Iterative Spatial Crowdsourcing in Peer-to-Peer Opportunistic Networks



Abstract
1. Introduction
2. Related Work
3. Problem Overview
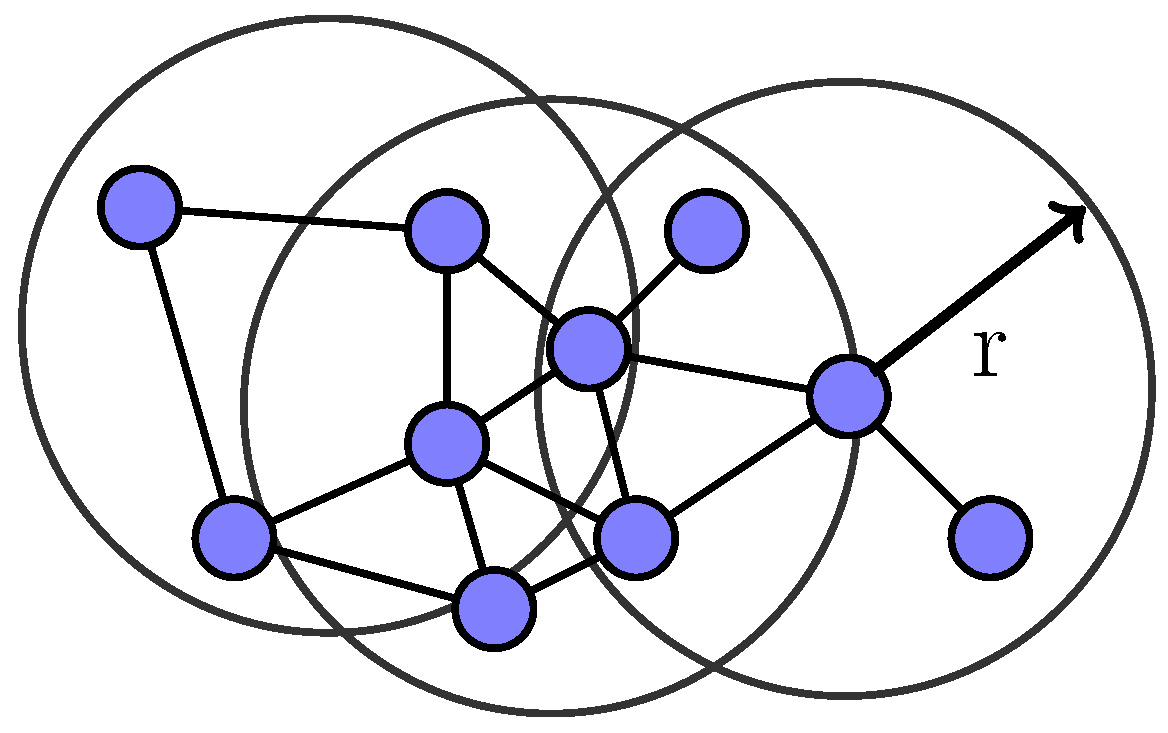
3.1. Our Problem
3.2. Metrics
- Number of responses—this refers to the size of the total result set for each region. In a P2P spatial crowdsourcing network, a node will disseminate a query in the region through mobile peers in its range and then obtain responses from the mobile device peers. In general, the number of responses would be less than or equal to the number of peers receiving the query.
- Number of rounds required—this is defined as the number of rounds of querying required. In each round, a set of queries is issued in parallel to find out about a particular chosen set of regions (assuming one query per region). Note that we use the term “iterative” to refer to the processes we are studying in this paper, each of which is comprised of one or more rounds of queries (that is, there is an iteration till the number of regions of interest has been found).
4. Task Propagation Strategies in P2P Spatial Crowdsourcing
4.1. Flooding
4.1.1. Idea
4.1.2. Algorithm
| Algorithm 1: Flooding(k, F, R, τ, μ) |
| Input : k: number of regions to find, F: predicate on region, R: set of regions, |
| : Time-to-Live, : time for transmitting a query, |
| N: set of selected unobserved neighbors, S: set of source nodes |
| Output: D: set of found regions, O: set of observed regions |
| /* initial value for found regions */ |
| /* initial value for unobserved neighbors */ |
| /* initial value for source node equal to “Requestor” node */ |
| /* expiry period of query of S */ |
| while () AND () |
| selectNeighbors |
| askCrowdAbout(N); |
| := response from crowd about N, where |
| and |
| and ( |
| ; /* assign the neighbor nodes to source nodes */ |
| end |
| return D and O; |
| Algorithm 2: selectNeighbors(S, k, D, R \ O) |
| Input : S: set of source nodes = , k: number of positive regions to find, |
| D: set of found regions, R: set of regions, O: set of observed regions, |
| : set of selected unobserved neighbors of |
| Output: N: set of selected unobserved neighbors to be queried |
| ; /* prepare empty list for collecting new neighbors from source nodes (S)*/ |
| ; |
| for each |
| := select all neighbors in the range of from , where ; |
| N := ; |
| end |
| return N; |
4.1.3. Analysis
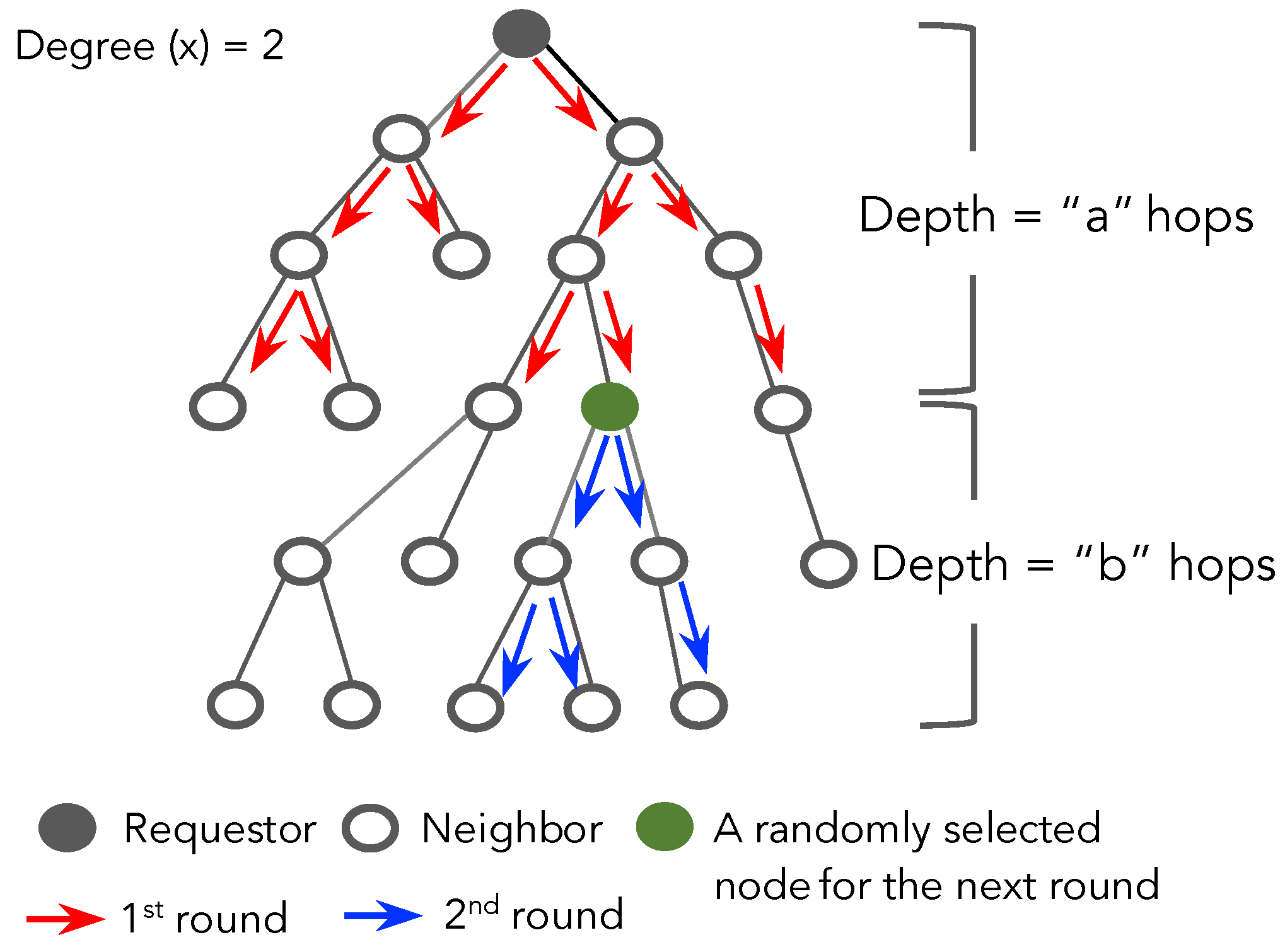
4.2. Random-X-Walker
4.2.1. Idea
| Algorithm 3: Random-X-Walker |
| Input : k: number of regions to find, F: predicate on region, R: set of regions, |
| : Time-to-Live, : time for transmitting a query, x: node degree, |
| H: current hop level, : maximum number of hops that a query can be propagated |
| Output: D: set of found regions, O: set of observed regions, : number of rounds |
| /* initial value for found regions */ |
| /* initial value for unobserved neighbors */ |
| /* initial value for source nodes */ |
| /* expiry period of query of S */ |
| H := 0; /* initial current hop level */ |
| := 0; /* initial round */ |
