A Machine Learning Based Two-Stage Wi-Fi Network Intrusion Detection System †

 ,
, 


Abstract
1. Introduction
- A two-stage ML-based Wi-Fi network intrusion detection system (WNIDS) is proposed to enhance the detection accuracy using Aegean Wi-Fi Intrusion Dataset (AWID), a publicly available labeled dataset created from real Wi-Fi network traffic traces.
- A significant performance improvement in computational time and detection accuracy of an ML-based IDS is achieved by proper data analysis and selection of features that help understanding the relevant features for the classification task and filtering the noisy features from ML model development. We perform a detailed study of the AWID features and apply various feature selection techniques to improve its classification and computational performance.
- Having better understanding of the selected features allows efficient implementation of the countermeasures against the intrusions; Explainable Artificial Intelligence (XAI) has been used for this purpose.
2. Related Works
3. Overview of AWID and Initial Data Preparation
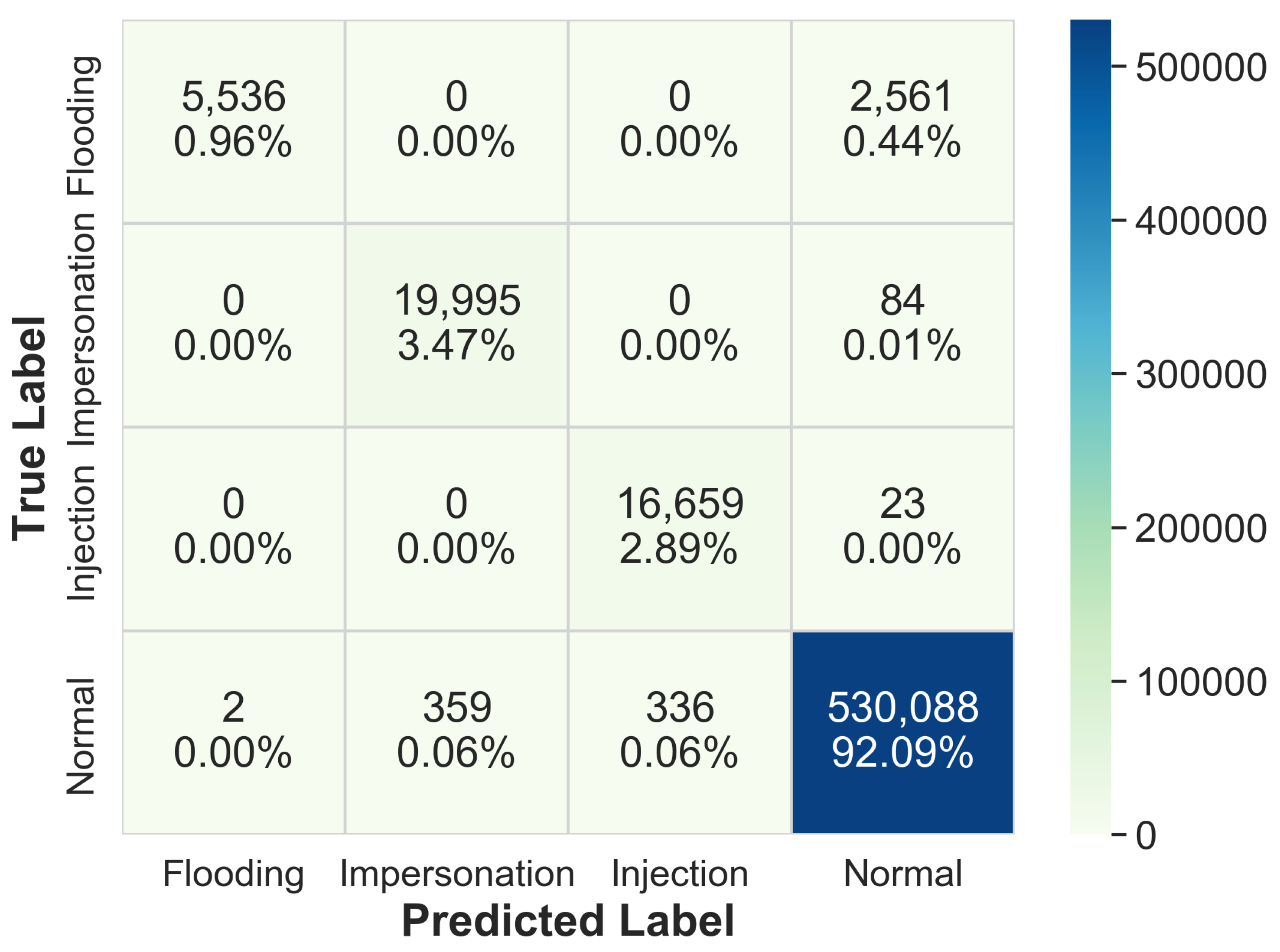
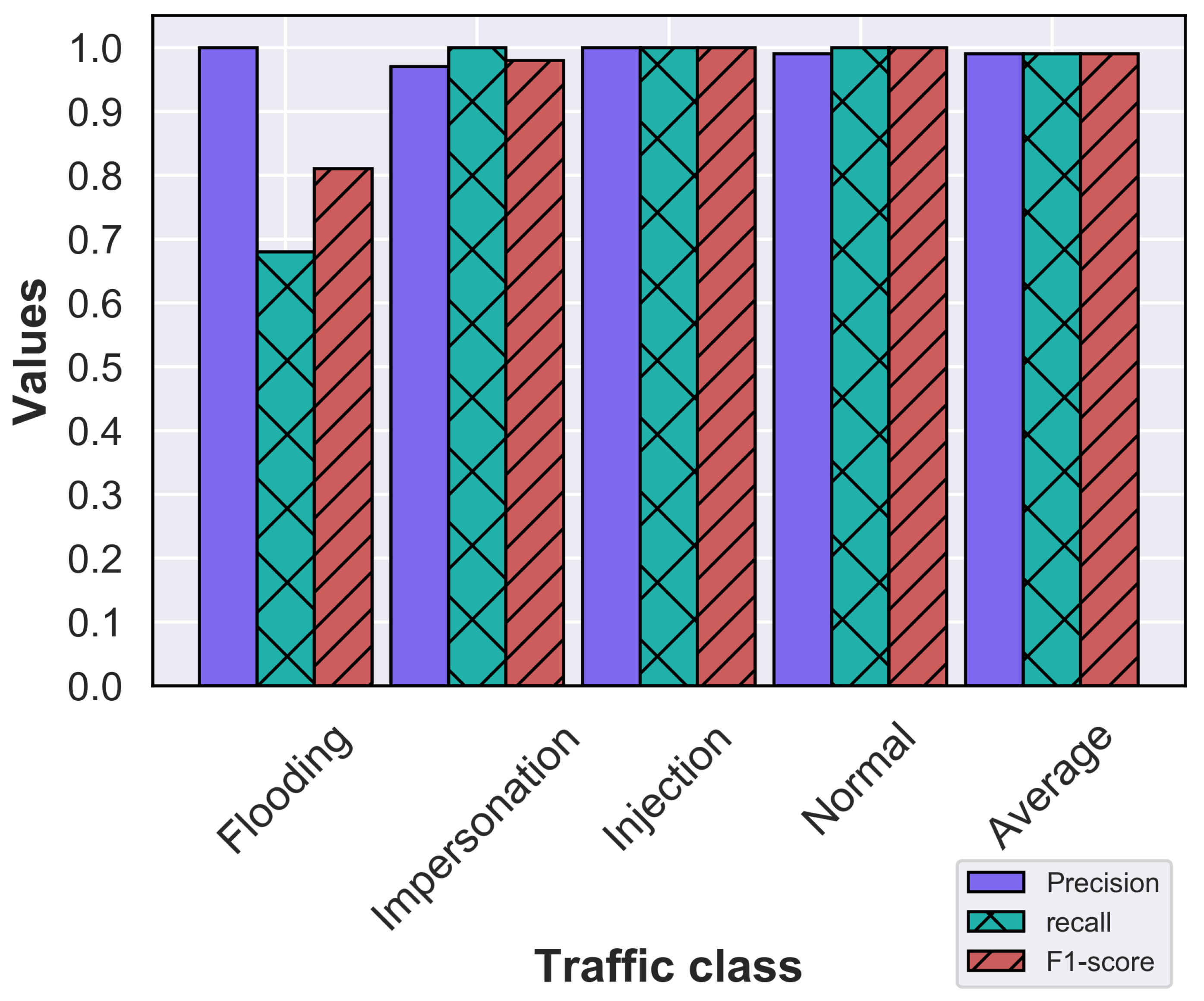
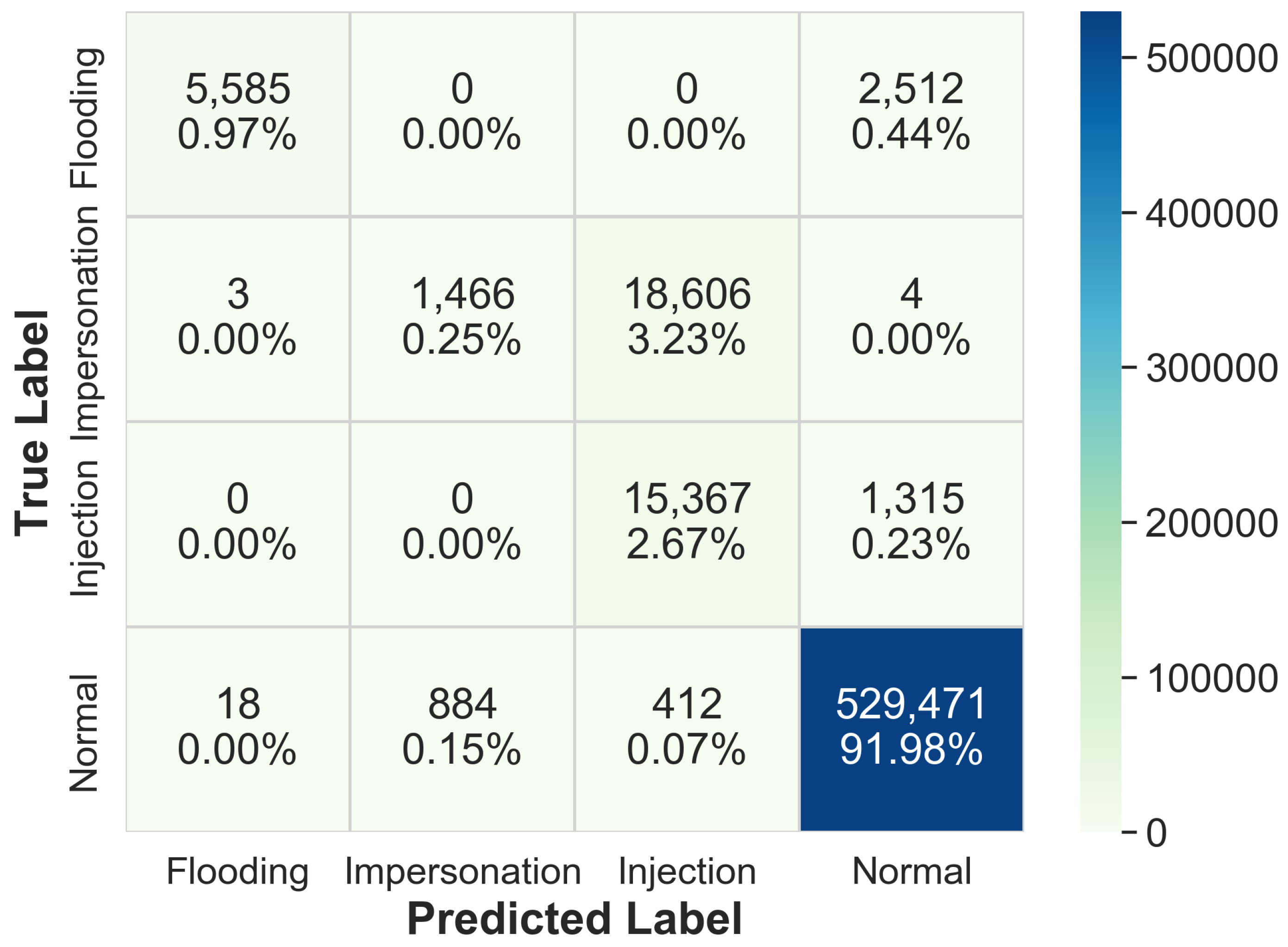
4. Two-Stage WNIDS Implementation and Experimental Results
| Algorithm 1: Pseudocode for Two-Stage WNIDS |
 |
4.1. Feature Selection
- Recursive Feature Elimination (RFE): In this technique, we start with the full list of features and then recursively remove the weakest feature up to the point until the performance is not degraded. The technique tends to eliminate dependencies and collinearity that may exist among the features [27].
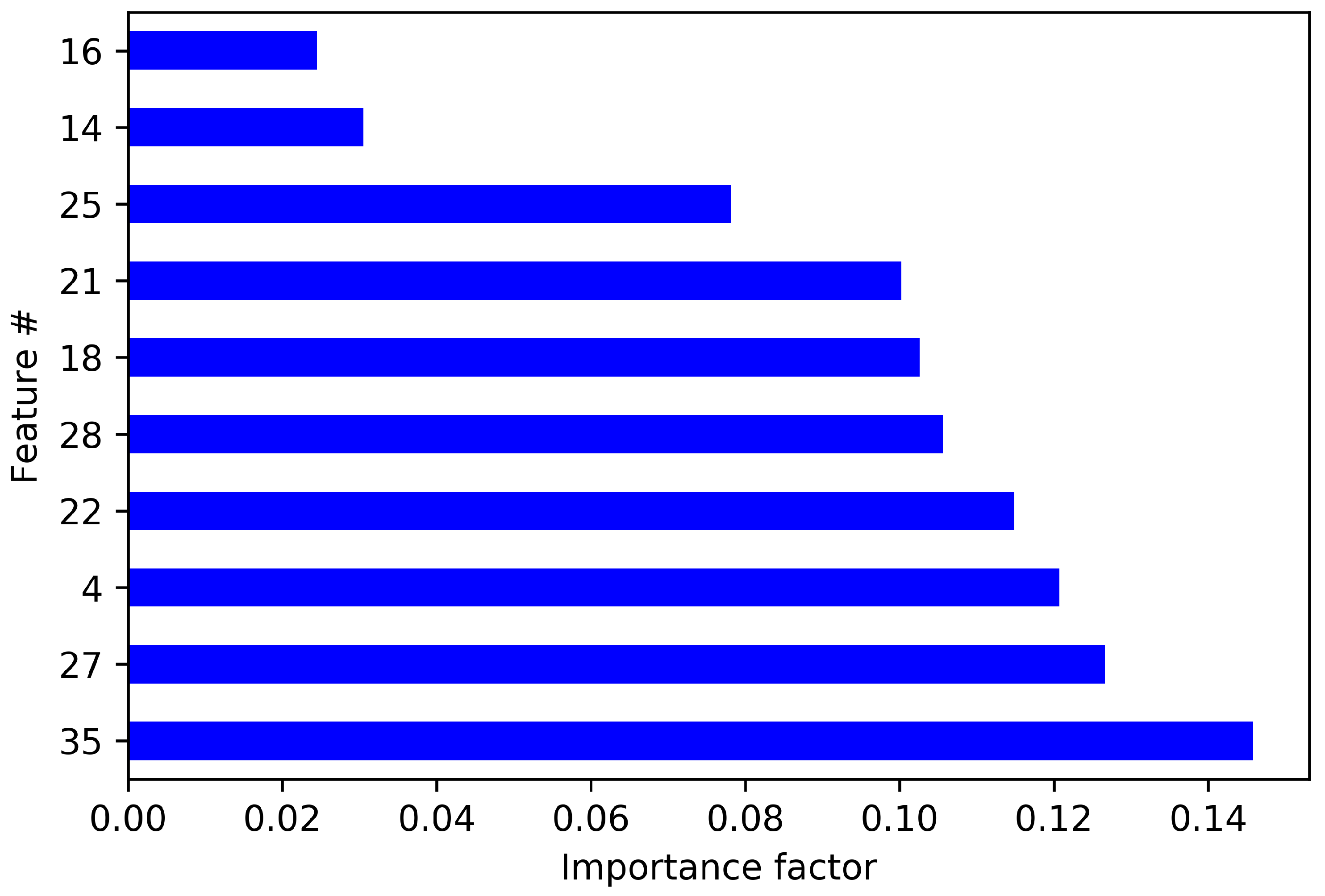
- Feature Importance: Relative importance of each feature for the ML model prediction is computed and ranking is given accordingly. Features are selected based on this ranking [28].
