1. Introduction
Computer systems are now at the heart of all business functions (accounting, customer relations, production, etc.) and more generally in everyday life. These systems consist of heterogeneous applications and data. They are sometimes described through modular architectures that integrate and compose them in order to meet the needs of the organization. Service Oriented Architectures (SOA) are suitable for this purpose.
These architectures are distributed and facilitate the communication between heterogeneous systems. The main components of such architectures are web services. A web service is a collection of open protocols and standards for exchanging data between systems. Thus, software applications written in different programming languages and running on different platforms can therefore use web services to exchange data. These services can be internal and only concern one organization. However, with technological advances in communication networks especially the Internet and the expansion of online services via cloud computing or simply the interconnection of IT systems, the need to expose services to the outside world is growing. Cloud computing for example enables sharing of IT resources (computing, storage, networks, etc.) on demand over the Internet. These services are often deployed on the basis of smaller components (containers, virtual machines, etc.) deployed on a single site or on several geographically distributed sites. They can also be provided by several different cloud service providers (multi-cloud applications).
However, web services, as with many other technologies taking advantage of the Internet, are also facing attacks on availability, integrity, and confidentiality of platforms and user data. Moreover, web services deployed in the cloud inherit their vulnerabilities. Indeed, they are vulnerable to different risks that have to be evaluated [
1]. Recently, new attacks exploiting cloud vulnerabilities such as side-channel, VM escape, hacked interfaces and APIs, and account hijacking [
2,
3,
4] are considerably reducing the effectiveness of traditional detection and prevention systems (e.g., firewall, intrusion detection systems, etc.) available in the market. Web services deployed in the cloud also inherit their vulnerabilities.
As mentioned above, cyber attacks are multiplying and becoming more and more sophisticated. We show that, to better tolerate and limit the impact of these attacks, the monitoring of the information systems is of paramount importance for any organization. Traditional intrusion detection systems are deployed to identify and inhibit attacks as much as possible. Usually, the detection of anomalies is based on the comparison of observed behaviors with previously established normal behaviors. An alert is raised when these two behaviors differ. In the case of dysfunction of the information systems, they are able to act accordingly. Moreover, monitoring makes it possible to analyze in real time the state of the computer system and the state of the computer network for preventive purposes.
However, we believe that the monitoring and detection of attacks require an awareness of the risks that the system might be exposed to. As such, it is mandatory to include risk management in the monitoring strategy in order to reduce the probability of failure or uncertainty. Risk management attempts to reduce or eliminate potential vulnerabilities, or at least reduce the impact of potential threats by implementing controls and/or countermeasures. In the case in which it is not possible to eliminate the risk, mitigation mechanisms should be applied to reduce their effects.
In this paper, we adopt a new end-to-end security approach based on risk analysis, formal monitoring, software diversity and software reflection. This approach integrates security of cloud applications based on web services at all levels: design, specification, development, deployment, and execution.
At the design phase, we model cloud applications as choreographies of web services in order to benefit from the distributed nature of cloud applications. Besides when deploying choreographies, one should ensure that these choreography are realizable and the participants of these choreographies act according to the requirements. Choreographies are written as process algebras and formally verified and projected on the peers. Each participant of that choreography is deployed in one container or virtual machine and diversified. The basic idea is to have variants of the components of the system and these variants react and replace themselves when one of these components is compromised due to the effects of an attack. Skeletons of the corresponding services are generated by ChorGen, a new Domain Specific Language (DSL) we propose.
To anticipate attacks and better monitor the system, we leverage the traditional risk management loop to build a risk-based monitoring that integrates risks into monitoring. This risk analysis helps identify the attacks most likely to be executed against the system. Once these attacks are identified, we rely on software reflection to monitor the system and detect the attacks. Reflection is a software engineering technique that helps a program to monitor, analyze, and adjust its behavior dynamically.
We propose an attack tolerance framework (offline and online) for cloud applications based on the web services in [
5]. This paper is an extension of that work covering different aspects, which are not addressed in this first version. In particular, we enrich the related work and the risk analysis sections, by giving more details on the work carried out in these areas and by presenting in more detail our results. In summary, the contributions of the paper are the following:
We detail the methodological aspects (models, assumptions, and implementation) and all the steps that led to the construction of this approach (
Section 3.5 and
Section 4). In short, a more complete framework is proposed in this paper.
We illustrate the approach through a concrete case study: an electronic vote system (
Section 5). Experiments on this use case highlight the attack tolerance capability of the whole framework. The use case is also detailed. In particular, we present how conformance of the roles with respect to the choreography is achieved.
We discuss improvements and research avenues in the area of attack tolerance (
Section 6).
The paper is organized as follows. We review the main attack tolerance techniques and the principal issues related to web services in
Section 2.
Section 3 fully describes the risk-based monitoring methodology. In this section, we also detail remediation strategies to apply corrective actions for mitigating the impact. Following the above methodology, an attack tolerance framework for cloud applications is presented in
Section 4. In
Section 5, we present a concrete case study: an electronic vote system. Experiments on this use case highlight the attack tolerance capability of the whole framework. Conclusions and future enhancements of this work are given in
Section 6.
