Intelligent Prediction of Private Information Diffusion in Social Networks



Abstract
1. Introduction
2. Related Work
3. Prediction of User Forwarding Behavior
3.1. Analysis of Influencing Factors of Forwarding
3.1.1. Weight of Privacy Information Entropy
- The probability that the ith private information belongs to category j is:
- The entropy value of class j is:where, .
- The entropy weight of class j is:Thus, the weight of users’ privacy information entropy can be obtained:When , ; otherwise, .
3.1.2. Forwarding Users’ Privacy Concerns
3.1.3. Relation with Privacy Information Releasing User
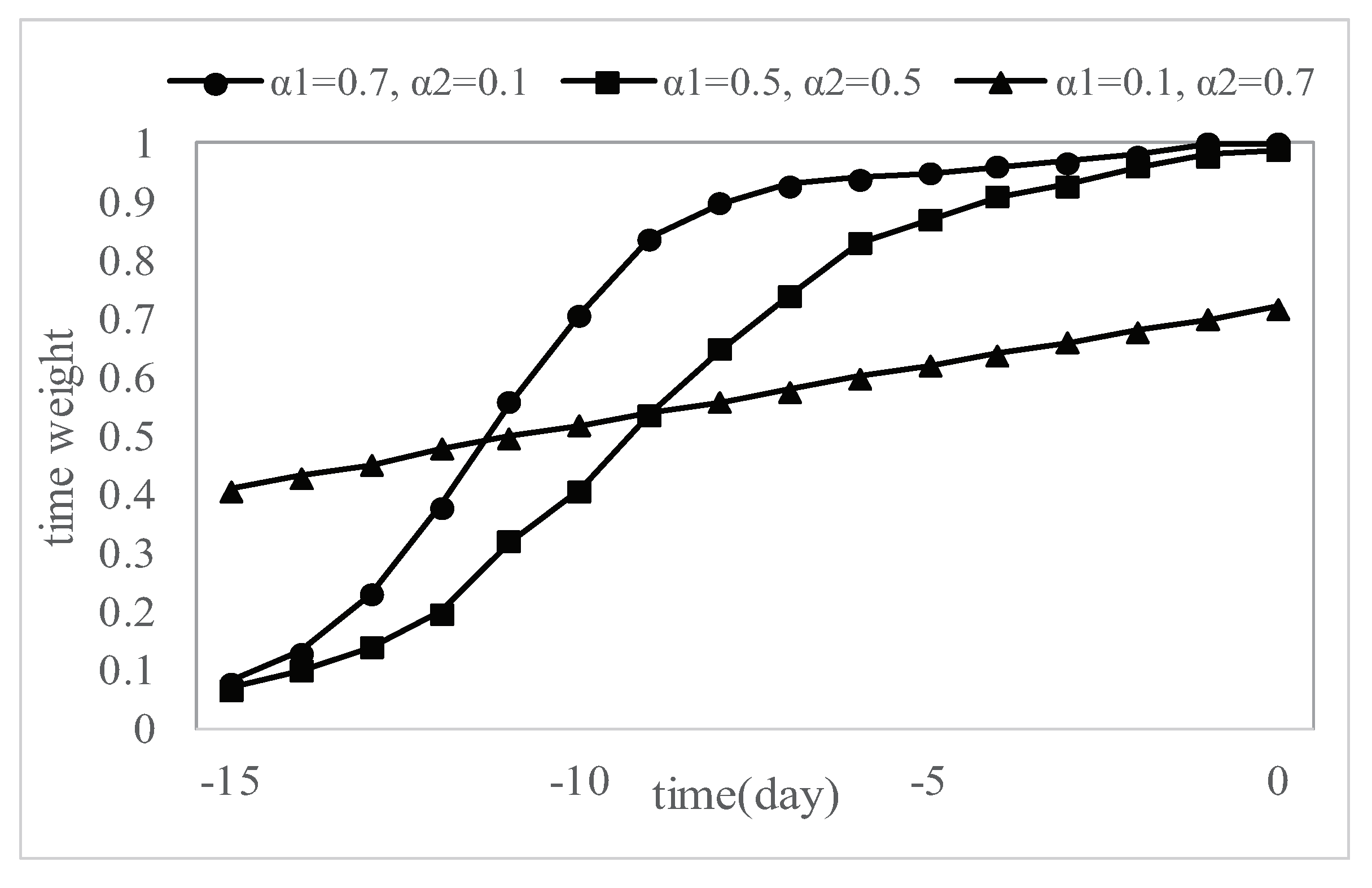
3.1.4. Release Time of Private Information
3.2. Prediction Model of User Forwarding Behavior
4. Privacy Information Diffusion Prediction
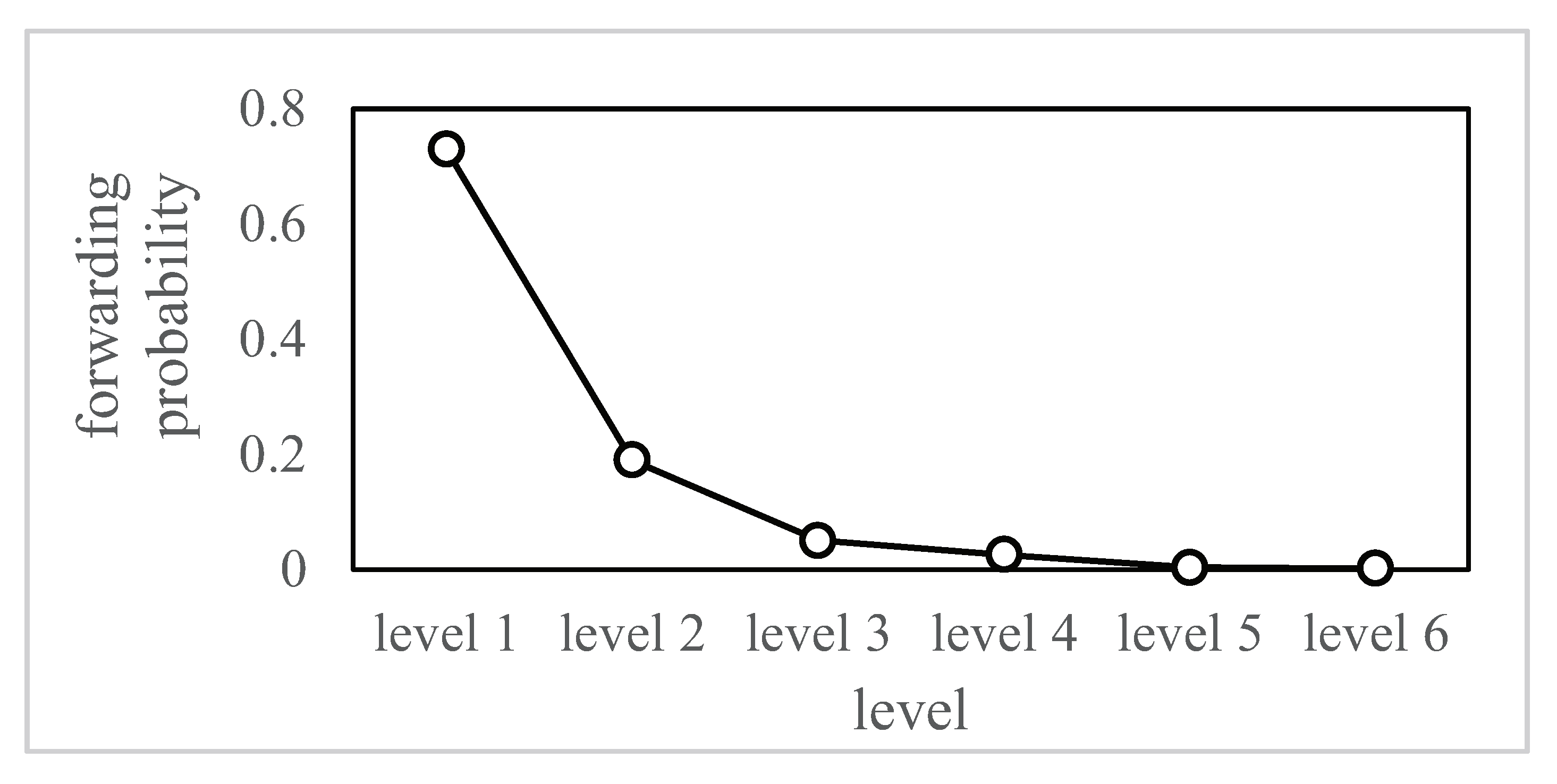
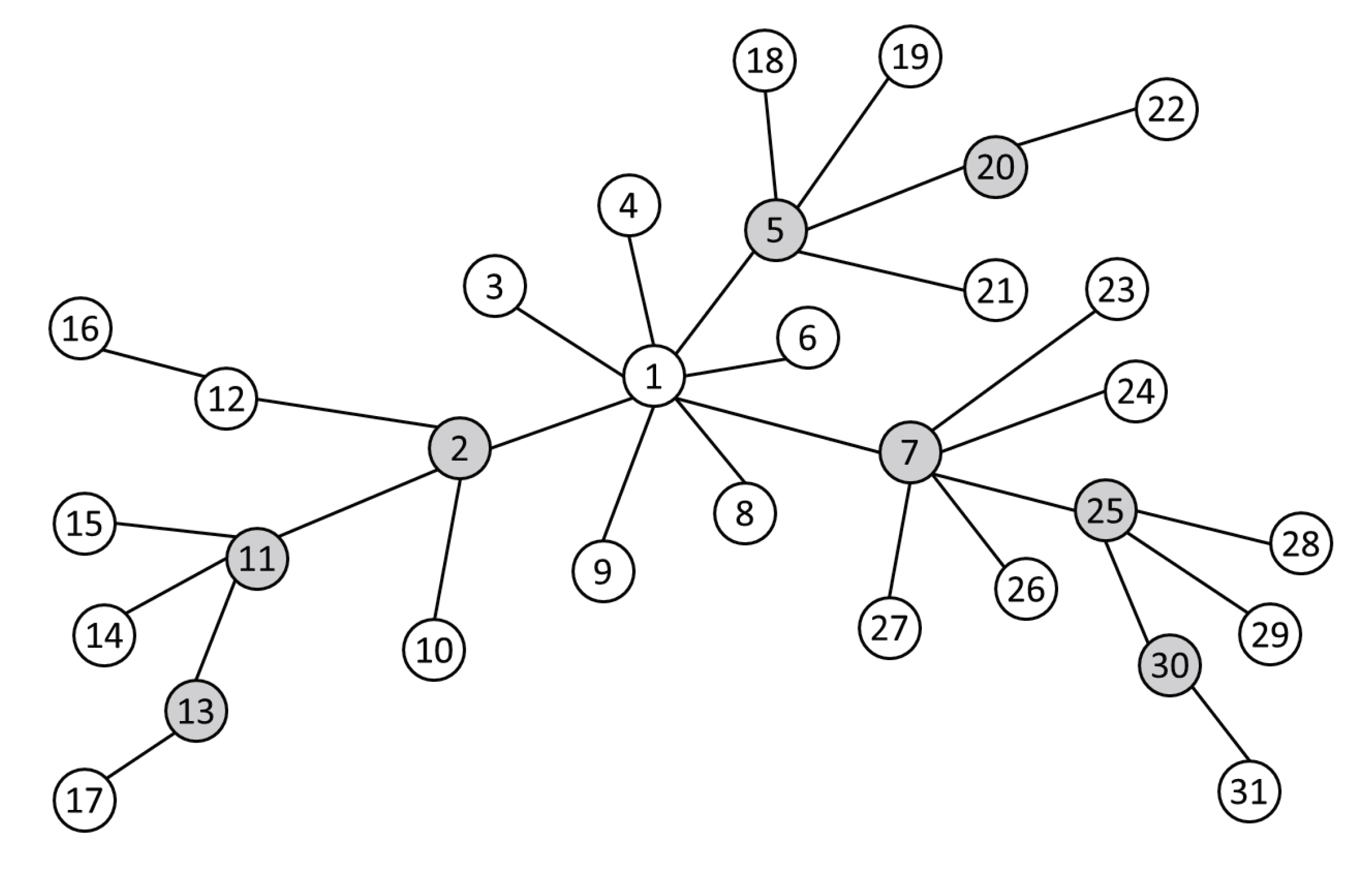
4.1. Choice of Key Forwarding Nodes
4.1.1. Calculate the Time Interaction Behavior Weight between User u and User v
- (1)
- Calculate the probability of the information being viewed by the user’s fans .where, Friends(v) represents concerned users collection of fan v, even . represents the total number of messages released by user u during the time period t.
