SOFIA: Selection of Medical Features by Induced Alterations in Numeric Labels

 ,
,  ,
,
Abstract
1. Introduction
- It considers the improvement of multi-target prediction models, allowing to know in advance whether a multi-stage treatment will be effective when no session has yet been made. The data transformation that leads to a high prediction percentage (optimal solution) has been efficiently explored by means of the SOFIA method, which improves the results expected by the use of the unmodified datasets when training prediction models.
- A multi-objective extension of the natural optimization (NO) approach for SA has been considered with a single-objective NO. For the proposed Multi-Objective Natural Optimization (MONO), the use of the hypervolume metric has been considered to accept those promising solutions. Moreover, MONO considers a parallel execution of the multi-objective optimization with the purpose of diminishing the computational cost [17].
- The proposed SOFIA methodology is applied in a realistic scenario when analyzing EMRs of migraineurs under the OnabotulinumtoxinA (BoNT-A) treatment. In this way, the multi-target prediction models have benefited significantly when performing the SOFIA method, achieving mean accuracies close to 88%. In addition, the selected medical features achieved through the SOFIA method have reduced the economic cost associated to collect all the medical features from a patient, allowing us to focus only on those that allow to know in advance the response that the treatment will have in the patients.
2. Related Work
3. Methodology
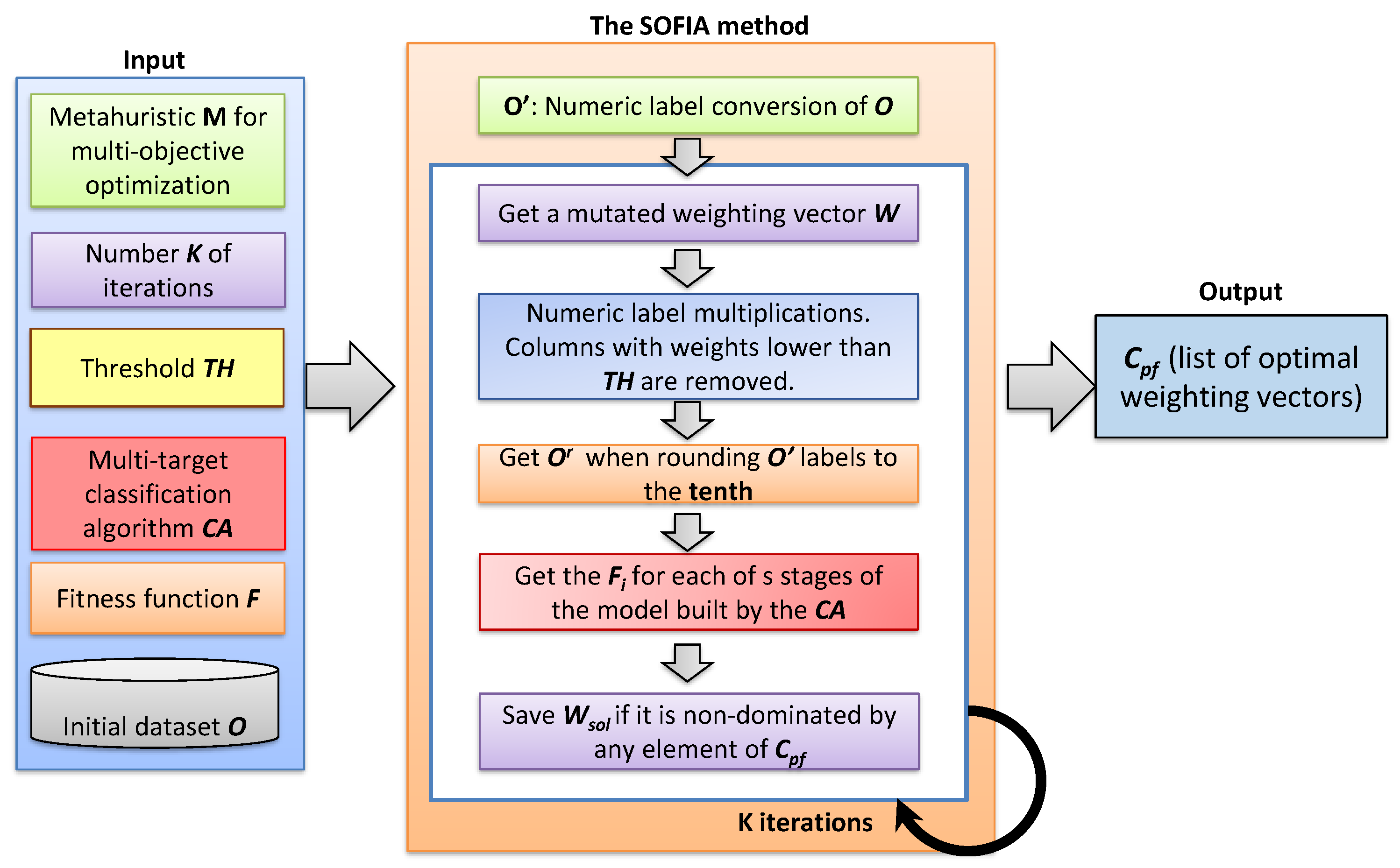
3.1. The Sofia Method
- An initial dataset O containing m clinical records, each containing the same set of n features (columns) .
- The selected metaheuristic algorithm () for performing the multi-objective optimization.
- The number K of iterations to be performed by .
- A threshold to discard features with weights below this value.
- The selected multi-target classification algorithm () to build the prediction model M.