| while () AND () |
| := calMaxHops(); |
| while () AND () AND () |
| selectNeighbors |
| askCrowdAbout(N); |
| := response from crowd about N, where |
| and |
| and ( |
| ; |
| := ; ; |
| end |
| S := selectOneNeighbor(N); |
| H := 0; ; |
| end |
| return D, O and ; |
| Algorithm 4: calMaxHops |
| Input : D: set of found regions, x: node degree |
| k: number of positive regions to find |
| Output: : maximum number of hops |
| ; |
| ; |
| return |
| Algorithm 5: selectOneNeighbor |
| Input :N: set of selected unobserved neighbors to be queried |
| Output: S: set of source nodes |
| S := randomly selected member from N; |
| return S |
| Algorithm 6: selectNeighbors |
| Input :S: set of source nodes = , k: number of positive regions to find, |
| D: set of found regions, R: set of regions, O: set of observed regions, |
| : set of selected unobserved neighbors of , x: node degree |
| Output: N: set of selected unobserved neighbors to be queried |
| ; |
| ; |
| for each |
| := randomly select x neighbors within the communication range of from |
| , where ; ( := c neighbors, when ) |
| N := ; |
| end |
| return |
4.2.2. Algorithm
4.2.3. Analysis
4.3. Random-X-Walker with Redundancy
4.3.1. Idea
4.3.2. Algorithm
| Algorithm 7: selectNeighbors |
| Input : S: set of source nodes = , k: number of positive regions to find, |
| D: set of found regions, R: set of regions, O: set of observed regions, |
| : set of selected unobserved neighbors of , x: number of degrees |
| Output: N: set of selected unobserved neighbors to be queried |
| ; |
| ; |
| for each |
| := randomly select x neighbors within the communication range of from |
| , where ; ( := c neighbors, when ) |
| N := ; |
| return |
4.3.3. Analysis
4.4. Multi-Criteria Neighbor Selection
4.4.1. Idea
- the number of positive results returned previously
- the number of query messages forwarded to others previously
- the number of neighbor nodes
- the battery power remaining
4.4.2. Algorithm and Analysis
- Find the neighbors of each node v (i.e., nodes within its transmission range).
- Compute a ratio using the number of positive answers derived from each of node v neighbors, using the formula: , where is the total number of positive results previously returned from node i.
- For every node, compute a ratio using the number of forwarded queries of node v, using the formula: , where is the total number of forwarded queries of node i.
- Compute a ratio using the number of each of node v’s neighbors. This gives a relative measure of node degree and is denoted by , as , where is the number of neighbors of node i.
- Then, compute the relative remaining power of node v, using the formula: , where is the remaining power of node i.
- Calculate the score of node v, using the formula:where and are the weighing criteria for the corresponding spatial crowdsourcing and the sum of weights and is equal to 1.
- Choose the node with the highest . A query will be then sent to that node.
- Repeat steps 2 to 7 for the remaining nodes not yet selected for forwarding any queries.
