Exposing Speech Resampling Manipulation by Local Texture Analysis on Spectrogram Images


Abstract
1. Introduction
2. Principle of Resampling
3. Effect on the Spectrogram of Speech Resampling
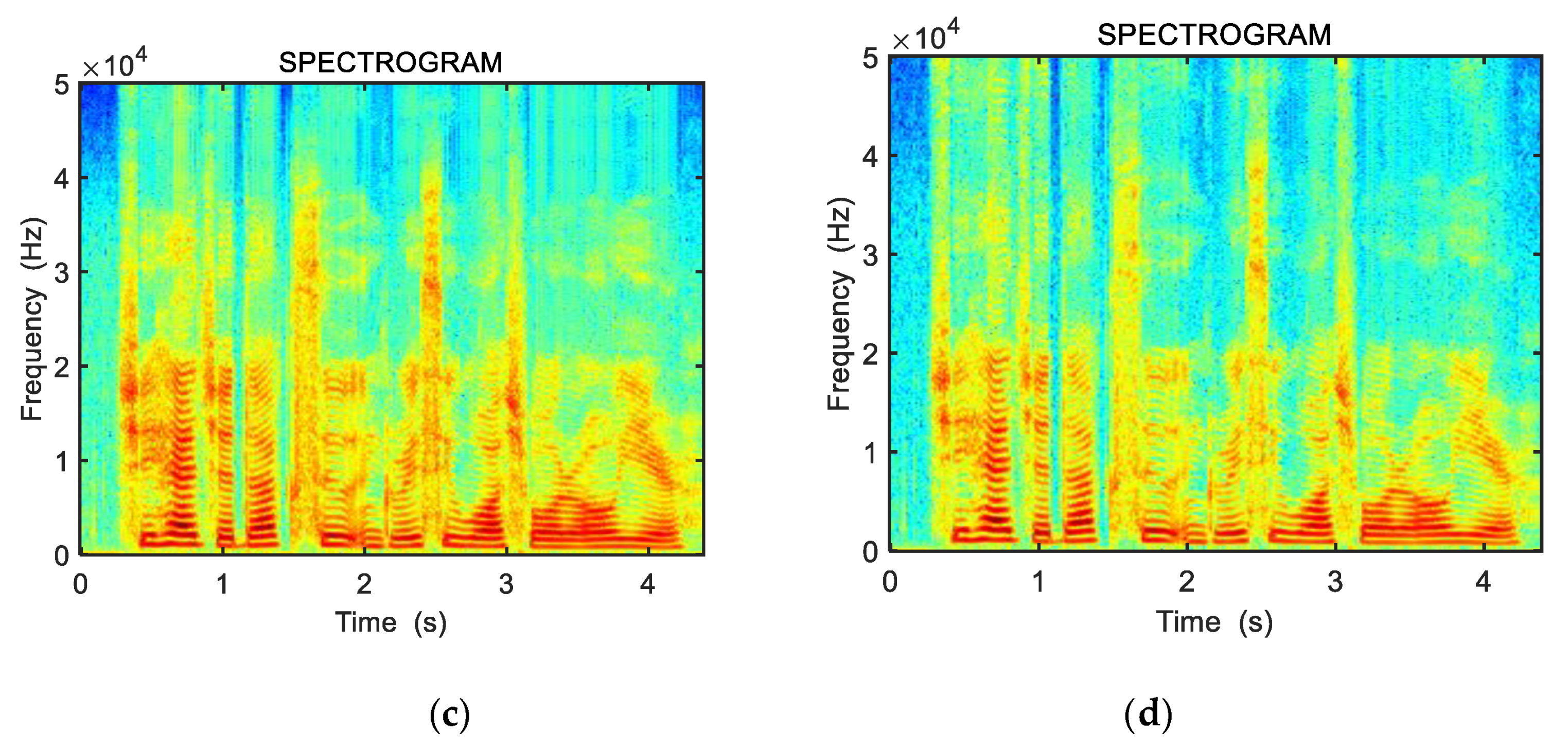
3.1. Spectrogram
3.2. Relationship between Resampling and Spectrogram
4. Feature Extraction
5. Experimental Results and Analysis
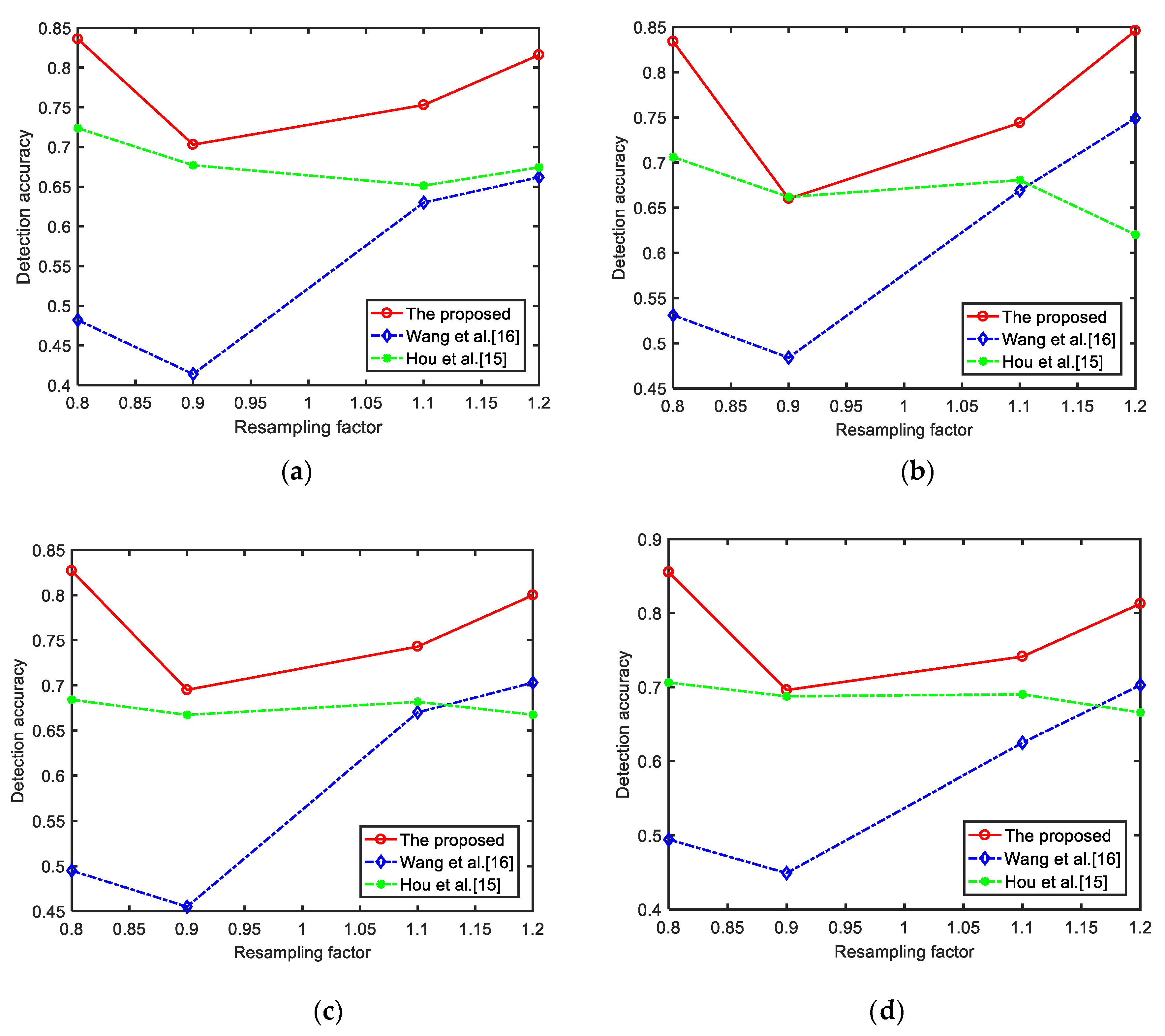
5.1. Experimental Results under Different Compression Interpolation Methods
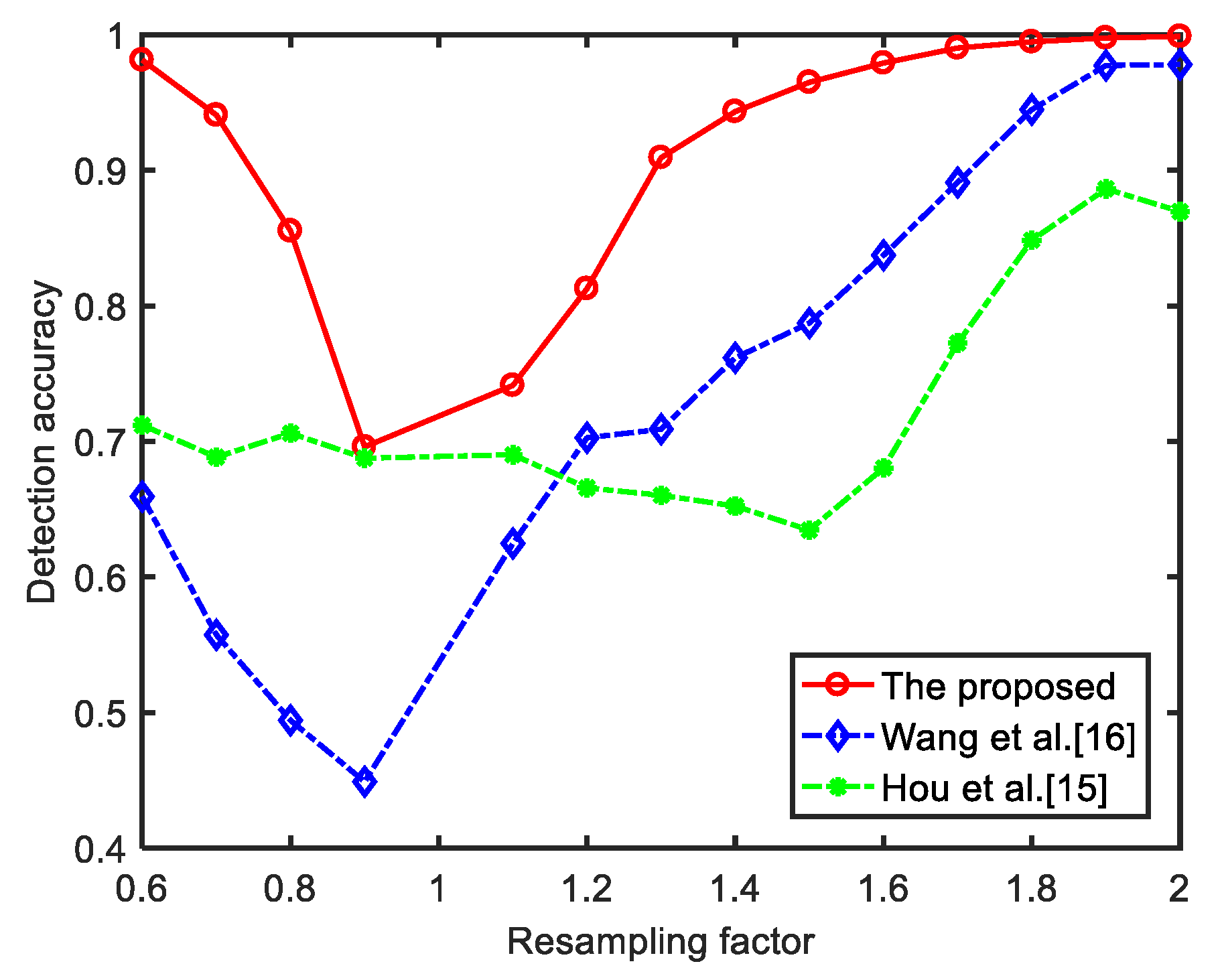
5.2. Experimental Results under Different Compression Sampling Factors
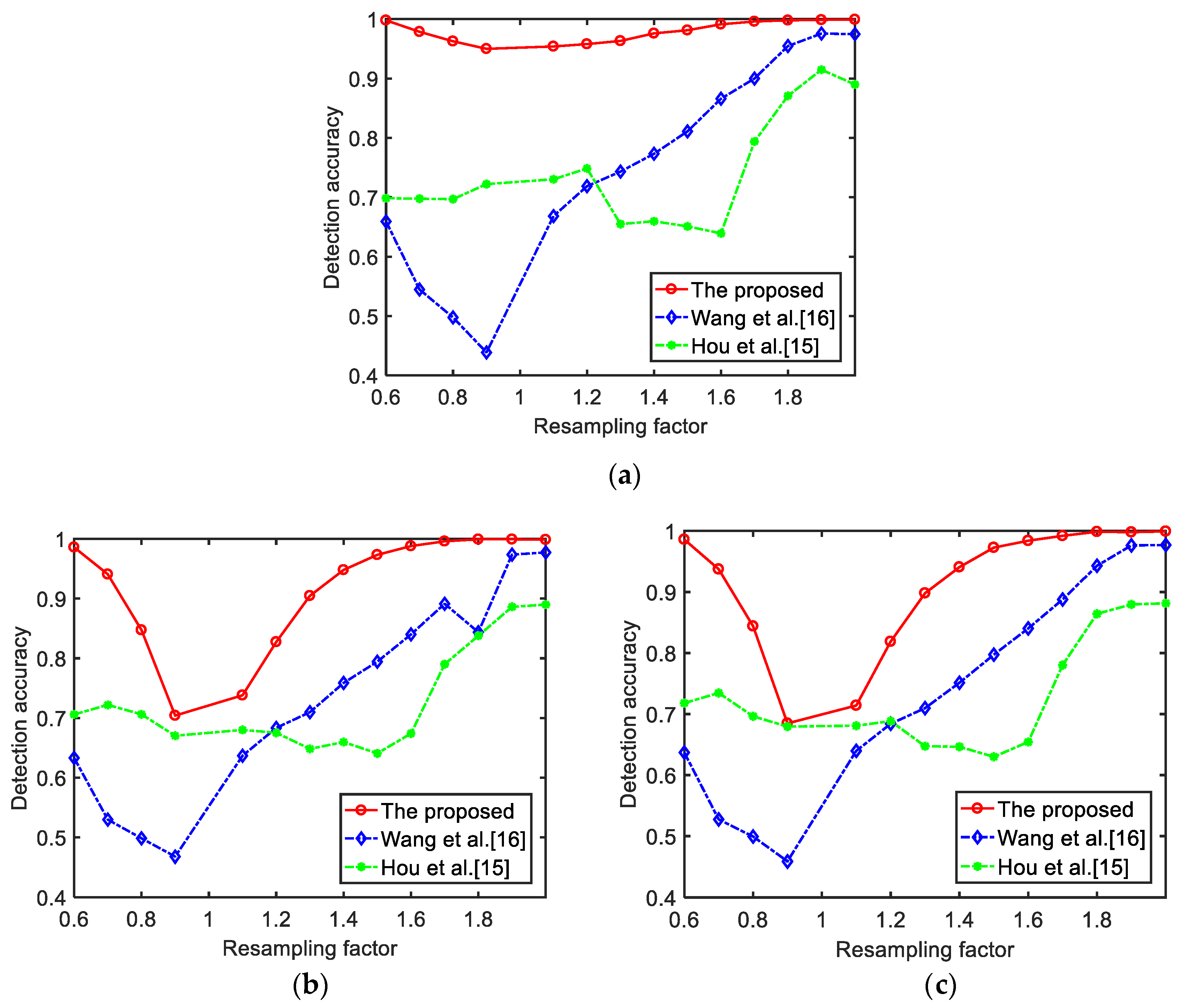
5.3. Experimental Results under Different Compression Scenarios
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Li, F.; Xin, M.; Li, J.; Yu, J. Improved detection for copy-move forgery with multi-scale sliding windows. In Proceedings of the 2017 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Xiamen, China, 6–9 November 2017; pp. 231–236. [Google Scholar]
- Chen, C.L.; Ni, J.Q.; Shen, Z.Y.; Shi, Y.Q. Blind Forensics of Successive Geometric Transformations in Digital Images Using Spectral Method: Theory and Applications. IEEE Trans. Image Process. 2017, 26, 2811–2824. [Google Scholar] [CrossRef] [PubMed]
- Bappy, J.H.; Simons, C.; Nataraj, L.; Manjunath, B.S.; Roy-Chowdhury, A.K. Hybrid LSTM and Encoder–Decoder Architecture for Detection of Image Forgeries. IEEE Trans. Image Process. 2019, 28, 3286–3300. [Google Scholar] [CrossRef] [PubMed]
