Deep Learning Based Biomedical Literature Classification Using Criteria of Scientific Rigor




Abstract
1. Introduction
2. Background and Related Work
2.1. Use of Machine Learning and Deep Learning for Biomedical Literature Classification
2.2. Use of Cochrane Reviews for Annotation of Scientifically Rigor Studies
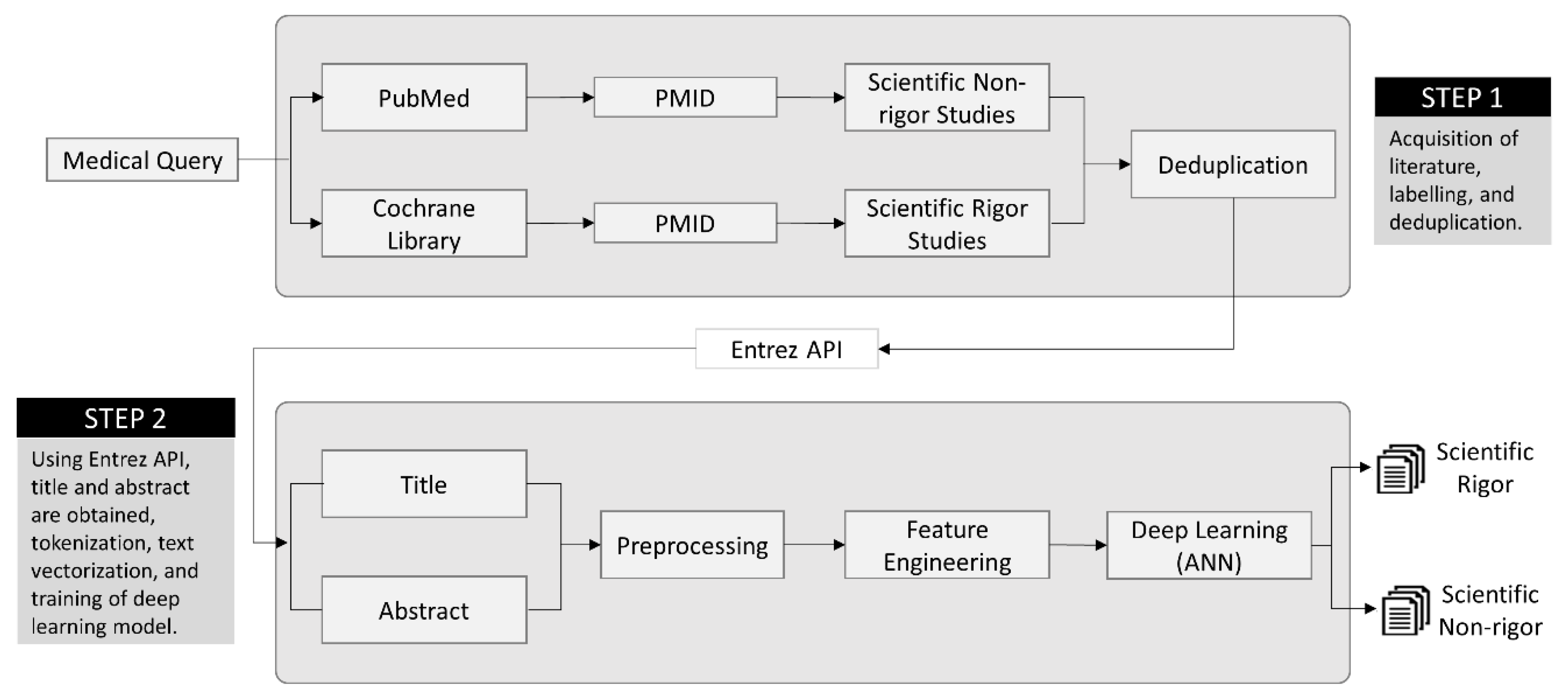
3. Methods
3.1. Step 1—Preparation of Datasets
3.2. Step 2—Development of Deep Learning Model
3.2.1. Preprocessing
3.2.2. Feature Extraction
3.2.3. Automatic Feature Engineering
3.2.4. Classification Model
3.2.5. Performance and Explanation
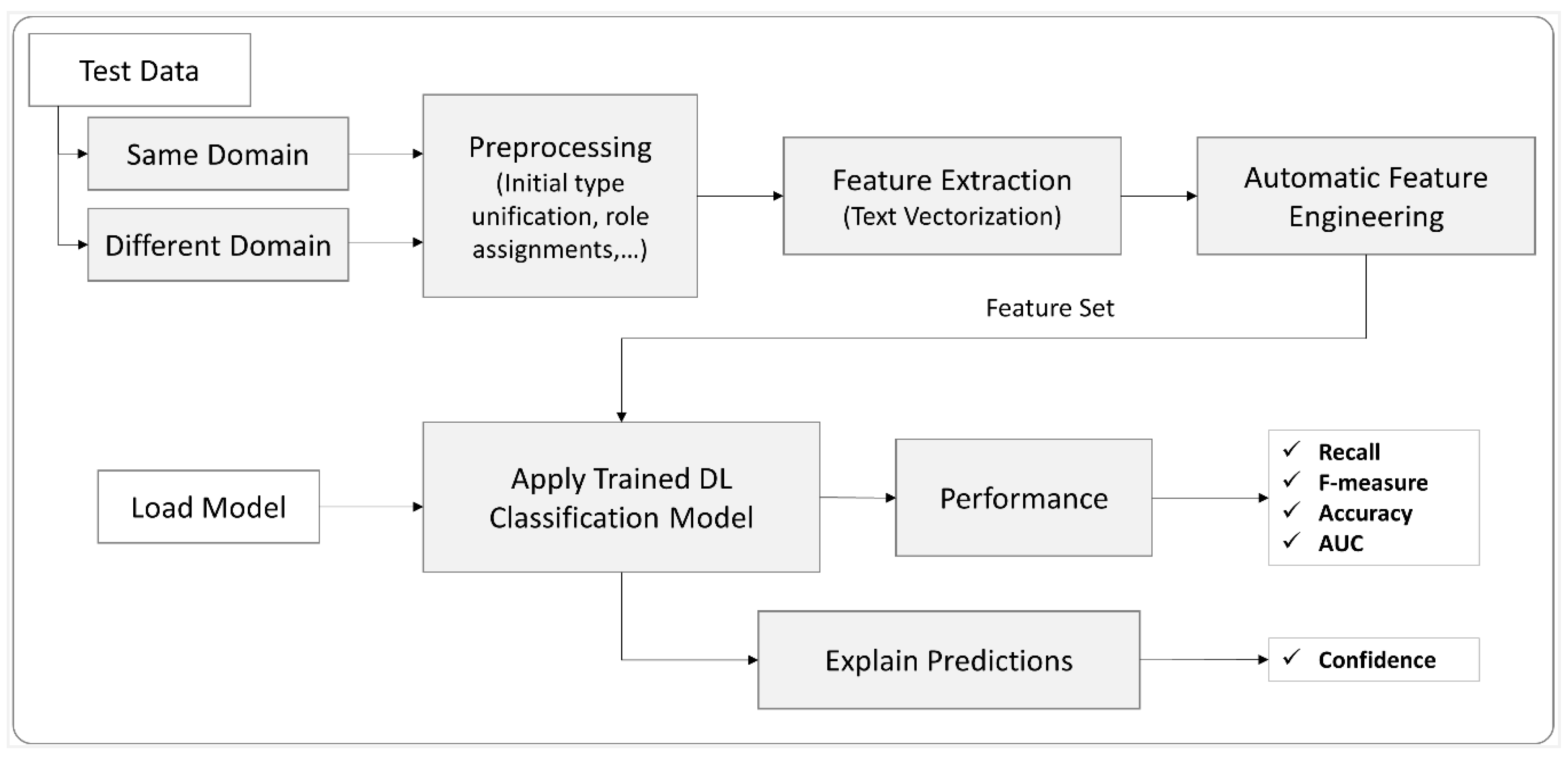
3.3. Model Selection
4. Results and Discussion
4.1. Scenario 1: Results of Same Domain Test Queries
4.2. Scenario 2: Different Domain Test Queries Results
4.3. Significant Findings
4.4. Comparison with Prior Work
4.5. Error Analysis
4.6. Limitation and Future Work
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Heneghan, C.; Mahtani, K.R.; Goldacre, B.; Godlee, F.; Macdonald, H.; Jarvies, D. Evidence based medicine manifesto for better healthcare. BMJ 2017, 357, j2973. [Google Scholar] [CrossRef] [PubMed]
- Güiza, F.; Ramon, J.; Bruynooghe, M. Machine learning techniques to examine large patient databases. Best Pract. Res. Clin. Anaesthesiol. 2009, 23, 127–143. [Google Scholar]
- Zhang, Y.; Lin, H.; Yang, Z.; Wang, J.; Sun, Y.; Xu, B.; Zhao, Z. Neural network-based approaches for biomedical relation classification: A review. J. Biomed. Inform. 2019, 99, 103294. [Google Scholar] [CrossRef] [PubMed]
- Burns, G.A.; Li, X.; Peng, N. Building deep learning models for evidence classification from the open access biomedical literature. Database 2019, 2019, 1–9. [Google Scholar] [CrossRef] [PubMed]
- McCartney, M.; Treadwell, J.; Maskrey, N.; Lehman, R. Making evidence based medicine work for individual patients. BMJ 2016, 353, i2452. [Google Scholar] [CrossRef] [PubMed]