It should be mentioned that this paper is focused on the design of a framework for attack tolerance of cloud applications, and the proposed approach could be adapted to network security [
6], but this subject is out of the scope of the paper.
2. Attack Tolerance for Web Services
This section first presents attack tolerance and existing techniques highlighting the main issues that remain unsolved. We explore software formal methods as well, in order to disclose their benefits for attack tolerance. Finally we provide an overview of web services security issues and the proposed attack tolerance approaches.
2.1. Attack Tolerance Techniques
The attack tolerance concept comes from fault tolerance, a term used in dependability [
7]. Dependability is a generic notion that measures the trustworthiness of a system, so that the users have a justified trust in the service delivered by that system [
8]. It mainly includes four components: reliability, maintainability, availability, and security. Dependability has emerged as a necessity in particular with industrial developments. The goal is to build systems that are reliable and contain near-zero defaults. As IT systems are facing both diversified and sophisticated intrusions, intrusion tolerance can be considered as one of the crucial attributes of dependability to be taken into account.
Attack tolerance of a system is then the ability of that system to continue to function properly with minimal degradation of performance, despite intrusions or malicious attacks. Several approaches and techniques are proposed in the literature. The goal of the work in [
9] is to identify common techniques for building highly available intrusion tolerant systems. The authors mentioned that a major assumption of intrusion tolerance is that IT systems can be faulty and compromised and the main challenge consists in continuing to provide (possibly degraded) services when attacks are present. In addition, the main techniques used for attack tolerance are presented in [
10]. Voting and dynamic reconfiguration are some examples of these techniques.
Furthermore, there are several solutions that provide attack tolerance using one or a combination of such techniques [
11,
12,
13,
14,
15]. Constable et al. [
16] explored how to build distributed systems that are attack-tolerant by design. The idea is to implement systems with equivalent functionality that can respond to attacks in a more safe way. Roy et al. [
17] proposed an attack tree, which they named attack-countermeasure tree. The aim is to model and analyze cyber attacks and countermeasures. They used this tree to allow automation of the attack scenarios.
Other approaches have been developed to cope with intrusion-tolerance. In [
18], the authors proposed a hybrid authorization service. The main contribution of that study is the introduction of an Intrusion tolerance authorization scheme. In this scheme, the system is able to distribute proofs of authorization to the participants of the system.
Besides, Nguyen and Sood [
19] classified ITS (Intrusion Tolerant Systems) architectures into four categories:
Detection-triggered architectures build multiple levels of defense to increase system survivability. Most of them rely on an intrusion detection that triggers reactions mechanisms.
Algorithm-driven systems employ algorithms such as the voting algorithm, threshold cryptography, and fragmentation redundancy scattering (FRS) to harden their resilience.
Recovery-based systems assume that, when a system goes online, it is compromised. Periodic restoration to a former good state is necessary.
Hybrid systems combine different architectures mentioned above.
The main conclusion of this section is that the complementary combination of these architectures can lead to the design of more efficient architectures. Our intrusion tolerance approach for web services in this paper also combines the attack tolerance mechanisms in a coherent manner by incorporating new detection methods.
2.2. Formal Methods
One of the open issues in software engineering is the correct development of computer systems. We want to be able to design safe systems. The secure design of software refers to techniques based on mathematics for the specification, development, and verification of software and hardware systems. The use of a secure design is especially important in reliable systems where, due to safety and security reasons, it is important to ensure that errors are not included during the development process. Secure designs are particularly effective when used early in the development process, at the requirements and specification levels, but can be used for a completely secure development of a system. One of the advantages of using a secure representation of systems is that it allows rigorously analyzing their properties. In particular, it helps to establish the correctness of the system with respect to the specification or the fulfilment of a specific set of requirements, to check the semantic equivalence of two systems, to analyze the preference of a system over another one with respect to a given criterion, to predict the possibility of incorrect behaviors, to establish the performance level of a system, etc. Formal methods are well suited to address the above mentioned issues as there are based on mathematical foundations that support reasoning.
There are two different categories of formal methods, static analysis, and dynamic analysis [
20]. In static analysis, the code is not executed but some properties are proven. Dynamic analysis consists of executing the code or simulating it in order to reveal bugs. Software testing consists in comparing the result of a program with the expected result. A particular type of dynamic analysis is formal monitoring which remains more used for the detection of attacks. This is why we deeply present formal monitoring.
What Is Monitoring?
Monitoring is the process of dynamically collecting, interpreting, and presenting metrics and variables related to a system’s behavior in order to perform management and control tasks [
21]. The idea behind monitoring is to measure and observe performance, connectivity, security issues, application usage, data modifications, and any other variable that permits determining the current status of the entity being monitored. By keeping a constant view of the different entities, we can obtain a real-time status of Key Performance Indicators (KPI) or Service Level Agreements (SLA) compliance as well as faults and security breaches. In addition, security requirements can be specified using different formalisms as regular expressions, temporal logic formulas, etc. Monitoring can be performed in several domains that include user activity, network and Internet traffic, software applications, services, and security. The monitoring processes should not disturb the normal operation of the protocol, application, or service under analysis.