- Tang, W.; Li, B.; Tan, S.; Barni, M.; Huang, J. CNN-Based Adversarial Embedding for Image Steganography. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2074–2087. [Google Scholar] [CrossRef]
- Ali, Z.; Imran, M.; Alsulaiman, M. An Automatic Digital Audio Authentication/Forensics System. IEEE Access 2017, 5, 2994–3007. [Google Scholar] [CrossRef]
- Luo, D.; Korus, P.; Huang, J.W. Band energy difference for source attribution in audio forensics. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2179–2189. [Google Scholar] [CrossRef]
- Luo, W.Q.; Li, H.D.; Yan, Q.; Yang, R. Improved audio steganalytic feature and its applications in audio forensics. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2018, 14, 1–14. [Google Scholar] [CrossRef]
- Lin, X.; Kang, X. Exposing speech tampering via spectral phase analysis. Digit. Signal Process. 2017, 60, 63–74. [Google Scholar] [CrossRef]
- Yan, Q.; Yang, R.; Huang, J. Robust Copy–Move Detection of Speech Recording Using Similarities of Pitch and Formant. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2331–2341. [Google Scholar] [CrossRef]
- Yan, D.; Wang, R.; Zhou, J.; Jin, C.; Wang, Z. Compression history detection for MP3 audio. Ksii Trans. Internet Inf. Syst. 2018, 12, 662–675. [Google Scholar]
- Yao, Q.M.; Chai, P.Q.; Xuan, G.R.; Yang, Z.Q.; Shi, Y.Q. Audio re-sampling detection in audio forensics based on EM algorithm. J. Comput. Appl. 2006, 26, 2598–2601. [Google Scholar]
