DTaPO: Dynamic Thermal-Aware Performance Optimization for Dark Silicon Many-Core Systems

 ,
,
Abstract
1. Introduction
2. Related Work
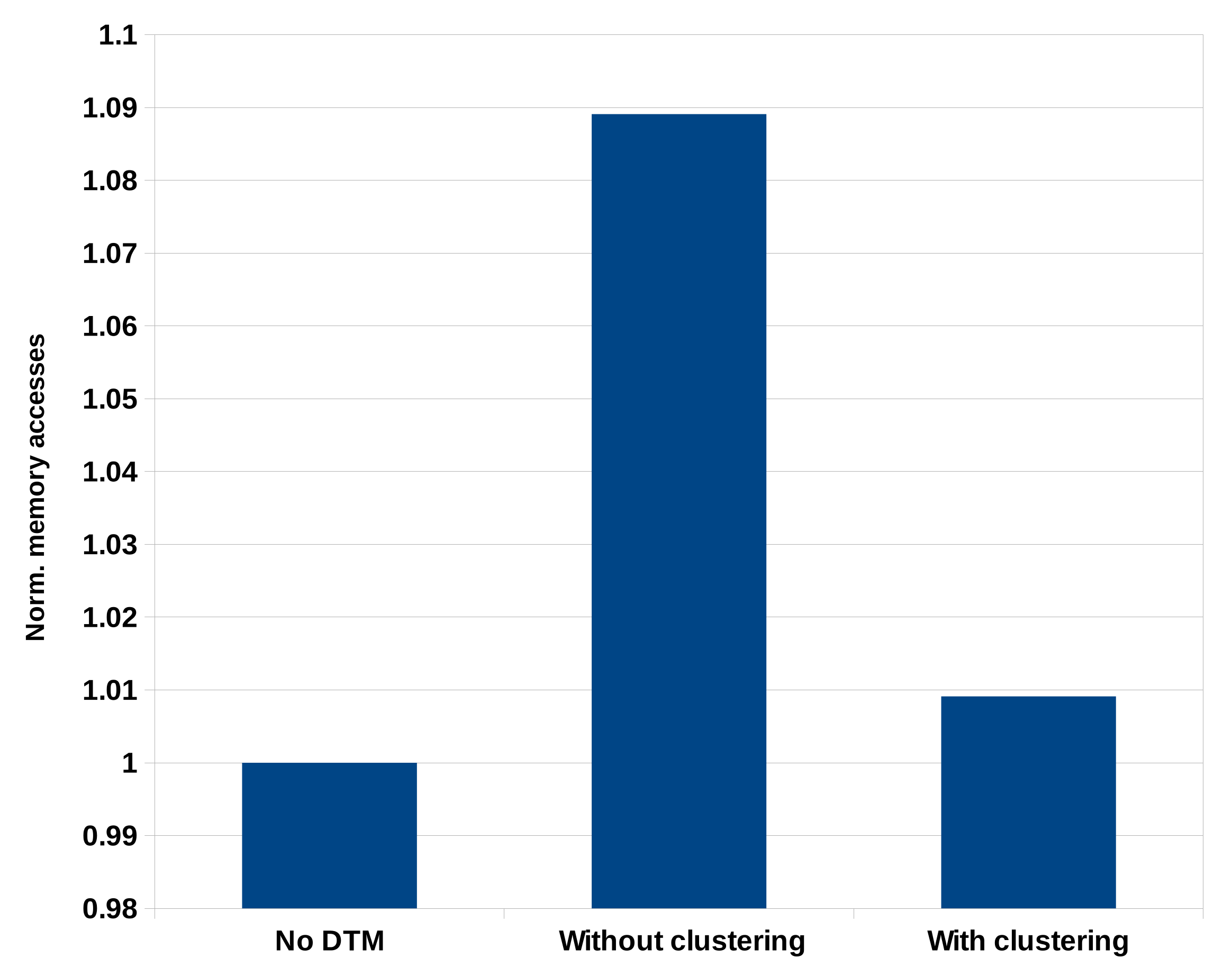
- A cluster-based task migration is used to reduce the number of memory accesses due to L2 cache misses as migration is only allowed between cores sharing the LLC.
- The cold start overhead is considered as it can significantly affect the system performance.
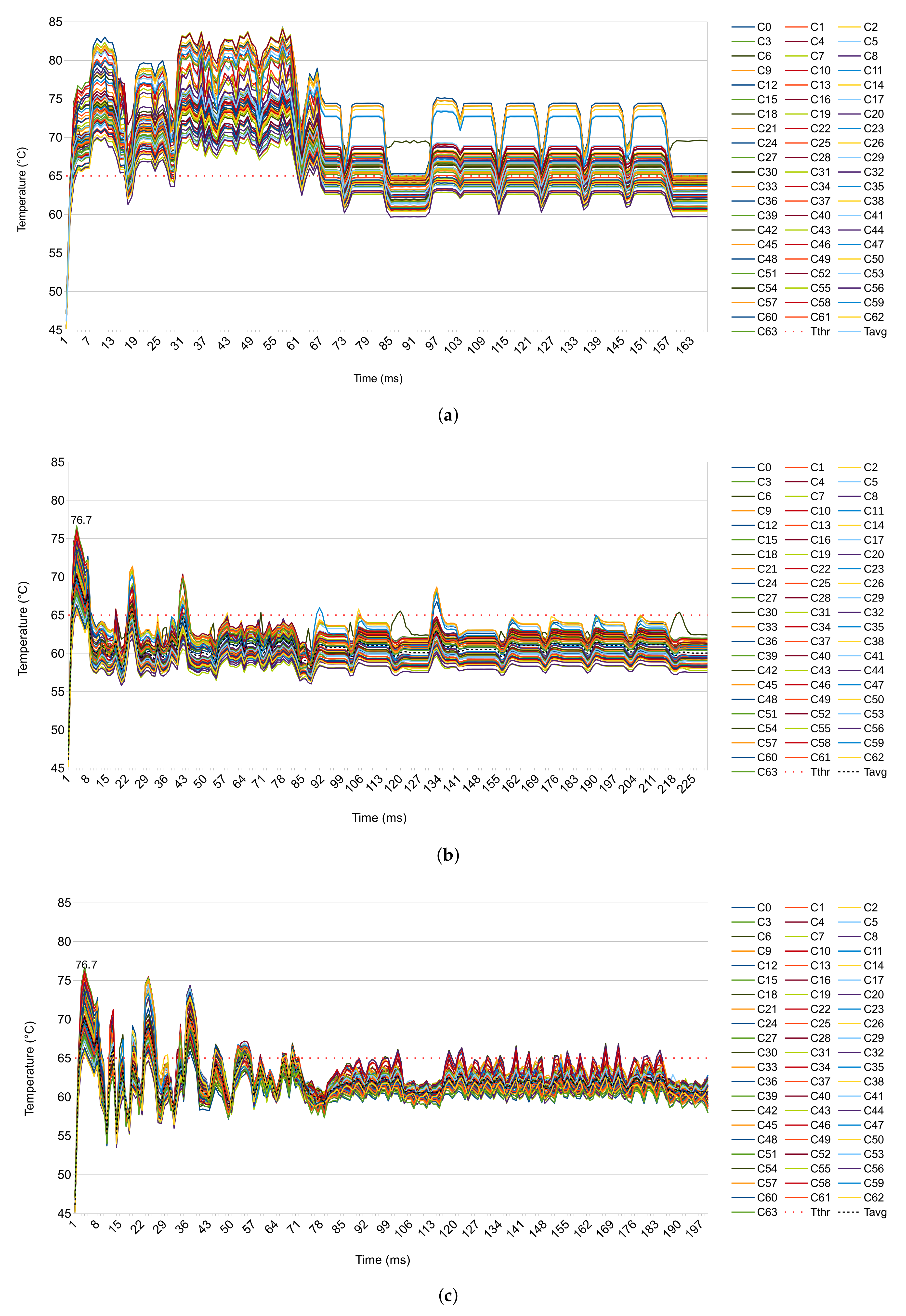
- The proposed DTaPO’s performance is evaluated under several threshold temperatures.