- (2)
- Calculate the activity of fan vwhere, is the total amount of messages released by the user during time period t, is the number of times someone retweets someone else’s message, is the number of times where v participated in comments.
- (3)
- Calculate the interaction strength between fan v and user u. It reflects the power degree of relation between users. The stronger the interaction relationship, the greater the influence on information recipient, and the more likely he/she will participate in forwarding. It can be calculated by the following Equation (13):where, , are respectively the total number of micro-blog and total number of comments which v forward u within time period. , are respectively the weight of retweet and comment, and .
4.1.2. Measure the Contribution Rate of Fan v of User u and the Fan w to u
4.1.3. Influence Calculation of User u
4.2. Determination of Key Forwarding Path
| Algorithm 1 critical path search algorithm |
| Input: social graph G(V,E), released user u, privacy micro-blog T |
| Output: critical path set |
|
4.3. Privacy Diffusion Prediction Model
| Algorithm 2 Diffusion prediction model based critical path DEPM-KP |
| Input: social graph G(V,E), released user u, privacy information T |
| Output: diffusion scale , diffusion depth |
|
5. Experiment
5.1. Experimental Data and Evaluation Criteria
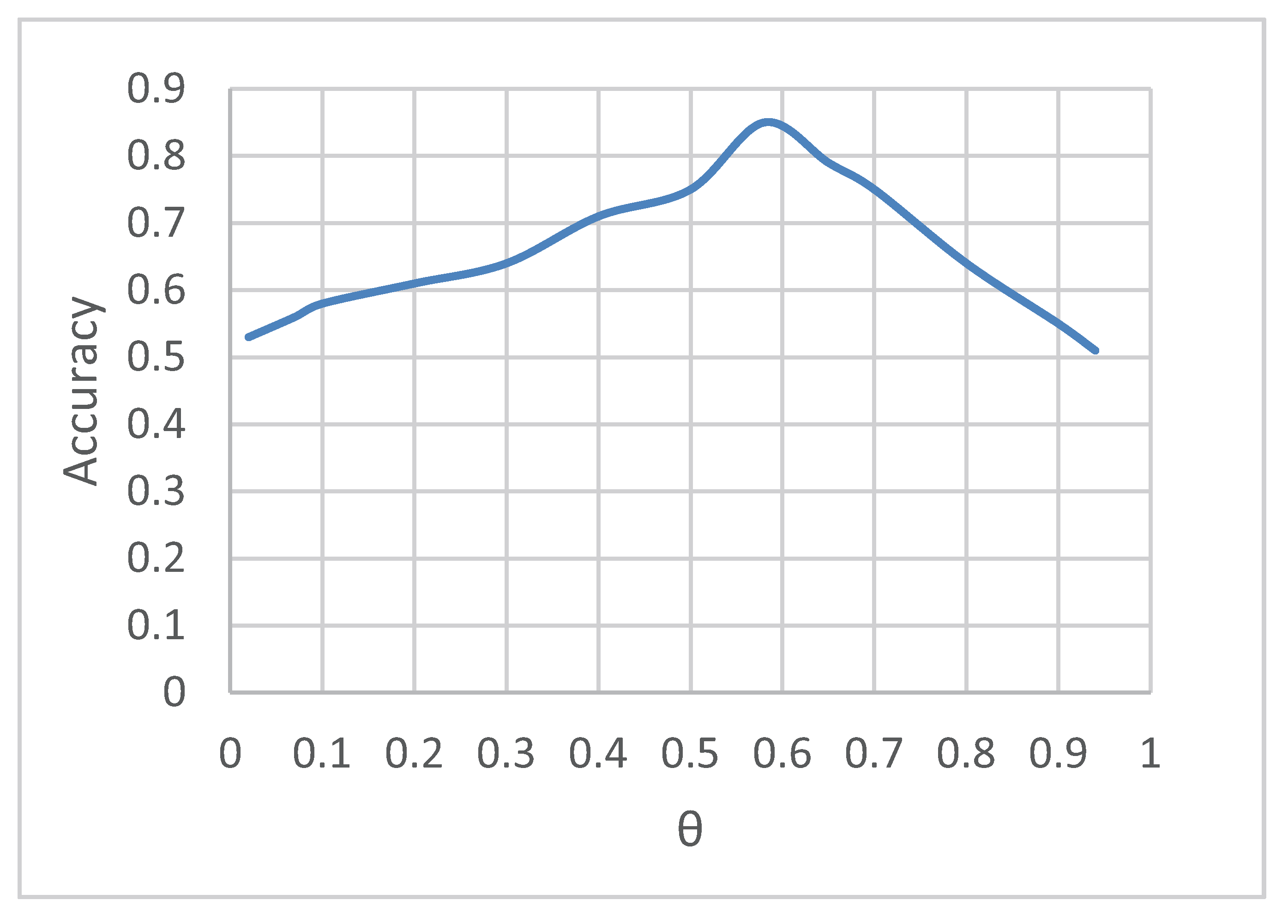
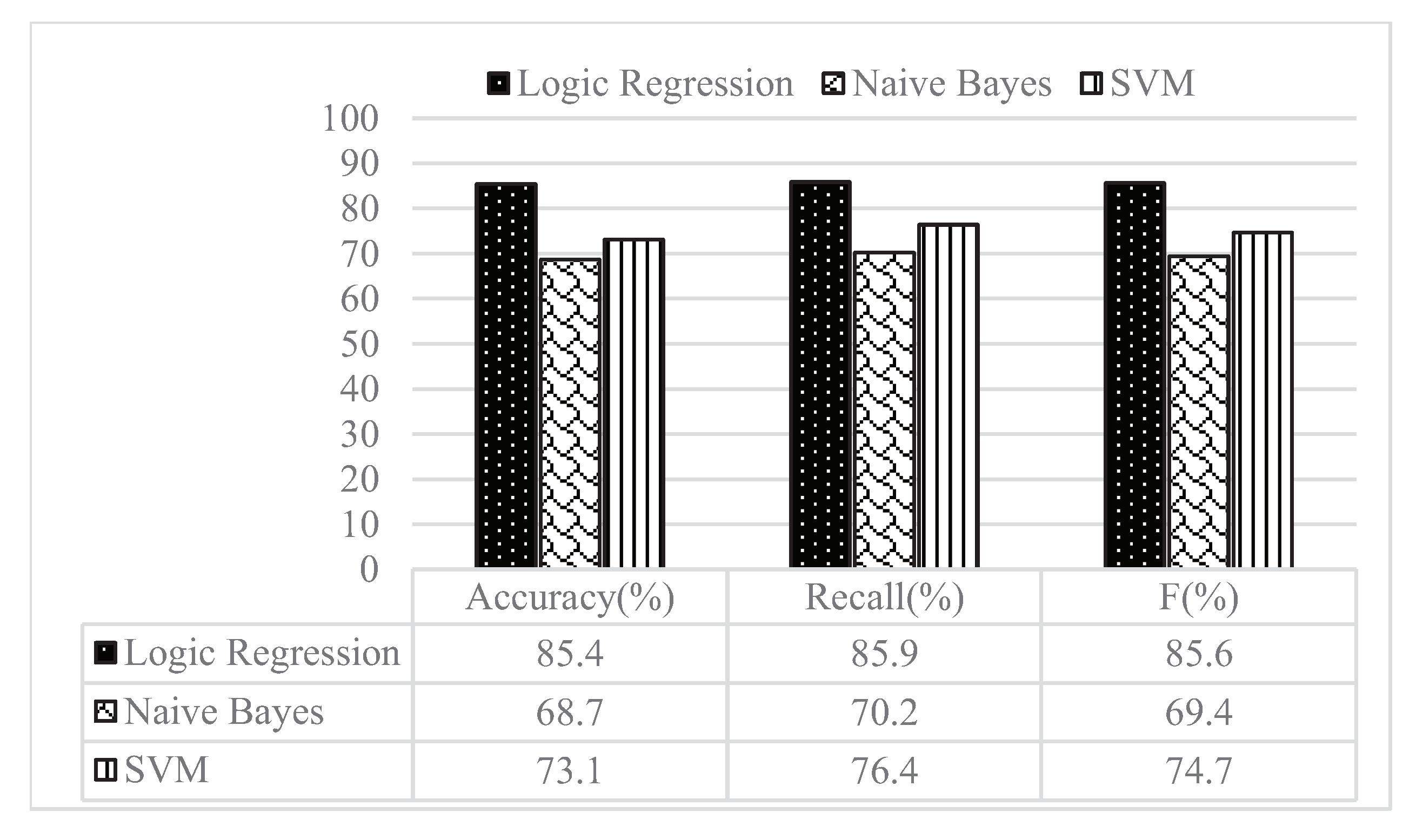
5.2. User Forwarding Behavior Prediction Experiment
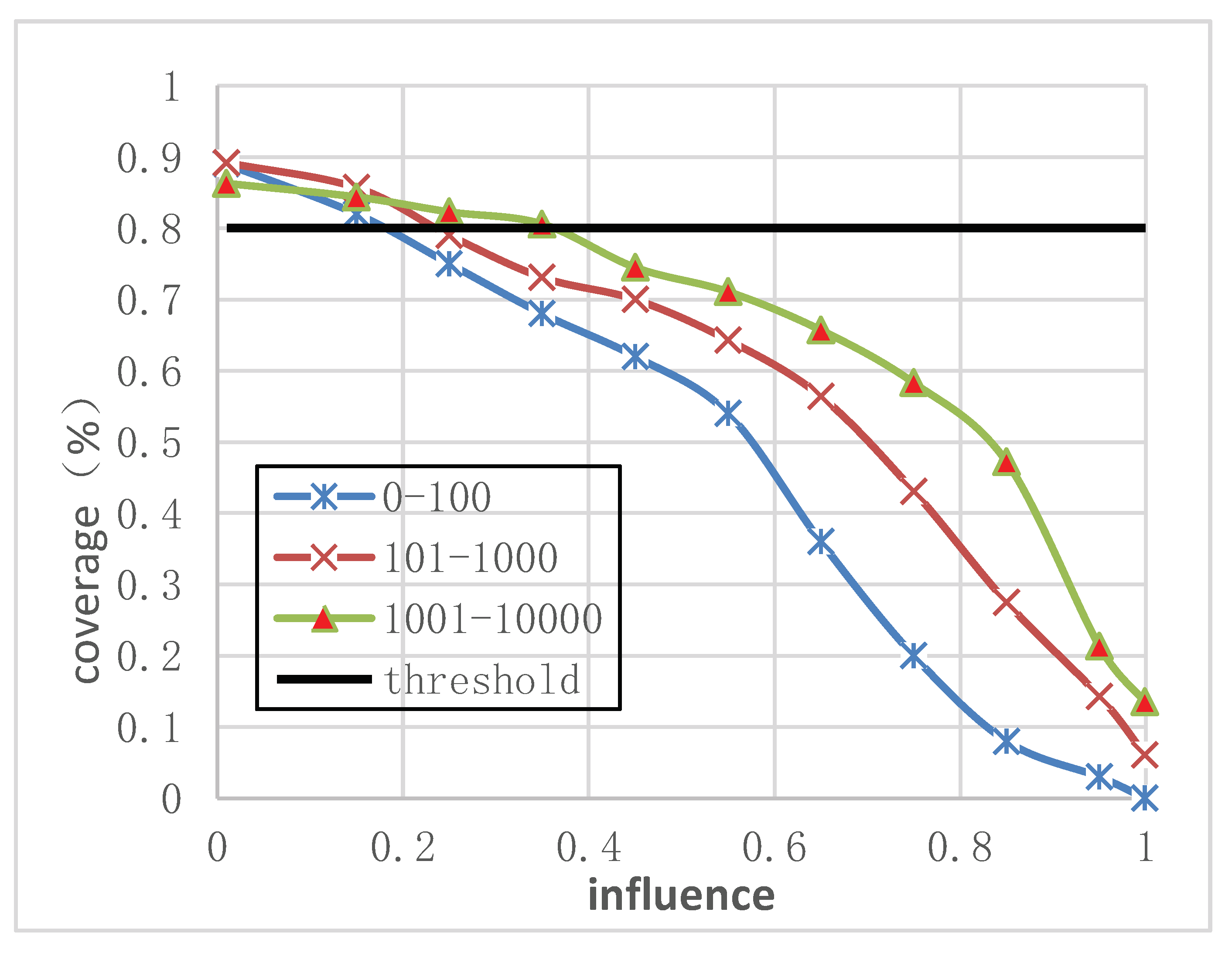
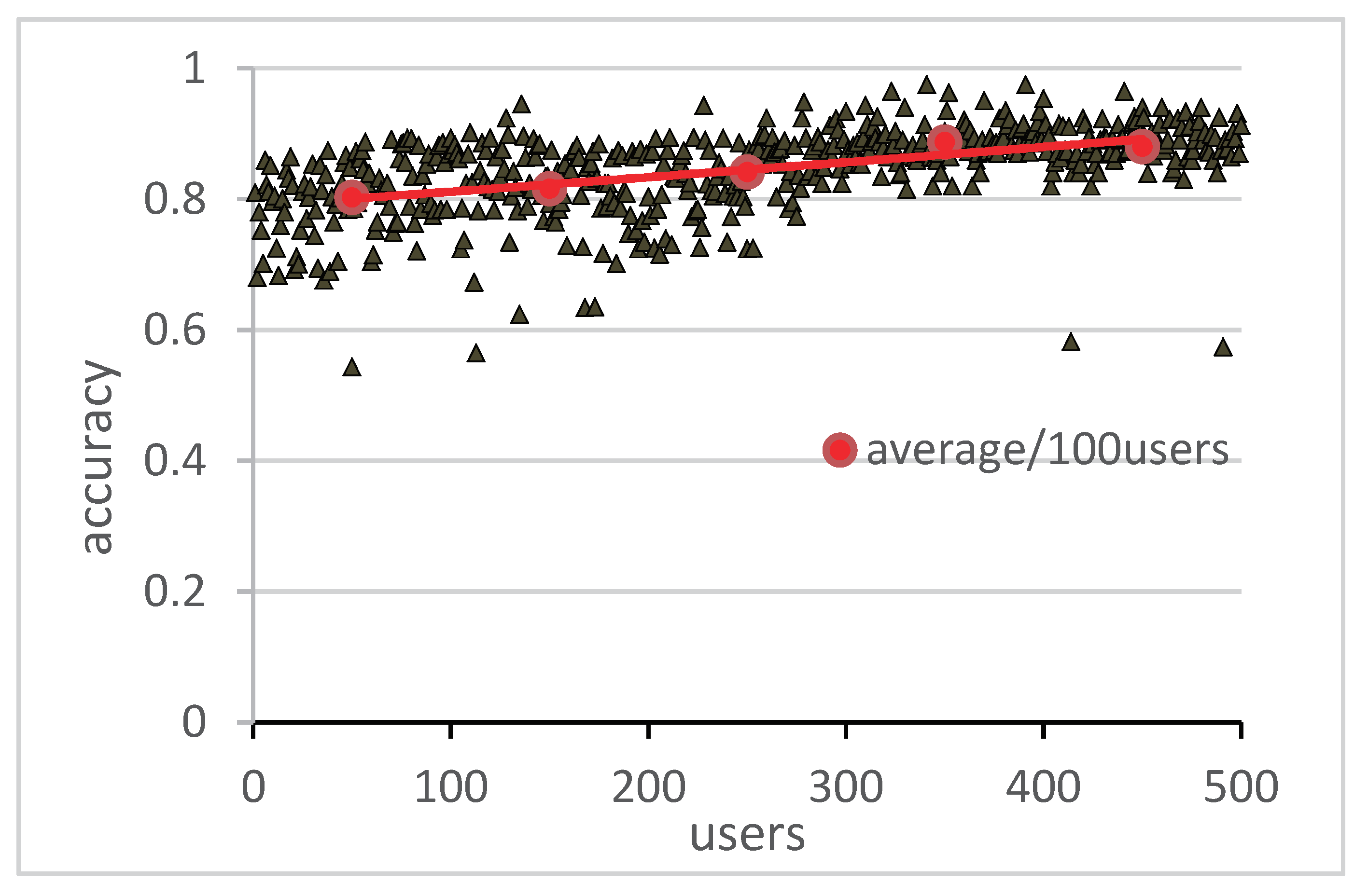
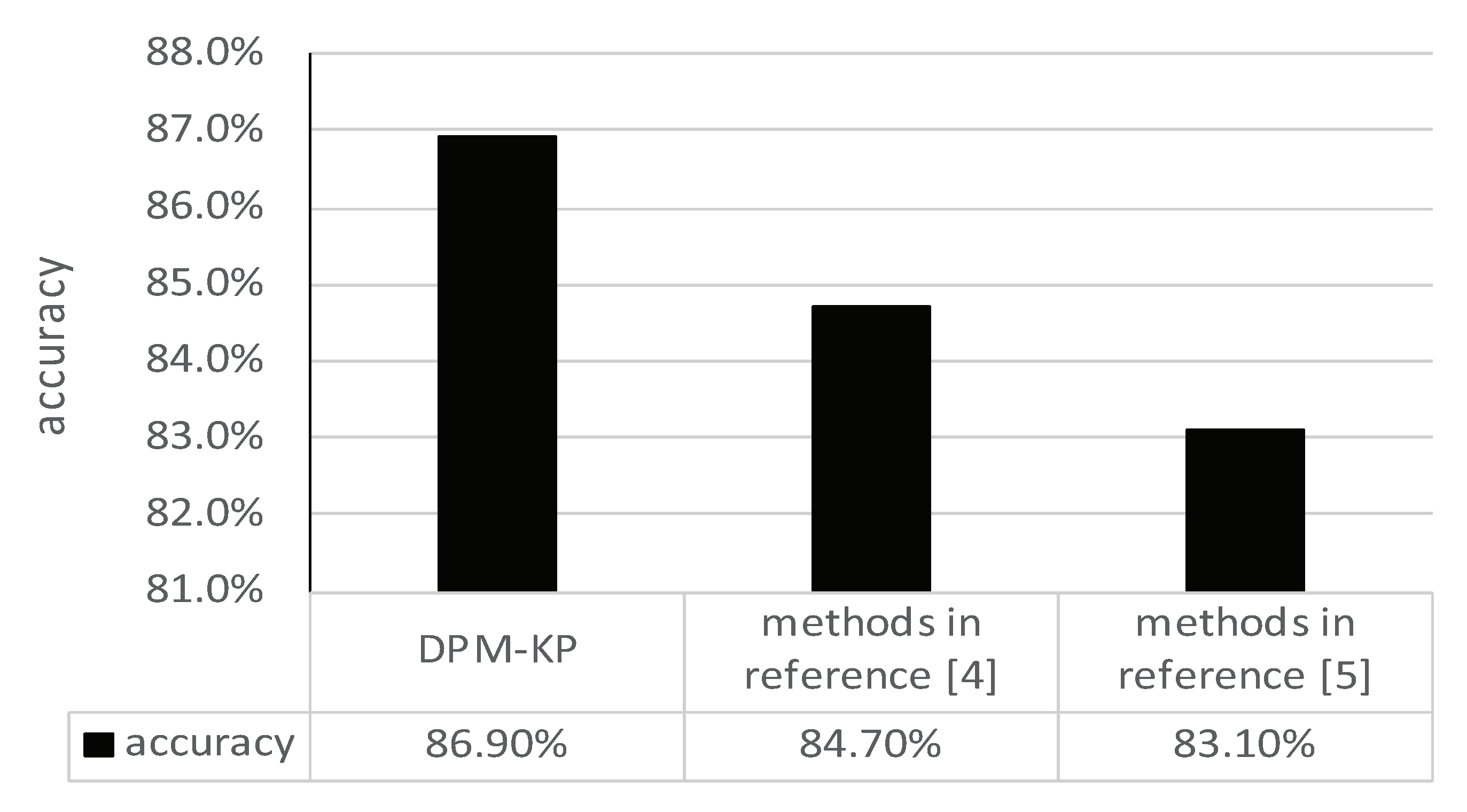
5.3. Privacy Diffusion Prediction Experiment
- (1)
- micro-blog is often forwarded;
- (2)
- a certain amount of micro-blog forwarding.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Dong, G.; Gao, J.; Huang, L.; Shi, C. Online Burst Events Detection Oriented Real-Time Microblog Message Stream. Comput. Mater. Contin. 2019, 60, 213–225. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, T.; Jin, X.; Cheng, X. Personal privacy protection in the era of big data. J. Comput. Res. Dev. 2015, 52, 230–232. [Google Scholar]
- Li, Z. Study on User Privacy in Mobile Internet; Beijng University of Posts and Telecommunications Press: Beijng, China, 2019. [Google Scholar]
