Integration of Discrete Wavelet Transform, DBSCAN, and Classifiers for Efficient Content Based Image Retrieval

 ,
,  , ,
, ,  ,
,
Abstract
1. Introduction
1.1. Problem Statement
1.2. Literature Review
2. Materials and Methods
2.1. Discrete Wavelet Transform
2.2. Dictionary Learning
- (2).
- Connectivity
2.3. Similarity Measurement
2.4. Classification
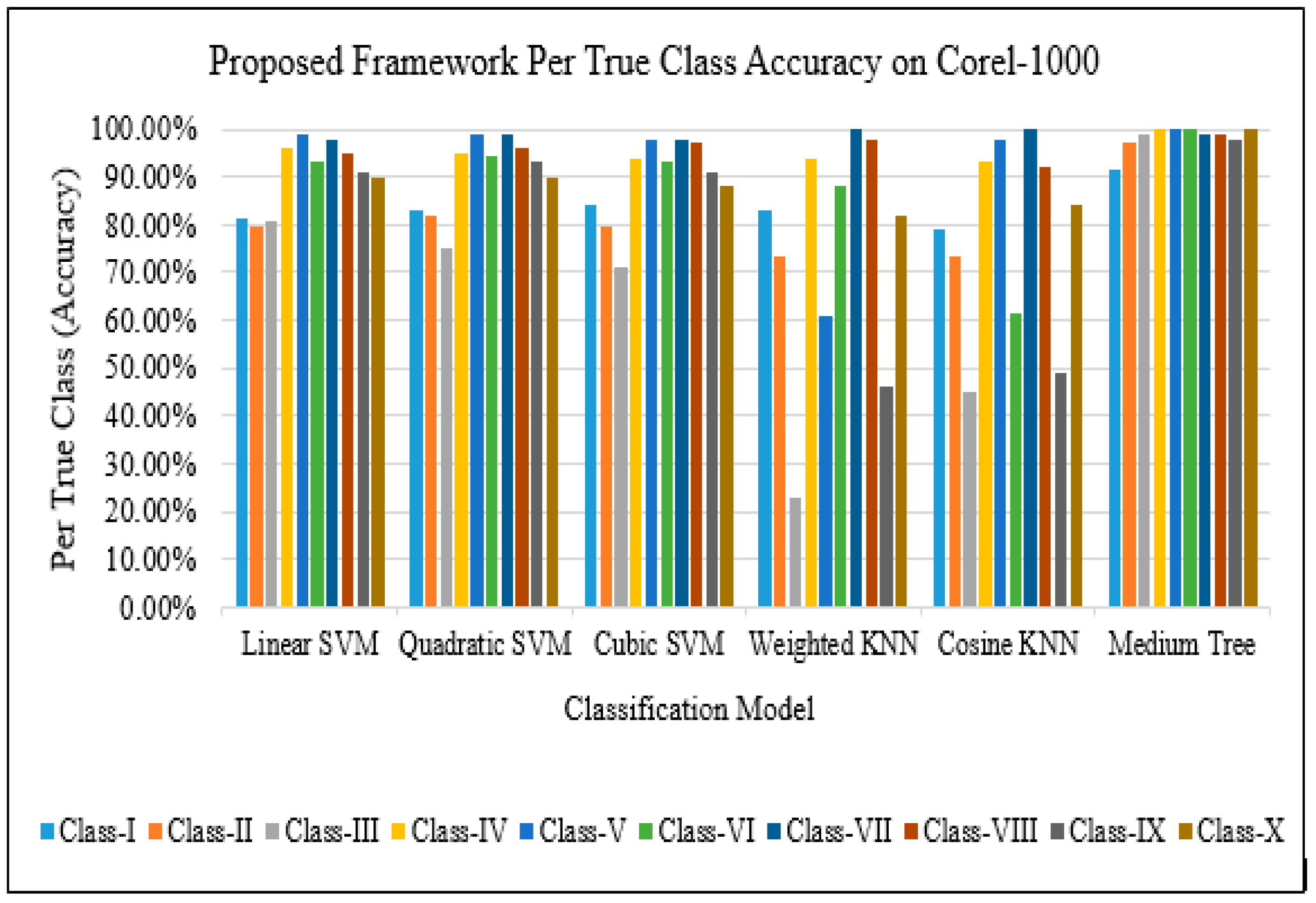
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Rana, S.P.; Dey, M.; Siarry, P. Boosting content based image retrieval performance through integration of parametric & nonparametric approaches. J. Vis. Commun. Image Represent. 2019, 58, 205–219. [Google Scholar]
- Tyagi, V. Content-based image retrieval techniques: A review. In Content-Based Image Retrieval; Springer: Singapore, 2017; pp. 29–48. [Google Scholar]
- Memon, M.H.; Li, J.; Memon, I.; Arain, Q.A. GEO matching regions: Multiple regions of interests using content based image retrieval based on relative locations. Multimed. Tools Appl. 2017, 76, 15377–15411. [Google Scholar] [CrossRef]
- Ali, G.; Ali, A.; Ali, F.; Draz, U.; Majeed, F.; Yasin, S.; Haider, N. Artificial neural network based ensemble approach for multicultural facial expressions analysis. IEEE Access. 2020, 8, 134950–134963. [Google Scholar] [CrossRef]
- Guo, Z.; Zhang, L.; Zhang, D. A completed modeling of local binary pattern operator for texture classification. IEEE Trans. Image Process. 2010, 19, 1657–1663. [Google Scholar] [PubMed]
- Tiwari, D.; Tyagi, V. Dynamic Texture Recognition Based on Completed Volume Local Binary Pattern. Multidimens. Syst. Signal Process. 2016, 27, 563–575. [Google Scholar] [CrossRef]
- Zhao, G.; Pietikäinen, M. Dynamic texture recognition using volume local binary patterns. In Dynamical Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 165–177. [Google Scholar]
- Shrivastava, N.; Tyagi, V. Noise-invariant structure pattern for image texture classification and retrieval. Multimed. Tools Appl. 2016, 75, 10887–10906. [Google Scholar] [CrossRef]
