
Metabolic Profiling Early Post-Allogeneic Haematopoietic Cell Transplantation in the Context of CMV Infection
 ,
,  , , , , , , ,
, , , , , , ,
Abstract
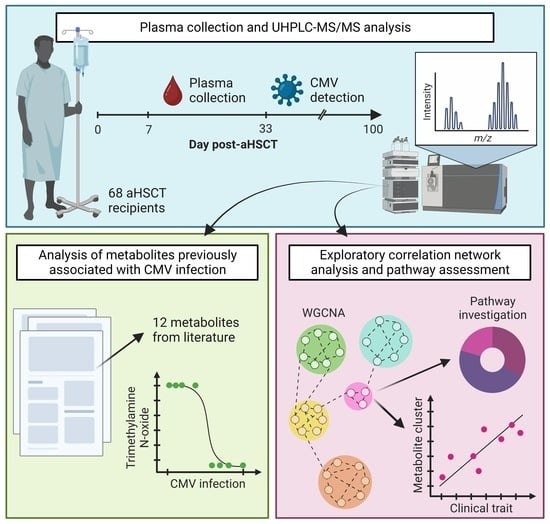
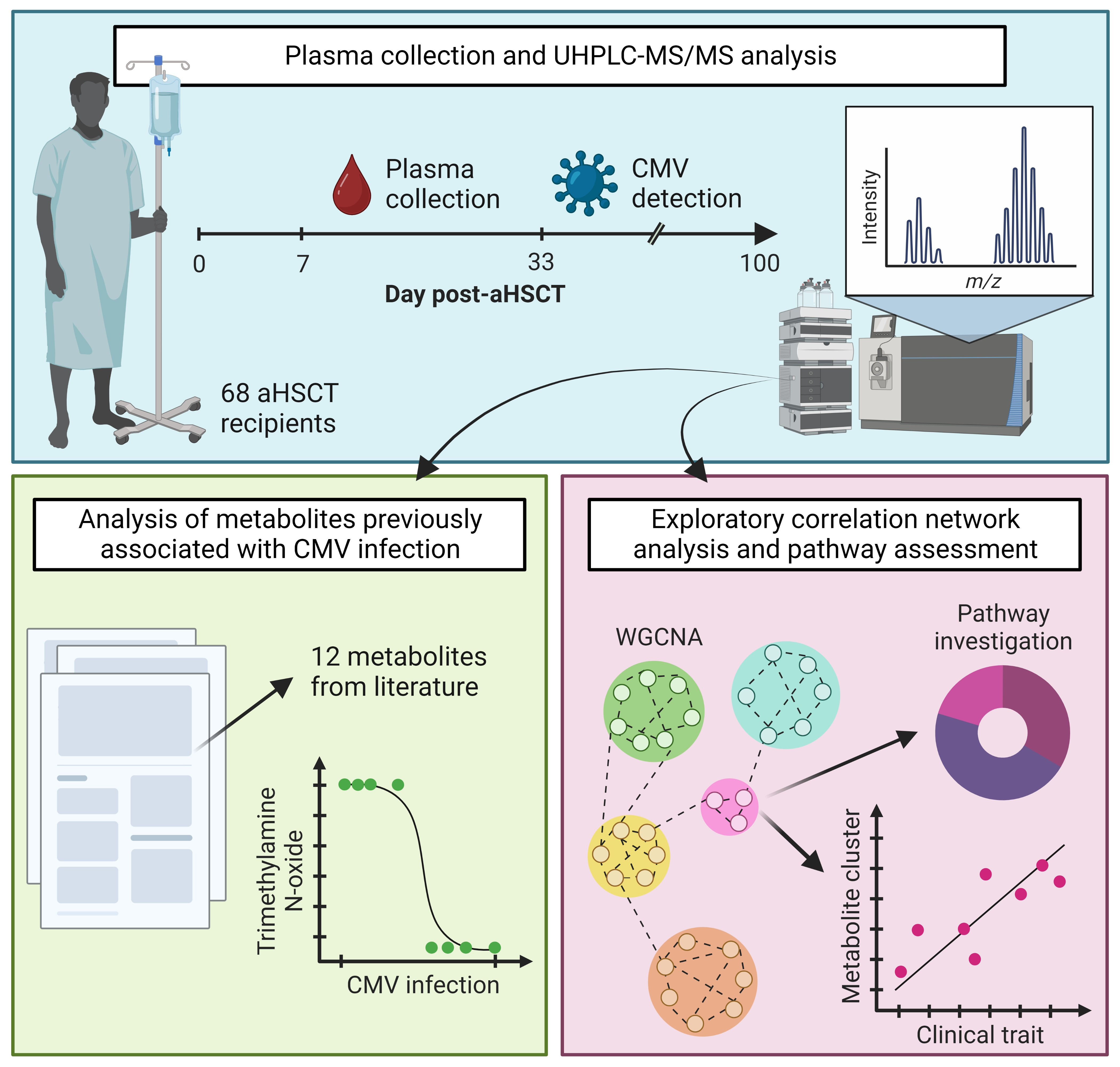
:
1. Introduction
2. Materials and Methods
2.1. Patient and Sample Selection
2.2. Sample Selection
2.3. Clinical Data
2.4. Conditioning Regimens
2.5. CMV Monitoring and Treatment
2.6. Metabolomics and Lipidomics Analysis
2.7. Pre-Processing of Metabolomics and Lipidomics Data
2.8. Statistical Analysis
2.9. Pathway-Resolved Correlation Network Analysis
2.10. Software
3. Results
3.1. aHSCT Patient Cohort
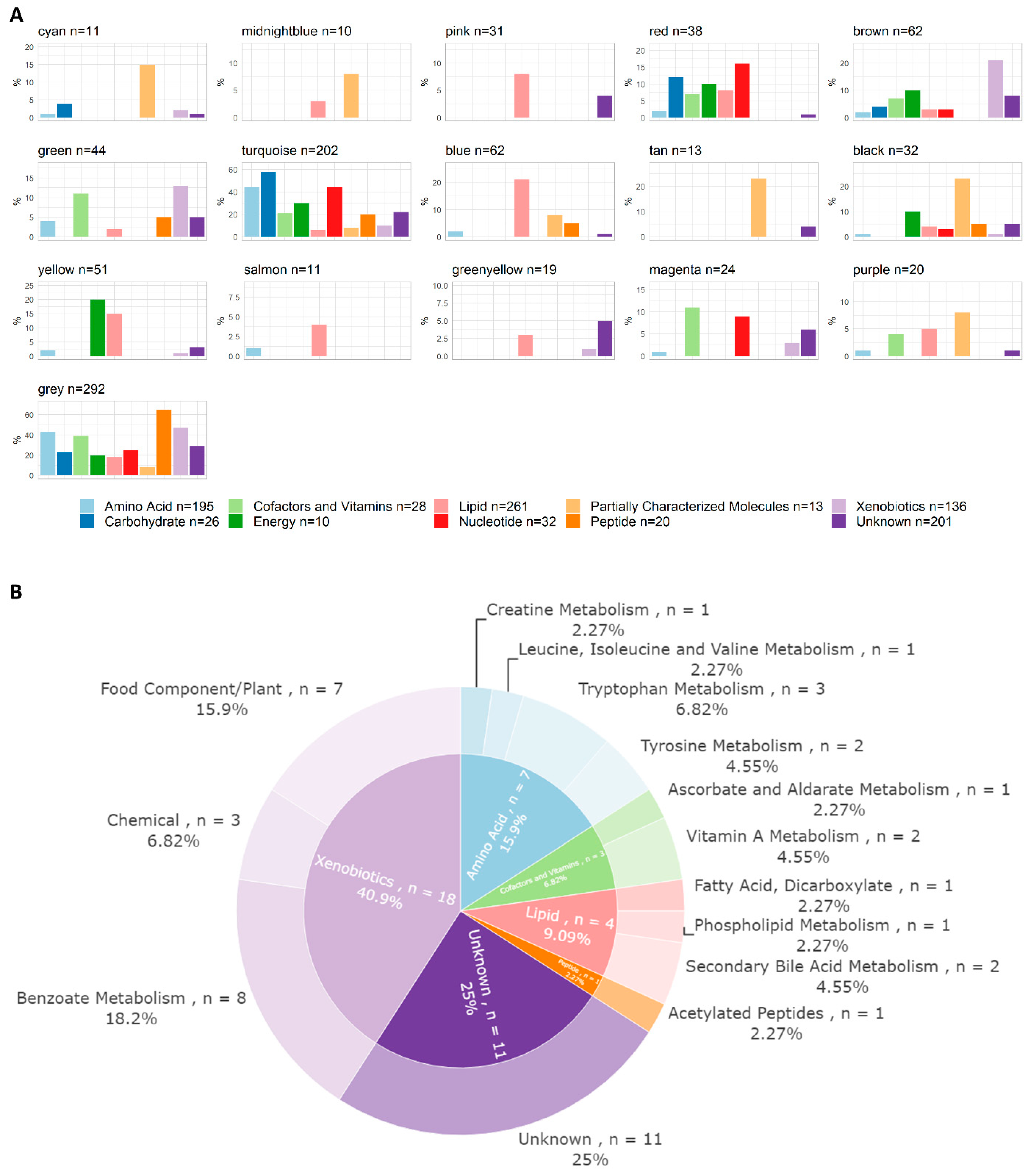
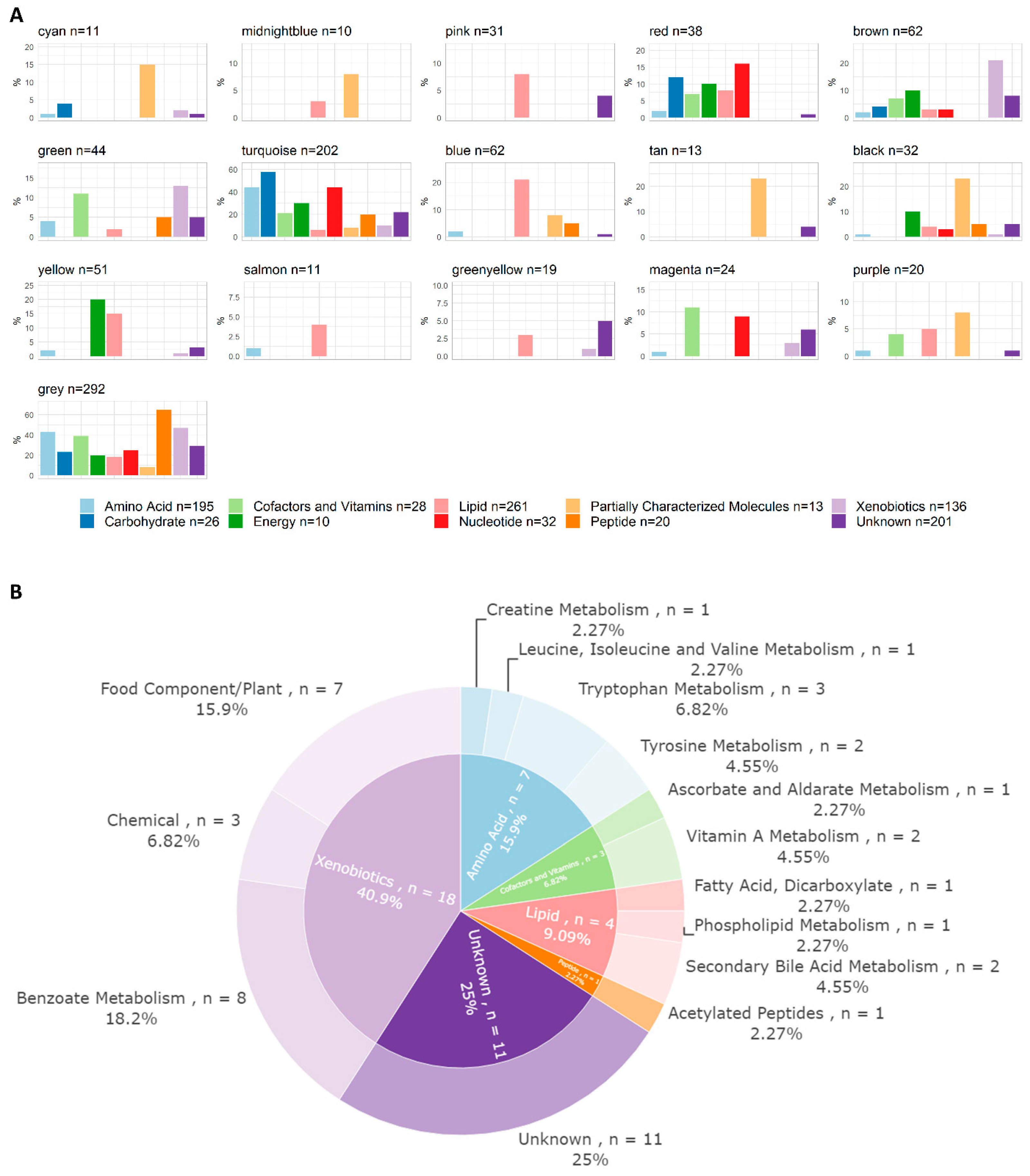
3.2. Metabolomics and Lipidomics Data
3.3. Single-Marker Associations with CMV Infection
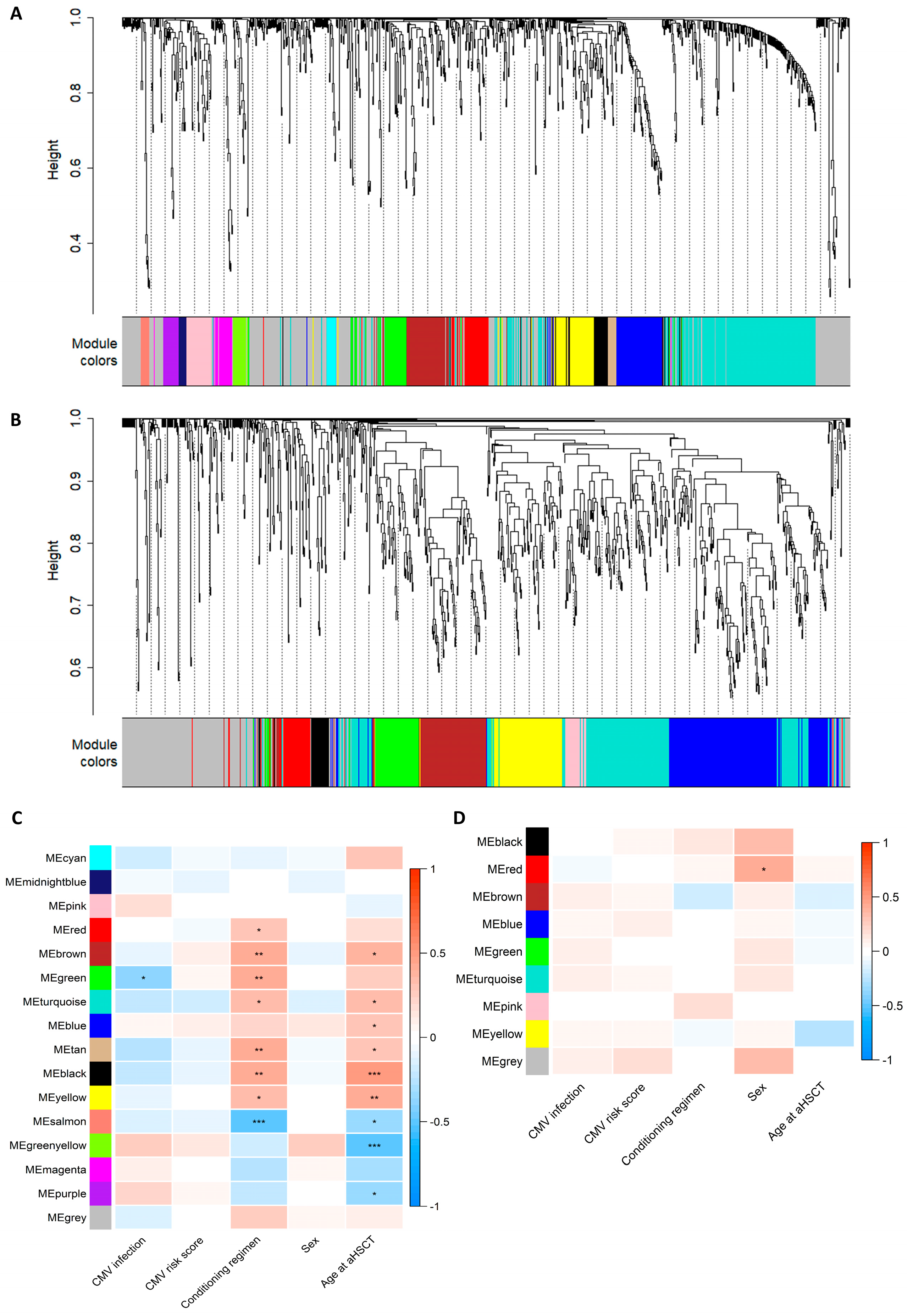
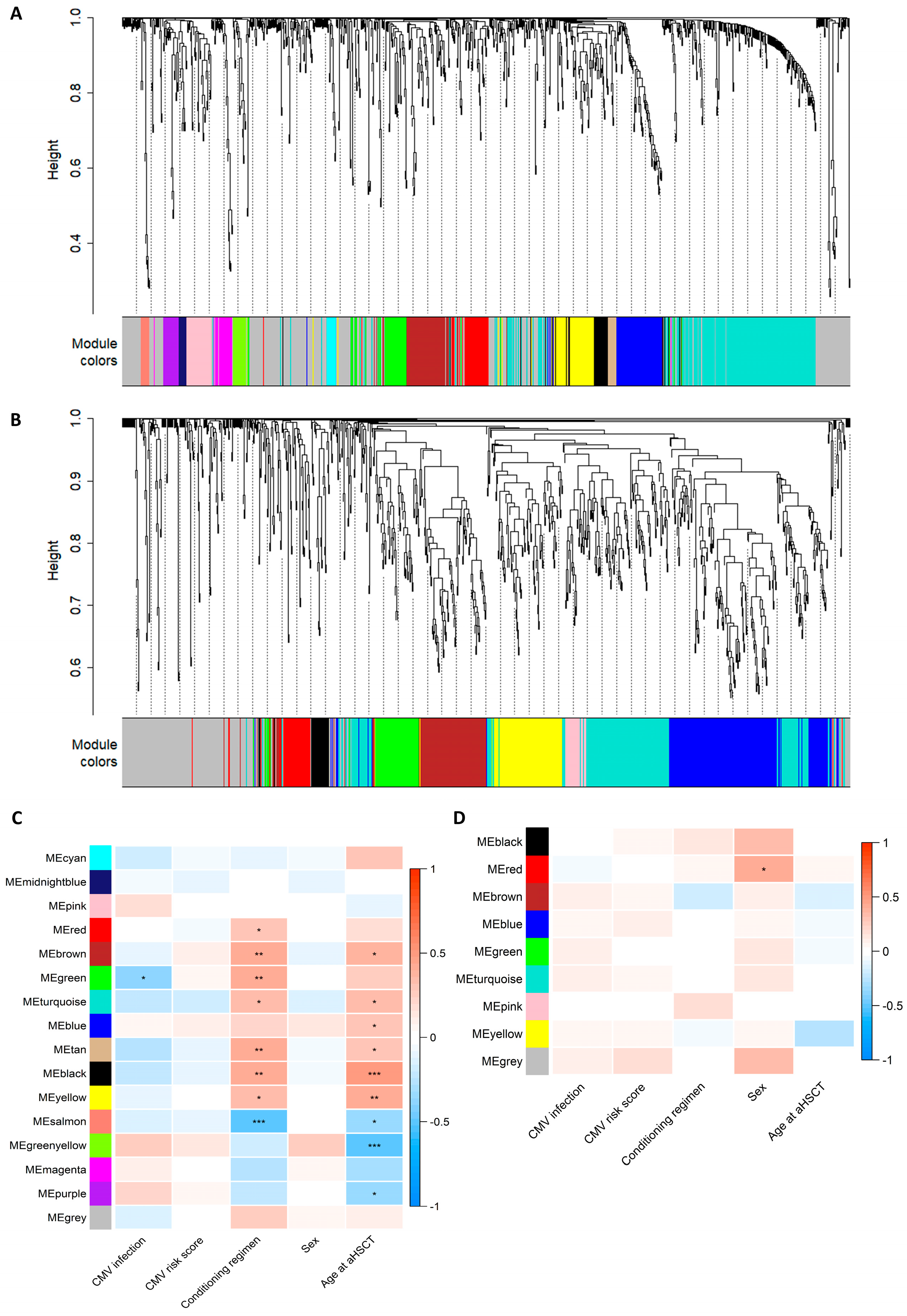
3.4. WGCNA Module Associations with Clinical Traits
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Giralt, S.; Bishop, M.R. Principles and Overview of Allogeneic Hematopoietic Stem Cell Transplantation. In Cancer Treatment and Research; Springer: Boston, MA, USA, 2009; Volume 144, pp. 1–21. [Google Scholar] [CrossRef]
