
Hyperparameter Optimization of an hp-Greedy Reduced Basis for Gravitational Wave Surrogates

 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
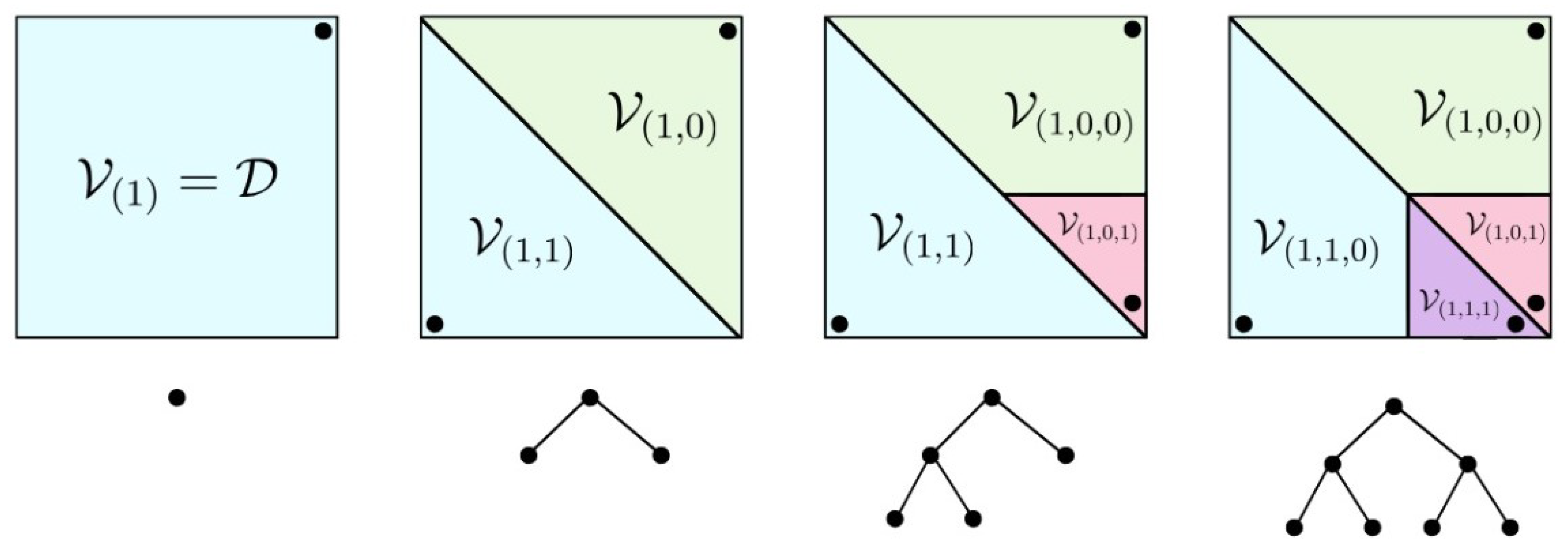
- The maximum depth of the resulting tree (briefly described in the next section), which limits the number of recursive partitions. As with any tree in ML, deeper trees lead to higher accuracies when training but, at the same time, they risk overfitting.
2. hp-Greedy Reduced Basis
3. Hyperparameter Optimization
3.1. Bayesian Optimization
3.2. Sequential Model-Based Optimization (SMBO)
| Algorithm 1: SMBO |
| input: , ,
|
3.3. Tree-Structured Parzen Estimator
- using “good” observations (); and
- using “bad” observations ().