The general processes involved in monitoring are: the definition of the detection method to track and label events and measurements of interest; the transmission of the collected information to a processing entity; the filtering and classification; and, finally, the generation decisions associated to the results obtained after the evaluation [
21]. Regarding how to collect events and measurements, monitoring techniques can be classified into three main categories: active, passive, and hybrid approaches.
Active monitoring: The System Under Observation (SUO) is stimulated in order to obtain responses to determine its behavior under certain circumstances or events. This technique permits directing requests to the concerned entities under observation. However, it presents some drawbacks. The injection of requests towards the SUO might affect its performance. This will vary depending on the amount of data required to perform the desired tests or monitoring requests. For large amounts of data, the SUO processing load might increase and produce undesirable effects. Secondly, the injected information might also influence the measurements that are being taken, for example incurring in additional delay. Lastly, active monitoring injects data that could be considered invasive. In a network operator context, it could limit its use and applicability [
22].
Passive monitoring: It consists in capturing a copy of the information produced by the SUO without a direct interaction [
23]. Runtime verification can be also considered as a form of passive monitoring [
24]. This technique reduces the overhead required on active monitoring. Conversely, certain delay should be considered when analyzing large amounts of data. Additionally, in some cases, it is not always possible to perform real-time monitoring because of required offline data post-processing [
23]. This technique has the advantage over the active approach of not performing invasive requests [
25,
26,
27].
We have seen that the formal methods make it possible to check that the system is working properly according to the expected specifications. We also note the benefits of monitoring information systems. Probes provide valuable information about the state of the system. In conclusion, monitoring can contributes to attack tolerance.
2.3. Security Issues Related to Web Services
Web services are the target of Cyber attacks. Web services face several attacks. The main attacks such as XML DoS are these listed in [
28,
29,
30]. Moreover, web services are increasingly used to develop Enterprise Service Oriented Architectures. These services are often deployed in the cloud. Indeed, Sharma et al. [
31] showed interest in deploying web services in the cloud. They pointed out that deploying web services in the cloud increases the availability and reliability of these services and reduces the messaging overhead. In fact, the resources, provided per demand in the cloud with great elasticity, satisfy the requirements of the service consumers. In conclusion, web services deployed in the cloud or used for building cloud applications inherit the vulnerabilities of the cloud platforms (
Table 1).
Moreover, few studies have been conducted to transpose the techniques and framework cited in the previous section to web services. Ficco and Rak [
29] and Sadegh and Azgomi [
32] presented attack tolerant Web service architectures based on diversity techniques presented above. These solutions protect essentially against XML DoS attacks. While these approaches are interesting, they do not address the specificity of services-based application deployed on cloud platforms. The solutions are attack-specific. Moreover, for this kind of application, it is necessary to integrate security in all the process steps, i.e., from modeling to deployment. We need a more efficient intrusion-tolerant mechanism.
2.4. Discussion
To cope with all these issues, it is necessary to consider information security as a permanent issue that needs to be managed in order to obtain attack-tolerant web services. In this work, we design an attack tolerant system that integrates intrusion detection methods, formal methods, and diverse defense strategies. By means of constant monitoring, we provide an attack-tolerant framework, so that potential security breaches within can be dynamically detected and appropriate mitigation measures can be activated on-line, thus reducing the effects of the detected attacks. As a result, we ensure a total attack tolerance attack tolerance for applications based on web services deployed in the cloud. Moreover, even though currently many companies continue to build their business applications using a Service Oriented Architecture (SOA) approach, micro service architectures will become the standard in the years to come. We believe our approach in this paper may suit new development paradigms such as micro services.
