Combining K-Means and XGBoost Models for Anomaly Detection Using Log Datasets





Abstract
1. Introduction
2. Background and Related Work
2.1. Base Concepts
2.2. Related Work
2.3. K-Means
2.4. Decision Trees
2.5. XGBoost
2.6. Dask
3. Proposed Framework
3.1. Description of the Algorithm
| Algorithm 1 Proposed Algorithm |
INPUT:E, Event Set
OUTPUT:, Identification of the anomaly cluster OUTPUT:, Total number of events OUTPUT:, Total number o anomalies |
3.2. Tools
- python fca_normalization
- -in NASA_access_log_Jul95
- -in_encoding in_encoding.data
- -out logs_NASA.csv
- -out_encoding out_encoding.data
- python fca_model
- -in logs_NASA.csv
- -out fca_xgboost.pkl
- python fca_analysis
- -in_model fca_xgboost.pkl
- -in_data logs_NASA.csv
- -out outlier_events.csv
4. Discussion and Evaluation
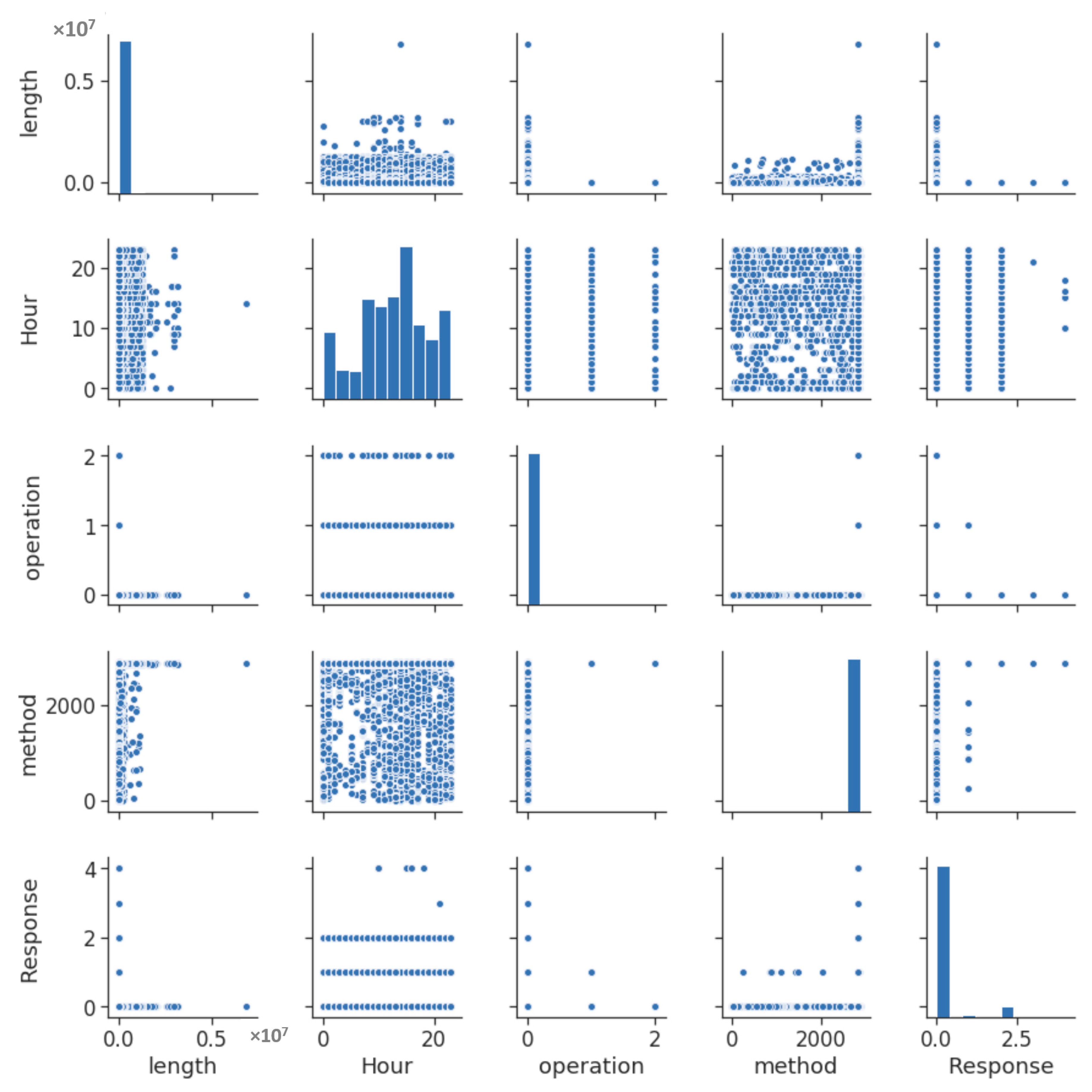
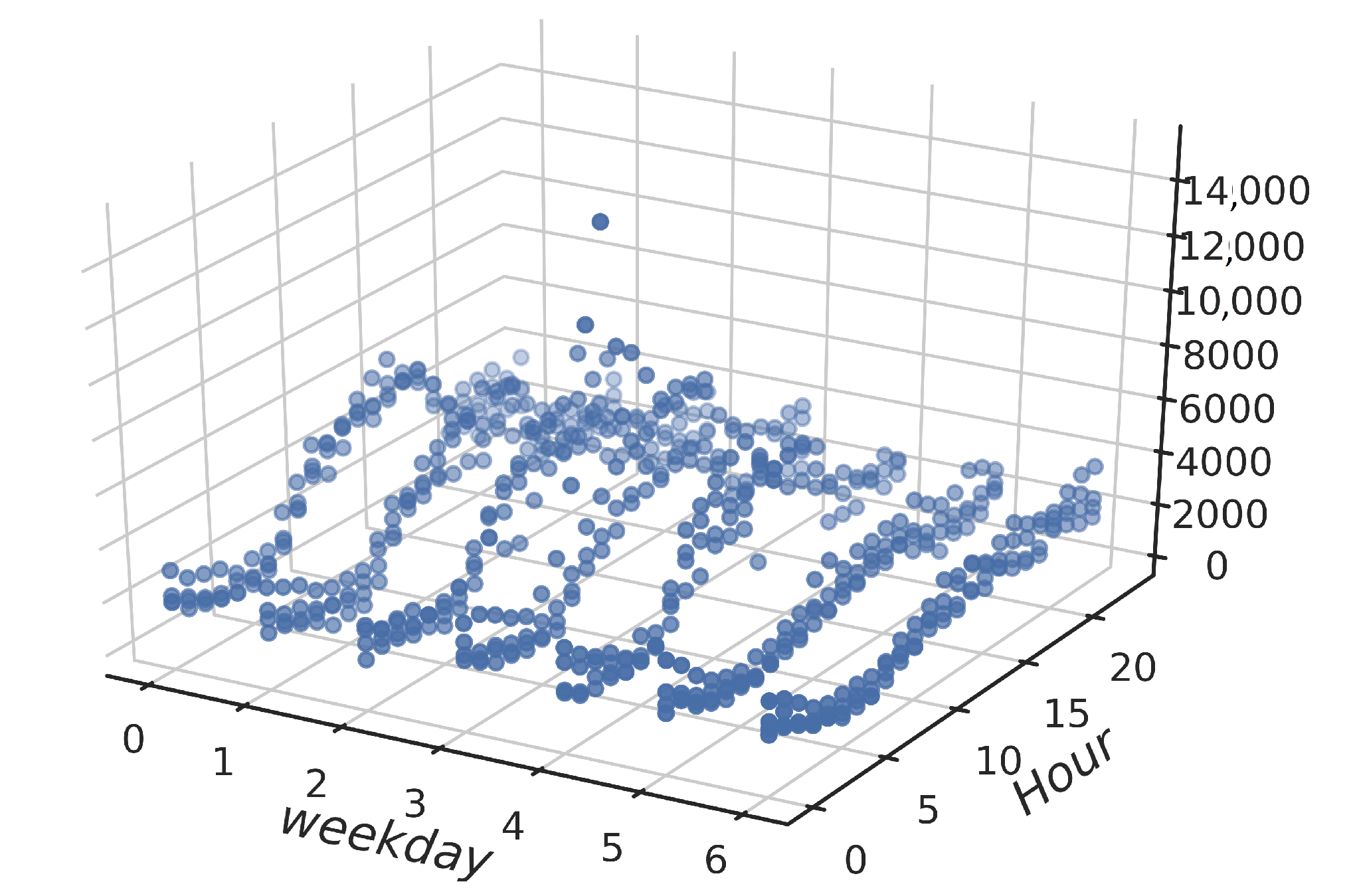
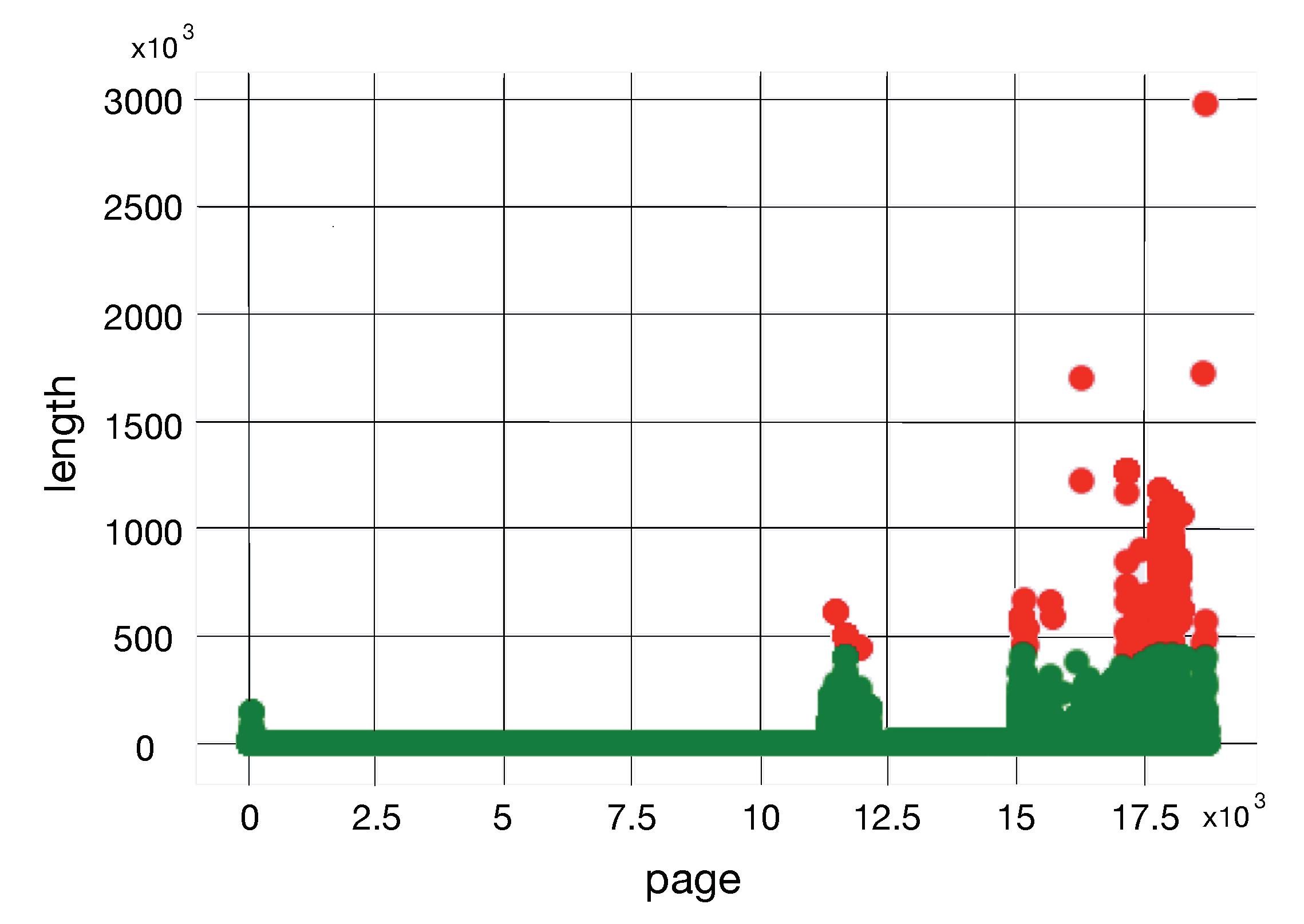
4.1. Feature Extraction and Data Exploration
4.2. Clustering
- [[4.41534608e+04, 0.00000000e+00, 8.12115012e+05, 1.14495884e+01,
- 0.00000000e+00, 0.00000000e+00, 1.26692042e+01, 2.96762857e+01,
- 2.94179871e+01, 0.00000000e+00, 1.75010380e+04, 2.84859910e+03,
- 2.82322741e+00, 2.23245109e-01]
- [4.27877328e+04, 1.63161125e-01, 1.53047043e+04, 1.24323538e+01,
- 0.00000000e+00, 0.00000000e+00, 1.26856431e+01, 2.95910303e+01,
