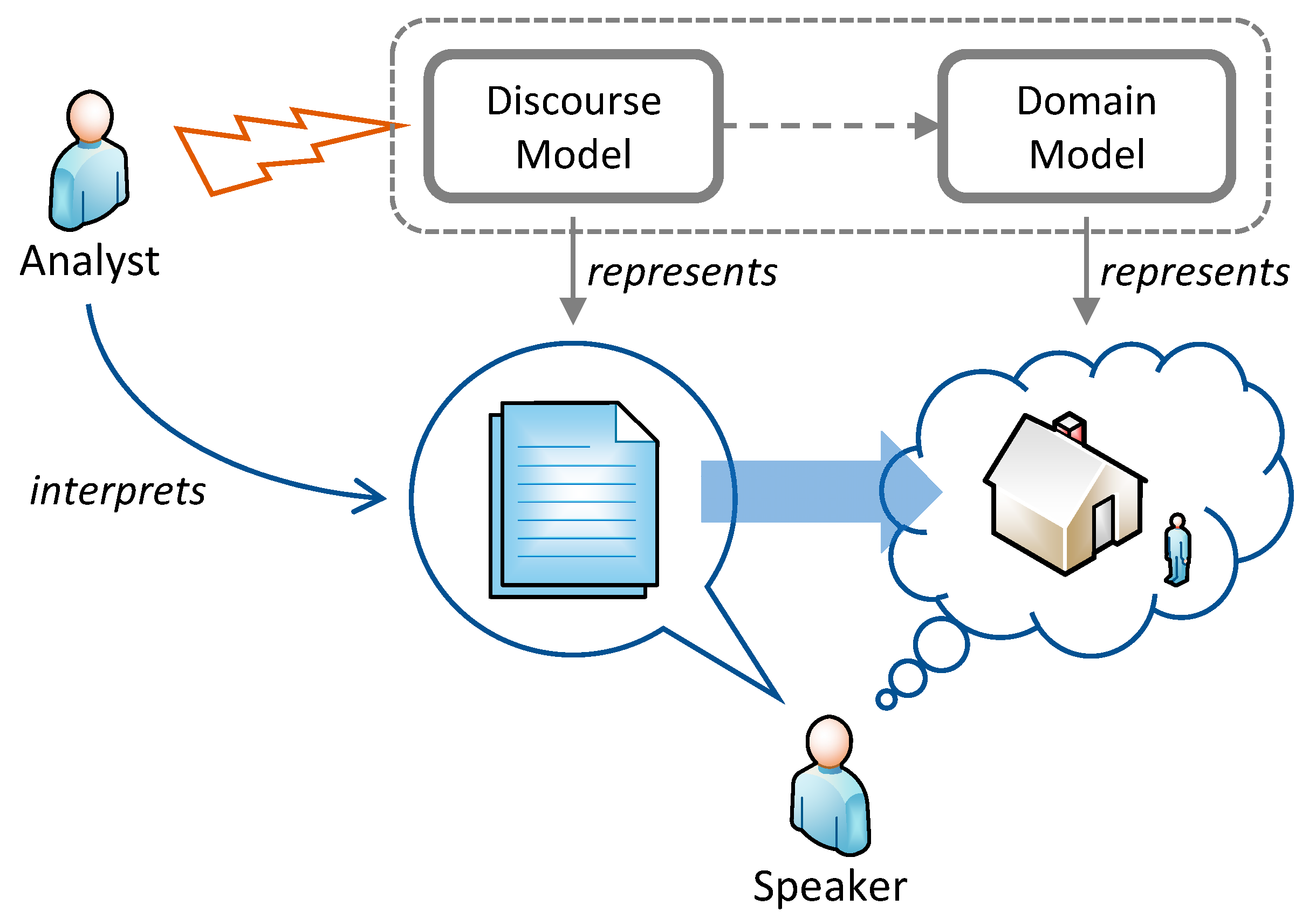
An ontological proxy is an element in a discourse model that stands for another element in the associated domain model, and which may be referenced by multiple propositions. Let us unpack this definition and explore its consequences.
These consequences have been used as design criteria to extend the IAT+ metamodel and incorporate the necessary constructs to support ontological proxies. The following subsections describe these criteria and the associated implementation in greater detail.
3.1. IAT+ Metamodel
As described above, the IAT+ metamodel must provide modelling primitives to express ontological proxies and denotations.
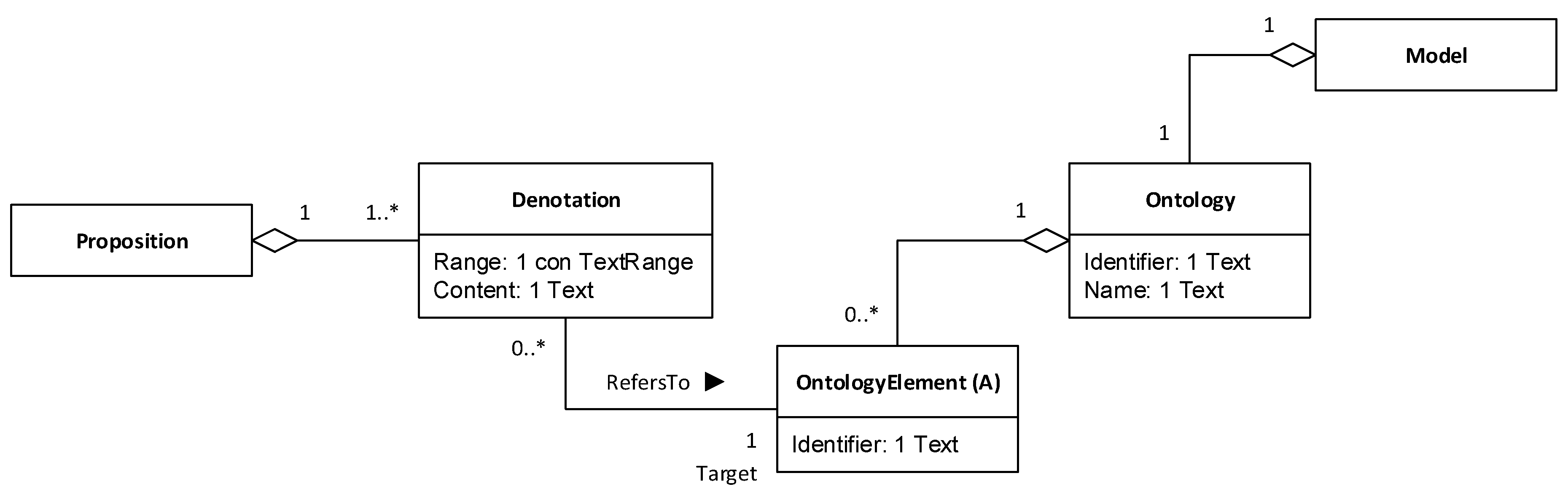
Figure 5 shows the relevant part of the metamodel.
According to the metamodel, every discourse model (simply called
Model in
Figure 5) has an associated domain model (called
Ontology in the figure). We said in previous sections that multiple discourse models can share a common domain model. However, the Ontology class in
Figure 5 does not represent domain models themselves, but the proxy image of a domain model that is kept by a discourse model. In other words, and from the perspective of a discourse model (
Model in
Figure 5),
Ontology represents a private and simplified copy of the associated ontology. Consequently, this relationship has been modelled as a one-to-one whole/part association.