- Chen, Y.X.; Xi, W.U. A method of detecting re-sampling based on expectation maximization applied in audio blind forensics. J. Circuits Syst. 2012, 17, 118–123. [Google Scholar]
- Shi, Q.; Ma, X.H. Detection of audio interpolation based on singular value decomposition. In Proceedings of the 2011 3rd International Conference on Awareness Science and Technology (iCAST), Dalian, China, 27–30 September 2011; pp. 287–290. [Google Scholar]
- Qi, D.; Peng, X.J. Audio Tampering Detection Based on Band-Partitioning Spectral Smoothness. Appl. Sci. Electron. Inf. Eng. 2010, 28, 142–146. [Google Scholar]
- Hou, L.M.; Wu, W.Q.; Zhang, X.P. Audio re-sampling detection in audio forensics based on second-order derivative. J. Shanghai Univ. 2014, 20, 304–312. [Google Scholar]
- Wang, Z.F.; Yan, D.; Wang, R. Speech resampling detection based on inconsistency of band energy. CMC-Comput. Mater. Contin. 2018, 56, 247–259. [Google Scholar]
- Wang, F.; Li, C.; Tian, L. An algorithm of detecting audio copy-move forgery based on DCT and SVD. In Proceedings of the 2017 IEEE 17th International Conference on Communication Technology (ICCT), Chengdu, China, 27–30 October 2017; pp. 1652–1657. [Google Scholar]
- Mulimani, M.; Koolagudi, S.G. Segmentation and characterization of acoustic event spectrograms using singular value decomposition. Expert Syst. Appl. 2019, 120, 413–425. [Google Scholar] [CrossRef]