- Chi-Square Test: Chi-square test is used in statistics to test the independence of two events. In the feature selection task, the goal is to select the features that are highly dependent on the prediction. The higher the chi-square value (or lower p-value), the more the feature is dependent on the response and suitable candidate for ML model development [29].
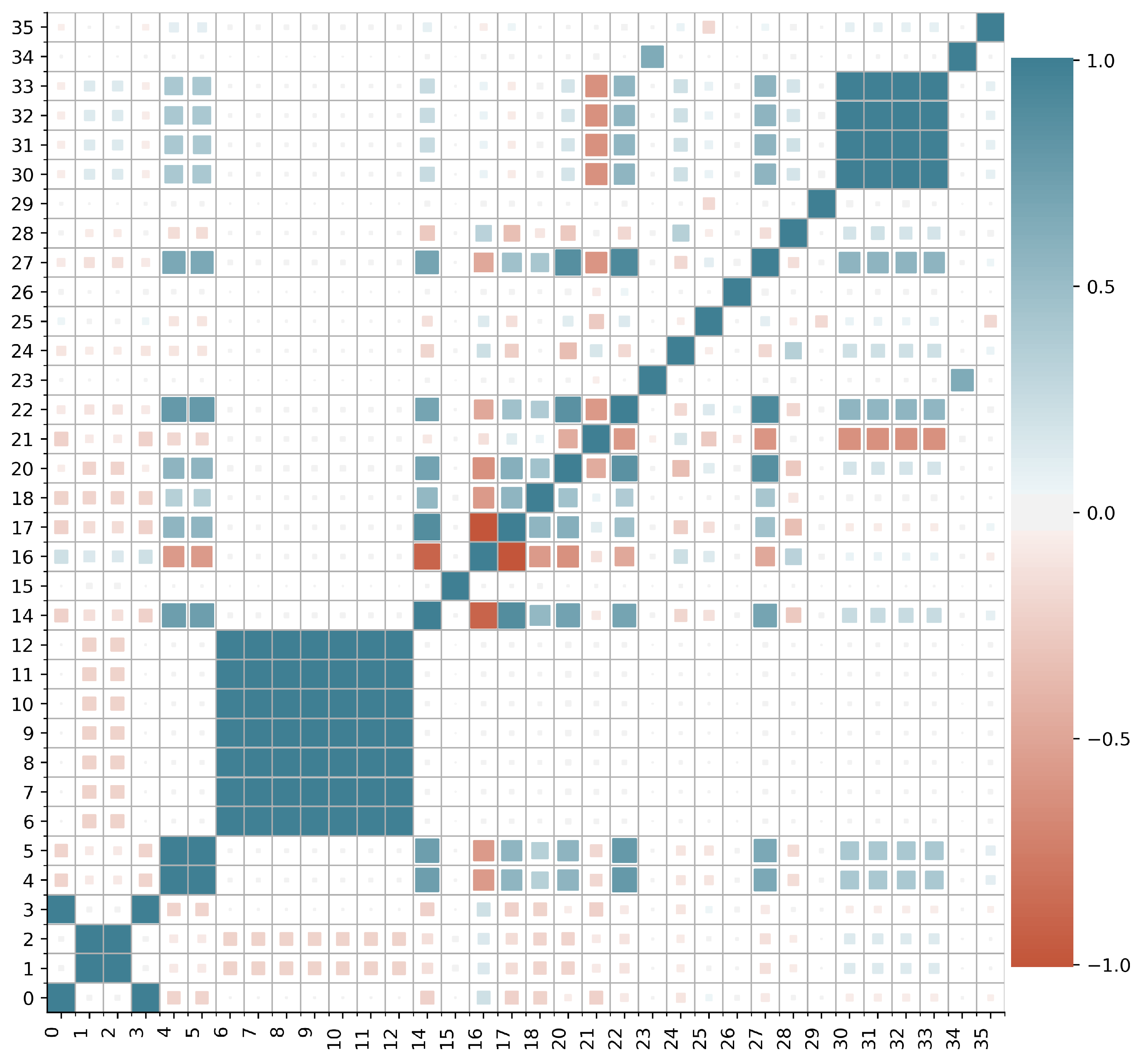
- Feature Correlation: It describes how features are related to each other. If we determine a set of features highly related to each other, i.e., features follow a correlated pattern for their values in the set, then the set can be replaced by only one of its features [30].
- Particle Swarm Optimization (PSO): Feature selection is a computationally expensive task for those ML problems in which the datasets have a large number of features. Optimization based feature selection techniques help with finding an optimal set of features within a reasonable time in such cases. Particle swarm optimization (PSO) is a nature inspired swarm intelligence based optimization algorithm modeled from the movement of a flock of birds [31]. PSO based feature selection techniques have been studied and found to be promising compared to other optimization approaches [32,33]. For this reason, we implemented a PSO-based feature selection technique by adopting the approach discussed in [33]. In this approach, each particle is expressed in a d-dimensional space, where d is the number of features in the dataset. For the implementation, we used Pyswarms, a Python library for PSO [34].
4.2. ML Model Development for Two Stages
- Bootstrap Aggregation (Bagging): It is an ensemble method that combines predictions from multiple ML model to make better predictions than the individual models. In bagging, random subsets of data points are assigned to individual ML models during training. When a new data point is evaluated for prediction, the value assigned to it is the most common value predicted by the individuals’ models [35].
- Random Forest: It is an improved version of decision tree classifier, where several decision trees are constructed during the training time, and each of them uses a random subset of features from the full features set of features during model development. The random samples of features help to guarantee a low variance in the results [36].
