1. Introduction
In standard datasets, large and medium objects usually occupy a larger proportion than small objects. Nevertheless, small objects may carry crucial information, and thus, small object detection has great application potential. In medical image analysis, it contributes to finding mild illness before a disease intensifies. In traffic management, it improves the monitoring accuracy of video monitoring systems for traffic flow, providing assistance for vehicle management. In automatic driving, the preliminary detection of distant vehicles, signal lights, and signs is helpful in expanding the perception range of the visual system and preparing responses in advance. The importance of small object detection is clearly highlighted in the field of remote sensing image analysis, which is inherently associated with long-distance imaging.
With the powerful ability of convolutional neural networks (ConvNets) in feature extraction, deep learning methods have been integrated with mainstream methods of object detection for rapid results. In 2012, AlexNet [
1] won the ImageNet Large Scale Visual Recognition Competition, and achieved more outstanding classification results than traditional algorithms, which promoted the rapid development of deep learning technology. The feature extraction method using ConvNets soon surpassed the traditional extraction scheme based on hand-designed features (such as SIFT [
2] and HOG [
3]). Although existing object detectors based on deep learning exhibit good performance for large and medium objects, the actual application scenario is often more complicated. Small object detection remains one of the most difficult and challenging tasks in computer vision. When small objects or those at large distances from the imaging device are captured, the number of small objects dramatically increases. Compared with large objects, small objects, which occupy less space and possess weaker textures, are prone to background interference and drowning in noise. Therefore, they cannot retain enough features after multiple convolutions and pooling, due to which detectors fail to detect them.
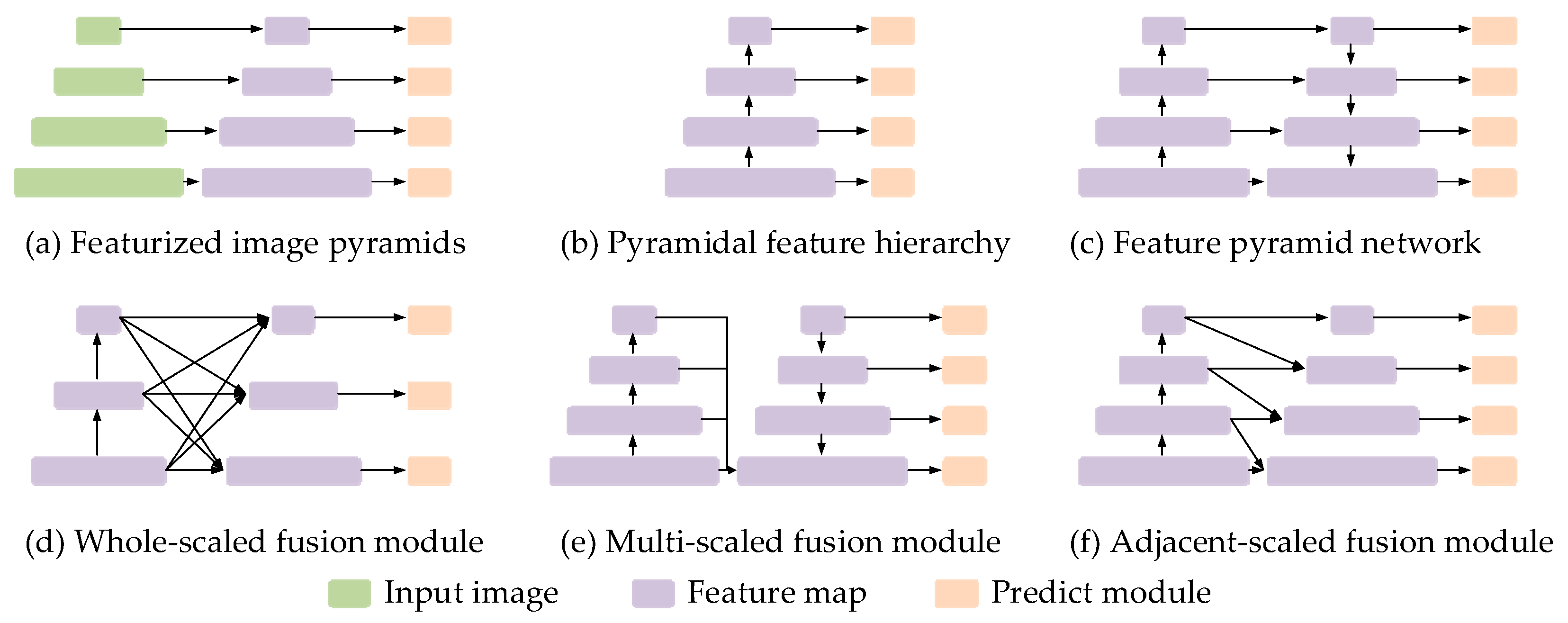
The object detection task includes two subtasks: localization and classification, which depend on detailed information and semantic information, respectively. However, the classic bottom-up ConvNets are unable to learn a group of feature maps possessing both high semantics and high resolution. For object detection tasks, features in deeper layers contain rich semantic information, but poor location information. In contrast, features in shallower layers contain rich location information, but poor semantic information. The single shot multibox detector (SSD) [
4] creatively introduces multi-scale features to detect objects of different sizes, as shown in
