Malware analysis and detection are crucial tasks to counter malicious attacks and prevent them from conducting their harmful acts. However, it is not always an easy task, especially when dealing with new and unknown malware that has never been seen. Conventional security mechanisms are rely on a specific set of signatures and employ static analysis techniques such as model checking and theorem proving to perform detection [
1,
3]. The malware functionality is explored by examining its static properties that imply maliciousness of the analysed file [
3], then a signature (or a pattern) that identifies its unique characteristics can be crafted, so that specific malware can be identified in the future, including similar variants [
1,
25]. In this context, various malware detection techniques based on signatures and static analysis have been proposed by the research community [
1,
23,
25]. Many of these works used the opcode sequence (or operational code) as a feature in malware detection by calculating the similarity between opcode sequences, or frequency of appearance of opcode sequences [
26,
27,
28]. For instance, work in [
26] proposed a new method to detect variants of known malware families based on the frequency of appearance of opcode sequences. However, this technique can only deal with known malware variants. Work in [
29] presented a method to detect obfuscated calls relating to “push”, “pop” and “ret” opcodes. They have proposed a state machine technique to cope with obfuscated calls. The proposed approach contains many deficiencies, such as authors being unable to cope with the scenario when push and pop instructions are decomposed into multiple instructions. Researchers in [
30] extracted the opcode distribution from PE files, which can be used to identify obfuscated malware. However, this research was not effective in detecting malware, as some of the prevalent opcodes were not able to correctly identify malware.
Several other works have addressed malware detection using a Control Flow Graph (CFG) to extract the malicious program structure [
31,
32]. Most of these detection methods were based on comparing the CFG shapes associated to the original malware with that of variants [
1]. For instance, the study in [
31] compared basic block instructions of an original malware with those of its variants by using the Longest Common Sub-sequence (LCS). In [
33], the authors extracted the system call dependency graphs from a corpus of malware containing 2393 executables. The resulting analysis method led to an accuracy of 86.77%. The main drawback of such malware detection techniques, which are based on static analysis of the malware program, is their vulnerability to evasion techniques like packing and obfuscation [
1,
23], which modify the malware payload by compressing or encrypting the data and severely limit the attempts to statically analyse the malware. When employing such obfuscation methods (packing, polymorphism, oligomorphism and metamorphism), attackers may successfully recycle existing malware by converting the malware binaries to packed and compressed files which reveal no information and therefore bypass the signature-based detection system [
34].
To overcome the limitations of static analysis, many dynamic (or behaviour) analysis techniques have been developed. These techniques execute the malicious software in a controlled, confined and simulated environment in order to model the behaviour of the malware [
1]. This kind of detection methods can detect malicious files based on normal and abnormal activities perceived in the isolated environment, with normal activities referring to the processes produced by benign applications and abnormal activities including the specific characteristic behaviours of malware [
35]. In addition, dynamic analysis methods capture the interaction between the execution of the malicious sample and the operating system, thereby collecting the artefacts that allow security analysts to develop a technical defence. To hinder such efforts, advanced and sophisticated malware samples have the ability to check for the presence of a virtual machine or a simulated operating system environment. When detecting that it is being analysed by the sandbox agent, some malware modifies its behaviour, causing the analysis to yield incorrect results. The latest research work suggests [
36,
37] that traditional sandboxes are not evasive resistance because they hook data by dropping their agent in a controlled environment that can be easily detected by advanced strains of malware. As a result, they either stop their executing or execute with limited functionality.
