DiPLIP: Distributed Parallel Processing Platform for Stream Image Processing Based on Deep Learning Model Inference



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Background and Related Works
2.1. Distributed Parallel Processing Platform
2.1.1. Hadoop
2.1.2. Spark
2.1.3. SparkCL
2.1.4. Storm
2.2. Cloud Infrastructure
3. DiPLIP Architecture
3.1. User Interface Layer
3.2. Master Layer
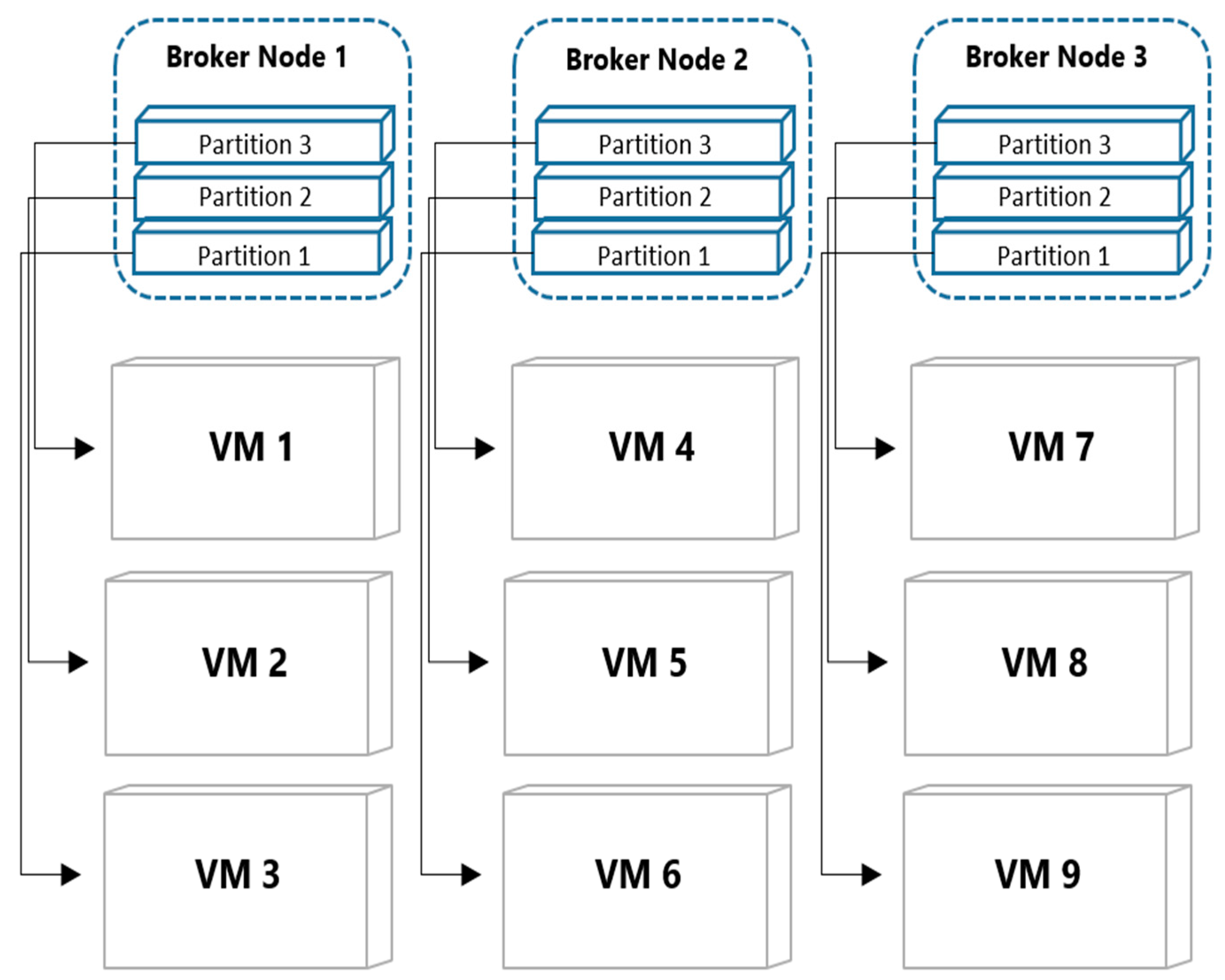
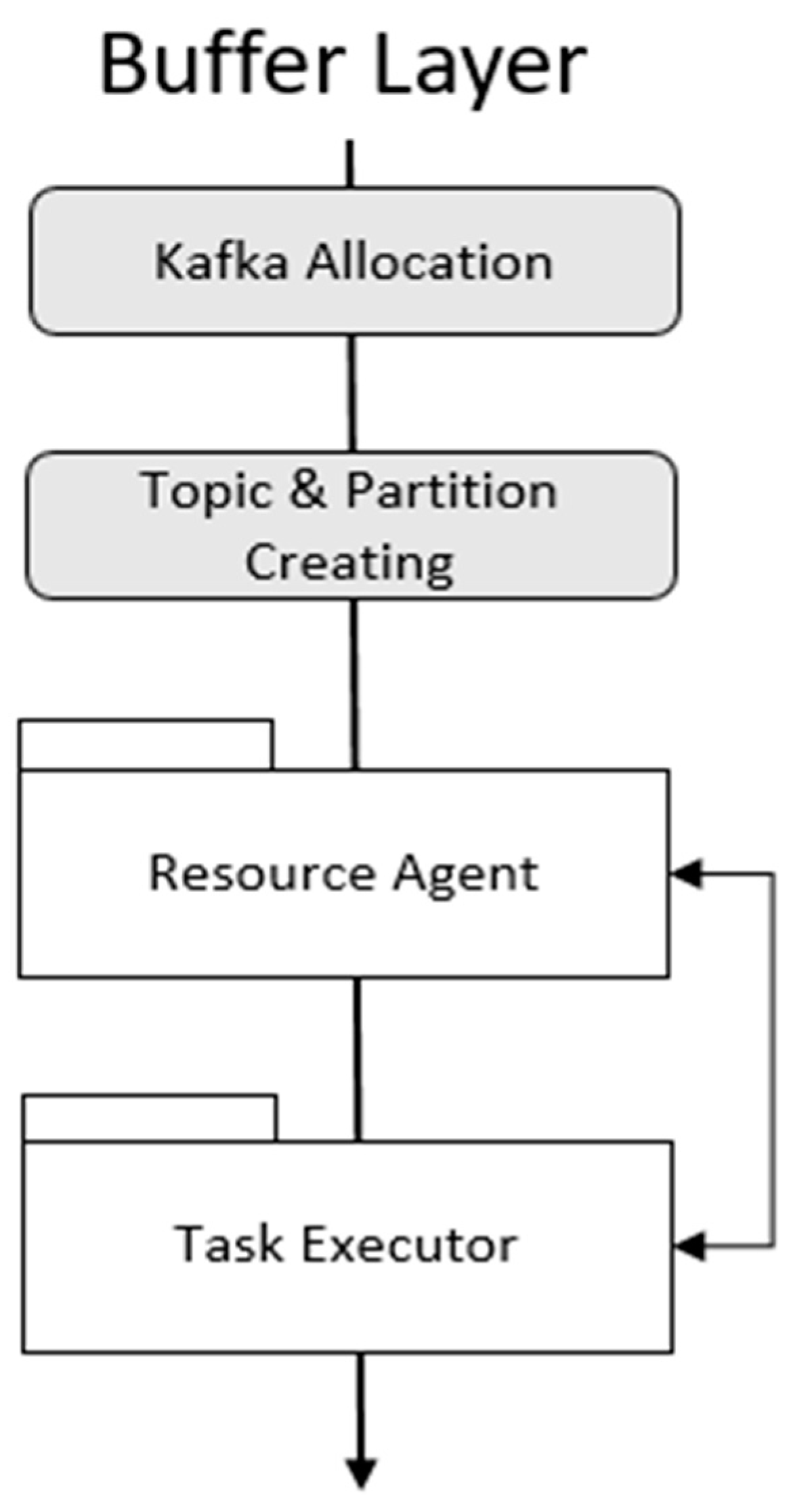
3.3. Buffer Layer
3.4. Worker Layer
4. Implementation
4.1. User Interface Layer
4.2. Master Layer
4.3. Buffer Layer
4.4. Worker Layer
4.5. Execution Scenario
- The user requests an available resource from the user interface layer.
- The master layer informs the user of available resources.
- The user requests the allocation of a distributed node that will serve as a buffer for real-time stream data and a worker node to perform a trained deep learning model.