- Krauthammer, M.; Nenadic, G. Term identification in the biomedical literature. J. Biomed. Inform. 2004, 37, 512–526. [Google Scholar] [CrossRef] [PubMed]
- Kilicoglu, H.; Demner-Fushman, D.; Rindflesch, T.C.; Wilczynski, N.L.; Haynes, R.B. Towards Automatic Recognition of Scientifically Rigorous Clinical Research Evidence. J. Am. Med. Inform. Assoc. 2009, 16, 25–31. [Google Scholar] [CrossRef] [PubMed]
- Shi, H.; Liu, Y. Naïve Bayes vs. Support. Vector Machine: Resilience to Missing Data; Springer: Berlin/Heidelberg, Germany, 2011; pp. 680–687. [Google Scholar]
- Khan, A.; Khan, A.; Baharudin, B.; Lee, L.H.; Khan, K.; Tronoh, U.T.P. A Review of Machine Learning Algorithms for Text-Documents Classification. J. Adv. Inf. Technol. VOL 2010, 1, 4–20. [Google Scholar]
- Anderlucci, L.; Guastadisegni, L.; Viroli, C. Classifying textual data: Shallow, deep and ensemble methods. arXiv 2019, arXiv:1902.07068. [Google Scholar]
- Kim, Y. Convolutional neural networks for sentence classification. In Proceedings of the EMNLP 2014-2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Del Fiol, G.; Michelson, M.; Iorio, A.; Cotoi, C.; Haynes, R.B. A Deep Learning Method to Automatically Identify Reports of Scientifically Rigorous Clinical Research from the Biomedical Literature: Comparative Analytic Study. J. Med. Internet Res. 2018, 20, e10281. [Google Scholar] [CrossRef] [PubMed]
- Sarker, A.; Mollá, D.; Paris, C. Automatic evidence quality prediction to support evidence-based decision making. Artif. Intell. Med. 2015, 64, 89–103. [Google Scholar] [CrossRef] [PubMed]
- Bian, J.; Morid, M.A.; Jonnalagadda, S.; Luo, G.; Del Fiol, G. Automatic identification of high impact articles in PubMed to support clinical decision making. J. Biomed. Inform. 2017, 73, 95–103. [Google Scholar] [CrossRef] [PubMed]
- Afzal, M.; Hussain, M.; Haynes, R.B.; Lee, S. Context-aware grading of quality evidences for evidence-based decision-making. Health Inform. J. 2017, 25, 146045821771956. [Google Scholar] [CrossRef] [PubMed]