- Mulimani, M.; Koolagudi, S.G. Extraction of MapReduce-based features from spectrograms for audio-based surveillance. Digit. Signal Process. 2019, 87, 1–9. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikäinen, M.; Harwood, D. A comparative study of texture measures with classification based on featured distributions. Pattern Recognit. 1996, 29, 51–59. [Google Scholar] [CrossRef]
- Liu, X.; Xue, F.; Teng, L. Surface Defect Detection Based on Gradient LBP. In Proceedings of the 2018 IEEE 3rd International Conference on Image, Vision and Computing (ICIVC), Chongqing, China, 27–29 June 2018; pp. 133–137. [Google Scholar]
- Song, T.; Li, H.; Meng, F.; Wu, Q.; Cai, J. LETRIST: Locally Encoded Transform Feature Histogram for Rotation-Invariant Texture Classification. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 1565–1579. [Google Scholar] [CrossRef]
- Chang, C.; Lin, C. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2007, 2, 62–71. [Google Scholar] [CrossRef]
- Wang, K.; Li, C.; Tian, L. Audio zero watermarking for MP3 based on low frequency energy. In Proceedings of the 2017 6th International Conference on Informatics, Electronics and Vision & 2017 7th International Symposium in Computational Medical and Health Technology (ICIEV-ISCMHT), Himeji, Japan, 1–7 September 2017; pp. 1–5. [Google Scholar]
- Erfani, Y.; Pichevar, R.; Rouat, J. Audio Watermarking Using Spikegram and a Two-Dictionary Approach. IEEE Trans. Inf. Forensics Secur. 2017, 12, 840–852. [Google Scholar] [CrossRef]