- Poon, M.L.; Champlin, R.E. Principles of Hematopoietic Stem Cell Transplantation. In Principles and Practice of Transplant Infectious Diseases; Springer: Berlin/Heidelberg, Germany, 2019; pp. 153–163. ISBN 9781493990344. [Google Scholar]
- Da Cunha-Bang, C.; Sørensen, S.S.; Iversen, M.; Sengeløv, H.; Hillingsø, J.G.; Rasmussen, A.; Mortensen, S.A.; Fox, Z.V.; Kirkby, N.S.; Christiansen, C.B.; et al. Factors Associated with the Development of Cytomegalovirus Infection Following Solid Organ Transplantation. Scand. J. Infect. Dis. 2011, 43, 360–365. [Google Scholar] [CrossRef] [PubMed]
- Bhat, V. Cytomegalovirus Infection in the Bone Marrow Transplant Patient. World J. Transplant. 2015, 5, 287. [Google Scholar] [CrossRef] [PubMed]
- Ljungman, P.; Hakki, M.; Boeckh, M. Cytomegalovirus in Hematopoietic Stem Cell Transplant Recipients. Hematol. Oncol. Clin. N. Am. 2011, 25, 151–169. [Google Scholar] [CrossRef] [PubMed]
- Kumar, D.; Selzner, N. Cytomegalovirus: The “Troll of Transplantation” Is Now the “Troll of Tolerance”. Transplantation 2020, 104, 238–239. [Google Scholar] [CrossRef]
- Camargo, J.F. Cytomegalovirus in Hematopoietic Stem Cell Transplant Recipients: Prevention, Diagnosis, and Treatment. In Emerging Transplant Infections; Springer International Publishing: Cham, Switzerland, 2020; pp. 1–44. [Google Scholar]