- 2.94991093e+01, 2.22648078e-03, 1.47567972e+04, 2.84883391e+03,
- 2.68136168e+00, 1.93607622e-01]]
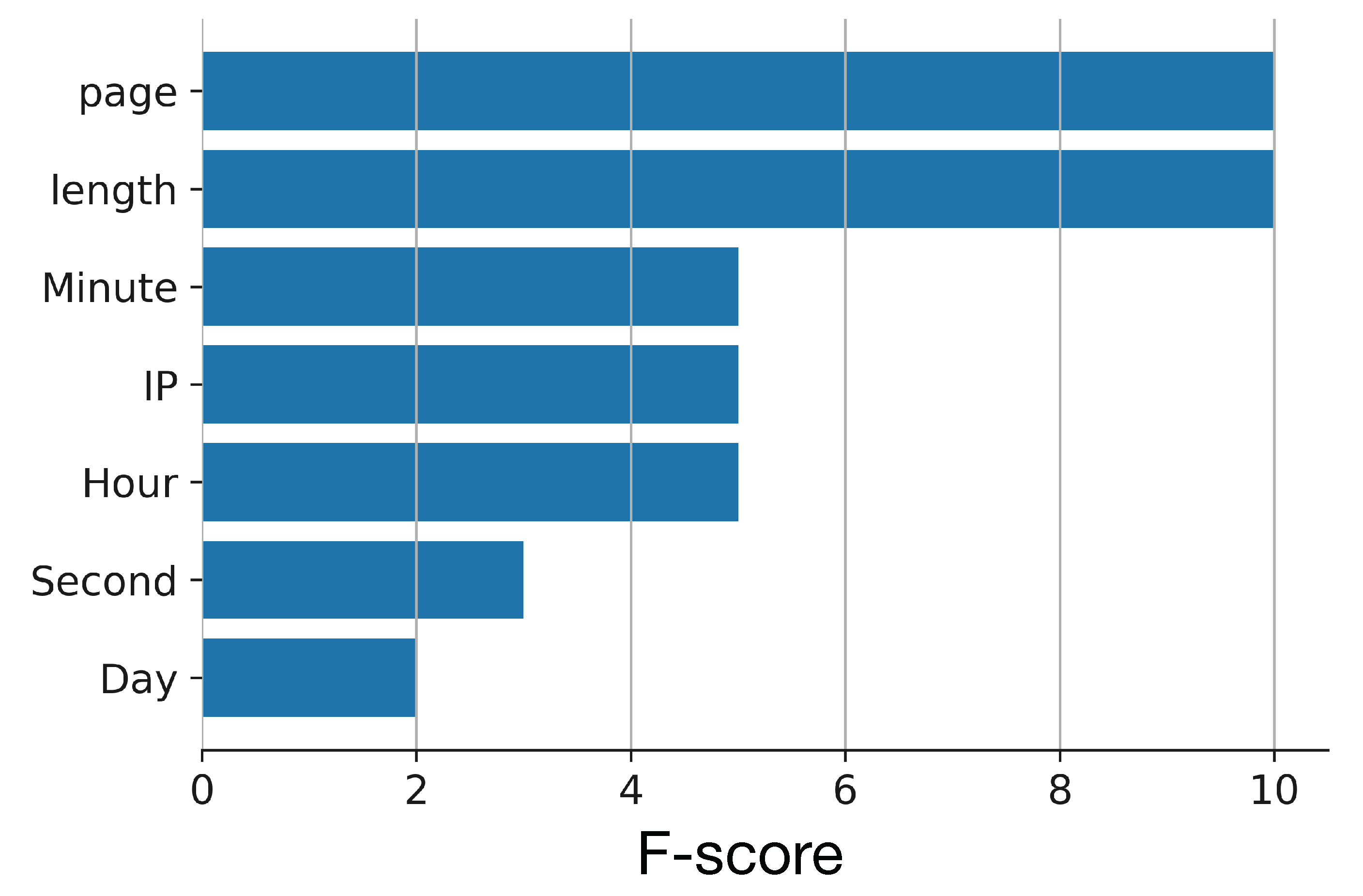
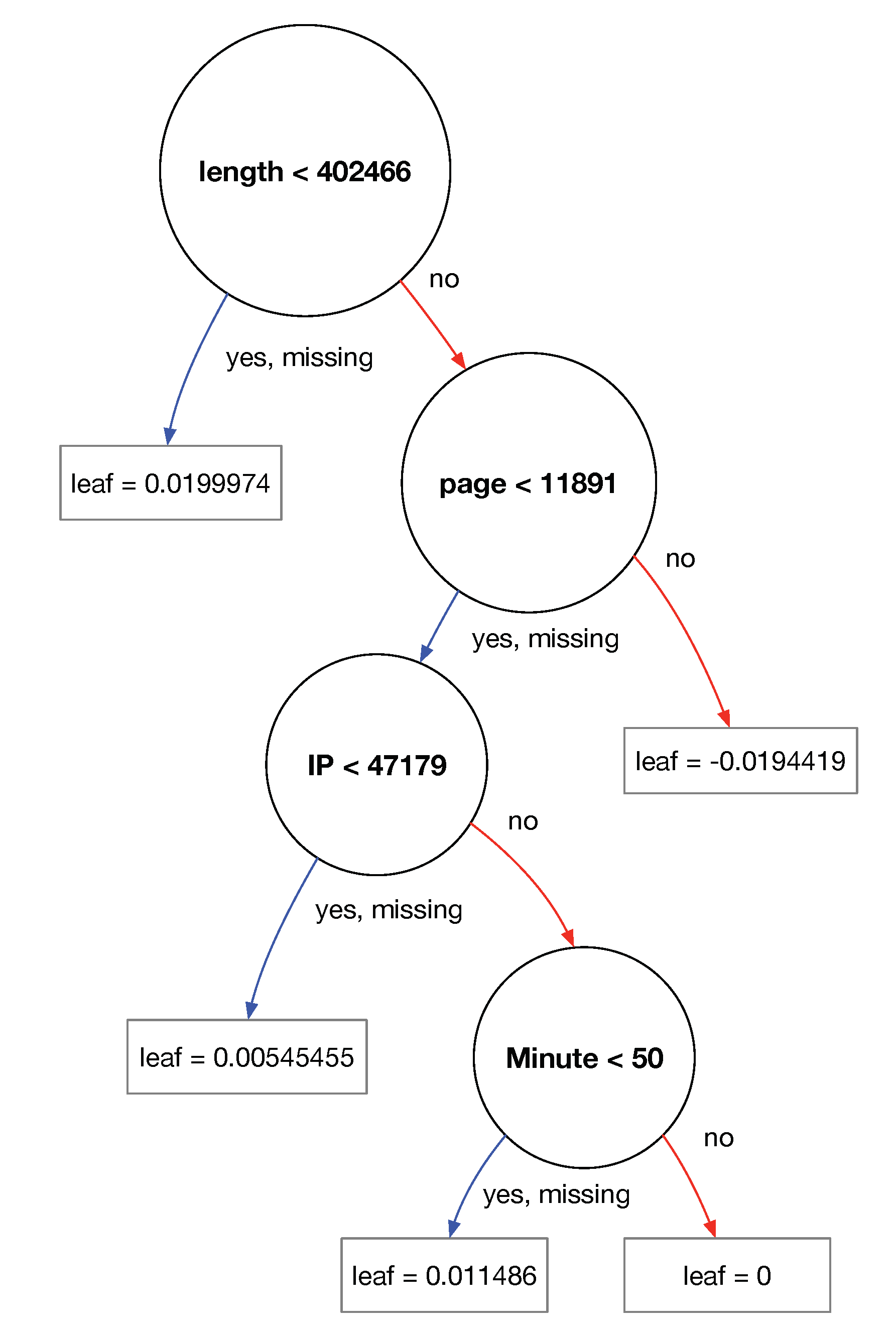
4.3. Classification
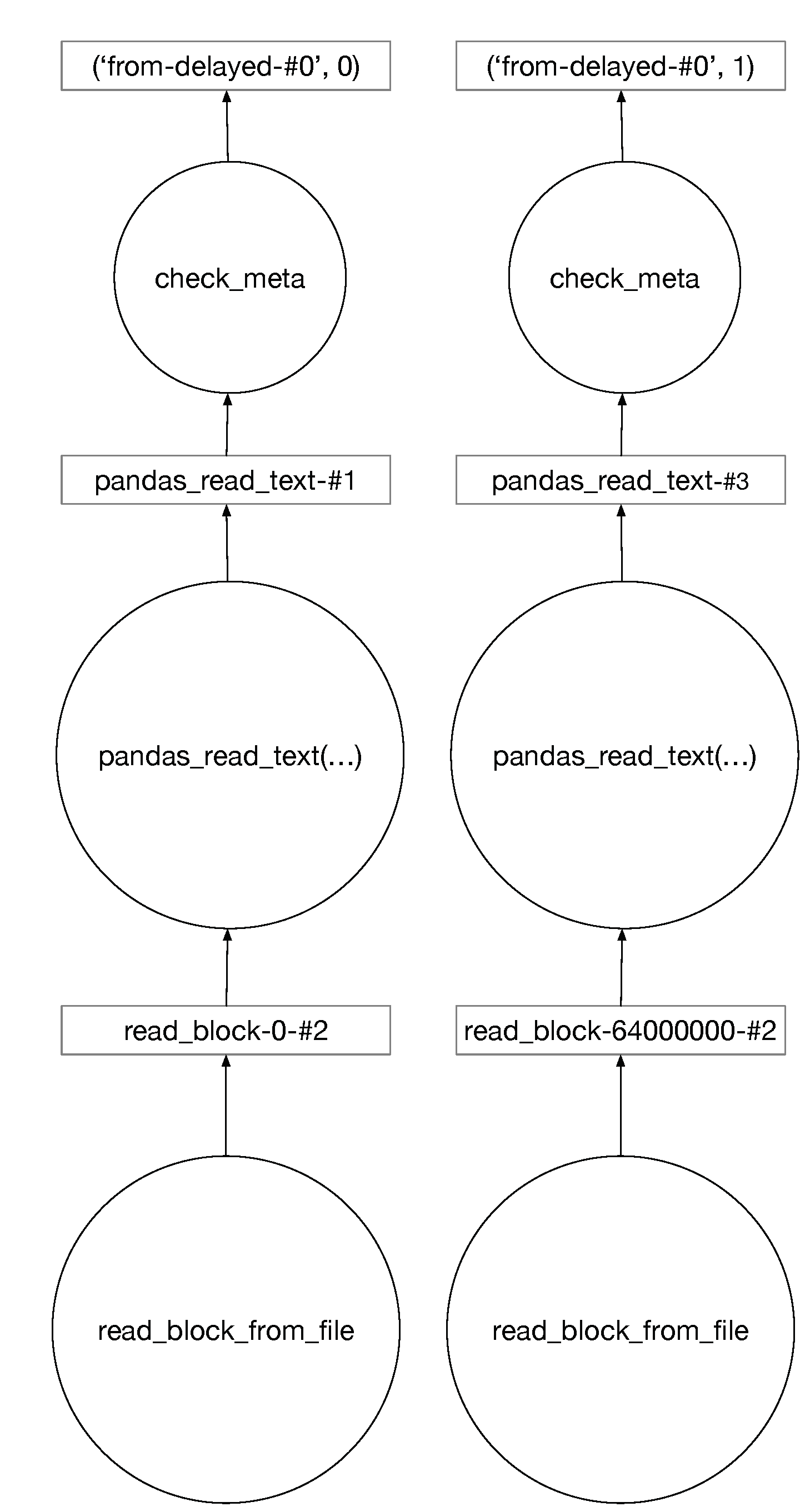
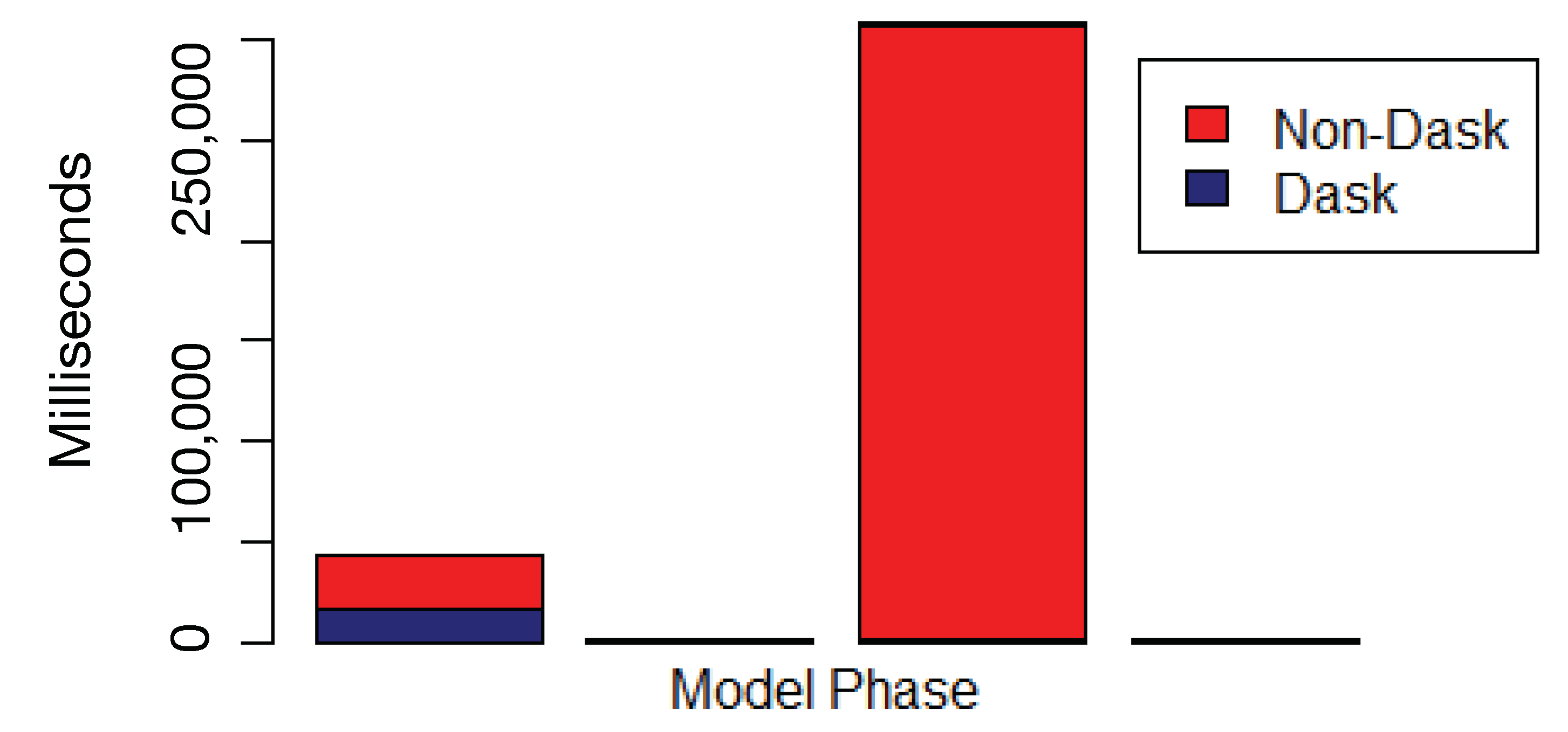
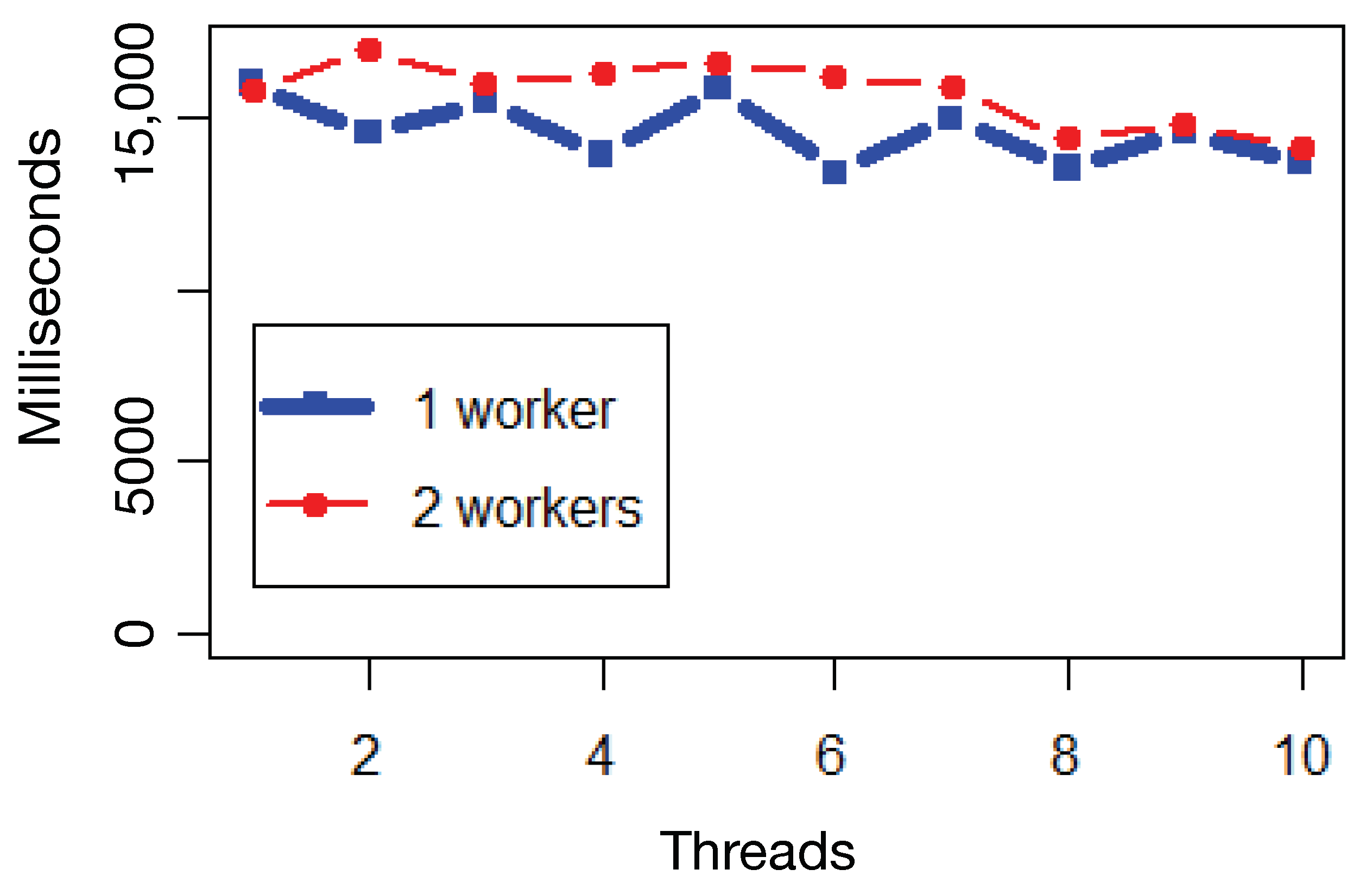
4.4. Parallelization
4.5. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Adamsky, F.; Aubigny, M.; Battisti, F.; Carli, M.; Cimorelli, F.; Cruz, T.; Giorgio, A.D.; Foglietta, C.; Galli, A.; Giuseppi, A.; et al. Integrated protection of industrial control systems from cyber-attacks: The ATENA approach. Int. J. Crit. Infrastruct. Prot. 2018, 21, 72–82. [Google Scholar] [CrossRef]
