.1–84.7 | 0–14 | |
| E-STRAND | 85–96 | 12 | hydrophobic 89 |
| EF-TURN | 96.1–96.2 | 0–2 | |
| F-STRAND | 97–104 | 8 | 2nd-CYS 104 |
| FG-LOOP | 105–117 | 13 (or less, or more) | |
| G-STRAND | 118–128 | 11 (or less) |
2.4.2.4. Conserved Amino Acids
2.4.2.5. Genomic Delimitation
2.4.3. IMGT/Collier-de-Perles Tool
| IMGT® Tools | Results for IG V or C Domains (Nucleotide or Amino Acid Sequences) | Entry Types, Protocol References and Examples of Applications |
|---|---|---|
| IMGT/Collier-de-Perles [27] | Graphical 2D representation of IMGT Colliers de Perles [66,67,68,69] | User “IMGT gapped” V or C domain amino acid sequences (1 sequence per representation) [27] |
| IG V-DOMAIN nucleotide sequence and repertoire analysis | ||
| IMGT/V-QUEST [13,14,15,16,17,18] |
| |
| IMGT/HighV-QUEST [22,23,24] |
| |
| IG V-DOMAIN or C-DOMAIN amino acid sequence analysis | ||
| IMGT/DomainGapAlign [10,25,26] |
|
|
| IMGT® databases | Results for IG V-DOMAIN or C-DOMAIN (amino acid sequences or structures) | Number of entries and examples of applications |
| IMGT/3Dstructure-DB [9,10,11] |
|
|
| IMGT/2Dstructure-DB [11] * |
