Cheminformatics to Characterize Pharmacologically Active Natural Products



Abstract
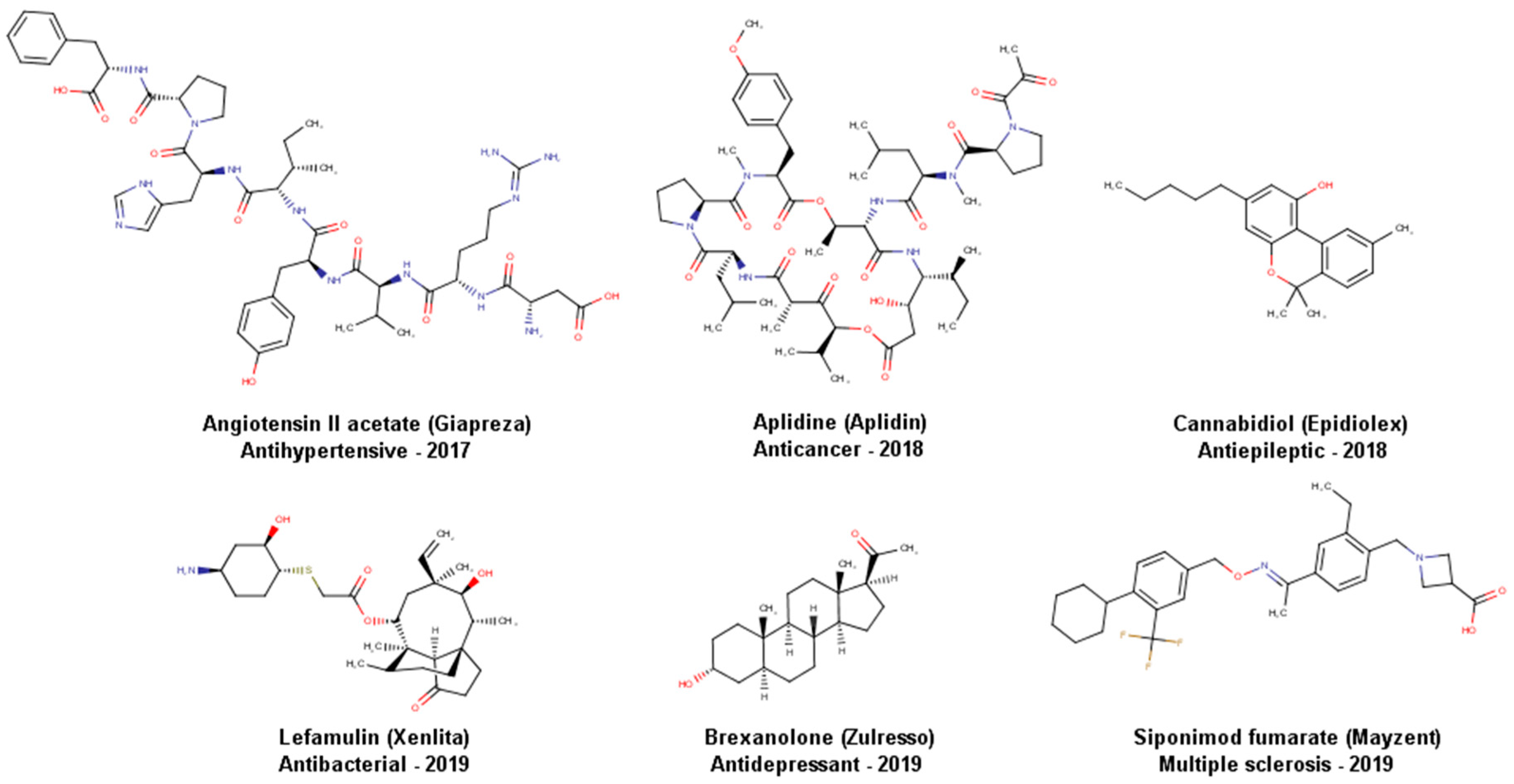
1. Introduction
2. Natural Product Databases
3. Chemoinformatic Profiling
3.1. Physicochemical Properties
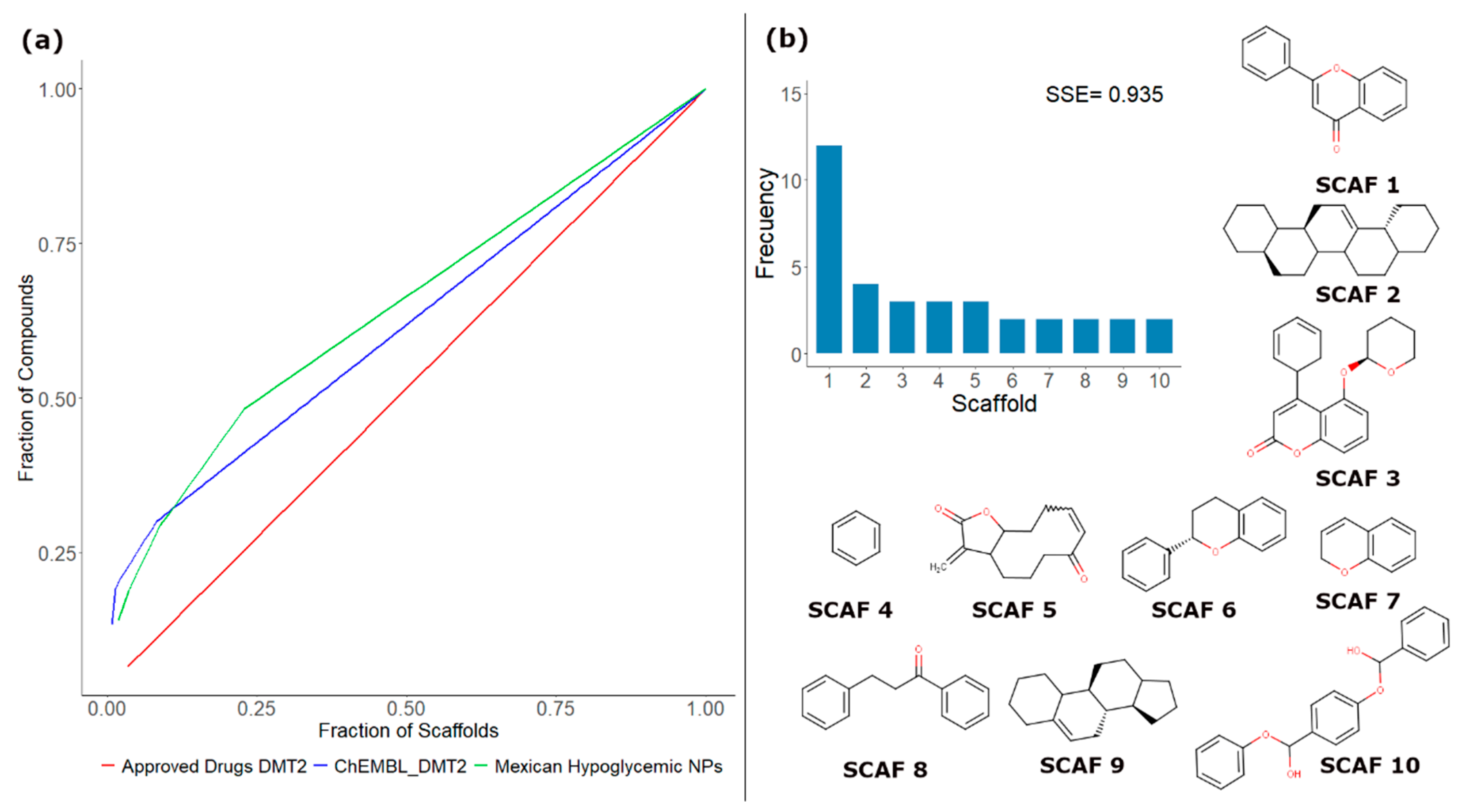
3.2. Molecular Scaffolds
3.3. Molecular Complexity
3.4. Fragments
3.5. Acid and Base Profiling
3.6. ADME/Tox Profiling
3.7. Global Diversity
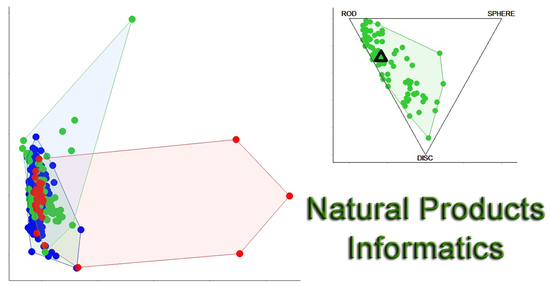
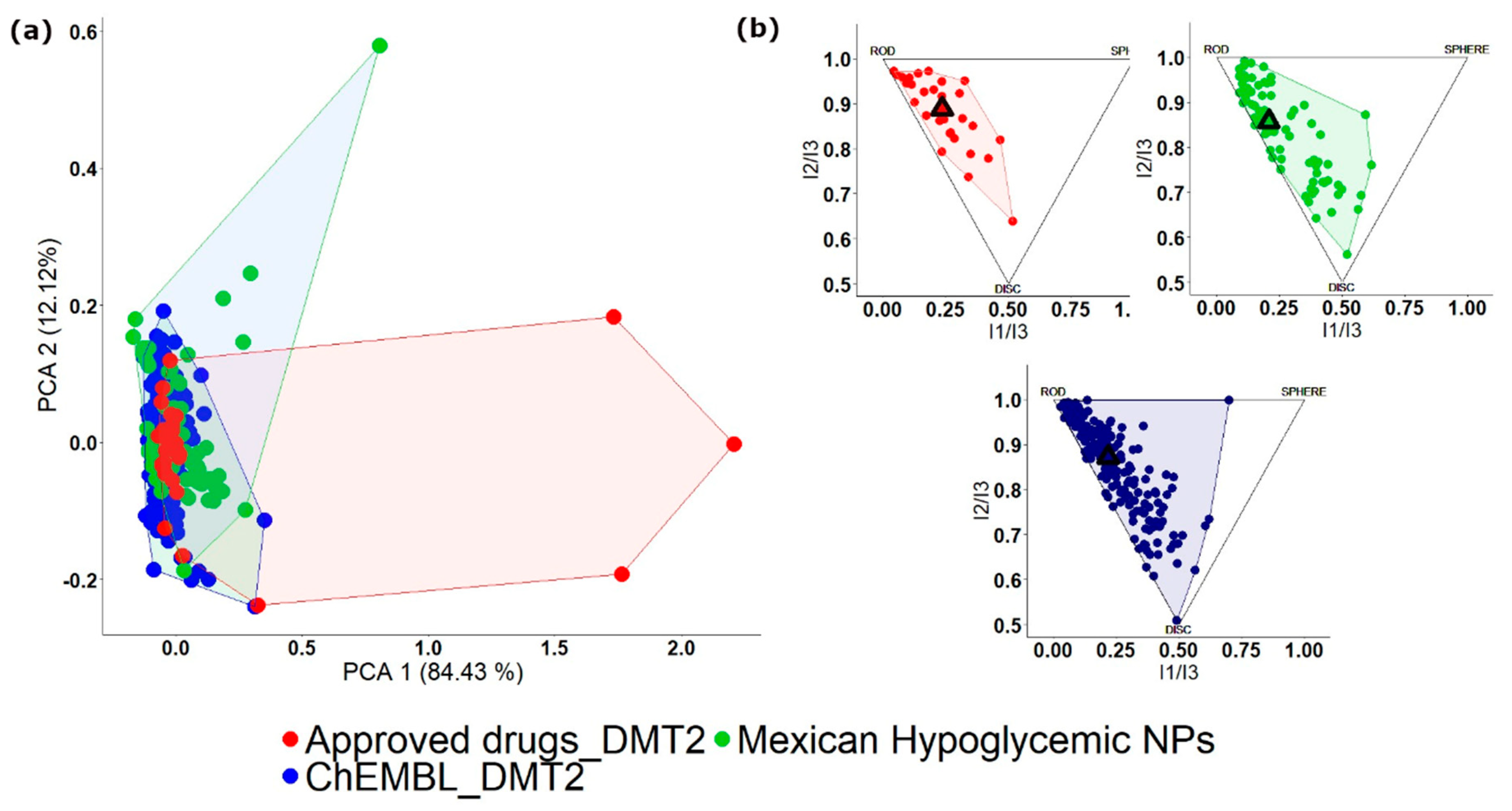
3.8. Chemical Space: Visual Representation
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Newman, D.J.; Cragg, G.M. Natural products as sources of new drugs over the nearly four decades from 01/1981 to 09/2019. J. Nat. Prod. 2020, 83, 770–803. [Google Scholar] [CrossRef] [PubMed]
- Corrêa, T.D.; Takala, J.; Jakob, S.M. Angiotensin II in septic shock. Crit. Care 2015, 16, 98. [Google Scholar] [CrossRef] [PubMed]
- Broggini, M.; Marchini, S.V.; Galliera, E.; Borsotti, P.; Taraboletti, G.; Erba, E.; Sironi, M.; Jimeno, J.; Faircloth, G.T.; Giavazzi, R.; et al. Aplidine, a new anticancer agent of marine origin, inhibits vascular endothelial growth factor (VEGF) secretion and blocks VEGF-VEGFR-1 (flt-1) autocrine loop in human leukemia cells MOLT-4. Leukemia 2003, 17, 52–59. [Google Scholar] [CrossRef] [PubMed]
- Ibeas Bih, C.; Chen, T.; Nunn, A.V.; Bazelot, M.; Dallas, M.; Whalley, B.J. Molecular targets of cannabidiol in neurological disorders. Neurotherapeutics 2015, 12, 699–730. [Google Scholar] [CrossRef]
- Méndez-Lucio, O.; Medina-Franco, J.L. The many roles of molecular complexity in drug discovery. Drug Discov. Today 2017, 22, 120–126. [Google Scholar] [CrossRef]
- Saldívar-González, F.I.; Gómez-García, A.; Chávez-Ponce de León, D.E.; Sánchez-Cruz, N.; Ruiz-Rios, J.; Pilón-Jiménez, B.A.; Medina-Franco, J.L. Inhibitors of DNA methyltransferases from natural sources: A computational perspective. Front. Pharmacol. 2018, 9, 1144. [Google Scholar] [CrossRef]
- Medina-Franco, J.L. Discovery and development of lead compounds from natural sources using computational approaches. In Evidence-Based Validation of Herbal Medicine; Mukherjee, P., Ed.; Elsevier: Amsterdam, The Netherlands, 2015; pp. 455–475. [Google Scholar]
- Prieto-Martínez, F.D.; Norinder, U. Cheminformatics explorations of natural products. In Progress in the Chemistry of Organic Natural Products; Kinghorn, A., Falk, H., Gibbons, S., Kobayashi, J., Asakawa, Y., Eds.; Springer: Cham, Switzerland, 2019; Volume 110. [Google Scholar]
