Optimization of Spiking Neural Networks Based on Binary Streamed Rate Coding



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Structure of Spiking Neural Network
2.1. Overall Structure of SNN
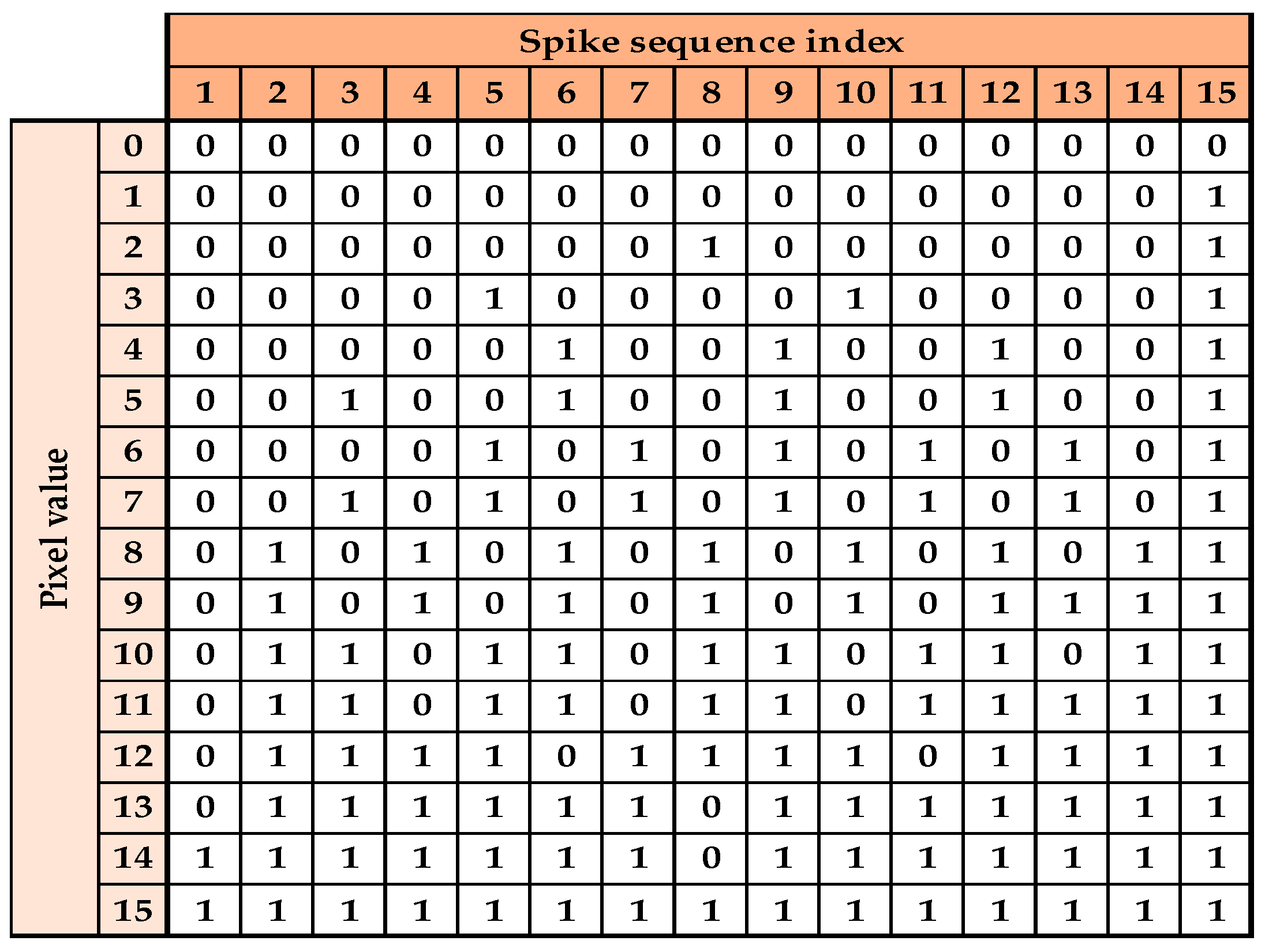
2.2. Spike Signal Representation
| Algorithm 1 Generate Binary Stream of Spikes |
| Inputs: input image pixel values Pv, n bits representing each pixel value, length of binary stream. Output: Stream of Spikes (Sspikes) with length For each pixel in the input image: 1. initialize Sspikes with all zeros 2. if 0 < Pv < /2) then // No spike is added if Pv = 0 3. for ; step = −/Pv) 4. Sspikes [i] = 1 5. Random-rotate (Sspikes) // Rotate in range (, ) 6. else if Pv ≥ then 7. initialize Sspikes with all ones 8. // Calculate 2’s complement of Pv 9. if =1 then // Only 1 spike is needed in the stream 10. Sspikes [/2)] = 0 11. Random-rotate (Sspikes) // Rotate in range (, ) 12. else if > 1 then //generate equally distributed zeros 13. for 14. Sspikes [i] = 0 15. Random-rotate (Sspikes) // Rotate in range (, ) |
2.3. Spiking Neural Network Model
3. Optimization of SNN Model
- BSRC spike coding scheme significantly reduces the hardware cost by combining the advantages of both rate and temporal coding schemes using a built-in randomizer.
