Artificial Intelligence Modelling Framework for Financial Automated Advising in the Copper Market



Abstract
1. Introduction
2. Literature Review
2.1. Robo-Advisors
2.2. Copper Financial Market
2.3. AI in Forecasting Financial Markets
3. Methodology
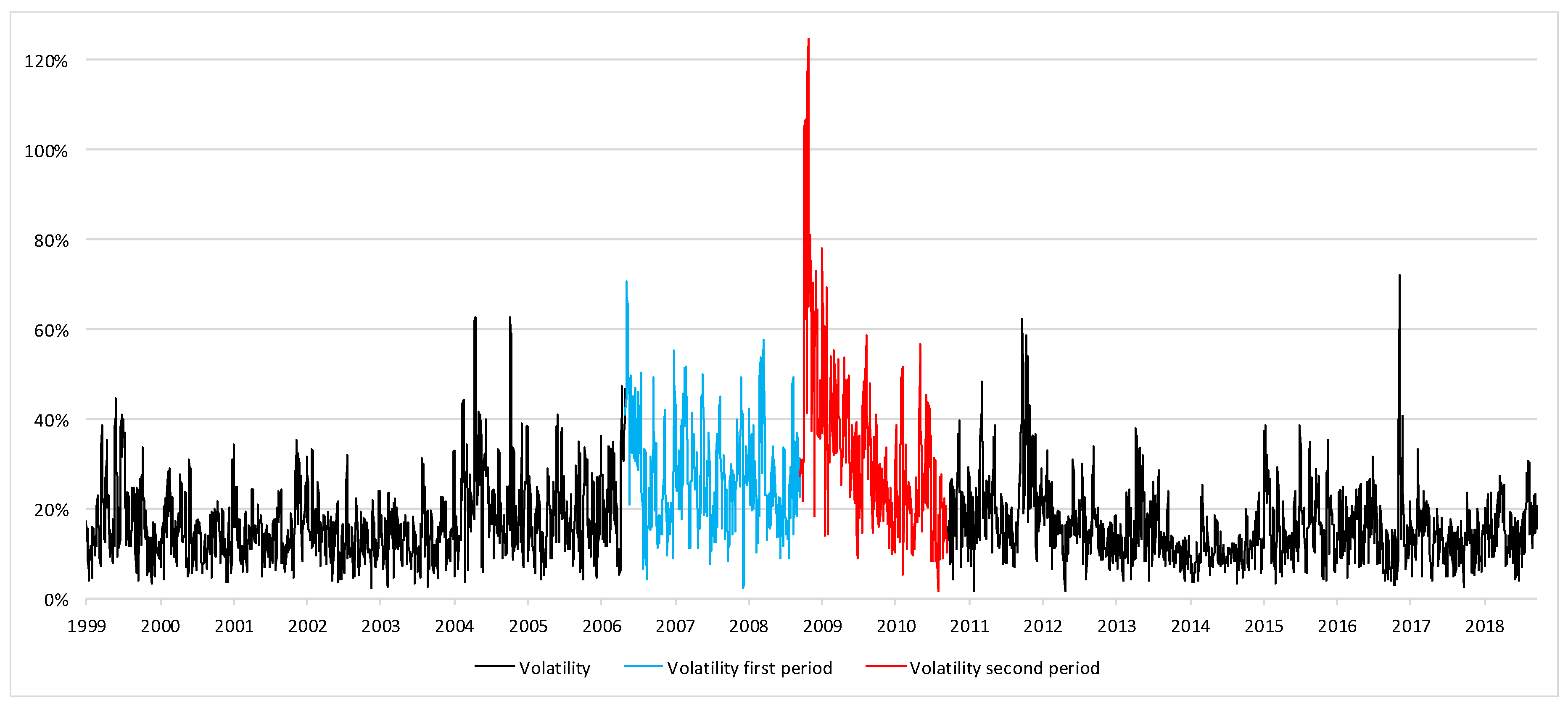
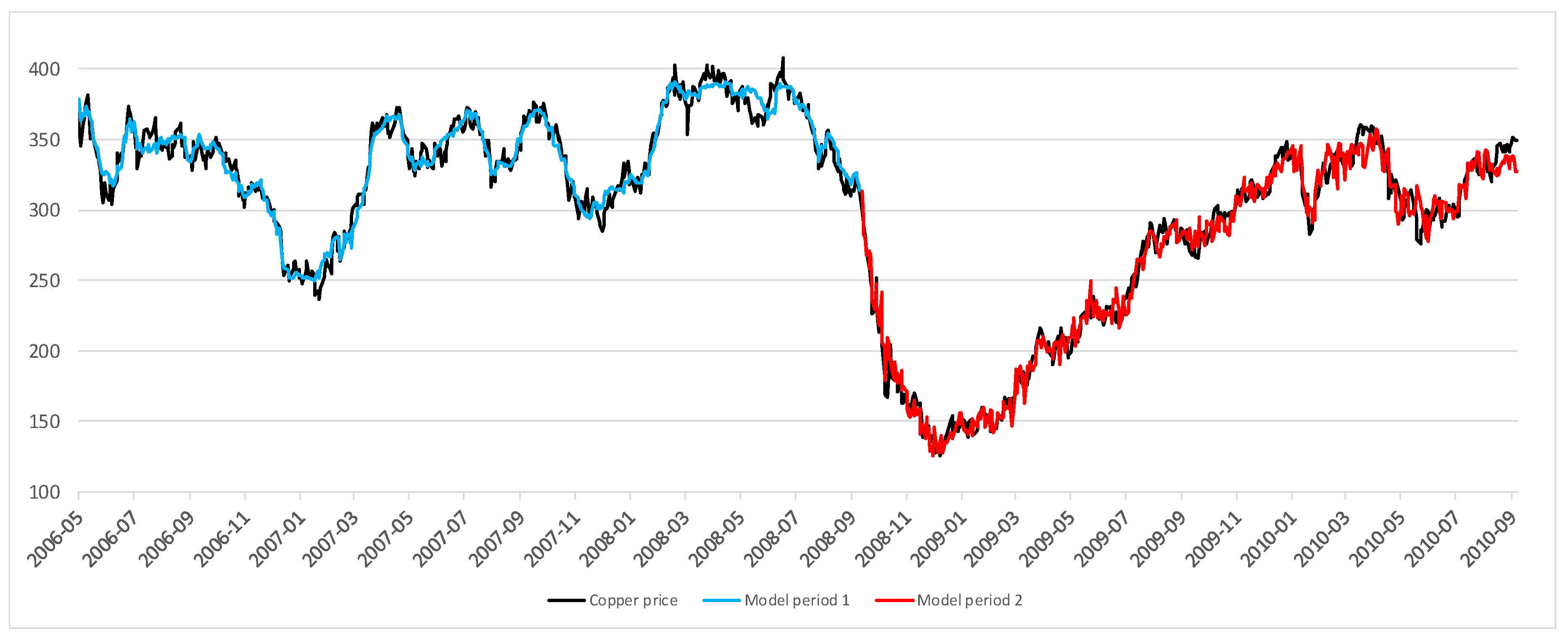
3.1. Data
3.2. Model
4. Discussion and Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Tani, M.; Papaluca, O.; Sasso, P. The System Thinking Perspective in the Open-Innovation Research: A Systematic Review. J. Open Innov. Technol. Mark. Complex. 2018, 4, 38. [Google Scholar] [CrossRef]
- Lee, J.; Suh, T.; Roy, D.; Baucus, M. Emerging Technology and Business Model Innovation: The Case of Artificial Intelligence. J. Open Innov. Technol. Mark. Complex. 2019, 5, 44. [Google Scholar] [CrossRef]
- Statista Robo-Advisors. Available online: https://www.statista.com/outlook/337/100/robo-advisors/worldwide (accessed on 23 February 2019).