- Koulouridi, E.; Valli, M.; Ntie-Kang, F.; Bolzani, V.D.S. A primer on natural product-based virtual screening. Phys. Sci. Rev. 2019, 4, 20180105. [Google Scholar] [CrossRef]
- Chen, Y.; Kirchmair, J. Cheminformatics in natural product-based drug discovery. Mol. Inf. 2020, in press. [Google Scholar] [CrossRef]
- Martinez-Mayorga, K.; Madariaga-Mazon, A.; Medina-Franco, J.L.; Maggiora, G. The impact of chemoinformatics on drug discovery in the pharmaceutical industry. Exp. Opin. Drug Discov. 2020, 15, 293–306. [Google Scholar] [CrossRef]
- Zhang, R.; Li, X.; Zhang, X.; Qin, H.; Xiao, W. Machine learning approaches for elucidating the biological effects of natural products. Nat. Prod. Rep. 2020, in press. [Google Scholar] [CrossRef]
- Kirchweger, B.; Kratz, J.M.; Ladurner, A.; Grienke, U.; Langer, T.; Dirsch, V.M.; Rollinger, J.M. In Silico workflow for the discovery of natural products activating the G protein-coupled bile acid receptor 1. Front. Chem. 2018, 6, 242. [Google Scholar] [CrossRef] [PubMed]
- Gasteiger, J. Chemistry in times of artificial intelligence. ChemPhysChem 2020, 21, 2233–2242. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; De Bruyn Kops, C.; Kirchmair, J. Data resources for the computer-guided discovery of bioactive natural products. J. Chem. Inf. Model. 2017, 57, 2099–2111. [Google Scholar] [CrossRef] [PubMed]
- Yongye, A.B.; Waddell, J.; Medina-Franco, J.L. Molecular scaffold analysis of natural products databases in the public domain. Chem. Biol. Drug Des. 2012, 80, 717–724. [Google Scholar] [CrossRef] [PubMed]
- Fullbeck, M.; Michalsky, E.; Dunkel, M.; Preissner, R. Natural products: Sources and databases. Nat. Prod. Rep. 2006, 23, 347–356. [Google Scholar] [CrossRef] [PubMed]
- Sorokina, M.; Steinbeck, C. Review on natural products databases: Where to find data in 2020. J. Cheminf. 2020, 12, 20. [Google Scholar] [CrossRef]
- Simoben, C.V.; Qaseem, A.; Moumbock, A.F.A.; Telukunta, K.K.; Günther, S.; Sippl, W.; Ntie-Kang, F. Pharmacoinformatic investigation of medicinal plants from East Africa. Mol. Inf. 2020, 39, 2000163. [Google Scholar] [CrossRef]
- Medina-Franco, J.L. Towards a unified Latin American natural products database: LANaPD. Future Sci. OA 2020, 6, FSO468. [Google Scholar] [CrossRef]