|
|
3. IMGT® Tools for IG V-DOMAIN and C-DOMAIN Analysis
3.1. IMGT/V-QUEST
3.1.1. IMGT/V-QUEST Tool
3.1.2. IMGT/V-QUEST Reference Directory
3.2. IMGT/HighV-QUEST
3.2.1. IMGT/HighV-QUEST for NGS Repertoire Analysis
3.2.2. IMGT/HighV-QUEST for IMGT® Clonotype (AA) Analysis
3.2.2.1. IMGT Clonotypes (AA) Diversity
3.2.2.2. IMGT Clonotypes (AA) Expression
3.2.2.3. IMGT® Standardized Diversity and Expression Immunoprofiles
3.3. IMGT/DomainGapAlign
3.3.1. IMGT/DomainGapAlign Tool
3.3.2. IMGT/DomainSeq Reference Directory
4. IMGT® Databases for IG V-DOMAIN and C-DOMAIN Analysis
4.1. IMGT/3Dstructure-DB
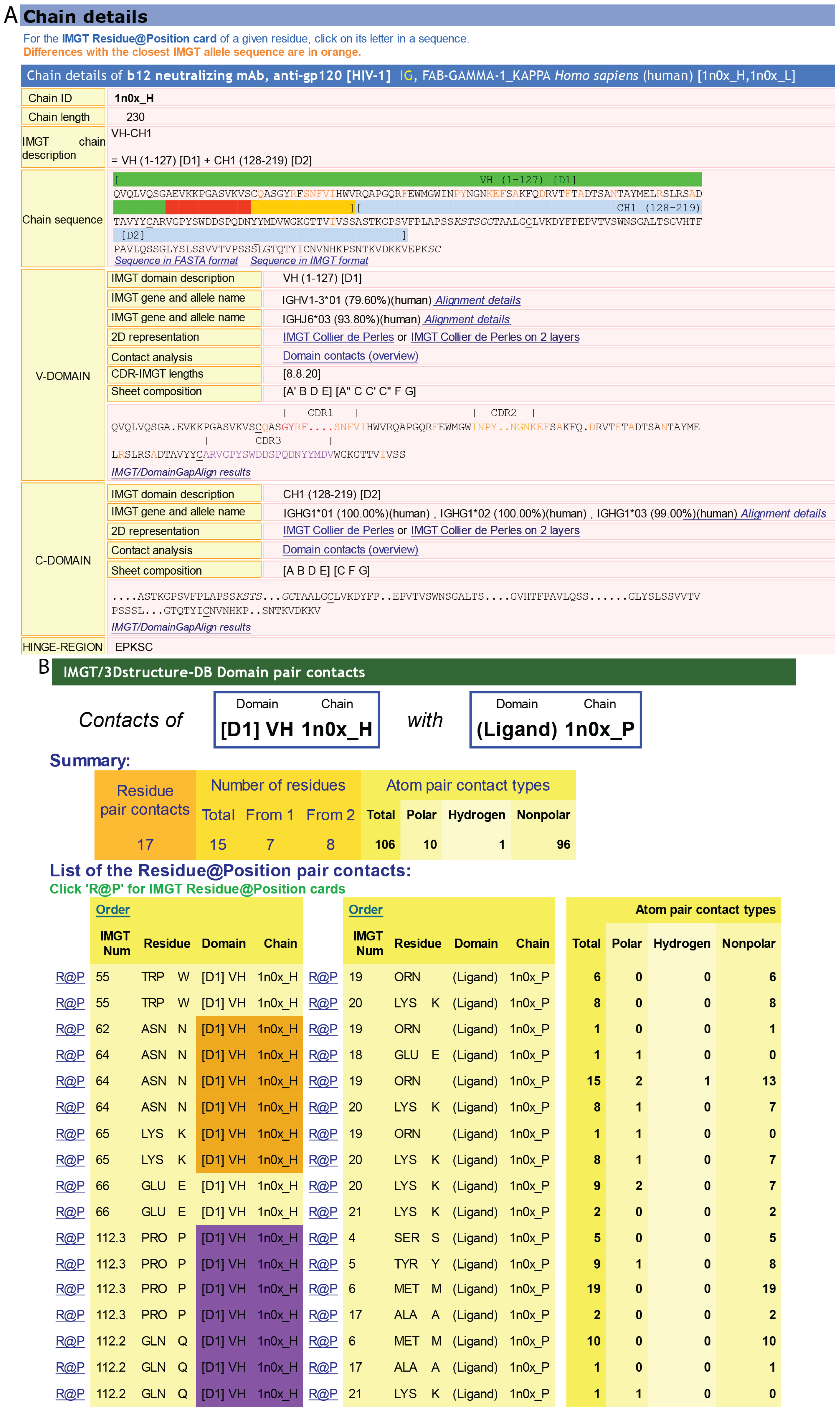
4.1.1. IMGT/3Dstructure-DB card
4.1.2. IMGT Chain and Domain Annotation
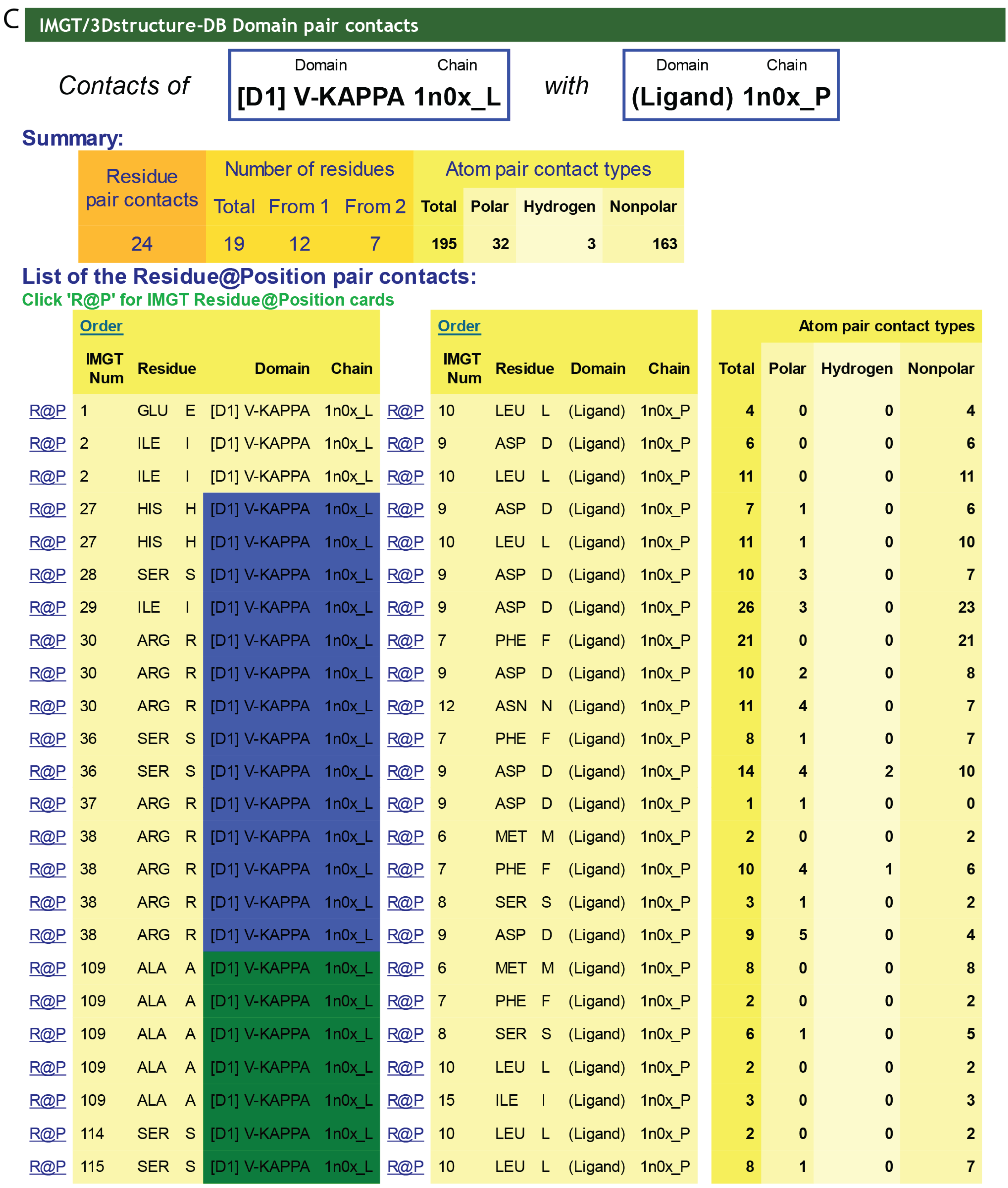
4.1.3. Contact Analysis
4.1.4. Paratope and Epitope
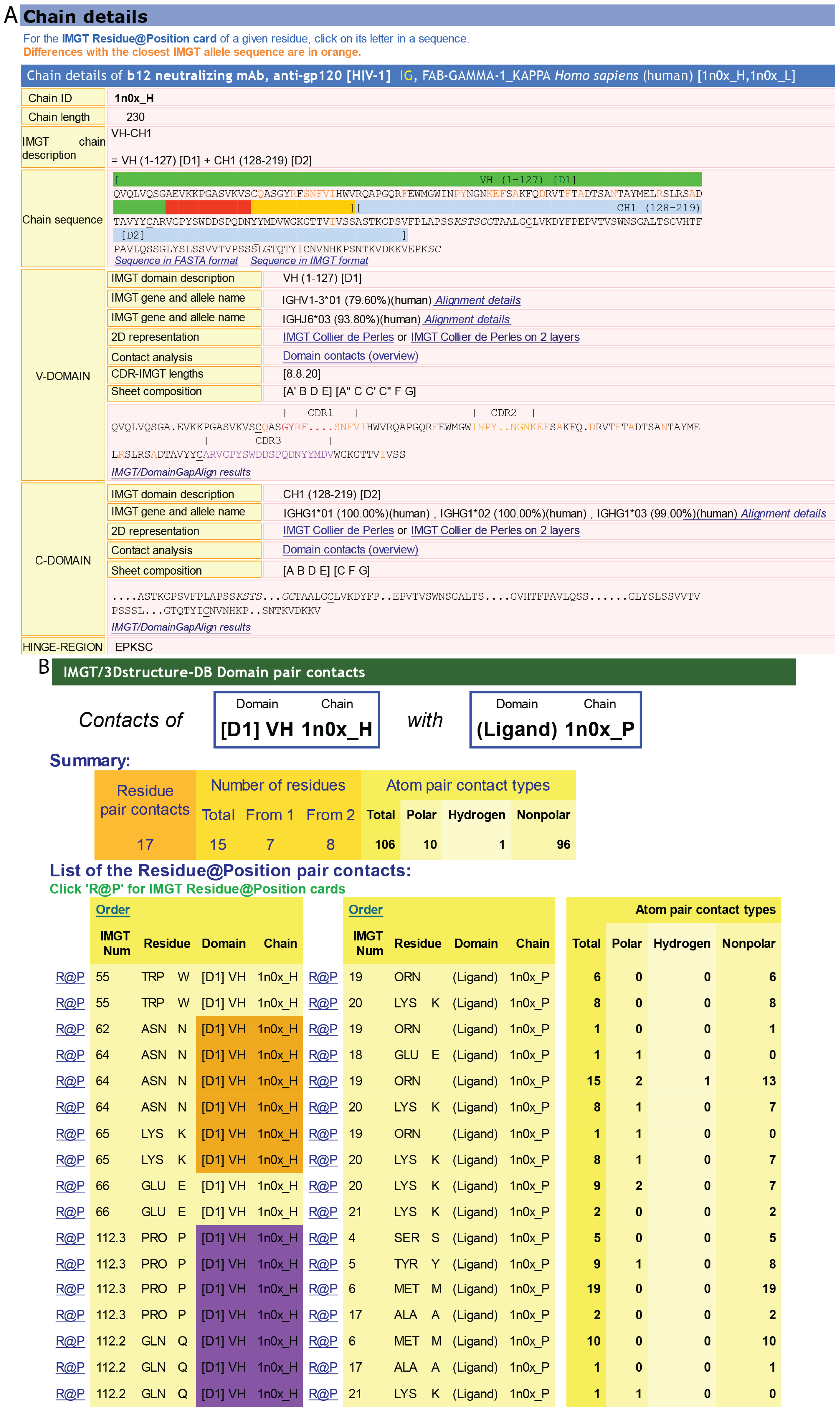
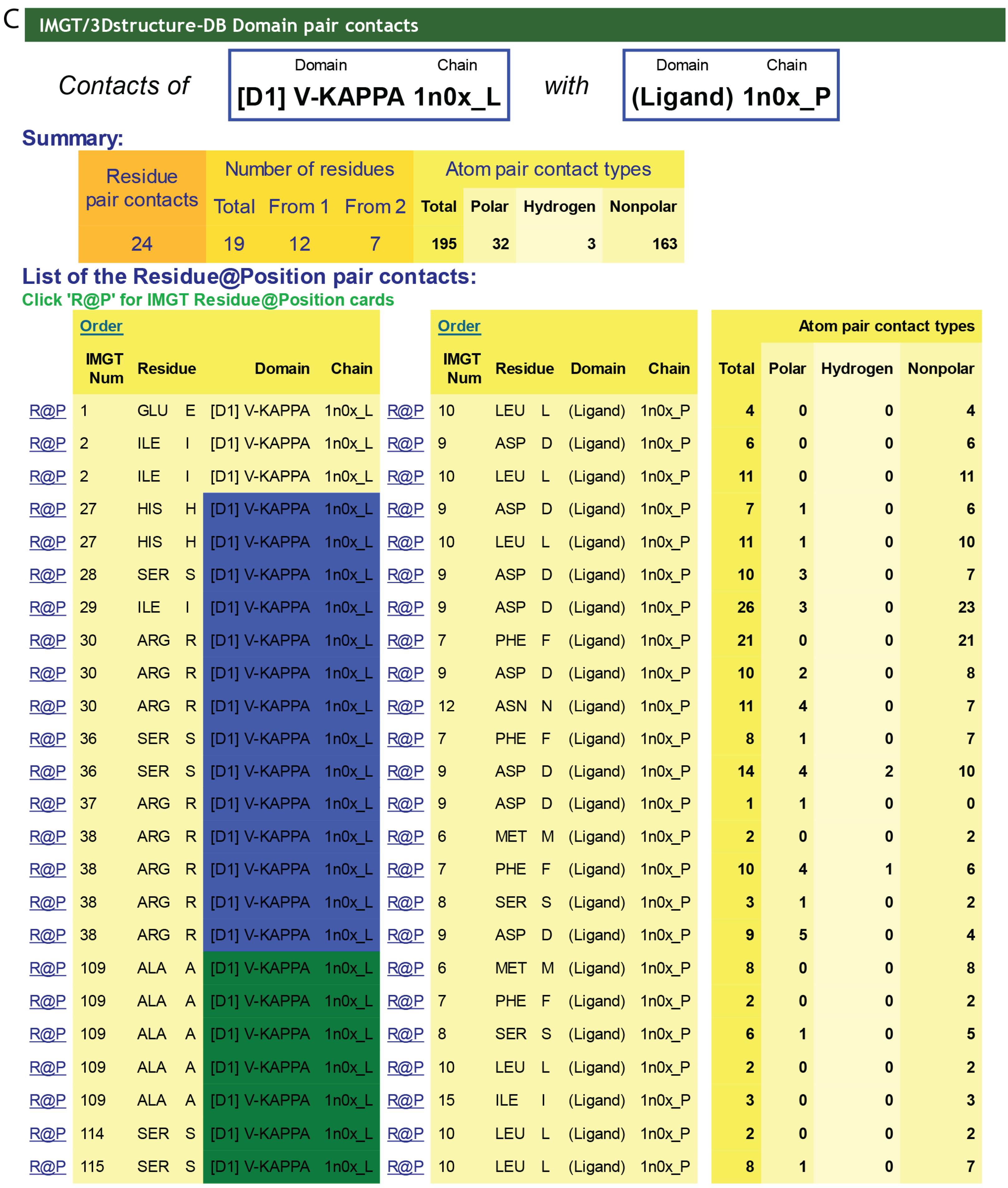
4.1.5. Renumbered Flat File and IMGT Numbering Comparison
4.1.6. IMGT/3Dstructure-DB Associated Tools
4.2. IMGT/2Dstructure-DB
5. IMGT® IG V-DOMAIN and C-DOMAIN Analysis for Antibody Humanization and Engineering
5.1. CDR-IMGT Delimitation for Grafting