- Cho, S.Y.; Lee, D.G.; Kim, H.J. Cytomegalovirus Infections after Hematopoietic Stem Cell Transplantation: Current Status and Future Immunotherapy. Int. J. Mol. Sci. 2019, 20, 2666. [Google Scholar] [CrossRef]
- Ljungman, P.; Boeckh, M.; Hirsch, H.H.; Josephson, F.; Lundgren, J.; Nichols, G.; Pikis, A.; Razonable, R.R.; Miller, V.; Griffiths, P.D. Definitions of Cytomegalovirus Infection and Disease in Transplant Patients for Use in Clinical Trials. Clin. Infect. Dis. 2017, 64, 87–91. [Google Scholar] [CrossRef]
- Valle-Arroyo, J.; Aguado, R.; Páez-Vega, A.; Pérez, A.B.; González, R.; Fornés, G.; Torre-Cisneros, J.; Cantisán, S. Lack of Cytomegalovirus (CMV)-Specific Cell-Mediated Immune Response Using QuantiFERON-CMV Assay in CMV-Seropositive Healthy Volunteers: Fact Not Artifact. Sci. Rep. 2020, 10, 7194. [Google Scholar] [CrossRef]
- Clish, C.B. Metabolomics: An Emerging but Powerful Tool for Precision Medicine. Mol. Case Stud. 2015, 1, a000588. [Google Scholar] [CrossRef]
- Beger, R.D.; Dunn, W.; Schmidt, M.A.; Gross, S.S.; Kirwan, J.A.; Cascante, M.; Brennan, L.; Wishart, D.S.; Oresic, M.; Hankemeier, T.; et al. Metabolomics Enables Precision Medicine: “A White Paper, Community Perspective”. Metabolomics 2016, 12, 149. [Google Scholar] [CrossRef]