- Christoforow, A.; Wilke, J.; Binici, A.; Pahl, A.; Ostermann, C.; Sievers, S.; Waldmann, H. Design, synthesis, and phenotypic profiling of pyrano-furo-pyridone pseudo natural products. Angew. Chem. Int. Ed. 2019, 58, 14715–14723. [Google Scholar] [CrossRef]
- Chávez-Hernández, A.L.; Sánchez-Cruz, N.; Medina-Franco, J.L. A fragment library of natural products and its comparative chemoinformatic characterization. Mol. Inf. 2020, 39, 2000050. [Google Scholar] [CrossRef]
- Saldívar-González, F.I.; Medina-Franco, J.L. Chapter 3—Chemoinformatics approaches to assess chemical diversity and complexity of small molecules. In Small Molecule Drug Discovery; Trabocchi, A., Lenci, E., Eds.; Elsevier: Amsterdam, The Netherlands, 2020; pp. 83–102. [Google Scholar]
- Olmedo, D.A.; González-Medina, M.; Gupta, M.P.; Medina-Franco, J.L. Cheminformatic characterization of natural products from Panama. Mol. Divers. 2017, 21, 779–789. [Google Scholar] [CrossRef] [PubMed]
- Olmedo, D.A.; Medina-Franco, J.L. Chemoinformatic approach: The case of natural products of Panama. In Cheminformatics and Its Applications; Stefaniu, A., Rasul, A., Hussain, G., Eds.; IntechOpen: London, UK, 2019. [Google Scholar] [CrossRef]
- González-Medina, M.; Medina-Franco, J.L. Chemical diversity of cyanobacterial compounds: A chemoinformatics analysis. ACS Omega 2019, 4, 6229–6237. [Google Scholar] [CrossRef]
- Saldívar-González, F.I.; Valli, M.; Andricopulo, A.D.; Da Silva Bolzani, V.; Medina-Franco, J.L. Chemical space and diversity of the NUBBE database: A chemoinformatic characterization. J. Chem. Inf. Model. 2019, 59, 74–85. [Google Scholar] [CrossRef] [PubMed]
- Santibáñez-Morán, M.G.; Medina-Franco, J.L. Analysis of the acid/base profile of natural products from different sources. Mol. Inf. 2020, 39, e1900099. [Google Scholar] [CrossRef] [PubMed]
- Sánchez-Cruz, N.; Pilón-Jiménez, B.; Medina-Franco, J. Functional group and diversity analysis of Biofacquim: A mexican natural product database [version 2; peer review: 3 approved]. F1000Research 2020, 8, 2071. [Google Scholar] [CrossRef]
- Durán-Iturbide, N.A.; Díaz-Eufracio, B.I.; Medina-Franco, J.L. In silico ADME/Tox profiling of natural products: A focus on Biofacquim. ACS Omega 2020, 5, 16076–16084. [Google Scholar] [CrossRef]
- Tran, T.D.; Ogbourne, S.M.; Brooks, P.R.; Sánchez-Cruz, N.; Medina-Franco, J.L.; Quinn, R.J. Lessons from exploring chemical space and chemical diversity of propolis components. Int. J. Mol. Sci. 2020, 21, 4988. [Google Scholar] [CrossRef]
