Adaptive Wiener Filter and Natural Noise to Eliminate Adversarial Perturbation

Abstract
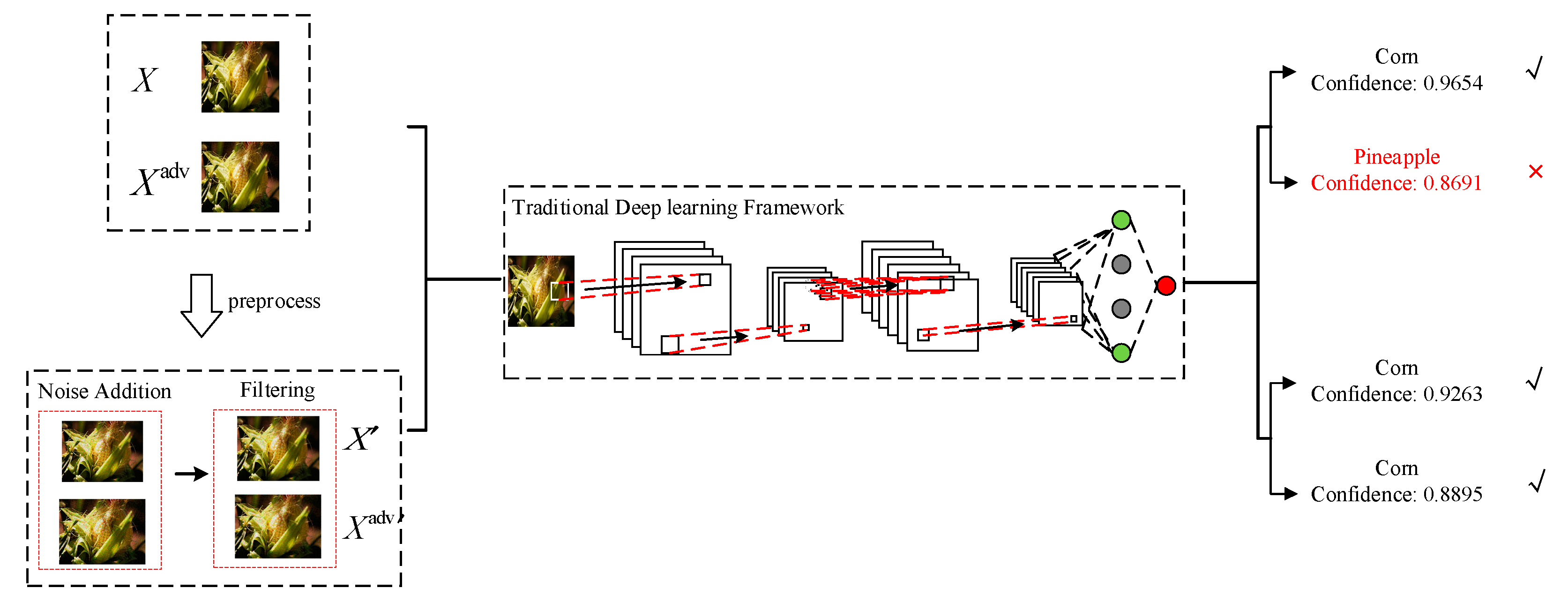
1. Introduction
- We introduce classic image-processing techniques, such as noise addition and filtering, to degrade the image in a certain range and reduce the perturbation effect. The advantage of the classic image-processing method is easy to operate, and we properly improve the adaptive Wiener filtering technology to improve the efficiency. Adversarial examples after processing can be correctly recognized and classified.
- We deeply study the principles and the distribution of the perturbed pixels caused by the different adversarial attacks. They are not deployed regularly, but randomly distributed in the whole image. Therefore, adding natural noise, such as gaussian noise, is bound to have an impact on adversarial perturbation. A subsequent adaptive wiener filtering can be applied to soft this corruption.
- We simulate different types of attack situations (defense-unaware scenario and defense-aware scenario). Then conduct a comprehensive experimental study to demonstrate that the proposed method can effectively eliminate the perturbation in adversarial examples and achieve state-of-the-art performance.
