Automatic Identification of High Impact Relevant Articles to Support Clinical Decision Making Using Attention-Based Deep Learning




Abstract
:1. Introduction
2. Background and State of the Art
2.1. TREC Evaluation
2.2. Pre-Trained Text Classification
2.3. Contextualized Word Representations
2.4. Contextualized Word Embedding for Information Retrieval
2.5. Self-Attention Model
2.6. Scoring Mechanisms for Information Retrieval
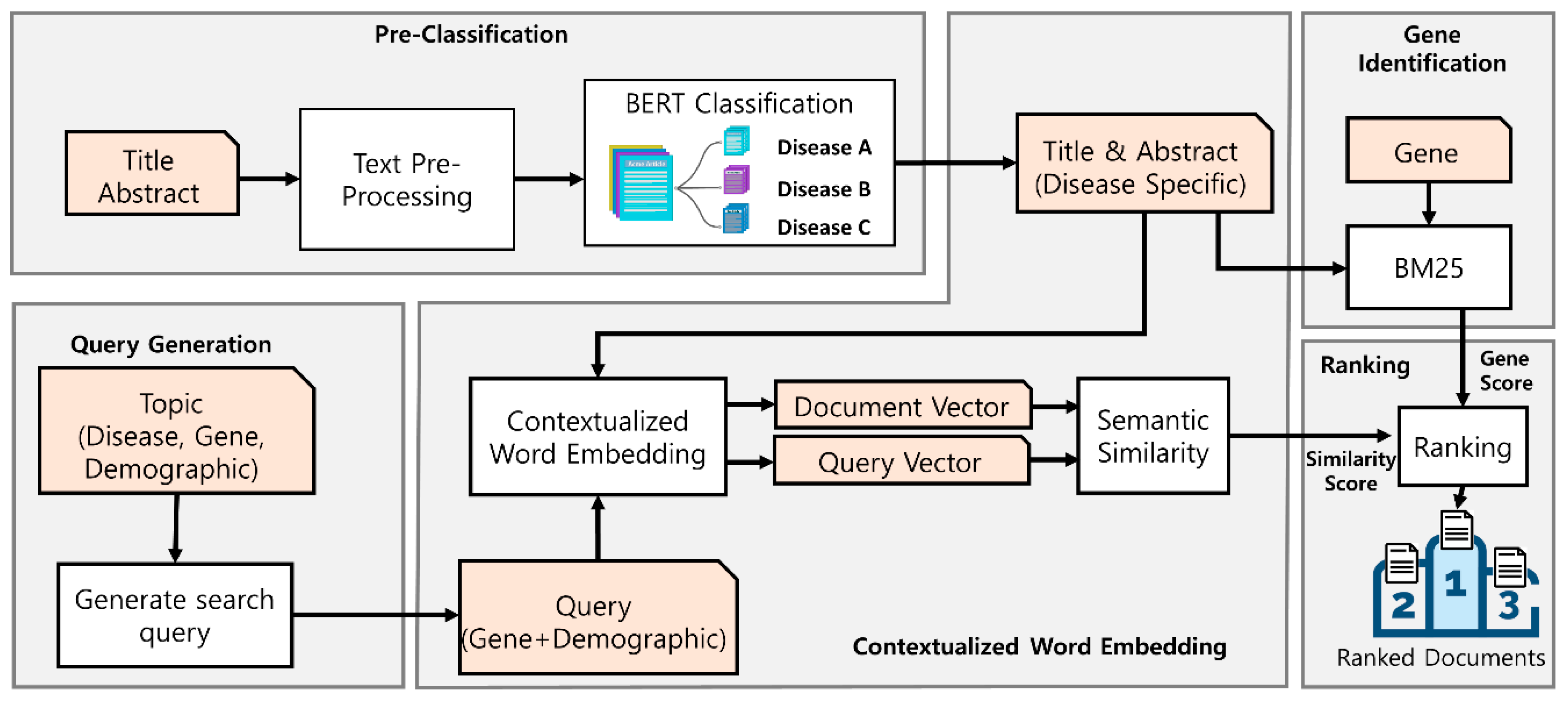
3. Materials and Methods
3.1. Data Acquisition
3.2. Pre-Classification for Disease
3.3. Query Creation
3.4. Sentence Similarity with Contextualized Word Embedding
3.5. Gene Importance Score
| Algorithm 1. Algorithms to find document ranking based on similarity score aggregation. |
| Input: D: The list of documents G: Topic Gene Data Q: Query Output: RD: Ranked list of documents according to their relevance score |
| Begin: 1. foreach title and abstract in D do: 2. title_tokenization← tokenizer.tokenize(title) 3. abstracts_tokenization ← tokenizer.tokenize(abstract) 4. endfor 5. title_embedding ← embedder.bertencoder(title_tokenization) 6. abstract_embedding ← embedder.bertencoder(abstracts_tokenization) 7. query_embedding ← embedder.bertencoder(Q) 8. title_bm25ranking ← bm25raking (title_tokenization) 9. abstract_bm25ranking ← bm25raking (abstracts_tokenization) 10. title_bm25_score ← title_bm25ranking.get_scores(tokenizer.tokenize(G)) *2 11. abstract_bm25_score ← abstract_bm25ranking.get_scores(tokenizer.tokenize(G)) *2 12. total_bm25_Score ← title_bm25_score + abstract_bm25_score 13. embedding_score_title ← sum (query_embedding * title_embedding)/title_embedding 14. embedding_score_abstract ← sum (query_embedding *abstract_embedding)/abstract_embedding 15. top_doc_ids ← get_top(embedding_score_title + embedding_score_abstract + total_bm25_Score) 16. foreach id in top_doc_ids do: 17. score ← (embedding_score_title[id] + embedding_score_abstract[id] +total_bm25_Score[id]) 18. RD ← get (D[“id”], D[“Title”], score) 19. endfor 20. return RD 21. End |
4. Results
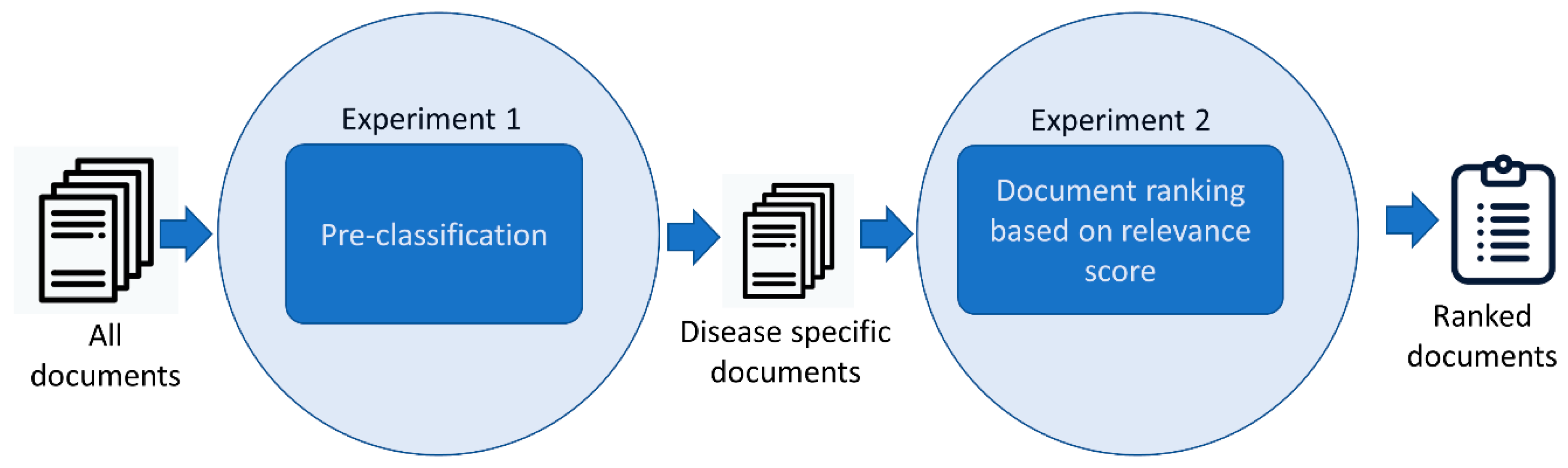
4.1. Experiment Design
4.2. Pre-Classification Results and evaluation
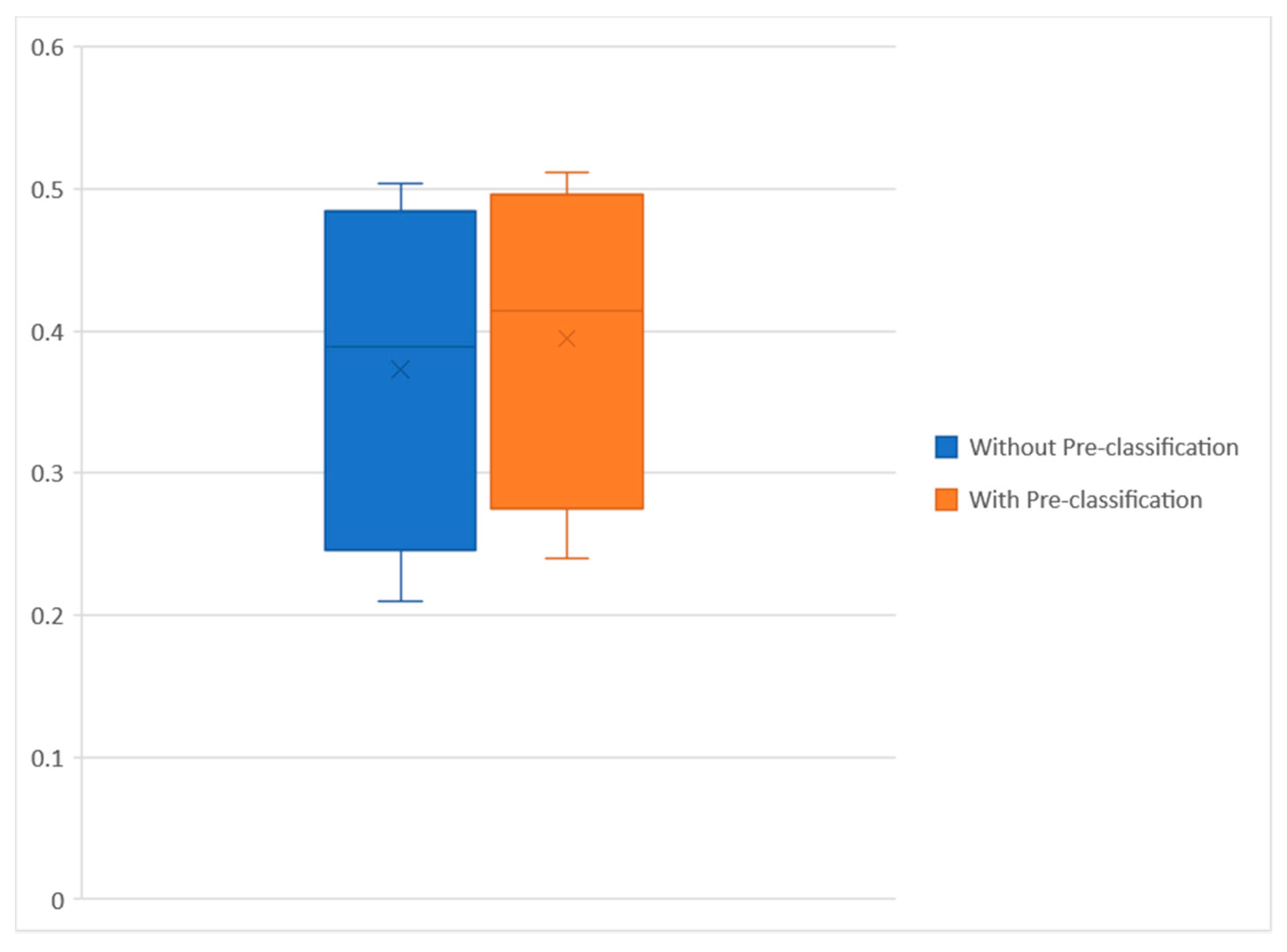
4.3. Relevance Document Ranking
- Relevance ranking results without pre-classification of health condition
- Relevance ranking results with pre-classification of health condition
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Topic | Query | ||
|---|---|---|---|
| Disease | Gene | Demographic | |
| Melanoma | BRAF (V600E) | 64-year-old male | BRAF V600E in old adult males |
| Melanoma | BRAF (V600K) | 54-year-old male | BRAF V600K in middle adult males |
| Melanoma | BRAF (V600R) | 80-year-old male | BRAF V600R in middle old males |
| Melanoma | BRAF (K601E) | 38-year-old male | BRAF K601E in adult males |
| Melanoma | BRAF (V600E), PTEN loss of function | 57-year-old male | BRAF V600E PTEN loss of function in old adult males |
| Melanoma | BRAF (V600E), NRAS (Q61R) | 67-year-old male | BRAF V600E NRAS Q61R in old males |