- BSRC achieves high training and testing accuracies, while keeping the training time short. It reduces the training time by 50% compared to STBP [11] for the same accuracy goal.
- For a network model of (784-800-10), BSRC achieves higher accuracy even with a small number of training epochs compared with the previous model.
- By splitting the one hidden layer into two hidden layers, we can substantially reduce the hardware cost with little loss in the classification accuracy.
- The proposed quantization algorithm provides further reduction in hardware cost.
3.1. BSRC Based Training
3.2. SNN Structure Optimization
- Fully connected SNNs for MNIST are considered.
- Each pixel of the input image is represented by 4 bits.
- The target accuracy for MNIST is 94.60% or higher.
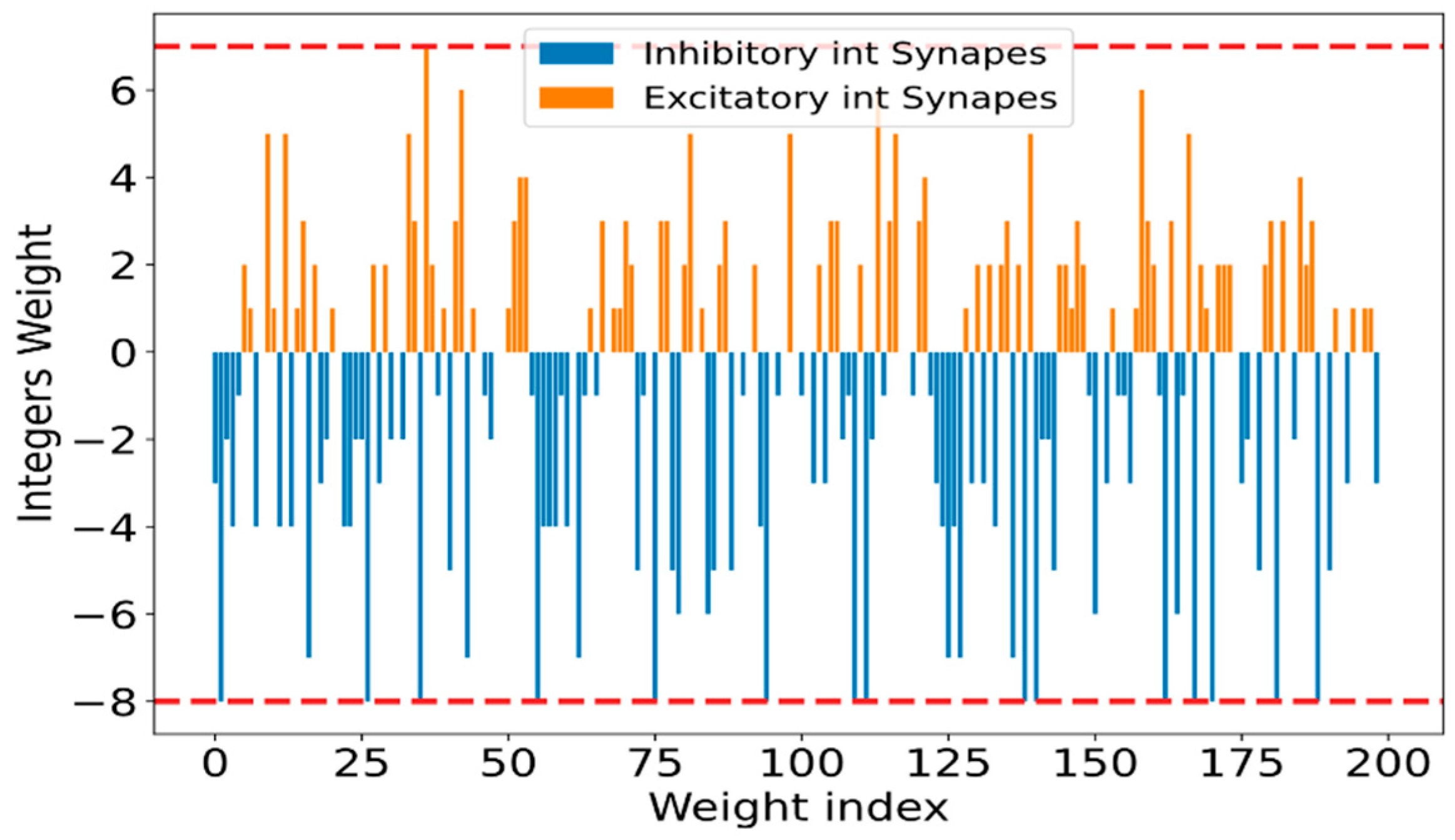
3.3. SNN Weight Quantization
- Positive weights for Excitatory Synapses
- Negative weights for Inhibitory Synapses
| Algorithm 2 Find optimal Weight Quantization |
| Inputs: SNN with floating-point weights w, Target Accuracy ATarget, Max allowable number of bits Bmax for quantization Output: The number bits N, Quantized weights wExc _int and wInh_int 1. for L // L is the num. of layers // Group all weights into excitatory and inhibitory weights 2. for 3. if [i] ≥ 0 then wExc = ; 4. else wInh = ; // Compute statistics of all weights in floating point: 5. MExc= mean(wExc); StdExc= std(wExc); 6. MInh= mean(wInh); StdInh = std(wInh); 7. Repeat for all (nExc, nInh) in range (nmin, nmax) with step (nstep) // Gradually increase the quantized weight resolution: 8. LExc = nExc StdExc + MeanExc; 9. LInh = nInh StdInh + MeanInh; 10. for 11. if [i] > LExc then [i] = LExc; // Clip the max value 12. else if [i] < LInh then [i] = LInh; // Clip the min value 13. for N Bmax// Find the best quantization bits N // Calculate the quantization step 14. ΔExcq = LExc/(2N−1−1); 15. ΔInhq = LInh/(2N−1); // Quantize all clipped weights to N-bits 16. for 17. if [i] ≥ 0 then wQ_int[i] = int ([i] /ΔExcq); 18. else wQ_int[i] = int ([i] /ΔInhq); 19. = Comp_Thresh (wQ_int) 20. Acc = Calculate Accuracy of SNN (wQ_int) 21. Select best (nExc, nInh) with min N that meets ATarget |
