Measuring Traffic Volumes Using an Autoencoder with No Need to Tag Images with Labels



Abstract
:1. Introduction
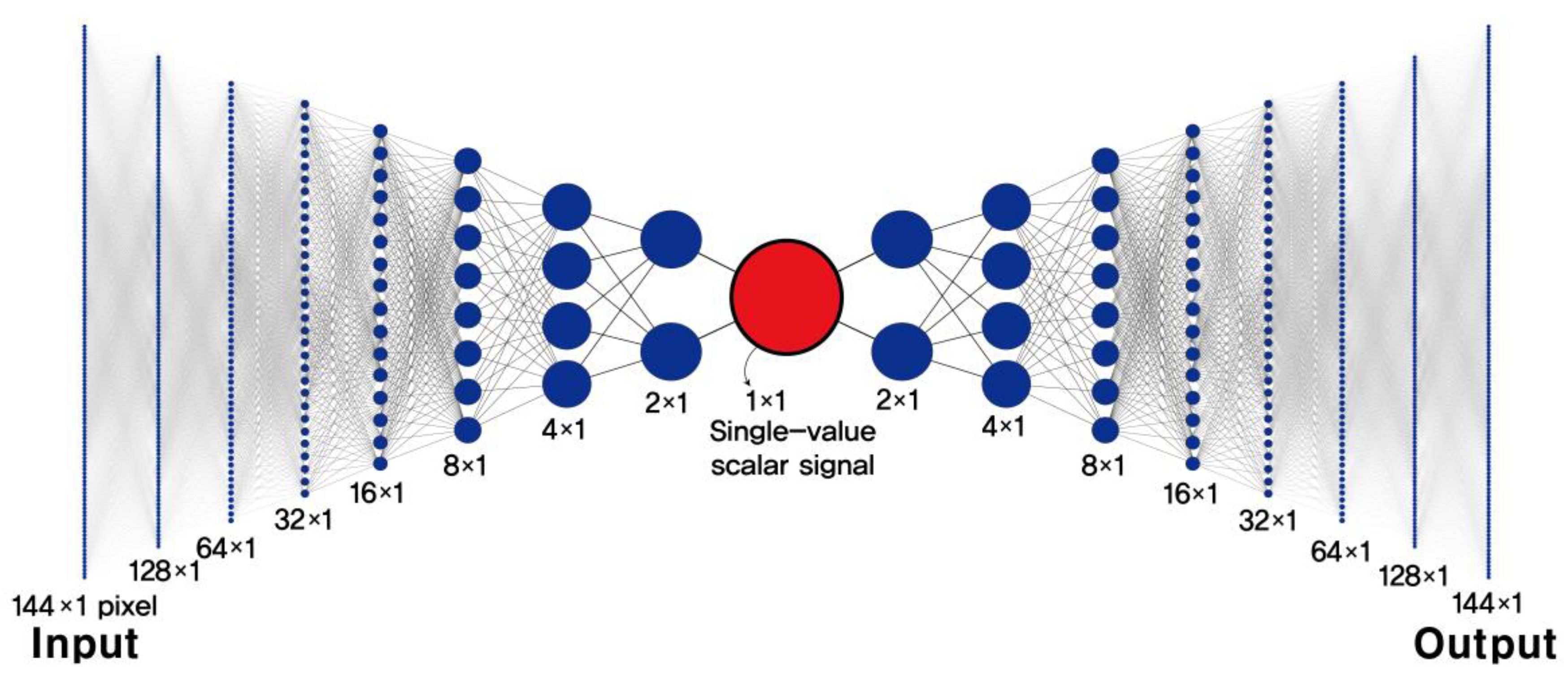
2. An Autoencoder Recognizes the Presence of Vehicles
3. Testbed and Data Collection
4. The Model Performance Based on Real Photos
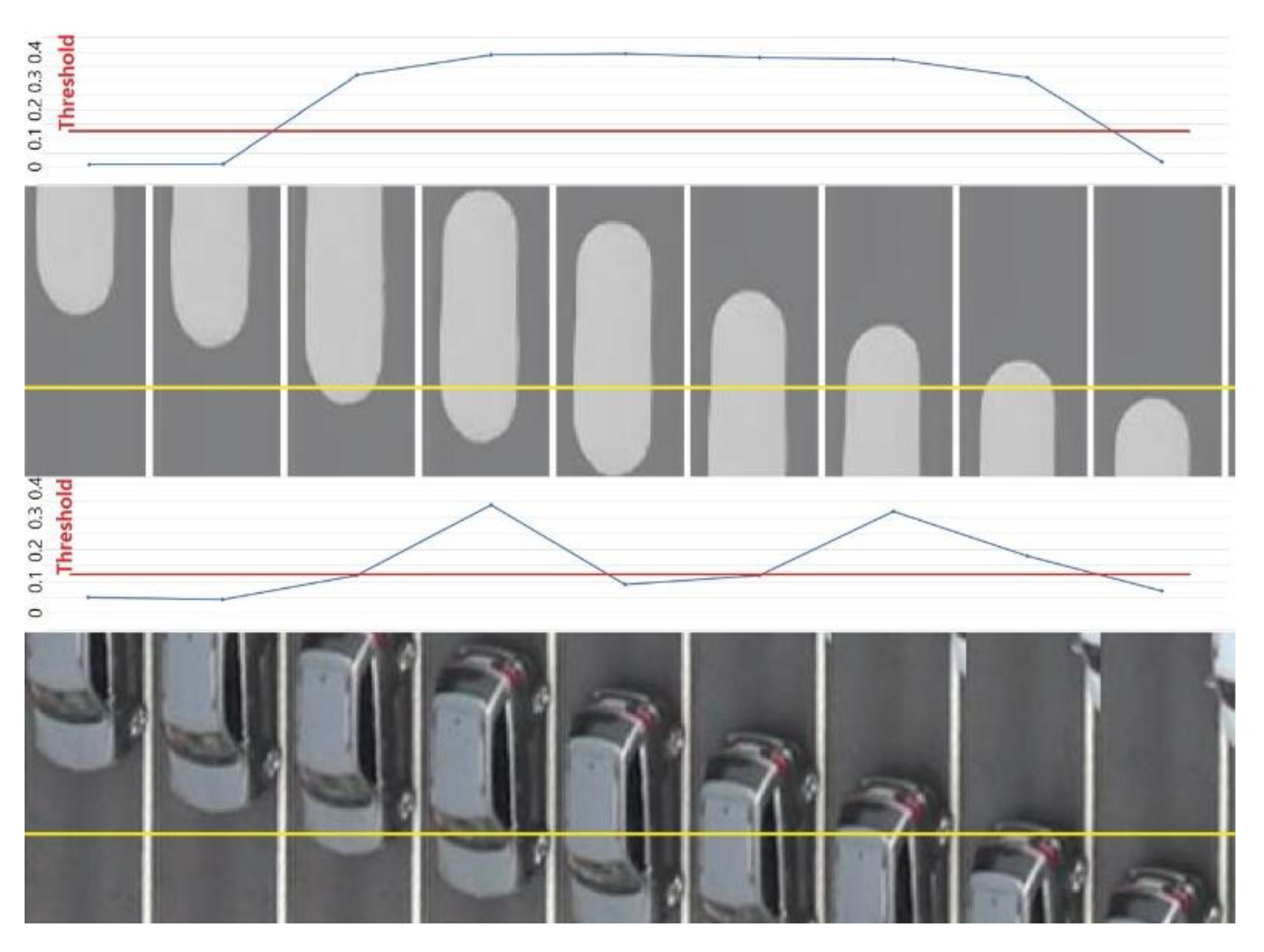
4.1. Choosing Threshold Values to Measure Traffic Volumes
4.2. The Performance of the Autoencoder at Judging the Presence of Vehicles
4.3. The Performance of the Proposed Approach to Measure Traffic Volumes Compared with that of a Yolo-Based Model
5. The Model Performance Based on Synthesized Images
5.1. The Introduction of a Cycle-Consistent Adversarial Network (CycleGAN)
5.2. Enhancing the Performance of the Autoencoder to Better Judge the Presence of Vehicles
5.3. The Performance of the Updated Autoencoder in Measuring Traffic Volumes Compared with that of a Yolo-Based Model
6. The Model Efficiency and the Potential to Classify Vehicle Types
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Riedel, T.; Erni, K. Do my loop detectors count correctly? A set of functions for detector plausibility testing. J. Traffic Transp. Eng. (JTTE) 2016, 4, 117–130. [Google Scholar]
- Meng, C.; Yi, X.; Su, L.; Gao, J.; Zheng, Y. City-wide traffic volume inference with loop detector data and taxi trajectories. In Proceedings of the 25th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 7–10 November 2017; pp. 1–10.