- Hou, W.; Huang, Y.; Zhang, K. Research of micro-blog diffusion effect based on analysis of retweet behavior. In Proceedings of the IEEE 14th International Conference on Cognitive Informatics & Cognitive Computing, Beijing, China, 6–8 July 2015; pp. 255–261. [Google Scholar]
- Li, Y. Research on Microblog Communication Effect Prediction Technology. Ph.D. Thesis, PLA University of Information Engineering, Zhengzhou, China, 2013. [Google Scholar]
- Zhou, H.; Sun, G.; Fu, S.; Jiang, W.; Xue, J. A Scalable Approach for Fraud Detection in Online E-Commerce Transactions with Big Data Analytics. Comput. Mater. Contin. 2019, 60, 179–192. [Google Scholar] [CrossRef]
- Wang, B.; Kong, W.; Guan, H.; Xiong, N.N. Air Quality Forecasting Based on Gated Recurrent Long Short Term Memory Model in Internet of Things. IEEE Access 2019, 7, 69524–69534. [Google Scholar] [CrossRef]
- Huang, Y.; Liu, Z.; Yu, M.; Gao, M. The Microblog Retweeting Prediction Evaluation System and Performance Comparation The Microblog Retweeting Prediction Evaluation System and Performance ComparationThe Microblog Retweeting Prediction Evaluation System and Performance Comparation. J. Harbin Univ. Sci. Technol. 2013, 18, 52–57. [Google Scholar]