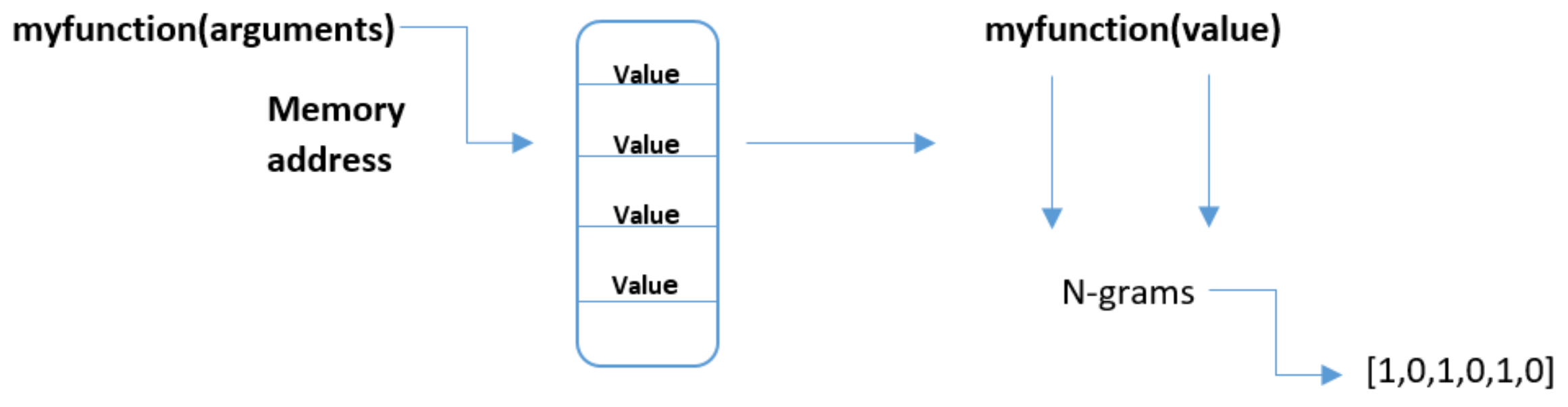
N-Grams
An N-gram is a substring of a given sample of text or speech string with a length
n. This string can include several types depending upon the application. For example, it can include letters, words, phonetics, syllables, etc. N-grams are created by splitting a text string into substrings of fixed length. For example, world MALWARE 3-grams will look like this “MAL”, “ALW”, “LWA”, ”WAR”, “ARE”. As a result of the string-based nature of analysis files, this technique has been widely adopted by the security researchers to represent the features of malware. The IBM research group [
30] is considered to be a pioneer in using N-grams for malware analysis, having started work in the area since the 1990s. More recently, researchers also introduced the concept of using N-grams to create malware signatures. However, one of the main drawbacks of this line of research was that the early studies lacked an experimental methodology to prove the claim. Santos et al. [
38] demonstrated that unknown variants of malware could be detected effectively using the N-grams technique by extracting code and text fragments from a corpus of malware that was executed in the control environment. Furthermore, signatures of these executables were created to train/test the classifier. In [
33], a similar study was proposed, where N-grams were used to represent the features e.g., API calls, arguments, etc. and to reduce the features space to a manageable size, a feature reduction technique was applied which results in only those N-grams that significantly influence the accuracy. Similarly, Ref. [
39] also demonstrated a classification method using N-grams. In this method, 2312 malware samples were executed in a controlled environment to obtain Indicators of Compromise (IOC) using dynamic analysis. The primary focus of the study was using the API log data to construct feature vectors. The N-gram technique was used to represent these features and, in a later stage, TF-IDF was employed to calculate the frequency of occurrence of these N-grams. Finally, the N-grams with a higher frequency of occurrence were used for model training and testing. The experimental results of the study depict the average precision and recall as 55% and 90%, respectively.
In [
40], N-grams profiles were used as a malware detection mechanism and to design an effective, robust system. The feature vectors were created based on the frequency of N-grams, which were extracted from 25 malware and 40 clean files. Finally, the study claimed to achieve 94 % classification accuracy using the K nearest neighbour algorithm. Kolter and Maloof in [
41] introduced an N-grams-based malware detection system. This method uses 4-grams as features and uses the information gain method to find the top 500 N-grams as the most significant features for classifying malware. The research utilizes several learning algorithms to train/test model, such as Naive Bayes, Support Vector Machines, Boosted Tree, etc. However, the experimental results and ROC curves depict that the Boosted Decision Tree produces good classification accuracy as compared to other algorithms. In [
42], Shabtai et al. used static analysis for malware detection with different N-gram sizes N = (
). In the study, several classifiers were implemented to check the efficiency and efficacy of the system.Finally, it was observed from experimental the results that system is performing better at N = 2 as compared to other values of N-grams.