3. Risk-Based Monitoring Methodology
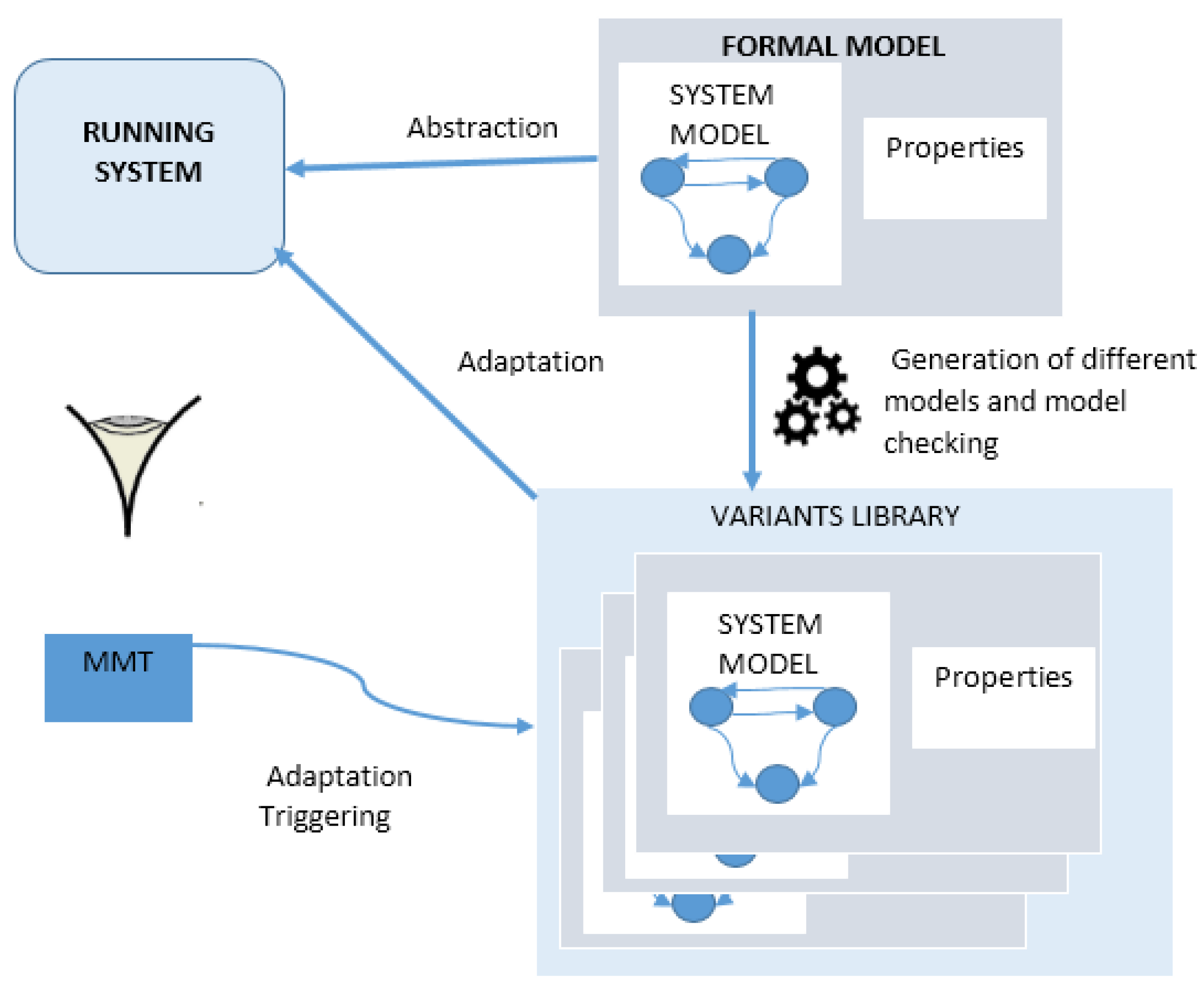
We leverage the risk management loop to build our risk-based monitoring loop, as depicted in
Figure 1. Indeed, this risk-based monitoring solution can be summarized by the following objectives:
Identification of system assets
Risk analysis to categorize threats that can exploit system vulnerabilities and result in different levels of risks
Threat modeling,
System monitoring to detect potential occurrences of attacks
Remediation strategies to apply corrective actions for mitigating the impact of the attack on the target system
Steps 1–5 are described in detail below.
3.1. Identifying Assets
Assets are defined as proprietary resources of value and necessary for its proper functioning. We distinguish business-level assets from system assets. In terms of business assets, we mainly find information (e.g., credit card numbers) and processes (e.g., transaction management or account administration). The business assets of the organization are often entirely managed through the information system. System assets include technical elements, such as hardware, business-critical applications, and their corresponding databases and networks, as well as the computer system environment, such as users or buildings. System assets can also represent some attributes or properties of the system such as the data integrity and availability. This is particularly true for cloud services consumers. As such, no company can afford to lose these assets.
3.2. Risk and Vulnerability Analysis
Risk is the possibility or likelihood that a threat will exploit a vulnerability resulting in a loss, unauthorized access, or deterioration of an asset. A threat is a potential occurrence that can be caused by anything or anyone and can result in an undesirable outcome. Natural occurrences, such as floods or earthquakes, accidental acts by an employee, or intentional attacks can all be threats to an organization. A vulnerability is any type of weakness that can be exploited. The weakness can be due to, for example, a flaw, limitation, or the absence of a security control.
Thus, after identifying valuable assets, it is necessary to perform vulnerability analysis. This type of analysis attempts to discover weaknesses in the systems with respect to potential threats. For example, in the context of access control, vulnerability analysis attempts to identify the strengths and weaknesses of the different access control mechanisms and the potential of a threat to exploit these weaknesses.