- Yu, H.; Yang, X. Studying on the node’s influence and propagation path modes in microblogging. J. Commun. 2012, S1, 96–102. [Google Scholar]
- Wu, K. Information Transmission Modeling and Node Influence Research Based on Microblog. Ph.D. Thesis, PLA University of Information Engineering, Zhengzhou, China, 2013. [Google Scholar]
- Gruhl, D.; Guha, R.; Liben-Nowell, D.; Tomkins, A. Information diffusion through blogspace. In Proceedings of the 13th International conference on World Wide Web, New York, NY, USA, 17–20 May 2004; pp. 491–501. [Google Scholar]
- Yang, X.; Liu, Y. Application of Improved SIR Model on Information Diffusion in Microblog. Sci. Mosaic 2015, 2, 12–16. [Google Scholar]
- Leskovec, J.; McGlohon, M.; Faloutsos, C.; Glance, N.; Hurst, M. Cascading behavior in large blog graphs: Patterns and a model. In Society of Applied and Industrial Mathematics: Data Mining; Carnegie Mellon University: Pittsburgh, PA, USA, 2007; pp. 551–556. [Google Scholar]
- Xie, J.; Liu, G.; Su, B.; Meng, K. Prediction of User’s Retweet Behavior in Social Network. J. Shanghai Jiaotong Univ. 2013, 4, 584–588. [Google Scholar]