In [
43], a similar study was done by Moskovitch et al. using N-gram opcode analysis to investigate the detection of malware. Although this study had implemented different classification methods as compared to the previous study, even then the experiential results show that N = 2 is best in terms of malware detection. Different machine learning algorithms have been widely used for malware detection, including classification, clustering, time series, etc. Decision Tree, Random Forest, Logistic Regression, Support Vector Machine, etc. are the most common classifying algorithms.
Classification is a controlled process that is usually separated into 2 phases: the first step includes the preparation of classification using a classification algorithm centred on the specimen characterizing and based on a specific area. There are a variety of classification algorithms used in the literature to classify malware. Such classification algorithms are discussed in-depth as below:
Decision Tree algorithms create a model of decision-making dependent on real data component values. Any node without leaves in the trees is a measure of an anti-category feature in the study set of each anti-leaf branch division, and a leaf network is a class or class allocated for that node. A direction from either the root to a leaf vertex defines a ranking law [
44]. The Application Program Interface, creatively named as the testing item by PE, uses a shifting window mechanism to remove this functionality and adopts the Decision Tree Algorithm for identifying unknown malware, which has been suggested by [
45] to detect uncertain malware. The consequence reveals that the Decision Tree is beyond the Naive Bayesian algorithm, and the consistency is more reliable than the other two algorithms.