- A mix of four compute- and memory-intensive applications are used with more cores to show the task migration overhead, where using only compute-intensive applications cannot show the task migration overhead.
3. Proposed DTaPO Methodology
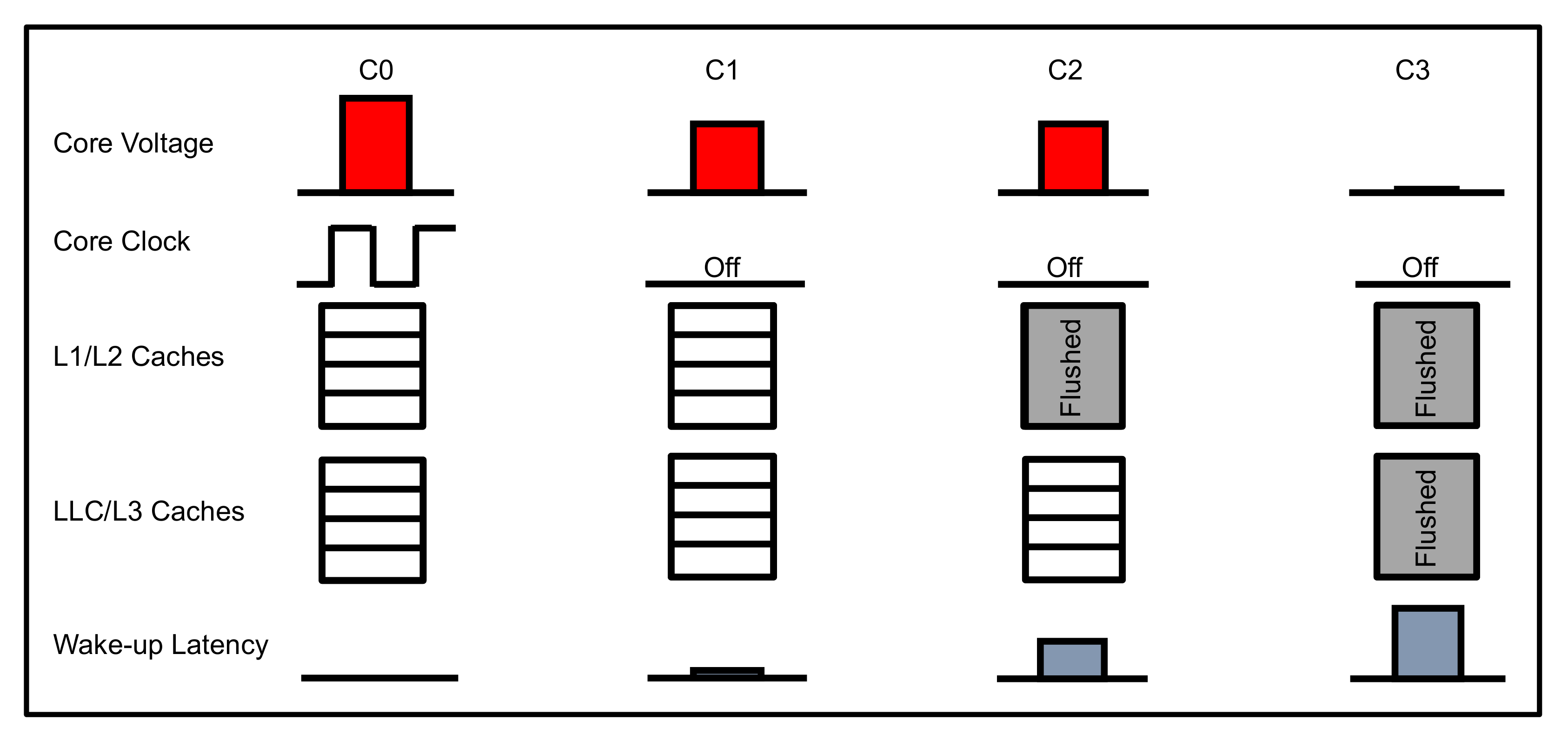
3.1. Core Power States
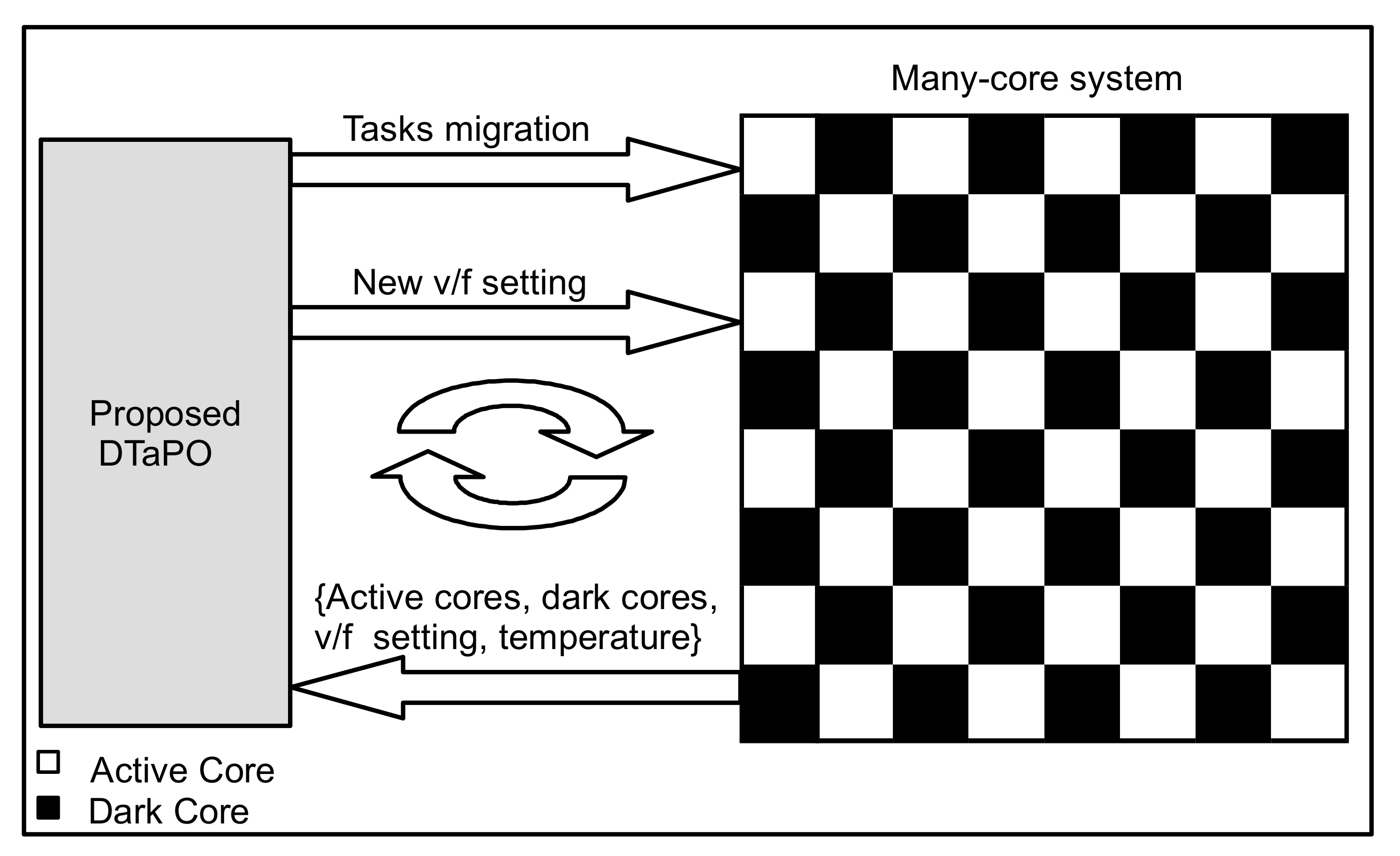
3.2. Proposed Framework