| Melanoma | BRAF amplification | 61-year-old male | BRAF amplification in old adult males |
| Melanoma | NRAS (Q61R) | 63-year-old female | NRAS Q61R in old adult females |
| Melanoma | NRAS (Q61L) | 34-year-old female | NRAS Q61L in adult females |
| Melanoma | KIT (L576P) | 65-year-old female | KIT L576P in old adult females |
| Melanoma | KIT (L576P), KIT amplification | 56-year-old female | KIT L576P KIT amplification in old adult females |
| Melanoma | KIT (K642E) | 62-year-old female | KIT K642E in old adult females |
| Melanoma | KIT (N822Y) | 39-year-old female | KIT N822Y in adult females |
| Melanoma | KIT amplification | 66-year-old female | KIT amplification in old adult females |
| Melanoma | NF1 truncation | 70-year-old male | NF1 truncation in old adult males |
| Melanoma | NTRK1 rearrangement | 60-year-old male | NTRK1 rearrangement in old adult males |
| Melanoma | TP53 loss of function | 72-year-old male | TP53 loss of function in old adult males |
| Melanoma | tumor cells with >50% membranous PD-L1 expression | 48-year-old female | tumor cells with >50% membranous PD-L1 expression in adult females |
| Melanoma | tumor cells negative for PD-L1 expression | 73-year-old male | tumor cells negative for PD-L1 expression in old adult males |
| Melanoma | high tumor mutational burden | 86-year-old female | high tumor mutational burden in old adult males |
| Melanoma | extensive tumor infiltrating lymphocytes | 49-year-old male | extensive tumor infiltrating lymphocytes in adult males |