2. Background: Adversarial Attack
2.1. Box-Constrained L-BFGS
2.2. Fast Gradient Sign Method (FGSM)
2.3. Jacobian-Based Saliency Map Attack (JSMA)
2.4. Carlini and Wagner Attacks (C&W)
2.5. Deepfool
3. Related Work
Distribution of Attacks
4. Methodology
4.1. Natural Noise
4.2. Adaptive Wiener Filtering
5. Experiment
5.1. Adversarial Example Generation
5.2. Legitimate Samples Test
5.3. Different Attack Scenarios Test
5.4. Comparison Experiment
5.5. Discussion and Limitation
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
References
- Zhang, K.; Liang, Y.; Zhang, J.; Wang, Z.; Li, X.; Zhanga, J. No one can escape: A general approach to detect tampered and generated image. IEEE Access 2019, 7, 129494–129503. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Liu, C.; Song, D. Delving into transferable adversarial examples and black-box attacks. arXiv 2016, arXiv:1611.02770. [Google Scholar]
- Xie, C.; Wang, J.; Zhang, Z.; Zhou, Y.; Xie, L.; Yuille, A. Adversarial examples for semantic segmentation and object detection. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1378–1387. [Google Scholar]
- Fischer, V.; Kumar, M.C.; Metzen, J.H.; Brox, T. Adversarial examples for semantic image segmentation. arXiv 2017, arXiv:1703.01101. [Google Scholar]
- Zheng, S.; Song, Y.; Leung, T.; Goodfellow, I. Improving the robustness of deep neural networks via stability training. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4480–4488. [Google Scholar]
- Papernot, N.; McDaniel, P.; Wu, X.; Jha, S.; Swami, A. Distillation as a defense to adversarial perturbations against deep neural networks. In Proceedings of the 2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; pp. 582–597. [Google Scholar]
- Carlini, N.; Wagner, D. Defensive distillation is not robust to adversarial examples. arXiv 2016, arXiv:1607.04311. [Google Scholar]
- Gao, J.; Wang, B.; Lin, Z.; Xu, W.; Qi, Y. DeepCloak: Masking deep neural network models for robustness against adversarial samples. arXiv 2017, arXiv:1702.06763. [Google Scholar]
- Samangouei, P.; Maya, K.; Rama, C. Defense-gan: Protecting classifiers against adversarial attacks using generative models. arXiv 2018, arXiv:1805.06605. [Google Scholar]
- Zhou, Y.; Hu, X.; Wang, L.; Duan, S.; Chen, Y. Markov Chain Based Efficient Defense Against Adversarial Examples in Computer Vision. IEEE Access 2019, 7, 5695–5706. [Google Scholar] [CrossRef]
- Xu, W.; Evans, D.; Qi, Y. Feature squeezing: Detecting adversarial examples in deep neural networks. arXiv 2017, arXiv:1704.01155. [Google Scholar]
- Metzen, J.H.; Genewein, T.; Fischer, V.; Bischoff, B. On detecting adversarial perturbations. arXiv 2017, arXiv:1702.04267. [Google Scholar]
- Grosse, K.; Manoharan, P.; Papernot, N.; Backes, M.; McDaniel, P. On the (Statistical) detection of adversarial examples. arXiv 2017, arXiv:1702.06280. [Google Scholar]
- Wu, T.; Tong, L.; Vorobeychik, Y. Defending against physically realizable attacks on image classification. arXiv 2019, arXiv:1909.09552. [Google Scholar]
- Kou, C.; Lee, H.K.; Chang, E.-C.; Ng, T.K. Enhancing transformation-based defenses against adversarial attacks with a distribution classifier. arXiv 2019, arXiv:1906.00258. [Google Scholar]
- Song, C.; He, K.; Lin, J.; Wang, L.; Hopcroft, J.E. Robust local features for improving the generalization of adversarial training. arXiv 2019, arXiv:1909.10147. [Google Scholar]