- Ozkurt, C.; Camci, F. Automatic Traffic Density Estimation and Vehicle Classification for Traffic Surveillance System using Neural Networks. Math. Comput. Appl. 2009, 14, 187–196. [Google Scholar] [CrossRef] [Green Version]
- López, M.T.; Fernández-Caballero, A.; Mira, J.; Delgado, A.E.; Fernández, M.A. Algorithmic lateral inhibition method in dynamic and selective visual attention task: Application to moving objects detection and labeling. Expert Syst. Appl. 2006, 31, 570–594. [Google Scholar] [CrossRef] [Green Version]
- López, M.T.; Fernández-Caballero, A.; Fernández, M.A.; Mira, J.; Delgado, A.E. Visual Surveillance by Dynamic Visual Attention Method. Pattern Recogn. 2006, 39, 2194–2211. [Google Scholar] [CrossRef] [Green Version]
- Ji, X.; Wei, Z.; Feng, Y. Effective vehicle detection technique for traffic surveillance systems. J. Vis. Commun. Image Represent. 2006, 17, 647–658. [Google Scholar] [CrossRef]
- Qimin, X.; Xu, L.; Mingming, W.; Bin, L.; Xianghui, S. A methodology of vehicle speed estimation based on optical flow. In Proceedings of the 2014 IEEE International Conference on Service Operations and Logistics, and Informatics, Qingdao, China, 8–10 October 2014; pp. 33–37. [Google Scholar]
- Indu, S.; Gupta, M.; Bhattacharyya, A. Vehicle tracking and speed estimation using optical flow method. Int. J. Eng. Sci. Technol. 2011, 3, 429–434. [Google Scholar]
- Haag, M.; Nagel, H.H. Combination of edge element and optical flow estimates for 3D-model-based vehicle tracking in traffic image sequences. Int. J. Comput. Vis. 1999, 35, 295–319. [Google Scholar] [CrossRef]
- Zhou, J.; Gao, D.; Zhang, D. Moving vehicle detection for automatic traffic monitoring. IEEE Trans. Veh. Technol. 2007, 56, 51–59. [Google Scholar] [CrossRef] [Green Version]
- Niu, X. A semi-automatic framework for highway extraction and vehicle detection based on a geometric deformable model. ISPRS J. Photogramm. Remote Sens. 2006, 61, 170–186. [Google Scholar] [CrossRef]
- Qian, Z.M.; Shi, H.X.; Yang, J.K. Video vehicle detection based on local feature. Adv. Mater. Res. 2011, 186, 56–60. [Google Scholar] [CrossRef]
- Jayaram, M.A.; Fleyeh, H. Convex hulls in image processing: a scoping review. Am. J. Intell.Syst. 2016, 6, 48–58. [Google Scholar]
- Zhu, Z.; Xu, G. VISATRAM: A real-time vision system for automatic traffic monitoring. Image Vis. Comput. 2000, 18, 781–794. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition(CVPR), Las Vegas, NV, USA, 6 June–1 July 2016; pp. 779–788. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Asha, C.S.; Narasimhadhan, A.V. Vehicle counting for traffic management system using YOLO and correlation filter. In Proceedings of the 2018 IEEE International Conference on Electronics, Computing and Communication Technologies (CONECCT), Bangalore, India, 16–17 March 2018; pp. 1–6. [Google Scholar]
- Lopez, G. Traffic Counter with YOLO and SORT. Available online: https://github.com/guillelopez/python-traffic-counter-with-yolo-and-sort (accessed on 11 December 2018).