- Zhang, Y.; Lu, R.; Yang, Q. Predicting retweeting in microblogs. J. Chin. Inf. Process. 2012, 26, 109–114. [Google Scholar]
- Cao, J.; Wu, J.; Shi, W.; Liu, B.; Zheng, X.; Luo, J. Sina Microblog Information Diffusion Analysis and Prediction. Chin. J. Comput. 2014, 37, 779–790. [Google Scholar]
- Xu, H.; Xu, Y. Research on privacy disclosure detection in microblog. In Proceedings of the 3rd IEEE International Conference on Computer and Communications, Chengdu, China, 13–16 December 2017; pp. 1479–1486. [Google Scholar]
- Hu, J.; Sun, J. A case retrieval method of hybrid data based on information entropy. In Proceedings of the 2nd IEEE International Conference on Computer and Communications, Chengdu, China, 14–17 October 2016; pp. 155–159. [Google Scholar]
- Bioglio, L.; Pensa, R. Modeling the impact of privacy on information diffusion in social networks. In International Workshop on Complex Networks; Springer: Cham, Switzerland, 2017; pp. 95–107. [Google Scholar]
- Li, X.; Croft, W. Time-based language models. In Proceedings of the Twelfth International Conference on Information and Knowledge Management, New Orleans, LA, USA, November 2003; Association for Computing Machinery: New York, NY, USA, 2003; pp. 469–475. [Google Scholar]