- Satterlee, W.G.; Eggers, R.G.; Grimes, D.A. Effective Medical Education: Insights From the Cochrane Library. Obstet. Gynecol. Surv. 2008, 63, 329–333. [Google Scholar] [CrossRef] [PubMed]
- Armstrong, R.; Hall, B.J.; Doyle, J.; Waters, E. "Scoping the scope" of a cochrane review. J. Public Health (Bangkok) 2011, 33, 147–150. [Google Scholar] [CrossRef] [PubMed]
- Bethesda (MD): National Center for Biotechnology Information (US). Entrez Programming Utilities Help. 2010. Available online: https://www.ncbi.nlm.nih.gov/books/NBK25501/ (accessed on 1 July 2020).
- Winter, D.J. Rentrez: An R package for the NCBI eUtils API. R J. 2017, 9, 520–526. [Google Scholar] [CrossRef]
- Rapidminer Build Predictive Models, Faster & Better|RapidMiner Auto Model. Available online: https://rapidminer.com/products/auto-model/ (accessed on 18 July 2020).
- Wilczynski, N.L.; Morgan, D.; Haynes, R.B. An overview of the design and methods for retrieving high-quality studies for clinical care. BMC Med. Inform. Decis. Mak. 2005, 5, 1–8. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | Description |
|---|---|---|
| activation | Rectifier | Rectifier Linear Unit is the activation function used by the hidden layers to choose the maximum value of the input. |
| hidden layer sizes | Two layers each with a size of 50 neurons | The number of hidden layers is limited to only two layers for the reason of the simplicity and efficiency of the model. |
| local random seed | 1992 | Local random numbers are the pseudo-random number assigned initially to start the network. |
| epochs | 10.0 | The number of times the dataset should be iterated. |
| epsilon | 1.0 × 10−8 | Similar to the learning rate, it allows forward progress. |
| rho | 0.99 | rho is the “Gradient moving average decay factor” used for the learning rate decay over each update. |
| L1 | 1.0 × 10−5 | It is a regularization method that constrains the absolute value of the weights. |