- Sang, J.; Wu, Z.; Guo, P.; Hu, H.; Xiang, H.; Zhang, Q.; Cai, B. An improved YOLOv2 for vehicle detection. Sensors 2018, 18, 4272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bathija, A.; Sharma, G. Visual Object Detection and Tracking using YOLO and SORT. Int. J. Eng. Res. Technol. (IJERT) 2019, 8, 705–708. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3645–3649. [Google Scholar]
- Shin, J.; Roh, S.; Sohn, K. Image-Based Learning to Measure the Stopped Delay in an Approach of a Signalized Intersection. IEEE Access 2019, 7, 169888–169898. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. arXiv 2017, arXiv:1703.10593. [Google Scholar]
- Lee, J.; Roh, S.; Shin, J.; Sohn, K. Image-based learning to measure the space mean speed on a stretch of road without the need to tag images with labels. Sensors 2019, 19, 1227. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zabalza, J.; Ren, J.; Zheng, J.; Zhao, H.; Qing, C.; Yang, Z.; Du, P.; Marshall, S. Novel segmented stacked autoencoder for effective dimensionality reduction and feature extraction in hyperspectral imaging. Neurocomputing 2015, 185, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E.; Salakhutdinov, R. Reducing the dimensionality of data with neural networks. Science 2016, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lu, X.; Tsao, Y.; Matsuda, S.; Hori, C. Speech enhancement based on deep denoising autoencoder. In Proceedings of the Interspeech, Lyon, France, 25–29 August 2013; pp. 436–440. [Google Scholar]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th international conference on Machine learning (ICML), Association for Computing Machinery, New York, NY, USA, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Pasa, L.; Sperduti, A. Pre-training of recurrent neural networks via linear autoencoders. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3572–3580. [Google Scholar]
- Glüge, S.; Böck, R.; Wendemuth, A. Auto-encoder pre-training of segmented-memory recurrent neural networks. In Proceedings of the European Symposium on Artificial Neural Networks (ESANN), Bruges, Belgium, 24–26 April 2013. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, UK, 2016. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Train Data | Test Data | |||||
|---|---|---|---|---|---|---|
| Positive (Ground Truth) | Negative (Ground Truth) | Sum | Positive (Ground Truth) | Negative (Ground Truth) | Sum | |
| Positive (Predicted) | 19,806 | 456 | 20,262 | 4230 | 84 | 4314 |
| Negative (Predicted) | 1355 | 51,603 | 52,958 | 202 | 11,164 | 11,366 |
| Sum | 21,161 | 52,059 | 73,220 | 4432 | 11,248 | 15,680 |
| Precision | 0.977 | 0.981 | ||||
| Recall | 0.936 | 0.954 | ||||
| Accuracy Comparison | Autoencoder Model | YOLO v3 Model | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Lane 1 | Lane 2 | Lane 3 | Lane 4 | Lane 1 | Lane 2 | Lane 3 | Lane 4 | ||
| C1~2 | Predicted/ Ground truth | 35/34 | 31/30 | 18/18 | 21/21 | 22/34 | 29/30 | 18/18 | 20/21 |
| C3~4 | Predicted/ Ground truth | 39/39 | 42/40 | 17/17 | 19/19 | 38/39 | 39/40 | 14/17 | 17/19 |