| Melanoma | no tumor infiltrating lymphocytes | 74-year-old female | no tumor infiltrating lymphocytes in old adult females |
| Melanoma | PTEN loss of function | 68-year-old male | PTEN loss of function in old adult males |
| Melanoma | APC loss of function | 47-year-old male | APC loss of function in adult males |
| Melanoma | high serum LDH levels | 69-year-old female | high serum LDH levels in old adult females |
References
- Bian, J.; Abdelrahman, S.; Shi, J.; Del Fiol, G. Automatic identification of recent high impact clinical articles in PubMed to support clinical decision making using time-agnostic features. J. Biomed. Inform. 2019, 89, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Bian, J.; Morid, M.A.; Jonnalagadda, S.; Luo, G.; Del Fiol, G. Automatic identification of high impact articles in PubMed to support clinical decision making. J. Biomed. Inform. 2017, 73, 95–103. [Google Scholar] [CrossRef] [PubMed]
- Afzal, M.; Hussain, M.; Malik, K.M.; Lee, S. Undefined Impact of Automatic Query Generation and Quality Recognition Using Deep Learning to Curate Evidence from Biomedical Literature: Empirical Study. JMIR Med. Inform. 2019, 7. [Google Scholar] [CrossRef] [PubMed]
- MacAvaney, S.; Cohan, A.; Yates, A.; Goharian, N. CEDR: Contextualized embeddings for document ranking. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 1101–1104. [Google Scholar]
- Text REtrieval Conference (TREC) Overview. Available online: https://trec.nist.gov/overview.html (accessed on 19 February 2020).