- Brandenburg, K.; Stoll, G. ISO/MPEG-1 Audio: A Generic Standard for Coding of High-Quality Digital Audio. J. Audio Eng. Soc. 1994, 42, 780–792. [Google Scholar]
- Zhang, Q.Y.; Zhang, T.; Qiao, S.B.; Wu, D.F. Spectrogram-based Efficient Perceptual Hashing Scheme for Speech Identification. Int. J. Netw. Secur. 2019, 21, 259–268. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| p/q | Mixed Interpolation | Linear Interpolation | Spline Interpolation | Cubic Interpolation |
|---|---|---|---|---|
| 0.8 | 0.8360 | 0.8340 | 0.8270 | 0.8553 |
| 0.9 | 0.7030 | 0.6600 | 0.6950 | 0.6960 |
| 1.1 | 0.7530 | 0.7440 | 0.7430 | 0.7413 |
| 1.2 | 0.8160 | 0.8460 | 0.8000 | 0.8127 |
| p/q | Mixed Interpolation | Linear Interpolation | Spline Interpolation | Cubic Interpolation |
|---|---|---|---|---|
| 0.8 | 0.4943 | 0.4820 | 0.5310 | 0.4950 |
| 0.9 | 0.4490 | 0.4140 | 0.4840 | 0.4550 |
| 1.1 | 0.6247 | 0.6300 | 0.6690 | 0.6700 |
| 1.2 | 0.7027 | 0.6620 | 0.7490 | 0.7030 |
| p/q | Mixed Interpolation | Linear Interpolation | Spline Interpolation | Cubic Interpolation |
|---|---|---|---|---|
| 0.8 | 0.7061 | 0.7237 | 0.7061 | 0.6841 |
| 0.9 | 0.6876 | 0.6771 | 0.6619 | 0.6673 |
| 1.1 | 0.6902 | 0.6514 | 0.6806 | 0.6817 |
| 1.2 | 0.6657 | 0.6745 | 0.6201 | 0.6675 |
| p/q | Proposed Method | Wang et al. [16] | Hou et al. [15] |
|---|---|---|---|
| 0.6 | 0.9813 | 0.6593 | 0.7120 |
| 0.7 | 0.9407 | 0.5573 | 0.6884 |