- Chambers, J.W.; Maguire, T.G.; Alwine, J.C. Glutamine Metabolism Is Essential for Human Cytomegalovirus Infection. J. Virol. 2010, 84, 1867–1873. [Google Scholar] [CrossRef]
- Sadeghi, M.; Lahdou, I.; Daniel, V.; Schnitzler, P.; Fusch, G.; Schefold, J.C.; Zeier, M.; Iancu, M.; Opelz, G.; Terness, P. Strong Association of Phenylalanine and Tryptophan Metabolites with Activated Cytomegalovirus Infection in Kidney Transplant Recipients. Hum. Immunol. 2012, 73, 186–192. [Google Scholar] [CrossRef]
- Monleón, D.; Giménez, E.; Muñoz-Cobo, B.; Morales, J.M.; Solano, C.; Amat, P.; Navarro, D. Plasma Metabolomics Profiling for the Prediction of Cytomegalovirus DNAemia and Analysis of Virus–Host Interaction in Allogeneic Stem Cell Transplant Recipients. J. Gen. Virol. 2015, 96, 3373–3381. [Google Scholar] [CrossRef]
- Ilett, E.E.; Helleberg, M.; Reekie, J.; Murray, D.D.; Wulff, S.M.; Khurana, M.P.; Mocroft, A.; Daugaard, G.; Perch, M.; Rasmussen, A.; et al. Open Forum Infectious Diseases Incidence Rates and Risk Factors of Clostridioides Difficile Infection in Solid Organ and Hematopoietic Stem Cell Transplant Recipients; Oxford University Press: Oxford, UK, 2019. [Google Scholar] [CrossRef]