- GitHub—Usnistgov/trec_eval: Evaluation Software Used in the Text Retrieval Conference. Available online: https://github.com/usnistgov/trec_eval (accessed on 20 February 2020).
- Kalchbrenner, N.; Grefenstette, E.; Blunsom, P. A convolutional neural network for modelling sentences. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 22 June 2014; Volume 1, pp. 655–665. [Google Scholar]
- Zhang, X.; LeCun, Y. Text Understanding from Scratch. Adv. Neural Inf. Process. Syst. 2015, 649–657. [Google Scholar]
- Duque, A.B.; Santos, L.L.J.; Macêdo, D.; Zanchettin, C. Squeezed very deep convolutional neural networks for text classification. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Munich, Germany, 17–19 September 2019; Volume 11727, pp. 193–207. [Google Scholar]
- Johnson, R.; Zhang, T. Deep pyramid convolutional neural networks for text categorization. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1, pp. 562–570. [Google Scholar]
- Yogatama, D.; Dyer, C.; Ling, W.; Blunsom, P. Generative and Discriminative Text Classification with Recurrent Neural Networks. arXiv 2017, arXiv:1703.01898. [Google Scholar]
- Lin, Z.; Feng, M.; Dos Santos, C.N.; Yu, M.; Xiang, B.; Zhou, B.; Bengio, Y. A structured self-attentive sentence embedding. In Proceedings of the 5th International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Sun, C.; Qiu, X.; Xu, Y.; Huang, X. How to fine-tune BERT for text classification? In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Berlin, Germany, 13 June 2019; Volume 11856, pp. 194–206. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. 2018. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 21 August 2020).
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 8 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Manning, C.D.; Schütze, H.; Weikurn, G. Foundations of Statistical Natural Language Processing. SIGMOD Rec. 2002, 31, 37–38. [Google Scholar]
- Sundermeyer, M.; Ney, H.; Schluter, R. From feedforward to recurrent LSTM neural networks for language modeling. IEEE Trans. Audio Speech Lang. Process. 2015, 23, 517–529. [Google Scholar] [CrossRef]
- Mikolov, T.; Kombrink, S.; Burget, L.; Černocký, J.; Khudanpur, S. Extensions of recurrent neural network language model. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Prague, Czech Republic, 22–27 May 2011; pp. 5528–5531. [Google Scholar]
- Li, F.; Jin, Y.; Liu, W.; Rawat, B.P.S.; Cai, P.; Yu, H. Undefined Fine-Tuning Bidirectional Encoder Representations from Transformers (BERT)–Based Models on Large-Scale Electronic Health Record Notes: An Empirical. JMIR Med. Inform. 2019, 7, e14830. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 2227–2237. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 2017, pp. 5999–6009. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2019. [Google Scholar] [CrossRef] [PubMed]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. In Proceedings of the 1st International Conference on Learning Representations, Scottsdale, AZ, USA, 2–4 May 2013. [Google Scholar]
- Contextualized Word Embedding (Concept)—Woosung Choi’s Blog. Available online: http://intelligence.korea.ac.kr/members/wschoi/nlp/deeplearning/paperreview/Contextualized-Word-Embedding/ (accessed on 24 February 2020).