Figure 1b. In multi-scale detection algorithms, we can obtain sufficient detail and semantic information in high-level feature maps for large objects. However, it is difficult to achieve good performance from a single layer for small object detection. In small object detection, on the one hand, a larger receptive field is required for richer semantic information and context information. On the other hand, high-resolution feature maps are required for more detailed information. The smaller the size of the object, the more obvious the contradiction between the two requirements.
To alleviate this contradiction, multi-scale feature fusion methods have been explored. Existing research show that richer feature representations can be obtained by fusing features at different scales. As shown in
Figure 1c–f, there are some typical feature fusion methods which have been proposed to obtain more discriminative representation on the base feature hierarchy. In addition to the feature fusion methods, the attention mechanism is also advantageous in feature selection and enhancement. By learning differentiated weights, important channels or areas of interest can be locally enhanced, which is beneficial for capturing features of small samples.
In this paper, we introduce two novel and effective blocks to enhance the original SSD, and propose a feature fusion and spatial attention-based single shot detector for small object detection, named FASSD. The main contributions of our works are summarized as follows:
(1) We propose a lightweight spatial attention block, which consists of continuous convolution, batch normalization, and activation function layers. It can learn an attention mask to enhance areas of interest and can be easily inserted into the network. Residual connection is adopted to prevent serious information loss after the attention mechanism.
(2) We present an effective feature fusion block that applies transposed convolution to upsample feature maps, and concatenation is adopted to fuse features. To adjust the number of channels, we utilize group convolution layers with 1 × 1 kernels.
(3) Applying the above two blocks, we design an improved framework based on SSD. Our FASSD achieves better performance on benchmark datasets of PASCAL VOC2007 than many improved frameworks based on SSD.
(4) We establish a Lake-Boat dataset for small object detection and prove the effectiveness of our algorithm. Our algorithm can detect surface objects with high accuracy and speed. This proves the high application potential of our work on water surface detection systems.
3. Methods
In this section, we first describe the principle of the proposed FASSD and the two enhancement blocks: feature fusion block (FFB) and spatial attention block (SAB). Then, we discuss our training strategies. Finally, we introduce a new boat dataset for small object detection.
3.1. FASSD Architecture
Considering the difference in the distributions of object sizes in Visual Object Classes (VOC) and LAKE-BOAT, we applied different scale settings for the two datasets.