5.2. Evaluation of the Degree of “Humanization” of an IG V Sequence
5.3. IGHG1 Alleles and G1m Allotypes
| IGHG1 Alleles | G1m Alleles a | IMGT Amino acid Positions b | Populations [77] | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| allotypes | Isoallotypes c | CH1 | CH3 | ||||||||
| 103 | 120 | 12 | 14 | 110 | |||||||
| G1m17/nG1m1 | G1m1/nG1m1 | G1m2/- | |||||||||
| G1m3 d | |||||||||||
| IGHG1*01 e, IGHG1*02 e | G1m17,1 | I | K | D | L | A | Caucasoid Negroid Mongoloid | ||||
| IGHG1*04 | G1m17,1,27 | ||||||||||
| IGHG1*05p | G1m17,1,28 | Negroid | |||||||||
| IGHG1*06p | G1m17,1,27,28 | Negroid | |||||||||
| IGHG1*03 | G1m3 | nG1m1, nG1m17 | I | R | E | M | A | Caucasoid | |||
| IGHG1*07p f | G1m17,1,2 | I | K | D | L | G | Caucasoid Mongoloid | ||||
| IGHG1*08p f | G1m3,1 | nG1m17 | I | R | D | L | A | Mongoloid | |||
5.4. IGHG N-Linked Glycosylation Site CH2 N84.4
6. Conclusions
Acknowledgments
Availability and Citation
Conflicts of Interest
References
- IMGT®, the international ImMunoGeneTics information system®. Available online: http://www.imgt.org/ (accessed on 4 November 2014).