- Faloon, M.; Scherer, B. Individualization of Robo-Advice. J. Wealth Manag. 2017, 20, 30–36. [Google Scholar] [CrossRef]
- Anderson, C. The Long Tail: Why the Future of Business is Selling More for Less; Hyperion: New York, NY, USA, 2006. [Google Scholar]
- Deloitte. The Expansion of Robo-Advisory in Wealth Management; Deloitte: Berlin, Germany, 2016. [Google Scholar]
- Fama, E.F. The Behavior of Stock-Market Prices. J. Bus. 1965, 38, 34–105. [Google Scholar] [CrossRef]
- Otto, S. A Speculative Efficiency Analysis of the London Metal Exchange in a Multi-Contract Framework. Int. J. Econ. Financ. 2011, 3, 3–16. [Google Scholar] [CrossRef]
- Kenourgios, D.; Samitas, A.G. Testing efficiency of the copper futures market: New evidence from London metal exchange. Glob. Bus. Econ. Rev. Anthology. 2004, pp, 261–271. [Google Scholar]
- Park, J.; Lim, B. Testing Efficiency of the London Metal Exchange: New Evidence. Int. J. Financ. Stud. 2018, 6, 32. [Google Scholar] [CrossRef]
- Cheng, I.-H.; Xiong, W. Financialization of commodity markets. Ann. Rev. Financ. Econ. 2014, 6, 419–441. [Google Scholar] [CrossRef]
- Gross, M. A semi-strong test of the efficiency of the aluminum and copper markets at the LME. J. Futur. Mark. 1988, 8, 67–77. [Google Scholar] [CrossRef]
- Tkáč, M.; Verner, R. Artificial neural networks in business: Two decades of research. Appl. Soft Comput. 2015, 38, 788–804. [Google Scholar] [CrossRef]
- Deutsche Bank Research. Robo-Advice—A True Innovation in Asset Management, EU Monitor Global Financial Markets; Deutsche Bank Research: Frankfurt, Germany, 2017. [Google Scholar]
- Sironi, P. FinTech Innovation: From Robo-Advisors to Goal Based Investing and Gamification; John Wiley & Sons: Chichester, West Sussex, UK, 2016; ISBN 9781119226987. [Google Scholar]
- Jung, D.; Dorner, V.; Glaser, F.; Morana, S.-F. Robo-Advisory: Digitalization and Automation of Financial Advisory. Bus. Inf. Syst. Eng. 2018, 60, 81–86. [Google Scholar] [CrossRef]
- Laboissiere, L.A.; Fernandes, R.A.S.; Lage, G.G. Maximum and minimum stock price forecasting of Brazilian power distribution companies based on artificial neural networks. Appl. Soft Comput. J. 2015, 35, 66–74. [Google Scholar] [CrossRef]
- Zahedi, J.; Rounaghi, M.M. Application of artificial neural network models and principal component analysis method in predicting stock prices on Tehran Stock Exchange. Phys. A Stat. Mech. Its Appl. 2015, 438, 178–187. [Google Scholar] [CrossRef]
- De Oliveira, F.A.; Nobre, C.N.; Zárate, L.E. Applying Artificial Neural Networks to prediction of stock price and improvement of the directional prediction index—Case study of PETR4, Petrobras, Brazil. Expert Syst. Appl. 2013, 40, 7596–7606. [Google Scholar] [CrossRef]
- Patel, J.; Shah, S.; Thakkar, P.; Kotecha, K. Predicting stock and stock price index movement using Trend Deterministic Data Preparation and machine learning techniques. Expert Syst. Appl. 2015, 42, 259–268. [Google Scholar] [CrossRef]
- Godarzi, A.A.; Amiri, R.M.; Talaei, A.; Jamasb, T. Predicting oil price movements: A dynamic Artificial Neural Network approach. Energy Policy 2014, 68, 371–382. [Google Scholar] [CrossRef]
- Chiroma, H.; Abdulkareem, S.; Abubakar, A.; Zeki, A.; Ya’U Gital, A. Intelligent system for predicting the price of natural gas based on non-oil commodities. In Proceedings of the 2013 IEEE Symposium on Industrial Electronics & Applications, Kuching, Malaysia, 22–25 September 2013; pp. 200–205. [Google Scholar]
- Kriechbaumer, T.; Angus, A.; Parsons, D.; Rivas Casado, M. An improved wavelet-ARIMA approach for forecasting metal prices. Resour. Policy 2014, 39, 32–41. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, J.; Yu, L. A deep learning ensemble approach for crude oil price forecasting. Energy Econ. 2017, 66, 9–16. [Google Scholar] [CrossRef]
- Buncic, D.; Moretto, C. Forecasting copper prices with dynamic averaging and selection models. N. Am. J. Econ. Financ. 2015, 33, 1–38. [Google Scholar] [CrossRef]
- Weng, B.; Ahmed, M.A.; Megahed, F.M. Stock market one-day ahead movement prediction using disparate data sources. Expert Syst. Appl. 2017, 79, 153–163. [Google Scholar] [CrossRef]
- Thomas, L. At BlackRock, Machines are Rising Over Managers to Pick Stocks. Available online: https://www.nytimes.com/2017/03/28/business/dealbook/blackrock-actively-managed-funds-computer-models.html (accessed on 30 September 2018).