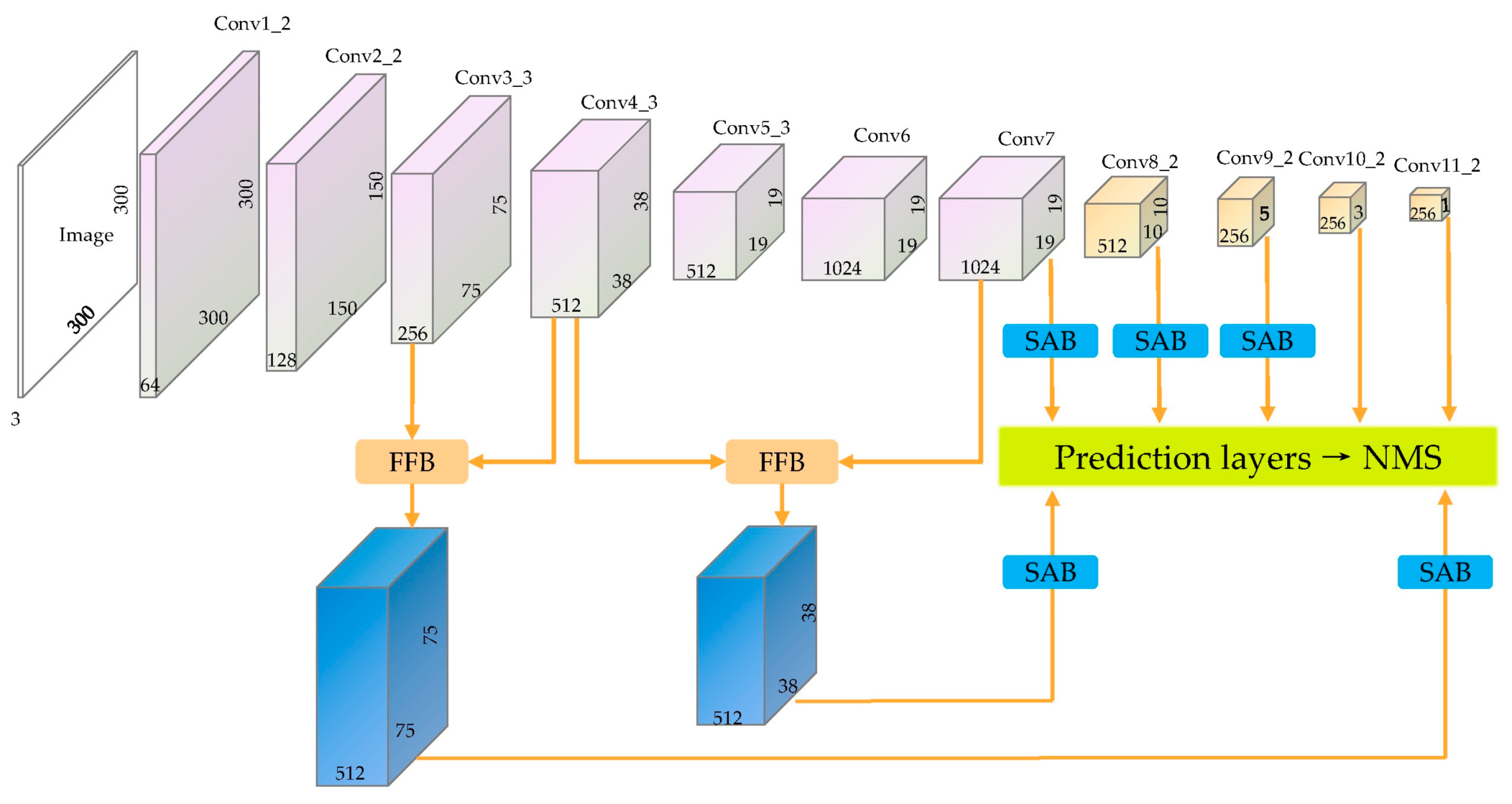
Figure 2 and
Figure 3 present the architecture of our FASSD and simplified FASSD with 300 × 300 input. VGG16 [
32] is adopted as backbone network. Similar to DeepLab-LargeFOV [
33], we convert fully connected layers (fc6 and fc7) to convolutional layers (conv6 and conv7). Fc8 layer and all dropout layers are removed. Following the strategy in SSD [
4], we add four convolutional layers to extract feature hierarchy. As shown in
Figure 2, conv1 to conv7 are VGG16 layers, conv8 to conv11 are SSD layers.