The Random Forest is an aggregate learning method that creates a plurality of decision-making bodies and produces a forecast, which is the fashion of the different trees groups. For individual trees to expand, a collection from the training database (local set) is chosen with the remaining samples to approximate fitness. Trees are generated by separating the regional game at any nodes from a sampled subset of variables as per the importance of a random variable. The study in [
46] proposed a methodology focused on string knowledge dependent on vulnerability classification utilizing numerous well-recognized detection algorithms, such as IB1, AdaBoost and Random Forest. The studies have shown that the grouping strategies of IB1 and Random Forest are the most successful for this area. Since the spread of polymorphic and metamorphic malware, dynamic analysis has been established as an effective method to model the behaviour of these malware samples in a controlled environment [
25,
47].
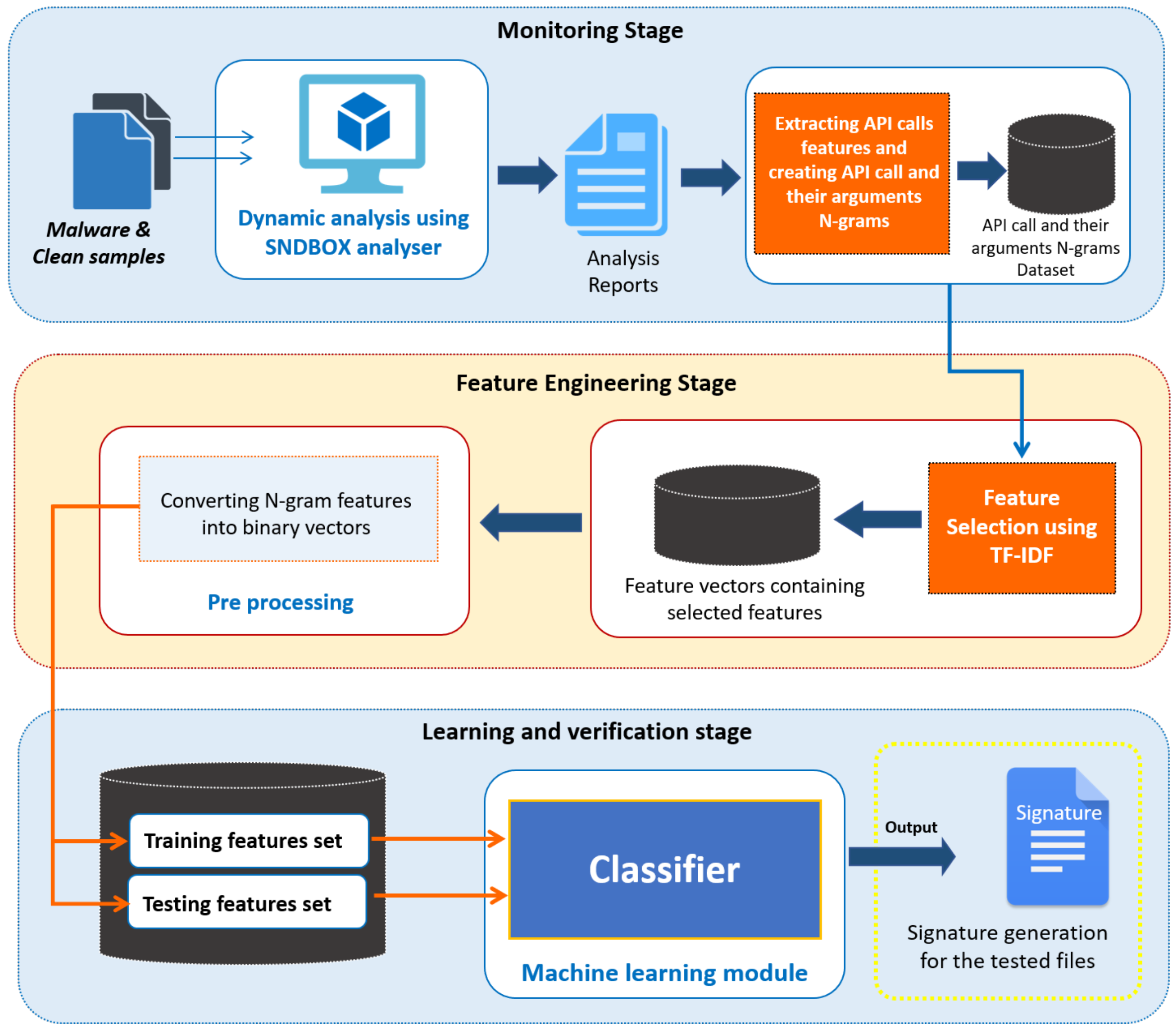
In this study, we aim to improve the current state of the art in malware analysis by presenting the design and experimental evaluation of a malware detection system, with the following contributions:
(a) Malware behavioural modelling using advance sandbox: In contrast to other studies and research work where the traditional sandboxes such as Cuckoo, Norman, Joe, etc. were used to model the behaviour of malware as from our previous research work [
36], we found that they are not so effective in capturing the behaviour of advanced and sophisticated malware; therefore, we have utilized AI-based sandbox in this work to perform dynamic analysis and to model the behaviour of the malware.