- Lewis, D. Computers May Not Make Mistakes but Many Consumers Do. Proceedings of the International Conference on HCI in Business, Government, and Organizations; Springer: Berlin/Heidelberg, Germany, 2018; Volume 10923, pp. 361–371. [Google Scholar]
- Joueid, A.; Coenders, G. Marketing Innovation and New Product Portfolios. A Compositional Approach. J. Open Innov. Technol. Mark. Complex. 2018, 4, 19. [Google Scholar] [CrossRef]
- Suh, T.; Kang, S.; Kemp, E.A. A Bayesian network approach to juxtapose brand engagement and behaviors of substantive interest in e-services. Electron. Commer. Res. 2018, 1–19. [Google Scholar] [CrossRef]
- Witt, U. What kind of innovations do we need to secure our future? J. Open Innov. Technol. Mark. Complex. 2016, 2, 17. [Google Scholar] [CrossRef]
- Beltramini, E. Human vulnerability and robo-advisory: An application of Coeckelbergh’s vulnerability to the machine-human interface. Balt. J. Manag. 2018, 13, 250–263. [Google Scholar] [CrossRef]
- ESAs. JC Report on Automation in Financial Advice; European Supervisory Authorities: Paris, France, 2018. [Google Scholar]
- Ringe, W.-G.; Ruof, C. A Regulatory Sandbox for Robo Advice; ILE Working Paper Series; ILE: Hamburg, Germany, 2018. [Google Scholar]
- Falkowski, M. Financialization of commodities. Contemp. Econ. 2011, 5, 4–17. [Google Scholar] [CrossRef]
- Goldstein, I.; Yang, L. Commodity Financialization and Information Transmission; Rotman School of Management: Toronto, ON, Canada, 2018. [Google Scholar]
- U.S. Geological Survey. Mineral Commodity Summaries 2019; U.S. Geological Survey: Reston, WV, USA, 2019.
- Norilsk Nickel. Annual Report 2018; Norilsk Nickel: Moscow, Russia, 2019. [Google Scholar]
- Freedonia Group World Copper. Available online: https://www.freedoniagroup.com/industry-study/world-copper-3274.htm (accessed on 20 August 2019).
- CFTC Commitments of Traders|U.S. Commodity Futures Trading Commission. Available online: https://www.cftc.gov/MarketReports/CommitmentsofTraders/index.htm (accessed on 17 February 2019).
- Sánchez Lasheras, F.; de Cos Juez, F.J.; Suárez Sánchez, A.; Krzemień, A.; Riesgo Fernández, P. Forecasting the COMEX copper spot price by means of neural networks and ARIMA models. Resour. Policy 2015, 45, 37–43. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Lin, T.Y.; Tseng, C.H. Optimum design for Artificial Neural Networks: An example in a bicycle derailleur system. Eng. Appl. Artif. Intell. 2000, 13, 3–14. [Google Scholar] [CrossRef]
- Sha, W. Comment on the issues of statistical modelling with particular reference to the use of artificial neural networks. Appl. Catal. A Gen. 2007, 324, 87–89. [Google Scholar] [CrossRef]
- Vanstone, B.; Finnie, G. An empirical methodology for developing stockmarket trading systems using artificial neural networks. Expert Syst. Appl. 2009, 36, 6668–6680. [Google Scholar] [CrossRef]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995; ISBN 0198538642. [Google Scholar]
- Dunis, C.L.; Laws, J.; Sermpinis, G. Modelling and trading the EUR/USD exchange rate at the ECB fixing. Eur. J. Financ. 2010, 16, 541–560. [Google Scholar] [CrossRef]
- Zhong, X.; Enke, D. Forecasting daily stock market return using dimensionality reduction. Expert Syst. Appl. 2017, 67, 126–139. [Google Scholar] [CrossRef]
- Liu, C.; Hu, Z.; Li, Y.; Liu, S. Forecasting copper prices by decision tree learning. Resour. Policy 2017, 52, 427–434. [Google Scholar] [CrossRef]
- Vochozka, M.; Horák, J. Comparison of Neural Networks and Regression Time Series When Estimating the Copper Price Development. In Sustainable Growth and Development of Economic Systems. Contributions to Economics; Ashmarina, S., Vochozka, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; pp. 169–181. ISBN 9783030117542. [Google Scholar]
- Dehghani, H. Forecasting copper price using gene expression programming. J. Min. Environ. 2018, 9, 349–360. [Google Scholar]
- Falat, L.; Stanikova, Z.; Durisova, M.; Holkova, B.; Potkanova, T. Application of Neural Network Models in Modelling Economic Time Series with Non-constant Volatility. Procedia Econ. Financ. 2015, 34, 600–607. [Google Scholar] [CrossRef]
- Gilbert, C.L. Speculative Influences on Commodity Futures Prices 2006-2008. In Proceedings of the United Nations Conference on Trade and Development, Geneva, Switzerland, March 2010. [Google Scholar]
- Boyd, N.E.; Harris, J.H.; Li, B. An update on speculation and financialization in commodity markets. J. Commod. Mark. 2018, 10, 91–104. [Google Scholar] [CrossRef]
- EIA Spot Prices for Crude Oil and Petroleum Products. Available online: https://www.eia.gov/dnav/pet/PET_PRI_SPT_S1_D.htm (accessed on 17 February 2019).