- Guo, J.; Fan, Y.; Ai, Q.; Croft, W.B. A deep relevance matching model for Ad-hoc retrieval. In Proceedings of the International Conference on Information and Knowledge Management, Indianapolis, IN, USA, 26–28 October 2016; pp. 55–64. [Google Scholar]
- Dai, Z.; Callan, J.; Xiong, C.; Liu, Z. Convolutional neural networks for soft-matching N-grams in ad-hoc search. In Proceedings of the 11th ACM International Conference on Web Search and Data Mining, Marina Del Rey, CA, USA, 5–9 February 2018; Volume 2018, pp. 126–134. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Dai, Z.; Callan, J. Deeper text understanding for IR with contextual neural language modeling. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 985–988. [Google Scholar]
- Yang, J.; Liu, Y.; Qian, M.; Guan, C.; Yuan, X. Information extraction from electronic medical records using multitask recurrent neural network with contextual word embedding. Appl. Sci. 2019, 9, 3658. [Google Scholar] [CrossRef] [Green Version]
- Juan Ramos Using tf-idf to determine word relevance in document queries. Proc. First Instr. Conf. Mach. Learn. 2003, 242, 29–48.
- Robertson, S.; Zaragoza, H. The probabilistic relevance framework: BM25 and beyond. Found. Trends Inf. Retr. 2009, 3, 333–389. [Google Scholar] [CrossRef]
- Oleynik, M.; Faessler, E.; Sasso, A.M.; Kappattanavar, A.; Bergner, B.; Freitas Da Cruz, H.; Sachs, J.-P.; Datta, S.; Böttinger, E. HPI-DHC at TREC 2018 Precision Medicine Track; TREC: Austin, TX, USA, 2018.
- Pasche, E.; Van Rijen, P.; Gobeill, J.; Mottaz, A.; Mottin, L.; Ruch, P. SIB text mining at TREC 2018 precision medicine track. In Proceedings of the TREC 2018 Conference, Gaithersburg, MD, USA, 14–16 November 2018. [Google Scholar]
- Ronzano, F.; Centeno, E.; Pérez-Granado, J.; Furlong, L. IBI at TREC 2018: Precision Medicine Track Notebook Paper; TREC: Austin, TX, USA, 2018.
- Taylor, S.J.; Goodwin, T.R.; Harabagiu, S.M. UTD HLTRI at TREC 2018: Precision Medicine Track; TREC: Austin, TX, USA, 2018.
- Zheng, Z.; Li, C.; He, B.; Xu, J. UCAS at TREC-2018 Precision Medicine Track; TREC: Austin, TX, USA, 2018.
- Zhou, X.; Chen, X.; Song, J.; Zhao, G.; Wu, J. Team Cat-Garfield at TREC 2018 Precision Medicine Track; TREC: Austin, TX, USA, 2018.
- Lopez, M.M.; Kalita, J. Deep Learning applied to NLP. arXiv 2017, arXiv:1703.03091. [Google Scholar]
- Zhou, P.; Qi, Z.; Zheng, S.; Xu, J.; Bao, H.; Xu, B. Text classification improved by integrating bidirectional LSTM with two-dimensional max pooling. In Proceedings of the 26th International Conference on Computational Linguistics, Osaka, Japan, 11–16 December 2016; pp. 3485–3495. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Zhou, P.; Shi, W.; Tian, J.; Qi, Z.; Li, B.; Hao, H.; Xu, B. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 207–212. [Google Scholar]
- Kenter, T.; De Rijke, M. Short text similarity with word embeddings. In Proceedings of the International Conference on Information and Knowledge Management, Melbourne, Australia, 19–23 October 2015; pp. 1411–1420. [Google Scholar]
- Zuccon, G.; Koopman, B.; Bruza, P.; Azzopardi, L. Integrating and evaluating neural word embeddings in information retrieval. In Proceedings of the ACM International Conference Proceeding Series, Parramatta, Australia, 8–9 December 2015; pp. 1–8. [Google Scholar]