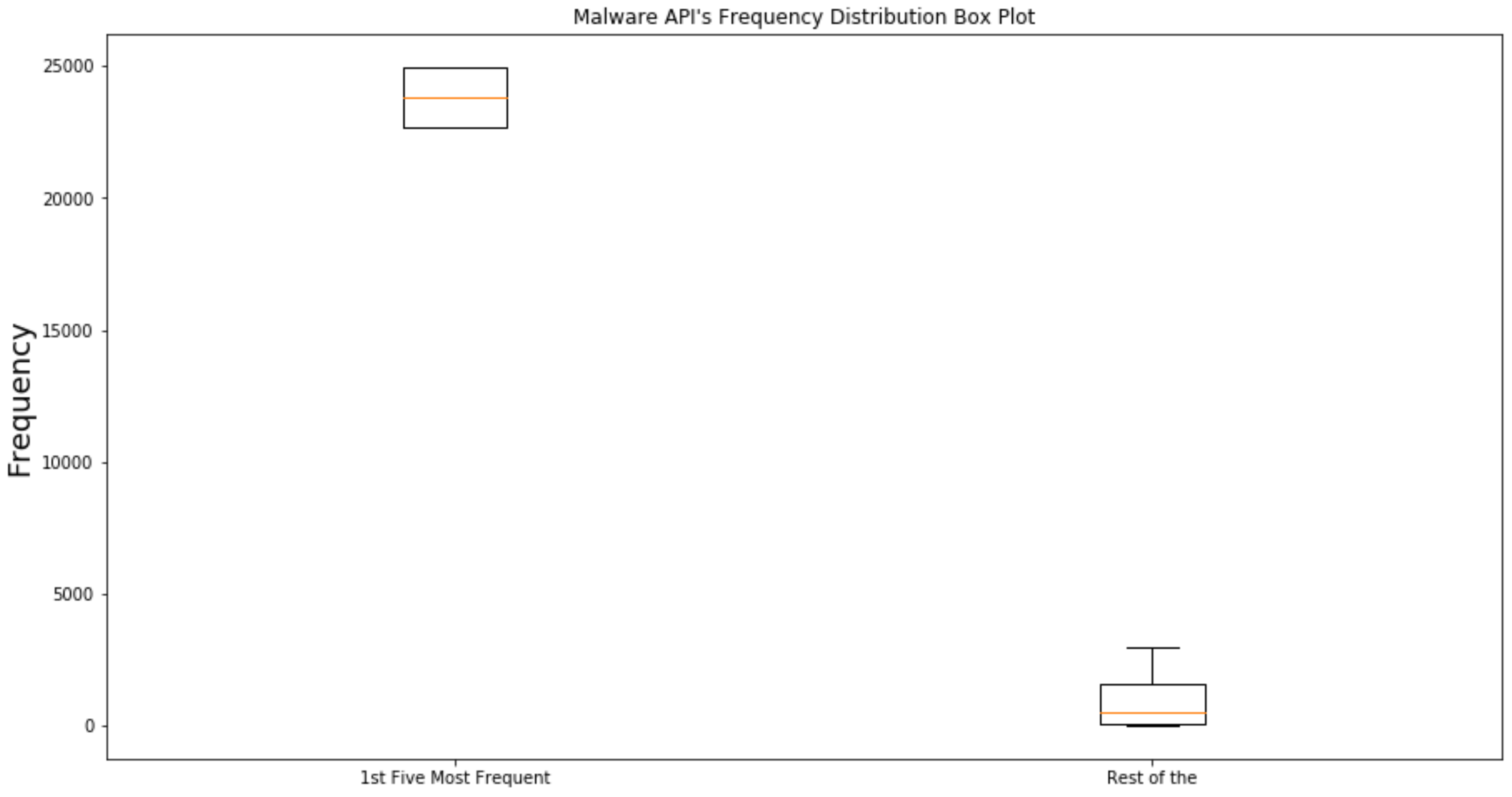
(b) Feature extraction and representation algorithm: we presented an effective feature extraction and representation algorithm that helped in building the malware detection system with optimal accuracy based on our results for other methods it could vary. We select a set of observable features from analysis files generated during dynamic analysis and whose values can be used to infer whether a given sample is malware or not. We evaluate the most significant features in terms of its usefulness for malware detection.