- Rosa, L.; Proença, J.; Henriques, J.; Graveto, V.; Cruz, T.; Simões, P.; Caldeira, F.; Monteiro, E. An Evolved Security Architecture for Distributed Industrial Automation and Control Systems. In Proceedings of the 16th European Conference on Cyber Warfare and Security (ECCWS 2017), Dublin, Ireland, 29–30 June 2017; pp. 380–390. [Google Scholar]
- Wu, X.; Kumar, V.; Quinlan, J.R.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Philip, S.Y.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Rocklin, M. Dask: Parallel computation with blocked algorithms and task scheduling. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; pp. 130–136. [Google Scholar]
- Grubbs, F.E. Procedures for detecting outlying observations in samples. Technometrics 1969, 11, 1–21. [Google Scholar] [CrossRef]
- Gogoi, P.; Bhattacharyya, D.; Borah, B.; Kalita, J.K. A survey of outlier detection methods in network anomaly identification. Comput. J. 2011, 54, 570–588. [Google Scholar] [CrossRef]
- Zheng, Y.; Zhang, H.; Yu, Y. Detecting collective anomalies from multiple spatio-temporal datasets across different domains. In Proceedings of the 23rd SIGSPATIAL international conference on advances in geographic information systems, Seattle, WA, USA, 3–6 November 2015; pp. 1–10. [Google Scholar]