| Algorithm 8: selectNeighbors |
| Input : S: set of source nodes = , k: number of positive regions to find, |
| D: set of found regions, R: set of regions, O: set of observed regions, |
| : set of selected unobserved neighbors of , x: node degree, |
| : a list of neighbors of , : numbers of the list LN |
| Output: N: set of selected unobserved neighbors to be queried |
| ; |
| ; |
| for each |
| ; |
| := select all neighbors within the communication range of from ; |
| for each of |
| := calculateScore(); |
| end |
| := sort in descending order of their scores; |
| := select top x neighbors from , where ; |
| ( := c neighbors, when ) |
| N := ; |
| end |
| return |
4.5. Multi-Criteria Neighbor Selection with Redundancy
4.5.1. Idea
4.5.2. Algorithm and Analysis
| Algorithm 9: selectNeighbors |
| Input : S: set of source nodes = , k: number of positive regions to find, |
| D: set of found regions, R: set of regions, O: set of observed regions, |
| : set of selected unobserved neighbors of , x: node degree, |
| : a list of neighbors of , : numbers of the list LN |
| Output: N: set of selected unobserved neighbors to be queried |
| ; |
| ; |
| for each |
| ; |
| := select all neighbors within the communication range of from ; |
| for each of |
| := calculateScore(); |
| end |
| := sort in descending order of their scores; |
| := select top x neighbors from , where ; |