- Athalye, A.; Sutskever, I. Synthesizing robust adversarial examples. arXiv 2017, arXiv:1707.07397. [Google Scholar]
- Wang, S.; Chen, S.; Chen, T.; Nepal, S.; Rudolph, C.; Grobler, M. Generating semantic adversarial examples via feature manipulation. arXiv 2020, arXiv:2001.02297. [Google Scholar]
- Goodfellow, I.; Lee, H.; Le, Q.V.; Saxe, A.; Ng, A.Y. Measuring invariances in deep networks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 7–10 December 2009; pp. 646–654. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2014, arXiv:1312.6199. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2015, arXiv:1412.6572. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial machine learning at scale. arXiv 2017, arXiv:1611.01236. [Google Scholar]
- Papernot, N.; McDaniel, P.; Jha, S.; Fredrikson, M.; Celik, Z.B.; Swami, A. The limitations of deep learning in adversarial settings. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy, Saarbrucken, Germany, 21–24 March 2016; pp. 372–387. [Google Scholar]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. arXiv 2016, arXiv:1608.04644. [Google Scholar]
- Moosavi-Dezfooli, S.-M.; Fawzi, A.; Frossard, P. DeepFool: A simple and accurate method to fool deep neural networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2574–2582. [Google Scholar]
- Diamond, S.; Sitzmann, V.; Boyd, S.; Wetzstein, G.; Heide, F. Dirty pixels: Optimizing image classification architectures for raw sensor data. arXiv 2017, arXiv:1701.06487. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4 inception-resnet and the impact of residual connections on learning. arXiv 2017, arXiv:1602.07261. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. arXiv 2016, arXiv:1603.05027. [Google Scholar]
- Karen, S.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Carlini, N.; Wagner, D. Adversarial examples are not easily detected: By passing ten detection methods. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Jin, G.; Shen, S.; Zhang, D.; Dai, F.; Zhang, Y. APE-GAN: Adversarial perturbation elimination with GAN. arXiv 2017, arXiv:1705.07263. [Google Scholar]
- Nilaksh, D.; Shanbhogue, M.; Chen, S.-T.; Hohman, F.; Li, S.; Chen, L.; Kounavis, M.E.; Chau, D.H. Shield: Fast, practical defense and vaccination for deep learning using jpeg compression. arXiv 2014, arXiv:1802.06816. [Google Scholar]
- Guo, C.; Rana, M.; Cisse, M.; van der Maaten, L. Countering adversarial images using input transformations. arXiv 2017, arXiv:1711.00117. [Google Scholar]
- Liang, B.; Li, H.; Su, M.; Li, X.; Shi, W.; Wang, X. Detecting adversarial image examples in deep neural networks with adaptive noise reduction. IEEE Trans. Dependable Secur. Comput. 2019, 1, 99. [Google Scholar] [CrossRef]
- Dougherty, E.R. Digital Image Processing Methods; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Filter | Gaussian White Noise | Salt & Pepper Noise | Poisson Noise | Multiplicative Noise |
|---|---|---|---|---|
| Gaussian | 98.17%/98.26%/98.64% | 97.16%/97.69%/97.53% | 98.29%/97.55%/96.94% | 99.03%/98.14%/98.33% |
| Median | 99.19%/98.61%/97.92% | 99.46%/98.97%/98.86% | 98.49%/98.25%/98.47% | 99.24%/99.13%/99.02% |
| Mean | 98.87%/98.89%/98.49% | 99.03%/98.89%/98.43% | 98.60%/97.68%/98.29% | 99.14%/98.71%/98.66% |
| Bilateral | 99.34%/99.01%/99.12% | 99.21%/98.56%/98.74% | 98.93%/98.61%/98.59% | 99.9%/98.84%/98.73% |
| KNN | 97.37%/97.11%/96.86% | 97.67%/96.83%/96.93% | 98.87%/98.38%/98.14% | 98.99%/99.04%/98.59% |