- Agarwal, M.; Singhal, A.; Lall, B. Multi-channel local ternary pattern for content-based image retrieval. Pattern Anal. Appl. 2019, 22, 1585–1596. [Google Scholar] [CrossRef]
- Ali, T.; Noureen, J.; Draz, U.; Shaf, A.; Yasin, S.; Ayaz, M. Participants Ranking Algorithm for Crowdsensing in Mobile Communication. EAI Endorsed Trans. Scalable Inf. Syst. 2018, 5, 154467. [Google Scholar] [CrossRef]
- Hussain, A.; Draz, U.; Ali, T.; Tariq, S.; Irfan, M.; Glowacz, A.; Rahman, S. Waste Management and Prediction of Air Pollutants Using IoT and Machine Learning Approach. Energies 2020, 13, 3930. [Google Scholar] [CrossRef]
- Burges, C.J. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Shawe-Taylor, J.; Sun, S. A review of optimization methodologies in support vector machines. Neurocomputing 2011, 74, 3609–3618. [Google Scholar] [CrossRef]
- Qaisar, Z.H.; Irfan, M.; Ali, T.; Ahmad, A.; Ali, G.; Glowacz, A.; Glowacz, W.; Caesarendra, W.; Mashraqi, A.M.; Draz, U.; et al. Effective beamforming technique amid optimal value for wireless communication. Electronics 2020, 9, 1869. [Google Scholar] [CrossRef]
- Schölkopf, B.; Burges, C.J.; Smola, A.J. Advances in Kernel Methods: Support Vector Learning; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Khosla, G.; Rajpal, N.; Singh, J. Evaluation of Euclidean and Manhanttan metrics in content based image retrieval system. In Proceedings of the 2015 2nd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 11–13 March 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Nalini, P.; Malleswari, B. An Empirical Study and Comparative Analysis of Content Based Image Retrieval (CBIR) Techniques with Various Similarity Measures. In Proceedings of the 3rd International Conference on Electrical, Electronics, Engineering Trends, Communication, Optimization and Sciences (EEECOS), Tadepalligudem, India, 1–2 June 2016. [Google Scholar]
- Jia Li, J.Z.W. Corel-1000. Available online: http://wang.ist.psu.edu/docs/related/ (accessed on 2 February 2020).