3.4. Integer Threshold Compensation
| Algorithm 3 Integer Threshold Compensation |
| Inputs: Trained SNN quantized with N-bits (integer weights), number of layers , number of neurons in each layer l, in floating point, floating-point weights. Outputs: Integer thresholds for each layer 1. for l // Calculate for each layer 2. Read floating-point and integer weights; // , 3. for //Divide the accumulated weights for each neuron 4. 5. // Use Equation (16) 6. Report for each layer |
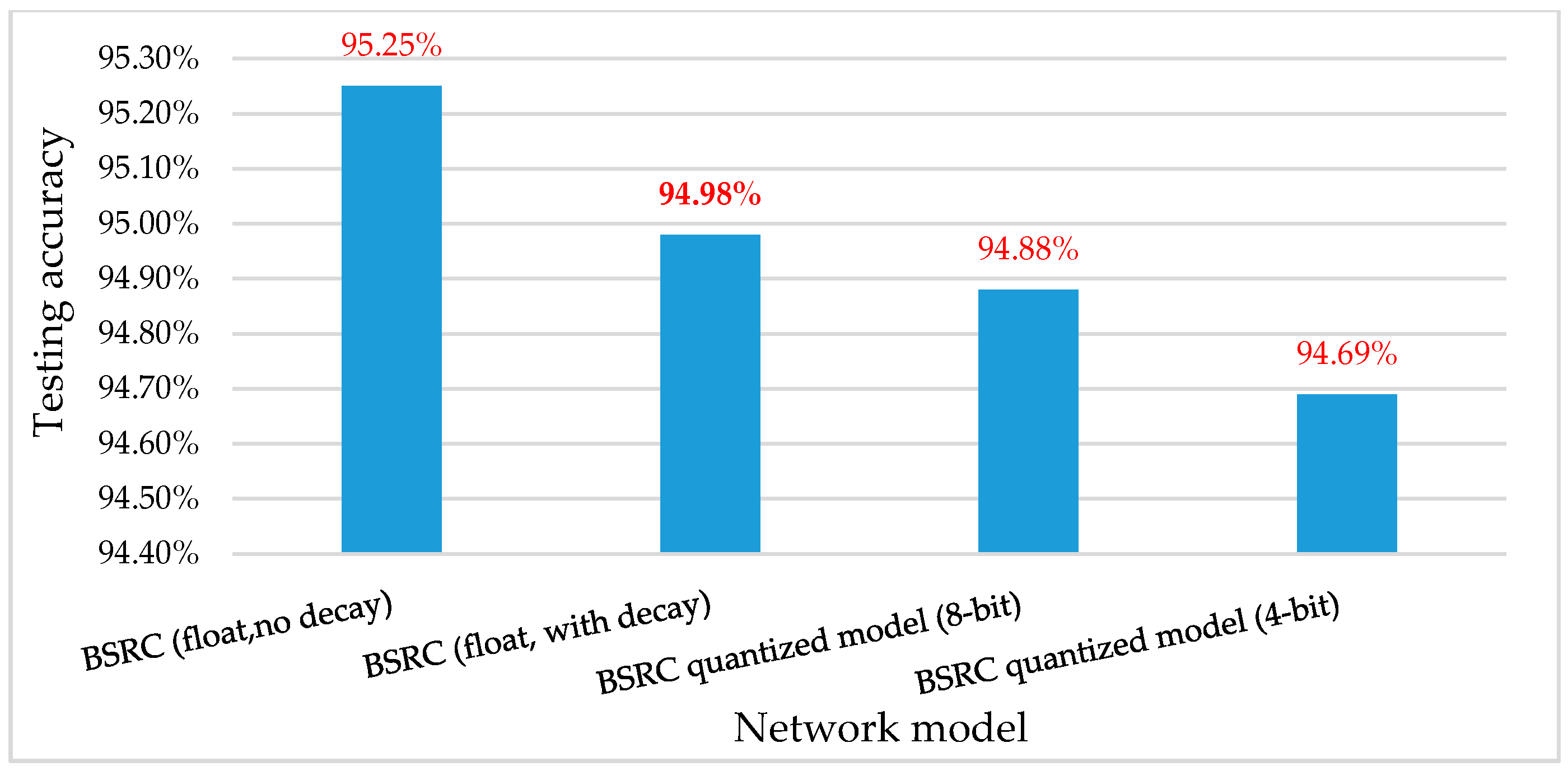
4. Performance Evaluation
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pfeiffer, M.; Pfeil, T. Deep Learning With Spiking Neurons: Opportunities and Challenges. Front. Neurosci. 2018, 12, 774. [Google Scholar] [CrossRef] [PubMed]
- Pedroni, B.U.; Sheik, S.; Mostafa, H.; Paul, S.; Augustine, C.; Cauwenberghs, G. Small-footprint Spiking Neural Networks for Power-efficient Keyword Spotting. In Proceedings of the 2018 IEEE Biomedical Circuits and Systems Conference (BioCAS), Cleveland, OH, USA, 17–19 October 2018; pp. 1–4. [Google Scholar]
- Furber, S.B.; Lester, D.R.; Plana, L.A.; Garside, J.D.; Painkras, E.; Temple, S.; Brown, A.D. Overview of the SpiNNaker System Architecture. IEEE Trans. Comput. 2012, 62, 2454–2467. [Google Scholar] [CrossRef]
- Yan, Y.; Kappel, D.; Neumarker, F.; Partzsch, J.; Vogginger, B.; Hoppner, S.; Furber, S.B.; Maass, W.; Legenstein, R.; Mayr, C.; et al. Efficient Reward-Based Structural Plasticity on a SpiNNaker 2 Prototype. IEEE Trans. Biomed. Circuits Syst. 2019, 13, 579–591. [Google Scholar] [CrossRef] [PubMed]
- Davies, M.; Srinivasa, N.; Lin, T.-H.; Chinya, G.; Cao, Y.; Choday, S.H.; Dimou, G.; Joshi, P.; Imam, N.; Jain, S.; et al. Loihi: A Neuromorphic Manycore Processor with On-Chip Learning. IEEE Micro 2018, 38, 82–99. [Google Scholar] [CrossRef]
