Dynamic Deep Forest: An Ensemble Classification Method for Network Intrusion Detection


Abstract
:1. Introduction
2. Related Works
2.1. Mainstream Methods in NIDS
2.2. The Idea of Dynamic Deep Forest
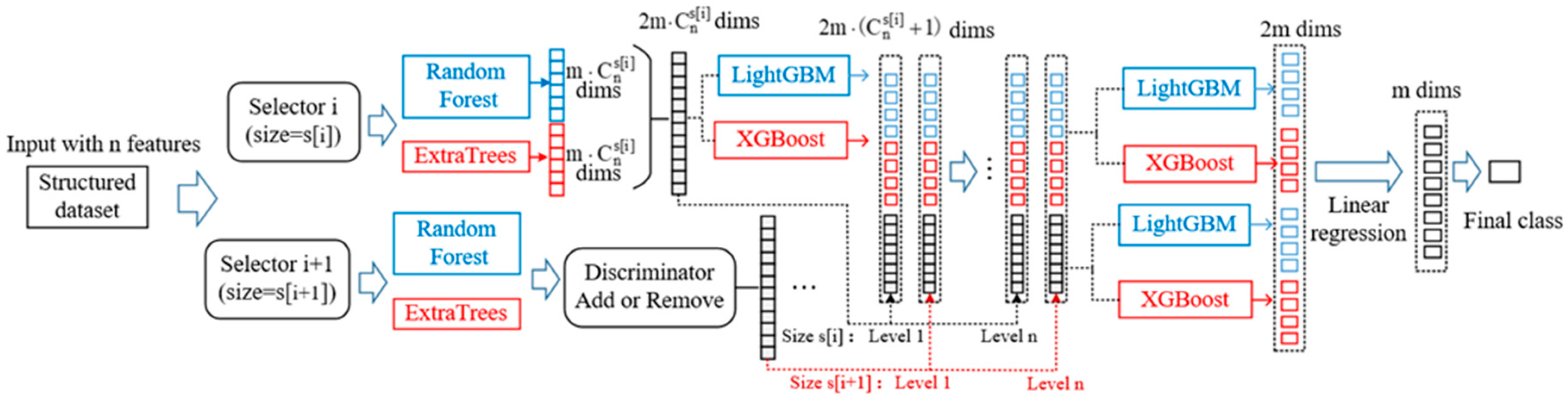
3. Details of Dynamic Deep Forest
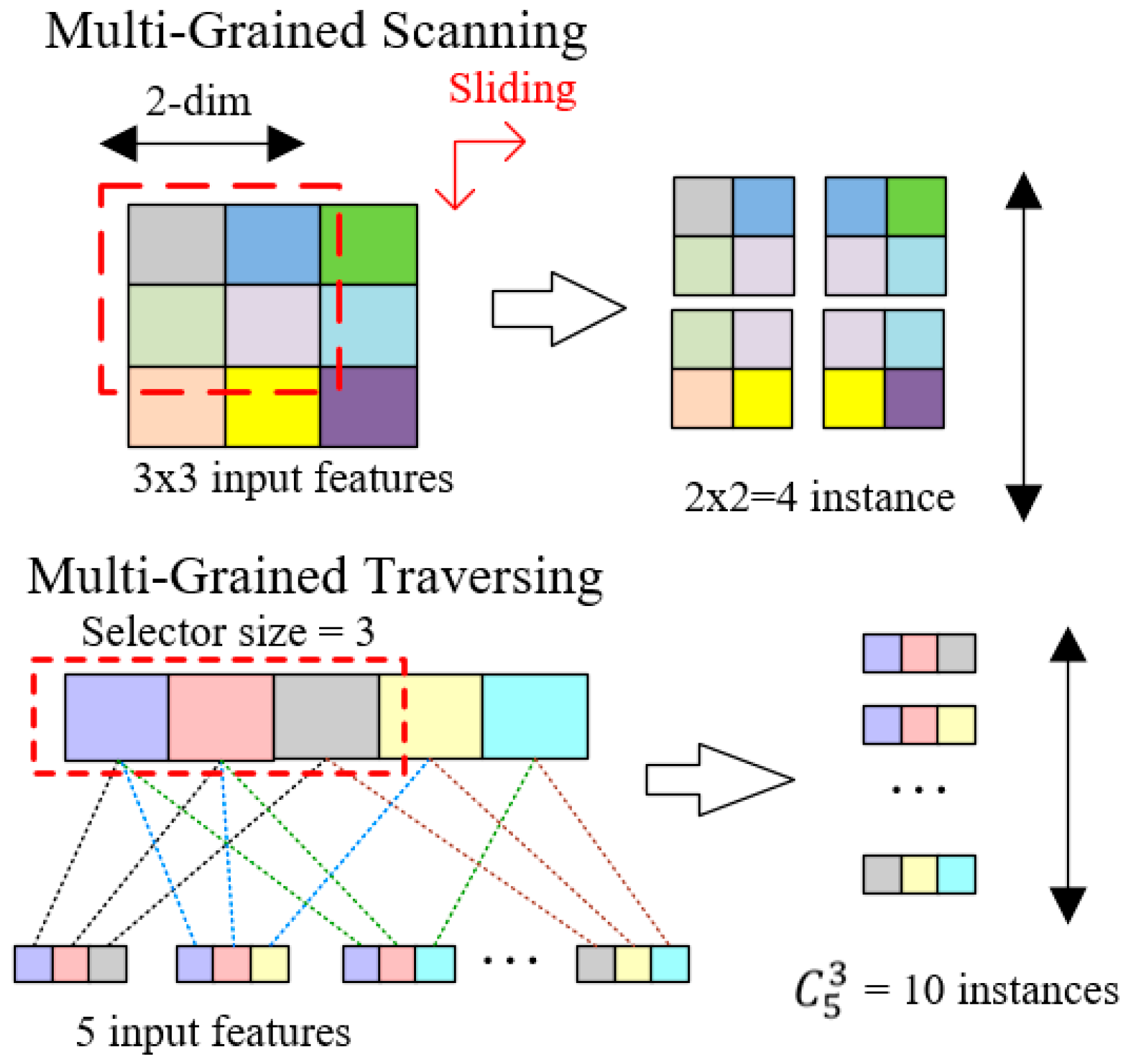
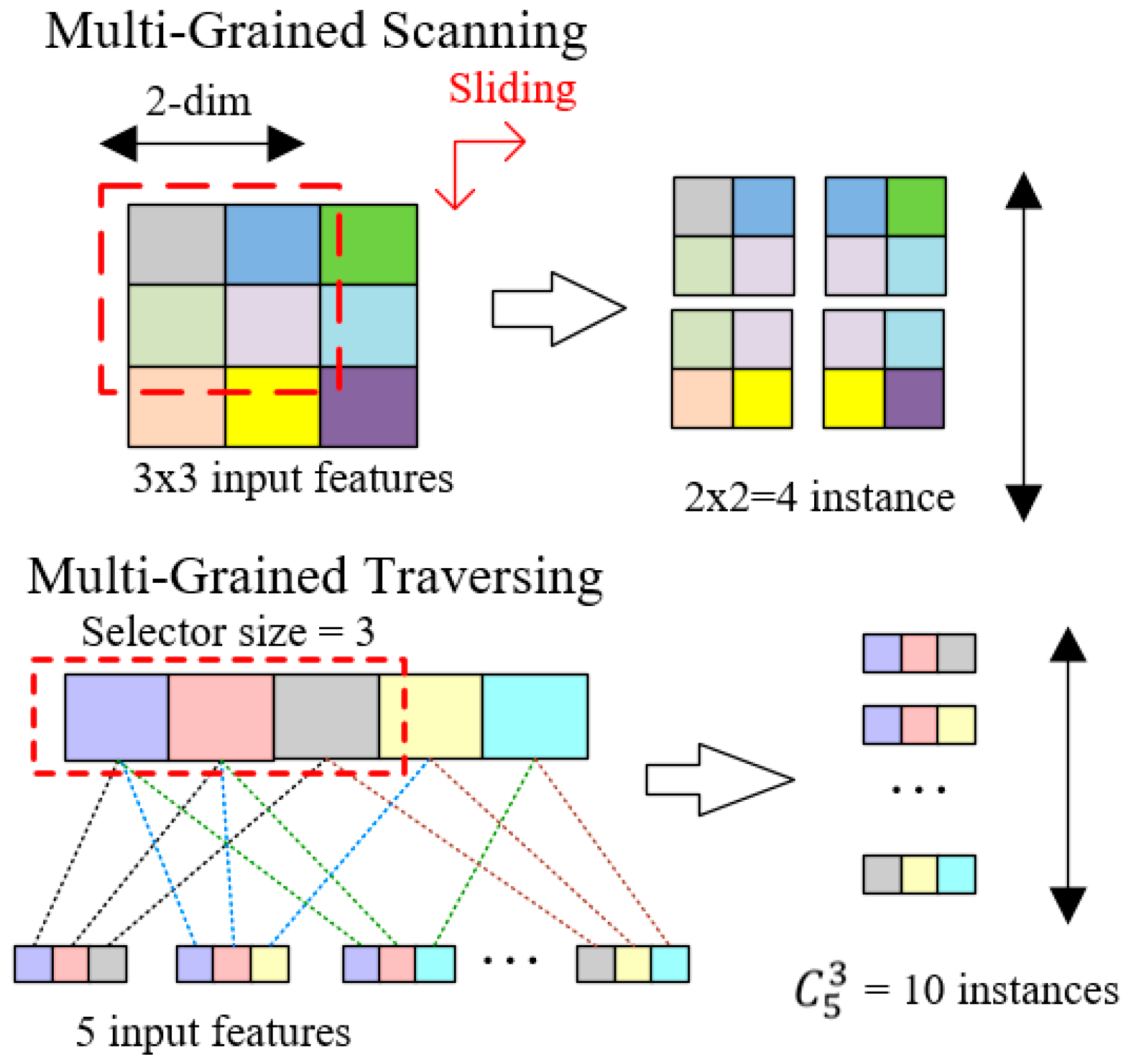
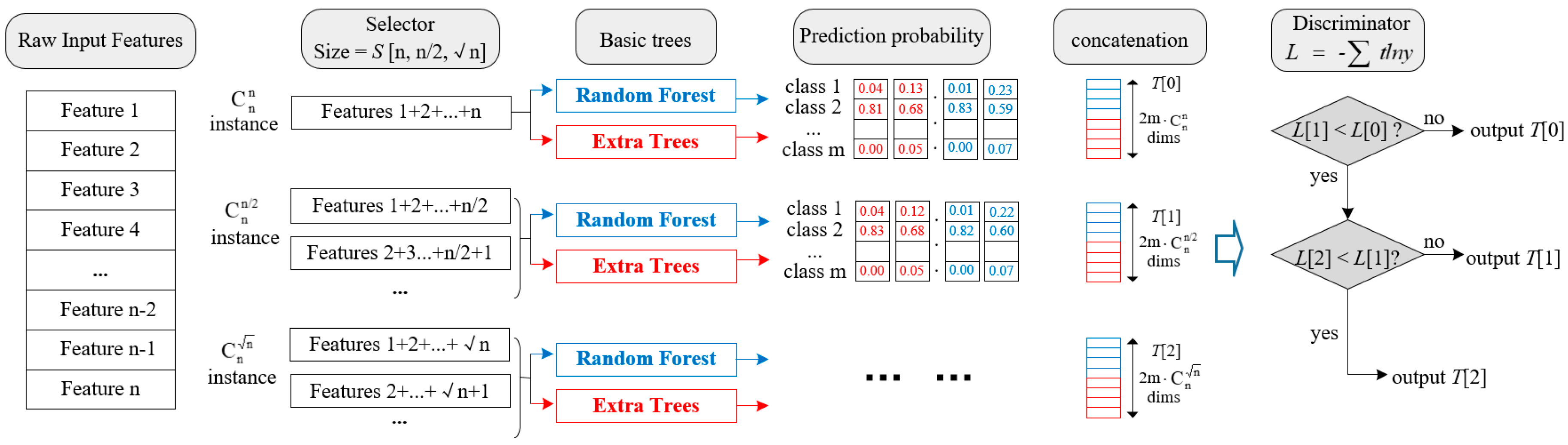
3.1. Dynamic Multi-Grained Traversing
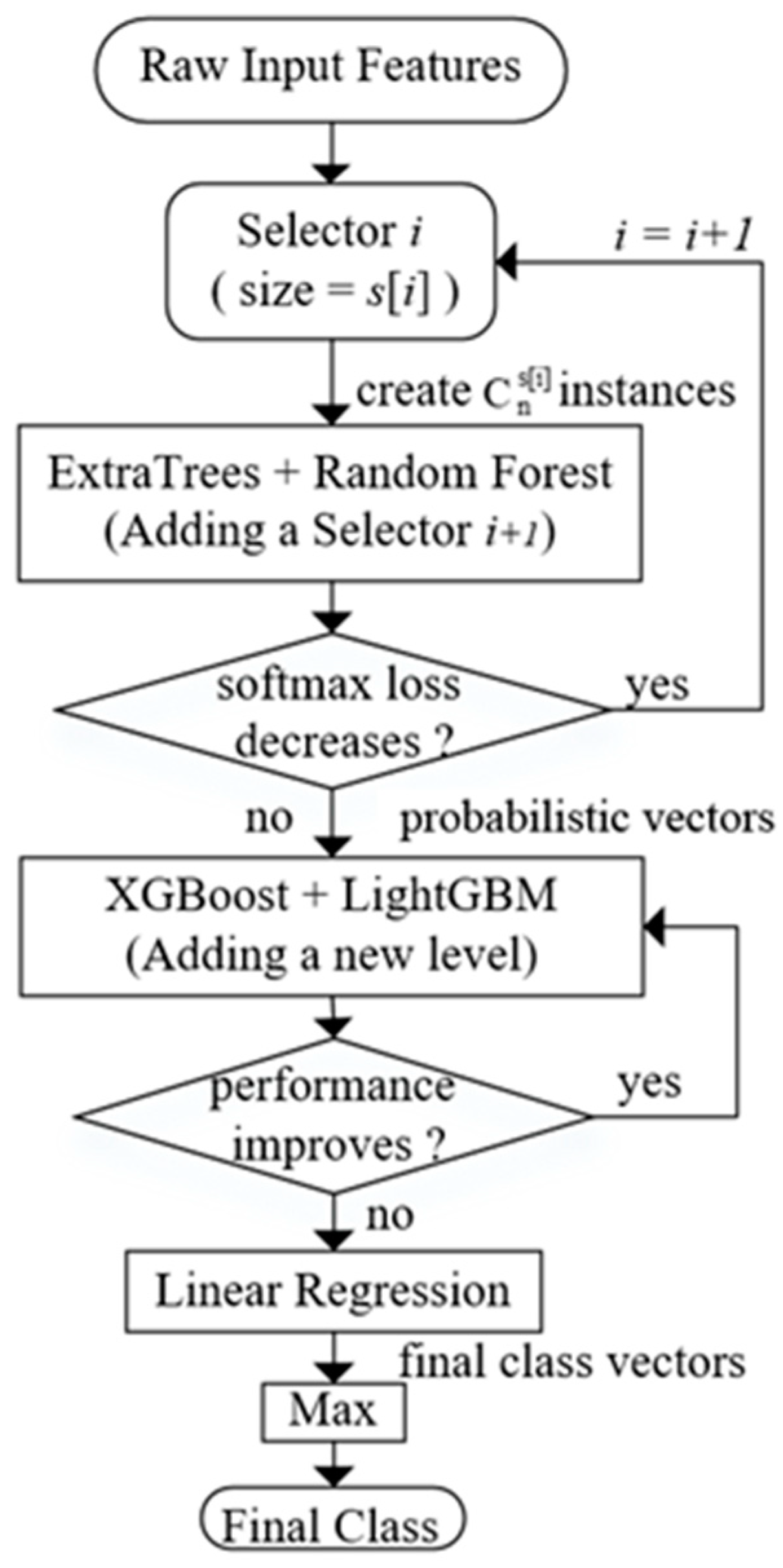
| Algorithm 1:Selectors Adding Strategy |
| Input: Raw Input Features |
| Output: Final probabilistic vectors, number of selectors |
| 1: procedure FUNCTION(Strategy) |
| 2: Initialize , i = 0. |
| 3: for each size of selectors in S do |
| 4: In selector i, size = S[i], create instances. |