3.3. Proposed Algorithm
| Algorithm 1 DTaPO algorithm |
 |
4. Experimental Evaluation
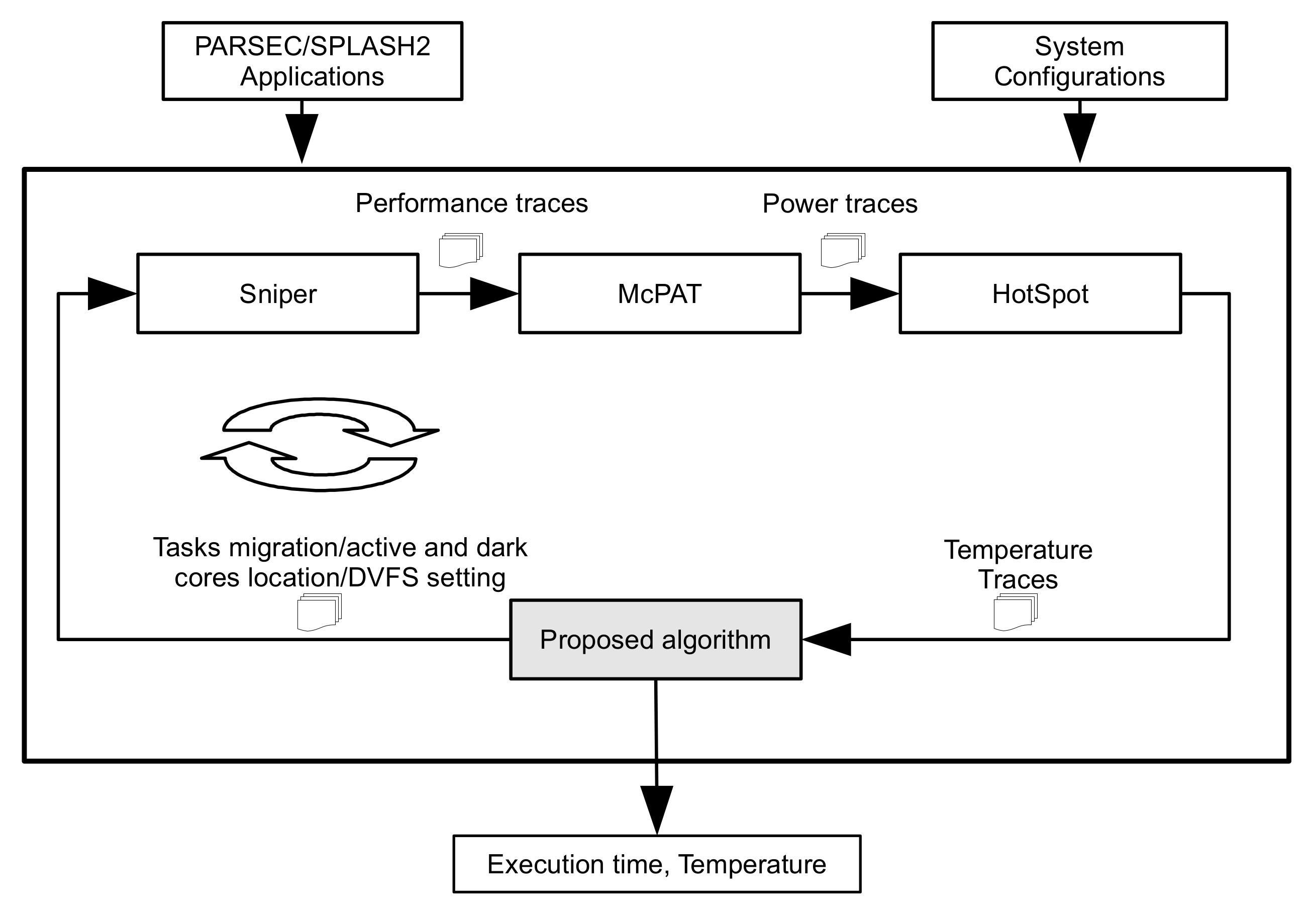
4.1. Experimental Setup
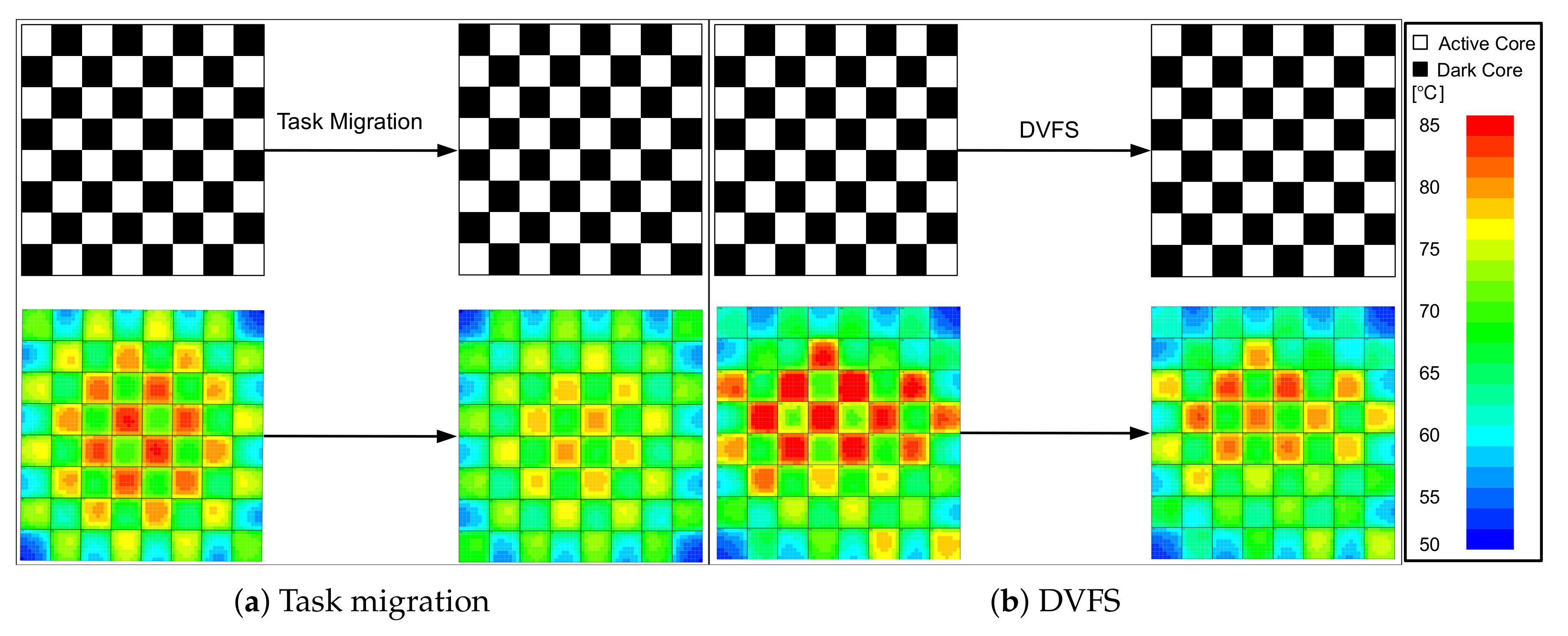
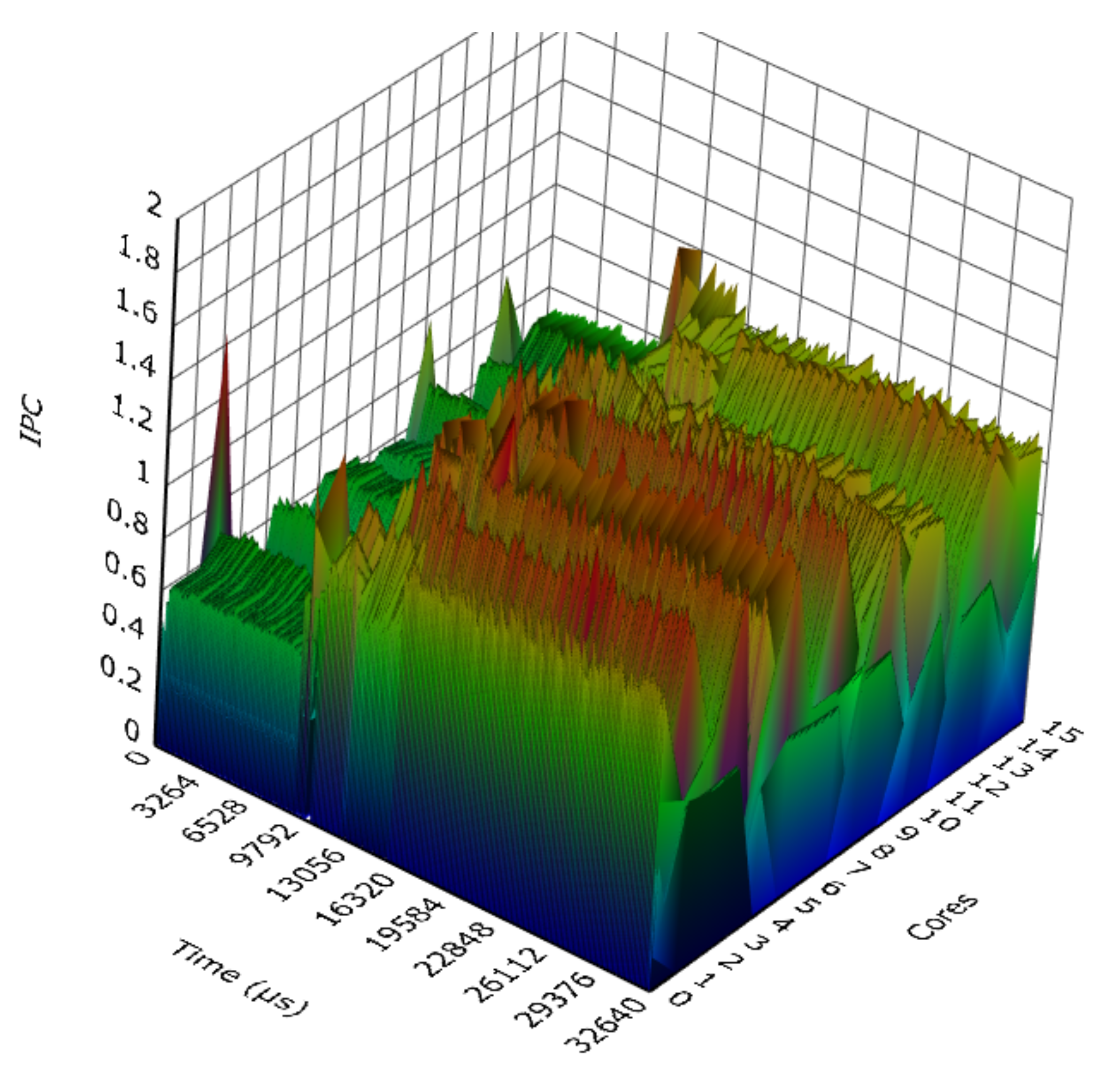
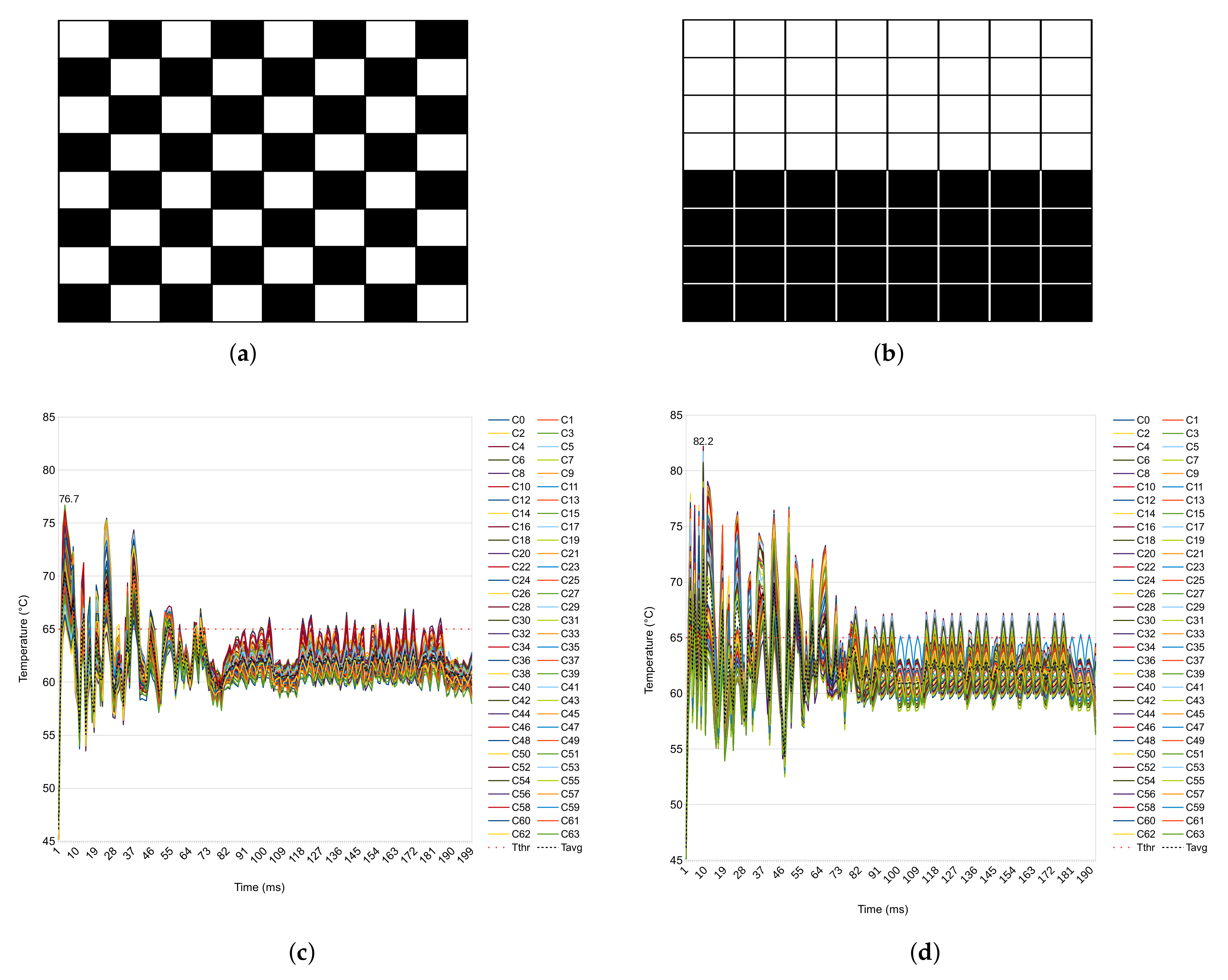
4.2. Experimental Results and Discussion
- A fixed time is spent on storing and restoring the state of architecture.
- Time is spent draining and refilling a core’s pipeline.
- Time is spent restoring the data from memory due to cache misses.
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Moore, G.E. Cramming more components onto integrated circuits. Electronics 1965, 38, 114–117. [Google Scholar] [CrossRef]
- Dennard, R.H.; Gaensslen, F.H.; Rideout, V.L.; Bassous, E.; LeBlanc, A.R. Design of ion-implanted MOSFET’s with very small physical dimensions. IEEE J. Solid-State Circuits 1974, 9, 256–268. [Google Scholar] [CrossRef]
- ITRS. International Technology Roadmap for Semiconductors 2.0. Available online: https://www.semiconductors.org/wp-content/uploads/2018/06/0_2015-ITRS-2.0-Executive-Report-1.pdf (accessed on 14 October 2019).