- Lefranc, M.-P.; Giudicelli, V.; Duroux, P.; Jabado-Michaloud, J.; Folch, G.; Aouinti, S.; Carillon, E.; Duvergey, H.; Houles, A.; Paysan-Lafosse, T.; et al. IMGT®, the international ImMunoGeneTics information system® 25 years on. Nucleic Acids Res. 2014. [Google Scholar] [CrossRef]
- Lefranc, M.-P.; Lefranc, G. The Immunoglobulin FactsBook; Academic Press: London, UK, 2001; pp. 1–458. [Google Scholar]
- Lefranc, M.-P.; Lefranc, G. The T Cell Receptor FactsBook; Academic Press: London, UK, 2001; pp. 1–398. [Google Scholar]
- Lefranc, M.-P. Nomenclature of the human immunoglobulin genes. In Current Protocols in Immunology; Coligan, J.E., Bierer, B.E., Margulies, D.E., Shevach, E.M., Strober, W., Eds.; John Wiley and Sons: Hoboken, NJ, USA, 2000; pp. 1–37. [Google Scholar]
- Lefranc, M.-P. Nomenclature of the human T cell Receptor genes. In Current Protocols in Immunology; Coligan, J.E., Bierer, B.E., Margulies, D.E., Shevach, E.M., Strober, W., Eds.; John Wiley and Sons: Hoboken, NJ, USA, 2000; pp. 1–23. [Google Scholar]
- Giudicelli, V.; Duroux, P.; Ginestoux, C.; Folch, G.; Jabado-Michaloud, J.; Chaume, D.; Lefranc, M.-P. IMGT/LIGM-DB, the IMGT® comprehensive database of immunoglobulin and T cell receptor nucleotide sequences. Nucleic Acids Res. 2006, 34, D781–D784. [Google Scholar] [CrossRef] [PubMed]
- Giudicelli, V.; Chaume, D.; Lefranc, M.-P. IMGT/GENE-DB: A comprehensive database for human and mouse immunoglobulin and T cell receptor genes. Nucleic Acids Res. 2005, 33, D256–D261. [Google Scholar] [CrossRef] [PubMed]
- Kaas, Q.; Ruiz, M.; Lefranc, M.-P. IMGT/3Dstructure-DB and IMGT/StructuralQuery, a database and a tool for immunoglobulin, T cell receptor and MHC structural data. Nucleic Acids Res. 2004, 32, D208–D210. [Google Scholar] [CrossRef]
- Ehrenmann, F.; Kaas, Q.; Lefranc, M.-P. IMGT/3Dstructure-DB and IMGT/DomainGapAlign: A database and a tool for immunoglobulins or antibodies, T cell receptors, MHC, IgSF and MhcSF. Nucleic Acids Res. 2010, 38, D301–D307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ehrenmann, F.; Lefranc, M-P. IMGT/3Dstructure-DB: Querying the IMGT Database for 3D Structures in Immunology and Immunoinformatics (IG or Antibodies, TR, MH, RPI, and FPIA). Cold Spring Harb. Protoc. 2011, 6, 750–761. [Google Scholar]
- Poiron, C.; Wu, Y.; Ginestoux, C.; Ehrenmann, F.; Duroux, P.; Lefranc, M.-P. IMGT/mAb-DB: the IMGT® database for therapeutic monoclonal antibodies. In Proceedings of the 11èmes Journées Ouvertes de Biologie, Informatique et Mathématiques (JOBIM), Montpellier, France, 7–9 September 2010.