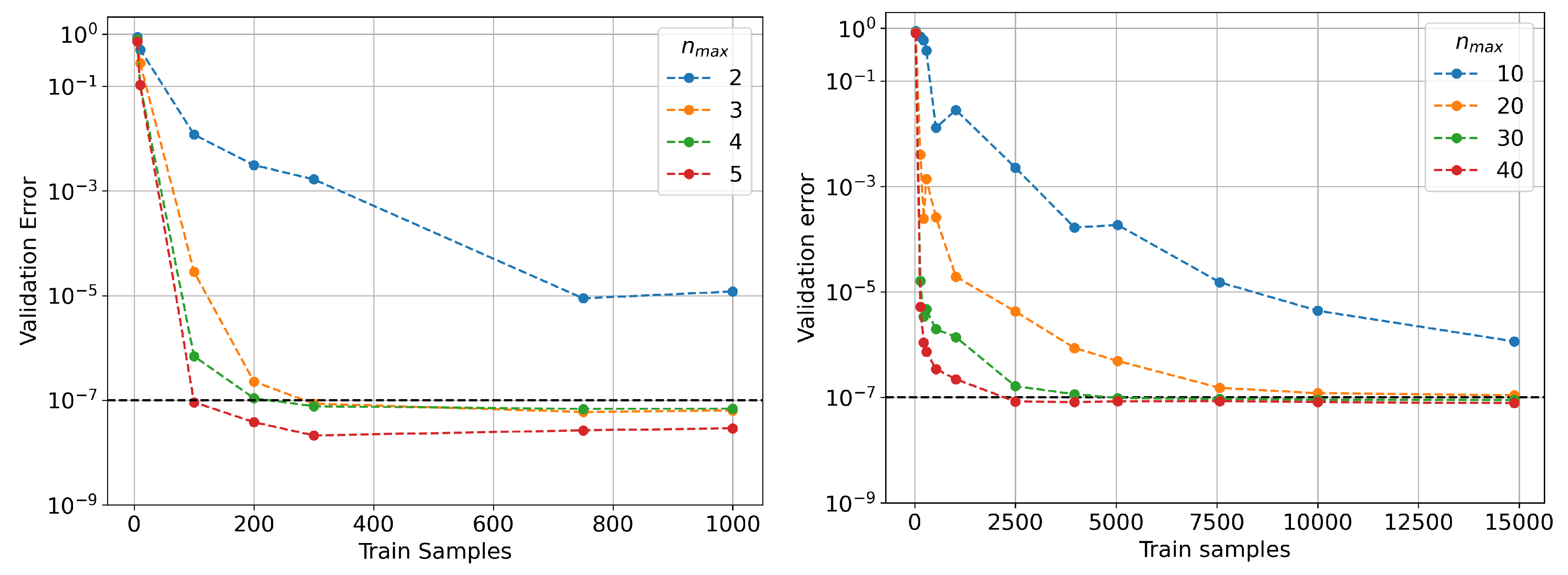
3.4. A Comparison between HPO, Grid, and Random Searches
4. Hyper-Optimized hp-Greedy Reduced Bases for Gravitational Waves
4.1. Physical Setup
- 1D Case: This scenario involves no spin, where the sole free parameter is the mass ratio, .
- 2D Case: Two spins aligned in the same direction and with equal magnitudes, , are added to the 1D scenario.
4.2. Optimization Methods Compared
- On the convergence speed of TPE compared to random search, and how consistent it is through multiple runs.
- On the time difference between grid search and one run of TPE.
4.3. Optimized hp-Greedy Reduced Bases versus Global Ones
5. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
| 1 | The hp-greedy approach, as well as the reduced basis, were originally introduced in the context of parameterized partial differential equations. |
| 2 | Which can be intuitively understood in that case being the greedy approach a global optimization algorithm. |
| 3 | Full details of the Serafín cluster at https://ccad.unc.edu.ar/equipamiento/cluster-serafin/, accessed on 12 October 2023. |
References
- Tiglio, M.; Villanueva, A. Reduced order and surrogate models for gravitational waves. Living Rev. Relativ. 2022, 25, 2. [Google Scholar] [CrossRef]
- Mandic, V.; Thrane, E.; Giampanis, S.; Regimbau, T. Parameter estimation in searches for the stochastic gravitational-wave background. Phys. Rev. Lett. 2012, 109, 171102. [Google Scholar] [CrossRef]
- Isi, M.; Chatziioannou, K.; Farr, W.M. Hierarchical test of general relativity with gravitational waves. Phys. Rev. Lett. 2019, 123, 121101. [Google Scholar] [CrossRef] [PubMed]
- Lange, J.; O’Shaughnessy, R.; Rizzo, M. Rapid and accurate parameter inference for coalescing, precessing compact binaries. arXiv 2018, arXiv:1805.10457. [Google Scholar]
- Lynch, R.; Vitale, S.; Essick, R.; Katsavounidis, E.; Robinet, F. Information-theoretic approach to the gravitational-wave burst detection problem. Phys. Rev. D 2017, 95, 104046. [Google Scholar] [CrossRef]
- Mandel, I.; Berry, C.P.; Ohme, F.; Fairhurst, S.; Farr, W.M. Parameter estimation on compact binary coalescences with abruptly terminating gravitational waveforms. Class. Quantum Gravity 2014, 31, 155005. [Google Scholar] [CrossRef]
- Mandel, I.; Farr, W.M.; Gair, J.R. Extracting distribution parameters from multiple uncertain observations with selection biases. Mon. Not. R. Astron. Soc. 2019, 486, 1086–1093. [Google Scholar] [CrossRef]
- Usman, S.A.; Mills, J.C.; Fairhurst, S. Constraining the inclinations of binary mergers from gravitational-wave observations. Astrophys. J. 2019, 877, 82. [Google Scholar] [CrossRef]
- Van Der Sluys, M.; Mandel, I.; Raymond, V.; Kalogera, V.; Röver, C.; Christensen, N. Parameter estimation for signals from compact binary inspirals injected into LIGO data. Class. Quantum Gravity 2009, 26, 204010. [Google Scholar] [CrossRef]
- Fishbach, M.; Essick, R.; Holz, D.E. Does Matter Matter? Using the mass distribution to distinguish neutron stars and black holes. Astrophys. J. Lett. 2020, 899, L8. [Google Scholar] [CrossRef]