- Benjamin, B.V.; Gao, P.; McQuinn, E.; Choudhary, S.; Chandrasekaran, A.R.; Bussat, J.-M.; Alvarez-Icaza, R.; Arthur, J.V.; Merolla, P.A.; Boahen, K. Neurogrid: A Mixed-Analog-Digital Multichip System for Large-Scale Neural Simulations. Proc. IEEE 2014, 102, 699–716. [Google Scholar] [CrossRef]
- Merolla, P.A.; Arthur, J.V.; Alvarez-Icaza, R.; Cassidy, A.S.; Sawada, J.; Akopyan, F.; Jackson, B.L.; Imam, N.; Guo, C.; Nakamura, Y.; et al. A million spiking-neuron integrated circuit with a scalable communication network and interface. Science 2014, 345, 668–673. [Google Scholar] [CrossRef]
- Xu, Y.; Tang, H.; Xing, J.; Li, H. Spike trains encoding and threshold rescaling method for deep spiking neural networks. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–6. [Google Scholar]
- Brette, R. Philosophy of the Spike: Rate-Based vs. Spike-Based Theories of the Brain. Front. Syst. Neurosci. 2015, 9, 151. [Google Scholar] [CrossRef]
- Kiselev, M. Rate coding vs. temporal coding-is optimum between? In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 1355–1359. [Google Scholar]
- Wu, Y.; Deng, L.; Li, G.; Zhu, J.; Shi, L. Spatio-Temporal Backpropagation for Training High-Performance Spiking Neural Networks. Front. Neurosci. 2018, 12, 331. [Google Scholar] [CrossRef]
- Wu, S.; Li, G.; Chen, F.; Shi, L. Training and inference with integers in deep neural networks. arXiv 2018, arXiv:1802.04680. (preprint). [Google Scholar]
- Courbariaux, M.; Itay, H.; Daniel, S.; Ran, E.-Y.; Yoshua, B. Binarized neural networks: Training deep neural networks with weights and activations constrained to +1 or −1. arXiv 2016, arXiv:1602.02830. (preprint). [Google Scholar]
- Han, J.; Li, Z.; Zheng, W.; Zhang, Y. Hardware implementation of spiking neural networks on FPGA. Tsinghua Sci. Technol. 2020, 25, 479–486. [Google Scholar] [CrossRef]
- Cheng, J.; Wu, J.; Leng, C.; Wang, Y.; Hu, Q. Quantized CNN: A Unified Approach to Accelerate and Compress Convolutional Networks. IEEE Trans. Neural Networks Learn. Syst. 2017, 29, 4730–4743. [Google Scholar] [CrossRef]