Furthermore, every private and simplified ontology contains a number of ontological proxies, called ontology elements in the metamodel.
OntologyElement is an abstract class, as indicated by the “(A)” marker in
Figure 5. This means that it has a number of subtypes representing different kinds of ontology proxies, which we discuss below.
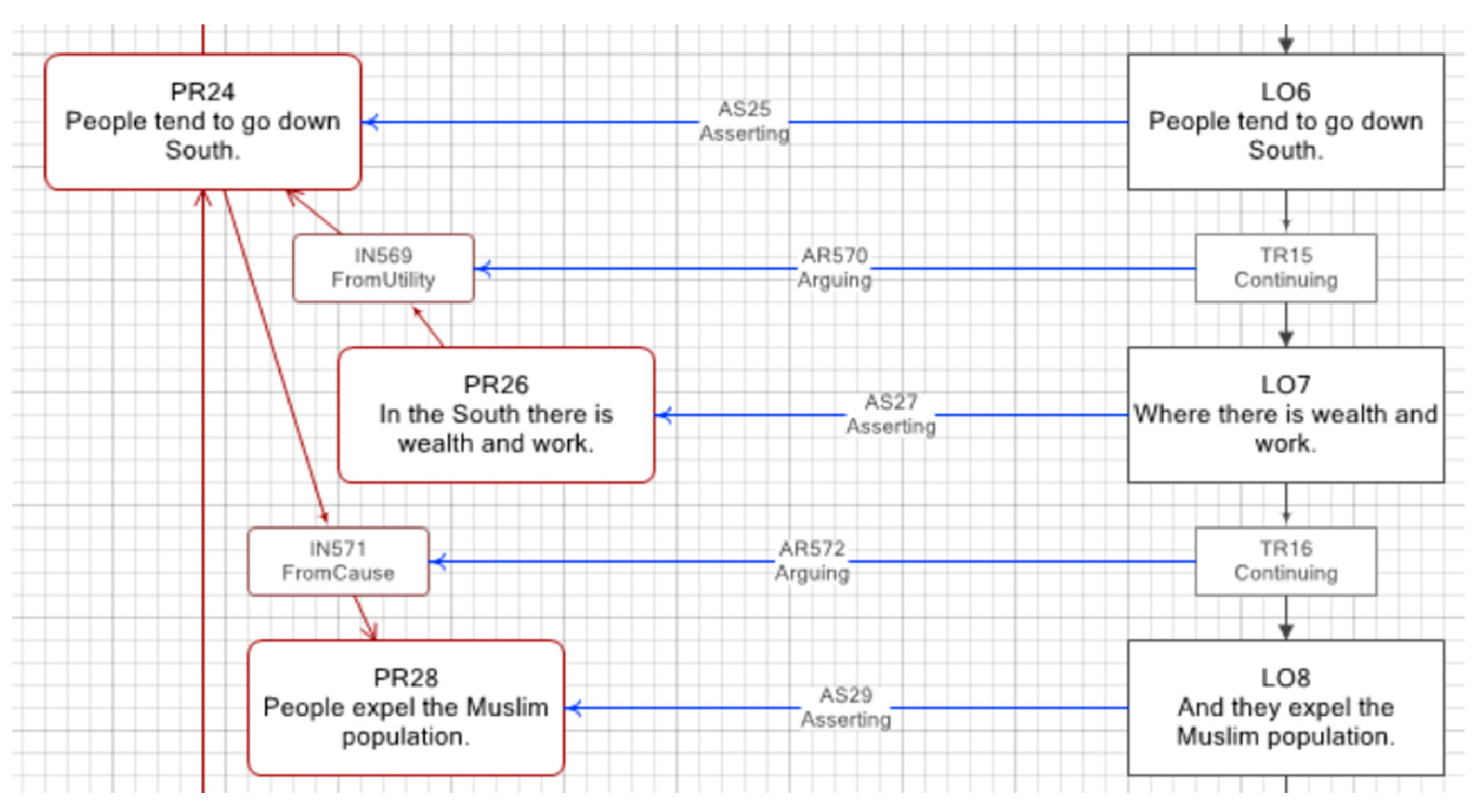
Reading now from the left-hand side of the diagram, every proposition has a number of denotations. A denotation is a fragment of a proposition that refers to an ontology element. The concept of denotation allows us to pick specific words or phrases in a proposition that clearly refer to an element in the ontology, such as “tend to go” in PR24 or “the South” in PR26 in
Figure 4.
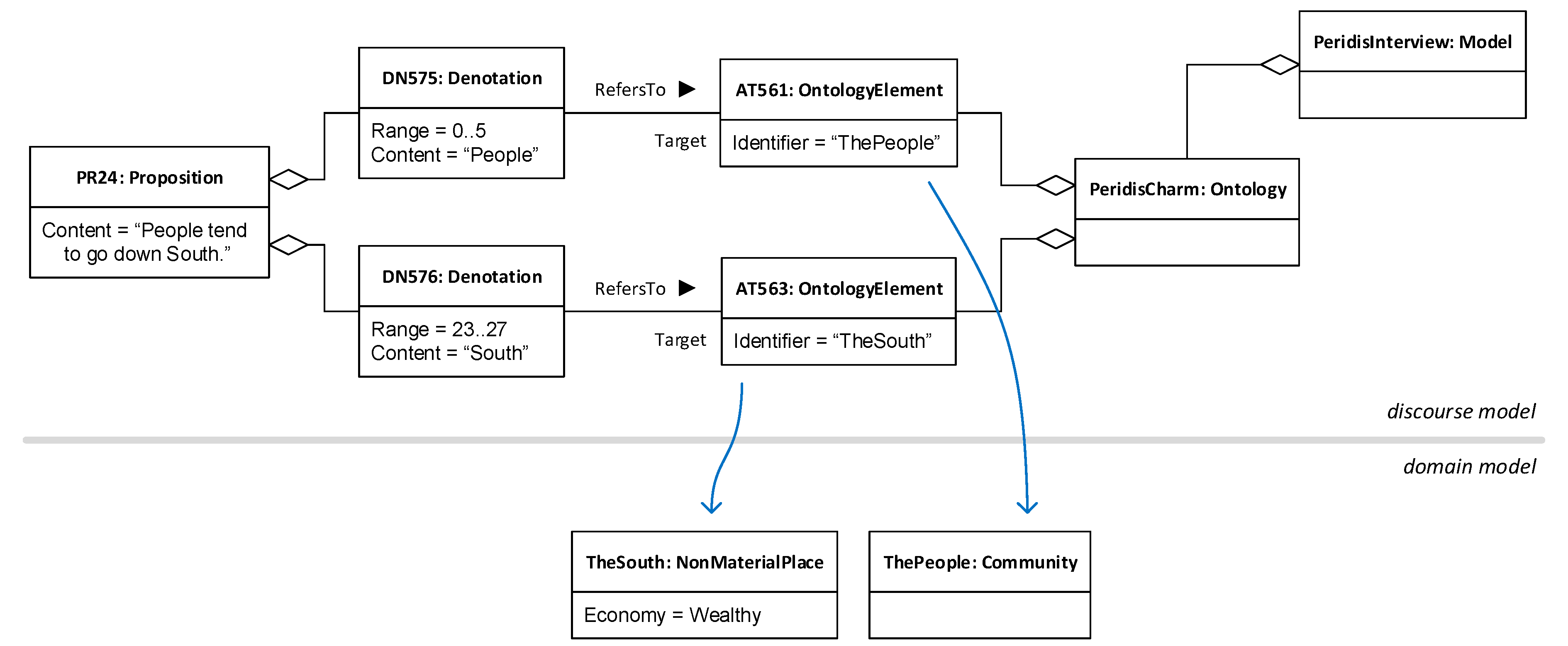
Figure 6 depicts a sample instance model conforming to the metamodel in
Figure 5.