- Al Sharie, A.H.; El-Elimat, T.; Al Zu’bi, Y.O.; Aleshawi, A.J.; Medina-Franco, J.L. Chemical space and diversity of seaweed metabolite database (SWMD): A cheminformatics study. J. Mol. Graph. Model. 2020, 100, 107702. [Google Scholar] [CrossRef]
- Fatima, S.; Gupta, P.; Sharma, S.; Sharma, A.; Agarwal, S.M. ADMET profiling of geographically diverse phytochemical using chemoinformatic tools. Future Med. Chem. 2020, 12, 69–87. [Google Scholar] [CrossRef]
- Moumbock, A.F.A.; Gao, M.; Qaseem, A.; Li, J.; Kirchner, P.A.; Ndingkokhar, B.; Bekono, B.D.; Simoben, C.V.; Babiaka, S.B.; Malange, Y.I.; et al. StreptomeDB 3.0: An updated compendium of streptomycetes natural products. Nucleic Acids Res. 2020, in press. [Google Scholar] [CrossRef]
- Lipinski, C.A. Lead- and drug-like compounds: The rule-of-five revolution. Drug Discov. Today Technol. 2004, 1, 337–341. [Google Scholar] [CrossRef] [PubMed]
- Veber, D.F.; Johnson, S.R.; Cheng, H.Y.; Smith, B.R.; Ward, K.W.; Kopple, K.D. Molecular properties that influence the oral bioavailability of drug candidates. J. Med. Chem. 2002, 45, 2615–2623. [Google Scholar] [CrossRef] [PubMed]
- Feher, M.; Schmidt, J.M. Property distributions: Differences between drugs, natural products, and molecules from combinatorial chemistry. J. Chem. Inf. Comput. Sci. 2003, 43, 218–227. [Google Scholar] [CrossRef]
- Singh, N.; Guha, R.; Giulianotti, M.A.; Pinilla, C.; Houghten, R.A.; Medina-Franco, J.L. Chemoinformatic analysis of combinatorial libraries, drugs, natural products, and molecular libraries small molecule repository. J. Chem. Inf. Model. 2009, 49, 1010–1024. [Google Scholar] [CrossRef] [PubMed]
- Pilón-Jimenez, B.A.; Saldívar-González, F.I.; Díaz-Eufracio, B.I.; Medina-Franco, J.L. BIOFACQUIM: A Mexican compound database of natural products. Biomolecules 2019, 9, 31. [Google Scholar] [CrossRef]
- Evans, B.E.; Rittle, K.E.; Bock, M.G.; DiPardo, R.M.; Freidinger, R.M.; Whitter, W.L.; Lundell, G.F.; Veber, D.F.; Anderson, P.S.; Chang, R.S.L.; et al. Methods for drug discovery: Development of potent, selective, orally effective cholecystokinin antagonists. J. Med. Chem. 1988, 31, 2235–2246. [Google Scholar] [CrossRef] [PubMed]
- Schneider, G.; Neidhart, W.; Giller, T.; Schmid, G. Scaffold-hopping by topological pharmacophore search: A contribution to virtual screening. Angew. Chem. Int. Ed. 1999, 38, 2894–2896. [Google Scholar] [CrossRef]