- Wu, J.; Leng, C.; Wang, Y.; Hu, Q.; Cheng, J. Quantized convolutional neural networks for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4820–4828. [Google Scholar]
- Choukroun, Y.; Kravchik, E.; Yang, F.; Kisilev, P. Low-bit quantization of neural networks for efficient inference. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 3009–3018. [Google Scholar]
- Wang, Y.; Shahbazi, K.; Zhang, H.; Oh, K.I.; Lee, J.-J.; Ko, S.-B. Efficient spiking neural network training and inference with reduced precision memory and computing. IET Comput. Digit. Tech. 2019, 13, 397–404. [Google Scholar] [CrossRef]
- Wang, Y.; Xu, Y.; Yan, R.; Tang, H. Deep Spiking Neural Networks with Binary Weights for Object Recognition. IEEE Trans. Cogn. Dev. Syst. 2020, 1. [Google Scholar] [CrossRef]
- Courbariaux, M.; Yoshua, B.; Jean-Pierre, D. Binaryconnect: Training deep neural networks with binary weights during propagations. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2015; pp. 3123–3131. [Google Scholar]
- Cao, Y.; Chen, Y.; Khosla, D. Spiking Deep Convolutional Neural Networks for Energy-Efficient Object Recognition. Int. J. Comput. Vis. 2014, 113, 54–66. [Google Scholar] [CrossRef]
- Jin, Y.; Li, P.; Zhang, W. Hybrid macro/micro level backpropagation for training deep spiking neural networks. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc.: La Jolla, CA, USA, 2018; pp. 7005–7015. [Google Scholar]
- Markram, H. Regulation of Synaptic Efficacy by Coincidence of Postsynaptic APs and EPSPs. Science 1997, 275, 213–215. [Google Scholar] [CrossRef]
- Kheradpisheh, S.R.; Ganjtabesh, M.; Masquelier, T. Bio-inspired unsupervised learning of visual features leads to robust invariant object recognition. Neurocomputing 2016, 205, 382–392. [Google Scholar] [CrossRef]
- Kistler, W.M.; Van Hemmen, J.L. Modeling Synaptic Plasticity in Conjunction with the Timing of Pre- and Postsynaptic Action Potentials. Neural Comput. 2000, 12, 385–405. [Google Scholar] [CrossRef]