- Cornish, N.J. Rapid and robust parameter inference for binary mergers. Phys. Rev. D 2021, 103, 104057. [Google Scholar] [CrossRef]
- Berry, C.P.; Mandel, I.; Middleton, H.; Singer, L.P.; Urban, A.L.; Vecchio, A.; Vitale, S.; Cannon, K.; Farr, B.; Farr, W.M.; et al. Parameter estimation for binary neutron-star coalescences with realistic noise during the Advanced LIGO era. Astrophys. J. 2015, 804, 114. [Google Scholar] [CrossRef]
- Biscoveanu, S.; Haster, C.J.; Vitale, S.; Davies, J. Quantifying the effect of power spectral density uncertainty on gravitational-wave parameter estimation for compact binary sources. Phys. Rev. D 2020, 102, 023008. [Google Scholar] [CrossRef]
- Bizouard, M.A.; Maturana-Russel, P.; Torres-Forné, A.; Obergaulinger, M.; Cerdá-Durán, P.; Christensen, N.; Font, J.A.; Meyer, R. Inference of protoneutron star properties from gravitational-wave data in core-collapse supernovae. Phys. Rev. D 2021, 103, 063006. [Google Scholar] [CrossRef]
- Banagiri, S.; Coughlin, M.W.; Clark, J.; Lasky, P.D.; Bizouard, M.A.; Talbot, C.; Thrane, E.; Mandic, V. Constraining the gravitational-wave afterglow from a binary neutron star coalescence. Mon. Not. R. Astron. Soc. 2020, 492, 4945–4951. [Google Scholar] [CrossRef]
- Coughlin, M.W.; Dietrich, T.; Margalit, B.; Metzger, B.D. Multimessenger Bayesian parameter inference of a binary neutron star merger. Mon. Not. R. Astron. Soc. Lett. 2019, 489, L91–L96. [Google Scholar] [CrossRef]
- Wysocki, D.; Lange, J.; O’Shaughnessy, R. Reconstructing phenomenological distributions of compact binaries via gravitational wave observations. Phys. Rev. D 2019, 100, 043012. [Google Scholar] [CrossRef]
- Christensen, N.; Meyer, R. Parameter estimation with gravitational waves. Rev. Mod. Phys. 2022, 94, 025001. [Google Scholar] [CrossRef]
- Jaranowski, P.; Królak, A. Gravitational-wave data analysis. Formalism and sample applications: The Gaussian case. Living Rev. Relativ. 2012, 15, 1–47. [Google Scholar] [CrossRef]
- Smith, R.; Borhanian, S.; Sathyaprakash, B.; Vivanco, F.H.; Field, S.E.; Lasky, P.; Mandel, I.; Morisaki, S.; Ottaway, D.; Slagmolen, B.J.; et al. Bayesian inference for gravitational waves from binary neutron star mergers in third generation observatories. Phys. Rev. Lett. 2021, 127, 081102. [Google Scholar] [CrossRef]
- Breschi, M.; Gamba, R.; Bernuzzi, S. Bayesian inference of multimessenger astrophysical data: Methods and applications to gravitational waves. Phys. Rev. D 2021, 104, 042001. [Google Scholar] [CrossRef]
- Chua, A.J.; Vallisneri, M. Learning Bayesian posteriors with neural networks for gravitational-wave inference. Phys. Rev. Lett. 2020, 124, 041102. [Google Scholar] [CrossRef] [PubMed]
- Meyer, R.; Edwards, M.C.; Maturana-Russel, P.; Christensen, N. Computational techniques for parameter estimation of gravitational wave signals. Wiley Interdiscip. Rev. Comput. Stat. 2022, 14, e1532. [Google Scholar] [CrossRef]
- Edwards, M.C.; Meyer, R.; Christensen, N. Bayesian parameter estimation of core collapse supernovae using gravitational wave simulations. Inverse Probl. 2014, 30, 114008. [Google Scholar] [CrossRef][Green Version]