3.1.1. FASSD Architecture
When performing multi-scale object detection, feature maps of different scales are responsible for responding to objects with corresponding scales, and the responses of small objects often occur in shallow layers. Considering the lack of semantic information in the shallow layers, we chose to import semantic information from adjacent scales up to the current layer, rather than recovering semantic information from the top layer. The feature maps at the top level are capable of extracting global semantics, but it is difficult to retain the local semantic information of small object areas. Multiple upsamplings may introduce noise, which will deteriorate the performance of small object detection.
To enhance the performance of small object detection, we added an extra scale of 75 × 75 compared with SSD. The feature maps of conv4_3 and conv7 were upsampled and concatenated with conv3_3 and conv4_3, respectively. The fused feature was integrated and extracted through further convolution in the feature fusion block. To ensure the versatility of FFB and reduce the design burden, the same FFBs were maintained except for the number of input channels and parameters of deconvolution layers. Spatial positions of interest were enhanced by inserting five spatial attention blocks into the network. Considering the lack of spatial information in the top two layers, they were not taken into consideration.
In the design of prediction layers, seven prediction layers were added to make prediction on seven-scale feature maps. For feature maps of size w × h with p channels, we applied 3 × 3 × p kernels to perform prediction at each of the w × h locations. Each prediction layer contained two convolutional layers which were applied to predict scores and location offsets respectively. The output channels were set to a × c and a × 4 where “a” represented the number of anchors about each cell of feature maps, “c” represented the number of object classes and “4” represented the number of location parameters. After prediction, NMS (non-maximum suppression) was applied to filter out redundant boxes during inference, targeting a final value of only 200 detections.
3.1.2. Simplified FASSD Version for Small Object Detection
Multi-scale detection is robust to scale variance. However, when the scale and size of the objects are similar, the great advantage of multi-scale detection is lost. Moreover, when small objects occupy a larger proportion of the dataset, the scale imbalance may prevent the training of high-level prediction layers, resulting in more false positives. To adopt the object characteristics of LAKE-BOAT, we directly removed high-level convolution layers after conv7, and only three scales were retained for prediction. Such an operation also reduces the inference time. The architecture of a simplified FASSD for small object detection is shown in
Figure 3.
3.2. Feature Fusion Block
Two feature fusion blocks were used in our framework.
Figure 4a shows their architectures. The dimension of all the feature maps was first reduced to 256 for computation optimization. To fit the special shape of feature maps from two layers, a deconvolution (transposed convolution) layer was added for upsampling. The kernel size was 3 × 3 or 2 × 2 with stride 2. We integrated the features through concatenation and further convolution. Every convolution or deconvolution layer was followed by ReLu layers. Batch normalization layers were extensively used to prevent feature divergence.
To optimize the computation, we applied four 1 × 1 convolution layers for dimensionality adjustment. We utilized two 1 × 1 convolution layers to reduce the channels of input feature maps to 256 each before concatenation. Before and after further convolution, a 1 × 1 convolution layer was used to reduce or restore the channels. Specifically, all 1 × 1 convolutional layers adopt the form of group convolution, which is inspired by ResNext [
34]. All the parameters of the groups were set to 32. In ordinary convolution, each output channel is connected to all input channels. Group convolution divides the input and output channels into multiple groups, and each group follows the ordinary convolution operation, but there is no information interaction between groups. Therefore, group convolution is more conducive to retain the differences between channels.
