1. Introduction
Ground-penetrating radar (GPR) is an important non-destructive evaluation (NDE) method [
1,
2]. Over the past decade, GPR has been widely applied to geological exploration [
3], landmine detection [
4], and NDE of structures [
5]. In civil field, it has become a routine tool for inspecting rebars in concrete, locating subsurface utilities, structural evaluation, etc. [
6,
7,
8,
9]. It utilizes underground materials’ different electromagnetic properties to detect underground areas based on the propagation and scattering characteristics of high-frequency electromagnetic (EM) waves [
10,
11,
12]. Scattering from a single point or cylinder, such as rebar and pipeline, will produce hyperbolic reflection characteristics in the recorded GPR B-scans [
13,
14]. As a result, the detection of the hyperbola regions in the GRP B-scans is equivalent to the detection of the underground targets. Thus, the problem of underground targets detection can be transferred to the detection of hyperbola regions.
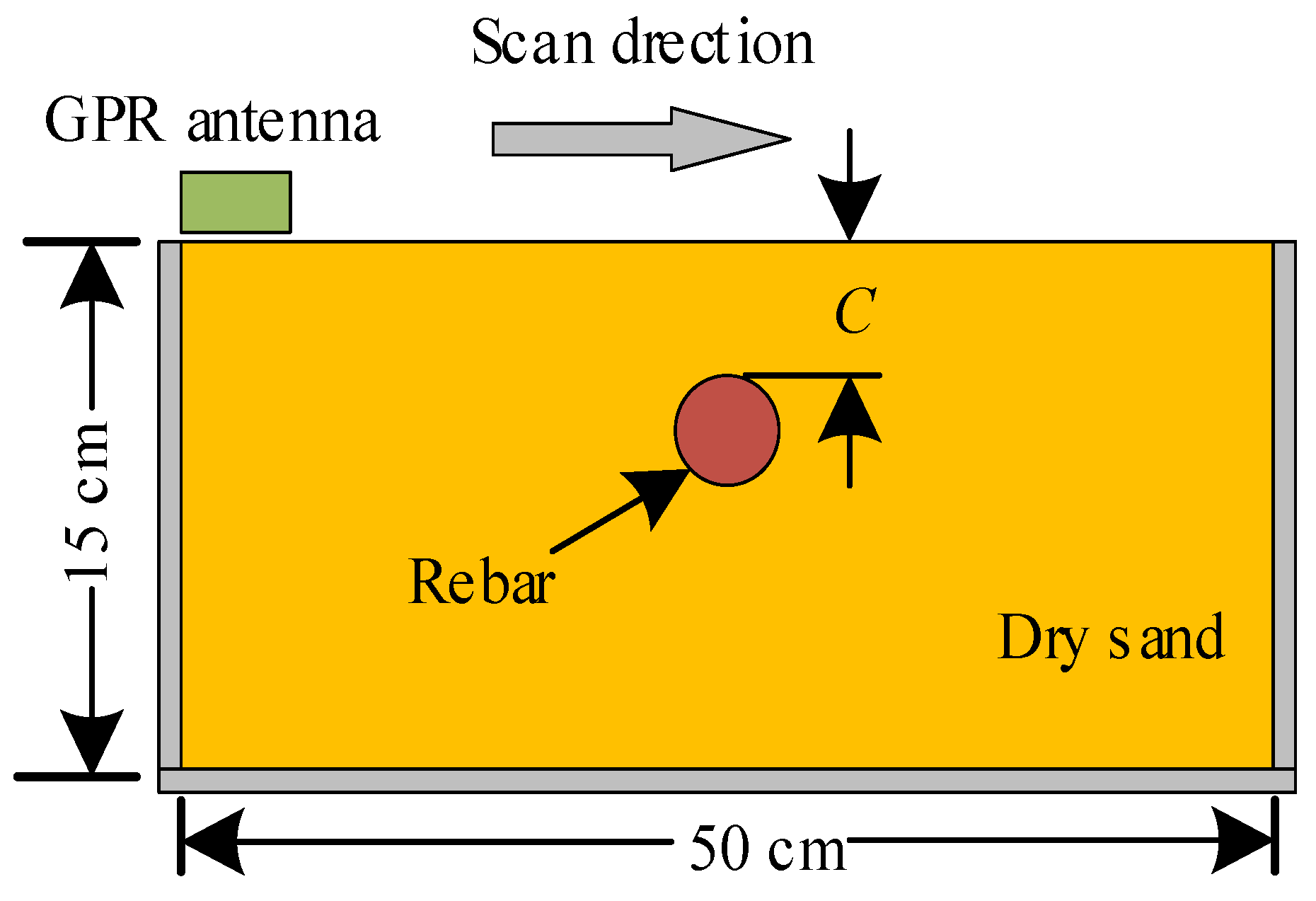
In the process of civil infrastructure construction, more and more cylindrical objects are buried underground, including rebars, pipelines (gas, water, oil, sewage, etc.), cylindrical tanks, and cables (energy, optical, signal). It is particularly important to accurately estimate the diameter of cylindrical underground objects with GPR technology [
15]. However, the diameter estimation of underground cylindrical objects from GPR B-scans often requires manual interaction [
16]. The high time consumption limits its application in the field environment. Therefore, the researchers have aroused great interest in the automatic detection and interpretation of GPR data in recent years [
17]. Interpretation of GPR B-scans usually consists of two parts: hyperbola region detection and parameter estimation (e.g., diameter).