- Dupuis, R.J.; Woan, G. Bayesian estimation of pulsar parameters from gravitational wave data. Phys. Rev. D 2005, 72, 102002. [Google Scholar] [CrossRef]
- Talbot, C.; Smith, R.; Thrane, E.; Poole, G.B. Parallelized inference for gravitational-wave astronomy. Phys. Rev. D 2019, 100, 043030. [Google Scholar] [CrossRef]
- Veitch, J.; Raymond, V.; Farr, B.; Farr, W.; Graff, P.; Vitale, S.; Aylott, B.; Blackburn, K.; Christensen, N.; Coughlin, M.; et al. Parameter estimation for compact binaries with ground-based gravitational-wave observations using the LALInference software library. Phys. Rev. D 2015, 91, 042003. [Google Scholar] [CrossRef]
- Biwer, C.M.; Capano, C.D.; De, S.; Cabero, M.; Brown, D.A.; Nitz, A.H.; Raymond, V. PyCBC Inference: A Python-based parameter estimation toolkit for compact binary coalescence signals. Publ. Astron. Soc. Pac. 2019, 131, 024503. [Google Scholar] [CrossRef]
- Ashton, G.; Hübner, M.; Lasky, P.D.; Talbot, C.; Ackley, K.; Biscoveanu, S.; Chu, Q.; Divakarla, A.; Easter, P.J.; Goncharov, B.; et al. BILBY: A user-friendly Bayesian inference library for gravitational-wave astronomy. Astrophys. J. Suppl. Ser. 2019, 241, 27. [Google Scholar] [CrossRef]
- Romero-Shaw, I.M.; Talbot, C.; Biscoveanu, S.; D’emilio, V.; Ashton, G.; Berry, C.; Coughlin, S.; Galaudage, S.; Hoy, C.; Hübner, M.; et al. Bayesian inference for compact binary coalescences with bilby: Validation and application to the first LIGO–Virgo gravitational-wave transient catalogue. Mon. Not. R. Astron. Soc. 2020, 499, 3295–3319. [Google Scholar] [CrossRef]
- Smith, R.J.; Ashton, G.; Vajpeyi, A.; Talbot, C. Massively parallel Bayesian inference for transient gravitational-wave astronomy. Mon. Not. R. Astron. Soc. 2020, 498, 4492–4502. [Google Scholar] [CrossRef]
- Wofford, J.; Yelikar, A.; Gallagher, H.; Champion, E.; Wysocki, D.; Delfavero, V.; Lange, J.; Rose, C.; Valsan, V.; Morisaki, S.; et al. Expanding RIFT: Improving performance for GW parameter inference. arXiv 2022, arXiv:2210.07912. [Google Scholar]
- Dax, M.; Green, S.R.; Gair, J.; Macke, J.H.; Buonanno, A.; Schölkopf, B. Real-time gravitational wave science with neural posterior estimation. Phys. Rev. Lett. 2021, 127, 241103. [Google Scholar] [CrossRef]
- Antil, H.; Field, S.E.; Herrmann, F.; Nochetto, R.H.; Tiglio, M. Two-Step Greedy Algorithm for Reduced Order Quadratures. J. Sci. Comput. 2013, 57, 604–637. [Google Scholar] [CrossRef]
- Canizares, P.; Field, S.E.; Gair, J.R.; Tiglio, M. Gravitational wave parameter estimation with compressed likelihood evaluations. Phys. Rev. D 2013, D87, 124005. [Google Scholar] [CrossRef]
- Canizares, P.; Field, S.E.; Gair, J.; Raymond, V.; Smith, R.; Tiglio, M. Accelerated gravitational wave parameter estimation with reduced order modeling. Phys. Rev. Lett. 2015, 114, 071104. [Google Scholar] [CrossRef]
- Barrault, M.; Maday, Y.; Nguyen, N.C.; Patera, A.T. An ‘empirical interpolation’method: Application to efficient reduced-basis discretization of partial differential equations. Comptes Rendus Math. 2004, 339, 667–672. [Google Scholar] [CrossRef]