| 0.8 | 0.8553 | 0.4943 | 0.7061 |
| 0.9 | 0.6960 | 0.4490 | 0.6876 |
| 1.1 | 0.7413 | 0.6247 | 0.6902 |
| 1.2 | 0.8127 | 0.7027 | 0.6657 |
| 1.3 | 0.9093 | 0.7090 | 0.6603 |
| 1.4 | 0.9433 | 0.7617 | 0.6523 |
| 1.5 | 0.9649 | 0.7873 | 0.6346 |
| 1.6 | 0.9791 | 0.8373 | 0.6804 |
| 1.7 | 0.9902 | 0.8910 | 0.7725 |
| 1.8 | 0.9947 | 0.9447 | 0.8484 |
| 1.9 | 0.9976 | 0.9773 | 0.8863 |
| 2.0 | 0.9987 | 0.9780 | 0.8696 |
| p/q | Proposed Method at 32 kbps | Wang et al. [16] at 32 kbps | Hou et al. [15] at 32 kbps | Proposed Method at 64 kbps | Wang et al. [16] at 64 kbps | Hou et al. [15] at 64 kbps | Proposed Method at 128 kbps | Wang et al. [16] at 128 kbps | Hou et al. [15] at 128 kbps |
|---|---|---|---|---|---|---|---|---|---|
| 0.6 | 0.9980 | 0.6593 | 0.6984 | 0.9860 | 0.6330 | 0.7059 | 0.9860 | 0.6370 | 0.7179 |
| 0.7 | 0.9787 | 0.5447 | 0.6977 | 0.9407 | 0.5297 | 0.7219 | 0.9373 | 0.5273 | 0.7346 |
| 0.8 | 0.9627 | 0.4977 | 0.6968 | 0.8473 | 0.4983 | 0.7061 | 0.8440 | 0.4993 | 0.6963 |
| 0.9 | 0.9500 | 0.4387 | 0.7222 | 0.7040 | 0.4677 | 0.6702 | 0.6847 | 0.4587 | 0.6795 |
| 1.1 | 0.9540 | 0.6683 | 0.7303 | 0.7380 | 0.6367 | 0.6800 | 0.7140 | 0.6397 | 0.6809 |
| 1.2 | 0.9580 | 0.7187 | 0.7485 | 0.8273 | 0.6833 | 0.6752 | 0.8187 | 0.6840 | 0.6884 |
| 1.3 | 0.9633 | 0.7433 | 0.6549 | 0.9047 | 0.7097 | 0.6482 | 0.8980 | 0.7097 | 0.6473 |
| 1.4 | 0.9760 | 0.7733 | 0.6596 | 0.9480 | 0.7587 | 0.6596 | 0.9407 | 0.7513 | 0.6464 |