| ( := c neighbors, when ) |
| N := ; |
| end |
| return |
5. Performance Evaluation
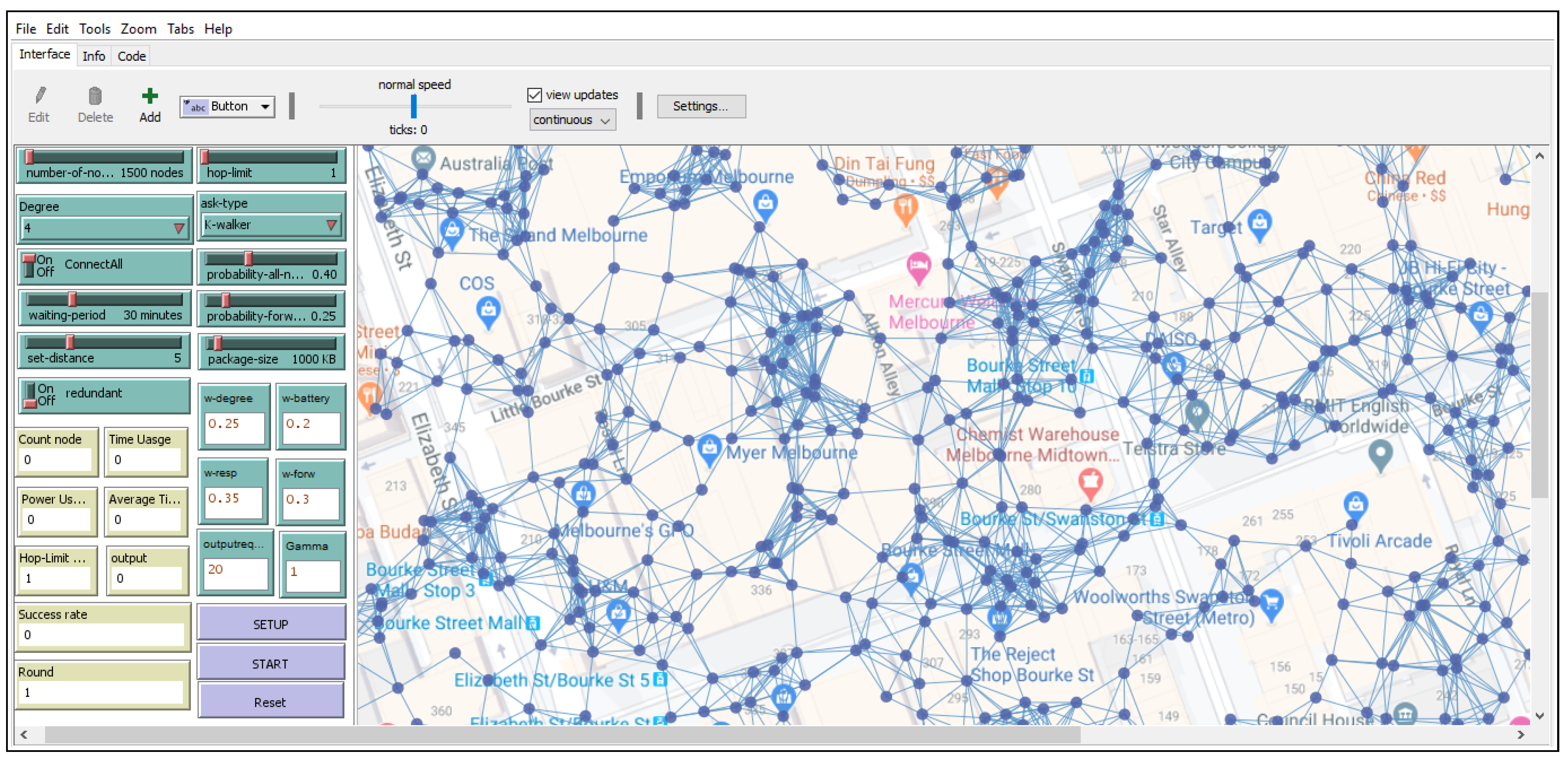
5.1. Simulation with Netlogo and Scenarios
5.2. Comparing Approaches
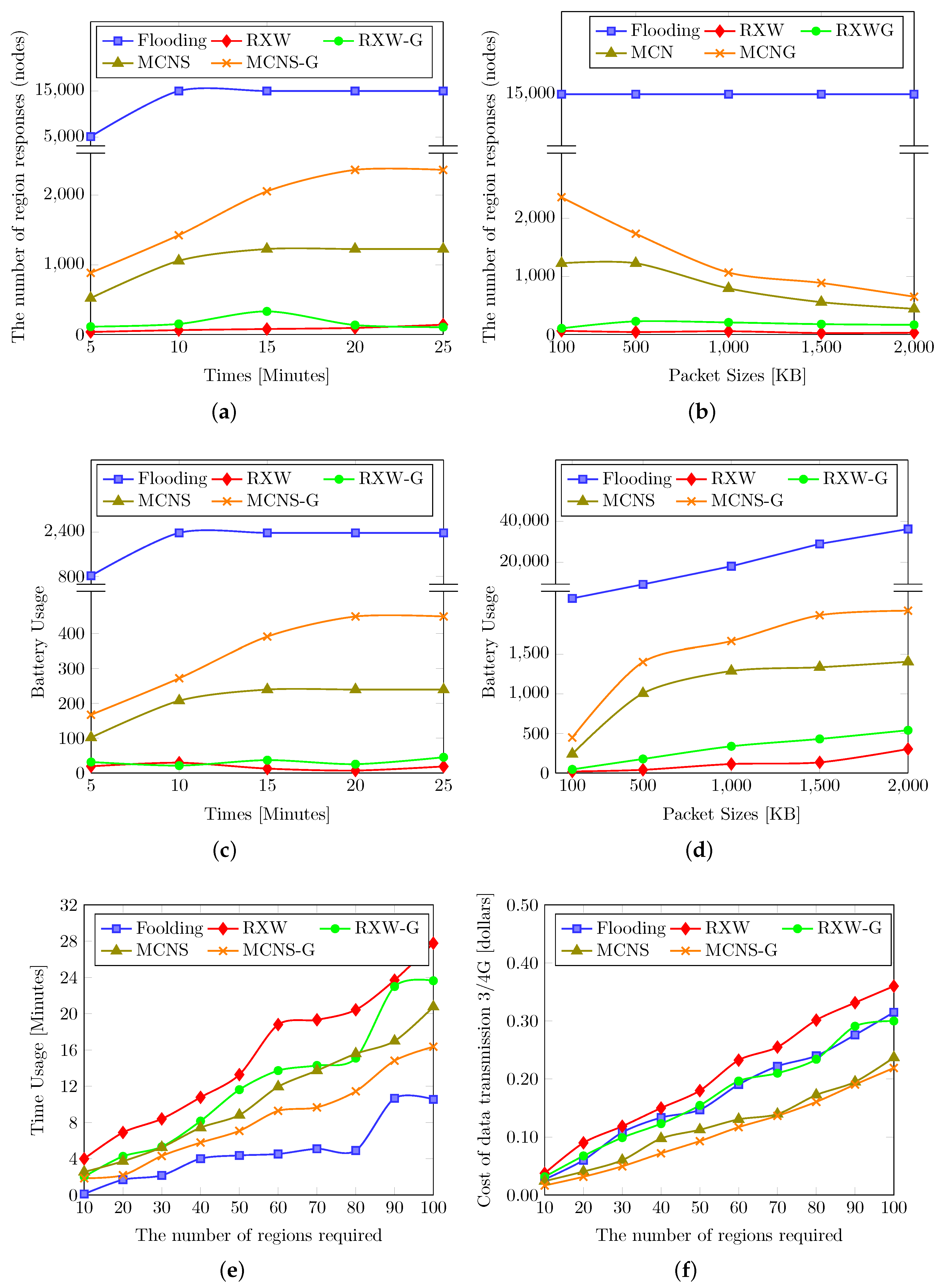
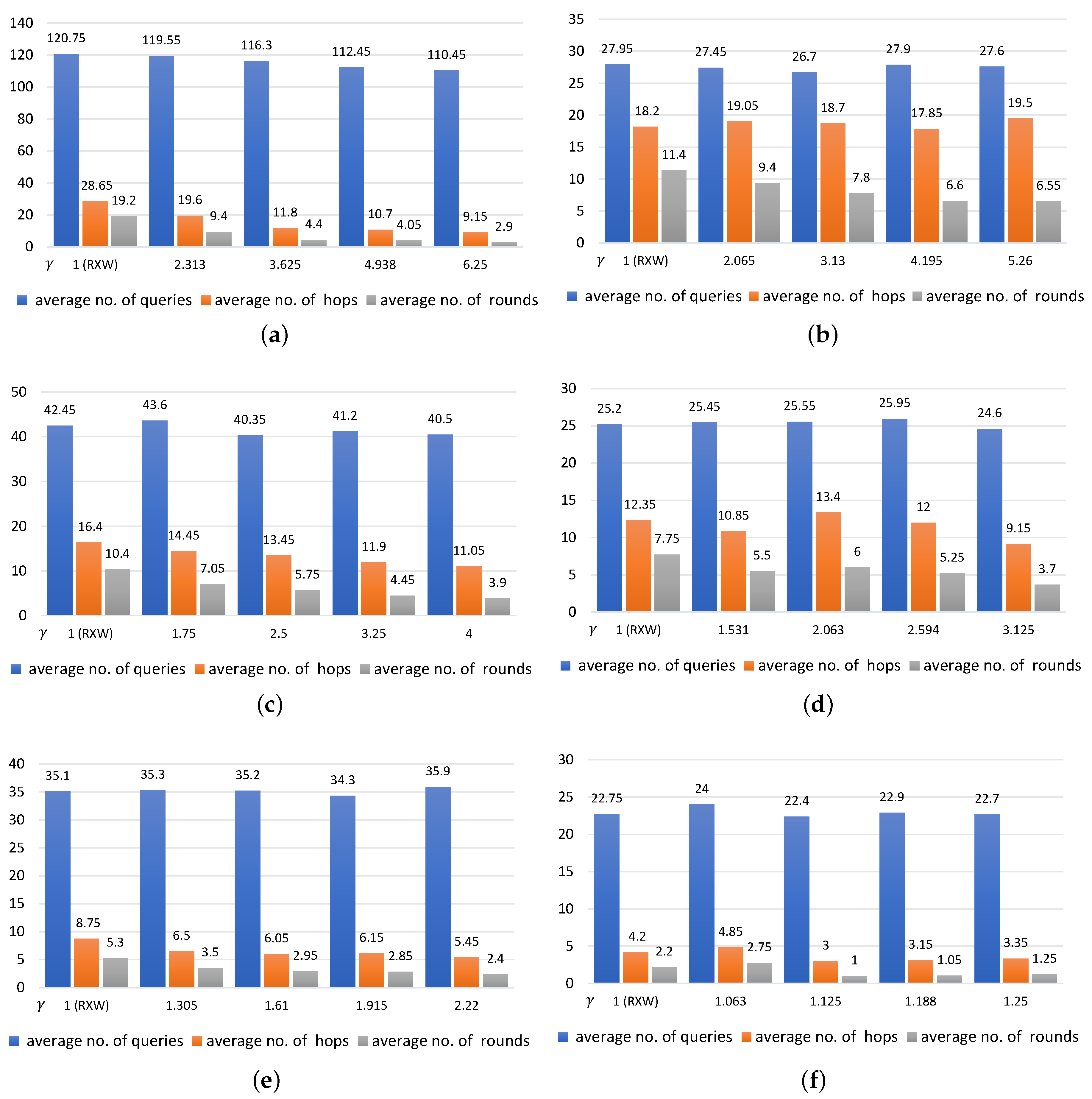
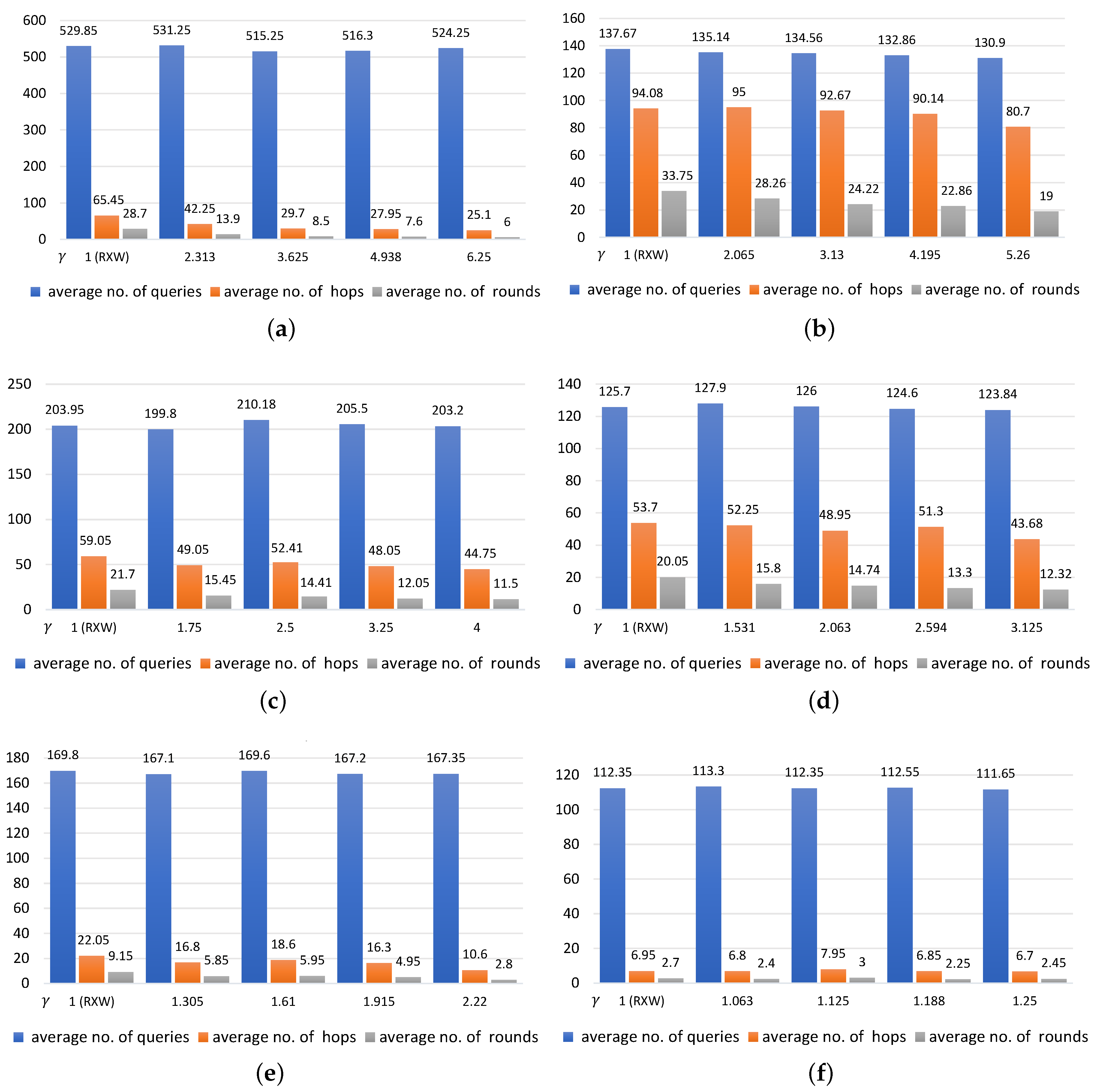
5.2.1. Evaluation Results
5.2.2. Discussion
5.3. Comparison between RXW and RXW-G
5.3.1. Evaluation Results
5.3.2. Discussion
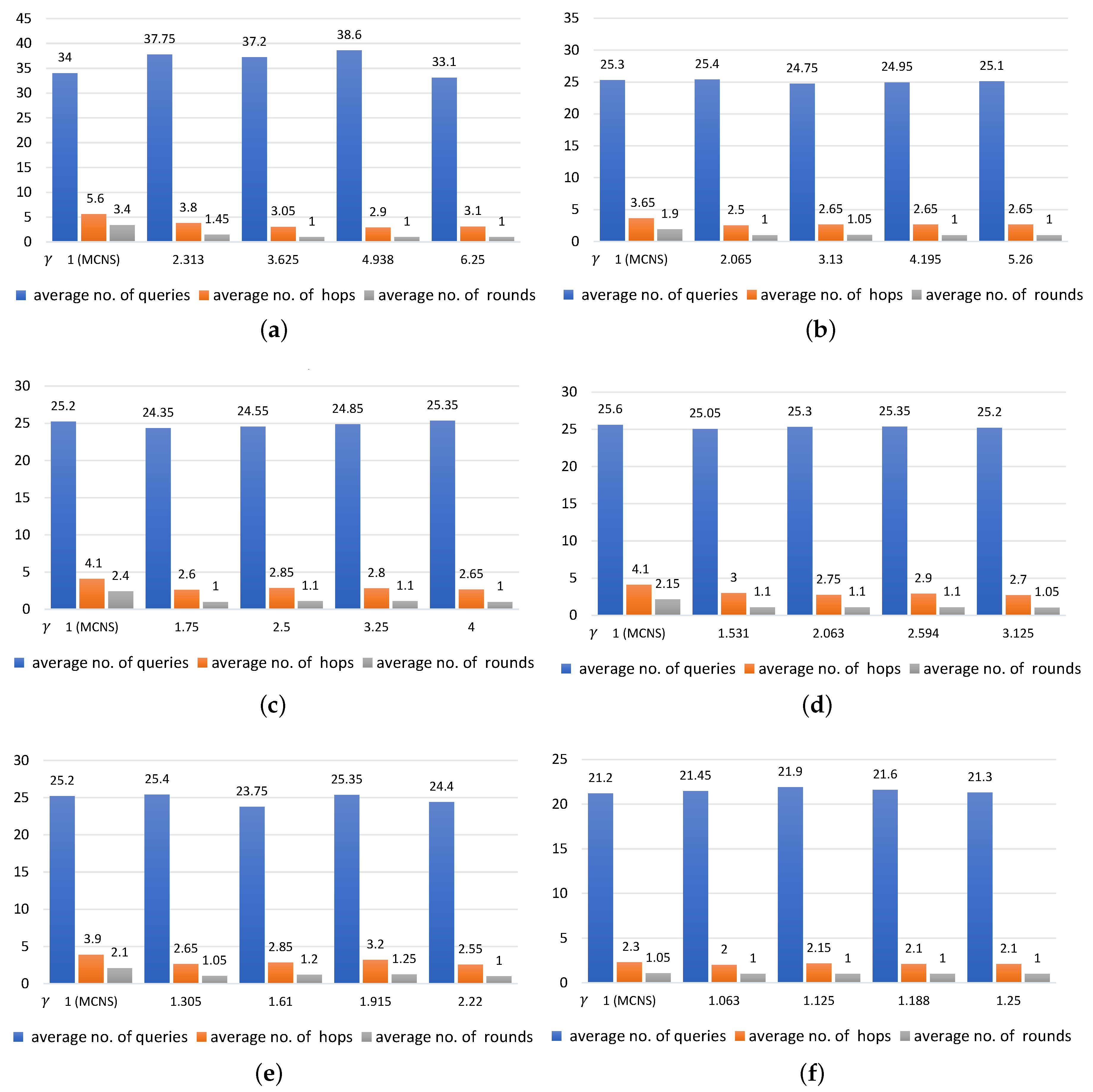
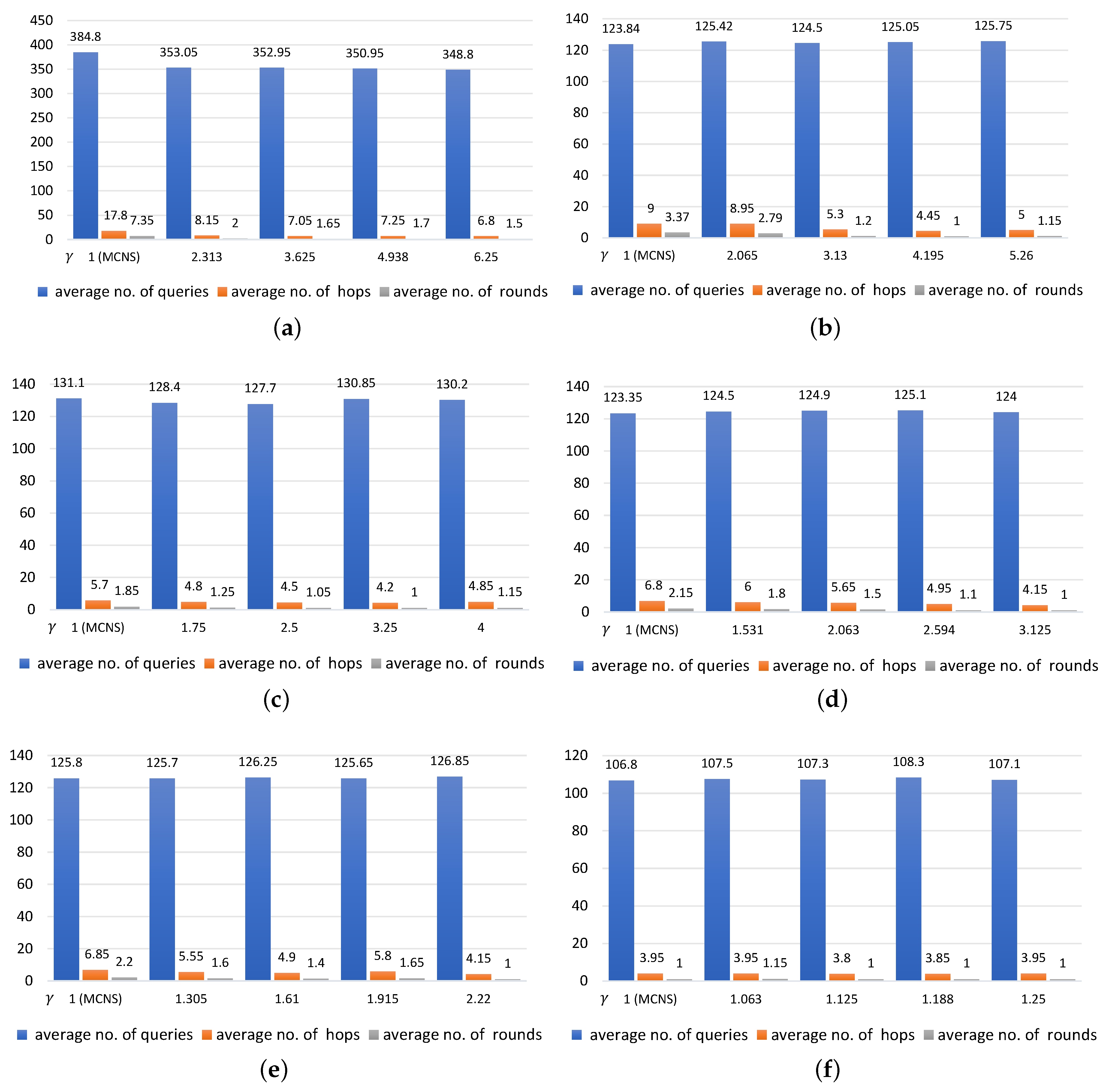
5.4. Comparison between MCNS and MCNS-G
5.4.1. Evaluation Results
- The smaller was, the more queries, hops, and rounds were needed, For example, with = 0.16, 0.32, 0.81 in Figure 7a,c,f and with = 1, increasing the values of led to a slight drop in the number of queries (34, 25.6, and 21.2 queries, respectively). Under the same conditions, the average number of rounds taken to find the targeted regions were 3.4, 2.15, and 1.05 and there was a decline in the average number of hops to 5.4, 4.1, and 2.3, respectively.
- A likely explanation for why the value of did not seem to be significantly correlated with the number of queried regions is that the number of queries remained steady even when the value of increased. In contrast, both the average number of rounds and average number of hops were negatively related to the value of . This means that the larger the number of the implied, the lower the number of rounds and hops were. Note that this can be clearly seen when the k values were large.