- The fitness function F, which refers to the selected evaluation metric (like F-score or accuracy) for measuring the precision of every s stage in M.
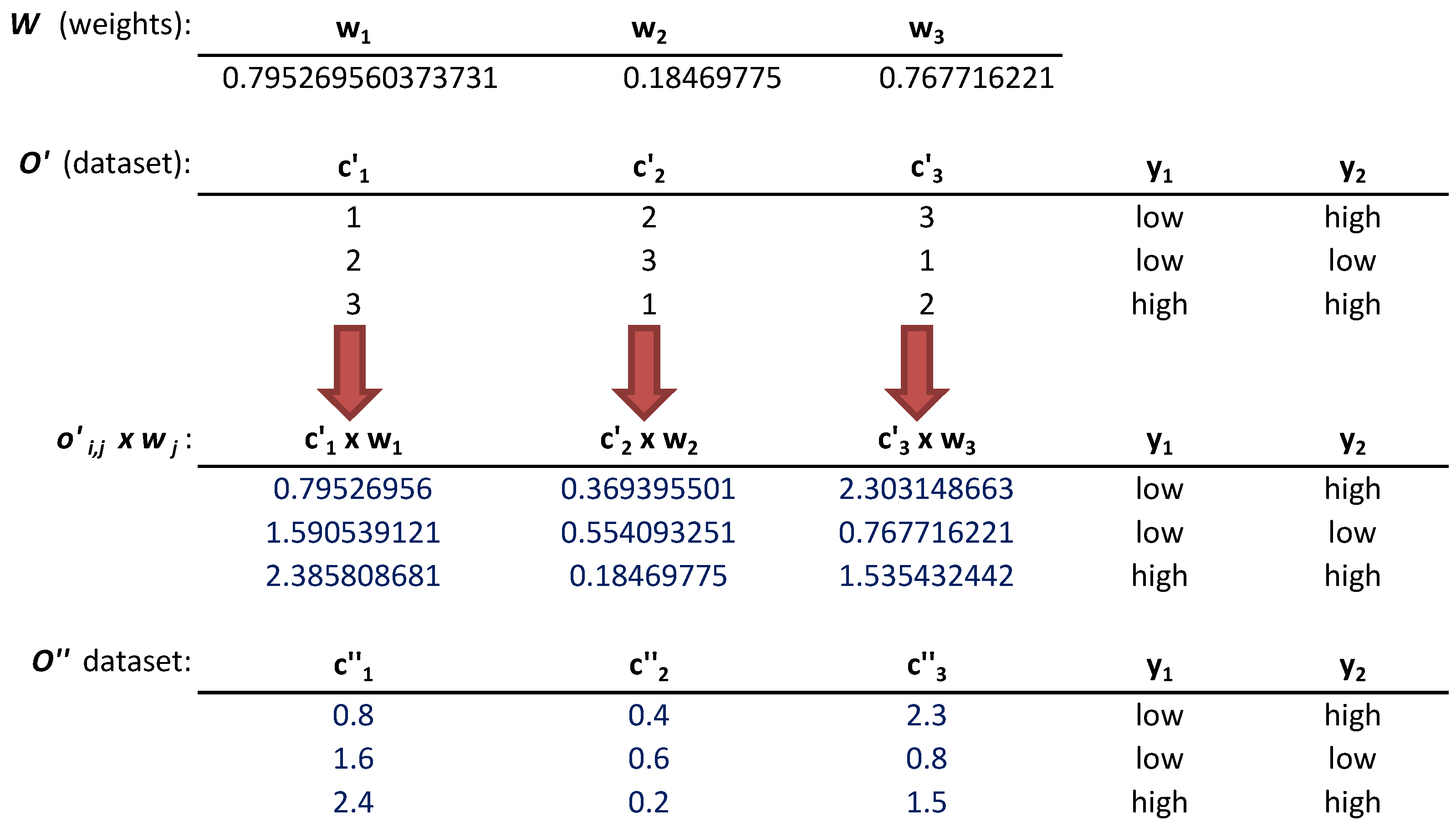
- The conversion of nominal labels of O to numbers was done following a consecutive order of integers beginning with 1. It is done for the n columns of O. The modified dataset was called with as modified columns.
- Once the dataset was generated, the next step was performing the feature weighting task. For it, the found the optimal weights , , i.e., one for each column that optimize the fitness values of every s stage in multi-target prediction models. The weights will reflect the degree of relevance of a column for a problem to solve, where . Those whose were lower than were discarded. The current weighting vector solution were shaped by those weights.
- The numeric labels of every cell were multiplied by the corresponding weight through the operation, , and , . This multiplication is illustrated in Figure 2.
- The dataset was rounded to the tenth, generating the modified dataset. The rounding to the tenth operation has been selected due the good results achieved in [9] when generating small perturbations among the different numeric labels in each column [30,31]. These rounded labels generated modifications in the prediction models learned by the multi-target classification algorithms that work with real numbers. An example of this step is shown in Figure 2.
- The prediction models were learned by the multi-target classification algorithm when it is trained with the modified dataset . The fitness value for each of the s stages (, ) of is obtained when performing the fitness function F on it.
- The goals to be optimized by MA are be the maximization or minimization of the fitness value of each of the s stages separately. If the current is a non-dominated solution, the current Pareto front () is updated when adding to it, removing the dominated elements from the list.
3.2. Mono: Multi-Objective Natural Optimization Approach for Simulated Annealing
- At the beginning of the execution, multiple initial solutions () were generated, one for each thread, instead of only handling one initial solution.