- Esmaeilzadeh, H.; Blem, E.; Amant, R.S.; Sankaralingam, K.; Burger, D. Dark silicon and the end of multicore scaling. In Proceedings of the 38th Annual International Symposium on Computer Architecture (ISCA), San Jose, CA, USA, 4–8 June 2011; pp. 365–376. [Google Scholar]
- Henkel, J.; Khdr, H.; Pagani, S.; Shafique, M. New trends in dark silicon. In Proceedings of the 2015 52nd ACM/EDAC/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 8–12 June 2015; pp. 1–6. [Google Scholar]
- Raghunathan, B.; Turakhia, Y.; Garg, S.; Marculescu, D. Cherry-picking: Exploiting process variations in dark-silicon homogeneous chip multi-processors. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 18–22 March 2013; pp. 39–44. [Google Scholar]
- Rezaei, A.; Zhao, D.; Daneshtalab, M.; Wu, H. Shift sprinting: Fine-grained temperature-aware NoC-based MCSoC architecture in dark silicon age. In Proceedings of the 53rd Annual Design Automation Conference (DAC), Austin, TX, USA, 5–9 June 2016; pp. 1–6. [Google Scholar]
- Wang, H.; Ma, J.; Tan, S.X.D.; Zhang, C.; Tang, H.; Huang, K.; Zhang, Z. Hierarchical dynamic thermal management method for high-performance many-core microprocessors. ACM Trans. Des. Autom. Electron. Syst. (TODAES) 2016, 22, 1–21. [Google Scholar] [CrossRef]
- Pagani, S.; Khdr, H.; Munawar, W.; Chen, J.J.; Shafique, M.; Li, M.; Henkel, J. TSP: Thermal safe power: Efficient power budgeting for many-core systems in dark silicon. In Proceedings of the 2014 International Conference on Hardware/Software Codesign and System Synthesis, New Delhi, India, 12–17 October 2014; pp. 1–10. [Google Scholar]
- Shafique, M.; Garg, S.; Henkel, J.; Marculescu, D. The EDA challenges in the dark silicon era: Temperature, reliability, and variability perspectives. In Proceedings of the 51st Annual Design Automation Conference, Francisco, CA, USA, 2–5 June 2014; pp. 1–6. [Google Scholar]
- Raghavan, A.; Luo, Y.; Chandawalla, A.; Papaefthymiou, M.; Pipe, K.P.; Wenisch, T.F.; Martin, M.M. Computational sprinting. In Proceedings of the 18th International Symposium on High-Performance Computer Architecture, New Orleans, LA, USA, 25–29 February 2012; pp. 1–12. [Google Scholar]
- Khdr, H.; Pagani, S.; Shafique, M.; Henkel, J. Thermal constrained resource management for mixed ILP-TLP workloads in dark silicon chips. In Proceedings of the the 52nd ACM/EDAC/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 8–12 June 2015; pp. 1–6. [Google Scholar]
- Shafique, M.; Gnad, D.; Garg, S.; Henkel, J. Variability-aware dark silicon management in on-chip many-core systems. In Proceedings of the 2015 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2015; pp. 387–392. [Google Scholar]
- Donald, J.; Martonosi, M. Techniques for Multicore Thermal Management: Classification and New Exploration. In Proceedings of the 33rd International Symposium on Computer Architecture (ISCA’06), Boston, MA, USA, 17–21 June 2006; pp. 78–88. [Google Scholar]
- Thakkar, I.G.; Pasricha, S. LIBRA: Thermal and process variation aware reliability management in photonic networks-on-chip. IEEE Trans. Multi-Scale Comput. Syst. 2018, 4, 758–772. [Google Scholar]
- Shafique, M.; Garg, S. Computing in the Dark Silicon Era: Current Trends and Research Challenges. IEEE Des. Test. 2017, 34, 8–23. [Google Scholar] [CrossRef]
- Muthukaruppan, T.S.; Pricopi, M.; Venkataramani, V.; Mitra, T.; Vishin, S. Hierarchical power management for asymmetric multi-core in dark silicon era. In Proceedings of the 50th ACM/EDAC/IEEE Design Automation Conference (DAC), Austin, TX, USA, 29 May–7 June 2013; pp. 1–9. [Google Scholar]
- Kanduri, A.; Haghbayan, M.H.; Rahmani, A.M.; Liljeberg, P.; Jantsch, A.; Tenhunen, H. Dark Silicon Aware Runtime Mapping for Many-core Systems: A Patterning Approach. In Proceedings of the 33rd IEEE International Conference on Computer Design (ICCD), New York, NY, USA, 18–21 October 2015; pp. 573–580. [Google Scholar]
- Wang, X.; Singh, A.K.; Wen, S. Exploiting dark cores for performance optimization via patterning for many-core chips in the dark silicon era. In Proceedings of the 2018 Twelfth IEEE/ACM International Symposium on Networks-on-Chip (NOCS), Turin, Italy, 4–5 October 2018; pp. 1–8. [Google Scholar]
- Wang, X.; Singh, A.; Li, B.; Yang, Y.; Li, H.; Mak, T. Bubble budgeting: Throughput optimization for dynamic workloads by exploiting dark cores in many core systems. IEEE Trans. Comput. 2018, 67, 178–192. [Google Scholar] [CrossRef]
- Raghavan, A.; Emurian, L.; Shao, L.; Papaefthymiou, M.; Pipe, K.P.; Wenisch, T.F.; Martin, M.M. Utilizing dark silicon to save energy with computational sprinting. IEEE Micro 2013, 33, 20–28. [Google Scholar] [CrossRef]
- Zhan, J.; Xie, Y.; Sun, G. NoC-sprinting: Interconnect for fine-grained sprinting in the dark silicon era. In Proceedings of the 51st Annual Design Automation Conference, Francisco, CA, USA, 2–5 June 2014; pp. 1–6. [Google Scholar]
- Shao, L.; Raghavan, A.; Emurian, L.; Papaefthymiou, M.C.; Wenisch, T.F.; Martin, M.M.; Pipe, K.P. On-chip phase change heat sinks designed for computational sprinting. In Proceedings of the 2014 Semiconductor Thermal Measurement and Management Symposium (SEMI-THERM), San Jose, CA, USA, 9–13 March 2014; pp. 29–34. [Google Scholar]
- Kaplan, F.; Coskun, A.K. Adaptive sprinting: How to get the most out of Phase Change based passive cooling. In Proceedings of the 2015 IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED), Rome, Italy, 22–24 July 2015; pp. 37–42. [Google Scholar]
- Morris, N.; Stewart, C.; Birke, R.; Chen, L.; Kelley, J. Early work on modeling computational sprinting. In Proceedings of the 2017 Symposium on Cloud Computing, Santa Clara, CA, USA, 24–27 September 2017; p. 661. [Google Scholar]
- Morris, N.; Stewart, C.; Chen, L.; Birke, R.; Kelley, J. Model-driven computational sprinting. In Proceedings of the Thirteenth EuroSys Conference, Porto, Portugal, 23–26 April 2018; pp. 1–13. [Google Scholar]
- Wang, J.; Chen, Z.; Guo, S.; Li, Y.B.; Lu, Z. Optimal Sprinting Pattern in Thermal Constrained CMPs. IEEE Trans. Emerg. Top. Comput. 2019. [Google Scholar] [CrossRef]
- Hanumaiah, V.; Vrudhula, S.; Chatha, K.S. Performance optimal online DVFS and task migration techniques for thermally constrained multi-core processors. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2011, 30, 1677–1690. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, M.; Tan, S.X.D.; Zhang, C.; Yuan, Y.; Huang, K.; Zhang, Z. New power budgeting and thermal management scheme for multi-core systems in dark silicon. In Proceedings of the 2016 29th IEEE International System-on-Chip Conference (SOCC), Seattle, WA, USA, 6–9 September 2016; pp. 344–349. [Google Scholar]
- Intel. Intel® Xeon Phi Processor x200 Product Family Datasheet, Volume 1. Available online: https://www.intel.com/content/www/us/en/processors/xeon/xeon-phi-processor-x200-product-family-datasheet.html (accessed on 12 February 2020).