- Yang, Q.; Wu, X. 10 challenging problems in data mining research. Int. J. Inf. Technol. Decis. Making 2006, 5, 597–604. [Google Scholar] [CrossRef]
- Chen, Z.; Li, Y.F. Anomaly detection based on enhanced DBScan algorithm. Procedia Eng. 2011, 15, 178–182. [Google Scholar] [CrossRef]
- Syarif, I.; Prugel-Bennett, A.; Wills, G. Unsupervised clustering approach for network anomaly detection. In Proceedings of the International Conference on Networked Digital Technologies, Dubai, UAE, 24–26 April 2012; pp. 135–145. [Google Scholar]
- Hoglund, A.J.; Hatonen, K.; Sorvari, A.S. A computer host-based user anomaly detection system using the self-organizing map. In Proceedings of the IEEE-INNS-ENNS International Joint Conference on Neural Networks (IJCNN 2000), Como, Italy, 27 July 2000; pp. 411–416. [Google Scholar]
- Lichodzijewski, P.; Zincir-Heywood, A.N.; Heywood, M.I. Host-based intrusion detection using self-organizing maps. In Proceedings of the 2002 International Joint Conference on Neural Networks (IJCNN’02), Honolulu, HI, USA, 12–17 May 2002; pp. 1714–1719. [Google Scholar]
- Münz, G.; Li, S.; Carle, G. Traffic Anomaly Detection Using K-Means Clustering. GI/ITG Workshop MMBnet, 2007; pp. 13–14. Available online: https://pdfs.semanticscholar.org/634e/2f1a20755e7ab18e8e8094f48e140a32dacd.pdf (accessed on 15 June 2017).