- Ding, Z.; Jia, Y.; Zhou, B.; Tang, F. Survey of Influence Analysis for Social Networks. Comput. Sci. 2014, 41, 48–53. [Google Scholar]
- Richardson, M.; Domingos, P. Mining knowledge-sharing sites for viral marketing. In Proceedings of the Eighth ACM SIGKDD International Conference On Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 61–70. [Google Scholar]
- Ullah, F.; Lee, S. Identification of influential nodes based on temporal-aware modeling of multi-hop neighbor interactions for influence spread maximization. Physica A 2017, 486, 968–985. [Google Scholar] [CrossRef]
- Chaoran, F.; Huang, S.; Li, Y. Study on microblog social network community detection. Microcomput. Appl. 2012, 23, 67–70. [Google Scholar]
- Chen, Z.; Liu, X.; Li, B. Analyzing micro-blog users’ propagation influence based on behavior and community. Appl. Res. Comput. 2018, 7, 37. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
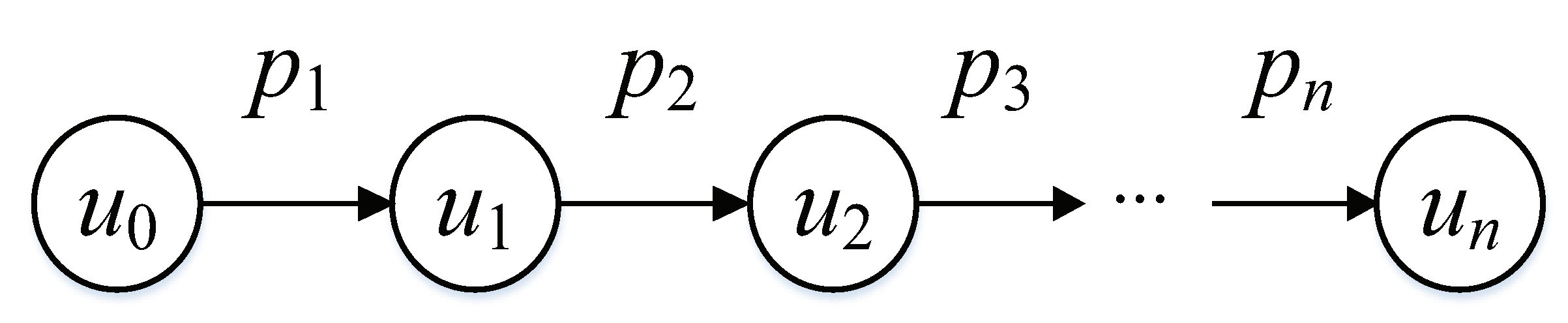{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Privacy Information | Class 0 | Class 1 | Class 2 | Class 3 |