- Mohammed, M.S.; Al-Dhamari, A.K.; Rahman, A.A.H.A.; Paraman, N.; Al-Kubati, A.A.M.; Marsono, M.N. Temperature-Aware Task Scheduling for Dark Silicon Many-Core System-on-Chip. In Proceedings of the 8th International Conference on Modeling Simulation and Applied Optimization (ICMSAO), Manama, Bahrain, 15–17 April 2019; pp. 1–5. [Google Scholar]
- Forum U.E.F.I. Advanced Configuration and Power Interface (ACPI) Specification. Available online: https://www.uefi.org/specifications (accessed on 12 February 2020).
- Pagani, S.; Chen, J.J.; Shafique, M.; Henkel, J. MatEx: Efficient transient and peak temperature computation for compact thermal models. In Proceedings of the 2015 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2015; pp. 1515–1520. [Google Scholar]
- Li, S.; Ahn, J.H.; Strong, R.D.; Brockman, J.B.; Tullsen, D.M.; Jouppi, N.P. McPAT: An integrated power, area, and timing modeling framework for multicore and manycore architectures. In Proceedings of the 42nd Annual IEEE/ACM International Symposium on Microarchitecture, New York, NY, USA, 12–16 December 2009; pp. 469–480. [Google Scholar]
- Rohith, R.; Rathore, V.; Chaturvedi, V.; Singh, A.K.; Thambipillai, S.; Lam, S.K. LifeSim: A lifetime reliability simulator for manycore systems. In Proceedings of the 2018 IEEE 8th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–10 January 2018; pp. 375–381. [Google Scholar]
- Heirman, W.; Carlson, T.; Eeckhout, L. Sniper: Exploring the level of abstraction for scalable and accurate parallel multi-core simulation. In Proceedings of the 2011 International Conference for High Performance Computing, Networking, Storage and Analysis, Seatle, WA, USA, 12–18 November 2011; pp. 1–12. [Google Scholar] [CrossRef]
- Zhang, R.; Stan, M.R.; Skadron, K. HotSpot 6.0: Validation, Acceleration and Extension; University of Virginia: Charlottesville, VA, USA, 2015. [Google Scholar]
- Gao, D.; Reis, D.; Hu, X.S.; Zhuo, C. Eva-CiM: A System-Level Performance and Energy Evaluation Framework for Computing-in-Memory Architectures. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2020, 39, 5011–5024. [Google Scholar] [CrossRef]
- Shen, L.; Wu, N.; Yan, G. Fuzzy-Based Thermal Management Scheme for 3D Chip Multicores with Stacked Caches. Electronics 2020, 9, 346. [Google Scholar] [CrossRef]
- Brooks, D.; Tiwari, V.; Martonosi, M. Wattch: A framework for architectural-level power analysis and optimizations. ACM Sigarch Comput. Archit. News 2000, 28, 83–94. [Google Scholar] [CrossRef]
- Lee, W.; Kim, Y.; Ryoo, J.H.; Sunwoo, D.; Gerstlauer, A.; John, L.K. PowerTrain: A learning-based calibration of McPAT power models. In Proceedings of the 2015 IEEE/ACM International Symposium on Low Power Electronics and Design (ISLPED), Rome, Italy, 22–24 July 2015; pp. 189–194. [Google Scholar]
- Schöne, R.; Molka, D.; Werner, M. Wake-up latencies for processor idle states on current x86 processors. Comput.-Sci.-Res. Dev. 2015, 30, 219–227. [Google Scholar] [CrossRef]
- Woo, S.C.; Ohara, M.; Torrie, E.; Singh, J.P.; Gupta, A. The SPLASH-2 programs: Characterization and methodological considerations. In Proceedings of the 22nd Annual International Symposium on Computer Architecture, Santa Margherita Ligure, Italy, 22–24 June 1995; pp. 24–36. [Google Scholar]