- Diehl, P.U.; Neil, D.; Binas, J.; Cook, M.; Liu, S.-C.; Pfeiffer, M. Fast-classifying, high-accuracy spiking deep networks through weight and threshold balancing. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar]
- Sengupta, A.; Ye, Y.; Wang, R.; Liu, C.; Roy, K. Going Deeper in Spiking Neural Networks: VGG and Residual Architectures. Front. Neurosci. 2019, 13, 95. [Google Scholar] [CrossRef]
- Rueckauer, B.; Lungu, I.-A.; Hu, Y.; Pfeiffer, M.; Liu, S.-C. Conversion of Continuous-Valued Deep Networks to Efficient Event-Driven Networks for Image Classification. Front. Neurosci. 2017, 11, 682. [Google Scholar] [CrossRef]
- Mostafa, H.; Pedroni, B.U.; Sheik, S.; Cauwenberghs, G. Fast classification using sparsely active spiking networks. In Proceedings of the 2017 IEEE International Symposium on Circuits and Systems (ISCAS), Baltimore, MD, USA, 28–31 May 2017; pp. 1–4. [Google Scholar]
- Mostafa, H. Supervised Learning Based on Temporal Coding in Spiking Neural Networks. IEEE Trans. Neural Networks Learn. Syst. 2017, 29, 3227–3235. [Google Scholar] [CrossRef] [PubMed]
- Burkitt, A.N. A Review of the Integrate-and-fire Neuron Model: I. Homogeneous Synaptic Input. Boil. Cybern. 2006, 95, 1–19. [Google Scholar] [CrossRef] [PubMed]














© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Al-Hamid, A.A.; Kim, H. Optimization of Spiking Neural Networks Based on Binary Streamed Rate Coding. Electronics 2020, 9, 1599. https://doi.org/10.3390/electronics9101599
Al-Hamid AA, Kim H. Optimization of Spiking Neural Networks Based on Binary Streamed Rate Coding. Electronics. 2020; 9(10):1599. https://doi.org/10.3390/electronics9101599
Chicago/Turabian StyleAl-Hamid, Ali A., and HyungWon Kim. 2020. "Optimization of Spiking Neural Networks Based on Binary Streamed Rate Coding" Electronics 9, no. 10: 1599. https://doi.org/10.3390/electronics9101599
APA StyleAl-Hamid, A. A., & Kim, H. (2020). Optimization of Spiking Neural Networks Based on Binary Streamed Rate Coding. Electronics, 9(10), 1599. https://doi.org/10.3390/electronics9101599