The detection of hyperbola region from B-scans is a first step of GPR data interpretation, after that, the parameters estimation of underground cylindrical objects can be conducted based on the picked regions [
18]. In Reference [
19], the Hough transform was first used for hyperbola detection in GPR B-scans. It can transform the global curve detection problem into an effective peak detection problem in the Hough parameter space. The Viola-Jones algorithm has been used to narrow the range of the reflection hyperbola. A generalized Hough transform was used to detect the hyperbolas and to derive the hyperbolic parameters [
20]. However, Hough transform is computationally expensive. In addition, some image processing methods are used to process radar signals [
21,
22]. An advanced imaging algorithm was proposed for automated detection of the hyperbola region, which used the Canny edge detector and performed well [
21]. Extensive research has applied deep learning (DL) techniques to process radar signals [
6,
23,
24,
25]. In Reference [
23], GPR waveform signals were classified by a neural network classifier to determine hyperbola regions. However, it is susceptible to clutter and noise. The work in Reference [
24] designed a binary classifier which employed high-order statistic cumulant features and used a multi-objective genetic approach for hyperbola detection. In Reference [
6], a method based on template matching and Convolutional Neural Network (CNN) was provided for hyperbola region detection. The matching template was designed to traverse GPR B-scans and the region with high similarity was calculated as the pre-detection region. Then, the CNN was used to eliminate the non-hyperbolic region and obtain the hyperbola region. However, it requires a large amount of data for model training. In Reference [
26], the author proposed a twin gray statistical sequence method to classify the hyperbola, which utilized the different physical meanings of the row vector and column vector of the B-scan image. In References [
27,
28], an advanced CNN, i.e., Faster Region-based CNN (Faster R-CNN) and another DL method, i.e., Single Shot Multibox Detector (SSD), have been employed in GPR hyperbola region detection. Although the detection accuracy of Faster R-CNN and SSD is promising, the detection speed cannot satisfy the requirement of real-time detection.
Numerous efforts have been contributed for the interpretation of GPR data, such as diameter estimation. In References [
29,
30], the authors optimized the estimations of cylindrical target diameter using ray-based analysis, assuming non-point diffractors and realistic antenna offset in common-offset GPR data. A key limitation in the method presented here is that it requires the GPR profile to be perpendicular to the rebars. In Reference [
31], Zhang et al. proposed a method based on GPR data to estimate the diameter of underground objects. The principle is based on the fact that the shape of a circle can be determined by the coordinates of three points on the circle. However, this method is easy to be disturbed by noise, which results in a low estimation accuracy. Methods including hyperbola coordinates localization and hyperbola fitting are the common selection for diameter estimation [
32,
33,
34,
35]. In Reference [
33], a column-connection clustering (C3) algorithm was proposed to locate the coordinate position of hyperbola and separate the hyperbola with intersections. The work in Reference [
34] used a least square method for fitting hyperbolae. In Reference [
35], a hyperbola-specific fitting technique using weighted least squares is proposed for the expected mathematical error of two-way travel time. However, researchers find that the shape of the hyperbolic curve is insensitive to diameter. Therefore, it is not easy to estimate the diameter of an underground cylindrical object by hyperbolic fitting with high accuracy [
36]. Moreover, this method only uses the coordinate information of hyperbolic contour and ignores the amplitude information of the GPR data.