- Giudicelli, V.; Chaume, D.; Lefranc, M.-P. IMGT/V-QUEST, an integrated software for immunoglobulin and T cell receptor V-J and V-D-J rearrangement analysis. Nucleic Acids Res. 2004, 32, W435–W440. [Google Scholar] [CrossRef] [PubMed]
- Giudicelli, V.; Lefranc, M.-P. Interactive IMGT on-line tools for the analysis of immunoglobulin and T cell receptor repertoires. In New Research on Immunology; Veskler, B.A., Ed.; Nova Science Publishers Inc.: New York, NY, USA, 2005; pp. 77–105. [Google Scholar]
- Brochet, X.; Lefranc, M.-P.; Giudicelli, V. IMGT/V-QUEST: the highly customized and integrated system for IG and TR standardized V-J and V-D-J sequence analysis. Nucleic Acids Res. 2008, 36, W503–W508. [Google Scholar] [CrossRef] [PubMed]
- Giudicelli, V.; Lefranc, M.-P. IMGT® standardized analysis of immunoglobulin rearranged sequences. In Immunoglobulin Gene Analysis in Chronic Lymphocytic Leukemia; Ghia, P., Rosenquist, R., Davi, F., Eds.; Wolters Kluwer Health Italy Ltd: Milan, Italy, 2008; Chapter 2; pp. 33–52. [Google Scholar]
- Giudicelli, V.; Brochet, X.; Lefranc, M.-P. IMGT/V-QUEST: IMGT Standardized Analysis of the Immunoglobulin (IG) and T Cell Receptor (TR) Nucleotide Sequences. Cold Spring Harb. Protoc. 2011, 6, 695–715. [Google Scholar]
- Alamyar, E.; Duroux, P.; Lefranc, M.-P.; Giudicelli, V. IMGT® tools for the nucleotide analysis of immunoglobulin (IG) and T cell receptor (TR) V-(D)-J repertoires, polymorphisms, and IG mutations: IMGT/V-QUEST and IMGT/HighV-QUEST for NGS. In Immunogenetics: Methods and Applications in Clinical Practice; Christiansen, F.T., Tait, B.D., Eds.; Humana Press, Springer Science + Business Media: New York, NY, USA, 2012; Chapter 32; pp. 569–604. [Google Scholar]
- Yousfi Monod, M.; Giudicelli, V.; Chaume, D.; Lefranc, M.-P. IMGT/JunctionAnalysis: The first tool for the analysis of the immunoglobulin and T cell receptor complex V-J and V-D-J JUNCTIONs. Bioinformatics 2004, 20, i379–i385. [Google Scholar] [CrossRef] [PubMed]
- Giudicelli, V.; Lefranc, M.-P. IMGT/JunctionAnalysis: IMGT standardized analysis of the V-J and V-D-J junctions of the rearranged immunoglobulins (IG) and T cell receptors (TR). Cold Spring Harb. Protoc. 2011, 6, 716–725. [Google Scholar]
- Giudicelli, V.; Protat, C.; Lefranc, M.-P. The IMGT strategy for the automatic annotation of IG and TR cDNA sequences: IMGT/Automat. In Proceedings of the European Conference on Computational Biology (ECCB 2003), Data and Knowledge Bases, ECCB 2003, Paris, France, 27–30 September 2003; Institut National de Recherche en Informatique et en Automatique: Paris, France, 2003; pp. 103–104. [Google Scholar]
- Giudicelli, V.; Chaume, D.; Jabado-Michaloud, J.; Lefranc, M.-P. Immunogenetics Sequence Annotation: the Strategy of IMGT based on IMGT-ONTOLOGY. Stud. Health Technol. Inform. 2005, 116, 3–8. [Google Scholar] [PubMed]
- Alamyar, E.; Giudicelli, V.; Shuo, L.; Duroux, P.; Lefranc, M.-P. IMGT/HighV-QUEST: The IMGT® web portal for immunoglobulin (IG) or antibody and T cell receptor (TR) analysis from NGS high throughput and deep sequencing. Immunome Res. 2012, 8, 1–15. [Google Scholar]
- Li, S.; Lefranc, M.-P.; Miles, J.J.; Alamyar, E.; Giudicelli, V.; Duroux, P.; Freeman, J.D.; Corbin, V.; Scheerlinck, J.-P.; Frohman, M.A.; et al. IMGT/HighV-QUEST paradigm for T cell receptor IMGT clonotype diversity and next generation repertoire immunoprofiling. Nat. Commun. 2013, 4, 1–13. [Google Scholar]
- Ehrenmann, F.; Lefranc, M.-P. IMGT/DomainGapAlign: IMGT standardized analysis of amino acid sequences of Variable, Constant, and Groove domains (IG, TR, MH, IgSF, MhSF). Cold Spring Harb. Protoc. 2011, 6, 737–749. [Google Scholar]
- Ehrenmann, F.; Lefranc, M.-P. IMGT/DomainGapAlign: The IMGT® tool for the analysis of IG, TR, MHC, IgSF and MhcSF domain amino acid polymorphism. In Immunogenetics: Methods and Applications in Clinical Practice; Christiansen, F.T., Tait, B.D., Eds.; Humana Press, Springer Science + Business Media: New York, NY, USA, 2012; Chapter 33; pp. 605–633. [Google Scholar]
- Ehrenmann, F.; Giudicelli, V.; Duroux, P.; Lefranc, M.-P. IMGT/Collier de Perles: IMGT Standardized Representation of Domains (IG, TR, and IgSF Variable and Constant Domains, MH and MhSF Groove Domains). Cold Spring Harb. Protoc. 2011, 6, 726–736. [Google Scholar]
- Lane, J.; Duroux, P.; Lefranc, M.-P. From IMGT-ONTOLOGY to IMGT/LIGMotif: The IMGT® standardized approach for immunoglobulin and T cell receptor gene identification and description in large genomic sequences. BMC Bioinform. 2010, 11, 1–16. [Google Scholar] [CrossRef]
- Pommié, C.; Levadoux, S.; Sabatier, R.; Lefranc, G.; Lefranc, M.-P. IMGT standardized criteria for statistical analysis of immunoglobulin V-REGION amino acid properties. J. Mol. Recognit. 2004, 17, 17–32. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P. IMGT, the international ImMunoGeneTics information system. In Immunoinformatics: Bioinformatic Strategies for Better Understanding of Immune Function; Bock, G., Goode, J., Eds.; Novartis Foundation Symposium, John Wiley and Sons: Chichester, UK, 2003; Volume 254, pp. 126–142. [Google Scholar]
- Lefranc, M.-P.; Giudicelli, V.; Ginestoux, C.; Chaume, D. IMGT, the international ImMunoGeneTics information system: the reference in immunoinformatics. Stud. Health Technol. Inform. 2003, 95, 74–79. [Google Scholar] [PubMed]
