Reformulating the Binary Masking Approach of Adress as Soft Masking


Abstract
:1. Introduction
2. Mixing Model
2.1. Adress
2.2. Problem
3. Separation via Azimuth Trajectories
- When the azimugram can be simplifiedas the product of ’s azimuth trajectory and ’s spectral content at that frequency.
- When the azimugram can be expressed ashowever, from the triangle inequality, it holds thatExpressing this portion of the azimugram as the product of source trajectories, and , and their corresponding source spectral content is an approximation.
4. Reconstruction
| Algorithm 1: Summary of the Redress Algorithm |
| Result: Separated sources |
| Compute the STFT of both channels, and ; |
| Compute the frequency azimuth plane by constructing and (Equations (8) and (9)); |
| Form the azimuth trajectory matrix, , using Equations (22)–(24); |
| Recover the sources by solving the NQP in Equation (25); |
| Extract the sources from the columns of the source magnitude TF Spectra matrix, , matrix in Equation (26); |
| Reconstruct the source magnitude spectra using Equation (27); |
| Use the mixture phase to reconstruct the discrete-time sources; |
5. Evaluation
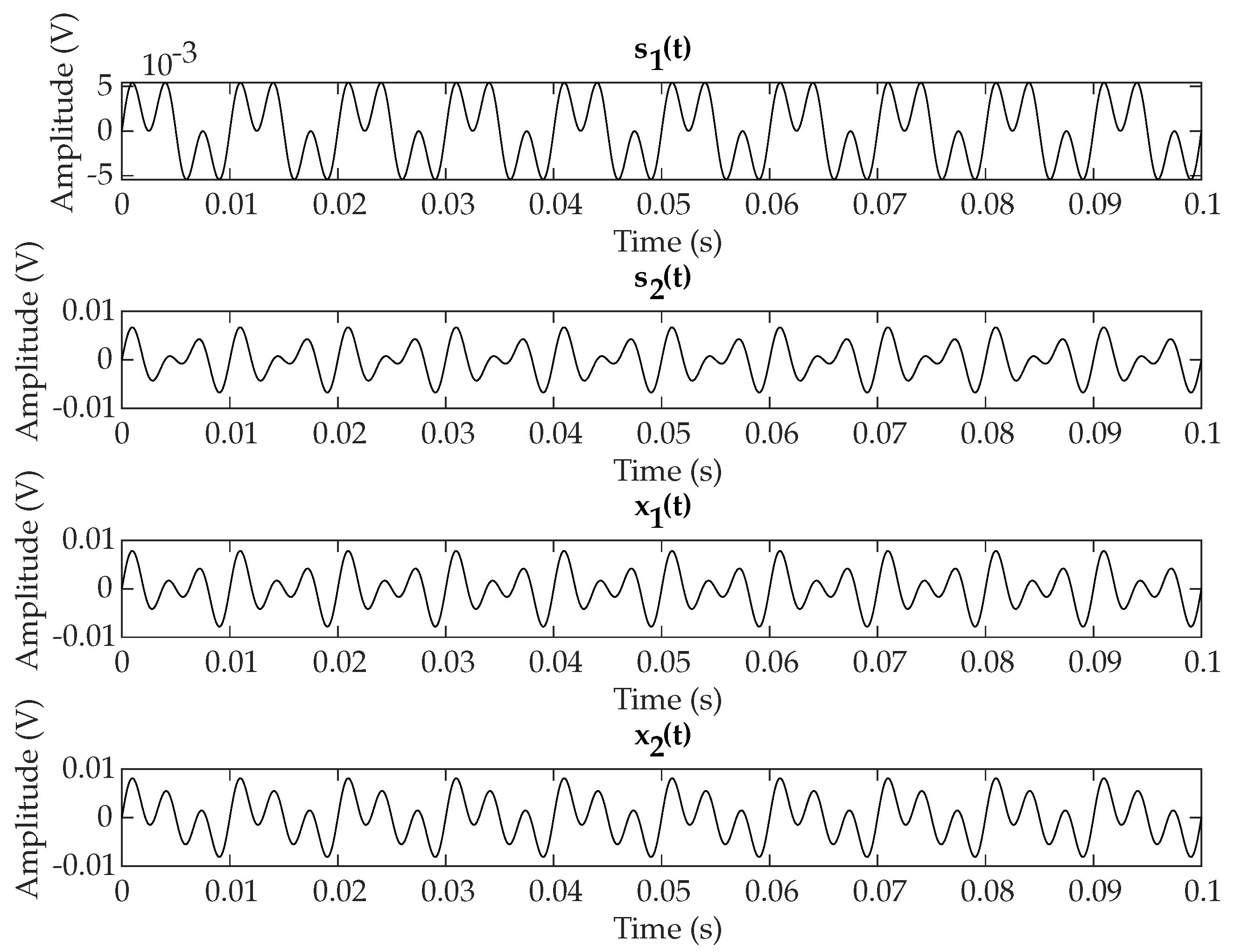
5.1. Separation Example: Redress
5.2. Overlapping Sources in TF
5.3. Discussion and Future Work
6. Conclusions
Funding
Conflicts of Interest
References
- Barker, J.; Watanabe, W.; Vincent, E.; Trmal, J. The fifth chime speech separation and recognition challenge: Dataset, task and baselines. arXiv 2018, arXiv:1803.10609. [Google Scholar]
- Wang, D. Time-frequency masking for speech separation and its potential for hearing aid design. Trends Amplif. 2008, 12, 332–353. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cano, E.; FitzGerald, D.; Liutkus, A.; Plumbley, M.; Stöter, F. Musical Source Separation: An Introduction. IEEE Signal Process. Mag. 2019, 36, 31–40. [Google Scholar] [CrossRef]
- Yilmaz, O.; Rickard, S. Blind separation of speech mixtures via time-frequency masking. IEEE Trans. Signal Process. 2004, 52, 1830–1847. [Google Scholar] [CrossRef]
- Barry, D.; Lawlor, B.; Coyle, E. Sound Source Separation: Azimuth Discrimination and Resynthesis. In Proceedings of the 7th International Conference on Digital Audio Effects, Naples, Italy, 5–8 October 2004. [Google Scholar]
- de Fréin, R.; Rickard, S.T. The Synchronized Short-Time-Fourier-Transform: Properties and Definitions for Multichannel Source Separation. IEEE Trans. Signal Process. 2011, 59, 91–103. [Google Scholar] [CrossRef] [Green Version]