- Langdon, S.R.; Brown, N.; Blagg, J. Scaffold diversity of exemplified medicinal chemistry space. J. Chem. Inf. Model. 2011, 51, 2174–2185. [Google Scholar] [CrossRef]
- Escandón-Rivera, S.M.; Mata, R.; Andrade-Cetto, A. Molecules isolated from Mexican hypoglycemic plants: A Review. Molecules 2020, 25, 4145. [Google Scholar] [CrossRef]
- Bemis, G.W.; Murcko, M.A. The properties of known drugs. 1. Molecular frameworks. J. Med. Chem. 1996, 39, 2887–2893. [Google Scholar] [CrossRef]
- Medina-Franco, J.; Martínez-Mayorga, K.; Bender, A.; Scior, T. Scaffold diversity analysis of compound data sets using an entropy-based measure. QSAR Comb. Sci. 2009, 28, 1551–1560. [Google Scholar] [CrossRef]
- Medina-Franco, J.L.; Maggiora, G.M. Molecular similarity analysis. In Chemoinformatics for Drug Discovery; John Wiley & Sons, Inc.: New York, NY, USA, 2013; pp. 343–399. [Google Scholar]
- Saldívar-González, F.I.; Huerta-García, C.S.; Medina-Franco, J.L. Chemoinformatics-based enumeration of chemical libraries: A tutorial. J. Cheminf. 2020, 12, 64. [Google Scholar] [CrossRef]
- Lovering, F. Escape from flatland 2: Complexity and promiscuity. MedChemComm 2013, 4, 515–519. [Google Scholar] [CrossRef]
- Wei, W.; Cherukupalli, S.; Jing, L.; Liu, X.; Zhan, P. Fsp3: A new parameter for drug-likeness. Drug Discov. Today 2020, 25, 1839–1845. [Google Scholar] [CrossRef]
- Sander, T.; Freyss, J.; Von Korff, M.; Rufener, C. Datawarrior: An open-source program for chemistry aware data visualization and analysis. J. Chem. Inf. Model. 2015, 55, 460–473. [Google Scholar] [CrossRef]
- López-López, E.; Naveja, J.J.; Medina-Franco, J.L. Datawarrior: An evaluation of the open-source drug discovery tool. Expert Opin. Drug Discov. 2019, 14, 335–341. [Google Scholar] [CrossRef]
- Ganesan, A. Natural products as a hunting ground for combinatorial chemistry. Curr. Opin. Biotechnol. 2004, 15, 584–590. [Google Scholar] [CrossRef]
- Mendez, D.; Gaulton, A.; Bento, A.P.; Chambers, J.; De Veij, M.; Félix, E.; Magariños, M.P.; Mosquera, J.F.; Mutowo, P.; Nowotka, M.; et al. Chembl: Towards direct deposition of bioassay data. Nucleic Acids Res. 2019, 47, D930–D940. [Google Scholar] [CrossRef]
- Manallack, D.T.; Prankerd, R.J.; Yuriev, E.; Oprea, T.I.; Chalmers, D.K. The significance of acid/base properties in drug discovery. Chem. Soc. Rev. 2013, 42, 485–496. [Google Scholar] [CrossRef]
- Santibáñez-Morán, M.G.; Rico-Hidalgo, M.P.; Manallack, D.T.; Medina-Franco, J.L. The acid/base profile of a large food chemical database. Mol. Inf. 2019, 38, e1800171. [Google Scholar] [CrossRef]