| 5: Concatenate all the instances produced before, the total number of instances is . |
| 6: Compute probabilistic vector T[i] using library function of RF and ET in scikit-learn. |
| 7: Compute Loss L[i] using Equation (1) |
| 8: if (i = 0 || L[i] < L[i − 1]) continue |
| 9: else i = i − 1, break |
| 10: end if |
| 11: i = i +1 |
| 12: end for |
| 13: return T[i], i + 1 |
| 14: end procedure. |
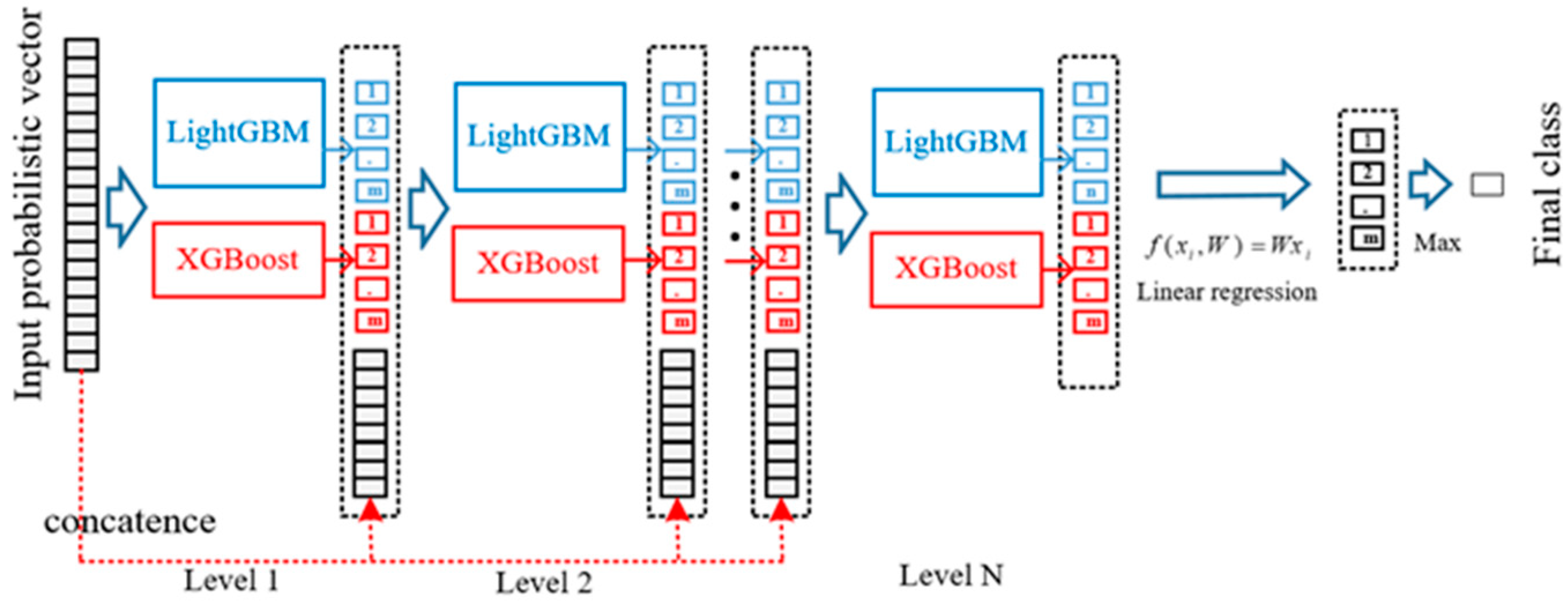
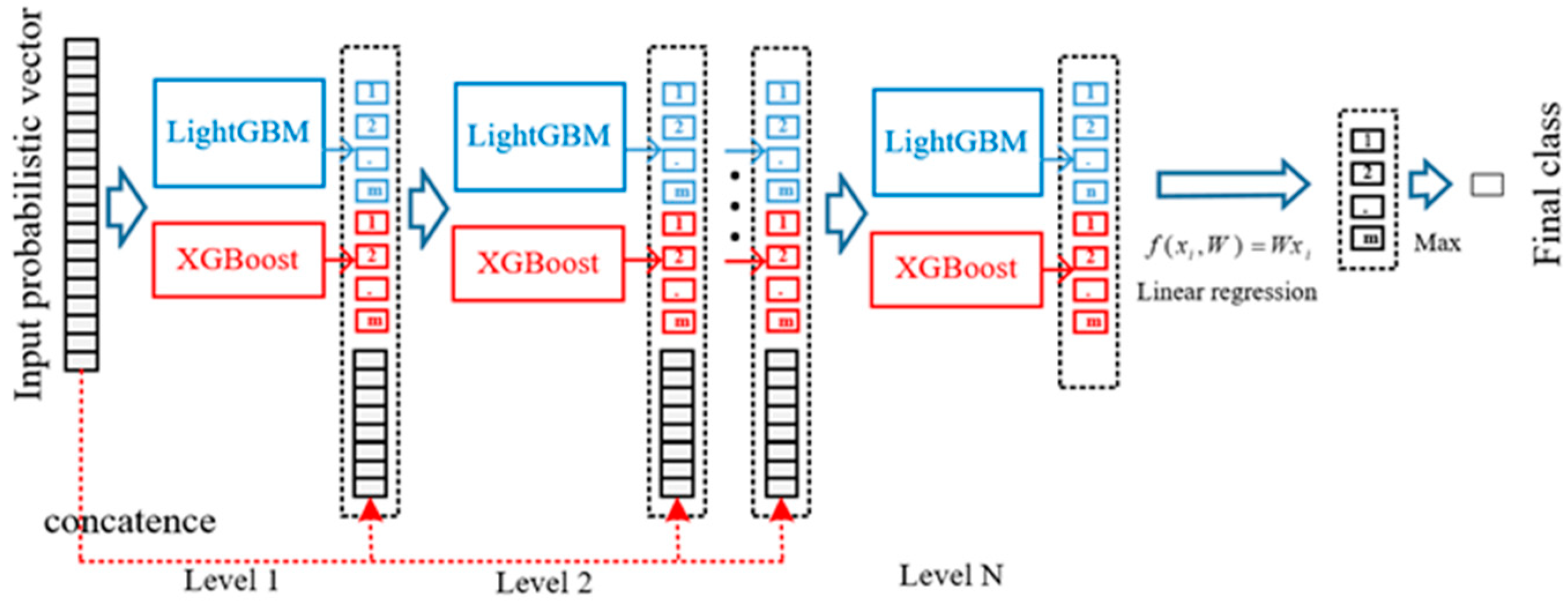
3.2. The Cascade Forest
4. Analysis of Experiments
4.1. Dataset chosen
4.2. Performance Evaluation Metrics
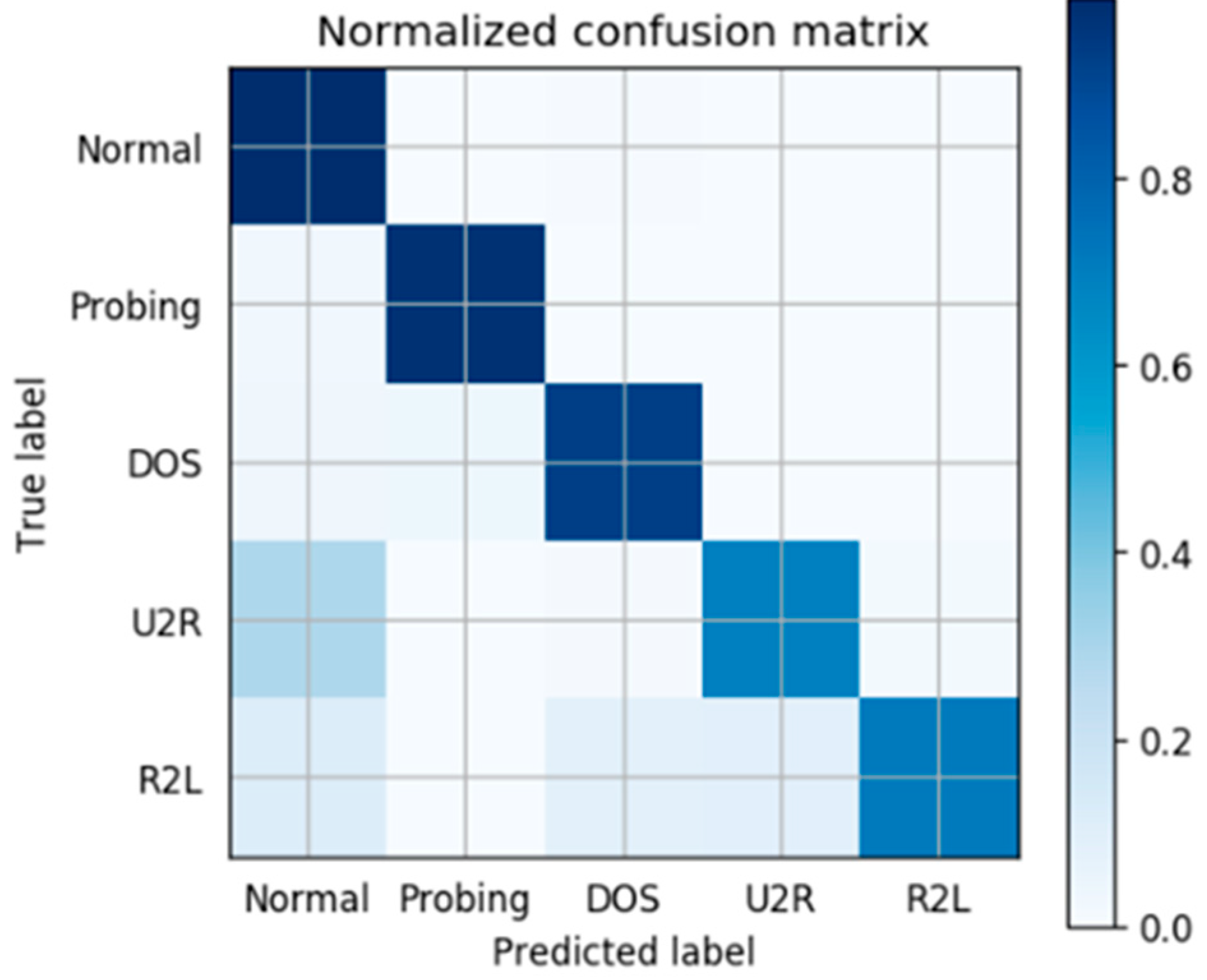
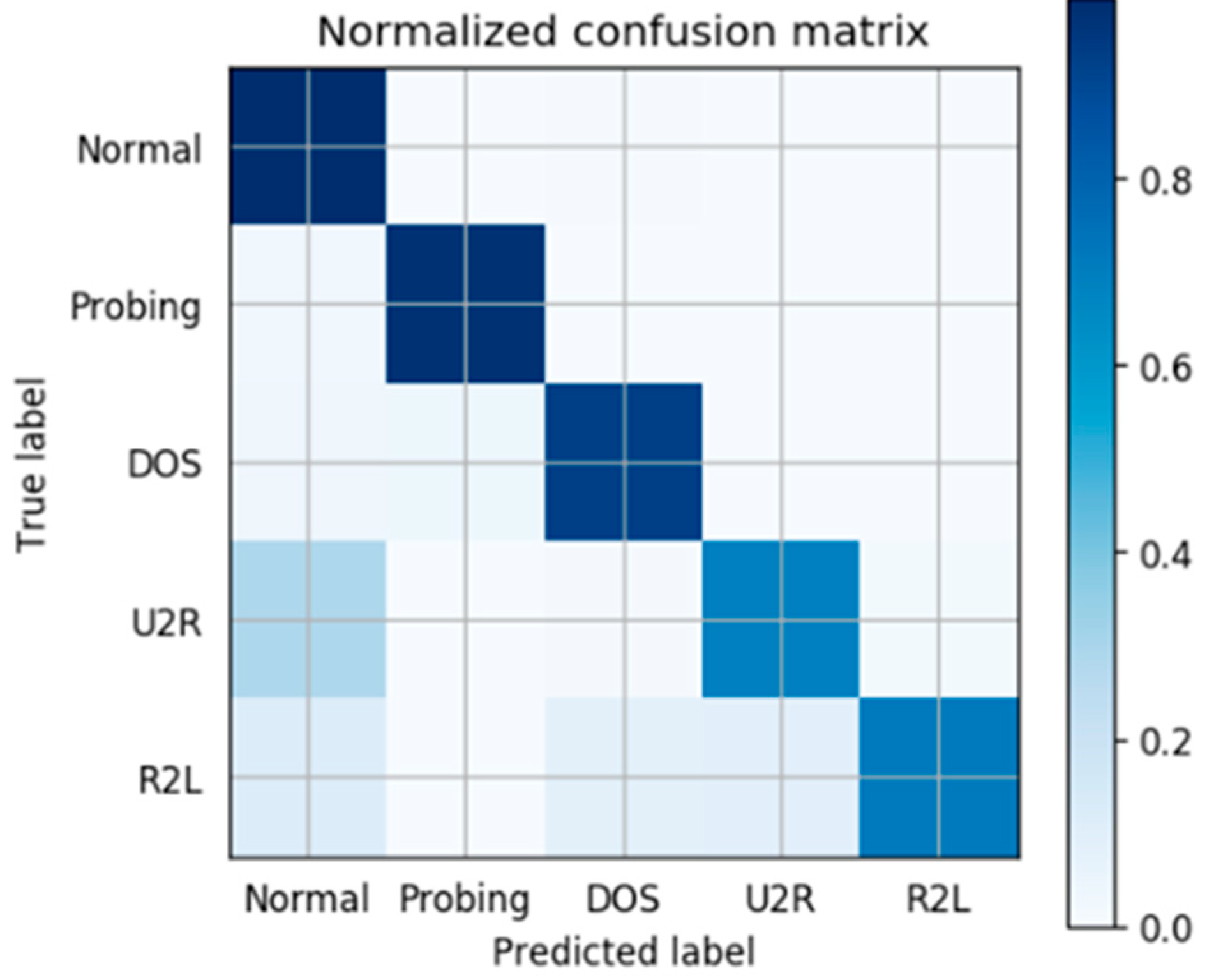
4.3. Evaluation Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, T.Y.; Wang, X.M.; Li, Z.Z.; Guo, F.Z. A survey of network anomaly visualization. Sci. China 2017, 12, 126–142. [Google Scholar] [CrossRef]