3.3. Spatial Attention Block
Small objects merely occupy a small area. We attempted to design a lightweight block to enhance the possible regions of small objects while suppressing the background response at the same time. To this end, we designed a spatial attention block consisting of continuous convolution, batch normalization, and activation function layers. To prevent serious information loss after attention, we utilized leaky ReLu instead of ReLu and also adopted the residual connection. SAB can learn an attention mask to enhance the area of interest. Element-wise products were applied to fuse the mask with each channel of the feature maps. Our structure is completely differentiable, and the parameters can be updated well in back-propagation.
We designed two versions of the spatial attention block, as shown in
Figure 4. One possesses only a single branch, as shown in
Figure 4b, and only 1 × 1 convolution is utilized for channel integration. It performs computations only at a certain position between different channels, without changing the receptive fields of the previous feature maps. The other possesses two branches, as shown in
Figure 4c. We introduced dilated convolution to improve the contextual information awareness of our attention blocks.
Assuming that the original feature maps are
x, the new feature maps after attention are
y and express the attention operation of each branch as function
F. Thus, the attention mechanism can be expressed as follows (taking the version with two branches as an example):
and represent the attention mask learned by two of the branches.
3.4. LAKE-BOAT Dataset for Small Object Detection
Small object detection has a greater demand for context information. To evaluate our framework more accurately, we constructed a LAKE-BOAT dataset under a typical lake scene. The lake scene we constructed has obvious background information on the water surface, which can effectively test the capability of the detection model for extracting context information.
The LAKE-BOAT dataset contained 350 images, in which 250 images were taken for training and the remaining 100 images were taken for testing. The original image size was 960 × 540 pixels. To increase the number of small instances, we performed a sample offline data augmentation by zooming out the original images. We first reduced the original width and height by half and then spliced it to four segments to restore the original resolution, as shown in
Figure 5. Label files were used to perform the corresponding conversion. The orange bounding boxes illustrate annotation results.
We analyzed the size attribute of objects’ ground truth box after resizing the image to 300 × 300, and the results are shown in
Table 1. Small objects and extra-small objects accounted for an extremely large proportion. Extra-small objects, small objects, medium objects, large objects, and extra-large objects correspond to levels 1 to 5, respectively. The area corresponding to level
x is calculated according to Formula (2), and the corresponding size in the 300 × 300 images and 75 × 75 feature maps are shown in
Table 2.
3.5. Training
3.5.1. Data Augmentation
We adopted the same online strategies for SSD. In addition, we applied a simple offline augmentation method (
Section 3.4) to train our model on the LAKE-BOAT dataset. In this manner, we obtained a new dataset with four-times-smaller objects. The original dataset and the augmented version were combined for further training.
3.5.2. Transfer Learning
Transfer learning can effectively improve the robustness of the model and speed up convergence. For the VOC task, we used the pre-trained VGG16 [
32] on the ILSVRC CLS-LOC dataset as initial weights. When training on the LAKE-BOAT dataset, we transferred the corresponding parameters from well-trained FASSD on VOC, except for the prediction layers. After transferring the weights, we first trained the prediction layer separately and then fine-tuned the network.
3.5.3. Anchor Setting
For the VOC task, the same setting strategy as the corresponding SSD level was adopted for the last six prediction layers. The scale of conv4_3 was 0.2, and the scale of the top layer was 0.9. As for the extra level, we set a smaller scale of 0.1. For conv7, conv8_2, conv9_2, six anchors were set for ratios in each cell of the feature maps. The other convolutions included four anchors in ratios . For the LAKE-BOAT task, the anchor setting of the remaining three scales applied the same strategy.
3.5.4. Loss Function
Following in SSD’s footsteps, we utilized Smooth L1 loss and Softmax loss to measure the localization loss and confidence loss respectively. The model loss is a sum of localization loss and confidence loss.
Our training strategies follow the baseline network. Some common points are not mentioned. Interested readers can refer to the original paper [
4] for more details.