In the figure, the ontological proxies are the objects of type OntologyElement. These objects have an Identifier value whose contents match the identifiers of elements in the domain model. This matching relationship is what makes ontological proxies to work as, precisely, proxies. Note that, in the diagram, proxy relationships are shown as blue arrows between the associated elements, but they do not exist as formal relationships as such, since, as we explained above, the discourse and domain models are expressed using different languages. In any case, both human users of the models as well as computers processing them can easily find these matches and thus follow the proxy relationships.
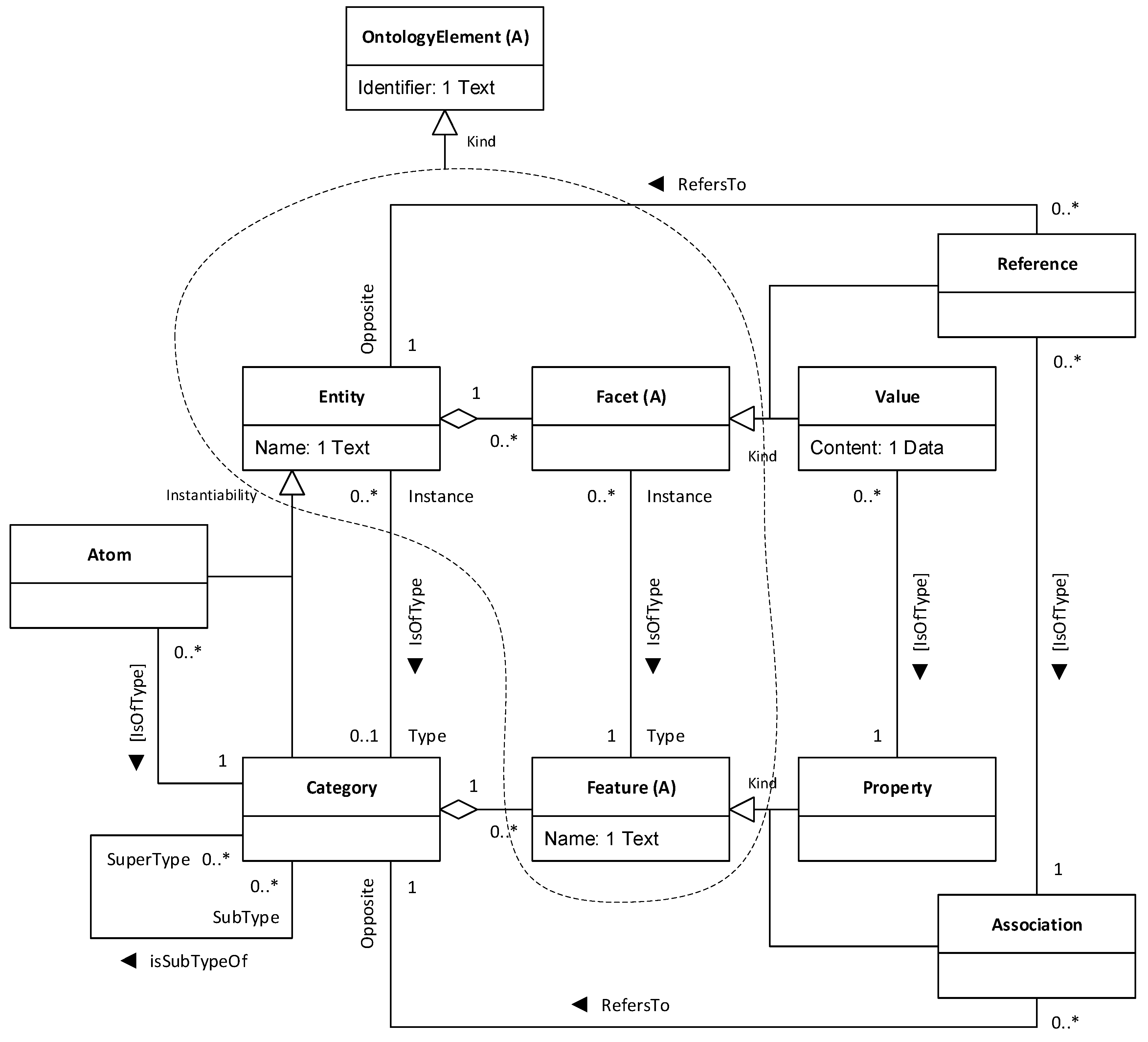
As we said above, and as depicted in
Figure 5,
OntologyElement is an abstract class and has a number of subtypes, corresponding to the different kinds of ontology elements that are common in domain models. Of course, there are many languages that one could use to express a domain model, so the IAT+ metamodel must be generic enough as to cater for as many as possible. For this purpose, we decided to implement a small but varied range of subtypes of
OntologyElement, which the design goal that at least languages such as ConML, OntoUML and OWL should be supported. Most conceptual modelling languages adopt an object-oriented approach and hence include primitives such as
Class,
Attribute,
Object and
Link. However, terminology varies between languages, and the specific semantics of the major primitives are also slightly different. Most languages, however, share the fact that they distinguish clearly between types and instances (or categories and entities, depending on the terminology used) as a major architectural principle around which their metamodels are organised. This means that ontological elements could also be organised along these lines. However, we felt that adopting a multilevel modelling approach [
18,
19] would entail little extra complexity but provide a much richer and more expressive ontological infrastructure. Multilevel modelling allows chains of type/instance relationships of arbitrary length, thus enabling the homogeneous treatment of types and instances for many common purposes and supports higher-order types with a rather simple structure. For these reasons, we adopted the multilevel modelling principles sketched in [
20] and designed the
OntologyElement subtype hierarchy shown in
Figure 7.
The first subtype of OntologyElement is Entity, which represents things in the world such as the computer I am using, my house, the Second World War, or the 5/2016 Act on Cultural Heritage, for example. Anything in the world may be an entity. Entities are characterised through facets of two kinds: values and references. Values represent atomic qualities or quantities of entities, such as the fact that I am 53 years old or that the Second World War began in 1939. References, in turn, represent connections between entities, such as the fact that I (an entity) work at Incipit CSIC (another entity), or that the 5/2016 Act on Cultural Heritage (an entity) applies in Galicia, Spain (another entity).
Entities come in two kinds, depending on whether or not they can be instantiated, as described in the multilevel modelling literature [
18,
20]. Some entities are not instantiable, that is, they cannot work as templates for other entities. These are called “particulars” (and sometimes “atoms”) in philosophy, “ur-elements” in mathematics, or “objects” in the object-oriented approach in software engineering. We call them atoms. Some examples of atoms include myself, the Second World War, or the 5/2016 Act on Cultural Heritage.