|---|---|---|---|---|
| privacy information 1 | ||||
| privacy information 2 | ||||
| 0.1 | 0.5 | 0.3 | 0.1 |
| Value Range of | 0 | (0, 0.5) | (0.5,1) | 1 |
| prediction accuracy of privacy diffusion depth | 89.3% | 10.1% | 0.5% | 0.1% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Jin, H.; Yu, X.; Xie, H.; Xu, Y.; Xu, H.; Zeng, H. Intelligent Prediction of Private Information Diffusion in Social Networks. Electronics 2020, 9, 719. https://doi.org/10.3390/electronics9050719
Li Y, Jin H, Yu X, Xie H, Xu Y, Xu H, Zeng H. Intelligent Prediction of Private Information Diffusion in Social Networks. Electronics. 2020; 9(5):719. https://doi.org/10.3390/electronics9050719
Chicago/Turabian StyleLi, Yangyang, Hao Jin, Xiangyi Yu, Haiyong Xie, Yabin Xu, Huajun Xu, and Huacheng Zeng. 2020. "Intelligent Prediction of Private Information Diffusion in Social Networks" Electronics 9, no. 5: 719. https://doi.org/10.3390/electronics9050719
APA StyleLi, Y., Jin, H., Yu, X., Xie, H., Xu, Y., Xu, H., & Zeng, H. (2020). Intelligent Prediction of Private Information Diffusion in Social Networks. Electronics, 9(5), 719. https://doi.org/10.3390/electronics9050719