| L2 | 0.0 | It is a regularization method that constrains the sum of the squared weights. |
| missing values handling | Mean Imputation | Missing values are replaced with the mean value. |
| Algorithm | Parameter Settings |
|---|---|
| Naïve Bayes | laplace correction (True) |
| Decision Tree | criterion (gain_ration), maximum depth (10), apply pruning (True) |
| Support Vector Machine | svm-type (c-SVC), kernel type (rbp), c (0.0) |
| Gradient Boosted Trees | number of trees (100), maximum depth (10), learning rate (0.01), sample rate (1.0) |
| Data Set: Title | |||||
| Method | ACC (%) | AUC | Recall (%) | F1 Score (%) | overall score |
| NB | 75.9 | 0.696 | 86.7 | 49.5 | 212.796 |
| MLP | 94.1 | 0.942 | 81.2 | 78.9 | 255.142 |
| DT | 91 | 0.679 | 36.2 | 52.1 | 179.979 |
| SVM | 94.8 | 0.968 | 71.8 | 79 | 246.568 |
| GBT | 92.74 | 0.941 | 70.87 | 72.62 | 237.171 |
| Data Set: Abstract | |||||
| Method | ACC (%) | AUC | Recall (%) | F1 Score (%) | overall score |
| NB | 90.1 | 0.882 | 89.2 | 70.9 | 251.082 |
| MLP | 92.1 | 0.967 | 89.1 | 75 | 257.167 |
| DT | 92.7 | 0.733 | 56.5 | 67.6 | 217.533 |
| SVM | 95.7 | 0.974 | 79.0 | 83.2 | 258.874 |
| GBT | 94.74 | 0.969 | 76.84 | 79.67 | 252.219 |
| Data Set: Title + Abstract | |||||
| Method | ACC (%) | AUC | Recall (%) | F1 Score (%) | overall score |
| NB | 88.2 | 0.830 | 87.4 | 66.9 | 243.33 |
| MLP | 97.3 | 0.993 | 95.1 | 90.4 | 283.793 |
| DT | 91.9 | 0.738 | 51.6 | 63.4 | 207.638 |
| SVM | 95.9 | 0.985 | 74.2 | 83.2 | 254.285 |
| GBT | 95.16 | 0.974 | 83.83 | 82.5 | 262.464 |
| Query | Number of Articles | ||
|---|---|---|---|
| High-Quality | General | ||
| Q1 | Chronic Kidney Disease | 1051 | 5527 |
| Q2 | Diabetic Kidney | 1045 | 5784 |
| Q3 | Kidney Transplantation | 1047 | 6732 |
| Q4 | Acute Kidney | 902 | 5398 |
| Query | ACC (%) | AUC | Recall (%) | F1 Score (%) |
|---|---|---|---|---|
| Q1 | 89.78 | 0.911 | 95.82 | 94.03 |
| Q2 | 91.17 | 0.877 | 96.53 | 94.87 |
| Q3 | 90.98 | 0.875 | 95.70 | 94.79 |
