Novel CNN-Based AP2D-Net Accelerator: An Area and Power Efficient Solution for Real-Time Applications on Mobile FPGA


Abstract
1. Introduction
- We propose a CNN structure named adaptive pointwise (PW) convolution and 2D convolution joint network (AP2D-Net), a dynamic precision activation and binary weights combined with PW convolution and 2D convolution structure, which works on resource-limited mobile platforms (such as Zynq UltraScale+ MPSoC Ultra96 or PYNQ-Z1/Z2). The architecture also can be configured on other FPGA platforms according to different hardware resources to achieve the highest throughput.
- For feature extraction layers, we simplified the convolution operation by using the XOR gate to remove the multiplication operation. Besides, we use offline preprocessing to combine batch normalization (BN) and scale/bias (SB) operation to optimize the computational kernels.
- To get high bandwidth, we use the advanced extensible interface (AXI4) protocol to communicate between the programming logic (PL), programming system (PS), and memory. Furthermore, we propose a multi-processing scheme to optimize the heterogeneous system and reduce the latency between PL and PS.
- We conduct a set of experiments considering the running speed, hardware resources, object detection accuracy, and power consumption to get the best combination. The code for training, inference, and our system demo is available online and is open source [9].
2. Background and Related Work
2.1. Related Work
2.1.1. Optimization of the Computational Kernels