- In the master layer, Kafka is deployed to distributed nodes by user’s request; it can be used as a buffer store.
- The topic of the repository is identified so that the worker node can find the buffer by name and submit the partition value for the topic.
- The user submits a deep learning trained model. In the master layer, the submitted deep learning model is packaged as a Docker image.
- The master node deploys the trained model to each worker node.
- Each worker pulls the docker image from the master node.
- The master node issues a command to execute the pulled image.
5. Performance Evaluation
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Lecture Notes in Computer Science; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. ISBN 978-3-319-46447-3. [Google Scholar]
- Liu, L.; Yang, S.; Meng, L.; Li, M.; Wang, J. Multi-scale Deep Convolutional Neural Network for Stroke Lesions Segmentation on CT Images. In Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries; Lecture Notes in Computer Science; Crimi, A., Bakas, S., Kuijf, H., Keyvan, F., Reyes, M., van Walsum, T., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 11383, pp. 283–291. ISBN 978-3-030-11722-1. [Google Scholar]
- Kiran, B.R.; Roldão, L.; Irastorza, B.; Verastegui, R.; Süss, S.; Yogamani, S.; Talpaert, V.; Lepoutre, A.; Trehard, G. Real-Time Dynamic Object Detection for Autonomous Driving Using Prior 3D-Maps. In Computer Vision—ECCV 2018 Workshops; Lecture Notes in Computer Science; Leal-Taixé, L., Roth, S., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 11133, pp. 567–582. ISBN 978-3-030-11020-8. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Carbone, P.; Katsifodimos, A.; Ewen, S.; Markl, V.; Haridi, S.; Tzoumas, K. Apache Flink: Stream and Batch Processing in a Single Engine. IEEE Data Eng. Bull. 2015, 36, 4. [Google Scholar]
- Shahrivari, S. Beyond Batch Processing: Towards Real-Time and Streaming Big Data. Computers 2014, 3, 117–129. [Google Scholar] [CrossRef]
- White, T. Hadoop: The Definitive Guide; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2012. [Google Scholar]
- Zaharia, M.; Chowdhury, M.; Das, T.; Dave, A.; Ma, J.; McCauley, M.; Franklin, M.J.; Shenker, S.; Stoica, I. Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. In Proceedings of the 9th USENIX Symposium on Networked Systems Design and Implementation, San Jose, CA, USA, 25–27 April 2012. [Google Scholar]
- Abadi, D.J.; Ahmad, Y.; Balazinska, M.; Hwang, J.-H.; Lindner, W.; Maskey, A.S.; Rasin, A.; Ryvkina, E.; Tatbul, N.; Xing, Y.; et al. The Design of the Borealis Stream Processing Engine. In Proceedings of the 2005 CIDR Conference, Asilomar, CA, USA, 4–7 January 2005. [Google Scholar]
- Stonebraker, M.; Çetintemel, U.; Zdonik, S. The 8 requirements of real-time stream processing. SIGMOD Rec. 2005, 34, 42–47. [Google Scholar] [CrossRef]
- Cherniack, M.; Balakrishnan, H.; Balazinska, M.; Carney, D. Scalable Distributed Stream Processing. In Proceedings of the 2003 CIDR Conference, Asilomar, CA, USA, 5–8 January 2003. [Google Scholar]
- Borthakur, D. The Hadoop Distributed File System: Architecture and Design. Hadoop Proj. Website 2007, 14, 21. [Google Scholar]
- Dean, J.; Ghemawat, S. MapReduce: Simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Condie, T.; Conway, N.; Alvaro, P.; Hellerstein, J.M.; Elmeleegy, K.; Sears, R. MapReduce Online. In Proceedings of the 7th USENIX Conference on Networked Systems Design and Implementation, San Jose, CA, USA, 28–30 April 2010. [Google Scholar]
- Toshniwal, A.; Donham, J.; Bhagat, N.; Mittal, S.; Ryaboy, D.; Taneja, S.; Shukla, A.; Ramasamy, K.; Patel, J.M.; Kulkarni, S.; et al. Storm@twitter. In Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data—SIGMOD ’14, Snowbird, UT, USA, 22–27 June 2014. [Google Scholar] [CrossRef]