| Q4 | 88.77 | 0.852 | 95.97 | 93.61 |
| Domain | ACC (%) | AUC | Recall (%) | F1 Score (%) | Number of Datasets | |
|---|---|---|---|---|---|---|
| High-Quality | General | |||||
| Cancer | 88.08 | 0.781 | 99.12 | 93.5 | 1022 | 6569 |
| Research Work | AI Method Used | Performance Metric | Datasets and Features |
|---|---|---|---|
| Del Fiol et al. [12] | Deep Learning (CNN) | Recall 96.9% Precision 34.6% F-measure 51% | 403,216 PubMed citations with title and abstract as features. |
| Afzal et al. [15] | Support Vector Machines | ACC 92.14% | 50,594 MEDLINE documents with title, abstract, publication type, and MeSH Headings as features. |
| Bian et al. [14] | Naïve Bayes | Recall 77.5% | 15,845 PubMed citations with Scopus citation count and journal impact factor art the top two features followed by some other PubMed® metadata. |
| Proposed Method | Deep Learning (MLP) | ACC 97.3% AUC 0.993 Recall 95.1% F1 Score 90.4% Precision 86.25% | 7958 Cochrane Review/PubMed with title and abstract as features. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Afzal, M.; Park, B.J.; Hussain, M.; Lee, S. Deep Learning Based Biomedical Literature Classification Using Criteria of Scientific Rigor. Electronics 2020, 9, 1253. https://doi.org/10.3390/electronics9081253
Afzal M, Park BJ, Hussain M, Lee S. Deep Learning Based Biomedical Literature Classification Using Criteria of Scientific Rigor. Electronics. 2020; 9(8):1253. https://doi.org/10.3390/electronics9081253
Chicago/Turabian StyleAfzal, Muhammad, Beom Joo Park, Maqbool Hussain, and Sungyoung Lee. 2020. "Deep Learning Based Biomedical Literature Classification Using Criteria of Scientific Rigor" Electronics 9, no. 8: 1253. https://doi.org/10.3390/electronics9081253
APA StyleAfzal, M., Park, B. J., Hussain, M., & Lee, S. (2020). Deep Learning Based Biomedical Literature Classification Using Criteria of Scientific Rigor. Electronics, 9(8), 1253. https://doi.org/10.3390/electronics9081253