2.1.2. Bandwidth Optimization to Improve Throughput
2.1.3. Model Optimization
2.2. Binary Neural Networks
2.3. Implementation Methodologies
3. System Design
3.1. Proposed System Architecture and IP Block Design
3.2. AP2D-Net Modeling of the CNN-Based FPGA Accelerator
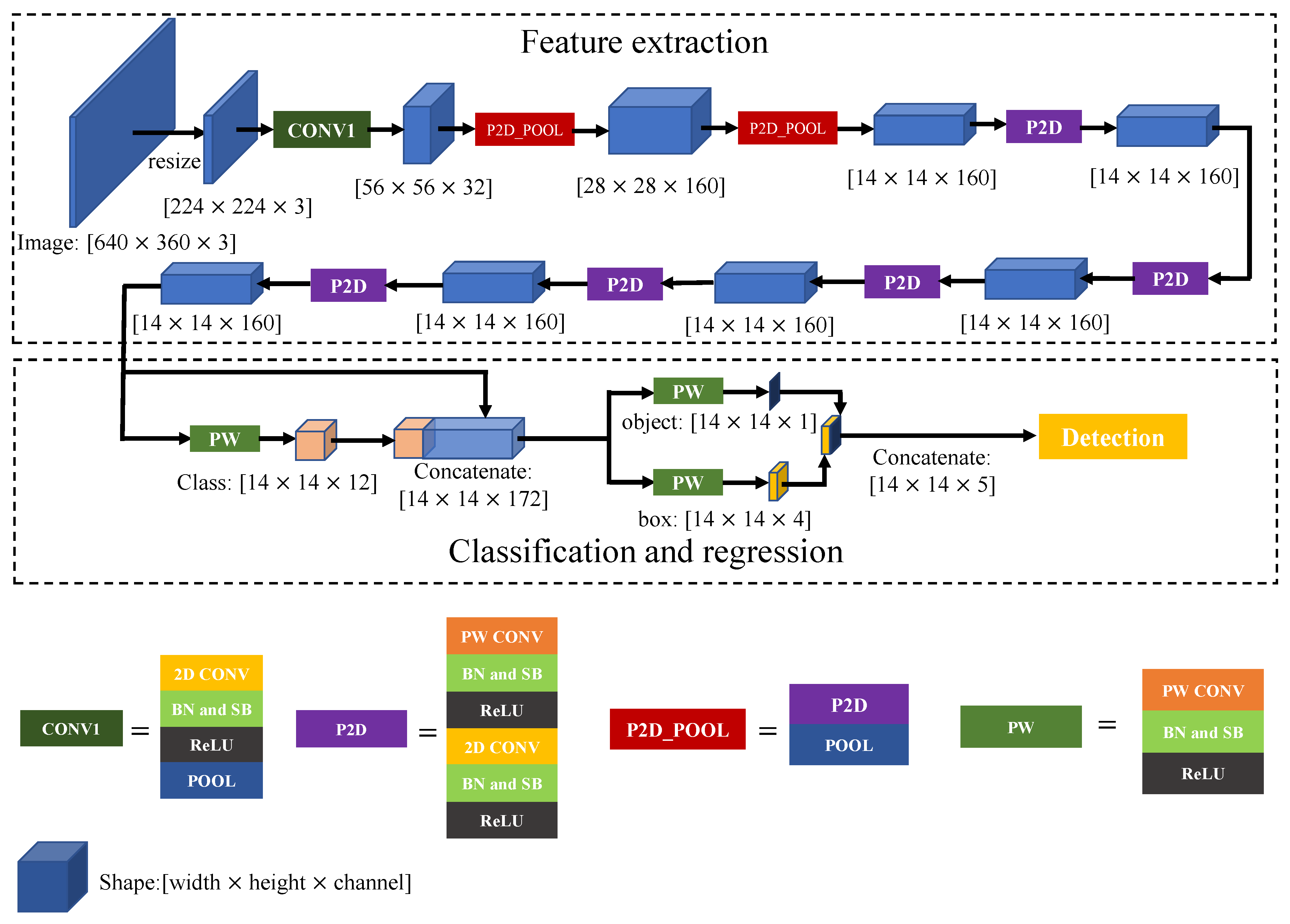
3.2.1. Structure of AP2D-Net
3.2.2. Feature Extraction
3.2.3. Classification and Regression
3.3. AP2D-NET System Design on FPGA
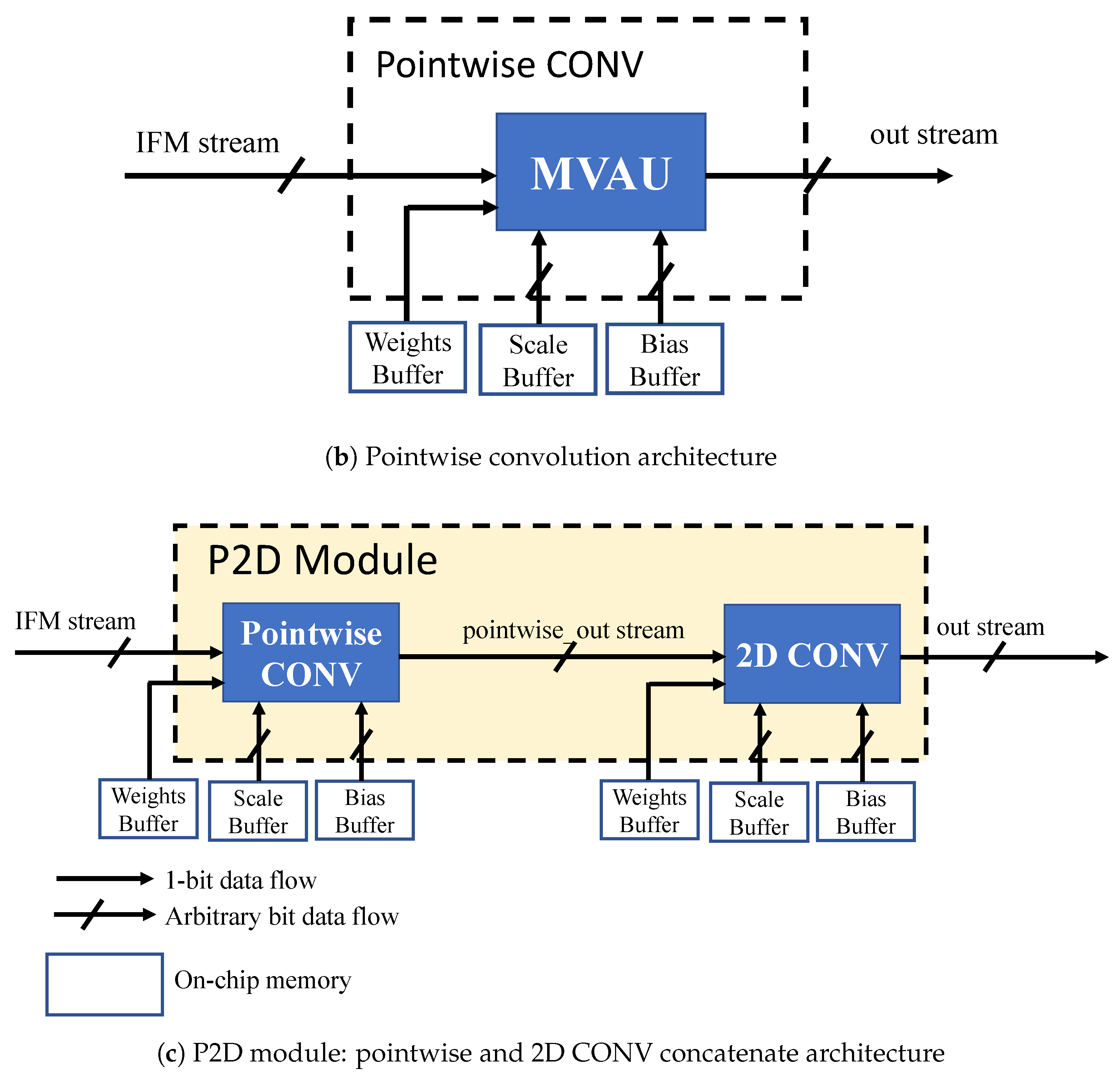
3.3.1. 2D Convolution Module Design
Sliding Window Unit
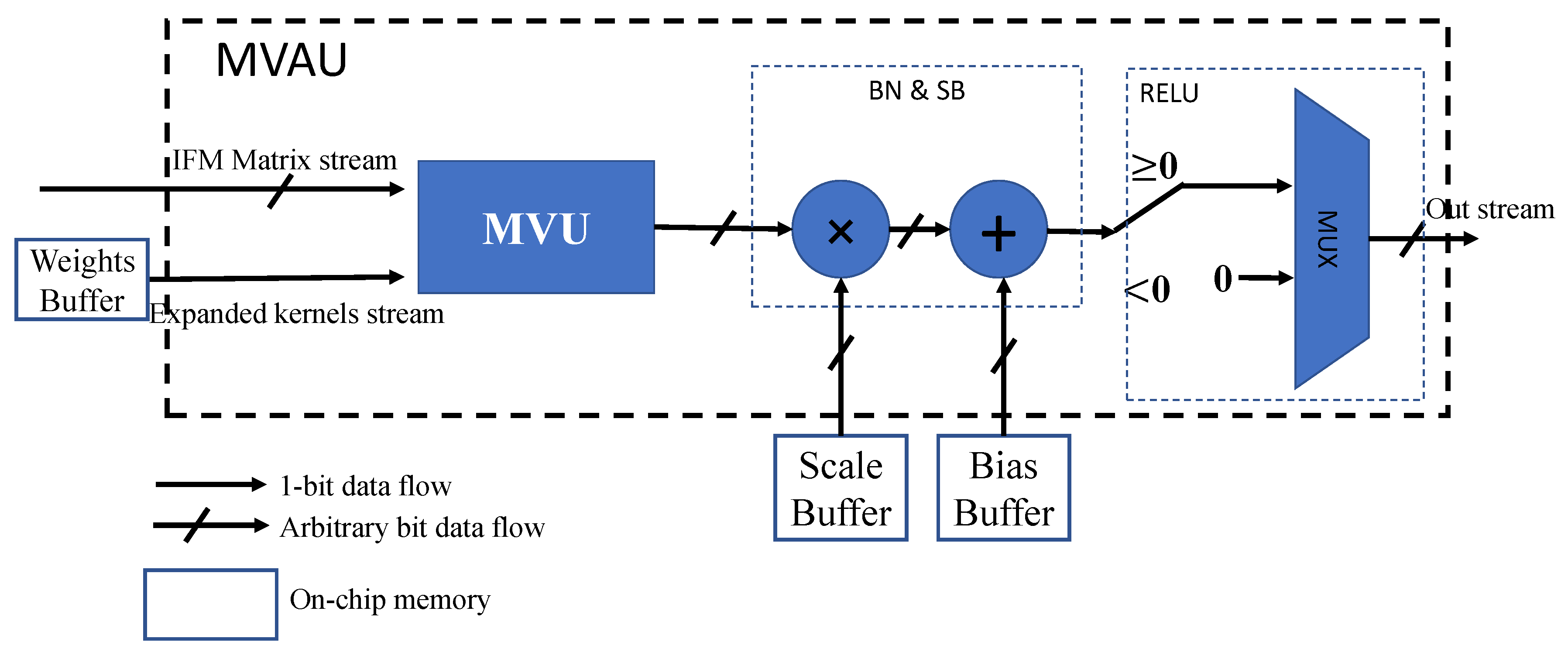
Matrix Vector Activation Unit
- MVU: This module generated the results after XOR operation between IFMs and kernels. We could apply the parallel mechanism in IFMs and OFMs to reduce the processing time on FPGA.