- Grit, L.; Irwin, D.; Yumerefendi, A.; Chase, J. Virtual Machine Hosting for Networked Clusters: Building the Foundations for “Autonomic” Orchestration. In Proceedings of the First International Workshop on Virtualization Technology in Distributed Computing (VTDC 2006), Tampa, FL, USA, 17 November 2006. [Google Scholar]
- Ranjan, R. Streaming Big Data Processing in Datacenter Clouds. IEEE Cloud Comput. 2014, 1, 78–83. [Google Scholar] [CrossRef]
- Kim, Y.-K.; Kim, Y.; Jeong, C.-S. RIDE: Real-time massive image processing platform on distributed environment. J. Image Video Proc. 2018, 2018, 39. [Google Scholar] [CrossRef]
- Kreps, J.; Narkhede, N.; Rao, J. Kafka: A Distributed Messaging System for Log Processing. In Proceedings of the 2011 ACM SIGMOD/PODS Conference, Athens, Greece, 12–16 June 2011. [Google Scholar]
- Tanenbaum, A.; Van, S.M. Distributed Systems: Principles and Paradigms; Prentice-Hall: Upper Saddle River, NJ, USA, 2007. [Google Scholar]
- Segal, O.; Colangelo, P.; Nasiri, N.; Qian, Z.; Margala, M. SparkCL: A Unified Programming Framework for Accelerators on Heterogeneous Clusters. arXiv 2015, arXiv:1505.01120. [Google Scholar]
- Merkel, D. Docker: Lightweight Linux Containers for Consistent Development and Deployment. Available online: https://www.linuxjournal.com/content/docker-lightweight-linux-containers-consistent-development-and-deployment (accessed on 24 August 2020).
- Cox, C.; Sun, D.; Tarn, E.; Singh, A.; Kelkar, R.; Goodwin, D. Serverless inferencing on Kubernetes. arXiv 2020, arXiv:2007.07366. [Google Scholar]
- Model Serving in PyTorch. Available online: https://pytorch.org/blog/model-serving-in-pyorch/ (accessed on 17 September 2020).
- Hindman, B.; Konwinski, A.; Zaharia, M.; Ghodsi, A.; Joseph, A.D.; Katz, R.; Shenker, S.; Stoica, I. Mesos: A Platform for Fine-Grained Resource Sharing in the Data Center. In Proceedings of the 8th USENIX Symposium on Networked Systems Design and Implementation, Boston, MA, USA, 30 March–1 April 2011. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Lecture Notes in Computer Science; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; Volume 8693, pp. 740–755. ISBN 978-3-319-10601-4. [Google Scholar]
- Henderson, P.; Ferrari, V. End-to-End Training of Object Class Detectors for Mean Average Precision. In Computer Vision—ACCV 2016; Lecture Notes in Computer Science; Lai, S.-H., Lepetit, V., Nishino, K., Sato, Y., Eds.; Springer International Publishing: Cham, Switzerland, 2017; Volume 10115, pp. 198–213. ISBN 978-3-319-54192-1. [Google Scholar]
- Hui, J. Object Detection: Speed and Accuracy Comparison (Faster R-CNN, R-FCN, SSD, FPN, RetinaNet and YOLOv3). Available online: https://medium.com/@jonathan_hui/object-detection-speed-and-accuracy-comparison-faster-r-cnn-r-fcn-ssd-and-yolo-5425656ae359 (accessed on 24 August 2020).












© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, Y.-K.; Kim, Y. DiPLIP: Distributed Parallel Processing Platform for Stream Image Processing Based on Deep Learning Model Inference. Electronics 2020, 9, 1664. https://doi.org/10.3390/electronics9101664
Kim Y-K, Kim Y. DiPLIP: Distributed Parallel Processing Platform for Stream Image Processing Based on Deep Learning Model Inference. Electronics. 2020; 9(10):1664. https://doi.org/10.3390/electronics9101664
Chicago/Turabian StyleKim, Yoon-Ki, and Yongsung Kim. 2020. "DiPLIP: Distributed Parallel Processing Platform for Stream Image Processing Based on Deep Learning Model Inference" Electronics 9, no. 10: 1664. https://doi.org/10.3390/electronics9101664
APA StyleKim, Y.-K., & Kim, Y. (2020). DiPLIP: Distributed Parallel Processing Platform for Stream Image Processing Based on Deep Learning Model Inference. Electronics, 9(10), 1664. https://doi.org/10.3390/electronics9101664