- were saved in the Pareto front list () when it is non-dominated by any element of instead of replacing the current best solution () by when its fitness value is lower than the obtained by .
- Some changes in the computation of and T were done for extending Equation (3) to the multi-objective optimization. More specifically, the QHV method was employed to compute the hypervolume occupied by , and for the multi-objective optimization. These changes are exposed in Equations (4) and (5).where N is the number of iterations, K is a constant that refers to the backward degree and time/quality trade-off and has been set to 1, and , and refer to the current solution, Pareto front and initial solution, respectively.
- The inputs of the algorithm are the number of iterations (N), the number of threads to perform () and the multi-objective fitness function.
- A unique list of current non-dominated solutions () is created. This list was accessible for all threads for allowing them to know whether a new solution is non-dominated by any of that list.
- Different initial solutions () were generated, one for each thread. Moreover, a number (N) of iterations to be performed for each thread was assigned.
- For each thread:
- In the beginning, the current solution () was equal to the initial solution ().
- A rollback solution () was defined as the before mutation. After that, the was mutated.
- The fitness value of the current solution () was computed when performing the multi-objective fitness function.
- A lock was applied for providing exclusive access to the while the non-dominated comparison of any thread was performed.
- The goodness of was evaluated when verifying that it was not dominated by any of the elements of .
- If the list was empty or if was non-dominated, was added to the list. After that, the list was evaluated in order to remove any dominated solution.
- The lock was removed.
- If was dominated by any element of the list and for avoiding to get trapped in a local minimum, the R ≤ P comparison was evaluated, where R is a generated random number and P is computed with Equation (3) but applying the changes expressed in Equations (4) and (5). If R ≤ P is true, is kept. Otherwise, a rollback is done when replacing by .
- The task was performed on each thread until the assigned number of iterations was completed. After that, the non-dominated solutions are contained in the list.
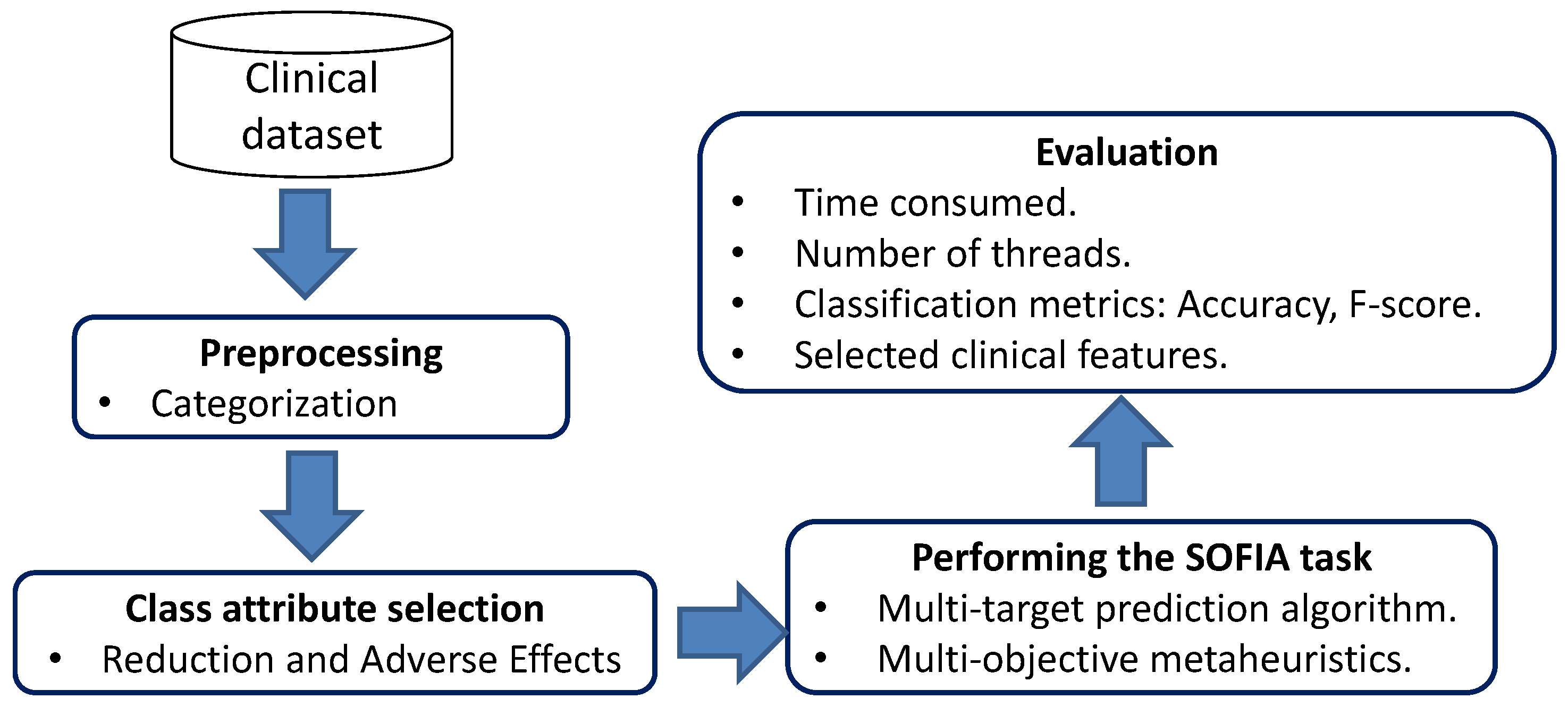
4. Analysis Case
4.1. Clinical Dataset
4.2. Categorization of Clinical Features
4.3. Class Attribute Selection
4.4. Performing the Sofia Method
5. Experiments
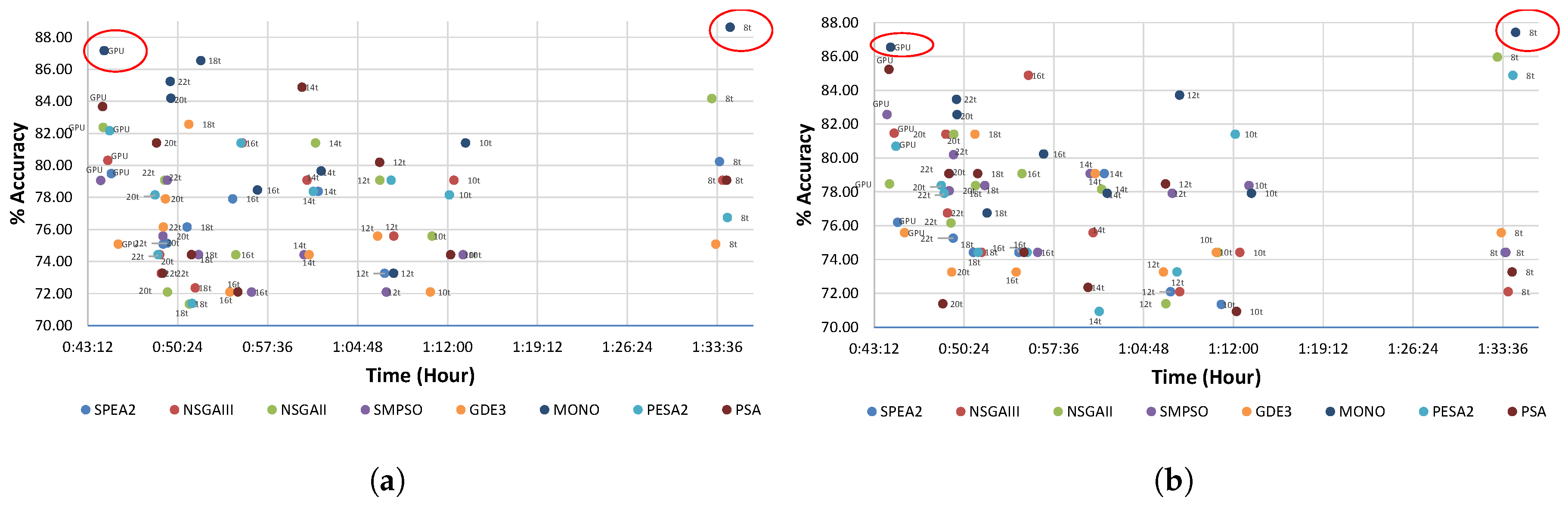
5.1. Runtime
5.2. Accuracy
5.3. Trade-Off Study
5.4. Selection of Medical Features
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| SOFIA | Selection Of medical Features by Induced Alterations |
| BoNT-A | OnabotulinumtoxinA |
| SA | Simulated annealing |
| PSA | Parallel Simulated annealing |
| RT | Random trees |
| PCT | Predictive clustering trees |
| NO | Natural optimization |
| MONO | Multi-objective Natural optimizationapproach for Simulated Annealing |
| MOEA | Multi-objective evolutionary algorithms |
| GPU | Graphics processing unit |
| HW | Hardware |
| FSS | Feature Subset Selection |
| EMRs | Electronic medical records |
| GDE3 | third version of the generalized differential evolution |