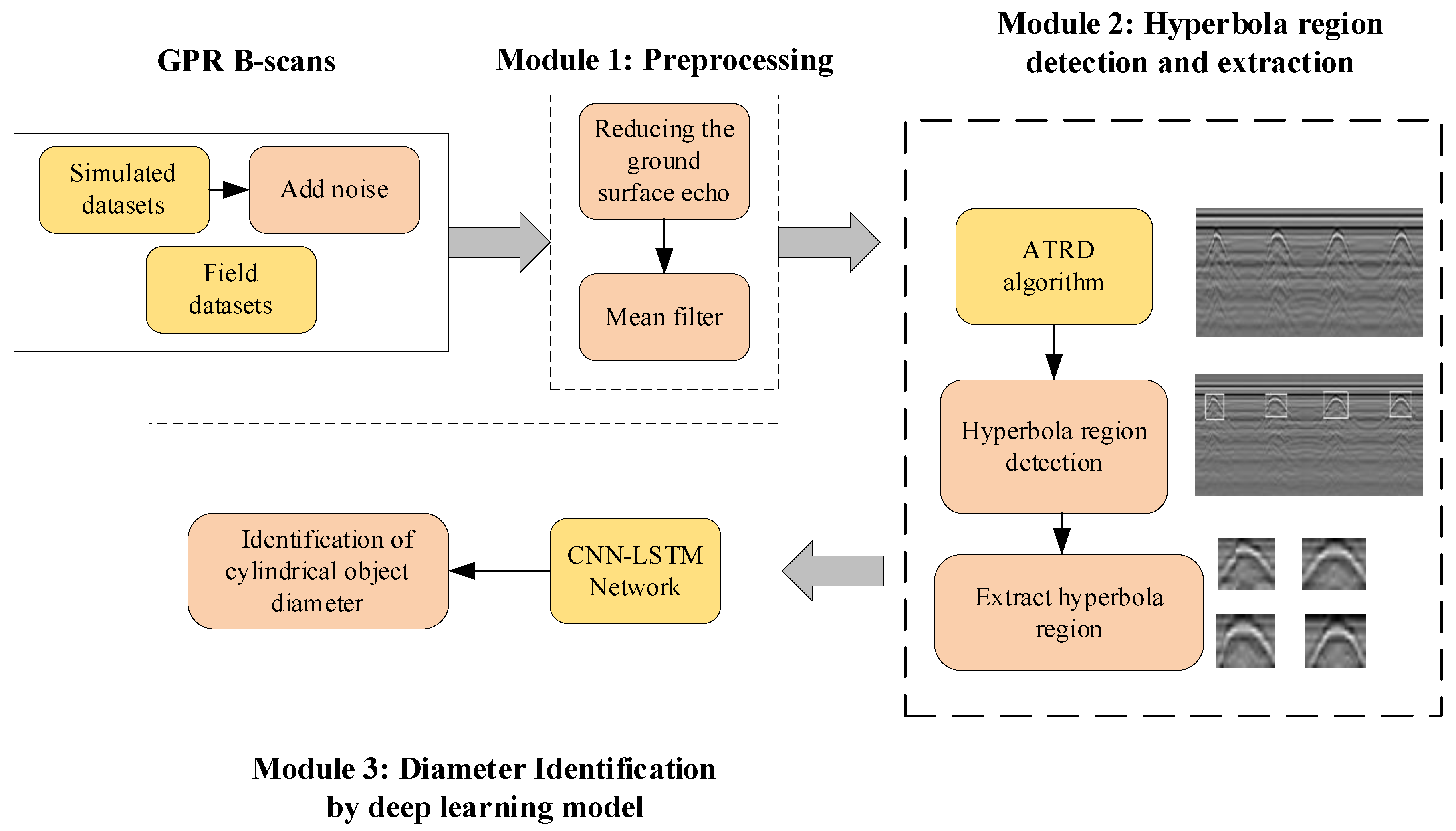
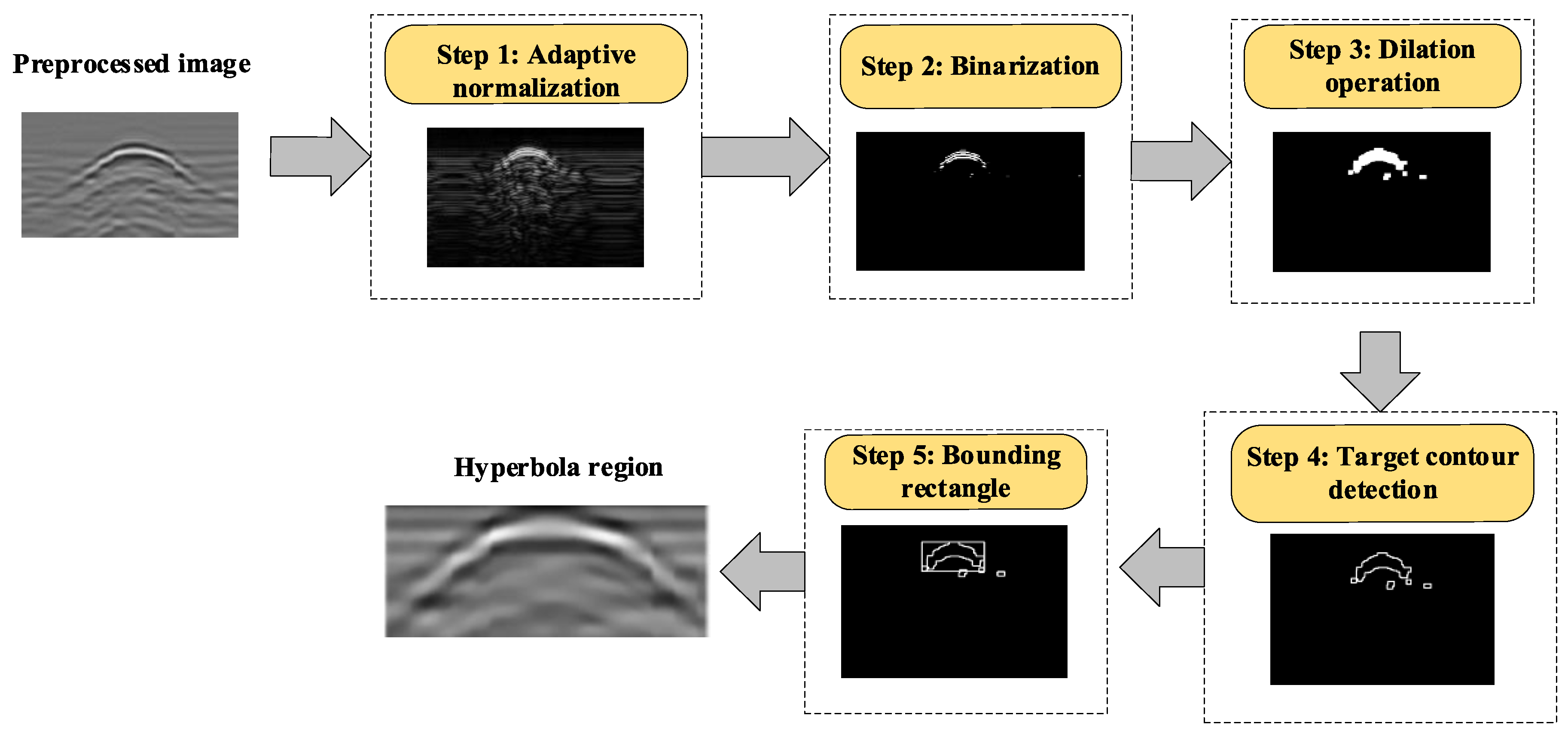
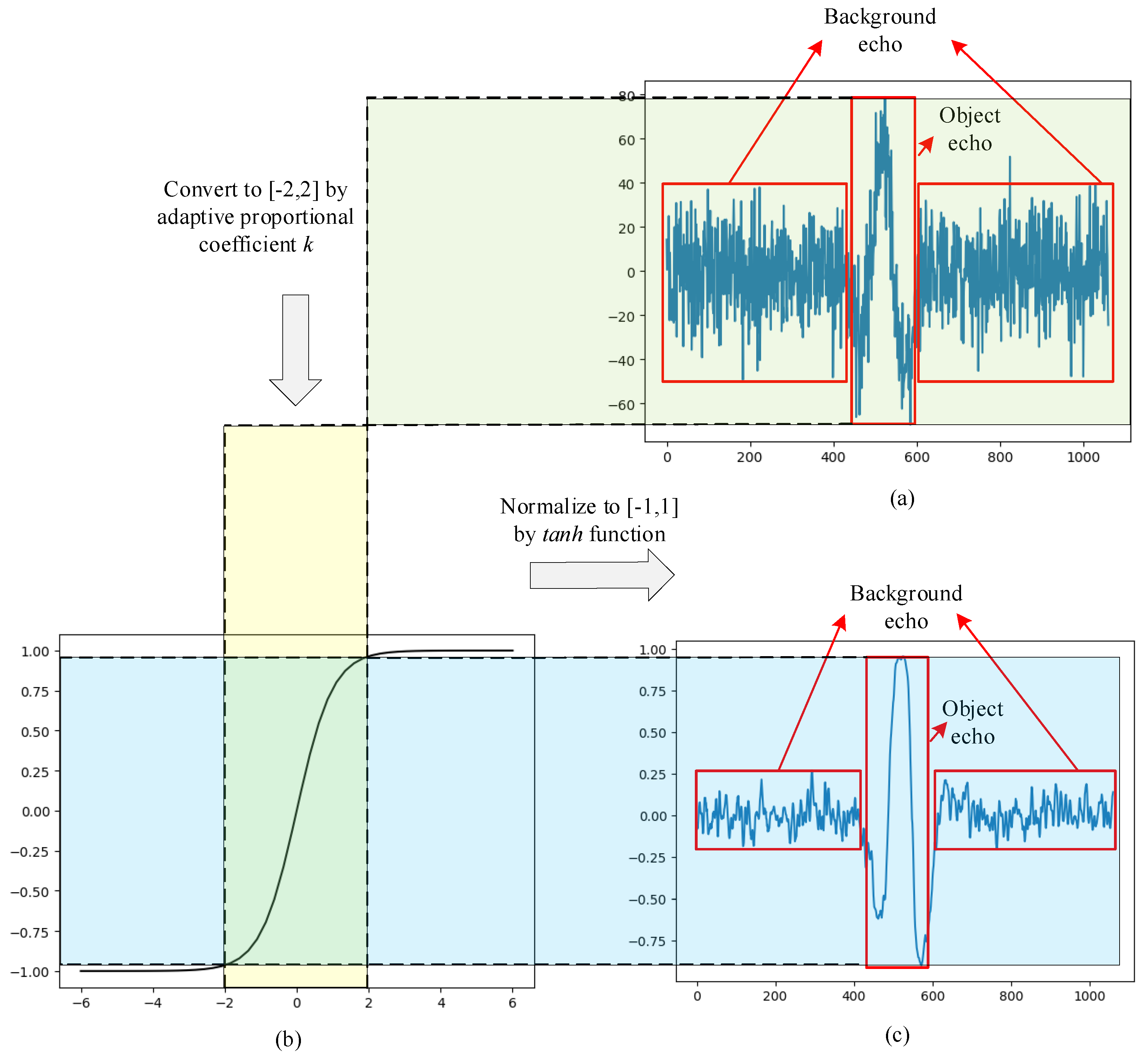
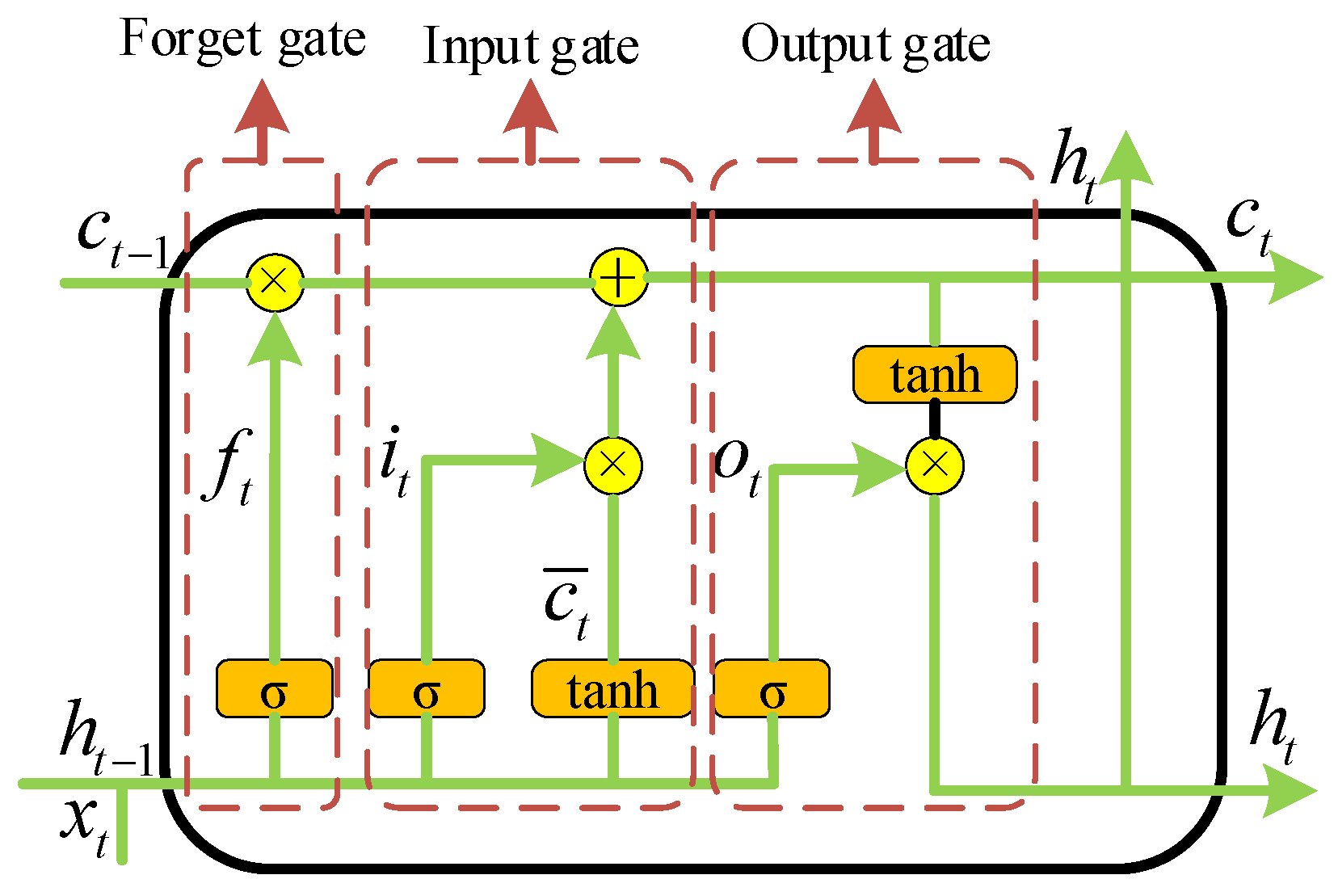
In order to solve these challenges, an automatic scheme based on the adaptive target region detection (ATRD) algorithm and Convolutional Neural Network-Long Short-Term Memory (CNN-LSTM) framework is proposed to interpret GPR data. Its flowchart is shown in
Figure 1, which consists of three modules: the data preprocessing module, hyperbola region detection module, and diameter identification module. The hyperbola region in GPR B-scans can be extracted by using the ATRD algorithm, after that, the CNN-LSTM framework integrates CNN and LSTM structures to extract hyperbola region features and transfer the diameter estimation task to the hyperbola region classification task.
The contributions of this paper are summarized as follows:
- (1)
The development of a scheme for diameter identification of underground cylindrical objects based on image processing and DL techniques.
- (2)
Designing an ATRD algorithm for hyperbola region detection from B-scans.
- (3)
Designing a CNN-LSTM framework for diameter identification.