- Lodding, I.P.; Da Cunha Bang, C.; Sørensen, S.S.; Gustafsson, F.; Iversen, M.; Kirkby, N.; Perch, M.; Rasmussen, A.; Sengeløv, H.; Mocroft, A.; et al. Open Forum Infectious Diseases® Cytomegalovirus (CMV) Disease Despite Weekly Preemptive CMV Strategy for Recipients of Solid Organ and Hematopoietic Stem Cell Transplantation; Oxford University Press: Oxford, UK, 2018. [Google Scholar] [CrossRef]
- Gjærde, L.K.; Brooks, P.T.; Andersen, N.S.; Friis, L.S.; Kornblit, B.; Petersen, S.L.; Schjødt, I.; Nielsen, S.D.; Ostrowski, S.R.; Sengeløv, H. Functional Immune Reconstitution Early after Allogeneic Haematopoietic Cell Transplantation: A Comparison of Pre- and Post-Transplantation Cytokine Responses in Stimulated Whole Blood. Scand. J. Immunol. 2021, 94, e13042. [Google Scholar] [CrossRef]
- Ryals, J.; Lawton, K.; Stevens, D.; Milburn, M. Metabolon, Inc. Pharmacogenomics 2007, 8, 863–866. [Google Scholar] [CrossRef] [PubMed]
- Kuhn, M. Building Predictive Models in R Using the Caret Package. J. Stat. Softw. Artic. 2008, 28, 1–26. [Google Scholar] [CrossRef]
- Langfelder, P.; Horvath, S. WGCNA: An R Package for Weighted Correlation Network Analysis. BMC Bioinform. 2008, 9, 559. [Google Scholar] [CrossRef] [PubMed]