- Gabbard, H.; Messenger, C.; Heng, I.S.; Tonolini, F.; Murray-Smith, R. Bayesian parameter estimation using conditional variational autoencoders for gravitational-wave astronomy. arXiv 2019, arXiv:1909.06296. [Google Scholar] [CrossRef]
- Green, S.; Gair, J. Complete parameter inference for GW150914 using deep learning. arXiv 2020, arXiv:2008.03312. [Google Scholar] [CrossRef]
- Green, S.R.; Simpson, C.; Gair, J. Gravitational-wave parameter estimation with autoregressive neural network flows. Phys. Rev. D 2020, 102, 104057. [Google Scholar] [CrossRef]
- George, D.; Huerta, E. Deep learning for real-time gravitational wave detection and parameter estimation with LIGO data. arXiv 2017, arXiv:1711.07966. [Google Scholar] [CrossRef]
- Álvares, J.D.; Font, J.A.; Freitas, F.F.; Freitas, O.G.; Morais, A.P.; Nunes, S.; Onofre, A.; Torres-Forné, A. Exploring gravitational-wave detection and parameter inference using deep learning methods. Class. Quantum Gravity 2021, 38, 155010. [Google Scholar] [CrossRef]
- Shen, H.; Huerta, E.; O’Shea, E.; Kumar, P.; Zhao, Z. Statistically-informed deep learning for gravitational wave parameter estimation. Mach. Learn. Sci. Technol. 2021, 3, 015007. [Google Scholar] [CrossRef]
- Morisaki, S.; Raymond, V. Rapid Parameter Estimation of Gravitational Waves from Binary Neutron Star Coalescence using Focused Reduced Order Quadrature. Phys. Rev. D 2020, 102, 104020. [Google Scholar] [CrossRef]
- Cerino, F.; Diaz-Pace, J.A.; Tiglio, M. An automated parameter domain decomposition approach for gravitational wave surrogates using hp-greedy refinement. Class. Quant. Grav. 2023, 40, 205003. [Google Scholar] [CrossRef]
- Eftang, J.L. Reduced Basis Methods for Parametrized Partial Differential Equations; Norwegian University of Science and Technology: Trondheim, Norway, 2011. [Google Scholar]
- Caudill, S.; Field, S.E.; Galley, C.R.; Herrmann, F.; Tiglio, M. Reduced Basis representations of multi-mode black hole ringdown gravitational waves. Class. Quant. Grav. 2012, 29, 095016. [Google Scholar] [CrossRef][Green Version]
- Bergstra, J.; Bardenet, R.; Bengio, Y.; Kégl, B. Algorithms for Hyper-Parameter Optimization. In Advances in Neural Information Processing Systems; Shawe-Taylor, J., Zemel, R., Bartlett, P., Pereira, F., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2011; Volume 24. [Google Scholar]
- Akiba, T.; Sano, S.; Yanase, T.; Ohta, T.; Koyama, M. Optuna: A Next-generation Hyperparameter Optimization Framework. In Proceedings of the 25rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Binev, P.; Cohen, A.; Dahmen, W.; DeVore, R.A.; Petrova, G.; Wojtaszczyk, P. Convergence Rates for Greedy Algorithms in Reduced Basis Methods. SIAM J. Math. Anal. 2011, 43, 1457–1472. [Google Scholar] [CrossRef]
- DeVore, R.; Petrova, G.; Wojtaszczyk, P. Greedy Algorithms for Reduced Bases in Banach Spaces. Constr. Approx. 2013, 37, 455–466. [Google Scholar] [CrossRef]