| PESA2 | Pareto Envelope-based Selection Algorithm |
| SMPSO | Speed-constrained Multi-objective Particle Swarm Optimisation Algorithm |
| NSGA | Non-dominated Sorting Genetic Algorithm |
References
- Wu, S.S.; Chan, K.S.; Bae, J.; Ford, E.W. Electronic clinical reminder and quality of primary diabetes care. Prim. Care Diabetes 2019, 13, 150–157. [Google Scholar] [CrossRef] [PubMed]
- Parrales, F.; Del Barrio García, A.; Gallego, M.; Gago, A.V.; Ruiz, M.; Guerrero, A.P.; Ayala, J. Prediction of patient’s response to OnabotulinumtoxinA treatment for migraine. Heliyon 2019, 5, e01043. [Google Scholar] [CrossRef]
- Leidner, A.J.; Chesson, H.W.; Xu, F.; Ward, J.W.; Spradling, P.R.; Holmberg, S.D. Cost-effectiveness of hepatitis C treatment for patients in early stages of liver disease. Hepatology 2015, 61, 1860–1869. [Google Scholar] [CrossRef]
- Rein, D.B.; Wittenborn, J.S.; Smith, B.D.; Liffmann, D.K.; Ward, J.W. The cost-effectiveness, health benefits, and financial costs of new antiviral treatments for hepatitis C virus. Clin. Infect. Dis. 2015, 61, 157–168. [Google Scholar] [CrossRef] [PubMed]
- Ruggeri, M. The cost effectiveness of Botox in Italian patients with chronic migraine. Neurol. Sci. 2014, 35, 45–47. [Google Scholar] [CrossRef] [PubMed]
- Cabitza, F.; Ciucci, D.; Rasoini, R. A giant with feet of clay: On the validity of the data that feed machine learning in medicine. In Organizing for the Digital World; Springer: New York, NY, USA, 2019; pp. 121–136. [Google Scholar]
- Armañanzas, R.; Bielza, C.; Chaudhuri, K.R.; Martinez-Martin, P.; Larrañaga, P. Unveiling relevant non-motor Parkinson’s disease severity symptoms using a machine learning approach. Artif. Intell. Med. 2013, 58, 195–202. [Google Scholar] [CrossRef] [PubMed]
- Parrales Bravo, F.; Del Barrio García, A.; Gallego de la Sacristana, M.; López Manzanares, L.; Vivancos, J.; Ayala Rodrigo, J. Support system to improve reading activity in parkinson’s disease and essential tremor patients. Sensors 2017, 17, 1006. [Google Scholar] [CrossRef] [PubMed]
- Parrales, F.; Del Barrio, A.A.; Gago, A.B.; Gallego, M.M.; Ruiz, M.; Peral, A.G.; Dzeroski, S.; Ayala, J.L. SMURF: Systematic Methodology for Unveiling Relevant Factors in retrospective data on chronic disease treatments. IEEE Access 2019, 1. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef]
- Parrales, F.; Del Barrio, A.A.; Ayala, J.L. A study on the parallelization of MOEAs to predict the patient’s response to the OnabotulinumtoxinA Treatment. In Proceedings of the 2019 Summer Simulation Multi-Conference. Society for Computer Simulation International, San Diego, CA, USA, 22–24 July 2019; p. 12. [Google Scholar]
- Ram, D.J.; Sreenivas, T.; Subramaniam, K.G. Parallel simulated annealing algorithms. J. Parallel Distrib. Comput. 1996, 37, 207–212. [Google Scholar] [CrossRef]
- Rundo, L.; Tangherloni, A.; Galimberti, S.; Cazzaniga, P.; Woitek, R.; Sala, E.; Nobile, M.S.; Mauri, G. HaraliCU: GPU-powered Haralick feature extraction on medical images exploiting the full dynamics of gray-scale levels. In Proceedings of the International Conference on Parallel Computing Technologies, Almaty, Kazakhstan, 3–7 September 2019; pp. 304–318. [Google Scholar]
- Manogaran, G.; Thota, C.; Lopez, D.; Vijayakumar, V.; Abbas, K.M.; Sundarsekar, R. Big data knowledge system in healthcare. In Internet of Things and Big Data Technologies for Next Generation Healthcare; Springer: New York, NY, USA, 2017; pp. 133–157. [Google Scholar]