- Extra Trees: It is also known as Extremely Randomized Trees, and the features and sub-datasets are selected at random, which makes it different from Random Forest. The splits are randomly chosen for each feature, demanding less computational effort compared to Random Forest [37].
- Extreme Gradient Boosting (XGBoost): It is an efficient tool implemented based on a Gradient Boosting classifier. Gradient Boosting shows effective performance in the form of an ensemble of weak prediction models. XGBoost offers the same reliability as Gradient Boosting, but with less computational expenses [38].
- Naive Bayes (NB): It is based on Bayes’ Theorem with a strong assumption of features independence and selects the best hypothesis for a given data based on the probabilities. It uses Gaussian distribution to extend its application for real-valued attributes [39].
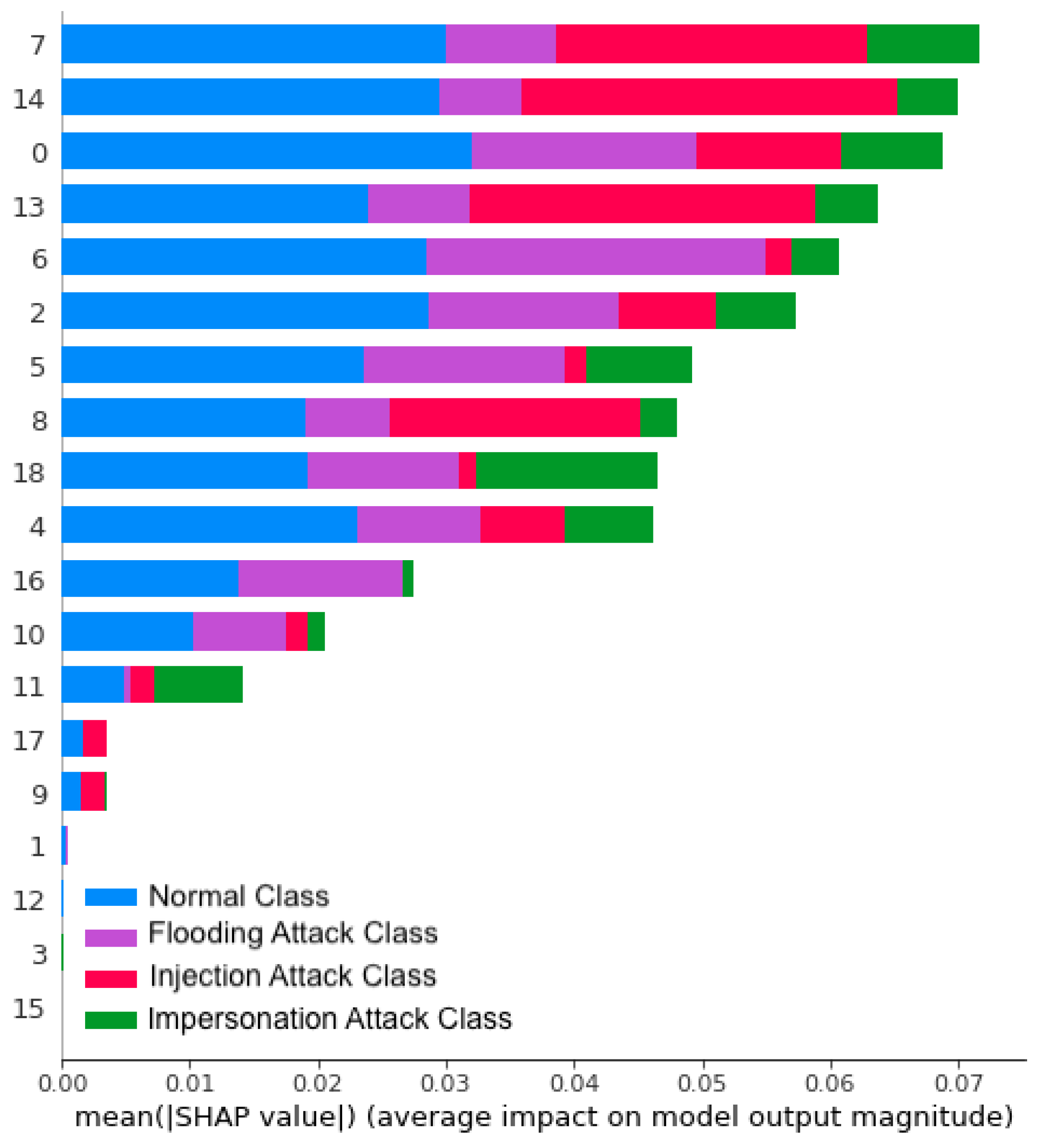
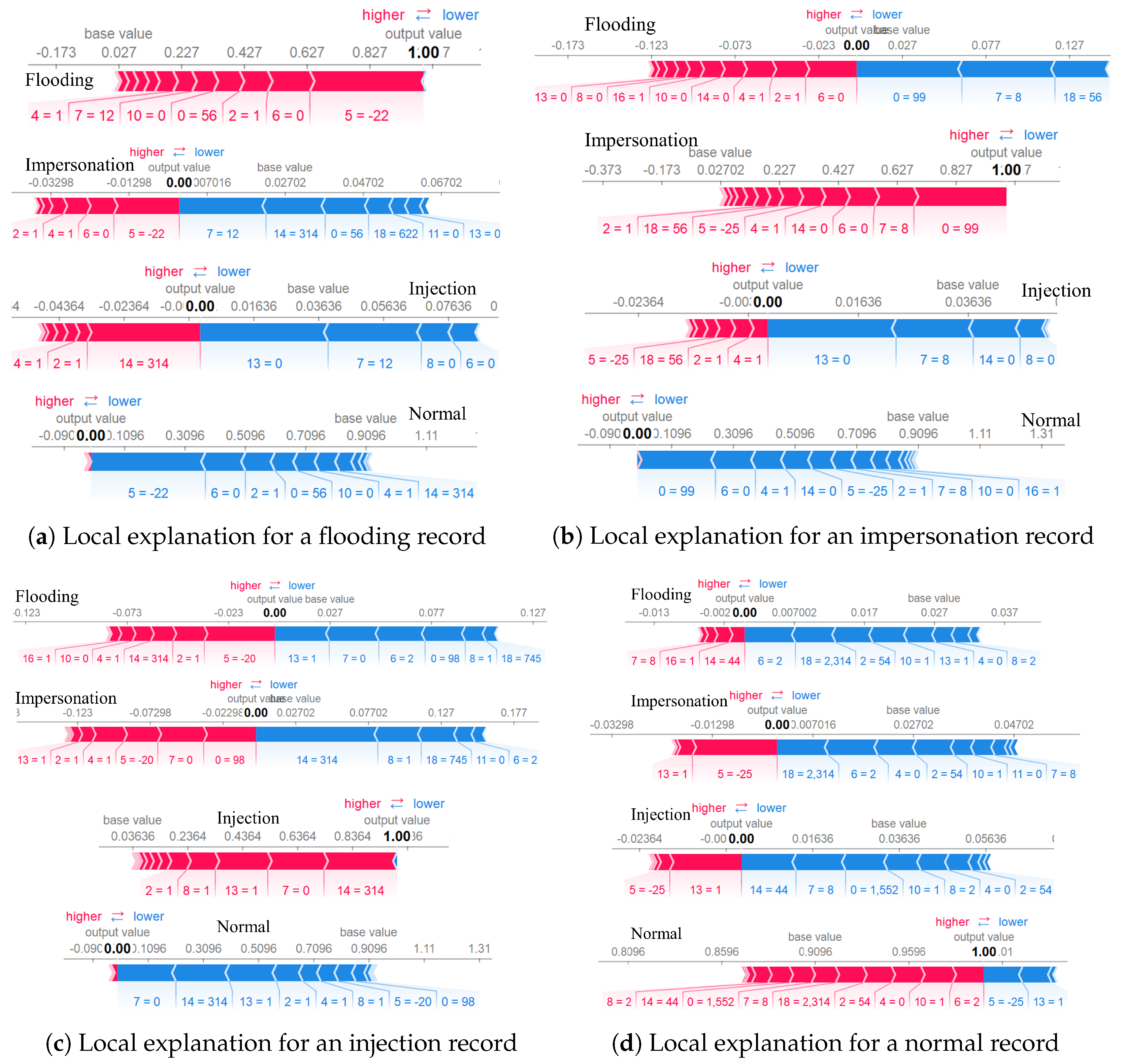
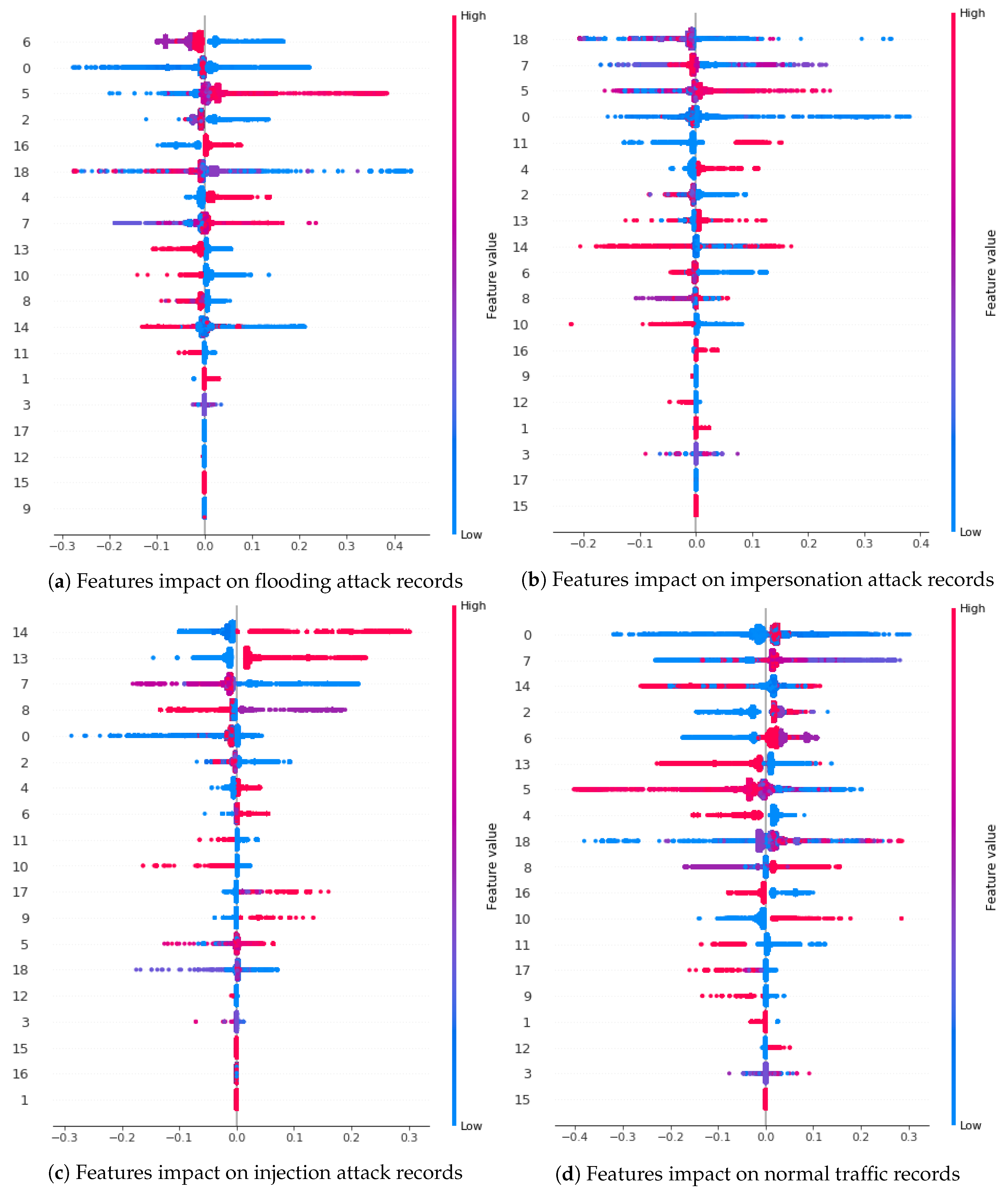
5. Explainable Artificial Intelligence (XAI)