- Lefranc, M.-P. IMGT databases, web resources and tools for immunoglobulin and T cell receptor sequence analysis. Leukemia 2003, 17, 260–266. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P. IMGT, the international ImMunoGenetics information system®. In Antibody Engineering Methods and Protocols, 2nd ed.; Lo, B.K.C., Ed.; Humana Press: Totowa, NJ, USA, 2004; pp. 27–49. [Google Scholar]
- Lefranc, M.-P. IMGT-ONTOLOGY and IMGT databases, tools and Web resources for immunogenetics and immunoinformatics. Mol. Immunol. 2004, 40, 647–660. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P. IMGT, the international ImMunoGeneTics information system: A standardized approach for immunogenetics and immunoinformatics. Immunome Res. 2005, 1, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P. IMGT®, the international ImMunoGeneTics information system® for immunoinformatics. Methods for querying IMGT® databases, tools and Web resources in the context of immunoinformatics. In Immunoinformatics: Predicting Immunogenicity in Silico; Flower, D.R., Ed.; Humana Press, Springer: Totowa, NJ, USA, 2007; Chapter 2; pp. 19–42. [Google Scholar]
- Lefranc, M.-P. IMGT-ONTOLOGY, IMGT® databases, tools and Web resources for Immunoinformatics. In Immunoinformatics; Schoenbach, C., Ranganathan, S., Brusic, V., Eds.; Immunomics Reviews, Series of Springer Science and Business Media LLC; Springer: New York, NY, USA, 2008; Volume 1, Chapter 1; pp. 1–18. [Google Scholar]
- Lefranc, M.-P.; Giudicelli, V.; Regnier, L.; Duroux, P. IMGT®, a system and an ontology that bridge biological and computational spheres in bioinformatics. Brief Bioinform. 2008, 9, 263–275. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P. IMGT®, the international ImMunoGeneTics information system® for immunoinformatics. Methods for querying IMGT® databases, tools and Web resources in the context of immunoinformatics. Mol. Biotechnol. 2008, 40, 101–111. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P. Antibody databases and tools: The IMGT® experience. In Therapeutic Monoclonal Antibodies: From Bench to Clinic; An, Z., Ed.; John Wiley and Sons: Hoboken, NJ, USA, 2009; Chapter 4; pp. 91–114. [Google Scholar]
- Lefranc, M.-P. Antibody databases: IMGT®, a French platform of world-wide interest (in French). Bases de données anticorps: IMGT®, une plate-forme française d’intérêt mondial. Med. Sci. 2009, 25, 1020–1023. [Google Scholar]
- Ehrenmann, F.; Duroux, P.; Giudicelli, V.; Lefranc, M.-P. Standardized sequence and structure analysis of antibody using IMGT®. In Antibody Engineering; Kontermann, R., Dübel, S., Eds.; Springer-Verlab: Berlin, Heidelberg, Germany, 2010; Volume 2, Chapter 2; pp. 11–31. [Google Scholar]
- Lefranc, M-P. IMGT, the international ImMunoGeneTics information system. Cold Spring Harb. Protoc. 2011, 6, 595–603. [Google Scholar]
- Lefranc, M.-P. IMGT® Information System. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer Science + Business Media, LLC012: New York, NY, USA, 2013; pp. 959–964. [Google Scholar]
- Lefranc, M.-P. Immunoglobulin (IG) and T cell receptor genes (TR): IMGT® and the birth and rise of immunoinformatics. Front. Immunol. 2014, 5, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P. WHO-IUIS Nomenclature Subcommittee for immunoglobulins and T cell receptors report. Immunogenetics 2007, 59, 899–902. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P. WHO-IUIS Nomenclature Subcommittee for immunoglobulins and T cell receptors report August 2007, 13th International Congress of Immunology, Rio de Janeiro, Brazil. Dev. Comp. Immunol. 2008, 32, 461–463. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. International Nonproprietary Names (INN) for Biological and Biotechnological Substances (a Review). Available online: http://www.who.int/medicines/services/inn/BioRev2012.pdf (accessed on 4 November 2014).
- Lefranc, M-P. Antibody nomenclature: From IMGT-ONTOLOGY to INN definition. MAbs 2011, 3, 1–2. [Google Scholar]
- Giudicelli, V.; Lefranc, M.-P. Ontology for immunogenetics: IMGT-ONTOLOGY. Bioinformatics 1999, 15, 1047–1054. [Google Scholar] [PubMed]
- Giudicelli, V.; Lefranc, M.-P. IMGT-ONTOLOGY 2012. Frontiers in Bioinformatics and Computational Biology. Front. Genet. 2012, 3, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Giudicelli, V.; Lefranc, M.-P. IMGT-ONTOLOGY. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer Science + Business Media, LLC012: New York, NY, USA, 2013; pp. 964–972. [Google Scholar]
- Giudicelli, V.; Lefranc, M.-P. IMGT-ONTOLOGY: Gestion et découverte de connaissances au sein d’IMGT (in French). In Extraction et Gestion des Connaissances (EGC’2003); Hacid, M.-S., Kodratoff, Y., Boulanger, D., Eds.; Hermès Science Publications, Lavoisier: Cachan, Paris, France, 2003; pp. 13–23. [Google Scholar]
- Lefranc, M.-P.; Giudicelli, V.; Ginestoux, C.; Bosc, N.; Folch, G.; Guiraudou, D.; Jabado-Michaloud, J.; Magris, S.; Scaviner, D.; Thouvenin, V.; et al. IMGT-ONTOLOGY for immunogenetics and immunoinformatics. Silico Biol. 2004, 4, 17–29. [Google Scholar]
- Lefranc, M.-P.; Clément, O.; Kaas, Q.; Duprat, E.; Chastellan, P.; Coelho, I.; Combres, K.; Ginestoux, C.; Giudicelli, V.; Chaume, D.; et al. IMGT-Choreography for Immunogenetics and Immunoinformatics. Silico Biol. 2005, 5, 45–60. [Google Scholar]
- Duroux, P.; Kaas, Q.; Brochet, X.; Lane, J.; Ginestoux, C.; Lefranc, M.-P.; Giudicelli, V. IMGT-Kaleidoscope, the formal IMGT-ONTOLOGY paradigm. Biochimie 2008, 90, 570–583. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P. From IMGT-ONTOLOGY IDENTIFICATION axiom to IMGT standardized keywords: For immunoglobulins (IG), T cell receptors (TR), and conventional genes. Cold Spring Harb. Protoc. 2011, 6, 604–613. [Google Scholar]