| C5~6 | Predicted/ Ground truth | 46/44 | 39/39 | 22/20 | 16/16 | 36/44 | 38/39 | 20/20 | 10/16 |
| C7~8 | Predicted/ Ground truth | 41/43 | 45/46 | 21/20 | 18/18 | 31/43 | 44/46 | 32/20 | 13/18 |
| Total | Predicted/ Ground truth | 161/160 | 157/155 | 78/75 | 74/74 | 127/160 | 150/155 | 84/75 | 60/74 |
| Error (%) | +0.6% | +1.3% | +4% | 0% | −20.6% | −3.2% | +12% | −18.9% | |
| Train Data | Test Data | |||||
|---|---|---|---|---|---|---|
| Positive (Ground Truth) | Negative (Ground Truth) | Sum | Positive (Ground Truth) | Negative (Ground Truth) | Sum | |
| Positive (Predicted) | 20,051 | 376 | 20,427 | 4206 | 32 | 4238 |
| Negative (Predicted) | 942 | 51,851 | 52,793 | 213 | 11,229 | 11,442 |
| Sum | 20,993 | 52,227 | 73,220 | 4419 | 11,261 | 15,680 |
| Precision | 0.982 | 0.992 | ||||
| Recall | 0.955 | 0.952 | ||||
| Accuracy Comparison | Autoencoder Model (Updated) | YOLO v3 Model (Fine Tuned) | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Lane 1 | Lane 2 | Lane 3 | Lane 4 | Lane 1 | Lane 2 | Lane 3 | Lane 4 | ||
| C1~2 | Predicted/Ground truth | 34/34 | 30/30 | 18/18 | 21/21 | 34/34 | 20/20 | 18/18 | 21/21 |
| C3~4 | Predicted/Ground truth | 39/39 | 40/40 | 17/17 | 19/19 | 47/39 | 40/40 | 16/17 | 19/19 |
| C5~6 | Predicted/Ground truth | 44/44 | 39/39 | 20/20 | 16/16 | 44/44 | 39/39 | 20/20 | 16/16 |
| C7~8 | Predicted/Ground truth | 41/43 | 45/46 | 20/20 | 18/18 | 41/43 | 45/46 | 25/20 | 16/18 |
| Total | Predicted/Ground truth | 158/160 | 154/155 | 75/75 | 74/74 | 166/160 | 154/155 | 79/75 | 72/74 |
| Error (%) | −1.3% | −0.6% | 0% | 0% | +3.8% | −0.6% | +5.3% | −2.7% | |
| Number of Parameters | Evaluation Time per Frame | |
|---|---|---|
| Autoencoder model | 59,361 | 0.00007 s |
| CycleGAN + Autoencoder model | 9,525,101 | 0.032 s |
| YOLO v3 model | 61,581,727 | 0.078 s |
| Accuracy Comparison | Autoencoder | CycleGAN + Autoencoder | YOLO v3 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Lane 1 | Lane 2 | Lane 3 | Lane 4 | Lane 1 | Lane 2 | Lane 3 | Lane 4 | Lane 1 | Lane 2 | Lane 3 | Lane 4 | |
| Small Vehicle | 152/150 | 155/155 | 74/73 | 71/72 | 149/150 | 154/155 | 73/73 | 72/72 | 156/150 | 154/155 | 77/73 | 70/72 |
| Large Vehicle | 9/10 | 2/0 | 4/2 | 3/2 | 9/10 | 0/0 | 2/2 | 2/2 | 10/10 | 0/0 | 2/2 | 2/2 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roh, S.; Shin, J.; Sohn, K. Measuring Traffic Volumes Using an Autoencoder with No Need to Tag Images with Labels. Electronics 2020, 9, 702. https://doi.org/10.3390/electronics9050702
Roh S, Shin J, Sohn K. Measuring Traffic Volumes Using an Autoencoder with No Need to Tag Images with Labels. Electronics. 2020; 9(5):702. https://doi.org/10.3390/electronics9050702
Chicago/Turabian StyleRoh, Seungbin, Johyun Shin, and Keemin Sohn. 2020. "Measuring Traffic Volumes Using an Autoencoder with No Need to Tag Images with Labels" Electronics 9, no. 5: 702. https://doi.org/10.3390/electronics9050702
APA StyleRoh, S., Shin, J., & Sohn, K. (2020). Measuring Traffic Volumes Using an Autoencoder with No Need to Tag Images with Labels. Electronics, 9(5), 702. https://doi.org/10.3390/electronics9050702