- BN and SB: This module would receive the MVU results, multiply them with the pre-compute parameter scale , and add a parameter bias .
- ReLU: This module would receive the data after SB and apply the ReLU function in (12).
2D Convolution and Pointwise Convolution
3.3.2. Overall Architecture of the AP2D-Net Accelerator
- For the first layer, the IFMs would go through four modules {standard 2D CONV, pooling, P2D, pooling} and output the first layer’s OFM stream.
- For the second layer, the IFMs would go through two modules {P2D, pooling} and output the second layer’s OFM stream.
- If it was the last layer in the feature extraction portion of AP2D-Net, the IFMs would go through six modules {P2D, PW CONV, concatenate, PW CONV (for object classification), PW CONV (for BB regression), detection} and output the object and bounding boxes’ information.
- For other layers, the IFMs would only go through the P2D module and output the layer’s OFM stream.
| Algorithm 1 Algorithm for AP2D-Net IP design. |
Input buffer: Image stream (first layer) IFM stream (the other layers) Output buffer: Object and BB stream (last layer) OFM stream (the other layers) We assumed there were L layers for features extraction in AP2D-Net. {The accelerator handles the input stream depending on different layer numbers in the feature extraction portion.} if layer == 1 then else if layer == 2 then else if layer == L then else end if |
3.4. Optimization on a Heterogeneous System
4. Performance Evaluation and Experimental Results
4.1. Dataset
4.2. Training
4.3. Evaluation Criteria
4.4. AP2D-Net Modeling
4.5. Trade-Off between Working Frequency and Energy Consumption
4.6. Hardware Usage on FPGA
4.7. Comparison with FPGA/GPU Designs
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Nvidia. CUDA Toolkit Documentation: Nvidia Developer Zone—CUDA C Programming Guide v8.0; Nvidia: Santa Clara, CA, USA, 2017. [Google Scholar]
- Chetlur, S.; Woolley, C.; Vandermersch, P.; Cohen, J.; Tran, J.; Catanzaro, B.; Shelhamer, E. cudnn: Efficient primitives for deep learning. arXiv 2014, arXiv:1410.0759. [Google Scholar]
- Li, S.; Luo, Y.; Sun, K.; Choi, K. Heterogeneous system implementation of deep learning neural network for object detection in OpenCL framework. In Proceedings of the 2018 International Conference on Electronics, Information, and Communication (ICEIC), Honolulu, HI, USA, 24–27 January 2018; pp. 1–4. [Google Scholar]
- Wang, D.; Xu, K.; Jiang, D. PipeCNN: An OpenCL-based open-source FPGA accelerator for convolution neural networks. In Proceedings of the 2017 International Conference on Field Programmable Technology (ICFPT), Melbourne, VIC, Australia, 11–13 December 2017; pp. 279–282. [Google Scholar]
- Gong, L.; Wang, C.; Li, X.; Chen, H.; Zhou, X. MALOC: A fully pipelined fpga accelerator for convolutional neural networks with all layers mapped on chip. IEEE Trans. Comput.-Aided Des. Integr. Circ. Syst. 2018, 37, 2601–2612. [Google Scholar] [CrossRef]
- Courbariaux, M.; Hubara, I.; Soudry, D.; El-Yaniv, R.; Bengio, Y. Binarized neural networks: Training deep neural networks with weights and activations constrained to+ 1 or −1. arXiv 2016, arXiv:1602.02830. [Google Scholar]
- Rastegari, M.; Ordonez, V.; Redmon, J.; Farhadi, A. XNOR-net: Imagenet classification using binary convolutional neural networks. In European Conference on Computer Vision; Springer: Berlin, Germany, 2016; pp. 525–542. [Google Scholar]
- Horowitz, M. Computing’s energy problem (and what we can do about it). In Proceedings of the 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), San Francisco, CA, USA, 9–13 February 2014; pp. 10–14. [Google Scholar]
- AP2D-Net. 2019. Available online: https://github.com/laski007/AP2D (accessed on 9 May 2020).