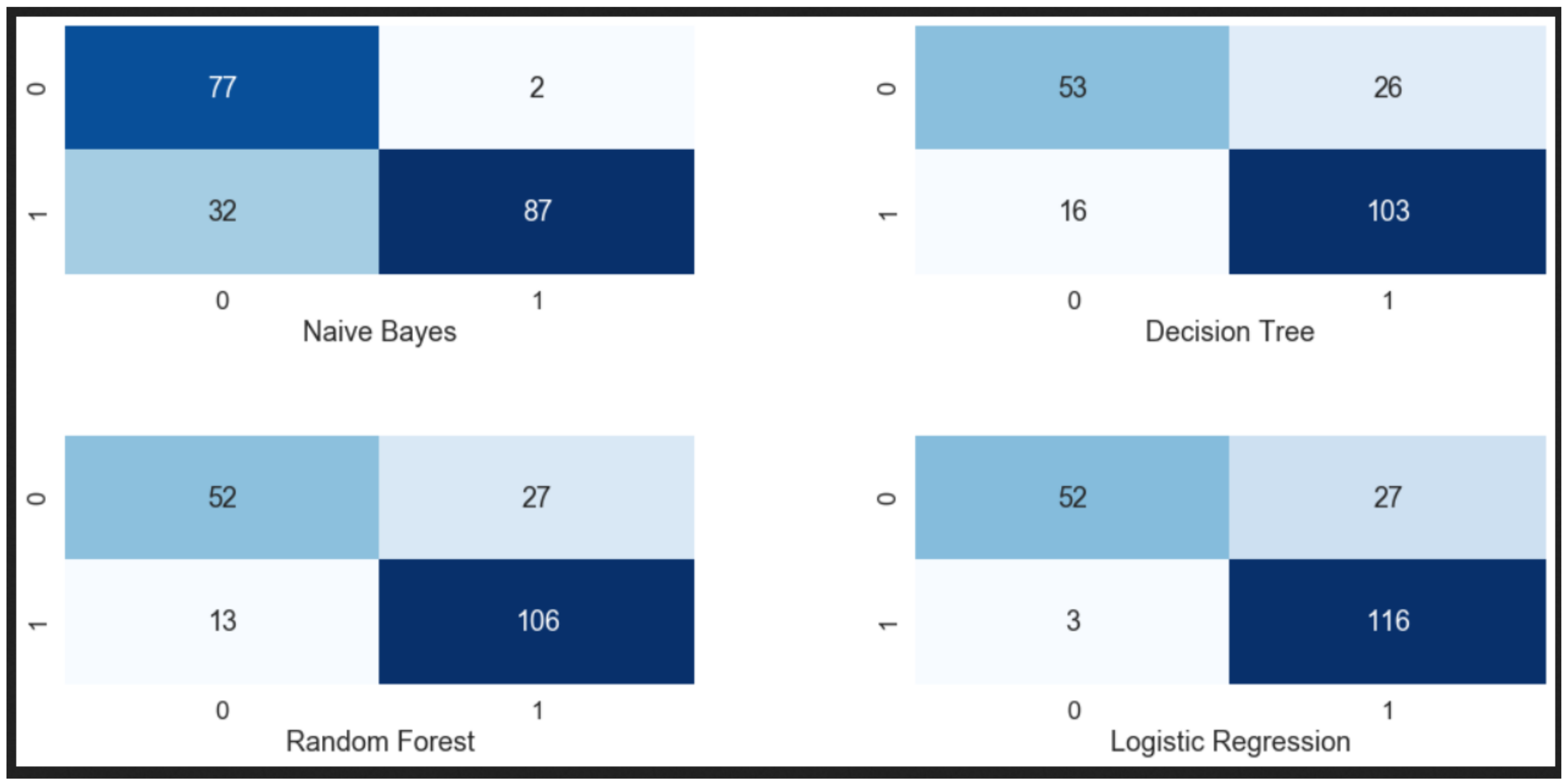
(c) Optimise Classification: We present the design of a classification system that uses Naive Bayes, Decision Tree, Random Forest to detected malware using new features.
(d) Experimental Evaluation: We evaluate the accuracy of the classification system on a corpus of more than 60 malicious and 60 clean samples. To evaluate our methodology, K-fold cross validation is used and experimental results show that our proposed detection system achieved 98.43% detection accuracy with a very minimum false positive rate.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}