- Huddar, V.; Desiraju, B.K.; Rajan, V.; Bhattacharya, S.; Roy, S.; Reddy, C.K. Predicting complications in critical care using heterogeneous clinical data. IEEE Access 2016, 4, 7988–8001. [Google Scholar] [CrossRef]
- Collen, M.F.; Ball, M.J. The History of Medical Informatics in the United States; Springer: New York, NY, USA, 2015. [Google Scholar]
- Durillo, J.J.; Nebro, A.J.; Luna, F.; Alba, E. A study of master-slave approaches to parallelize NSGA-II. In Proceedings of the 2008 IEEE International Symposium on Parallel and Distributed Processing, Sydney, Australia, 10–12 December 2008; pp. 1–8. [Google Scholar]
- Waegeman, W.; Dembczyński, K.; Hüllermeier, E. Multi-target prediction: A unifying view on problems and methods. Data Min. Knowl. Discov. 2019, 33, 293–324. [Google Scholar] [CrossRef]
- Meng, X.; Jiang, R.; Lin, D.; Bustillo, J.; Jones, T.; Chen, J.; Yu, Q.; Du, Y.; Zhang, Y.; Jiang, T.; et al. Predicting individualized clinical measures by a generalized prediction framework and multimodal fusion of MRI data. Neuroimage 2017, 145, 218–229. [Google Scholar] [CrossRef] [PubMed]
- Wathieu, H.; Ojo, A.; Dakshanamurthy, S. Prediction of chemical multi-target profiles and adverse outcomes with systems toxicology. Curr. Med. Chem. 2017, 24, 1705–1720. [Google Scholar] [CrossRef]
- Wang, X.; Zhen, X.; Li, Q.; Shen, D.; Huang, H. Cognitive assessment prediction in Alzheimer’s disease by multi-layer multi-target regression. Neuroinformatics 2018, 16, 285–294. [Google Scholar] [CrossRef]
- De Vicente, J.; Lanchares, J.; Hermida, R. Adaptive FPGA placement by natural optimisation. In Proceedings of the 11th International Workshop on Rapid System Prototyping. RSP 2000. Shortening the Path from Specification to Prototype, Paris, France, 21–23 June 2000; pp. 188–193. [Google Scholar] [CrossRef]
- Coello, C.A.C.; Lamont, G.B.; Van Veldhuizen, D.A. Evolutionary Algorithms for Solving Multi-Objective Problems; Springer: New York, NY, USA, 2007; Volume 5. [Google Scholar]
- Van Veldhuizen, D.A.; Lamont, G.B. Multiobjective evolutionary algorithms: Analyzing the state-of-the-art. Evol. Comput. 2000, 8, 125–147. [Google Scholar] [CrossRef]
- Ng, H.G.; Kerzel, M.; Mehnert, J.; May, A.; Wermter, S. Classification of MRI Migraine Medical Data Using 3D Convolutional Neural Network. In Proceedings of the International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; pp. 300–309. [Google Scholar]
- Li, J.; Chen, Q.; Liu, B. Classification and disease probability prediction via machine learning programming based on multi-GPU cluster MapReduce system. J. Supercomput. 2017, 73, 1782–1809. [Google Scholar] [CrossRef]
- Pogorelov, K.; Riegler, M.; Halvorsen, P.; Schmidt, P.T.; Griwodz, C.; Johansen, D.; Eskeland, S.L.; de Lange, T. GPU-accelerated real-time gastrointestinal diseases detection. In Proceedings of the 2016 IEEE 29th International Symposium on Computer-Based Medical Systems (CBMS), Dublin, Ireland, 20–24 June 2016; pp. 185–190. [Google Scholar]
- Zitzler, E.; Deb, K.; Thiele, L. Comparison of multiobjective evolutionary algorithms: Empirical results. Evol. Comput. 2000, 8, 173–195. [Google Scholar] [CrossRef]
- Alba, E.; Tomassini, M. Parallelism and evolutionary algorithms. IEEE Trans. Evol. Comput. 2002, 6, 443–462. [Google Scholar] [CrossRef]