- Cong, J.; Xiao, B. Minimizing computation in convolutional neural networks. In International Conference on Artificial Neural Networks; Springer: Berlin, Germany, 2014; pp. 281–290. [Google Scholar]
- Zeng, H.; Chen, R.; Zhang, C.; Prasanna, V. A framework for generating high throughput CNN implementations on FPGAs. In Proceedings of the 2018 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 25–27 February 2018; pp. 117–126. [Google Scholar]
- Aydonat, U.; O’Connell, S.; Capalija, D.; Ling, A.C.; Chiu, G.R. An opencl™ deep learning accelerator on arria 10. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; pp. 55–64. [Google Scholar]
- DiCecco, R.; Lacey, G.; Vasiljevic, J.; Chow, P.; Taylor, G.; Areibi, S. Caffeinated FPGAs: FPGA framework for convolutional neural networks. In Proceedings of the 2016 International Conference on Field-Programmable Technology (FPT), Monterey, CA, USA, 21–23 February 2016; pp. 265–268. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Suda, N.; Chandra, V.; Dasika, G.; Mohanty, A.; Ma, Y.; Vrudhula, S.; Seo, J.s.; Cao, Y. Throughput-optimized OpenCL-based FPGA accelerator for large-scale convolutional neural networks. In Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 21–23 February 2016; pp. 16–25. [Google Scholar]
- Li, H.; Fan, X.; Jiao, L.; Cao, W.; Zhou, X.; Wang, L. A high performance FPGA-based accelerator for large-scale convolutional neural networks. In Proceedings of the 2016 26th International Conference on Field Programmable Logic and Applications (FPL), Lausanne, Switzerland, 26–29 August 2016; pp. 1–9. [Google Scholar]
- Motamedi, M.; Gysel, P.; Akella, V.; Ghiasi, S. Design space exploration of FPGA-based deep convolutional neural networks. In Proceedings of the 2016 21st Asia and South Pacific Design Automation Conference (ASP-DAC), Macao, China, 25–28 January 2016; pp. 575–580. [Google Scholar]
- Nurvitadhi, E.; Weisz, G.; Wang, Y.; Hurkat, S.; Nguyen, M.; Hoe, J.C.; Martínez, J.F.; Guestrin, C. Graphgen: An fpga framework for vertex-centric graph computation. In Proceedings of the 2014 IEEE 22nd Annual International Symposium on Field-Programmable Custom Computing Machines, Boston, MA, USA, 11–13 May 2014; pp. 25–28. [Google Scholar]
- Ma, Y.; Cao, Y.; Vrudhula, S.; Seo, J.S. Optimizing the convolution operation to accelerate deep neural networks on FPGA. IEEE Trans. Very Large Scale Integr. Syst. 2018, 26, 1354–1367. [Google Scholar] [CrossRef]
- Zhang, C.; Li, P.; Sun, G.; Guan, Y.; Xiao, B.; Cong, J. Optimizing fpga-based accelerator design for deep convolutional neural networks. In Proceedings of the 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2015; pp. 161–170. [Google Scholar]
- Gokhale, V.; Jin, J.; Dundar, A.; Martini, B.; Culurciello, E. A 240 g-ops/s mobile coprocessor for deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; pp. 682–687. [Google Scholar]
- Fujii, T.; Sato, S.; Nakahara, H. A threshold neuron pruning for a binarized deep neural network on an FPGA. IEICE Tran. Inf. Syst. 2018, 101, 376–386. [Google Scholar] [CrossRef]
- Hailesellasie, M.; Hasan, S.R.; Khalid, F.; Wad, F.A.; Shafique, M. Fpga-based convolutional neural network architecture with reduced parameter requirements. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar]
- Geng, T.; Wang, T.; Sanaullah, A.; Yang, C.; Patel, R.; Herbordt, M. A framework for acceleration of cnn training on deeply-pipelined fpga clusters with work and weight load balancing. In Proceedings of the 2018 28th International Conference on Field Programmable Logic and Applications (FPL), Dublin, Ireland, 27–31 August 2018; pp. 394–3944. [Google Scholar]