- Pedersen, H.K.; Forslund, S.K.; Gudmundsdottir, V.; Petersen, A.Ø.; Hildebrand, F.; Hyötyläinen, T.; Nielsen, T.; Hansen, T.; Bork, P.; Ehrlich, S.D.; et al. A Computational Framework to Integrate High-Throughput ‘-Omics’ Datasets for the Identification of Potential Mechanistic Links. Nat. Protoc. 2018, 13, 2781–2800. [Google Scholar] [CrossRef]
- Team, R.C. R: A Language and Environment for Statistical Computing 2020; R Foundation for Statistical Computing: Vienna, Austria, 2020. [Google Scholar]
- Velasquez, M.T.; Ramezani, A.; Manal, A.; Raj, D.S. Trimethylamine N-Oxide: The Good, the Bad and the Unknown. Toxins 2016, 8, 326. [Google Scholar] [CrossRef]
- Bordoni, L.; Sawicka, A.K.; Szarmach, A.; Winklewski, P.J.; Olek, R.A.; Gabbianelli, R. A Pilot Study on the Effects of L-Carnitine and Trimethylamine-N-Oxide on Platelet Mitochondrial DNA Methylation and CVD Biomarkers in Aged Women. Int. J. Mol. Sci. 2020, 21, 1047. [Google Scholar] [CrossRef]
- Green, R.; Lord, J.; Xu, J.; Maddock, J.; Kim, M.; Dobson, R.; Legido-Quigley, C.; Wong, A.; Richards, M.; Proitsi, P. Metabolic Correlates of Late Midlife Cognitive Outcomes: Findings from the 1946 British Birth Cohort. Brain Commun. 2022, 4, fcab291. [Google Scholar] [CrossRef]
- Da Silva, R.R.; Dorrestein, P.C.; Quinn, R.A. Illuminating the Dark Matter in Metabolomics. Proc. Natl. Acad. Sci. USA 2015, 112, 12549–12550. [Google Scholar] [CrossRef] [PubMed]