4. Experiments
For our experiments, the Pytorch-version SSD provided by [
35] was selected as the baseline. We evaluated our FASSD on PASCAL VOC and LAKE-BOAT. PASCAL VOC is one of the most common benchmark datasets in object detection. It provides labeled images and evaluation toolbox of precision for researchers. The PASCAL VOC dataset contains 20 types of objects, including person, cat, bus, bottle, etc. VOC2007 annotated 9963 images and 24,640 objects in which 4952 images and 12,032 objects are taking for test; the trainval set of VOC2012 annotated 11,530 images and 27,450 objects. We adopt the common index mAP (mean average precision) and FPS (frame per second) to evaluate the detection accuracy and speed. The mAP is calculated by the official devkit provided by PASCAL VOC.
4.1. Ablation Study of VOC
To compare the contribution of each improvement measure, we performed our experiments on VOC with an input size of 300 × 300. All models were trained on the union of the 2007 and 2012 trainval (VOC07 + 12) and tested on the VOC2007 test set. The results are shown in
Table 3. All the results were tested by ourselves using a signal TITAN RTX GPU, an Intel I9-10900X@3.70GHz, and cuda 10.1, pytorch 1.0.0. We used 500 images from the VOC2007 test and resized them to 300 × 300 before the speed test. A value of 75 × 75 indicates whether to add the extra scale feature maps of 75 × 75 for detection.
4.1.1. Extra Scale of 75 × 75
The extra scale with small anchors is important for detecting small objects. In
Table 3, we compare the versions of models that apply attention v2 and feature fusion (row 4), and extra scale and attention v2 and feature fusion (row 7). The results indicate that an extra scale can increase the mAP by 1.1%. However, utilizing the extra scale and feature fusion method (row 5) only increases the mAP by 0.5%, which indicates that it works best when applying the three methods simultaneously.
4.1.2. Feature Fusion
In
Table 3, we compare the versions of models that apply attention v2 (row 3) and attention v2 and feature fusion (row 4). The results indicate that feature fusion methods can increase the mAP by 0.2%, while the increase in computation decreases the detection speed by 18%. The results also indicate that simple fusion does not necessarily bring considerable performance improvements. The choice of fusion feature maps is crucial.
4.1.3. Two Versions of SAB
We performed two groups of contrast to compare the performance of SAB v1 and SAB v2. By directly adding four SABs before the head of SSD, the two versions of SAB both achieved an improvement of 0.4% and 0.3% mAP. However, the performance of SAB v2 was lower than that of SAB v1. On the contrary, mAP slightly decreased. The result in the second row of
Table 3 shows that SAB v1 is a lightweight plug-and-play block. With the extra scale of 75 × 75 and application of feature fusion, SAB v2 achieved a better grade than SAB v1 at about 0.4% mAP. The results indicate that dilated convolution is more suitable for capturing detailed information, especially in large-scale feature maps.
4.1.4. Group Convolution
A 1 × 1 convolution layer is often used as a bottleneck layer for dimensionality reduction. As in our attempt in the attention block, a 1 × 1 convolution layer can also integrate features from multiple channels but it is not beneficial for further fusion and extraction. After 1 × 1 convolution, the difference between channels decreased, which further deteriorated the learning process. Therefore, we replaced the general convolution layers with the group convolution layers in the FFB. This operation increased the mAP from 78.7% to 79.3%.
4.2. Results on PASCAL VOC2007
We trained our FASSD on the union of the VOC2007 trainval and VOC2012 trainval, and tested it on VOC2007. Following the SSD, we set the batch size to 32 with the input 300 × 300 and trained FASSD for 120,000 iterations. The learning rate was set to 10−3 for the first 80,000 iterations, and then adjusted to 10−4 and 10−5 for the next and last 20,000 iterations, respectively. The SGD optimizer with a momentum of 0.9 and a weight decay of 0.0005 was adopted. The initialization parameters of the backbone were derived from a well pre-trained VGG16 on ImageNet, and Xavier initialization was applied to the remaining layers.