- Higham, N.J. Accuracy and Stability of Numerical Algorithms; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2002; Volume 80, p. 54. [Google Scholar]
- García Planas, M.I.; Tarragona Romero, S. Perturbación de los valores propios simples de matrices de polinomios dependientes diferenciablemente de parámetros. In Proceedings of the 2nd Meeting on Linear Algebra Matrix analysis and applications, Valencia, Spain, 2–4 June 2010; pp. 1–7. [Google Scholar]
- Laszczyk, M.; Myszkowski, P.B. Survey of quality measures for multi-objective optimization. Construction of complementary set of multi-objective quality measures. Swarm Evol. Comput. 2019, 48, 109–133. [Google Scholar] [CrossRef]
- Deng, J.; Zhang, Q. Approximating hypervolume and hypervolume contributions using polar coordinate. IEEE Trans. Evol. Comput. 2019, 23, 913–918. [Google Scholar] [CrossRef]
- Russo, L.M.; Francisco, A.P. Quick hypervolume. IEEE Trans. Evol. Comput. 2013, 18, 481–502. [Google Scholar] [CrossRef]
- Lovati, C.; Giani, L. Action mechanisms of Onabotulinum toxin-A: Hints for selection of eligible patients. Neurol. Sci. 2017, 38, 131–140. [Google Scholar] [CrossRef] [PubMed]
- Silberstein, S.D.; Dodick, D.W.; Aurora, S.K.; Diener, H.C.; DeGryse, R.E.; Lipton, R.B.; Turkel, C.C. Per cent of patients with chronic migraine who responded per onabotulinumtoxinA treatment cycle: PREEMPT. J. Neurol. Neurosurg. Psychiatry 2015, 86, 996–1001. [Google Scholar] [CrossRef]
- Yang, M.; Rendas-Baum, R.; Varon, S.F.; Kosinski, M. Validation of the Headache Impact Test (HIT-6™) across episodic and chronic migraine. Cephalalgia 2011, 31, 357–367. [Google Scholar] [CrossRef]
- Gasbarrini, A.; De, A.L.; Fiore, G.; Gambrielli, M.; Franceschi, F.; Ojetti, V.; Torre, E.; Gasbarrini, G.; Pola, P.; Giacovazzo, M. Beneficial effects of Helicobacter pylori eradication on migraine. Hepato-Gastroenterology 1998, 45, 765–770. [Google Scholar]
- Kukkonen, S.; Lampinen, J. GDE3: The third evolution step of generalized differential evolution. In Proceedings of the 2005 IEEE Congress on Evolutionary Computation, Scotland, UK, 2–5 September 2005; pp. 443–450. [Google Scholar]
- Corne, D.W.; Jerram, N.R.; Knowles, J.D.; Oates, M.J. PESA-II: Region-based selection in evolutionary multiobjective optimization. In Proceedings of the 3rd Annual Conference on Genetic and Evolutionary Computation; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2001; pp. 283–290. [Google Scholar]
- Nebro, A.J.; Durillo, J.J.; Garcia-Nieto, J.; Coello, C.C.; Luna, F.; Alba, E. Smpso: A new pso-based metaheuristic for multi-objective optimization. In Proceedings of the Computational Intelligence in Miulti-Criteria Decision-Making, Nashville, TN, USA,, 30 March–2 April 2009; pp. 66–73. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Deb, K.; Jain, H. An evolutionary many-objective optimization algorithm using reference-point-based nondominated sorting approach, part I: Solving problems with box constraints. IEEE Trans. Evol. Comput. 2014, 18, 577–601. [Google Scholar] [CrossRef]
- Zitzler, E.; Laumanns, M.; Thiele, L. SPEA2: Improving the strength Pareto evolutionary algorithm. TIK-Report 2001, 103, 1–20. [Google Scholar]
- Hadka, D. MOEA Framework. 2019. Available online: http://moeaframework.org/ (accessed on 6 June 2019).