- The findings of this study suggest that a significant difference in either the value of or of can affect the number of queries sent to each region in different ways. In cases where the value was set low and the value was set high, only a small number of positive regions were returned to the requestor in each round, leading to the need for more query propagation in the following rounds. Conversely, if the value of was fixed high and the value of was set low, a large number of positive regions were returned to the requestor and fewer queries were sent to regions in the rounds that followed. As a result, the numbers of rounds and hops may increase when compared to those in the previous case.
5.4.2. Discussion
6. Conclusions
- Using flooding technique to propagate a query to all of a node’s neighbors neighbors. During the propagation process, time-to-live (TTL) values are defined to limit the lifetime of queries so that the action of forwarding queries to others would eventually be stopped. This approach is able to find the desired number of positive regions within a relatively short period of time. This approach can thus be a good choice regardless of the cost-efficiency and power consumption factors.
- Using randomly forwarded queries over regions to X neighbors. This random walker mechanism executes until the TTL value expires or it receives k region responses. Moreover, we also proposed an efficient method using a proportionate number of redundant queries ( value) in each round in the expectation of failures to respond. The RXW method seems to have the poorest performance with the smallest number of regions, thereby resulting in queries being repeatedly submitted. In contrast, due to the potential of , the RXW-G approach can distribute more queries in a round, leading to a higher probability of finding the positive regions.
- Using historical or statistic data, such as workers’ historical task completion performance and movement, to select participants for spatial crowdsourcing. Choosing “good” neighbors by keeping track of simple statistics on a node’s neighbors (e.g., the number of positive results returned through the neighbors and the number of queries forwarded to others) has been deployed. In addition, in this technique, we also used a proportionate number of redundant queries ( value) in each round in the expectation of failures to respond or negative responses. By choosing good neighbors from historical data and considering the network characteristics of the regions, MCNS-G can strike a balance among the number of region responses, battery consumption, and total time spent within a fixed budget.