- Bienia, C.; Kumar, S.; Singh, J.P.; Li, K. The PARSEC benchmark suite: Characterization and architectural implications. In Proceedings of the 2008 International Conference on Parallel Architectures and Compilation Techniques (PACT), Toronto, ON, Canada, 25–29 October 2008; pp. 72–81. [Google Scholar]
- Yoon, C.; Shim, J.H.; Moon, B.; Kong, J. 3D die-stacked DRAM thermal management via task allocation and core pipeline control. IEICE Electron. Express 2018, 15, 1–12. [Google Scholar] [CrossRef]
- Van Craeynest, K.; Akram, S.; Heirman, W.; Jaleel, A.; Eeckhout, L. Fairness-aware scheduling on single-ISA heterogeneous multi-cores. In Proceedings of the 22nd International Conference on Parallel Architectures and Compilation Techniques, Edinburgh, UK, 7–11 September 2013; pp. 177–187. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| Set of all active cores | |
| Set of all dark cores | |
| Set of frequencies of all cores | |
| Set of transient temperature of all cores | |
| Set of all tasks | |
| Active core | |
| Dark core | |
| Task on core | |
| Threshold temperature | |
| Threshold frequency | |
| Safe margin value | |
| Frequency level step |
| Parameter | Value |
|---|---|
| Number of cores | 64 |
| Maximum frequency | 4 GHz |
| L1-I | 32 KB |
| L1-D | 32 KB |
| L2 | 512 KB |
| L3 | 8 MB/8 cores |
| Technology | 22 nm |
| Connection type | mesh NoC |
| Benchmark | Threads | Instructions (M) | Cycles (M) | Memory Accesses |
|---|---|---|---|---|
| Radix | 8 | 187.4 | 53.94 | 136,802 |
| Ocean | 8 | 1165 | 203.6 | 10,886,925 |
| Blackscholes | 8 | 1238 | 229.9 | 18,570 |
| Bodytrack | 8 | 3830 | 658.2 | 287,250 |
| Parameter | Value |
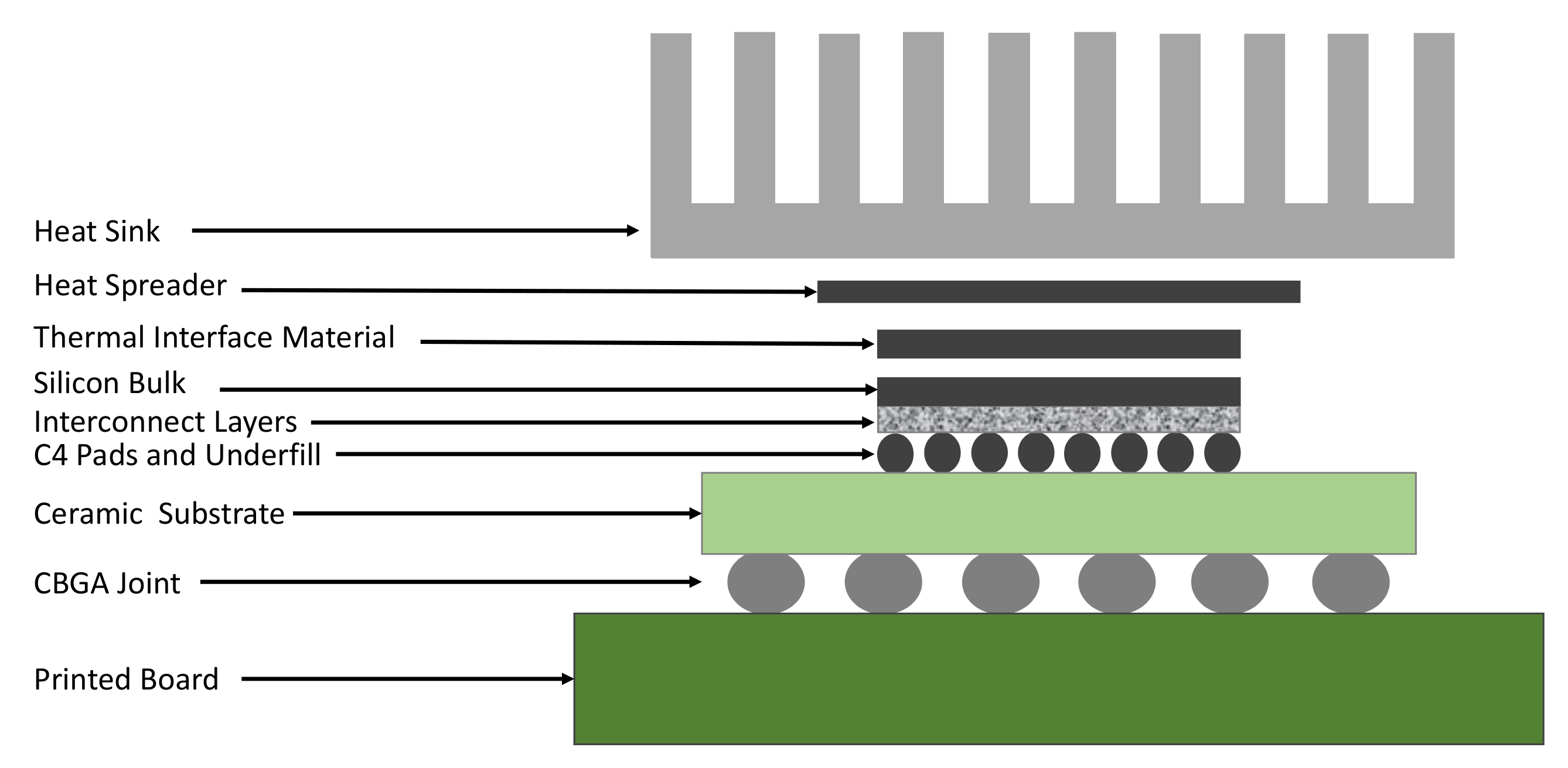
|---|---|
| Thickness of the chip | 0.15 mm |
| Silicon thermal conductivity | 100 W/(m·K) |
| Silicon specific heat | 1.75 × J/(m·K) |
| Heat sink convection capacitance | 140.4 J/K |
| Heat sink convection resistance | 0.1 K/W |
| Heat spreader thermal conductivity | 400 W/(m·K) |
| Heat sink spreader specific heat | 3.55 J/(m·K) |
| Interface material thickness | 20 m |
| Interface material thermal conductivity | 4 W/(m·K) |
| Interface material specific heat | 4 × 10 J/(m·K) |
| Ambient temperature | 318.15 K |
| Avg. Number of Migrations | Avg. Number of DVFS | |
|---|---|---|
| 60 C | 98.7 | 36.4 |
| 65 C | 74.3 | 27.4 |
| 70 C | 67.7 | 19.2 |
| 75 C | 28.7 | 3.7 |
| 80 C | 18.9 | 0 |
| 85 C | 0 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohammed, M.S.; Al-Kubati, A.A.M.; Paraman, N.; Ab Rahman, A.A.-H.; Marsono, M.N. DTaPO: Dynamic Thermal-Aware Performance Optimization for Dark Silicon Many-Core Systems. Electronics 2020, 9, 1980. https://doi.org/10.3390/electronics9111980
Mohammed MS, Al-Kubati AAM, Paraman N, Ab Rahman AA-H, Marsono MN. DTaPO: Dynamic Thermal-Aware Performance Optimization for Dark Silicon Many-Core Systems. Electronics. 2020; 9(11):1980. https://doi.org/10.3390/electronics9111980
Chicago/Turabian StyleMohammed, Mohammed Sultan, Ali A. M. Al-Kubati, Norlina Paraman, Ab Al-Hadi Ab Rahman, and M. N. Marsono. 2020. "DTaPO: Dynamic Thermal-Aware Performance Optimization for Dark Silicon Many-Core Systems" Electronics 9, no. 11: 1980. https://doi.org/10.3390/electronics9111980
APA StyleMohammed, M. S., Al-Kubati, A. A. M., Paraman, N., Ab Rahman, A. A.-H., & Marsono, M. N. (2020). DTaPO: Dynamic Thermal-Aware Performance Optimization for Dark Silicon Many-Core Systems. Electronics, 9(11), 1980. https://doi.org/10.3390/electronics9111980