- Li, J.; Wang, J.Z. Real-time Computerized Annotation of Pictures. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 30, 985–1002. [Google Scholar]
- Zhang, E.; Zhang, Y. Precision. In Encyclopedia of Database Systems; Liu, L., Özsu, M.T., Eds.; Springer: Boston, MA, USA, 2009; p. 2126. [Google Scholar]
- Hussain, A.; Irfan, M.; Baloch, N.K.; Draz, U.; Ali, T.; Glowacz, A.; Antonino-Daviu, J. Savior: A Reliable Fault Resilient Router Architecture for Network-on-Chip. Electronics 2020, 9, 1783. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Gudivada, V.N.; Raghavan, V.V. Content based image retrieval systems. Computer 1995, 28, 18–22. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, D.; Lu, G.; Ma, W.-Y. A survey of content-based image retrieval with high-level semantics. Pattern Recognit. 2007, 40, 262–282. [Google Scholar] [CrossRef]
- Kokare, M.; Chatterji, B.; Biswas, P. Comparison of similarity metrics for texture image retrieval. In Proceedings of the Conference on Convergent Technologies for Asia-Pacific Region (TENCON 2003), Bangalore, India, 15–17 October 2003; IEEE: Piscataway, NJ, USA, 2003. [Google Scholar]
- Graps, A. An introduction to wavelets. IEEE Comput. Sci. Eng. 1995, 2, 50–61. [Google Scholar] [CrossRef]
- Ali, G.; Ali, T.; Irfan, M.; Draz, U.; Sohail, M.; Glowacz, A.; Martis, C. IoT Based Smart Parking System Using Deep Long Short Memory Network. Electronics 2020, 9, 1696. [Google Scholar] [CrossRef]
- Ali, T.; Draz, U.; Yasin, S.; Noureen, J.; Shaf, A.; Ali, M. An Efficient Participant’s Selection Algorithm for Crowdsensing. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 399–404. [Google Scholar] [CrossRef]
- Vassilieva, N.S. Content-based image retrieval methods. Program. Comput. Softw. 2009, 35, 158–180. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikäinen, M.; Mäenpää, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intel. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Srivastava, P.; Khare, A. Integration of wavelet transform, local binary patterns and moments for content-based image retrieval. J. Vis. Commun. Image Represent. 2017, 42, 78–103. [Google Scholar] [CrossRef]
- Manjunath, B.S.; Ma, W.-Y. Texture features for browsing and retrieval of image data. IEEE Trans. Pattern Anal. Mach. Intell. 1996, 18, 837–842. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef]
- Cross, G.R.; Jain, A.K. Markov random field texture models. IEEE Trans. Pattern Anal. Mach. Intell. 1983, PAMI-5, 25–39. [Google Scholar] [CrossRef]
- Mezaris, V.; Kompatsiaris, I.; Strintzis, M.G. An ontology approach to object-based image retrieval. In Proceedings of the 2003 International Conference on Image Processing, Barcelona, Spain, 14–17 September 2003; IEEE: Piscataway, NJ, USA, 2003. [Google Scholar]
- Town, C.; Sinclair, D. Content Based Image Retrieval Using Semantic Visual Categories; AT&T Laboratories Cambridge: Cambridge, UK, 2000. [Google Scholar]
- Song, Y.; Wang, W.; Zhang, A. Automatic annotation and retrieval of images. World Wide Web 2003, 6, 209–231. [Google Scholar] [CrossRef]