- Jia, C.Y.; Li, J.Y.; Hao, G.F.; Yang, G.F. A drug-likeness toolbox facilitates ADMET study in drug discovery. Drug Discov. Today 2020, 25, 248–258. [Google Scholar] [CrossRef] [PubMed]
- Schneckener, S.; Grimbs, S.; Hey, J.; Menz, S.; Osmers, M.; Schaper, S.; Hillisch, A.; Göller, A.H. Prediction of oral bioavailability in rats: Transferring insights from in vitro correlations to (deep) machine learning models using in silico model outputs and chemical structure parameters. J. Chem. Inf. Model. 2019, 59, 4893–4905. [Google Scholar] [CrossRef] [PubMed]
- Vo, A.H.; Van Vleet, T.R.; Gupta, R.R.; Liguori, M.J.; Rao, M.S. An overview of machine learning and big data for drug toxicity evaluation. Chem. Res. Toxicol. 2020, 33, 20–37. [Google Scholar] [CrossRef] [PubMed]
- González-Medina, M.; Naveja, J.J.; Sanchez-Cruz, N.; Medina-Franco, J.L. Open chemoinformatic resources to explore the structure, properties and chemical space of molecules. RSC Adv. 2017, 7, 54153–54163. [Google Scholar] [CrossRef]
- Ntie-Kang, F. An in silico evaluation of the ADMET profile of the StreptomeDB database. Springerplus 2013, 2, 353. [Google Scholar] [CrossRef] [PubMed]
- Pires, D.E.V.; Blundell, T.L.; Ascher, D.B. Pkcsm: Predicting small-molecule pharmacokinetic and toxicity properties using graph-based signatures. J. Med. Chem. 2015, 58, 4066–4072. [Google Scholar] [CrossRef] [PubMed]
- Lin, X.; Li, X.; Lin, X. A Review on applications of computational methods in drug screening and design. Molecules 2020, 25, 1375. [Google Scholar] [CrossRef]
- Speck-Planche, A.; Cordeiro, M.N.D. De novo computational design of compounds virtually displaying potent antibacterial activity and desirable in vitro ADMET profiles. Med. Chem. Res. 2017, 26, 2345–2356. [Google Scholar] [CrossRef]
- Speck-Planche, A.; Cordeiro, M.N.D.S. Chemoinformatics for medicinal chemistry: In silico model to enable the discovery of potent and safer anti-cocci agents. Future Med. Chem. 2014, 6, 2013–2028. [Google Scholar] [CrossRef]
- González-Medina, M.; Prieto-Martínez, F.D.; Medina-Franco, J.L. Consensus diversity plots: A global diversity analysis of chemical libraries. J. Cheminf. 2016, 8, 63. [Google Scholar] [CrossRef]
- Saldívar-González, F.I.; Lenci, E.; Calugi, L.; Medina-Franco, J.L.; Trabocchi, A. Computational-aided design of a library of lactams through a diversity-oriented synthesis strategy. Bioorg. Med. Chem. 2020, 28, 115539. [Google Scholar] [CrossRef] [PubMed]