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- O’Dea, S. Number of Smartphone Users Worldwide from 2016 to 2021. 2020. Available online: https://www.statista.com/statistics/330695/number-of-smartphone-users-worldwide/ (accessed on 10 September 2020).
- Cisco. Cisco VNI Global—2021 Forecast Highlights. Available online: https://www.cisco.com/c/dam/m/en_us/solutions/service-provider/vni-forecast-highlights/pdf/Global_2021_Forecast_Highlights.pdf (accessed on 10 September 2020).
- Biggest Wi-Fi Hacks of Recent Times—Lessons Learnt? Available online: https://www.titanhq.com/biggest-wi-fi-hacks-of-2016-lessons-learnt/ (accessed on 10 September 2020).
- Vanhoef, M.; Piessens, F. Key Reinstallation Attacks: Forcing Nonce Reuse in WPA2. In Proceedings of the 24th ACM Conference on Computer and Communications Security (CCS), Dallas, TX, USA, 30 October–3 November 2017. [Google Scholar]
- Cermak, M.; Svorencik, S.; Lipovsky, R. KR00K-CVE-2019-15126, Serious Vulnerability Deep Inside Your Wi-Fi Encryption. 2020. Available online: https://www.welivesecurity.com/wp-content/uploads/2020/02/ESET_Kr00k.pdf (accessed on 10 September 2020).