Some other entities, as opposed to the previous, can be instantiable into other entities, working as templates for them, and usually corresponding to generic concepts or ideas. For example, the notion of
Tree can be instantiated into individual trees, such as each of the trees I can see through the window as I type this sentence. Similarly, the notion of
Person is instantiated into each individual person. These instantiable entities are called “universals” in philosophy or “classes” in object-oriented software engineering. We call them categories. In general, we can say that every entity has a category as type, since, in the words of George Lakoff, “There is nothing more basic than categorization to our thought, perception, action, and speech” [
21]. For example, I am of the
Person category, the Second World War is of the
ArmedConflict category, and the 5/2016 Act on Cultural Heritage is of the
Law category. In practice, and especially when constructing ontologies with some degree of uncertainty, we do not know or are not interested in the category of some entities, so specifying them is not mandatory.
Now, since categories are also entities, they can have values and references. In addition, they can be characterised through two extra kinds of features: properties and associations. Properties define possible values of the entities of the category. For example, since every person has a value for their age, then we can capture this fact by stating that the Person category has an Age property. Similarly, associations define possible references of the entities of the category. For example, since every person has been born in a particular place, then we can capture this fact by stating that the Person category has a WasBornIn association towards the Place category.
In this manner, the IAT+ metamodel supports ontological proxies of six concrete kinds: atoms, values, references, categories, properties, and associations. Although some types of modelling primitives are not covered (such as OntoUML non sortals, for example), these six kinds map nicely to the major modelling primitives of almost any conceptual modelling language, as exemplified by
Table 1.
We must also remark that the notation used in
Figure 6 is convenient to visualise the details of the data structures implementing the models. However, we suggest a different notation for most practical purposes, which is shown in
Figure 8.
The following sections provide guidance on how to find ontological proxies as well as some examples to illustrate how they can be used in practice.
3.2. How to Construct Ontological Proxies
As we described in previous sections, ontological proxies are model elements. This means that they are mental constructs that adhere to a well-known formalism or modelling language. In this section we tackle the issue of how ontological proxies, as model elements, are constructed.
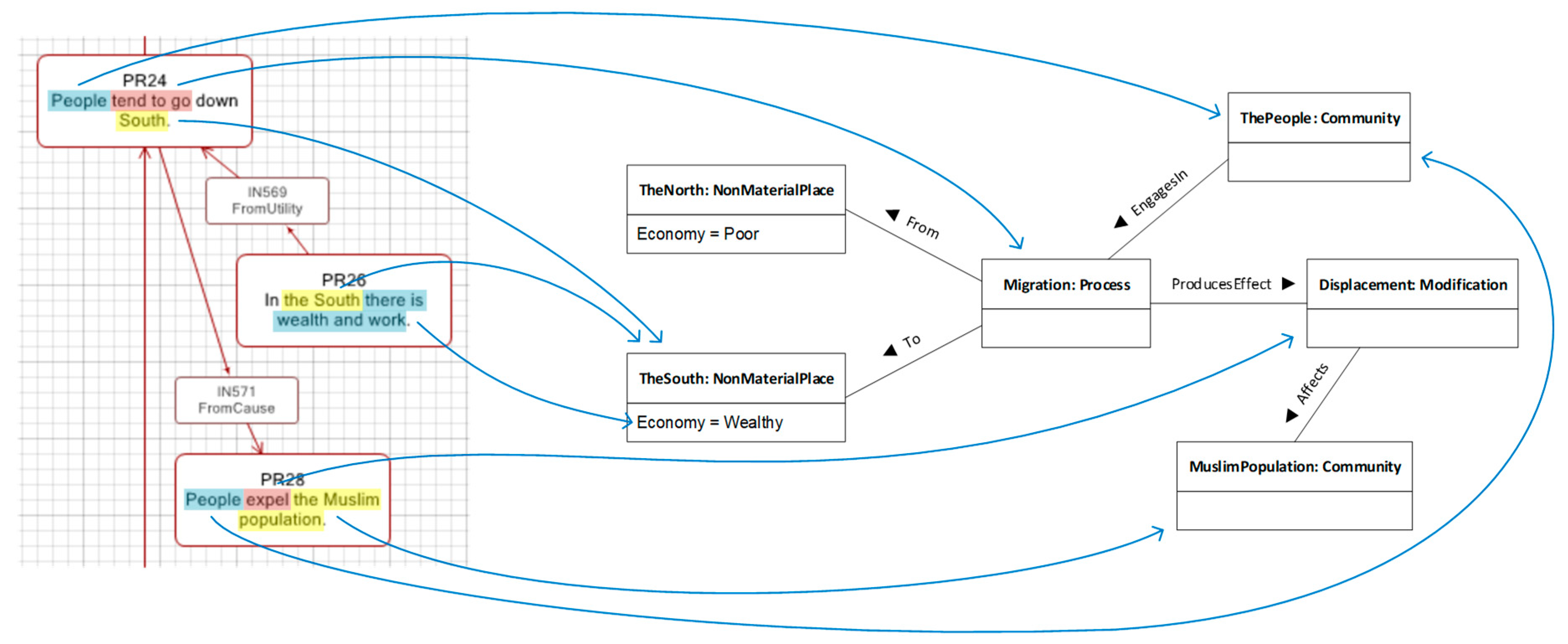
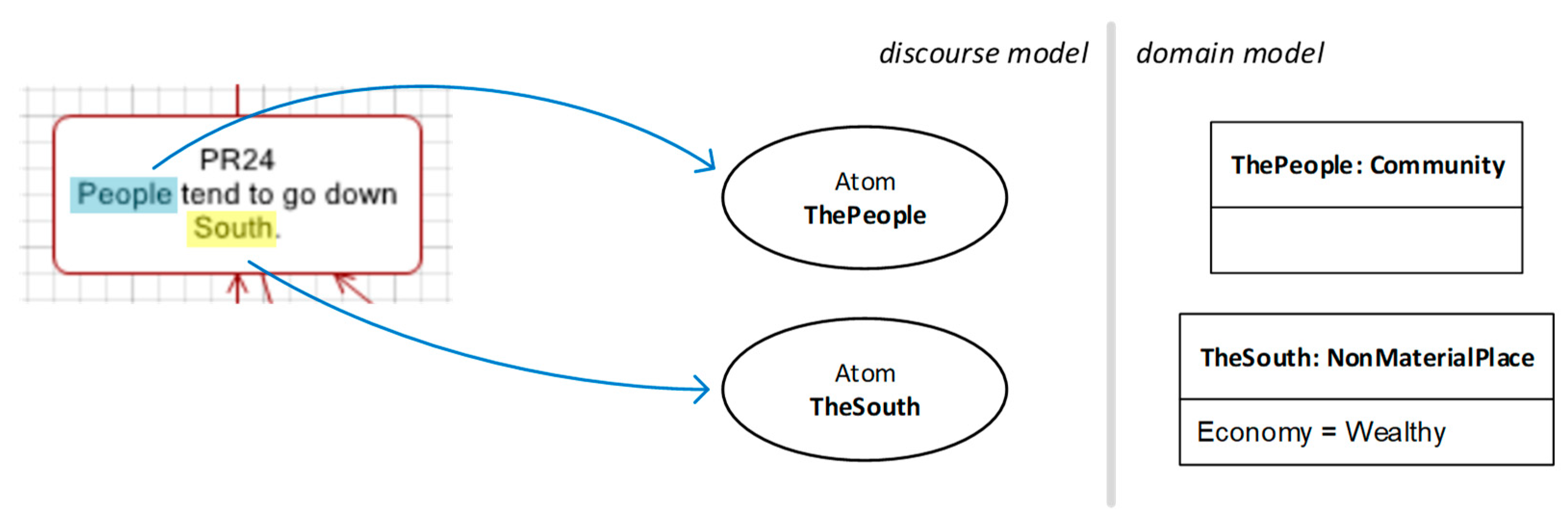
As explained above, ontological proxies are referred to by fragments of propositions. In
Figure 8, for example, the fragments “People” and “South” are highlighted to indicate that they correspond to denotations, each of them referring to an ontological proxy. So, in order to determine what ontological proxies must be constructed for a given proposition, we must take into account the following guidelines.