- Vigna, G.; Kemmerer, R.A. Netstat: A network-based intrusion detection system. J. Comput. Secur. 1999, 7, 37–71. [Google Scholar] [CrossRef]
- Garg, S.; Singh, A.; Batra, S.; Kumar, N.; Obaidat, M.S. EnClass: Ensemble-based classification model for network anomaly detection in massive datasets. In Proceedings of the IEEE Global Communications Conference, Singapore, 4–8 December 2018. [Google Scholar]
- Shone, N.; Ngoc, T.N.; Phai, V.D.; Shi, Q. A deep learning approach to network intrusion detection. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 2, 41–50. [Google Scholar] [CrossRef]
- Garg, S.; Batra, S. A novel ensembled technique for anomaly detection. Int. J. Commun. Syst. 2016, 30, e3248. [Google Scholar] [CrossRef]
- Aburomman, A.A.; Reaz, M.B.I. Ensemble of binary SVM classifiers based on PCA and LDA feature extraction for intrusion detection. In Proceedings of the 2016 IEEE Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Xi’an, China, 3–5 October 2017; pp. 636–640. [Google Scholar]
- Wang, Y.; Shen, Y.; Zhang, G. Research on intrusion detection model using ensemble learning methods. In Proceedings of the 2016 7th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 26–28 August 2016; pp. 422–425. [Google Scholar]
- Kim, J.; Shin, N.; Jo, S.Y.; Kim, S.H. Method of intrusion detection using deep neural network. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju, Korea, 13–16 February 2017; pp. 313–316. [Google Scholar]