- Vaca, F.D.; Niyaz, Q. An ensemble learning based wi-fi network intrusion detection system (wnids). In Proceedings of the 2018 IEEE 17th International Symposium on Network Computing and Applications (NCA), Cambridge, MA, USA, 1–3 November 2018; pp. 1–5. [Google Scholar]
- Kolias, C.; Kambourakis, G.; Stavrou, A.; Gritzalis, S. Intrusion detection in 802.11 networks: Empirical evaluation of threats and a public dataset. IEEE Commun. Surv. Tutor. 2015, 18, 184–208. [Google Scholar] [CrossRef]
- Aminanto, M.E.; Tanuwidjaja, H.; Yoo, P.D.; Kim, K. Weighted feature selection techniques for detecting impersonation attack in Wi-Fi networks. In Proceedings of the Symposium on Cryptography and Information Security (SCIS), Naha, Japan, 24–27 January 2017; pp. 1–8. [Google Scholar]
- Thanthrige, U.S.K.P.M.; Samarabandu, J.; Wang, X. Machine learning techniques for intrusion detection on public dataset. In Proceedings of the 2016 IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), Vancouver, BC, Canada, 15–18 May 2016; pp. 1–4. [Google Scholar]
- Kaleem, D.; Ferens, K. A cognitive multi-agent model to detect malicious threats. In Proceedings of the 2017 International Conference on Applied Cognitive Computing (ACC’17), Las Vegas, NV, USA, 17–20 July 2017. [Google Scholar]
- Thing, V.L. IEEE 802.11 network anomaly detection and attack classification: A deep learning approach. In Proceedings of the 2017 IEEE Wireless Communications and Networking Conference (WCNC), San Francisco, CA, USA, 19–22 March 2017; pp. 1–6. [Google Scholar]
- Ran, J.; Ji, Y.; Tang, B. A Semi-Supervised learning approach to IEEE 802.11 network anomaly detection. In Proceedings of the 2019 IEEE 89th Vehicular Technology Conference (VTC 2019-Spring), Kuala Lumpur, Malaysia, 28 April–1 May 2019; pp. 1–5. [Google Scholar]
- Aminanto, M.E.; Choi, R.; Tanuwidjaja, H.C.; Yoo, P.D.; Kim, K. Deep abstraction and weighted feature selection for Wi-Fi impersonation detection. IEEE Trans. Inf. Forensics Secur. 2017, 13, 621–636. [Google Scholar] [CrossRef]
- Lee, S.J.; Yoo, P.D.; Asyhari, A.T.; Jhi, Y.; Chermak, L.; Yeun, C.Y.; Taha, K. IMPACT: Impersonation attack detection via edge computing using deep autoencoder and feature abstraction. IEEE Access 2020, 8, 65520–65529. [Google Scholar] [CrossRef]
- Kim, K.; Aminanto, M.E.; Tanuwidjaja, H.C. Deep Feature Learning. In Network Intrusion Detection using Deep Learning. SpringerBriefs on Cyber Security Systems and Networks; Springer: Singapore, 2018; pp. 47–68. [Google Scholar]
- Wang, S.; Li, B.; Yang, M.; Yan, Z. Intrusion Detection for WiFi Network: A Deep Learning Approach; Wireless Internet. WICON 2018. Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering; Chen, J.L., Pang, A.C., Deng, D.J., Lin, C.C., Eds.; Springer: Cham, Switzerland, 2018; pp. 95–104. [Google Scholar]
- Kasongo, S.M.; Sun, Y. A deep learning method with wrapper based feature extraction for wireless intrusion detection system. Comput. Secur. 2020, 92, 101752. [Google Scholar] [CrossRef]
- Zhou, Y.; Cheng, G.; Jiang, S.; Dai, M. Building an efficient intrusion detection system based on feature selection and ensemble classifier. Comput. Netw. 2020, 174, 107247. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive data set for network intrusion detection systems (UNSW-NB15 network data set). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar]
- Tavallaee, M. An Adaptive Hybrid Intrusion Detection System. Ph.D. Thesis, Faculty of Computer Science, University of New Brunswick, Fredericton, NB, Canada, 2011. [Google Scholar]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A detailed analysis of the KDD CUP 99 data set. In Proceedings of the 2009 IEEE Symposium on Computational Intelligence for Security and Defense Applications, Ottawa, ON, Canada, 8–10 July 2009; pp. 1–6. [Google Scholar]
- Ullah, I.; Mahmoud, Q.H. A Two-Level Flow-Based Anomalous Activity Detection System for IoT Networks. Electronics 2020, 9, 530. [Google Scholar] [CrossRef]
- Ullah, I.; Mahmoud, Q.H. IoT-Botnet Dataset 2020. 2020. Available online: https://sites.google.com/view/iotbotnetdatset (accessed on 10 September 2020).
- Marino, D.L.; Wickramasinghe, C.S.; Manic, M. An adversarial approach for explainable ai in intrusion detection systems. In Proceedings of the IECON 2018-44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 3237–3243. [Google Scholar]
- Wang, M.; Zheng, K.; Yang, Y.; Wang, X. An Explainable Machine Learning Framework for Intrusion Detection Systems. IEEE Access 2020, 8, 73127–73141. [Google Scholar] [CrossRef]
- Brownlee, J. Feature Selection in Python with Scikit-Learn. 2014. Available online: https://machinelearningmastery.com/feature-selection-in-python-with-scikit-learn/ (accessed on 10 September 2020).
- Recursive Feature Elimination. Available online: https://scikit-learn.org/stable/modules/feature_selection.html (accessed on 10 September 2020).
- Feature Importances with Forests of Trees. Available online: https://scikit-learn.org/stable/auto_examples/ensemble/plot_forest_importances.html (accessed on 10 September 2020).
- Gajawada, S.K. Chi-Square Test for Feature Selection in Machine Learning. 2014. Available online: https://towardsdatascience.com/chi-square-test-for-feature-selection-in-machine-learning-206b1f0b8223 (accessed on 10 September 2020).
- Shaikh, R. Feature Selection Techniques in Machine Learning with Python. 2018. Available online: https://towardsdatascience.com/feature-selection-techniques-in-machine-learning-with-python-f24e7da3f36e (accessed on 10 September 2020).
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar]
- Xue, B.; Zhang, M.; Browne, W.N. New fitness functions in binary particle swarm optimisation for feature selection. In Proceedings of the 2012 IEEE Congress on Evolutionary Computation, Brisbane, Australia, 10–15 June 2012; pp. 1–8. [Google Scholar]
- Vieira, S.M.; Mendonça, L.F.; Farinha, G.J.; Sousa, J.M. Modified binary PSO for feature selection using SVM applied to mortality prediction of septic patients. Appl. Soft Comput. 2013, 13, 3494–3504. [Google Scholar] [CrossRef]
- Miranda, L. PySwarms: A Particle Swarm Optimization Library in Python. 2017. Available online: https://ljvmiranda921.github.io/projects/2017/08/11/pyswarms/ (accessed on 10 September 2020).
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Ceballos, F. An Intuitive Explanation of Random Forest and Extra Trees Classifiers. 2019. Available online: https://towardsdatascience.com/an-intuitive-explanation-of-random-forest-and-extra-trees-classifiers-8507ac21d54b (accessed on 10 September 2020).
- Introduction to Boosted Trees. Available online: https://xgboost.readthedocs.io/en/latest/tutorials/model.html (accessed on 10 September 2020).
- Brownlee, J. Naive Bayes for Machine Learning. 2016. Available online: https://machinelearningmastery.com/naive-bayes-for-machine-learning/ (accessed on 10 September 2020).
- Schmelzer, R. Understanding Explainable AI. 2019. Available online: https://www.forbes.com/sites/cognitiveworld/2019/07/23/understanding-explainable-ai/#74bdb29d7c9e (accessed on 10 September 2020).