First, it is important to acknowledge that conceptual modelling is always done for a purpose, i.e., it is a situated activity driven by a goal. Two models of the same part of the world but pursuing different goals are likely to be very different. In addition, conceptual modelling, as a concept-creation process, is clearly dependent on the subjective traits of the analyst such as academic and cultural background or personal preferences. Consequently, it is impossible to provide clear-cut rules as to how construct ontological proxies; only approximate guides can be offered.
Having said this, it is safe to say that the process to construct ontological proxies is often driven by an examination of the lexicon and grammar employed by the proposition at hand, with the goal of answering the question “what is this sentence talking about?”. For example, in “People tend to go down South” in
Figure 8, we can observe the following:
The subject “People” refers to an uncertain group of persons.
The verb “tend to go down” indicates a movement of said person group.
The complement “South” refers to the destination place of this movement.
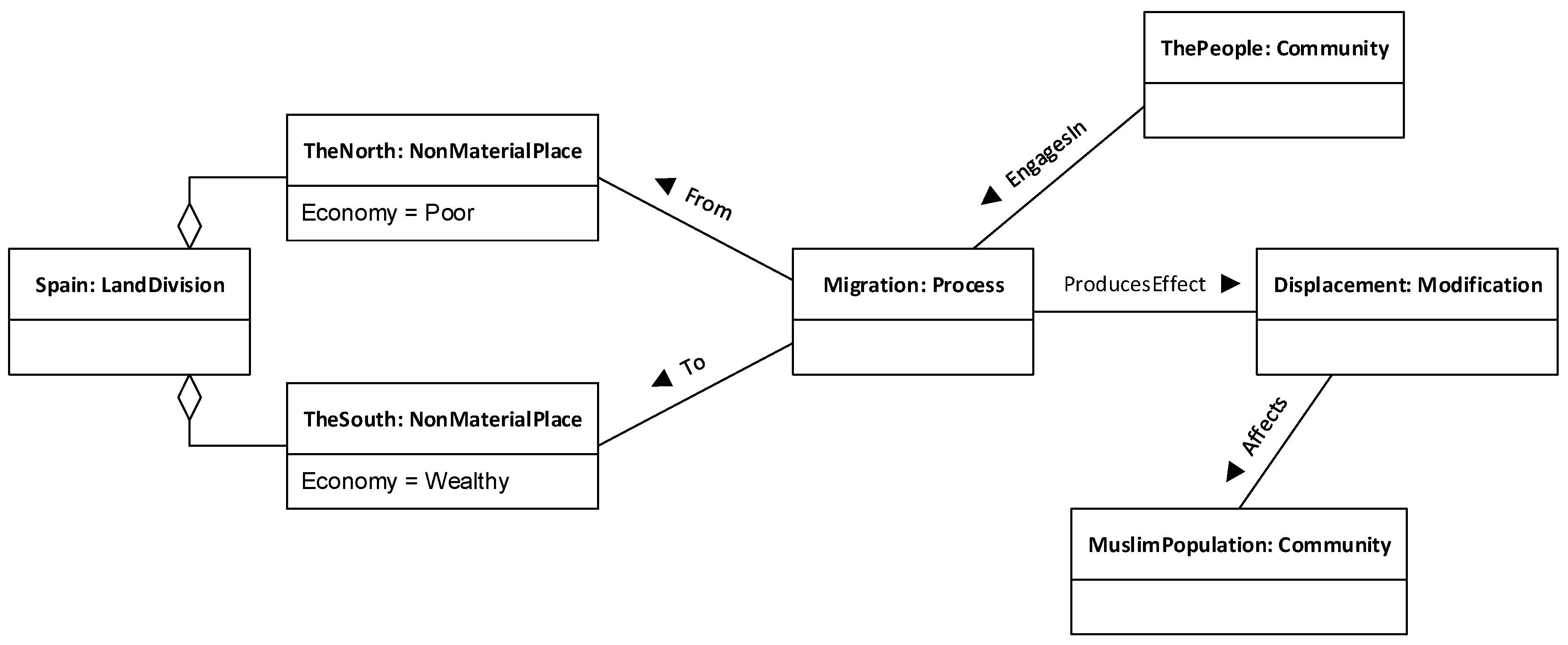
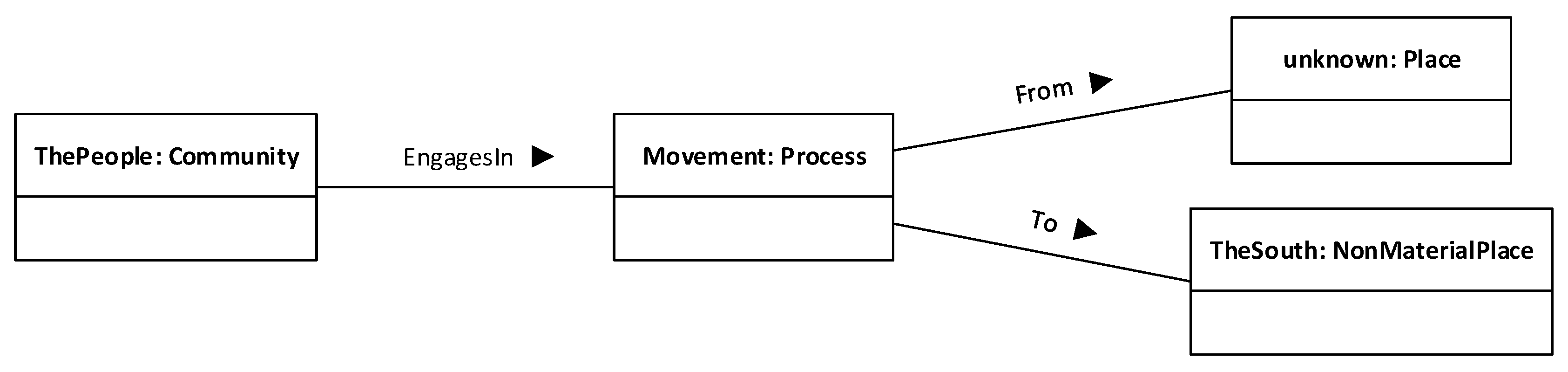
This means that the proposition contains three denotations, which in turn hint at three potential entities: a group of people, a movement process, and a destination place. It also hints at some connections between them: “People” points at the thing that is moving, and “South” points at the destination of such a movement. The source place of movement is unsaid, at least by this proposition. We can represent this by the domain model depicted in
Figure 9.