- de Fréin, R.; Rickard, S.T. Power-Weighted Divergences for Relative Attenuation and Delay Estimation. IEEE Signal Process. Lett. 2016, 23, 1612–1616. [Google Scholar] [CrossRef] [Green Version]
- Barry, D. Real-Time Sound Source Separation for Music Applications. Ph.D. Thesis, Technological University Dublin, Dublin, Ireland, 2019. [Google Scholar] [CrossRef]
- FitzGerald, D.; Liutkus, A.; Badeau, R. Projection-Based Demixing of Spatial Audio. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 1560–1572. [Google Scholar] [CrossRef]
- Duong, N.; Vincent, E.; Gribonval, R. Under-Determined Reverberant Audio Source Separation Using a Full-Rank Spatial Covariance Model. IEEE Trans. Audio Speech Lang. Process. 2010, 18, 1830–1840. [Google Scholar] [CrossRef] [Green Version]
- Fitzgerald, D.; Coyle, E.; Cranitch, M. Using Tensor Factorisation Models to Separate Drums from Polyphonic Music. In Proceedings of the International Conference on Digital Audio Effects (DAFX09), Como, Italy, 1–4 September 2009; pp. 1–4. [Google Scholar]
- Yoshii, K.; Goto, M.; Okuno, H.G. Drum Sound Recognition for Polyphonic Audio Signals by Adaptation and Matching of Spectrogram Templates With Harmonic Structure Suppression. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 333–345. [Google Scholar] [CrossRef] [Green Version]
- Gillet, O.; Richard, G. Transcription and Separation of Drum Signals From Polyphonic Music. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 529–540. [Google Scholar] [CrossRef] [Green Version]
- Wang, D.; Chen, J. Supervised Speech Separation Based on Deep Learning: An Overview. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1702–1726. [Google Scholar] [CrossRef] [PubMed]
- Luo, Y.; Mesgarani, N. TaSNet: Time-Domain Audio Separation Network for Real-Time, Single-Channel Speech Separation. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 696–700. [Google Scholar]
- Luo, Y.; Mesgarani, N. Conv-TasNet: Surpassing Ideal Time–Frequency Magnitude Masking for Speech Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1256–1266. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, D.; Seung, H. Algorithms for Non-Negative Matrix Factorization; MIT Press: Cambridge, MA, USA, 2000; pp. 556–562. [Google Scholar]
- Virtanen, T. Monaural Sound Source Separation by Nonnegative Matrix Factorization with Temporal Continuity and Sparseness Criteria. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 1066–1074. [Google Scholar] [CrossRef] [Green Version]