- Xu, S.; Wang, J. Dynamic extreme learning machine for data stream classification. Neurocomputing 2017, 238, 433–449. [Google Scholar] [CrossRef]
- Javaid, A.; Niyaz, Q.; Sun, W.; Alam, M. A deep learning approach for network intrusion detection system. In Proceedings of the 9th EAI International Conference on Bio-Inspired Information and Communications Technologies, New York, NY, USA, 3–5 December 2016; pp. 21–26. [Google Scholar]
- Breiman, L. Bagging predictors machine learning. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Johnson, R.W. An introduction to the bootstrap. In Teaching Statistics; John Wiley: New York, NY, USA, 2001. [Google Scholar]
- Kontschieder, P.; Fiterau, M.; Criminisi, A.; Bulo, S.R. Deep neural decision forests. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2016; pp. 1467–1475. [Google Scholar]
- Guo, C.; Berkhahn, F. Entity embeddings of categorical variables. arXiv 2016, arXiv:1604.06737. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. In Proceedings of the European Conference on Computational Learning Theory, Barcelona, Spain, 13–15 March 1995; Volume 55, pp. 23–37. [Google Scholar]
- Zhang, P.; Bui, T.D.; Suen, C.Y. A novel cascade ensemble classifier system with a high recognition performance on handwritten digits. Pattern Recognit. 2007, 40, 3415–3429. [Google Scholar] [CrossRef]
- Hong, J.S. Cascade Boosting of Predictive Models. U.S. Patent 6546379 B1, 8 March 2003. [Google Scholar]
- Zhou, Z.H. Ensemble Methods: Foundations and Algorithms; Taylor Francis: Milton Park, UK, 2012; Volume 8, pp. 77–79. [Google Scholar]
- Zhou, Z.H.; Feng, J. Deep forest: Towards an alternative to deep neural networks. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, Melbourne, Australia, 19–25 August 2017; pp. 3553–3559. [Google Scholar]
- Chen, T.Q.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Ke, G.T.; Meng, Q.; Finley, T. Lightgbm: A highly efficient gradient boosting decision tree. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 3146–3154. [Google Scholar]
- Liaw, A.; Matthew, W. Classification and regression by randomForest. R News 2002, 2/3, 18–22. [Google Scholar]
- KDD. The UCI KDD Archive Information and Computer Science. 1999. Available online: https://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on October 28, 1999).