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Sokolova, M.; Japkowicz, N.; Szpakowicz, S. Beyond accuracy, F-score and ROC: A family of discriminant measures for performance evaluation. In Australasian Joint Conference on Artificial Intelligence; Springer: New York, NY, USA, 2006; pp. 1015–1021. [Google Scholar]
- Chen, T.; Tang, K.; Chen, G.; Yao, X. A large population size can be unhelpful in evolutionary algorithms. Theor. Comput. Sci. 2012, 436, 54–70. [Google Scholar] [CrossRef]
- Zitzler, E.; Thiele, L. Multiobjective evolutionary algorithms: A comparative case study and the strength Pareto approach. IEEE Trans. Evol. Comput. 1999, 3, 257–271. [Google Scholar] [CrossRef]
- Fumero, J.; Papadimitriou, M.; Zakkak, F.S.; Xekalaki, M.; Clarkson, J.; Kotselidis, C. Dynamic application reconfiguration on heterogeneous hardware. In Proceedings of the 15th ACM SIGPLAN/SIGOPS International Conference on Virtual Execution Environments, Providence, RI, USA, 13–14 April 2019; pp. 165–178. [Google Scholar]
- Wang, C.; Mu, D.; Zhao, F.; Sutherland, J.W. A parallel simulated annealing method for the vehicle routing problem with simultaneous pickup–delivery and time windows. Comput. Ind. Eng. 2015, 83, 111–122. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Toxin-Age of Onset (Years) | Body Mass Index (kg/m2) | Hemoglobin (g/dL) | Creatinine (mg/dL) | Platelets (u/mcL) | Reduction Effects (1–4) |
|---|---|---|---|---|---|
| 51 | 20.39 | 13.4 | 0.71 | 213,000 | 4 |
| 49 | 26.5 | 14.2 | 0.55 | 252,000 | 2 |
| 36 | 23.15 | 13.5 | 0.44 | 304,000 | 3 |
| 26 | 17.7 | 13.1 | 0.66 | 218,000 | 2 |
| 31 | NA | 14.8 | 0.71 | 327,000 | 1 |
| 50 | NA | 16.2 | 0.74 | 327,000 | 3 |
| Reduction Effects (R) | Adverse Effects (A) | R/A | Categorized Value |
|---|---|---|---|
| 1 | 1 | 1 | low |
| 2 | 1 | 2 | high |
| 3 | 2 | 1.5 | high |
| 1 | 2 | 0.5 | low |
| Response | Stage 1 | Stage 2 |
|---|---|---|
| high | 98 | 71 |
| low | 75 | 102 |
| Methods | Number of Threads | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 4 | 6 | 8 | 10 | 12 | 14 | 16 | 18 | 20 | 22 | GPU | |
| MONO | 8:10:14 | 4:07:31 | 2:29:23 | 2:05:51 | 1:34:38 | 1:13:27 | 1:07:41 | 1:01:53 | 0:56:47 | 0:52:15 | 0:49:51 | 0:49:48 | 0:44:31 |
| PSA | 8:15:28 | 4:05:19 | 2:28:43 | 2:05:27 | 1:34:21 | 1:12:15 | 1:06:34 | 1:00:21 | 0:55:13 | 0:51:30 | 0:48:42 | 0:49:11 | 0:44:23 |
| SPEA2 | 8:16:53 | 4:06:08 | 2:30:37 | 2:04:26 | 1:33:47 | 1:11:02 | 1:06:58 | 1:01:39 | 0:54:48 | 0:51:09 | 0:49:14 | 0:49:32 | 0:45:05 |
| NSGAIII | 8:12:20 | 4:05:14 | 2:28:52 | 2:03:54 | 1:34:02 | 1:12:31 | 1:07:42 | 1:00:45 | 0:55:34 | 0:51:48 | 0:48:57 | 0:49:05 | 0:44:48 |
| NSGAII | 8:12:04 | 4:05:12 | 2:28:48 | 2:04:35 | 1:33:10 | 1:10:46 | 1:06:35 | 1:01:26 | 0:55:03 | 0:51:20 | 0:49:35 | 0:49:21 | 0:44:26 |
| SMPSO | 8:13:02 | 4:06:16 | 2:29:04 | 2:06:17 | 1:33:51 | 1:13:15 | 1:07:06 | 1:00:31 | 0:56:19 | 0:52:04 | 0:49:13 | 0:49:34 | 0:44:14 |
| PESA2 | 8:16:53 | 4:07:01 | 2:29:27 | 2:05:21 | 1:34:25 | 1:12:09 | 1:07:29 | 1:01:15 | 0:55:28 | 0:51:33 | 0:48:35 | 0:48:49 | 0:44:57 |
| GDE3 | 8:13:02 | 4:06:08 | 2:29:45 | 2:04:38 | 1:33:29 | 1:10:38 | 1:06:24 | 1:00:55 | 0:54:35 | 0:51:17 | 0:49:25 | 0:49:15 | 0:45:38 |
| Metaheuristic Algorithm | HW | First Stage | Second Stage | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Accuracy | Sensitivity | Specificity | F-Score | Accuracy | Sensitivity | Specificity | F-Score | ||
| No metaheuristic | 1 thread | 61.63% | 65.17% | 25.84% | 63,95% | 62.79% | 75.14% | 57.61% | 60.45% |
| FSS + RT (without SAR) | 1 thread | 68.14% | 64.78% | 70.25% | 66.13% | 67.45% | 70.21% | 65.18% | 65.43% |
| NO + RT [11] | 1 thread | 84.93% | 87.56% | 81.45% | 82.35% | 85.74% | 83.24% | 88.14% | 83.17% |
| MONO | 8 threads | 88.62% | 89.58% | 86.58% | 87.91% | 87.42% | 85.16% | 89.61% | 86.73% |
| PSA | GPU | 83.67% | 84.17% | 80.38% | 80.07% | 85.23% | 83.49% | 89.61% | 85.18% |
| SPEA2 | GPU | 79.48% | 75.94% | 81.45% | 77.15% | 76.19% | 81.24% | 75.56% | 77.18% |
| NSGAIII | 16 threads | 81.39% | 77.61% | 83.29% | 79.17% | 84.88% | 83.29% | 78.14% | 80.52% |
| NSGAII | 8 threads | 84.17% | 83.29% | 78.71% | 82.28% | 85.96% | 86.26% | 81.95% | 83.62% |
| SMPSO | GPU | 79.06% | 82.31% | 75.09% | 78.35% | 82.56% | 81.45% | 84.26% | 80.94% |
| PESA2 | 8 threads | 76.74% | 82.31% | 71.25% | 73.56% | 84.88% | 76.56% | 82.31% | 74.21% |
| GDE3 | 18 threads | 82.56% | 85.74% | 77.31% | 77.52% | 81.39% | 76.29% | 83.29% | 77.08% |