- Cochilco Metal Prices|Cochilco. Available online: https://www.cochilco.cl/Paginas/English/Statistics/Data Base/Metal-Prices.aspx (accessed on 17 February 2019).
- Kristjanpoller, R.W.; Hernández, P.E. Volatility of main metals forecasted by a hybrid ANN-GARCH model with regressors. Expert Syst. Appl. 2017, 84, 290–300. [Google Scholar] [CrossRef]
- Kristjanpoller, W.; Minutolo, M.C. Gold price volatility: A forecasting approach using the Artificial Neural Network-GARCH model. Expert Syst. Appl. 2015, 42, 7245–7251. [Google Scholar] [CrossRef]
- Yahoo S&P 500 Historical Data. Available online: https://finance.yahoo.com/quote/%5EGSPC/history?p=%5EGSPC (accessed on 17 February 2019).
- ECB. ECB Euro Reference Exchange Rate: US Dollar (USD). Available online: https://www.ecb.europa.eu/stats/policy_and_exchange_rates/euro_reference_exchange_rates/html/eurofxref-graph-usd.en.html (accessed on 17 February 2019).
- Reilly, F.K.; Brown, K.C. Investment Analysis and Portfolio Management; South-Western Cengage Learning: Boston, MA, USA, 2011; ISBN 978-0-324-28903-9. [Google Scholar]
- Kohli, R.K. Day-of-the-week effect and January effect examined in gold and silver metals. J. Bus. Econ. 2014, 5, 1949–1956. [Google Scholar] [CrossRef]
- Borowski, K.; Lukasik, M. Analysis of Selected Seasonality Effects in the Following Metal Markets: Gold, Silver, Platinum, Palladium and Copper. J. Manag. Financ. Serv. 2017, 59–86. [Google Scholar] [CrossRef]
- Kuhn, M. Caret package. J. Stat. Softw. 2008, 28, 1–26. [Google Scholar]
- Malkiel, B.G. Passive Investment Strategies and Efficient Markets. Eur. Financ. Manag. 2003, 9, 1–10. [Google Scholar] [CrossRef]
- Sharpe, W.F. Mutual Fund Performance. J. Bus. 1966, 39, 119–138. [Google Scholar] [CrossRef]
- Chen, Y.-C.; Rogoff, K.S.; Rossi, B. Can Exchange Rates Forecast Commodity Prices? Q. J. Econ. 2010, 125, 1145–1194. [Google Scholar] [CrossRef]
- Harvey, D.I.; Kellard, N.M.; Madsen, J.B.; Wohar, M.E. Long-Run Commodity Prices, Economic Growth, and Interest Rates: 17th Century to the Present Day. World Dev. 2017, 89, 57–70. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Type of Variables | Input Variables | Output Variable |
|---|---|---|
| Commodities Markets | Brent oil price(t-5) | Copper price(t) |
| West Texas oil price(t-5) | ||
| Gold price(t-5) | ||
| Silver price(t-5) | ||
| Copper price(t-5) | ||
| Copper price(t-6) | ||
| Copper price(t-7) | ||
| Copper price return(t-5) | ||
| Copper return 5-day rolling window volatility(t-5) | ||
| Tin price(t-5) | ||
| Lead price(t-5) | ||
| Zinc price(t-5) | ||
| Aluminum price(t-5) | ||
| Nickel price(t-5) | ||
| Fundamentals | S&P 500(t-5) | |
| Euro/US$ exchange rate(t-5) | ||
| Copper demand | Change in world copper inventory(t-5) | |
| Day of the Week Effect | Day of the week(t-5) | |
| Big Players | US OTC copper open interest(t-5) | |
| US OTC copper speculators long positions(t-5) | ||
| US OTC copper speculators short positions(t-5) | ||