- Elkan, C. Results of the KDD’99 classifier learning. ACM SIGKDD Explor. 2000, 1, 63–64. [Google Scholar] [CrossRef]
- Alrawashdeh, K.; Purdy, C. Toward an online anomaly intrusion detection system based on deep learning. In Proceedings of the 2016 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2017; pp. 195–200. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Names | Description | Type |
|---|---|---|
| Duration | length (number of seconds) of the conzznection. | continuous |
| Protocol_type | type of the protocol, e.g., tcp, udp, etc. | discrete |
| Service | network service on the destination, e.g., http, telnet. | discrete |
| Src_bytes | number of data bytes from source to destination. | continuous |
| Dst_bytes | number of data bytes from destination to source. | continuous |
| flag | normal or error status of the connection. | discrete |
| land | 1 if connection is from/to the same host/port; 0 otherwise | discrete |
| Attack Types | Description |
|---|---|
| Dos | denial-of-service, e.g., syn flood; |
| U2R | unauthorized access to local superuser (root) privileges, e.g., various “buffer overflo” attacks; |
| R2L | unauthorized access from a remote machine, e.g., guessing password; |
| Probing | surveillance and other probing, e.g., port scanning. |
| Normal | normal traffic data without attacks |
| Normal | Probing | Dos | U2R | R2L | |
|---|---|---|---|---|---|
| Normal | 0 | 1 | 2 | 2 | 2 |
| Probing | 1 | 0 | 2 | 2 | 2 |
| Dos | 2 | 1 | 0 | 2 | 2 |
| U2R | 3 | 2 | 2 | 0 | 2 |
| R2L | 4 | 2 | 2 | 2 | 0 |
| Attack Types | Precision | Recall | F1_score | False Alarm | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DDF | XGB | DBN | DDF | XGB | DBN | DDF | XGB | DBN | DDF | XGB | DBN | |
| Normal | 0.726 | 0.720 | 1.000 | 0.995 | 0.985 | 0.880 | 0.840 | 0.832 | 0.937 | 0.091 | 0.089 | 0.009 |
| DOS | 0.999 | 0.990 | 1.000 | 0.973 | 0.962 | 0.956 | 0.986 | 0.985 | 0.978 | 0.003 | 0.003 | 0.243 |
| Probing | 0.899 | 0.837 | 1.000 | 0.786 | 0.806 | 0.730 | 0.839 | 0.821 | 0.844 | 0.001 | 0.002 | 0.184 |
| R2L | 0.976 | 0.980 | 0.000 | 0.021 | 0.030 | 0.000 | 0.040 | 0.077 | 0.000 | 0.000 | 0.000 | 0.000 |
| U2R | 0.403 | 0.633 | 0.000 | 0.118 | 0.029 | 0.000 | 0.183 | 0.064 | 0.000 | 0.000 | 0.000 | 0.000 |
| Total | 0.917 | 0.896 | 0.881 | 0.862 | 0.849 | 0.806 | 0.831 | 0.814 | 0.841 | 0.028 | 0.029 | 0.194 |
| Method | Accuracy | Training Time (s) |
|---|---|---|
| Dynamic Deep Forest | 0.927 | 256.4 |
| XGBoost | 0.915 | 198.2 |
| Deep Belief Network | 0.806 | 27330 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, B.; Wang, J.; Zhu, Y.; Yang, T. Dynamic Deep Forest: An Ensemble Classification Method for Network Intrusion Detection. Electronics 2019, 8, 968. https://doi.org/10.3390/electronics8090968
Hu B, Wang J, Zhu Y, Yang T. Dynamic Deep Forest: An Ensemble Classification Method for Network Intrusion Detection. Electronics. 2019; 8(9):968. https://doi.org/10.3390/electronics8090968
Chicago/Turabian StyleHu, Bo, Jinxi Wang, Yifan Zhu, and Tan Yang. 2019. "Dynamic Deep Forest: An Ensemble Classification Method for Network Intrusion Detection" Electronics 8, no. 9: 968. https://doi.org/10.3390/electronics8090968
APA StyleHu, B., Wang, J., Zhu, Y., & Yang, T. (2019). Dynamic Deep Forest: An Ensemble Classification Method for Network Intrusion Detection. Electronics, 8(9), 968. https://doi.org/10.3390/electronics8090968