- Rahman, A.; Lee, J.; Choi, K. Efficient FPGA acceleration of convolutional neural networks using logical-3D compute array. In Proceedings of the 2016 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 14–18 March 2016; pp. 1393–1398. [Google Scholar]
- Qiu, J.; Wang, J.; Yao, S.; Guo, K.; Li, B.; Zhou, E.; Yu, J.; Tang, T.; Xu, N.; Song, S.; et al. Going deeper with embedded FPGA platform for convolutional neural network. In Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 21–23 February 2016; pp. 26–35. [Google Scholar]
- Guo, K.; Sui, L.; Qiu, J.; Yu, J.; Wang, J.; Yao, S.; Han, S.; Wang, Y.; Yang, H. Angel-Eye: A complete design flow for mapping CNN onto embedded FPGA. IEEE Trans. Comput.-Aided Des. Integr. Circ. Syst. 2017, 37, 35–47. [Google Scholar] [CrossRef]
- Zhang, C.; Wu, D.; Sun, J.; Sun, G.; Luo, G.; Cong, J. Energy-efficient CNN implementation on a deeply pipelined FPGA cluster. In Proceedings of the 2016 International Symposium on Low Power Electronics and Design, San Francisco, CA, USA, 8–10 August 2016; pp. 326–331. [Google Scholar]
- Guan, Y.; Liang, H.; Xu, N.; Wang, W.; Shi, S.; Chen, X.; Sun, G.; Zhang, W.; Cong, J. FP-DNN: An automated framework for mapping deep neural networks onto FPGAs with RTL-HLS hybrid templates. In Proceedings of the 2017 IEEE 25th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), Napa, CA, USA, 30 April–2 May 2017; pp. 152–159. [Google Scholar]
- Bai, L.; Zhao, Y.; Huang, X. A CNN accelerator on FPGA using depthwise separable convolution. IEEE Trans. Circ. Syst. II Express Briefs 2018, 65, 1415–1419. [Google Scholar] [CrossRef]
- Jordà, M.; Valero-Lara, P.; Peña, A.J. Performance Evaluation of cuDNN Convolution Algorithms on NVIDIA Volta GPUs. IEEE Access 2019, 7, 70461–70473. [Google Scholar] [CrossRef]
- Zhou, S.; Wu, Y.; Ni, Z.; Zhou, X.; Wen, H.; Zou, Y. Dorefa-net: Training low bitwidth convolutional neural networks with low bitwidth gradients. arXiv 2016, arXiv:1606.06160. [Google Scholar]
- Han, S.; Liu, X.; Mao, H.; Pu, J.; Pedram, A.; Horowitz, M.A.; Dally, W.J. EIE: Efficient inference engine on compressed deep neural network. ACM SIGARCH Comput. Arch. News 2016, 44, 243–254. [Google Scholar] [CrossRef]
- Motamedi, M.; Gysel, P.; Ghiasi, S. PLACID: A platform for FPGA-based accelerator creation for DCNNs. ACM Trans. Multimed. Comput. Commun. Appl. 2017, 13, 1–21. [Google Scholar] [CrossRef]
- Zhang, C.; Sun, G.; Fang, Z.; Zhou, P.; Pan, P.; Cong, J. Caffeine: Toward uniformed representation and acceleration for deep convolutional neural networks. IEEE Trans. Comput.-Aided Des. Integr. Circ. Syst. 2018, 38, 2072–2085. [Google Scholar] [CrossRef]
- Umuroglu, Y.; Fraser, N.J.; Gambardella, G.; Blott, M.; Leong, P.; Jahre, M.; Vissers, K. FINN: A framework for fast, scalable binarized neural network inference. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2017; pp. 65–74. [Google Scholar]
- Xilinx. AXI DMA v7.1 LogiCORE IP Product Guide. In Vivado Design Suite; Xilinx: San Jose, CA, USA, 2019. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Zhang, Z.; He, T.; Zhang, H.; Zhang, Z.; Xie, J.; Li, M. Bag of freebies for training object detection neural networks. arXiv 2019, arXiv:1902.04103. [Google Scholar]