- Wishart, D.S.; Tzur, D.; Knox, C.; Eisner, R.; Guo, A.C.; Young, N.; Cheng, D.; Jewell, K.; Arndt, D.; Sawhney, S.; et al. HMDB: The Human Metabolome Database. Nucleic Acids Res. 2007, 35, D521–D526. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
| All (n = 68) | Cases (n = 34) | Controls (n = 34) | p-Value | |
|---|---|---|---|---|
| Male * | 46 (72) | 25 (74) | 25 (71) | 1 † |
| Age upon aHSCT | 56.5 (17, 73) | 55.5 (22, 70) | 59.5 (17, 73) | 0.84 ‡ |
| Sample collection in days post-aHSCT | 28 (8, 33) | 26.8 (14, 33) | 28 (8, 33) | 0.34 ‡ |
| CMV infection onset in days post-aHSCT | 48.5 (34, 90) | 48.5 (34, 90) | - | |
| Graft origin | 0.19 § | |||
| Bone marrow | 11 (16) | 8 (24) | 3 (9) | |
| Peripheral blood | 57 (84) | 26 (76) | 31 (91) | |
| Conditioning regimen * | 1 † | |||
| Myeloablative conditioning (MAC) | 28 (41) | 14 (41) | 14 (41) | |
| Non-myeloablative conditioning (Mini) | 40 (59) | 20 (59) | 20 (59) | |
| CMV risk score ** | 0.00067 § | |||
| Low | 19 (28) | 3 (9) | 16 (47) | |
| Intermediate | 21 (31) | 11 (32) | 10 (29) | |
| High | 28 (41.2) | 20 (58.8) | 8 (24) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rasmussen, K.K.; dos Santos, Q.; MacPherson, C.R.; Zucco, A.G.; Gjærde, L.K.; Ilett, E.E.; Lodding, I.; Helleberg, M.; Lundgren, J.D.; Nielsen, S.D.; et al. Metabolic Profiling Early Post-Allogeneic Haematopoietic Cell Transplantation in the Context of CMV Infection. Metabolites 2023, 13, 968. https://doi.org/10.3390/metabo13090968