Common Attack Pattern Enumeration and Classification (CAPEC) [
33] provides a database of known patterns of attacks that have been employed to exploit known weaknesses in cyber systems. It represents attack patterns in three different ways: hierarchical representation via attack mechanisms or attack domains, representation according to the relations to the external factors, and representation according to the relations to the specific attributes. It can help to advance community understanding and enhance defenses. In the scope of our framework, for example, the known attack patterns in CAPEC may help to identify easily and quickly the weaknesses as well as their possible exploitation when analyzing the risk and vulnerability of target systems. Penetration Testing Execution Standard (PTES) [
34] defines a methodology based on penetration testing to check the robustness of a given system or application. There are many certifications designed for penetration testing: EC-Certified Ethical Hacker, GIAC Web Application Penetration Test (GWAPT), Certified Penetration Tester, etc. In the same way, the OWASP [
35] Benchmark Project attempts to establish a universal security benchmark by providing a suite of thousands of small Java programs containing security threats. In addition, our approach could be part of a global framework such as the NIST Framework for Improving Critical Infrastructure Cybersecurity (NIST Cybersecurity Framework or CSF) [
36]. Indeed, this framework leverages a risk-based approach and the core part of this framework is divided into five functions: identify, protect, detect, respond, and recover. These are similar to the five steps of our approach. In our research work, we do not consider these methodologies but we recognize that they are complementary to our approach, in particular to test tolerance to attacks.
3.3. Threats Modeling
The first step to avoid or repel the different threats that can affect an asset is to model them by identifying: affected modules/components, actions/behavior to trigger the threat, and potential objective of the threat. The formal model of a threat helps to understand the operation of the attacks and allows the creation of security mechanisms to protect, not only the assets, but also the software mechanisms that support them. Once the threats are modeled, we can identify the vulnerabilities that can affect the system and define monitoring and remediation mechanisms to minimize the damages that might occur. Again, consider the access control example. An access control process has two main steps: authentication and authorization. The latter usually comes after the former in a normal workflow. The authentication step is the more critical part of the access control process. The following description illustrates this assertion: Indeed, the attacker that may be inside the organization already knows or can easily find weak points in the organization’s defenses (inadequate security controls, failure of the principle of least privilege, software vulnerabilities, etc.). He can then attempt a privilege escalation to gain more permissions, to overcome an operating system’s permission, and to impersonate the root user so that he can create the fake user with root privilege and grant himself all the necessary privileges for further attacks or directly steal sensitive information with the administrator’s capabilities.
3.4. System Security Monitoring
The monitoring mechanism we propose allows constantly monitoring activities or events occurring in the network, in the applications, and in the systems. This information will be analyzed in near real-time to early detect any potential issue that may compromise the security or data privacy. If any anomalous situation is detected, the monitoring module will trigger a series of remediation mechanisms (countermeasures) oriented to notify, repel, or mitigate attacks and their effects.
3.5. Remediation
Once the risks of any system are established and the means of detection identified, it is essential to think about how to set up mechanisms that will allow to complete the risk-based monitoring loop i.e., to tolerate and mitigate the effects of the potential detected attacks. An efficient remediation technique should thwart as many attacks as possible. We explain below the proposed new approaches. They are based on diversity and meta-programming methods called software reflection.
3.5.1. Diversity-Based Attack Tolerance