- Ganguly, D.; Roy, D.; Mitra, M.; Jones, G.J.F. A word embedding based generalized language model for information retrieval. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 795–798. [Google Scholar]



| Topic | Query | ||
|---|---|---|---|
| Disease | Gene | Demographic | |
| Melanoma | BRAF (V600E) | 64-year-old male | BRAF V600E in old adult males |
| BRAF (V600E), PTEN loss of function | 57-year-old male | BRAF V600E PTEN loss of function in old adult males | |
| KIT (L576P), KIT amplification | 56-year-old female | KIT L576P KIT amplification in old adult females | |
| no tumor-infiltrating lymphocytes | 74-year-old female | no tumor-infiltrating lymphocytes in old adult females | |
| high serum LDH levels | 69-year-old female | high serum LDH levels in old adult females | |
| Health Condition | Train | Test |
|---|---|---|
| Breast Cancer | 4717 | 1179 |
| Healthy | 4918 | 1230 |
| HIV | 3945 | 986 |
| Melanoma | 1222 | 306 |
| Prostate Cancer | 2266 | 566 |
| Classifier | Precision | Recall | f1-Score | Accuracy | Training Time (min) |
|---|---|---|---|---|---|
| BERT | 0.96 | 0.95 | 0.95 | 0.95 | 1158.22 |
| Bi-LSTM | 0.95 | 0.95 | 0.95 | 0.94 | 1252.93 |
| RNN | 0.94 | 0.94 | 0.94 | 0.94 | 1284.69 |
| CNN | 0.93 | 0.93 | 0.93 | 0.93 | 62.32 |
| Method | P@5 | P@10 | P@15 | P@20 | P@30 | P@100 |
|---|---|---|---|---|---|---|
| CWE (Query) | 0.2100 | 0.1620 | 0.1253 | 0.1140 | 0.1060 | 0.0676 |
| CWE (Query) TF-IDF (Gene) | 0.3520 | 0.3500 | 0.2986 | 0.2548 | 0.1645 | 0.1150 |
| BM25 (Query) BM25 (Gene) | 0.4260 | 0.3600 | 0.3040 | 0.2860 | 0.2400 | 0.1380 |
| CWE (Query) and BM25 (Gene) | 0.5040 | 0.4200 | 0.3680 | 0.3260 | 0.2773 | 0.1824 |
| Method | P@5 | P@10 | P@15 | P@20 | P@30 | P@100 |
|---|---|---|---|---|---|---|
| CWE (Query) | 0.2400 | 0.1800 | 0.1400 | 0.1300 | 0.1100 | 0.0850 |
| CWE (Query) TF-IDF (Gene) | 0.3800 | 0.3900 | 0.3267 | 0.2700 | 0.2067 | 0.1390 |
| BM25 (Query) BM25 (Gene) | 0.4480 | 0.3880 | 0.3387 | 0.3020 | 0.2653 | 0.1800 |
| Proposed (CWE (Query) and BM25 (Gene) | 0.5120 | 0.4480 | 0.3840 | 0.3440 | 0.2893 | 0.1964 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, B.; Afzal, M.; Hussain, J.; Abbas, A.; Lee, S. Automatic Identification of High Impact Relevant Articles to Support Clinical Decision Making Using Attention-Based Deep Learning. Electronics 2020, 9, 1364. https://doi.org/10.3390/electronics9091364
Park B, Afzal M, Hussain J, Abbas A, Lee S. Automatic Identification of High Impact Relevant Articles to Support Clinical Decision Making Using Attention-Based Deep Learning. Electronics. 2020; 9(9):1364. https://doi.org/10.3390/electronics9091364
Chicago/Turabian StylePark, Beomjoo, Muhammad Afzal, Jamil Hussain, Asim Abbas, and Sungyoung Lee. 2020. "Automatic Identification of High Impact Relevant Articles to Support Clinical Decision Making Using Attention-Based Deep Learning" Electronics 9, no. 9: 1364. https://doi.org/10.3390/electronics9091364
APA StylePark, B., Afzal, M., Hussain, J., Abbas, A., & Lee, S. (2020). Automatic Identification of High Impact Relevant Articles to Support Clinical Decision Making Using Attention-Based Deep Learning. Electronics, 9(9), 1364. https://doi.org/10.3390/electronics9091364