- Karniadakis, G.; Sherwin, S.J. Spectral/hp Element Methods for Computational Fluid Dynamics, 2nd ed.; Oxford University Press: Oxford, UK, 2005. [Google Scholar] [CrossRef]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; de Freitas, N. Taking the Human Out of the Loop: A Review of Bayesian Optimization. Proc. IEEE 2016, 104, 148–175. [Google Scholar] [CrossRef]
- Brochu, E.; Cora, V.M.; de Freitas, N. A Tutorial on Bayesian Optimization of Expensive Cost Functions, with Application to Active User Modeling and Hierarchical Reinforcement Learning. arXiv 2010, arXiv:1012.2599. [Google Scholar] [CrossRef]
- Dewancker, I.; McCourt, M.; Clark, S. Bayesian Optimization Primer; SigOpt: San Francisco, CA, USA, 2015. [Google Scholar]
- Feurer, M.; Hutter, F. Hyperparameter Optimization. In Automated Machine Learning: Methods, Systems, Challenges; Hutter, F., Kotthoff, L., Vanschoren, J., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 3–33. [Google Scholar] [CrossRef]
- Jones, D. A Taxonomy of Global Optimization Methods Based on Response Surfaces. J. Glob. Optim. 2001, 21, 345–383. [Google Scholar] [CrossRef]
- Parzen, E. On Estimation of a Probability Density Function and Mode. Ann. Math. Stat. 1962, 33, 1065–1076. [Google Scholar] [CrossRef]
- Ozaki, Y.; Tanigaki, Y.; Watanabe, S.; Nomura, M.; Onishi, M. Multiobjective Tree-Structured Parzen Estimator. J. Artif. Int. Res. 2022, 73, 1209–1250. [Google Scholar] [CrossRef]
- Varma, V.; Field, S.E.; Scheel, M.A.; Blackman, J.; Kidder, L.E.; Pfeiffer, H.P. Surrogate model of hybridized numerical relativity binary black hole waveforms. Phys. Rev. D 2019, 99, 064045. [Google Scholar] [CrossRef]
- Villegas, A. hp-Greedy Bayesian Optimization. 2023. Available online: https://github.com/atuel96/hp-greedy-bayesian-optimization (accessed on 23 October 2023).
- Cerino, F. Scikit-ReducedModel. 2022. Available online: https://github.com/francocerino/scikit-reducedmodel (accessed on 12 October 2023).
- Morisaki, S.; Smith, R.; Tsukada, L.; Sachdev, S.; Stevenson, S.; Talbot, C.; Zimmerman, A. Rapid localization and inference on compact binary coalescences with the Advanced LIGO-Virgo-KAGRA gravitational-wave detector network. arXiv 2023, arXiv:2307.13380. [Google Scholar]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cerino, F.; Diaz-Pace, J.A.; Tassone, E.A.; Tiglio, M.; Villegas, A. Hyperparameter Optimization of an hp-Greedy Reduced Basis for Gravitational Wave Surrogates. Universe 2024, 10, 6. https://doi.org/10.3390/universe10010006
Cerino F, Diaz-Pace JA, Tassone EA, Tiglio M, Villegas A. Hyperparameter Optimization of an hp-Greedy Reduced Basis for Gravitational Wave Surrogates. Universe. 2024; 10(1):6. https://doi.org/10.3390/universe10010006
Chicago/Turabian StyleCerino, Franco, J. Andrés Diaz-Pace, Emmanuel A. Tassone, Manuel Tiglio, and Atuel Villegas. 2024. "Hyperparameter Optimization of an hp-Greedy Reduced Basis for Gravitational Wave Surrogates" Universe 10, no. 1: 6. https://doi.org/10.3390/universe10010006
APA StyleCerino, F., Diaz-Pace, J. A., Tassone, E. A., Tiglio, M., & Villegas, A. (2024). Hyperparameter Optimization of an hp-Greedy Reduced Basis for Gravitational Wave Surrogates. Universe, 10(1), 6. https://doi.org/10.3390/universe10010006