Author Contributions
Funding
Conflicts of Interest
References
- Livingstone, R. Crowdsourcing, by Daren C. Brabham. Inf. Soc. 2016, 32, 364–365. [Google Scholar] [CrossRef]
- Chatzimilioudis, G.; Konstantinidis, A.; Laoudias, C.; Zeinalipour-Yazti, D. Crowdsourcing with Smartphones. IEEE Internet Comput. 2012, 16, 36–44. [Google Scholar] [CrossRef]
- Morschheuser, B.; Hamari, J.; Koivisto, J. Gamification in Crowdsourcing: A Review. In Proceedings of the 2016 49th Hawaii International Conference on System Sciences (HICSS), Koloa, HI, USA, 5–8 January 2016; pp. 4375–4384. [Google Scholar] [CrossRef]
- Tong, Y.; Zhou, Z.; Zeng, Y.; Chen, L.; Shahabi, C. Spatial crowdsourcing: a survey. VLDB J. 2020, 29, 217–250. [Google Scholar] [CrossRef]
- Fuchs-Kittowski, F.; Faust, D. Architecture of Mobile Crowdsourcing Systems. In Collaboration and Technology; Baloian, N., Burstein, F., Ogata, H., Santoro, F., Zurita, G., Eds.; Springer International Publishing: Cham, The Netherlands, 2014; pp. 121–136. [Google Scholar]
- Ren, J.; Zhang, Y.; Zhang, K.; Shen, X. Exploiting mobile crowdsourcing for pervasive cloud services: challenges and solutions. IEEE Commun. Mag. 2015, 53, 98–105. [Google Scholar] [CrossRef]
- Guo, B.; Wang, Z.; Yu, Z.; Wang, Y.; Yen, N.Y.; Huang, R.; Zhou, X. Mobile Crowd Sensing and Computing: The Review of an Emerging Human-Powered Sensing Paradigm. ACM Comput. Surv. 2015, 48. [Google Scholar] [CrossRef]
- Zhao, Y.; Han, Q. Spatial crowdsourcing: current state and future directions. IEEE Commun. Mag. 2016, 54, 102–107. [Google Scholar] [CrossRef]
- Chen, L.; Shahabi, C. Spatial Crowdsourcing: Challenges and Opportunities. IEEE Data Eng. Bull. 2016, 39, 14–25. [Google Scholar]
- Phuttharak, J.; Loke, S.W. A Review of Mobile Crowdsourcing Architectures and Challenges: Toward Crowd-Empowered Internet-of-Things. IEEE Access 2019, 7, 304–324. [Google Scholar] [CrossRef]
- Guo, S.; Parameswaran, A.; Garcia-Molina, H. So Who Won? Dynamic Max Discovery with the Crowd. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 13 Nomvenber 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 385–396. [Google Scholar] [CrossRef]
- Parameswaran, A.G.; Garcia-Molina, H.; Park, H.; Polyzotis, N.; Ramesh, A.; Widom, J. CrowdScreen: Algorithms for Filtering Data with Humans. In Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data, Scottsdale, AZ, USA, 20–24 May 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 361–372. [Google Scholar] [CrossRef]
- Das Sarma, A.; Parameswaran, A.; Garcia-Molina, H.; Halevy, A. Crowd-powered find algorithms. In Proceedings of the 2014 IEEE 30th International Conference on Data Engineering, Chicago, IL, USA, 31 March–4 April 2014; pp. 964–975. [Google Scholar] [CrossRef]
- Loke, S.W. Heuristics for spatial finding using iterative mobile crowdsourcing. HCIS 2016, 6, 4. [Google Scholar] [CrossRef]
- Gummidi, S.R.B.; Xie, X.; Pedersen, T.B. A Survey of Spatial Crowdsourcing. ACM Trans. Database Syst. 2019, 44. [Google Scholar] [CrossRef]
- To, H. Task Assignment in Spatial Crowdsourcing: Challenges and Approaches. In Proceedings of the 3rd ACM SIGSPATIAL PhD Symposium; Association for Computing Machinery: New York, NY, USA, 2016. [Google Scholar] [CrossRef]
- Tong, Y.; Chen, L.; Shahabi, C. Spatial Crowdsourcing: Challenges, Techniques, and Applications. Proc. VLDB Endow. 2017, 10, 1988–1991. [Google Scholar] [CrossRef]
- Tang, F.; Zhang, H. Spatial Task Assignment Based on Information Gain in Crowdsourcing. IEEE Trans. Netw. Sci. Eng. 2019, 7, 139–152. [Google Scholar] [CrossRef]
- Chen, Z.; Cheng, P.; Zeng, Y.; Chen, L. Minimizing Maximum Delay of Task Assignment in Spatial Crowdsourcing. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 1454–1465. [Google Scholar] [CrossRef]
- Zhao, Y.; Zheng, K.; Li, Y.; Su, H.; Liu, J.; Zhou, X. Destination-aware Task Assignment in Spatial Crowdsourcing: A Worker Decomposition Approach. IEEE Trans. Knowl. Data Eng. 2019, 1. [Google Scholar] [CrossRef]
- Yang, P.; Zhang, N.; Zhang, S.; Yang, K.; Yu, L.; Shen, X. Identifying the Most Valuable Workers in Fog-Assisted Spatial Crowdsourcing. IEEE Internet Things J. 2017, 4, 1193–1203. [Google Scholar] [CrossRef]
- Tran, L.; To, H.; Fan, L.; Shahabi, C. A Real-Time Framework for Task Assignment in Hyperlocal Spatial Crowdsourcing. ACM Trans. Intell. Syst. Technol. 2018, 9. [Google Scholar] [CrossRef]
- Li, Y.; Yiu, M.L.; Xu, W. Oriented Online Route Recommendation for Spatial Crowdsourcing Task Workers. In International Symposium on Spatial and Temporal Databases; Springer: Cham, The Netherlands, 2015. [Google Scholar]
- Xiao, M.; Ma, K.; Liu, A.; Zhao, H.; Li, Z.; Zheng, K.; Zhou, X. SRA: Secure Reverse Auction for Task Assignment in Spatial Crowdsourcing. IEEE Trans. Knowl. Data Eng. 2019, 32, 782–796. [Google Scholar] [CrossRef]
- Tong, Y.; Wang, L.; Zhou, Z.; Ding, B.; Chen, L.; Ye, J.; Xu, K. Flexible Online Task Assignment in Real-Time Spatial Data. Proc. VLDB Endow. 2017, 10, 1334–1345. [Google Scholar] [CrossRef]
- Liu, A.; Wang, W.; Shang, S.; Li, Q.; Zhang, X. Efficient task assignment in spatial crowdsourcing with worker and task privacy protection. GeoInformatica 2017, 22, 1–28. [Google Scholar] [CrossRef]
- Yuan, D.; Li, Q.; Li, G.; Wang, Q.; Ren, K. PriRadar: A Privacy-Preserving Framework for Spatial Crowdsourcing. IEEE Trans. Inf. Forensics Secur. 2020, 15, 299–314. [Google Scholar] [CrossRef]
- Xiong, P.; Zhu, D.; Zhang, L.; Ren, W.; Zhu, T. Optimizing rewards allocation for privacy-preserving spatial crowdsourcing. Comput. Commun. 2019, 146, 85–94. [Google Scholar] [CrossRef]
- Ye, H.; Han, K.; Xu, C.; Xu, J.; Gui, F. Toward location privacy protection in Spatial crowdsourcing. Int. J. Distrib. Sens. Netw. 2019, 15, 1550147719830568. [Google Scholar] [CrossRef]
- Denko, M.K. Mobile Opportunistic Networks: Architectures, Protocols and Applications; Formerly CIP; CRC Press: Boca Raton, FL, USA, 2011. [Google Scholar]
- Abali, A.M.; Ithnin, N.B.; Ebibio, T.A.; Dawood, M.; Gadzama, W.A.; Abali, A.M.; Ithnin, N.B.; Ebibio, T.A.; Dawood, M.; Gadzama, W.A. A Survey of Geocast Routing Protocols in Opportunistic Networks. In Emerging Trends in Intelligent Computing and Informatics; Saeed, F., Mohammed, F., Gazem, N., Eds.; Springer International Publishing: Cham, The Netherlands, 2020; pp. 683–694. [Google Scholar]
- Menon, V. Review on Opportunistic Routing Protocols for Dynamic Ad hoc Networks: Taxonomy, Applications and Future Research Directions. 2019. Available online: https://www.preprints.org/manuscript/201903.0118/v1 (accessed on 25 June 2020).