The results of the PASCAL VOC2007 test are shown in
Table 4. By utilizing powerful data augmentation methods, the Pytorch-version SSD trained by ourselves beyond the latest Caffe version by 0.2 points, proposed by the authors after the paper publication. Our FASSD achieved 79.3% mAP with an input of 300 × 300, outperforming the baseline by 1.6 points with a similar performance to that of SSD512*. FASSD also outperformed CSSD, DSSD, DSOD, MDSSD, RSSD, and FSSD with similar input sizes.
4.3. Inference Speed on PASCAL VOC2007 Test
Table 5 shows the inference speed of Faster R-CNN and some networks based on SSD. Our FASSD can run at 45.3 FPS with an input size of 300 × 300 on a signal TITAN RTX GPU. For fair comparison, we tested the speed of SSD with the same settings. Because of the additional layers, our FASSD is 35% slower than SSD. However, compared with DSSD, MDSSD, and DSOD, our framework is very competitive with better performance in terms of both speed and accuracy.
4.4. Small Object Detection on LAKE-BOAT
To further evaluate the performance of our model, we designed experiments using the LAKE-BOAT dataset. For better convergence and faster training, we transferred the corresponding parameters from the corresponding version trained on the VOC model. Taking the number of images into consideration, we trained our model on LAKE-BOAT for only 7000 iterations. The learning rate was set to 10−3 for the first 1000 iterations, and then decreased to 10−4 for the next 4000 iterations, 10−5 for another 1000 iterations, and 10−6 for the last 1000 iterations. In the first 1000 iterations, we froze all parameters except for the prediction layers, after which we fine-tuned the entire network.
4.4.1. Results and Inference Speed
SSD300 maintains the same architecture as the VOC task, except for the prediction kernels. For a fair comparison, we trained a simplified version of SSD. SSD300
# removed the extra layers after conv7, and the feature maps from conv3_3 were used for prediction. The inference time was tested using a signal TITAN RTX GPU, an Intel I9-10900X@3.70GHz, and cuda 10.1, pytorch 1.0.0. We used 100 images of the Lake-Boat test and resized them to 300 × 300 before testing. The comparison results are shown in
Table 6.
By simplifying the architecture, the network can adapt to the target scene better, which significantly improves the detection speed. The simplified version of the SSD can run at 86.6 FPS. Because of the complexity of the scene and the objects’ dense distribution, the original version of SSD runs slightly slower than the test on the VOC dataset. Our FASSDv1 achieved a mAP of 75.3% while maintaining a real-time detection speed of 64.4 FPS, which exceeds the original version of SSD by 8 points and outperforms the simplified version of SSD by 3.5 points. The results indicate that our feature fusion block and spatial attention block perform well in enhancing the shallow layers. Contrary to the previous results on VOC, our model utilizing SAB v1 performs better than SAB v2. This phenomenon is closely related to the object size. In theory, the receptive field shared by SAB v2 is 125 times larger than SAB v1. Because some of the boat instances are extremely small, excessive background information will be imported when SAB v2 is applied.
4.4.2. Transfer Learning and Data Augmentation
We conducted a simple ablation study to evaluate the contribution of transfer learning and offline data augmentation. The comparison results are shown in
Table 7.
When pre-training was applied, the same strategy as in
Section 4.3 was maintained for the setting of the learning rate. However, it was difficult to train our model using a large learning rate. Loss value explosion invariably occurred without parameter transfer, which hindered the training process. Moreover, 7000 iterations are not sufficient to train the model well. Therefore, the initial learning rate was changed to 10
−4 for the first 20,000 iterations. Then, we decrease it to 10
−5 and 10
−6 for the next 10,000 iterations and last 10,000 iterations.