Rasmussen KK, dos Santos Q, MacPherson CR, Zucco AG, Gjærde LK, Ilett EE, Lodding I, Helleberg M, Lundgren JD, Nielsen SD, et al. Metabolic Profiling Early Post-Allogeneic Haematopoietic Cell Transplantation in the Context of CMV Infection. Metabolites. 2023; 13(9):968. https://doi.org/10.3390/metabo13090968
Chicago/Turabian StyleRasmussen, Kirstine K., Quenia dos Santos, Cameron Ross MacPherson, Adrian G. Zucco, Lars Klingen Gjærde, Emma E. Ilett, Isabelle Lodding, Marie Helleberg, Jens D. Lundgren, Susanne D. Nielsen, and et al. 2023. "Metabolic Profiling Early Post-Allogeneic Haematopoietic Cell Transplantation in the Context of CMV Infection" Metabolites 13, no. 9: 968. https://doi.org/10.3390/metabo13090968
APA StyleRasmussen, K. K., dos Santos, Q., MacPherson, C. R., Zucco, A. G., Gjærde, L. K., Ilett, E. E., Lodding, I., Helleberg, M., Lundgren, J. D., Nielsen, S. D., Brix, S., Sengeløv, H., & Murray, D. D. (2023). Metabolic Profiling Early Post-Allogeneic Haematopoietic Cell Transplantation in the Context of CMV Infection. Metabolites, 13(9), 968. https://doi.org/10.3390/metabo13090968