| US OTC copper hedgers long positions(t-5) | ||
| US OTC copper hedgers short positions(t-5) | ||
| US OTC copper small speculators long positions(t-5) | ||
| US OTC copper small speculators short positions(t-5) |
| (a) Best Models Period 1 | (b) Best Models Period 2 | ||||
|---|---|---|---|---|---|
| ANN Type [Structure] | MAPE | Correlation | ANN type [Structure] | MAPE | Correlation |
| MLP [25 16 0 0 1] | 1.78% | 97.75% | MLP [25 8 1 0 1] | 3.17% | 98.82% |
| Elman [25 18 0 0 1] | 1.82% | 97.46% | MLP [25 6 6 0 1] | 3.42% | 98.71% |
| Elman [25 17 9 0 1] | 2.12% | 96.85% | MLP [25 6 1 0 1] | 3.56% | 98.51% |
| Elman [25 13 3 0 1] | 2.57% | 95.31% | MLP [25 19 2 2 1] | 4.52% | 97.87% |
| (a) Training Set Model Period 1 | (b) Out-of-sample Set Model Period 1 | ||||
| Model | Model | ||||
| Market | Predicts down | Predicts up | Market | Predicts down | Predicts up |
| Actual down | 185 | 91 | Actual down | 14 | 2 |
| Actual up | 101 | 199 | Actual up | 3 | 4 |
| Accuracy: | 66.70% | Accuracy: | 78.26% | ||
| (c) Training Set Model Period 2 | (d) Out-of-sample Set Model Period 2 | ||||
| Model | Model | ||||
| Market | Predicts down | Predicts up | Market | Predicts down | Predicts up |
| Actual down | 134 | 118 | Actual down | 6 | 3 |
| Actual up | 117 | 136 | Actual up | 5 | 9 |
| Accuracy: | 53.47% | Accuracy: | 65.22% | ||
| (a) Strategy Model Period 1 | (b) Strategy Model Period 2 | |||||
|---|---|---|---|---|---|---|
| Buy & Hold | Sell & Hold | Robo-Advisor | Buy & Hold | Sell & Hold | Robo-Advisor | |
| Cum. return | −16.97% | 16.97% | 29.18% | 10.01% | −10.01% | 8.91% |
| Mean return | −0.74% | 0.74% | 1.27% | 0.44% | −0.44% | 0.39% |
| Std. dev. | 2.05% | 2.05% | 1.77% | 1.22% | 1.22% | 1.23% |
| Sharpe ratio | −0.36 | 0.35 | 0.71 | 0.35 | −0.36 | 0.31 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Méndez-Suárez, M.; García-Fernández, F.; Gallardo, F. Artificial Intelligence Modelling Framework for Financial Automated Advising in the Copper Market. J. Open Innov. Technol. Mark. Complex. 2019, 5, 81. https://doi.org/10.3390/joitmc5040081
Méndez-Suárez M, García-Fernández F, Gallardo F. Artificial Intelligence Modelling Framework for Financial Automated Advising in the Copper Market. Journal of Open Innovation: Technology, Market, and Complexity. 2019; 5(4):81. https://doi.org/10.3390/joitmc5040081
Chicago/Turabian StyleMéndez-Suárez, Mariano, Francisco García-Fernández, and Fernando Gallardo. 2019. "Artificial Intelligence Modelling Framework for Financial Automated Advising in the Copper Market" Journal of Open Innovation: Technology, Market, and Complexity 5, no. 4: 81. https://doi.org/10.3390/joitmc5040081
APA StyleMéndez-Suárez, M., García-Fernández, F., & Gallardo, F. (2019). Artificial Intelligence Modelling Framework for Financial Automated Advising in the Copper Market. Journal of Open Innovation: Technology, Market, and Complexity, 5(4), 81. https://doi.org/10.3390/joitmc5040081