- Ahmed, K.T.; Naqvi, S.A.H.; Rehman, A.; Saba, T. Convolution, Approximation and Spatial Information Based Object and Color Signatures for Content Based Image Retrieval. In Proceedings of the 2019 International Conference on Computer and Information Sciences (ICCIS), Sakaka, Saudi Arabia, 3–4 April 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Alzu’bi, A.; Amira, A.; Ramzan, N. Content-based image retrieval with compact deep convolutional features. Neurocomputing 2017, 249, 95–105. [Google Scholar] [CrossRef]
- Shaf, A.; Ali, T.; Farooq, W.; Javaid, S.; Draz, U.; Yasin, S. Two Classes Classification Using Different Optimizers in Convolutional Neural Network. In Proceedings of the 2018 IEEE 21st International Multi-Topic Conference (INMIC), Karachi, Pakistan, 1–2 November 2018; pp. 1–6. [Google Scholar]
- Cui, C.; Lin, P.; Nie, X.; Yin, Y.; Zhu, Q. Hybrid. textual-visual relevance learning for content-based image retrieval. J. Vis. Commun. Image Represent. 2017, 48, 367–374. [Google Scholar] [CrossRef]
- Zhou, W.; Li, H.; Sun, J.; Tian, Q. Collaborative index embedding for image retrieval. IEEE Trans. Pattern Anal. Mach. Intel. 2018, 40, 1154–1166. [Google Scholar] [CrossRef]
- Jin, C.; Jin, S.-W. Content-based image retrieval model based on cost sensitive learning. J. Vis. Commun. Image Represent. 2018, 55, 720–728. [Google Scholar] [CrossRef]
- Tzelepi, M.; Tefas, A. Deep convolutional learning for content based image retrieval. Neurocomputing 2018, 275, 2467–2478. [Google Scholar] [CrossRef]
- Pavithra, L.; Sharmila, T.S. An efficient framework for image retrieval using color, texture and edge features. Comput. Electr. Eng. 2018, 70, 580–593. [Google Scholar] [CrossRef]
- Xu, Y.; Gong, J.; Xiong, L.; Xu, Z.; Wang, J.; Shi, Y.-S. A privacy-preserving content-based image retrieval method in cloud environment. J. Vis. Commun. Image Represent. 2017, 43, 164–172. [Google Scholar] [CrossRef]
- Hussain, D.M.; Surendran, D. The efficient fast-response content-based image retrieval using spark and MapReduce model framework. J. Ambient. Intell. Humaniz. Comput. 2020, 7, 1–8. [Google Scholar]
- Alsmadi, M.K. Content-Based Image Retrieval Using Color, Shape and Texture Descriptors and Features. Arab. J. Sci. Eng. 2020, 45, 3317–3330. [Google Scholar] [CrossRef]
- Garg, M.; Dhiman, G. A novel content based image retrieval approach for classification using glcm features and texture fused lbp variants. Neural. Comput. Appl. 2020. [Google Scholar] [CrossRef]
- Cha, S.-H. Comprehensive survey on distance/similarity measures between probability density functions. City 2007, 1, 1. [Google Scholar]
- Yue, J.; Li, Z.; Liu, L.; Fu, Z. Content-based image retrieval using color and texture fused features. Math. Comput. Model. 2011, 54, 1121–1127. [Google Scholar] [CrossRef]
- Shen, L.; Bai, L. A review on Gabor wavelets for face recognition. Pattern Anal. Appl. 2006, 9, 273–292. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD), Portland, OR, USA, 2–4 August 1996. [Google Scholar]
- Hastie, T.; Rosset, S.; Tibshirani, R.; Zhu, J. The entire regularization path for the support vector machine. J. Mach. Learn. Res. 2004, 5, 1391–1415. [Google Scholar]