Note that, in the domain model, the source place of the movement is unknown. We show it in the diagram for completeness sake, and because it is likely that the analysis of another proposition in this discourse does refer to it, which would allow us to refine this domain model. The domain model, as is, contains four entities, named by the identifiers
ThePeople,
Movement and
TheSouth plus the keyword
unknown. Note also that we have chosen particular categories for these entities:
ThePeople is a community,
Movement is a
Process,
TheSouth is a
NonMaterialPlace, and the unknown source of the movement is a
Place. Other options may be also valid. For example, stating that the people referred to by “People” in the proposition make up a community may be too bold, as we have no guarantee, from the text being analysed, that they in fact do; these people may actually be a scattered collection of groups and families with little or no relation to each other, so we are not justified in categorising them collectively as a community. In this case, we should rather employ a different category such as the non-committal
GroupOfPeople. Choosing the right category is not always easy, as often there is not much information in the text about what “right” means in this context. Using a domain-specific reference model or ontology can be useful, as it would offer a catalogue of common concepts in the domain to choose from. For our examples we have used CHARM, the Cultural Heritage Abstract Reference Model [
22,
23,
24], which lists over 200 concepts related to cultural heritage and associated topics plus their properties and relationships.
In this example, all the denotations refer to entities in the world. Other propositions may refer to other kinds of ontological elements, such as values or references. For example, PR26 in
Figure 4 states that “In the South there is wealth and work”. Here, the fragment “there is wealth and work” can be interpreted as denoting a value for the entity denoted by “the South”, namely the predication that the economy of the South is good (or wealthy, as depicted in the figure).
In general, proper nouns or qualified noun phrases, such as “the South” or “the Muslim population” usually denote material or immaterial entities. Verbal phrases headed by dynamic verbs such as “tend to go down” or “expel” usually denote processes or activities. Both can be modelled through
Entity ontological proxies. Verbal phrases with stative verbs, such as “there is” or “have” often denote predications of values or references on the subject entity, which can be modelled through
Value and
Reference ontological proxies. Adjectival clauses such as “wealthy” or “long and difficult” usually denote the content of values or references. A special mention should be made of phrases with the verb “to be”, as this verb may carry different meanings in many languages. In English, for example, “to be” may indicate either existence (“there is a person”), which would be modelled through an
Entity; identity (“she is my mother”), which can be also modelled as an
Entity plus a
Reference; predication (“she is tall”), which is best modelled as a
Value or a
Reference; classification (“this is a house”), which can be modelled through an
Entity and a
Category; or subsumption (“a house is a structure”), which should be modelled through two related instances of
Category [
6]. Sentences containing “to be” must be carefully analysed.
Not that this lexical and grammatical analysis of propositions allows us to construct a domain model, rather than ontological proxies themselves. Ontological proxies, by definition, are lightweight replacements for elements in the domain model, so once this model is clear, an ontological proxy can be constructed for each model element. Coming back to the example in
Figure 9, we would construct three ontological proxies, all of them of the
Atom kind: one for
ThePeople, one for
Movement, and one for
TheSouth.
As we proceed to analyse more propositions in the same discourse, we would be adding to the domain model, or altering it to accommodate new elements. For example, it is likely that another proposition tells us something relevant to identify the source place of the movement in
Figure 9, or add extra detail to any of the associated entities. Conceptual modelling is usually an iterative and incremental task, which eventually converges to a stable resolution.
3.3. Usage Examples
Let us look at some examples of ontological proxies in practice. Firstly, let us focus on the issue of how ontological proxies may help us to document particular interpretations of the discourse. Consider the following fragment:
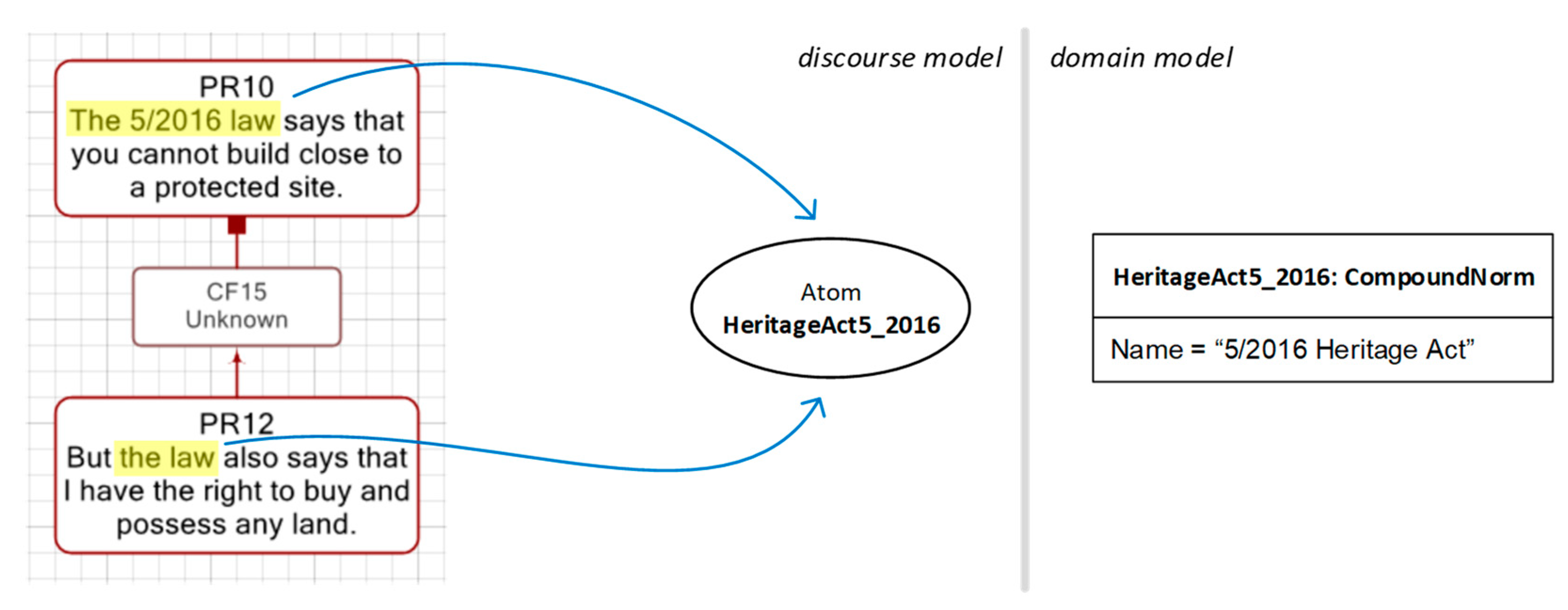
Alice: The 5/2016 law says that you cannot build close to a protected site.
Bob: But the law also says that I have the right to buy and possess any land.