| Metaheuristic Applied | Number of Features | Selected Clinical Features |
|---|---|---|
| FSS+RT (without SAR) | 11 | Sex, Chronic migraine time evolution, GON, Drugs tested before toxin, Preventive oral treatment, catamenial, Concomitant treatment with statins, Gastropathy, Pneumopathy, Headache days per month, Analgesics days per month |
| NO+RT [11] | 16 | Retroocular component, GGT, Migraine days per month, Drugs tested before toxin, Neuromodulator, Concomitant antihypertensive treatment, Enolism, Analgesics days per month, 1st grade family with migraine, Unilateral pain, GON, Chronic migraine time evolution, Anxiety, Platelets, Pneumopathy, Serum iron |
| MONO | 14 | Headache days per month, Migraine days per month, Chronic migraine time evolution, GON, Hemoglobin, Analgesic abuse, Serum iron, 1st grade family with migraine, Retroocular component, Unilateral pain, Platelets, Anxiety, Concomitant oral preventive treatment, Onset age of toxin treatment |
| SPEA2 | 14 | Chronic migraine time evolution, Hemoglobin, Analgesic abuse, Retroocular component, GON, Anxiety, Onset age of toxin treatment, 1st grade family with migraine, Headache days per month, GGT, Migraine days per month, Drugs tested before toxin, Neuromodulator, tricyclic antidepressants |
| NSGAIII | 15 | Onset age of toxin treatment, Migraine days per month, Chronic migraine time evolution, drugs tested before toxin, vitamin B12, GON, Preventive oral treatment at time of infiltration, Tricyclic antidepressants, Calcium antagonists, Catamenial, Concomitant oral preventive treatment, Gastropathy, Headache days per month, Analgesic abuse, Unilateral pain |
| NSGAII | 11 | Unilateral pain, GON, 1st grade family with migraine, Onset age of toxin treatment, Serum iron, Creatinine, Analgesic abuse, Preventive oral treatment at time of infiltration, Neuromodulator, Concomitant antidepressant treatment, Chronic migraine time evolution, Retroocular component |
| SMPSO | 11 | Headache days per month, GGT, Migraine days per month, Drugs tested before toxin, Neuromodulator, Concomitant oral preventive treatment, Enolism, Analgesic abuse, 1st grade family with migraine, Unilateral pain, GON |
| PESA2 | 10 | Chronic migraine time evolution, Anxiety, 1st grade family with migraine, Analgesic abuse, Platelets, Headache days per month, Unilateral pain, Migraine days per month, GON, Onset age of toxin treatment |
| GDE3 | 15 | Drugs tested before toxin, Concomitant oral preventive treatment, Headache days per month, Enolism, Analgesic abuse, 1st grade family with migraine, GGT, Migraine days per month, Chronic migraine time evolution, Hemoglobin, Retroocular component, GON, Anxiety, Onset age of toxin treatment, tricyclic antidepressants |
| Clinical Features | Frequency |
|---|---|
| GON | 9 |
| Chronic migraine time evolution | 8 |
| Headache days per month | 7 |
| Migraine days per month | 7 |
| 1st grade family with migraine | 7 |
| Analgesic abuse | 7 |
| Drugs tested before toxin | 6 |
| Unilateral pain | 6 |
| Onset age of toxin treatment | 6 |
| Retroocular component | 5 |
| Anxiety | 5 |
| GGT | 4 |
| Neuromodulator | 4 |
| Preventive oral treatment | 3 |
| Enolism | 3 |
| Platelets | 3 |
| Serum iron | 3 |
| Hemoglobin | 3 |
| Tricyclic antidepressants | 3 |
| Catamenial | 2 |
| Gastropathy | 2 |
| Pneumopathy | 2 |
| Analgesics days per month | 2 |
| Sex | 1 |
| Concomitant treatment with statins | 1 |
| Concomitant antihypertensive treatment | 1 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bravo, F.P.; García, A.A.D.B.; Russo, L.M.S.; Ayala, J.L. SOFIA: Selection of Medical Features by Induced Alterations in Numeric Labels. Electronics 2020, 9, 1492. https://doi.org/10.3390/electronics9091492
Bravo FP, García AADB, Russo LMS, Ayala JL. SOFIA: Selection of Medical Features by Induced Alterations in Numeric Labels. Electronics. 2020; 9(9):1492. https://doi.org/10.3390/electronics9091492
Chicago/Turabian StyleBravo, Franklin Parrales, Alberto A. Del Barrio García, Luis M. S. Russo, and Jose L. Ayala. 2020. "SOFIA: Selection of Medical Features by Induced Alterations in Numeric Labels" Electronics 9, no. 9: 1492. https://doi.org/10.3390/electronics9091492
APA StyleBravo, F. P., García, A. A. D. B., Russo, L. M. S., & Ayala, J. L. (2020). SOFIA: Selection of Medical Features by Induced Alterations in Numeric Labels. Electronics, 9(9), 1492. https://doi.org/10.3390/electronics9091492