- Lin, C.-H.; Chen, R.-T.; Chan, Y.-K. A smart content-based image retrieval system based on color and texture feature. Image Vis. Comput. 2009, 27, 658–665. [Google Scholar] [CrossRef]
- Irtaza, A.; Jaffar, A.; Aleisa, E.; Choi, T.-S. Embedding neural networks for semantic association in content based image retrieval. Multimed. Tools Appl. 2014, 72, 1911–1931. [Google Scholar] [CrossRef]
- Wang, X.-Y.; Yu, Y.-J.; Yang, H.-Y. An effective image retrieval scheme using color, texture and shape features. Comput. Stand. Interfaces 2011, 33, 59–68. [Google Scholar] [CrossRef]
- Walia, E.; Pal, A. Fusion framework for effective color image retrieval. J. Vis. Commun. Image Represent. 2014, 25, 1335–1348. [Google Scholar] [CrossRef]
- Walia, E.; Vesal, S.; Pal, A. An effective and fast hybrid framework for color image retrieval. Sens. Imaging 2014, 15, 93. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Corel-1k | Lin et al. [55] | Irtaza et al. [56] | Wang et al. [57] | Walia et al. [58] | Walia et al. [59] | Pavithra et al. [45] | Proposed Approach |
|---|---|---|---|---|---|---|---|
| Class-I | 55.5 | 53 | 80.5 | 41.25 | 73 | 81 | 91.6 |
| Class-II | 66 | 46 | 56 | 71 | 39.25 | 66 | 97.1 |
| Class-III | 53.5 | 59 | 48 | 46.75 | 46.25 | 78.75 | 99 |
| Class-IV | 84 | 73 | 70.5 | 59.25 | 82.5 | 96.25 | 100 |
| Class-V | 98.25 | 99.75 | 100 | 99.5 | 98 | 100 | 100 |
| Class-VI | 63.75 | 51 | 53.75 | 62 | 59.25 | 70.75 | 99 |
| Class-VII | 88.5 | 76.75 | 93 | 80.5 | 86 | 95.75 | 99 |
| Class-VIII | 87.25 | 70.25 | 89 | 68.75 | 89.75 | 98.75 | 99 |
| Class-IX | 48.75 | 62.5 | 52 | 69 | 41.75 | 67.75 | 98 |
| Class-X | 68.75 | 70.75 | 62.25 | 29.25 | 53.45 | 77.25 | 100 |
| Overall AP | 71.425% | 66.20% | 70.50% | 62.725% | 66.92% | 83.225% | 98.3% |
| Corel-1500 AP | - | - | - | - | - | - | 98.9% |
| Corel-5K AP | 58.753 | 53.238 | 60.58 | 49.67 | 56.72 | 68.605 | 98.8% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khalid, M.J.; Irfan, M.; Ali, T.; Gull, M.; Draz, U.; Glowacz, A.; Sulowicz, M.; Dziechciarz, A.; AlKahtani, F.S.; Hussain, S. Integration of Discrete Wavelet Transform, DBSCAN, and Classifiers for Efficient Content Based Image Retrieval. Electronics 2020, 9, 1886. https://doi.org/10.3390/electronics9111886
Khalid MJ, Irfan M, Ali T, Gull M, Draz U, Glowacz A, Sulowicz M, Dziechciarz A, AlKahtani FS, Hussain S. Integration of Discrete Wavelet Transform, DBSCAN, and Classifiers for Efficient Content Based Image Retrieval. Electronics. 2020; 9(11):1886. https://doi.org/10.3390/electronics9111886
Chicago/Turabian StyleKhalid, Muhammad Junaid, Muhammad Irfan, Tariq Ali, Muqaddas Gull, Umar Draz, Adam Glowacz, Maciej Sulowicz, Arkadiusz Dziechciarz, Fahad Salem AlKahtani, and Shafiq Hussain. 2020. "Integration of Discrete Wavelet Transform, DBSCAN, and Classifiers for Efficient Content Based Image Retrieval" Electronics 9, no. 11: 1886. https://doi.org/10.3390/electronics9111886
APA StyleKhalid, M. J., Irfan, M., Ali, T., Gull, M., Draz, U., Glowacz, A., Sulowicz, M., Dziechciarz, A., AlKahtani, F. S., & Hussain, S. (2020). Integration of Discrete Wavelet Transform, DBSCAN, and Classifiers for Efficient Content Based Image Retrieval. Electronics, 9(11), 1886. https://doi.org/10.3390/electronics9111886