5. Conclusions
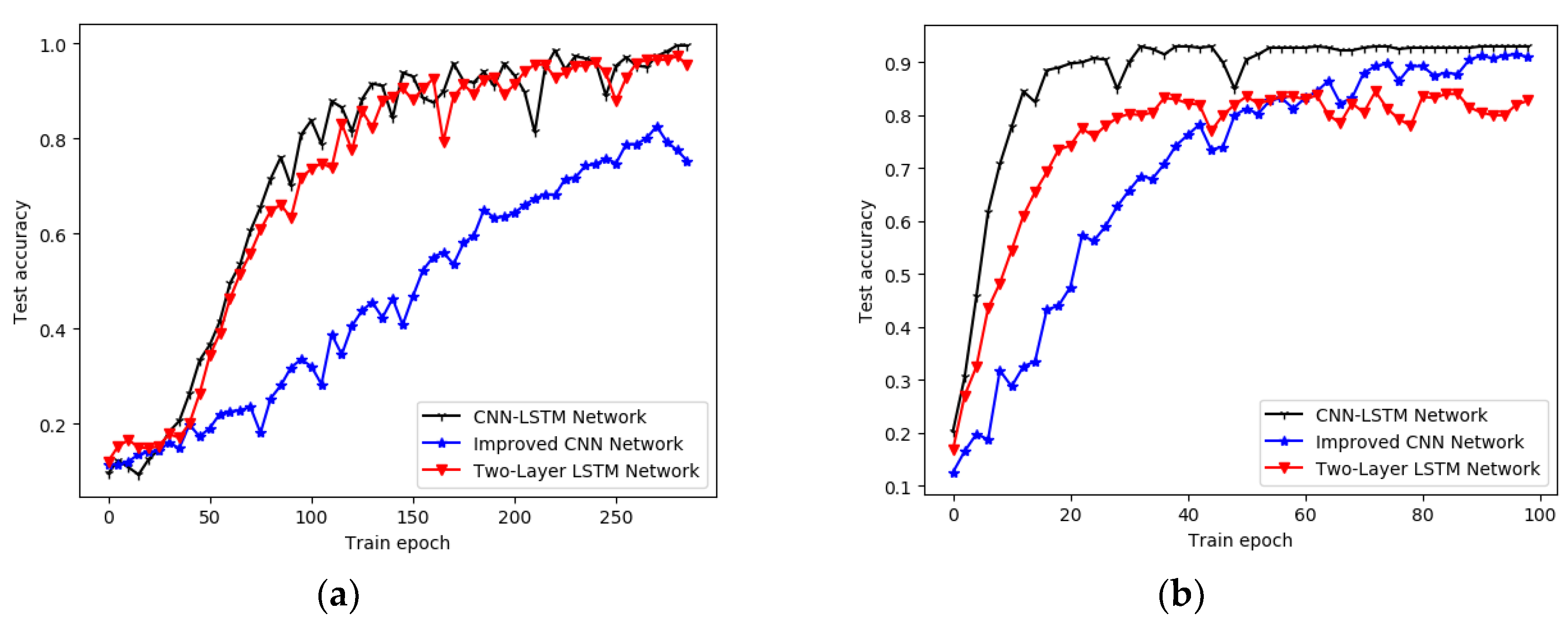
In this study, an automated scheme was proposed to identify the diameter of surface cylindrical objects in GPR B-scans. The proposed ATRD algorithm was able to extract the regions containing the expected hyperbola target from GPR B-scans. The CNN-LSTM was adopted as the main framework, which was developed to classify these regions and obtain the corresponding diameter identification results. The CNN-LSTM framework extracted both spatial position features and time series features of hyperbola regions and concatenated the two features as input of the FC layer. The comparative experiments were conducted on simulated and field datasets with nine types of diameters. The CNN-LSTM framework reached an accuracy of 99.5% on the simulated dataset and 92.5% on the field dataset, which can effectively identify different diameters of underground cylindrical objects and outperforms other DL networks. On the simulated datasets, it improved at an accuracy of 14.5% compared to the single CNN network and 4% compared to the single LSTM network. On the field datasets, it improved at an accuracy of 2.5% compared to the single CNN network and 7.5% compared to the single LSTM network.
However, the field datasets were not sufficient for the need of training the DL model. Due to the complex surface environment, it is difficult to collect and generate a large number of field data. Future work will focus on the data augmentation techniques. For example, the generative adversarial network (GAN) model could be used to generate and augment GPR datasets. In addition, the proposed scheme focuses on only the single target identification. The performance of the scheme is limited when there exists interferences or multiple targets. Future effort could be conducted to use the state-of-the-art DL network to extract the features of hyperbolic signatures with intersections with others in more complex scenarios for diameter identification.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}