- Vahdat, A.; Becker, D. Epidemic Routing for Partially-Connected Ad Hoc Networks; Technical Report; Duke University: Duhram, NC, USA, 2000. [Google Scholar]
- Boldrini, C.; Conti, M.; Jacopini, J.; Passarella, A. HiBOp: a History Based Routing Protocol for Opportunistic Networks. In Proceedings of the 2007 IEEE International Symposium on a World of Wireless, Mobile and Multimedia Networks, Espoo, Finland, 18–21 June 2007; pp. 1–12. [Google Scholar] [CrossRef]
- Lindgren, A.; Doria, A.; Schelén, O. Probabilistic Routing in Intermittently Connected Networks. SIGMOBILE Mob. Comput. Commun. Rev. 2003, 7, 19–20. [Google Scholar] [CrossRef]
- Phuttharak, J.; Loke, S.W. Mobile crowdsourcing in peer-to-peer opportunistic networks: Energy usage and response analysis. J. Netw. Comput. Appl. 2016, 66, 137–150. [Google Scholar] [CrossRef]
- Konstantinidis, A.; Zeinalipour-Yazti, D.; Andreou, P.; Samaras, G. Multi-objective Query Optimization in Smartphone Social Networks. In Proceedings of the 2011 IEEE 12th International Conference on Mobile Data Management, Lulea, Sweden, 6–9 June 2011; Volume 1, pp. 27–32. [Google Scholar] [CrossRef]
- Li, H.; Ota, K.; Dong, M.; Guo, M. Mobile Crowdsensing in Software Defined Opportunistic Networks. IEEE Commun. Mag. 2017, 55, 140–145. [Google Scholar] [CrossRef]
- Constantinides, M.; Constantinou, G.; Panteli, A.; Phokas, T.; Chatzimilioudis, G.; Zeinalipour-Yazti, D. Proximity Interactions with Crowdcast In Proceedings of the Hellenic Data Management Symposium (HDMS 2012), Crete, Greece, 11 April–28 June 2012.
- Tong, Y.; She, J.; Ding, B.; Wang, L.; Chen, L. Online mobile Micro-Task Allocation in spatial crowdsourcing. In Proceedings of the 2016 IEEE 32nd International Conference on Data Engineering (ICDE), Helsinki, Finland, 16–20 May 2016; pp. 49–60. [Google Scholar]
- Tao, Q.; Zeng, Y.; Zhou, Z.; Tong, Y.; Chen, L.; Xu, K. Multi-Worker-Aware Task Planning in Real-Time Spatial Crowdsourcing. In Database Systems for Advanced Applications; Pei, J., Manolopoulos, Y., Sadiq, S., Li, J., Eds.; Springer International Publishing: Cham, The Netherlands, 2018; pp. 301–317. [Google Scholar]
- Zeng, Y.; Tong, Y.; Chen, L.; Zhou, Z. Latency-Oriented Task Completion via Spatial Crowdsourcing. In Proceedings of the 2018 IEEE 34th International Conference on Data Engineering (ICDE), Paris, France, 16–19 April 2018; pp. 317–328. [Google Scholar]
- Gao, D.; Tong, Y.; She, J.; Song, T.; Chen, L.; Xu, K. Top-k Team Recommendation and Its Variants in Spatial Crowdsourcing. Data Sci. Eng. 2017, 2. [Google Scholar] [CrossRef]
- Yang, B.; Garcia-Molina, H. Improving search in peer-to-peer networks. In Proceedings of the 22nd International Conference on Distributed Computing Systems, Vienna, Austria, 2–5 July 2002; pp. 5–14. [Google Scholar] [CrossRef]
- Li, X.; Wu, J. Searching Techniques in Peer-to-Peer Networks. In Handbook on Theoretical and Algorithmic Aspects of Sensor, Ad Hoc Wireless, and Peer-to-Peer Networks; Auerbach Publications: Boston, MA, USA, 2005. [Google Scholar] [CrossRef]
- Zhang, D.; Xiong, H.; Wang, L.; Chen, G. CrowdRecruiter: Selecting Participants for Piggyback Crowdsensing under Probabilistic Coverage Constraint. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Seattle, WA, USA, 13–17 September 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 703–714. [Google Scholar] [CrossRef]
- Xiong, H.; Zhang, D.; Chen, G.; Wang, L.; Gauthier, V. CrowdTasker: Maximizing coverage quality in Piggyback Crowdsensing under budget constraint. In Proceedings of the 2015 IEEE International Conference on Pervasive Computing and Communications (PerCom), St. Louis, MO, USA, 23–27 March 2015; pp. 55–62. [Google Scholar]
- Xiong, H.; Zhang, D.; Chen, G.; Wang, L.; Gauthier, V.; Barnes, L.E. iCrowd: Near-Optimal Task Allocation for Piggyback Crowdsensing. IEEE Trans. Mob. Comput. 2016, 15, 2010–2022. [Google Scholar] [CrossRef]
- Phuttharak, J.; Loke, S.W. Towards Declarative Programming for Mobile Crowdsourcing: P2P Aspects. In Proceedings of the 2014 IEEE 15th International Conference on Mobile Data Management, Brisbane, Australia, 14–18 July 2014; IEEE Computer Society: NW Washington, DC, USA, 2014; Volume 2, pp. 61–66. [Google Scholar] [CrossRef]
- Phuttharak, J.; Loke, S.W. LogicCrowd: Crowd-Powered Logic Programming Based Mobile Applications. Comput. J. 2017, 61, 32–46. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values for Scenarios |
|---|---|
| Area size | 300 × 300 m2 |
| Communication Distances | 10 m |
| Number of nodes | 30,000 nodes |
| Probability of peers responding () | 0.5 |
| Probability of peers forwarding () | 0.5 |
| Number of time () | 1–4 |
| Waiting period () | 5–25 min |
| Packet size () | 100–2000 MB |
| Degree of node (d) | 1–10 |
| Metrics | Flooding | RXW | RXW-G | MCNS | MCNS-G |
|---|---|---|---|---|---|
| Number of region responses * | High | Low | Low | Moderate | Moderate |
| Battery usage * | High | Low | Low | Moderate | Moderate |
| Time usage ** | Low | High | Moderate | Moderate | Moderate |
| Cost (number of queried regions) ** | Moderate | High | Moderate | Moderate | Low |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Phuttharak, J.; Loke, S.W. Iterative Spatial Crowdsourcing in Peer-to-Peer Opportunistic Networks. Electronics 2020, 9, 1085. https://doi.org/10.3390/electronics9071085
Phuttharak J, Loke SW. Iterative Spatial Crowdsourcing in Peer-to-Peer Opportunistic Networks. Electronics. 2020; 9(7):1085. https://doi.org/10.3390/electronics9071085
Chicago/Turabian StylePhuttharak, Jurairat, and Seng W. Loke. 2020. "Iterative Spatial Crowdsourcing in Peer-to-Peer Opportunistic Networks" Electronics 9, no. 7: 1085. https://doi.org/10.3390/electronics9071085
APA StylePhuttharak, J., & Loke, S. W. (2020). Iterative Spatial Crowdsourcing in Peer-to-Peer Opportunistic Networks. Electronics, 9(7), 1085. https://doi.org/10.3390/electronics9071085