- Schmelzer, R. Shap. 2018. Available online: https://shap.readthedocs.io/ (accessed on 10 September 2020).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | ML Algorithm | Features | Classes | Accuracy |
|---|---|---|---|---|
| Kim [15] | SAE & K-means | 50 | 2 | 94.81% |
| Lee [14] | SAE & SVM | 5 | 2 | 98.22% |
| Vaca [6] | Random Forest | 36 | 2 | 99.11% |
| Ran [12] | Ladder Network | 95 | 2 | 99.28% |
| Kaleem [10] | ANN | 7 | 2 | 99.30% |
| Sydney [17] | FFDNN | 26 | 2 | 99.66% |
| Aminanto [8] | ANN | 11 | 2 | 99.86% |
| Aminanto [13] | SVM | 21 | 2 | 99.97% |
| Wang [16] | DNN | 71 | 4 | 92.49% |
| Udaya [9] | Random Tree | 41 | 4 | 95.12% |
| Vaca [6] | Random Forest | 36 | 4 | 95.88% |
| Kolias [7] | J48 | 20 | 4 | 96.20% |
| Ran [12] | Ladder Network | 95 | 4 | 98.54% |
| Thing [11] | Deep Learning | 154 | 4 | 98.67% |
| Zhou [18] | CSF-BA-Ensemble classifier | 8 | 4 | 99.50% |
| Sydney [17] | FFDNN | 26 | 4 | 99.77% |
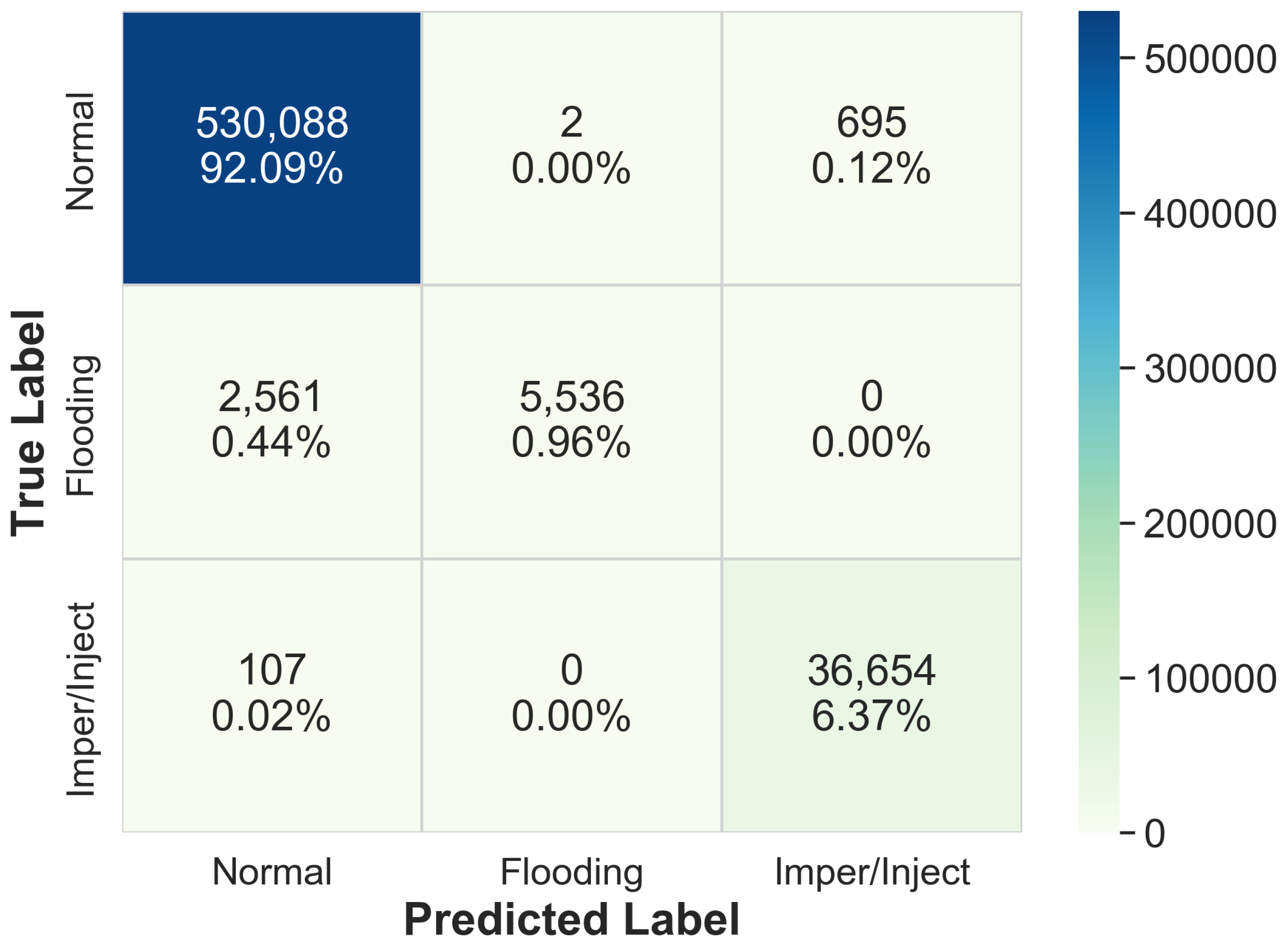
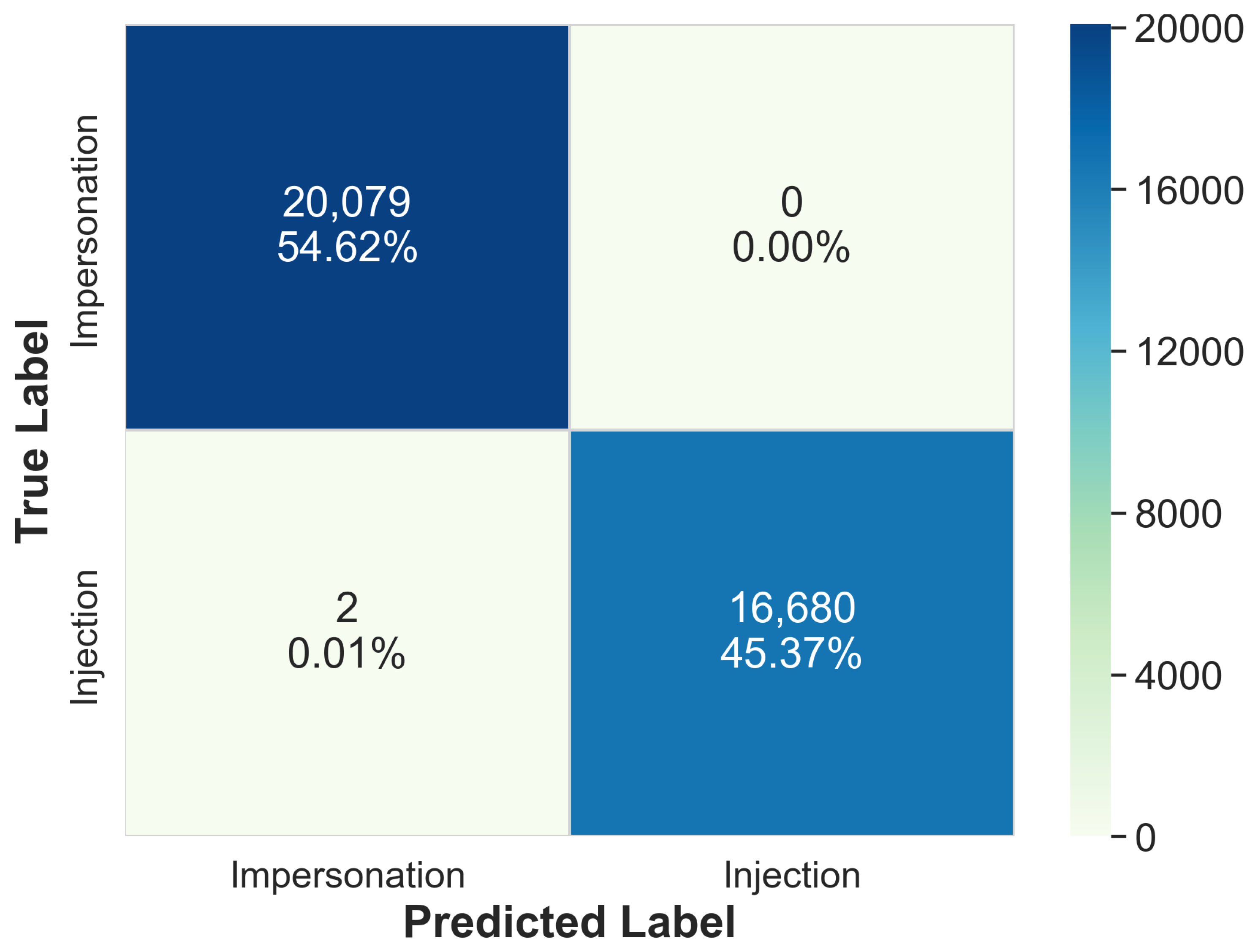
| Traffic Class | AWID-CLS-R-Trn | AWID-CLS-R-Tst |
|---|---|---|
| Normal | 1,633,190 (91%) | 530,785 (92.2%) |
| Impersonation | 48,484 (2.7%) | 8097 (1.4%) |
| Injection | 48,522 (2.7%) | 20,079 (3.5%) |
| Flooding | 65,379 (3.6%) | 16,682 (2.9%) |
| Feature # | Feature’s Name | Feature # | Feature’s Name |
|---|---|---|---|
| 0 | frame.time_epoch | 18 | radiotap.dbm_antsignal |
| 1 | frame.time_delta | 19 | wlan.fc.type_subtype |
| 2 | frame.time_delta_displayed | 20 | wlan.fc.type |
| 3 | frame.time_relative | 21 | wlan.fc.subtype |
| 4 | frame.len | 22 | wlan.fc.ds |
| 5 | frame.cap len | 23 | wlan.fc.frag |
| 6 | radiotap.length | 24 | wlan.fc.retry |
| 7 | radiotap.present.tsft | 25 | wlan.fc.pwrmgt |
| 8 | radiotap.present.flags | 26 | wlan.fc.moredata |
| 9 | radiotap.present.channel | 27 | wlan.fc.protected |
| 10 | radiotap.present.dbm_antsignal | 28 | wlan.duration |
| 11 | radiotap.present.antenna | 29 | wlan.ra |
| 12 | radiotap.present.rxflags | 30 | wlan.da |
| 13 | radiotap.present.mactime | 31 | wlan.ta |
| 14 | radiotap.datarate | 32 | wlan.sa |
| 15 | radiotap.channel.freq | 33 | wlan.bssid |
| 16 | radiotap.channel.type.cck | 34 | wlan.frag |
| 17 | radiotap.channel.type.ofdm | 35 | wlan.seq |
| Feature Selection Method | # of Features | Training Accuracy | Test Accuracy |
|---|---|---|---|
| Recursive Feature Elimination | 19 | 98.28% | 95.59% |
| Feature Importance | 8 | 98.87% | 95.05% |
| Chi-square Test | 24 | 98.84% | 95.43% |
| Feature Correlation | 19 | 99.46% | 96.19% |
| Particle Swarm Optimization | 23 | 97.47% | 95.77% |
| Feature # | Feature’s Name | Feature # | Feature’s Name |
|---|---|---|---|
| 0 | frame.len | 10 | wlan.fc.retry |
| 1 | radiotap.present.flags | 11 | wlan.fc.pwrmgt |
| 2 | radiotap.datarate | 12 | wlan.fc.moredata |
| 3 | radiotap.channel.freq | 13 | wlan.fc.protected |
| 4 | radiotap.channel.type.cck | 14 | wlan.duration |
| 5 | radiotap.dbm antsignal | 15 | wlan.ra |
| 6 | wlan.fc.type | 16 | wlan.da |
| 7 | wlan.fc.subtype | 17 | wlan.frag |
| 8 | wlan.fc.ds | 18 | wlan.seq |