Recall that diversity is the quality or state of having many different forms, types, ideas, etc. As our work targets attacks tolerance, we concentrate on the use of diversity as a mean for achieving it. At runtime, in the case an attack has been detected, the implementation of the running software is dynamically replaced by an implementation which is more robust. This idea is implemented through two complementary approaches. First, we present model-oriented diversity. This contribution is based on formal models. Then, we present the second approach, implementation-oriented diversity that reduces the shortcomings of the first approach and extends it. This second approach leverages Software Product lines (SPL) for devising a fine-grained attack tolerance system.
Model-based diversity for attack tolerance. It consists in investigating attack-tolerance at the design and specification phase. This model-based approach tries to obtain a balance between security and a good quality of experience. One can argue that the more secure model has to be implemented first. In that case, the user experience is lowered. For many applications, it is clear that the choice is not the more constrained model [
37]. The centerpiece of that approach is the usage of monitoring methods and formal models:
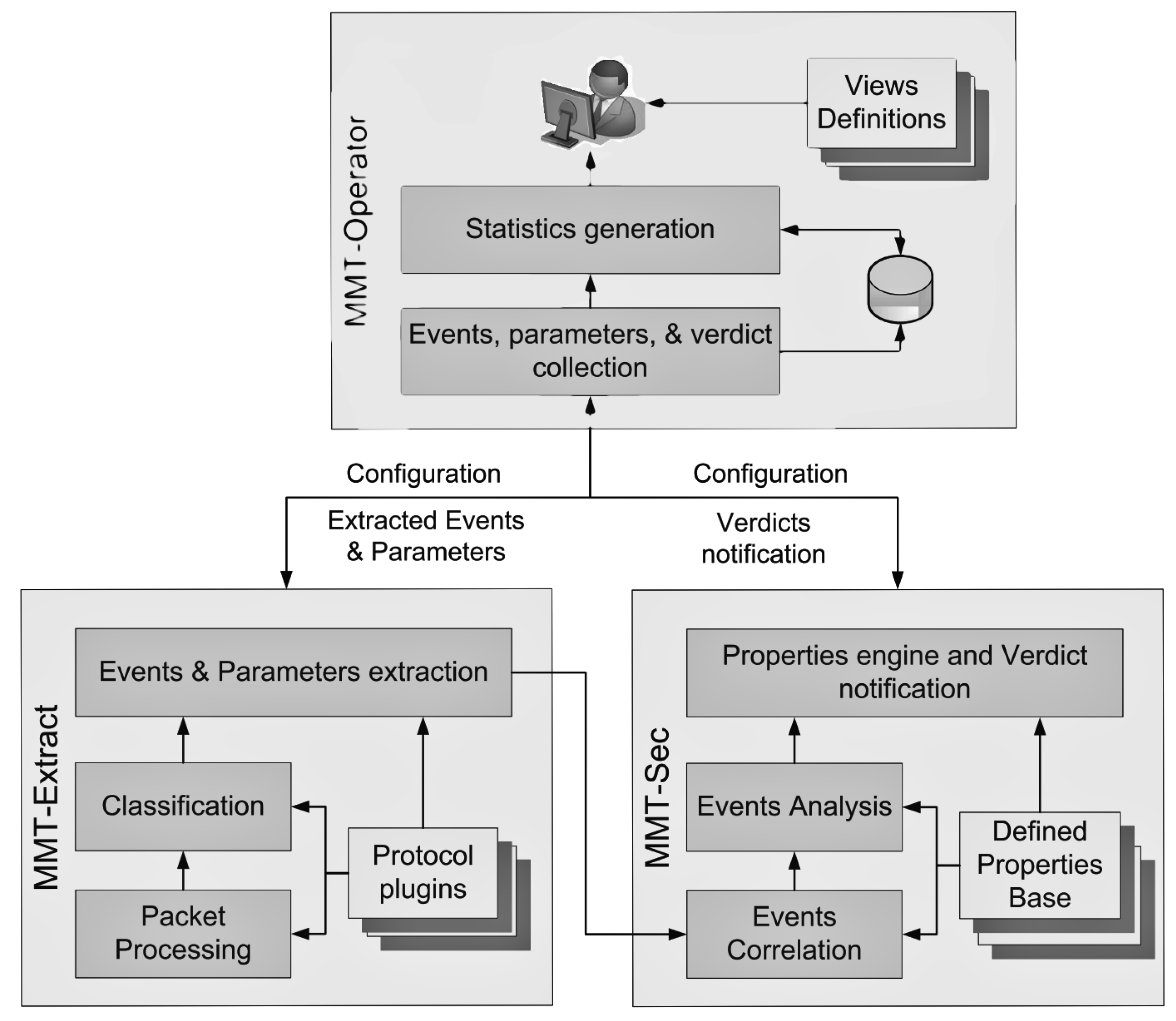
A running system is monitored to observe its run-time behavior with our Monitoring Tool (MMT). A formal model of the module that is susceptible to be suffering an attack is designed. This model is expressed as a Finite State Machine (FSM). The monitored values are abstracted and related to security properties we defined. These properties are written in linear temporal logic (LTL).
From this first model, other modified models are obtained. They have the same functionality but can have more mechanisms to impeach attacks; these models are more secure and robust.
Associated to each model, implementations are produced.
Violations of the properties described are thus detected by the monitoring tool. This detection triggers the adaptation process. The model is replaced with another model that is more robust and the implementation as well.
This approach is illustrated in
Figure 2. The principal difficulty of this method lies in the derivation of models. How should the models and implementations from the first model and implementation be derived?
Implementation-based diversity for attack tolerance. This approach aims at extending and solving the issues raised by the former approach by leveraging diversity [
38]. The idea is still the same as in the previous approach but here there is only one model and several implementations. To this end, we base our work on the concept of diversification. The more diversification there is, the more security is ensured. The model chosen is Feature Model (FM). A FM is used in the area of software product lines to model a particular product line. It specifies the common as well as the variable features of a family. A variable feature is called variability. Three patterns of variability were used in the FM: encoding style (document and RPC), encoding (literal and encoded) types, and languages (C and C ++). After implementing the WSDL of the diversified service, the skeletons of these services are generated. Then, the code of the latter are obfuscated by adding instructions that modify their normal control flow, just to have a source level diversification. Finally, a new layer of diversification at the binary level is added. This ensures that the implementations are not vulnerable to the same attacks leveraging the computation flow (code reuse attack). The services are then highly diversified and redundant. There are in total three levels of diversification.
To ensure the continuous availability of our system, it is configured in two ways: normal mode and attack mode. In normal mode, time is divided into
epochs. In each
epoch, only a unique variant is chosen. When the
epoch of time elapses, another implementation is deployed to ensure continuity of the service. In abnormal mode, it is the case where the defense mechanism has successfully detected an attack. The system reacts by switching to another more resistant implementation before even the
epoch has elapsed. The main design of the solution is depicted in
Figure 3.
Let us take another example of an organization. The asset in this case is the intellectual property of the company or the organization. This company has deployed an information system through which employees can communicate and exchange information. This information system may leverage web services. This information system is also connected to the Internet to allow the company to communicate with the outside. We assume that there is an unsuspecting employee in this company. This employee receives a malicious email containing malicious content and clicks on it. The threat to the company and its information system is the malicious email (sent by the hacker). The naive employee is therefore a vulnerability for the system. The hacker could therefore take advantage of this vulnerability. This vulnerability, once successful, may pose a risk for the company and its asset.