- de Fréin, R. Remedying Sound Source Separation via Azimuth Discrimination and Re-synthesis. In Proceedings of the Irish Signals and Systems Conference, Donegal, Ireland, 11–12 June 2020. [Google Scholar]
- Liutkus, A.; Stöter, F.; Rafii, Z.; Kitamura, D.; Rivet, B.; Ito, N.; Ono, N.; Fontecave, J. The 2016 Signal Separation Evaluation Campaign. In Latent Variable Analysis and Signal Separation; Tichavský, P., Babaie-Zadeh, M., Michel, O., Thirion-Moreau, N., Eds.; Springer: Cham, Switzerland, 2017; pp. 323–332. [Google Scholar]
- Vincent, E.; Gribonval, R.; Fevotte, C. Performance measurement in blind audio source separation. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1462–1469. [Google Scholar] [CrossRef] [Green Version]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bass | Drums | Other Instruments | Voice | |
|---|---|---|---|---|
| Redress | 11.8667 | 14.5693 | - | - |
| Adress | 10.7585 | 11.4251 | - | - |
| Redress | - | 13.3784 | 15.7878 | - |
| Adress | - | 11.4412 | 12.1051 | - |
| Redress | - | - | 10.4634 | 13.4975 |
| Adress | - | - | 9.3739 | 10.3778 |
| Redress | 13.0597 | - | - | 16.4422 |
| Adress | 10.1297 | - | - | 8.7984 |
| Bass | Drums | Other Instruments | Voice | |
|---|---|---|---|---|
| Redress | 9.8884 | 10.8795 | 8.7282 | - |
| Adress | 10.0437 | 8.6279 | 7.4703 | - |
| Redress | 9.0305 | 11.5192 | - | 8.8494 |
| Adress | 9.0694 | 9.7596 | - | 7.3313 |
| Redress | 10.7974 | - | 10.7052 | 8.2186 |
| Adress | 10.8326 | - | 8.5726 | 7.7733 |
| Redress | - | 10.1772 | 9.6942 | 7.6430 |
| Adress | - | 10.1582 | 7.8717 | 7.0842 |
| Bass | Drums | Other Instruments | Voice | |
|---|---|---|---|---|
| Redress | 6.0854 | 8.7291 | 5.8795 | 4.1330 |
| Adress | 5.2224 | 7.3386 | 5.0702 | 6.8377 |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
de Fréin, R. Reformulating the Binary Masking Approach of Adress as Soft Masking. Electronics 2020, 9, 1373. https://doi.org/10.3390/electronics9091373
de Fréin R. Reformulating the Binary Masking Approach of Adress as Soft Masking. Electronics. 2020; 9(9):1373. https://doi.org/10.3390/electronics9091373
Chicago/Turabian Stylede Fréin, Ruairí. 2020. "Reformulating the Binary Masking Approach of Adress as Soft Masking" Electronics 9, no. 9: 1373. https://doi.org/10.3390/electronics9091373
APA Stylede Fréin, R. (2020). Reformulating the Binary Masking Approach of Adress as Soft Masking. Electronics, 9(9), 1373. https://doi.org/10.3390/electronics9091373