- Xu, X.; Zhang, X.; Yu, B.; Hu, X.S.; Rowen, C.; Hu, J.; Shi, Y. Dac-sdc low power object detection challenge for uav applications. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef] [PubMed]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Memory Type | Memory Size | Energy Dissipation |
|---|---|---|
| Cache (on-chip memory) 64 bit | 8 KB | 10 pJ |
| 32 KB | 20 pJ | |
| 1 MB | 100 pJ | |
| DRAM | - | 1.3–2.6 nJ |
| Data Type | Operation | Width (Bit) | Energy Dissipation (pJ) |
|---|---|---|---|
| Floating | Add | 16 | 0.4 |
| 32 | 0.9 | ||
| Multiply | 16 | 1.1 | |
| 32 | 3.7 | ||
| Integer | Add | 8 | 0.03 |
| 32 | 0.1 | ||
| Multiply | 8 | 0.2 | |
| 32 | 3.1 |
| Category | Person | Car | Riding | Boat | Group | Wakeboarder | Drone | Truck | Paraglider | Whale | Building | Horse Rrider |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Percentage (%) | 29.90 | 26.74 | 18.18 | 5.57 | 5.15 | 3.53 | 2.76 | 2.54 | 1.81 | 1.64 | 1.44 | 0.74 |
| Activation Quantization | PW CONV Channel # | 2D CONV Channel # | Feature Extraction Layer # | Training IOU | Validation IOU |
|---|---|---|---|---|---|
| 5 bit | 64 | 96 | 15 | 0.65 | 0.53 |
| 5 bit | 64 | 96 | 17 | 0.64 | 0.52 |
| 5 bit | 64 | 96 | 19 | 0.65 | 0.50 |
| 4 bit | 128 | 128 | 15 | 0.65 | 0.53 |
| 3 bit | 128 | 160 | 15 | 0.75 | 0.55 |
| 2 bit | 128 | 256 | 15 | 0.72 | 0.49 |
| Component (Total) | Percentage (%) |
|---|---|
| LUT (70K) | 77.6 |
| Flip-flop (F/F) (141K) | 66.9 |
| DSP (360) | 79.7 |
| BRAM (216) | 75.2 |
| [5] | [30] | [27] | [24] | [29] | [19] | Our Work | |
|---|---|---|---|---|---|---|---|
| Year | 2018 | 2018 | 2018 | 2018 | 2017 | 2018 | 2019 |
| CNN model | AlexNet | MobileNet V2 | VGG16 | VGG16 | VGG19 | VGG16 | AP2D-Net |
| FPGA | Zynq XC7Z020 | Intel Arria 10 SoC | Zynq XC7Z020 | Virtex-7 VX690t | Stratix V GSMD5 | Intel Arria 10 | Ultra96 |
| Clock (MHz) | 200 | 133 | 214 | 150 | 150 | 200 | 300 |
| BRAMs (36Kb) | 268 | 1844 † | 85.5 | 1220 | 919 † | 2232 † | 162 |
| DSPs | 218 | 1278 | 190 | 2160 | 1036 | 1518 | 287 |
| LUTs | 49.8K | - | 29.9K | - | - | - | 54.3K |
| Flip-flop (F/F) | 61.2K | - | 35.5K | - | - | - | 94.3K |
| Precision (W, A) * | (16, 16) | (16, 16) | (8, 8) | (16, 16) | (16, 16) | (16, 16) | (1–24, 3) |
| Latency (ms) | 16.7 | 3.75 | 364 | 106.6 | 107.7 | 43.2 | 32.8 |
| Throughput (GOPS) | 80.35 | 170.6 | 84.3 | 290 | 364.4 | 715.9 | 130.2 |
| Power (W) | - | - | - | 35 | 25 | - | 5.59 |
| Power efficiency (GOPS/W) | - | - | - | 8.28 | 14.57 | - | 23.3 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Sun, K.; Luo, Y.; Yadav, N.; Choi, K. Novel CNN-Based AP2D-Net Accelerator: An Area and Power Efficient Solution for Real-Time Applications on Mobile FPGA. Electronics 2020, 9, 832. https://doi.org/10.3390/electronics9050832
Li S, Sun K, Luo Y, Yadav N, Choi K. Novel CNN-Based AP2D-Net Accelerator: An Area and Power Efficient Solution for Real-Time Applications on Mobile FPGA. Electronics. 2020; 9(5):832. https://doi.org/10.3390/electronics9050832
Chicago/Turabian StyleLi, Shuai, Kuangyuan Sun, Yukui Luo, Nandakishor Yadav, and Ken Choi. 2020. "Novel CNN-Based AP2D-Net Accelerator: An Area and Power Efficient Solution for Real-Time Applications on Mobile FPGA" Electronics 9, no. 5: 832. https://doi.org/10.3390/electronics9050832
APA StyleLi, S., Sun, K., Luo, Y., Yadav, N., & Choi, K. (2020). Novel CNN-Based AP2D-Net Accelerator: An Area and Power Efficient Solution for Real-Time Applications on Mobile FPGA. Electronics, 9(5), 832. https://doi.org/10.3390/electronics9050832