The results indicate that transfer learning is beneficial for the training process, especially for a small dataset. Transfer learning increased mAP by approximately 4.2 points. Data augmentation contributed to mAP by 1.4 points. This result suggests that the simultaneous use of online and offline data augmentation methods is beneficial when dataset is small.
4.4.3. Detection Rate and False Alarm Rate
In practical applications, the number of detected objects and false predictions are often of research interest. Considering this, we define the detection rate (DR) as the proportion of detected objects to the number of real objects, and the false alarm rate (FAR) as the proportion of false predictions to all predictions. The correctness of a prediction is determined by the intersection over union (IoU) of the prediction and the truths. IOU > 0.5, or not, is the judgment standard. False predictions include incorrect classification and poor position regression. DR and FAR can help evaluate the performance of the models more scientifically. By setting different confidence thresholds, we obtained corresponding results of DR and FAR. The analysis results of DR with FAR of 5%, 10%, and 20% are shown in
Table 8, and the relationship between DR and FAR is shown in
Figure 6.
As shown in
Table 8, all four models performed well in the detection of medium, large, and extra-large objects, with only few difficult instances being missed. However, our model significantly outperformed the original and simplified version of SSD in the detection of extra-small objects. FASSDv1 outperformed the simplified version of SSD by 13.6%, 9.1%, and 7% at FAR of 5%, 10%, and 20%, respectively.
4.5. Visualization Analysis
Figure 7 shows the visualization of feature maps. Through the attention mechanism, the area of the objects was enhanced. The contrast between the area of interest and the background was significantly improved. In the first and second rows, background information could be balanced and suppressed. For small objects in the third and fourth rows, the spatial attention block highlighted the center of objects and distinguished boundary information.
4.6. Visualization of Results
Figure 8 shows the results of detection for the PASCAL VOC2007 test. The confidence threshold was set to 0.6. Compared with the conventional SSD, our model showed performance improvements from three aspects. The first is in terms of small object detection, as shown in
Figure 8a. Owing to the shortage of semantic information in shallow layers and the small size of feature maps, SSD could not perform well, but our model showed targeted improvement. The second is in terms of dense and occluded cases, as shown in
Figure 8b. This improvement may be attributable to the spatial attention block, which can effectively enhance the contrast between objects and the background. The third is for objects with rich contextual information, as shown in
Figure 8c. Our FASSD takes contextual information into account and avoids mistaking the sheep in the flock for cows.
Figure 9 shows the results of detection with the LAKE-BOAT dataset. Only the predictions with confidence scores higher than 0.15 are displayed. We show the comparison of the simplified SSD and FASSDv1.
Figure 9a indicates our model’s advantage in small object detection. As shown in
Figure 9b, our model is more robust in the occluded and dense cases.
Figure 9c shows that our model works better in capturing contextual information. Without enhancement in shallow layers, the simplified SSD generated some false predictions.
5. Conclusions and Future Work
In this paper, we proposed an effective feature fusion block and a lightweight spatial attention block to enhance the sematic information of the shallow layers. The feature fusion blocks fuse sematic information from an adjacent scale. The spatial attention blocks utilize continuous convolution, batch normalization, and activation function layers to learn the special attention weights. On the basis of the two blocks, we propose a feature fusion and spatial attention-based single shot detector. Our FASSD achieves higher performance than many existing detectors with benchmark datasets while still maintaining a real-time detection speed. Experiments conducted with LAKE-BOAT demonstrate the capability of our model in small object detection.
In our model, we utilized an input of 300 × 300 for real-time detection. However, it could not fully utilize all the information of the original 960 × 540 images. The precision may be improved by increasing the input size, but the simultaneous optimization of inference time remains to be addressed, which is the focus of our future work. Our spatial attention block is lightweight and can conveniently be inserted into any ConvNets. It can be applied to other computer vision tasks that are sensitive to spatial information, such as segmentation tasks. The branch with 1 × k or k × 1 kernels can be used to capture horizontal or vertical connections in pedestrian detection. We will investigate these issues in our future work.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}