A first approach to analysing this fragment may interpret the exchange as a conflict, since “the law” in Bob’s line refers to the same thing as “The 5/2016 law” in Alice’s. In fact, the “But” lexical marker heading Bob’s retort is a usual indicator of conflict. This interpretation is captured by the models depicted in
Figure 10.
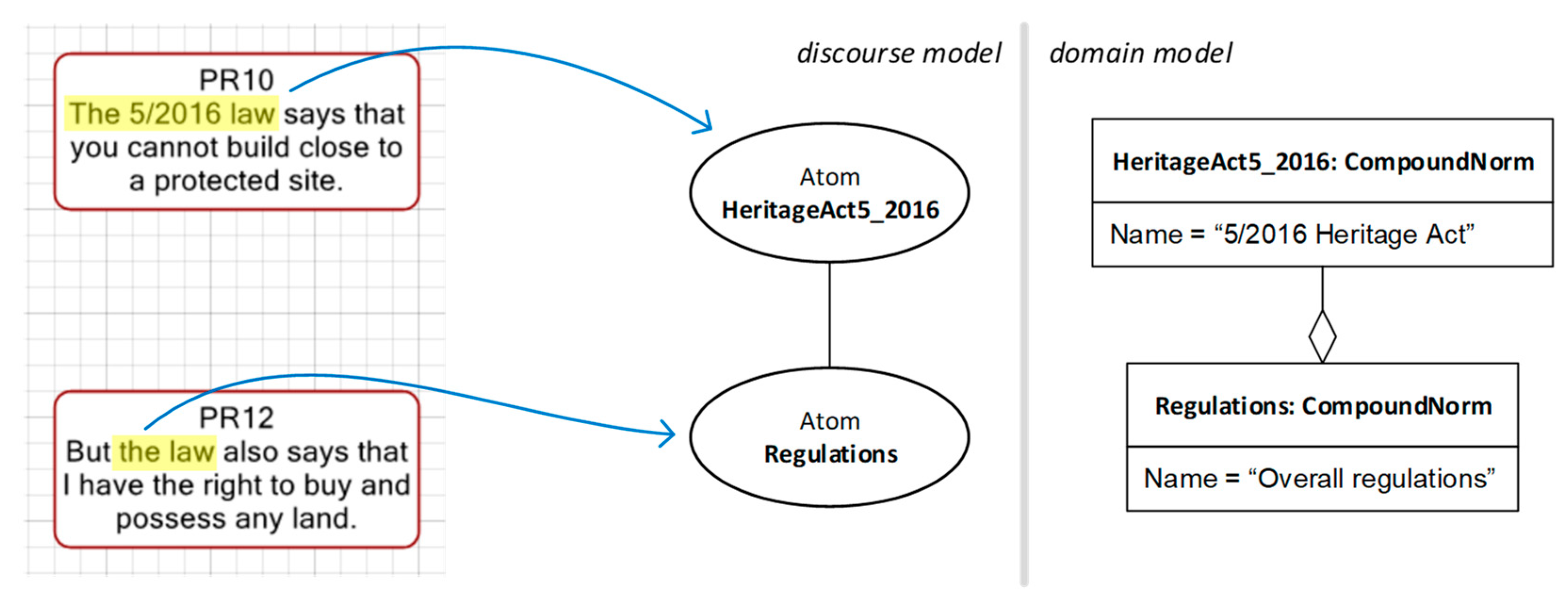
However, an alternative interpretation is possible. The denotation “the law” in Bob’s line may refer to the general laws and regulations that apply, rather than the 5/2016 Heritage Act in particular. If this is the case, then Bob is saying that regulations, in general, allow you to buy and possess any land, which may not be a conflict with Alice’s proposition after all, as the 5/2016 Heritage Act could be making an exception to the general right to buy and possess land. This alternative interpretation is captured in
Figure 11.
Here, two ontological proxies exist, capturing the facts that the 5/2016 Heritage Act is part of a larger set of overall regulations. Once this interpretation has been established, it is clear that there is no necessary conflict between propositions PR10 and PR12, as shown. Note that, in the absence of ontological proxies, the two discourse diagrams (corresponding to the boxes displayed on a grid) from
Figure 10 and
Figure 11 would show different options but with no associated explanation. A reader of these models would find no information as why a conflict was or was not described between the propositions. Once we incorporate the ontological proxies, however, and even in the absence of the domain model, the interpretation of the discourse becomes clear.
Let us now move to a different example and focus on how ontological proxies can work to assist in lexical/semantic studies. Consider the following text [
17]:
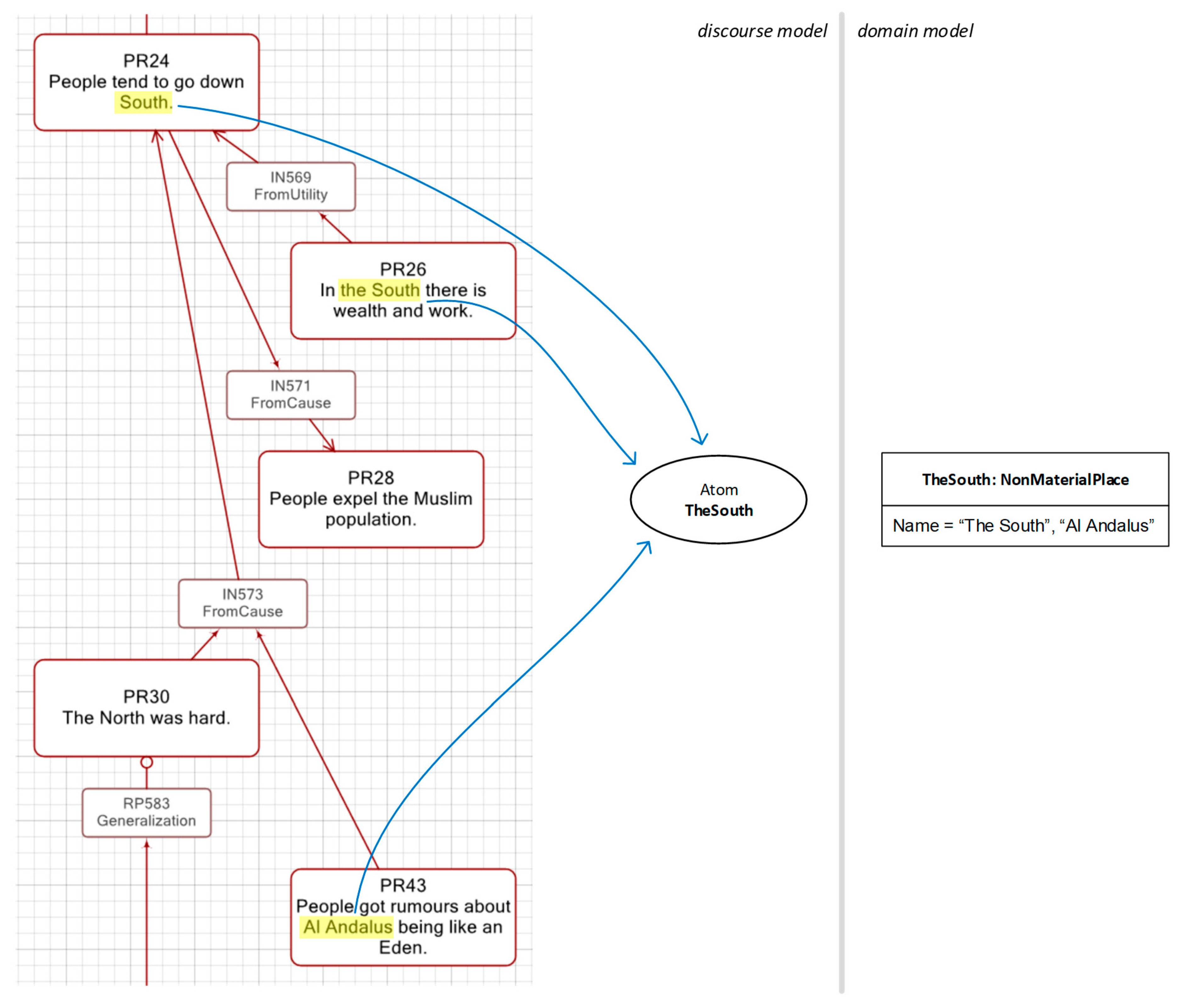
People tend to go down South, where there is wealth and work. And they expel the Muslim population. The North was hard, and they got rumours about Al Andalus being like an Eden.