- Lefranc, M.-P. From IMGT-ONTOLOGY DESCRIPTION axiom to IMGT standardized labels: For immunoglobulin (IG) and T cell receptor (TR) sequences and structures. Cold Spring Harb. Protoc. 2011, 6, 614–626. [Google Scholar]
- Lefranc, M.-P. From IMGT-ONTOLOGY CLASSIFICATION axiom to IMGT standardized gene and allele nomenclature: For immunoglobulins (IG) and T cell receptors (TR). Cold Spring Harb. Protoc. 2011, 6, 627–632. [Google Scholar]
- Lefranc, M.-P. Unique database numbering system for immunogenetic analysis. Immunol. Today 1997, 18, 509. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P. The IMGT unique numbering for Immunoglobulins, T cell receptors and Ig-like domains. Immunologist 1999, 7, 132–136. [Google Scholar]
- Lefranc, M.-P.; Pommié, C.; Ruiz, M.; Giudicelli, V.; Foulquier, E.; Truong, L.; Thouvenin-Contet, V.; Lefranc, G. IMGT unique numbering for immunoglobulin and T cell receptor variable domains and Ig superfamily V-like domains. Dev. Comp. Immunol. 2003, 27, 55–77. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P.; Pommié, C.; Kaas, Q.; Duprat, E.; Bosc, N.; Guiraudou, D.; Jean, C.; Ruiz, M.; da Piedade, I.; Rouard, M.; et al. IMGT unique numbering for immunoglobulin and T cell receptor constant domains and Ig superfamily C-like domains. Dev. Comp. Immunol. 2005, 29, 185–203. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P.; Duprat, E.; Kaas, Q.; Tranne, M.; Thiriot, A.; Lefranc, G. IMGT unique numbering for MHC groove G-DOMAIN and MHC superfamily (MhcSF) G-LIKE-DOMAIN. Dev. Comp. Immunol. 2005, 29, 917–938. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M-P. IMGT unique numbering for the variable (V), constant (C), and groove (G) domains of IG, TR, MH, IgSF, and MhSF. Cold Spring Harb. Protoc. 2011, 6, 633–642. [Google Scholar]
- Ruiz, M.; Lefranc, M.-P. IMGT gene identification and Colliers de Perles of human immunoglobulins with known 3D structures. Immunogenetics 2002, 53, 857–883. [Google Scholar] [CrossRef] [PubMed]
- Kaas, Q.; Lefranc, M.-P. IMGT Colliers de Perles: Standardized sequence-structure representations of the IgSF and MhcSF superfamily domains. Curr. Bioinform. 2007, 2, 21–30. [Google Scholar] [CrossRef]
- Kaas, Q.; Ehrenmann, F.; Lefranc, M.-P. IG, TR and IgSf, MHC and MhcSF: What do we learn from the IMGT Colliers de Perles? Brief Funct. Genomic Proteomic 2007, 6, 253–264. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M-P. IMGT Collier de Perles for the variable (V), constant (C), and groove (G) domains of IG, TR, MH, IgSF, and MhSF. Cold Spring Harb. Protoc. 2011, 6, 643–651. [Google Scholar]
- Lefranc, M.-P. IMGT® immunoglobulin repertoire analysis and antibody humanization. In Molecular Biology of B Cells, 2nd ed.; Alt, F., Honjo, T., Radbruch, A., Reth, M., Eds.; Elsevier Ltd.: London, UK, 2014; Volume 1, Chapter 27; pp. 481–514. [Google Scholar]
- Robert, R.; Lefranc, M.-P.; Ghochikyan, A.; Agadjanyan, M.G.; Cribbs, D.H.; van Nostrand, W.E.; Wark, K.L.; Dolezal, O. Restricted V gene usage and VH/VL pairing of mouse humoral response against the N-terminal immunodominant epitope of the amyloid β peptide. Mol. Immunol. 2010, 48, 59–72. [Google Scholar] [CrossRef] [PubMed]
- Ghia, P.; Stamatopoulos, K.; Belessi, C.; Moreno, C.; Stilgenbauer, S.; Stevenson, F.I.; Davi, F.; Rosenquist, R. ERIC recommendations on IGHV gene mutational status analysis in chronic lymphocytic leukemia. Leukemia 2007, 21, 1–3. [Google Scholar] [CrossRef] [PubMed]
- Agathangelidis, A.; Darzentas, N.; Hadzidimitriou, A.; Brochet, X.; Murray, F.; Yan, X.J.; Davis, Z.; van Gastel-Mol, E.J.; Tresoldi, C.; Chu, C.C.; et al. Stereotyped B-cell receptors in one third of chronic lymphocytic leukemia: Towards a molecular classification with implications for targeted therapeutic interventions. Blood 2012, 119, 4467–4475. [Google Scholar] [CrossRef] [PubMed]
- Kostareli, E.; Gounari, M.; Janus, A.; Murray, F.; Brochet, X.; Giudicelli, V.; Pospisilova, S.; Oscier, D.; Foroni, L.; di Celle, P.F.; et al. Antigen receptor stereotypy across B-cell lymphoproliferations: the case of IGHV4–59/IGKV3–20 receptors with rheumatoid factor activity. Leukemia 2012, 26, 1127–1131. [Google Scholar] [CrossRef] [PubMed]
- Xochelli, A.; Agathangelidis, A.; Kavakiotis, I.; Minga, E.; Sutton, L.A.; Baliakas, P.; Chouvarda, I.; Giudicelli, V.; Vlahavas, I.; Maglaveras, N.; et al. Immunoglobulin heavy variable (IGHV) genes and alleles: New entities, new names and implications for research and prognostication in chronic lymphocytic leukemia. Immunogenetics 2014. [Google Scholar] [CrossRef]
- Jefferis, R.; Lefranc, M.-P. Human immunoglobulin allotypes: Possible implications for immunogenicity. MAbs 2009, 1, 332–338. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P.; Lefranc, G. Human Gm, Km and Am allotypes and their molecular characterization: A remarkable demonstration of polymorphism. In Immunogenetics: Methods and Applications in Clinical Practice; Christiansen, F.T., Tait, B.D., Eds.; Humana Press, Springer: New York, NY, USA, 2012; Chapter 34; pp. 635–680. [Google Scholar]
- Dechavanne, C.; Guillonneau, F.; Chiappetta, G.; Sago, L.; Lévy, P.; Salnot, V.; Guitard, E.; Ehrenmann, F.; Broussard, C.; Chafey, P.; et al. Mass spectrometry detection of G3m and IGHG3 alleles and follow-up of differential mother and neonate IgG3. PLoS One 2012, 7, e46097. [Google Scholar] [CrossRef] [PubMed]