If the company anticipated this risk by ensuring remediation by construction that consists in diversifying the different parts of its information system and set up monitoring points at the level of the network and the applications, the risk is then mitigated, the asset is protected, and the continuity of the service is ensured.
3.5.2. Reflection-Based Attack Tolerance
The aim of this technique is to approach attack tolerance in a manner different from the methods mentioned above [
39]. In fact, the latter has the ability to detect attacks coming from the outside (DDoS, Brute-force, etc.). In addition, their tolerance features are designed before the deployment of the application(e.g., diversification of web services). That is why we consider finding a solution that would tolerate internal attacks. Meta-programming techniques in particular software reflection is investigated. Reflection is the possibility for a program of monitoring and/or modifying its behavior dynamically.
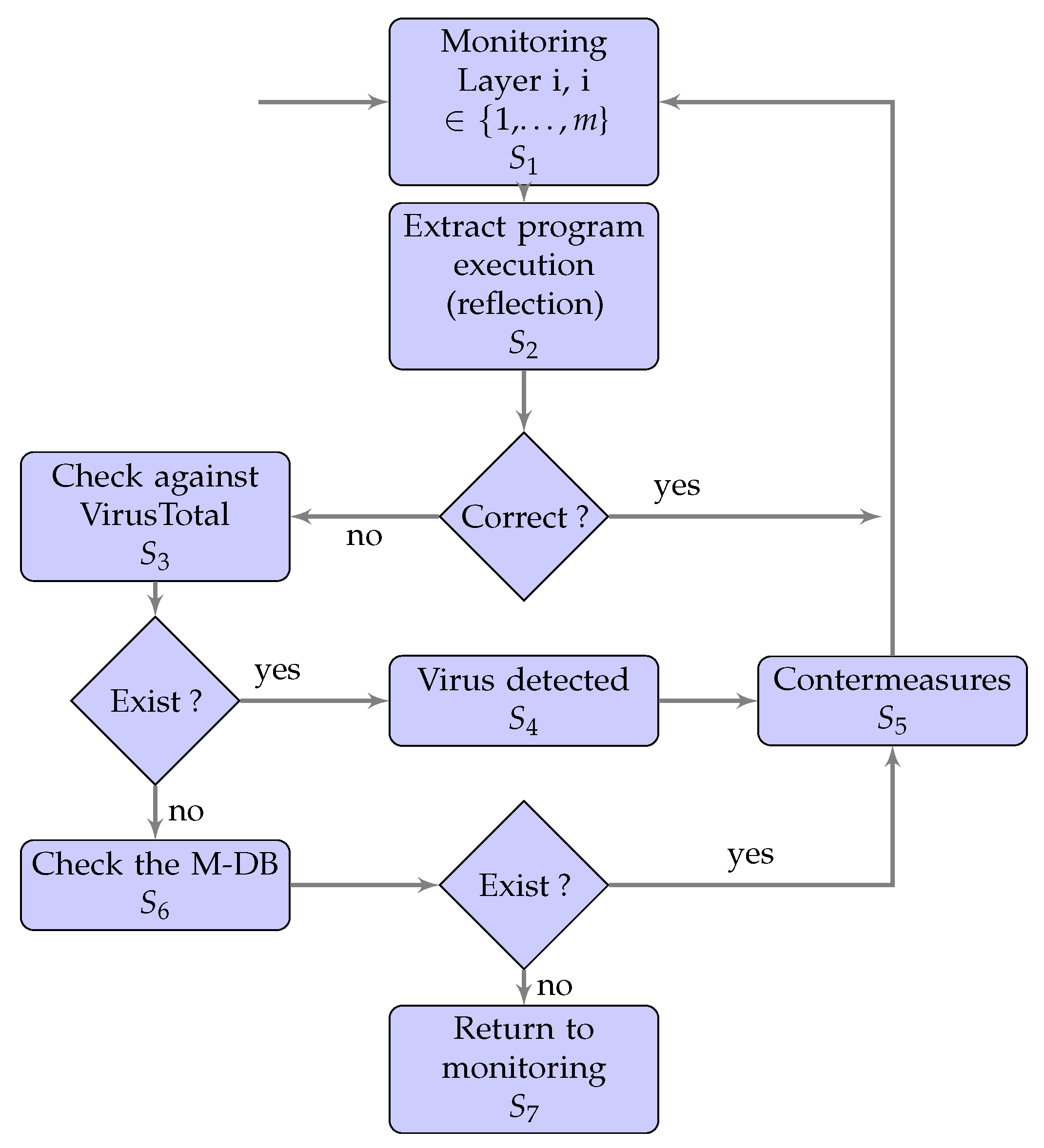
The basic idea is therefore the following. It is assumed that the software of the client is located in a safe environment. Some potential attacks that can take place are internal ones, i.e. coming from internal hackers. The goal of the intruder is to usurp the actions, i.e., to modify the methods of the API of the platform. By reflection, all the hash of the source code of any methods of the API are processed (
Figure 4). Any deviation at runtime of that hash value means the presence of a misbehavior. Such misbehavior could be an insider attack or a virus attack. Information such as date, hour, operation, hash, and host are stored in the log file. Any request has then two traces in the logs: outbound (request) and inbound (response). Let us describe the situation when an attack occurs, i.e., someone has modified the API and overridden one or several methods. First, this is the case where we see some information of the methods but there is no Hash. It is also possible to get only one hash for the outbound operation and nothing for the inbound operation. If there is an attack, the hashes of both Outbound and Inbound could not correspond in the log files. Finally, we can get some inconsistencies in the logs: timestamps incoherence, method inconsistencies (answer before request), or combination of inconsistencies.