- Virshup, A.M.; Contreras-García, J.; Wipf, P.; Yang, W.; Beratan, D.N. Stochastic voyages into uncharted chemical space produce a representative library of all possible drug-like compounds. J. Am. Chem. Soc. 2013, 135, 7296–7303. [Google Scholar] [CrossRef] [PubMed]
- Naveja, J.; Medina-Franco, J. Chemmaps: Towards an approach for visualizing the chemical space based on adaptive satellite compounds [version 2; peer review: 3 approved with reservations]. F1000Research 2017, 6, 1134. [Google Scholar] [CrossRef] [PubMed]
- Medina-Franco, J.L.; Martínez-Mayorga, K.; Giulianotti, M.A.; Houghten, R.A.; Pinilla, C. Visualization of the chemical space in drug discovery. Curr. Comput. Aided Drug Des. 2008, 4, 322–333. [Google Scholar] [CrossRef]
- Osolodkin, D.I.; Radchenko, E.V.; Orlov, A.A.; Voronkov, A.E.; Palyulin, V.A.; Zefirov, N.S. Progress in visual representations of chemical space. Exp. Opin. Drug Discov. 2015, 10, 959–973. [Google Scholar] [CrossRef]
- Meyers, J.; Carter, M.; Mok, N.Y.; Brown, N. On the origins of three-dimensionality in drug-like molecules. Future Med. Chem. 2016, 8, 1753–1767. [Google Scholar] [CrossRef]
- Probst, D.; Reymond, J.-L. Visualization of very large high-dimensional data sets as minimum spanning trees. J. Cheminf. 2020, 12, 12. [Google Scholar] [CrossRef]
- Saldívar-González, F.I.; Naveja, J.J.; Palomino-Hernández, O.; Medina-Franco, J.L. Getting smart in drug discovery: Chemoinformatics approaches for mining structure–multiple activity relationships. RSC Adv. 2017, 7, 632–641. [Google Scholar] [CrossRef]
- Medina-Franco, J.L.; Naveja, J.J.; López-López, E. Reaching for the bright StARs in chemical space. Drug Discov. Today 2019, 24, 2162–2169. [Google Scholar] [CrossRef]
- Saldívar-González, F.I.; Pilón-Jiménez, B.A.; Medina-Franco, J.L. Chemical space of naturally occurring compounds. Phys. Sci. Rev. 2018, 4, 20180103. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Goal and Approach | Reference |
|---|---|---|
| 454 NP from Panama. | Build and characterize the contents and diversity of a NP collection from Panama. Comparison with NP from other geographical regions. | [24,25] |
| 560 cyanobacteria metabolites (freshwater and marine). | Quantify the distribution of drug-like properties; measure the diversity using properties, molecular fingerprints, and molecular scaffolds. | [26] |