- Magdelaine-Beuzelin, C.; Kaas, Q.; Wehbi, V.; Ohresser, M.; Jefferis, R.; Lefranc, M.-P.; Watier, H. Structure-function relationships of the variable domains of monoclonal antibodies approved for cancer treatment. Crit. Rev. Oncol. Hematol. 2007, 64, 210–225. [Google Scholar] [CrossRef] [PubMed]
- Pelat, T.; Bedouelle, H.; Rees, A.R.; Crennell, S.J.; Lefranc, M.-P.; Thullier, P. Germline humanization of a non-human Primate antibody that neutralizes the anthrax toxin, by in vitro and in silico engineering. J. Mol. Biol. 2008, 384, 1400–1407. [Google Scholar] [CrossRef] [PubMed]
- Pelat, T.; Hust, M.; Hale, M.; Lefranc, M.-P.; Dübel, S.; Thullier, P. Isolation of a human-like antibody fragment (scFv) that neutralizes ricin biological activity. BMC Biotechnol. 2009, 9, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Lefranc, M.-P.; Ehrenmann, F.; Ginestoux, C.; Duroux, P.; Giudicelli, V. Use of IMGT® databases and tools for antibody engineering and humanization. In Antibody Engineering, 2nd ed.; Chames, P., Ed.; Humana Press, Springer Science + Business Media LLC: New York, NY, USA, 2012; Chapter 1; pp. 3–37. [Google Scholar]
- Alamyar, E.; Giudicelli, V.; Duroux, P.; Lefranc, M.-P. Antibody V and C domain sequence, structure and interaction analysis with special reference to IMGT®. In Monoclonal Antibodies: Methods and Protocols, 2nd ed.; Ossipow, V., Fisher, A., Eds.; Humana Press, Springer Science + Business Media LLC: New York, NY, USA, 2013; Chapter 21; pp. 337–381. [Google Scholar]
- Lefranc, M.-P. Immunoinformatics of the V, C and G domains: IMGT® definitive system for IG, TR and IgSF, MH and MhSF. In Immunoinformatics: From Biology to Informatics, 2nd ed.; de, R.K., Tomar, N., Eds.; Humana Press, Springer Science + Business Media LLC: New York, NY, USA, 2013; Chapter 4; pp. 59–107. [Google Scholar]
- Lefranc, M.-P. How to use IMGT® for therapeutic antibody engineering. In Handbook of Therapeutic Antibodies, 2nd ed.; Dübel, S., Reichert, J., Eds.; Wiley-VCH Verlag GmbH & Co. KGaA: Weinheim, Germany, 2014; Volume 1, Chapter 10; pp. 229–263. [Google Scholar]
- Shirai, H.; Prades, C.; Vita, R.; Marcatili, P.; Popovic, B.; Xu, J.; Overington, J.P.; Hirayama, K.; Soga, S.; Tsunoyama, K.; et al. Biochim. Biophys. Acta 2014, 1844, 2002–2015.
- BioPortal. Available online: http://bioportal.bioontology.org/ontologies/IMGT-ONTOLOGY/ (accessed on 4 November 2014).
- Wain, H.M.; Bruford, E.A.; Lovering, R.C.; Lush, M.J.; Wright, M.W.; Povey, S. Guidelines for human gene nomenclature. Genomics 2002, 79, 464–470. [Google Scholar] [CrossRef] [PubMed]
- Bruford, E.A.; Lush, M.J.; Wright, M.W.; Sneddon, T.P.; Povey, S.; Birney, E. The HGNC database in 2008: A resource for the human genome. Nucleic Acids Res. 2008, 36, D445–D448. [Google Scholar] [CrossRef] [PubMed]
- Letovsky, S.I.; Cottingham, R.W.; Porter, C.J.; Li, P.W. GDB: The human Genome Database. Nucleic Acids Res. 1998, 26, 94–99. [Google Scholar] [CrossRef] [PubMed]
- Maglott, D.R.; Katz, K.S.; Sicotte, H.; Pruitt, K.D. NCBI’s LocusLink and RefSeq. Nucleic Acids Res. 2000, 28, 126–128. [Google Scholar] [CrossRef] [PubMed]
- Maglott, D.; Ostell, J.; Pruitt, K.D.; Tatusova, T. Entrez Gene: Gene-centered information at NCBI. Nucleic Acids Res. 2007, 35, D26–D31. [Google Scholar] [CrossRef] [PubMed]
- Stabenau, A.; McVicker, G.; Melsopp, C.; Proctor, G.; Clamp, M.; Birney, E. The Ensembl core software libraries. Genome Res. 2004, 14, 929–933. [Google Scholar] [CrossRef] [PubMed]
- Wilming, L.G.; Gilbert, J.G.; Howe, K.; Trevanion, S.; Hubbard, T.; Harrow, J.L. The vertebrate genome annotation (Vega) database. Nucleic Acids Res. 2008, 36, D753–D760. [Google Scholar] [CrossRef] [PubMed]
- Kabat, E.A.; Wu, T.T.; Perry, H.M.; Gottesman, K.S.; Foeller, C. Sequences of Proteins of Immunological Interest; Department of Health and Human Services (USDHHS), National Institute of Health NIH Publication: Washington, DC, USA, 1991; pp. 91–3242. [Google Scholar]
- Chothia, C.; Lesk, A.M. Canonical structures for the hypervariable regions of immunoglobulins. Mol. Biol. 1987, 196, 901–917. [Google Scholar] [CrossRef]
- PyMOL. Available online: http://www.pymol.org/ (accessed on 4 November 2014).
- Rose, P.W.; Beran, B.; Bi, C.; Bluhm, W.F.; Dimitropoulos, D.; Goodsell, D.S.; Prlic, A.; Quesada, M.; Quinn, G.B.; Westbrook, J.D.; et al. The RCSB Protein Data Bank: Redesigned web site and web services. Nucleic Acids Res. 2011, 39, D392–D401. [Google Scholar] [CrossRef] [PubMed]
- Riechmann, L.; Clark, M.; Waldmann, H.; Winter, G. Reshaping human antibodies for therapy. Nature 1988, 332, 323–327. [Google Scholar] [CrossRef] [PubMed]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lefranc, M.-P. Immunoglobulins: 25 Years of Immunoinformatics and IMGT-ONTOLOGY. Biomolecules 2014, 4, 1102-1139. https://doi.org/10.3390/biom4041102
Lefranc M-P. Immunoglobulins: 25 Years of Immunoinformatics and IMGT-ONTOLOGY. Biomolecules. 2014; 4(4):1102-1139. https://doi.org/10.3390/biom4041102
Chicago/Turabian StyleLefranc, Marie-Paule. 2014. "Immunoglobulins: 25 Years of Immunoinformatics and IMGT-ONTOLOGY" Biomolecules 4, no. 4: 1102-1139. https://doi.org/10.3390/biom4041102
APA StyleLefranc, M.-P. (2014). Immunoglobulins: 25 Years of Immunoinformatics and IMGT-ONTOLOGY. Biomolecules, 4(4), 1102-1139. https://doi.org/10.3390/biom4041102