For the monitoring part of the framework, the programs are checked at runtime using reflection, as mentioned above. For detecting attacks, logs located on the two endpoints, the premises and server, are leveraged. We developed a new plugin for this kind of detection in the monitoring tool MMT. Some security policies (rules) are then applied. If the threat detected is a modification of one of the methods of the API, the system reacts using reflection by replacing this method with the original method in the API. If the attack is not known in the vulnerability DB, the system checks its own DB (M-DB). If the attack exists, countermeasures are launched, else the hash is stored in the M-DB.
6. Conclusions and Perspectives
In this paper, we investigate the attack tolerance or resilience issue. We show that, to better tolerate and limit the impact of these attacks, the monitoring of the information systems is of paramount importance for any organization. However, the monitoring and detection of attacks require an awareness of the risks that the system might be exposed to. As such, we propose a risk-based monitoring approach. This methodology involves the following aspects: (i) assets identification to define what is necessary to protect; (ii) threats and vulnerability analysis to evaluate the potential flaws the system may suffer; (iii) risk analysis to categorize the threats that can exploit the system vulnerabilities; (iv) system monitoring to detect potential occurrences of attacks; and (v) remediation strategies to repel or mitigate the impact of the attacks. Leveraging this methodology, we develop a new attack tolerance framework based on formal monitoring techniques as well as diversification and reflection software techniques. We instantiate the risk-based methodology for services-based applications deployed in the cloud and propose an offline and online attack tolerance framework for web services-based application in the cloud. With this aim, we first express any application deployed in the cloud as a choreography of services, which must be continuously monitored and tested. Then, we extend a formal framework for choreography testing by incorporating the methods for detecting and mitigating attacks presented in the previous sections. Adding mechanisms of detection and reaction on the fly to these applications ensures optimal attack tolerance.
As such, the risk-based monitoring approach is compliant with cloud asset management strategies of companies. In fact, this approach delivers visibility, control of all the assets of a cloud, and it is a crucial first step towards a more secure cloud.
Now, let us discuss improvements and open directions. We define in this paper attack tolerance as the ability of a system to continue to function properly with minimal degradation of performance, despite intrusions. The aim is to detect the known and unknown attacks and if not possible to reduce their impact on the system. Although we obtained satisfactory results, we believe that we can improve the tolerance to attacks if we can somehow anticipate or predict these attacks. Thus, in addition to detection and remediation, it would be necessary to be able to predict and anticipate future attacks. We think that the following two axes would be interesting to investigate.
Diagnosticability and predictability [
61]. Diagnosis consists in designing and implementing algorithms for verifying the formal properties of the system, ensuring that a model, which is known in advance of observable events, allows the detection and discrimination of a set of possible failures. Similarly, predictability is the ability to predict a future occurrence of a fault using the observable events preceding. We think that, if we can predict the occurrence of a fault, it would be interesting to prevent it from taking place and therefore to tolerate attacks effectively. However, an important step for using diagnosticability and predictability for attack tolerance will therefore be the formalization of faults that can occur from attacks.
Big data and machine learning. Recently, machine learning has emerged as a means to enhance security [
62]. The authors reviewed the literature of machine learning (ML) and data mining (DM) methods for intrusion detection. This study evaluated the different existing algorithms. They pointed out that the most effective methods for cyber detection must be established and adapted to the specificity of the attacks. Furthermore, adding big data to machine learning can improve cyber security [
63]. The introduction of Big Data processing led to a new era in the design and development of large-scale data processing systems. The idea is that data in raw format make it possible to create statistical baselines to identify normality. Subsequently, it is possible to instantly determine when the data deviate from this standard. These historical data also make it possible to create predictive and statistical models. While some supervised and unsupervised learning algorithms are already available for big data, there is much room for improvement. It has be recognized that the false-positive rate of machine learning algorithms is too high and the alerts generated are not always sufficiently interpretable to enable their exploitation. In summary, there is a research avenue for the application of such techniques for attack tolerance [
63].
The result of using predictability and/or ML and big data in conjunction with our attack tolerance methods would be the design and the implementation of a framework for software systems that is attack tolerant in the sense that is has the possibility to continue to deliver their services even after a successful attack and is able to recover quickly and learn from the past.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}