| High-pass | 8.17%/6.26%/7.14% | 7.87%/7.62%/7.34% | 9.69%/8.89%/9.64% | 6.95%/7.07%/6.81% |
| Low-pass | 98.77%/98.52%/98.71% | 98.41%/98.15%/98.27% | 98.65%/98.11%/98.23% | 98.97%/98.95%/98.78% |
| Adaptive wiener | 99.36%/99.13%/99.08% | 99.43%/99.26%/99.19% | 99.29%/99.06%/99.11% | 99.49%/99.32%/99.34% |
| Filter | Gaussian White Noise | Salt & Pepper Noise | Poisson Noise | Multiplicative Noise |
|---|---|---|---|---|
| Gaussian | 65.71% | 69.16% | 58.79% | 63.84% |
| Median | 51.49% | 56.47% | 52.31% | 56.53% |
| Mean | 67.54% | 61.29% | 62.63% | 66.87% |
| Bilateral | 46.92% | 53.38% | 48.43% | 49.45% |
| KNN | 36.41% | 40.26% | 47.31% | 39.68% |
| High-pass | 0% | 0% | 0% | 0% |
| Low-pass | 59.83% | 59.67% | 56.95% | 58.67% |
| Adaptive wiener | 76.58% | 81.29% | 74.94% | 93.87% |
| Models | Inception-v4 | Resnet-v2 | Vgg16 | |||
|---|---|---|---|---|---|---|
| Target Model | Defense Model | Target Model | Defense Model | Target Model | Defense Model | |
| FGSM () | 3.11% | 95.63% | 2.89% | 94.59% | 3.27% | 95.93% |
| FGSM () | 1.79% | 94.39% | 2.08% | 93.96% | 2.147% | 94.65% |
| C&W () | 1.36% | 91.62% | 1.59% | 92.16% | 2.25% | 93.27% |
| C&W () | 1.33% | 90.26% | 1.43% | 91.37% | 1.98% | 92.69% |
| C&W () | 1.21% | 90.53% | 1.34% | 91.78% | 1.88% | 91.53% |
| C&W () | 1.14% | 90.03% | 1.11% | 91.28% | 1.58% | 91.39% |
| C&W () | 1.29% | 92.75% | 1.18% | 94.03% | 1.59% | 91.17% |
| Deepfool | 2.87% | 96.33% | 1.89% | 97.63% | 2.65% | 96.48% |
| JSMA | 2.56% | 97.24% | 2.37% | 97.82% | 2.57% | 96.77% |
| L-BFGS | 2.81% | 95.86% | 2.51% | 96.79% | 2.66% | 96.01% |
| Models | Inception-v4 | Resnet-v2 | Vgg16 | |||
|---|---|---|---|---|---|---|
| Target Model | Defense Model | Target Model | Defense Model | Target Model | Defense Model | |
| FGSM () | 1.81% | 79.12% | 1.98% | 77.57% | 186% | 79.52% |
| C&W () | 2.37% | 62.84% | 2.17% | 64.73% | 2.17% | 68.13% |
| C&W () | 1.97% | 66.27% | 1.87% | 67.88% | 1.51% | 65.85% |
| Deepfool | 2.83% | 71.39% | 2.06% | 72.82% | 2.36% | 75.76% |
| JSMA | 2.26% | 81.78% | 2.27% | 82.34% | 2.99% | 78.04% |
| L-BFGS | 2.76% | 74.99% | 2.86% | 76.38% | 2.45% | 75.61% |
| JPEG | APE-GAN | Cropping + TVM + Quilting | Spatial Smoothing Filter | The Proposed Method | |
|---|---|---|---|---|---|
| FGSM | 65.63% | 50.91% | 71.52% | 89.61% | 94.93% |
| C&W | 71.85% | 73.92% | 70.51% | 85.15% | 91.74% |
| Deepfool | 71.88% | 54.15% | 71.47% | 88.76% | 90.68% |
| JSMA | 73.8% | 62.26% | 68.19% | 86.54% | 92.44% |
| L-BFGS | 72.9% | 61.71% | 70.16% | 87.33% | 93.79% |
| Defense-aware | 11.6% | 0% | 0% | 32.61% | 53.15% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, F.; Yang, W.; Xiao, L.; Zhu, J. Adaptive Wiener Filter and Natural Noise to Eliminate Adversarial Perturbation. Electronics 2020, 9, 1634. https://doi.org/10.3390/electronics9101634
Wu F, Yang W, Xiao L, Zhu J. Adaptive Wiener Filter and Natural Noise to Eliminate Adversarial Perturbation. Electronics. 2020; 9(10):1634. https://doi.org/10.3390/electronics9101634
Chicago/Turabian StyleWu, Fei, Wenxue Yang, Limin Xiao, and Jinbin Zhu. 2020. "Adaptive Wiener Filter and Natural Noise to Eliminate Adversarial Perturbation" Electronics 9, no. 10: 1634. https://doi.org/10.3390/electronics9101634
APA StyleWu, F., Yang, W., Xiao, L., & Zhu, J. (2020). Adaptive Wiener Filter and Natural Noise to Eliminate Adversarial Perturbation. Electronics, 9(10), 1634. https://doi.org/10.3390/electronics9101634