| 1.5 | 0.9813 | 0.8110 | 0.6510 | 0.9733 | 0.7943 | 0.6407 | 0.9727 | 0.7973 | 0.6299 |
| 1.6 | 0.9913 | 0.8660 | 0.6393 | 0.9880 | 0.8400 | 0.6739 | 0.9840 | 0.8403 | 0.6543 |
| 1.7 | 0.9960 | 0.9000 | 0.7939 | 0.9960 | 0.8913 | 0.7901 | 0.9920 | 0.8877 | 0.7803 |
| 1.8 | 0.9980 | 0.9547 | 0.8708 | 0.9993 | 0.8437 | 0.8377 | 0.9987 | 0.9430 | 0.8642 |
| 1.9 | 0.9987 | 0.9757 | 0.9148 | 0.9993 | 0.9737 | 0.8862 | 0.9980 | 0.9763 | 0.8796 |
| 2.0 | 0.9993 | 0.9747 | 0.8900 | 0.9987 | 0.9773 | 0.8899 | 0.9993 | 0.9770 | 0.8815 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Dai, S.; Song, W.; Zhang, L.; Li, D. Exposing Speech Resampling Manipulation by Local Texture Analysis on Spectrogram Images. Electronics 2020, 9, 23. https://doi.org/10.3390/electronics9010023
Zhang Y, Dai S, Song W, Zhang L, Li D. Exposing Speech Resampling Manipulation by Local Texture Analysis on Spectrogram Images. Electronics. 2020; 9(1):23. https://doi.org/10.3390/electronics9010023
Chicago/Turabian StyleZhang, Yujin, Shuxian Dai, Wanqing Song, Lijun Zhang, and Dongmei Li. 2020. "Exposing Speech Resampling Manipulation by Local Texture Analysis on Spectrogram Images" Electronics 9, no. 1: 23. https://doi.org/10.3390/electronics9010023
APA StyleZhang, Y., Dai, S., Song, W., Zhang, L., & Li, D. (2020). Exposing Speech Resampling Manipulation by Local Texture Analysis on Spectrogram Images. Electronics, 9(1), 23. https://doi.org/10.3390/electronics9010023