| 209,574 compounds from the Universal Natural Products Database and other NPs. | Comparative analysis of molecular complexity diversity based on physicochemical properties, molecular scaffolds and fingerprints. Comparison with drugs approved for clinical use. | [23,27] |
| 209,574 compounds from the Universal Natural Products Database, 423 molecules from BIOFACQUIM and other NPs. | Comparative analysis of the acid/based profile of NP from different sources. Comparison with drugs approved for clinical use and food chemicals. | [28] |
| 503 NPs from Mexico collected in the BIOFACQUIM database. | Diversity analysis based on different molecular representations and ADME/Tox profiling. | [29,30] |
| 578 compounds from honey bee and stingless bee propolis. | Analysis of chemical space, chemical diversity, and scaffold content. | [31] |
| 897 metabolites from the Seaweed Metabolite Database (SWMD). | Diversity analysis based on different molecular representations. | [32] |
| 1870 compounds from the Eastern Africa Natural Product Database (EANPDB). | Quantification of scaffold diversity and profiling of drug-likeness and ADME/Tox properties. | [19] |
| NPs from four NP data sets: phytochemica, SerpentinaDB, SANCDB, and NuBBEDB. | In silico profiling of ADME/Tox properties. | [33] |
| 6524 NPs originating from about 3300 producer streptomycetes strains | In addition to names and molecular structures of the compounds, information about source organisms, references, biological role, activities, synthesis routes, scaffolds, physicochemical properties, and predicted ADMET properties is included. | [34] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Medina-Franco, J.L.; Saldívar-González, F.I. Cheminformatics to Characterize Pharmacologically Active Natural Products. Biomolecules 2020, 10, 1566. https://doi.org/10.3390/biom10111566
Medina-Franco JL, Saldívar-González FI. Cheminformatics to Characterize Pharmacologically Active Natural Products. Biomolecules. 2020; 10(11):1566. https://doi.org/10.3390/biom10111566
Chicago/Turabian StyleMedina-Franco, José L., and Fernanda I. Saldívar-González. 2020. "Cheminformatics to Characterize Pharmacologically Active Natural Products" Biomolecules 10, no. 11: 1566. https://doi.org/10.3390/biom10111566
APA StyleMedina-Franco, J. L., & Saldívar-González, F. I. (2020). Cheminformatics to Characterize Pharmacologically Active Natural Products. Biomolecules, 10(11), 1566. https://doi.org/10.3390/biom10111566