| 9 | wlan.fc.frag |
| Feature Selection Method | # of Features | Training Accuracy | Test Accuracy |
|---|---|---|---|
| Recursive Feature Elimination | 10 | 100% | 48.38% |
| Feature Importance | 7 | 100% | 99.99% |
| Chi-square Test | 16 | 97.68% | 45.38% |
| Correlation Analysis | 16 | 99.91% | 49.36% |
| Particle Swarm Optimization | 15 | 99.92% | 49.46% |
| Feature # | Feature’s Name | Feature # | Feature’s Name |
|---|---|---|---|
| 0 | frame.len | 4 | wlan.fc.protected |
| 1 | radiotap.dbm_antsignal | 5 | wlan.duration |
| 2 | wlan.fc.subtype | 6 | wlan.seq |
| 3 | wlan.fc.ds |
| ML Algorithm | First, Stage ML Model | Second Stage ML Model | ||
|---|---|---|---|---|
| Accuracy | Training Time | Accuracy | Training Time | |
| Bagging | 99.41% | 4854.25 s | 99.99% | 54.63 s |
| Random Forest | 99.57% | 2168.85 s | 99.99% | 30.94 s |
| Extra Trees | 99.55% | 1802.91 s | 99.99% | 29.78 s |
| XGBoost | 99.49% | 854.50 s | 99.99% | 4.35 s |
| Naive Bayes | 87.85% | 320.79 s | 100.00% | 0.22 s |
| Class Name | Feature | Value | Impact |
|---|---|---|---|
| Flooding | wlan.fc.type (6) | High | Negative Low |
| frame.len (0) | Low | Positive Low | |
| radiotap.dbm_antsignal (5) | High | Positive High | |
| radiotap.datarate (2) | Low | Positive Low | |
| wlan.da (16) | High | Positive Low | |
| Impersonation | wlan.seq (18) | High | Negative High |
| wlan.fc.subtype (7) | Low/High | Positive High | |
| radiotap.dbm_antsignal (5) | high | Positive High | |
| frame.len (0) | Low | Positive High | |
| wlan.fc.pwrmgt (11) | High | Positive Low | |
| Injection | wlan.duration (14) | High | Positive High |
| wlan.fc.protected (13) | High | Positive High | |
| wlan.fc.subtype (7) | Low | Positive High | |
| wlan.fc.ds (8) | Low/High | Positive High | |
| frame.len (0) | Low | Negative High | |
| Normal | frame.len (0) | Low | Positive High |
| wlan.fc.subtype (7) | Low/High | Positive High | |
| wlan.duration (14) | High | Positive Low | |
| radiotap.datarate (2) | High | Positive Low | |
| wlan.fc.type (6) | High | Positive Low |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
A. Reyes, A.; D. Vaca, F.; Castro Aguayo, G.A.; Niyaz, Q.; Devabhaktuni, V. A Machine Learning Based Two-Stage Wi-Fi Network Intrusion Detection System. Electronics 2020, 9, 1689. https://doi.org/10.3390/electronics9101689
A. Reyes A, D. Vaca F, Castro Aguayo GA, Niyaz Q, Devabhaktuni V. A Machine Learning Based Two-Stage Wi-Fi Network Intrusion Detection System. Electronics. 2020; 9(10):1689. https://doi.org/10.3390/electronics9101689
Chicago/Turabian StyleA. Reyes, Abel, Francisco D. Vaca, Gabriel A. Castro Aguayo, Quamar Niyaz, and Vijay Devabhaktuni. 2020. "A Machine Learning Based Two-Stage Wi-Fi Network Intrusion Detection System" Electronics 9, no. 10: 1689. https://doi.org/10.3390/electronics9101689
APA StyleA. Reyes, A., D. Vaca, F., Castro Aguayo, G. A., Niyaz, Q., & Devabhaktuni, V. (2020). A Machine Learning Based Two-Stage Wi-Fi Network Intrusion Detection System. Electronics, 9(10), 1689. https://doi.org/10.3390/electronics9101689