Here, two terms, “the South” and “Al Andalus”, are being used to refer to the same thing. This interpretation is shown in
Figure 12.
First, note that propositions PR24 and PR26 use “South” or “the South” to refer to the southern region of Spain, whereas PR43 uses “Al Andalus” to refer to the same place. This is interpretation is clearly documented by the single ontological proxy labelled TheSouth. Once this has been established, it is easy to see why PR43 works as a premise (together with PR30) for inference IN573 and leading to the conclusion PR24: living in the North was hard, and since people got rumours that Al Andalus was like an Eden, they moved there. This argument only makes sense if we assume that Al Andalus and the South are the same thing. Again, this assumption is clearly documented through ontological proxies and thus works as grounding to support inference IN573.
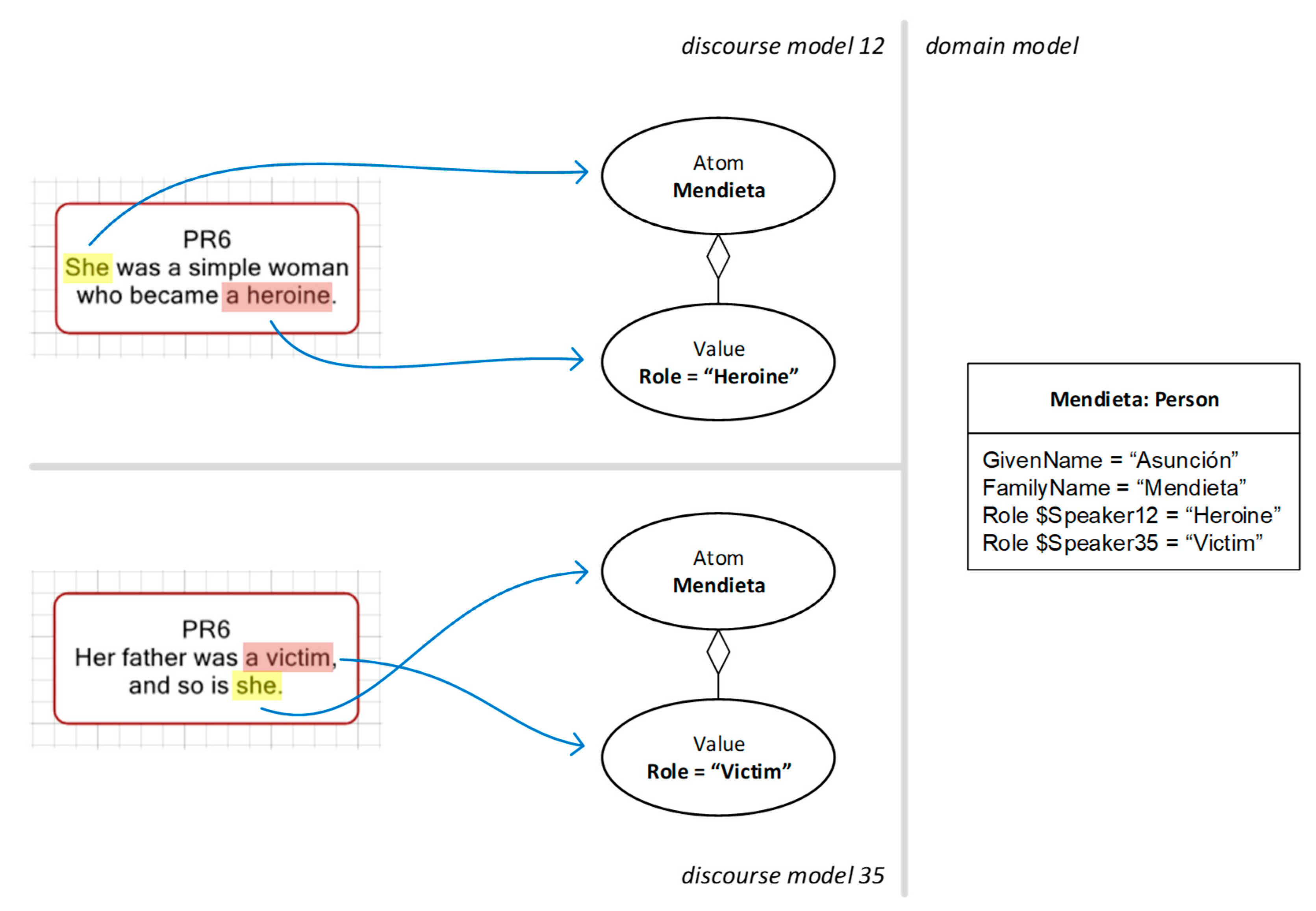
Finally, let us consider how ontological proxies may be useful to intertextual studies. Consider the following fragments, taken from different tweets in March 2020:
Speaker 12: She was a simple woman who became a heroine.
Speaker 35: Her father was a victim, and so is she.
Here, speakers 12 and 35 are not engaged in a dialog, and probably they do not even know about each other. But both are discussing the late Ascensión Mendieta, a Spanish activist for Historic Memory who struggled to restore the memory of her father, killed by Franco’s dictatorship in 1939. We know this because both tweets were inserted in threads where Mendieta was named.
Figure 13 depicts the models for both fragments.
In this example, the denotations “she” in both discourse models point to an atom labelled
Mendieta. Both models contain a denotation pointing to a
Role value for this atom, but with different contents: model 12 states that Mendieta is a heroine, whereas model 25 states that she is a victim. The domain model is shared between the two discourse models. In it, we can see a single object
Mendieta with subjectively marked values for the
Role attribute, corresponding to each of the
Role values in the discourse models. The modelling of subjectivity is out of the scope of this paper, but a brief introduction can be found in [
16]. Essentially, each of the lines starting with “Role” in the Mendieta box in the domain model stands for a value given to this object by a different agent, namely, our speakers 12 and 35. In this manner, two discourse models that were in principle disconnected and structurally unrelated are linked together through a common domain model that documents the associated speaker perspectives. This captures the fact that both discourses are referring to a common set of concepts in the world. This example only involves two discourse models, but this approach can be applied with any number of discourse models as long as all of them refer to a common set of things in the world.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}