- Tian, L.; Jianwen, W. Research on network intrusion detection system based on improved k-means clustering algorithm. In Proceedings of the 2009 International Forum on Computer Science-Technology and Applications, Chongqing, China, 25–27 December 2009; pp. 76–79. [Google Scholar]
- Eslamnezhad, M.; Varjani, A.Y. Intrusion detection based on MinMax K-means clustering. In Proceedings of the 7’th International Symposium on Telecommunications (IST’2014), Tehran, Iran, 9–11 September 2014; pp. 804–808. [Google Scholar]
- Ranjan, R.; Sahoo, G. A new clustering approach for anomaly intrusion detection. Int. J. Data Min. Knowl. Manage. Process 2014, 4, 29–38. [Google Scholar] [CrossRef]
- Makanju, A.; Zincir-Heywood, A.N.; Milios, E.E. Investigating event log analysis with minimum apriori information. In Proceedings of the 2013 IFIP/IEEE International Symposium on Integrated Network Management (IM 2013), Ghent, Belgium, 27–31 May 2013; pp. 962–968. [Google Scholar]
- Asif-Iqbal, H.; Udzir, N.I.; Mahmod, R.; Ghani, A.A.A. Filtering events using clustering in heterogeneous security logs. Inf. Technol. J. 2011, 10, 798–806. [Google Scholar] [CrossRef]
- Hajamydeen, A.I.; Udzir, N.I.; Mahmod, R.; GHANI, A.A.A. An unsupervised heterogeneous log-based framework for anomaly detection. Turkish J. Electr. Eng. Comput. Sci. 2016, 24, 1117–1134. [Google Scholar] [CrossRef]
- Varuna, S.; Natesan, P. An integration of k-means clustering and naïve bayes classifier for Intrusion Detection. In Proceedings of the 2015 3rd International Conference on Signal Processing, Communication and Networking, ICSCN 2015, Tamil Nadu, India, 26–28 March 2015; pp. 1–5. [Google Scholar]
- Muda, Z.; Yassin, W.; Sulaiman, M.; Udzir, N. K-means clustering and naive bayes classification for intrusion detection. J. IT Asia 2016, 4, 13–25. [Google Scholar] [CrossRef]
- Elbasiony, R.M.; Sallam, E.A.; Eltobely, T.E.; Fahmy, M.M. A hybrid network intrusion detection framework based on random forests and weighted k-means. Ain Shams Eng. J. 2013, 4, 753–762. [Google Scholar] [CrossRef]
- Sequeira, K.; Zaki, M. ADMIT: Anomaly-based data mining for intrusions. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 386–395. [Google Scholar]
- Liao, Y.; Vemuri, V.R. Use of k-nearest neighbor classifier for intrusion detection. Comput. Secur. 2002, 21, 439–448. [Google Scholar] [CrossRef]
- Breunig, M.M.; Kriegel, H.P.; Ng, R.T.; Sander, J. LOF: Identifying density-based local outliers. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, Dallas, TX, USA, 16–18 May 2000; pp. 93–104. [Google Scholar]
- Bahmani, B.; Moseley, B.; Vattani, A.; Kumar, R.; Vassilvitskii, S. Scalable k-means++. Proc. VLDB Endowment 2012, 5, 622–633. [Google Scholar] [CrossRef]
- Vattani, A. K-means requires exponentially many iterations even in the plane. Discrete Comput. Geom. 2011, 45, 596–616. [Google Scholar] [CrossRef]
- Arthur, D.; Vassilvitskii, S. How slow is the k-means method? In Proceedings of the twenty-second annual symposium on Computational geometry, Sedona, AZ, USA, 5–7 June 2006; pp. 144–153. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Additive logistic regression: A statistical view of boosting (with discussion and a rejoinder by the authors). Ann. Statist. 2000, 28, 337–407. [Google Scholar] [CrossRef]
- Johnson, R.; Zhang, T. Learning nonlinear functions using regularized greedy forest. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 942–954. [Google Scholar] [CrossRef]
- He, X.; Pan, J.; Jin, O.; Xu, T.; Liu, B.; Xu, T.; Shi, Y.; Atallah, A.; Herbrich, R.; Bowers, S.; et al. Practical lessons from predicting clicks on ads at facebook. In Proceedings of the Eighth International Workshop on Data Mining for Online Advertising, New York, NY, USA, 24 August 2014; pp. 1–9. [Google Scholar]
- Kaggle. Available online: www.Kaggle.com (accessed on 16 July 2018).
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- H2O.ai. H2O Framework for Machine Learning. Available online: http://docs.h2o.ai/h2o/latest-stable/h2o-docs/index.html (accessed on 15 February 2020).
- Meng, X.; Bradley, J.; Yavuz, B.; Sparks, E.; Venkataraman, S.; Liu, D.; Freeman, J.; Tsai, D.; Amde, M.; Owen, S.; et al. MLlib: Machine Learning in Apache Spark. J. Mach. Learn. Res. 2016, 17, 1235–1241. [Google Scholar]
- NASA. NASA HTTP. Available online: http://ita.ee.lbl.gov/html/contrib/NASA-HTTP.html (accessed on 1 July 2018).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tool | Input | Output |
|---|---|---|
| Normalization | HTTP raw logs data, encoding | Normalized data, encoding |
| Modelling | Normalized data | Model |
| Analysis | Model, normalized data | Anomaly events |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Henriques, J.; Caldeira, F.; Cruz, T.; Simões, P. Combining K-Means and XGBoost Models for Anomaly Detection Using Log Datasets. Electronics 2020, 9, 1164. https://doi.org/10.3390/electronics9071164
Henriques J, Caldeira F, Cruz T, Simões P. Combining K-Means and XGBoost Models for Anomaly Detection Using Log Datasets. Electronics. 2020; 9(7):1164. https://doi.org/10.3390/electronics9071164
Chicago/Turabian StyleHenriques, João, Filipe Caldeira, Tiago Cruz, and Paulo Simões. 2020. "Combining K-Means and XGBoost Models for Anomaly Detection Using Log Datasets" Electronics 9, no. 7: 1164. https://doi.org/10.3390/electronics9071164
APA StyleHenriques, J., Caldeira, F., Cruz, T., & Simões, P. (2020). Combining K-Means and XGBoost Models for Anomaly Detection Using Log Datasets. Electronics, 9(7), 1164. https://doi.org/10.3390/electronics9071164