Speech Enhancement for Secure Communication Using Coupled Spectral Subtraction and Wiener Filter



Abstract
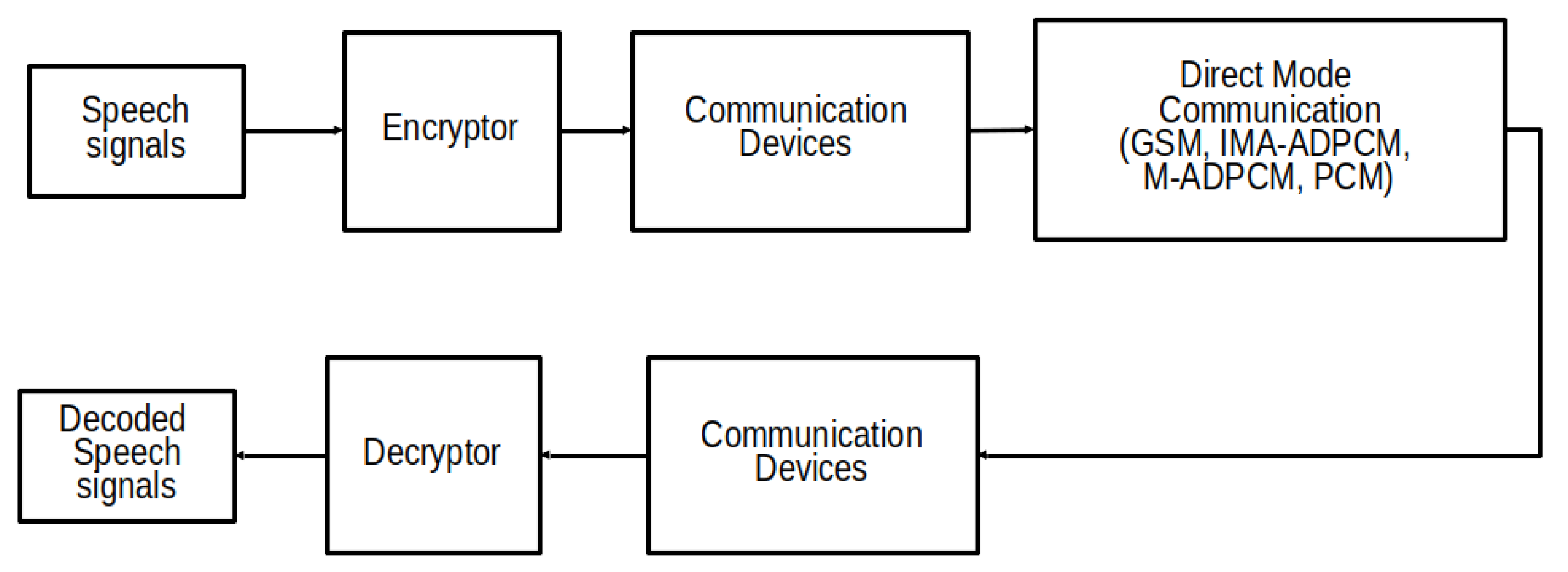
:1. Introduction
2. Speech Enhancement Methods
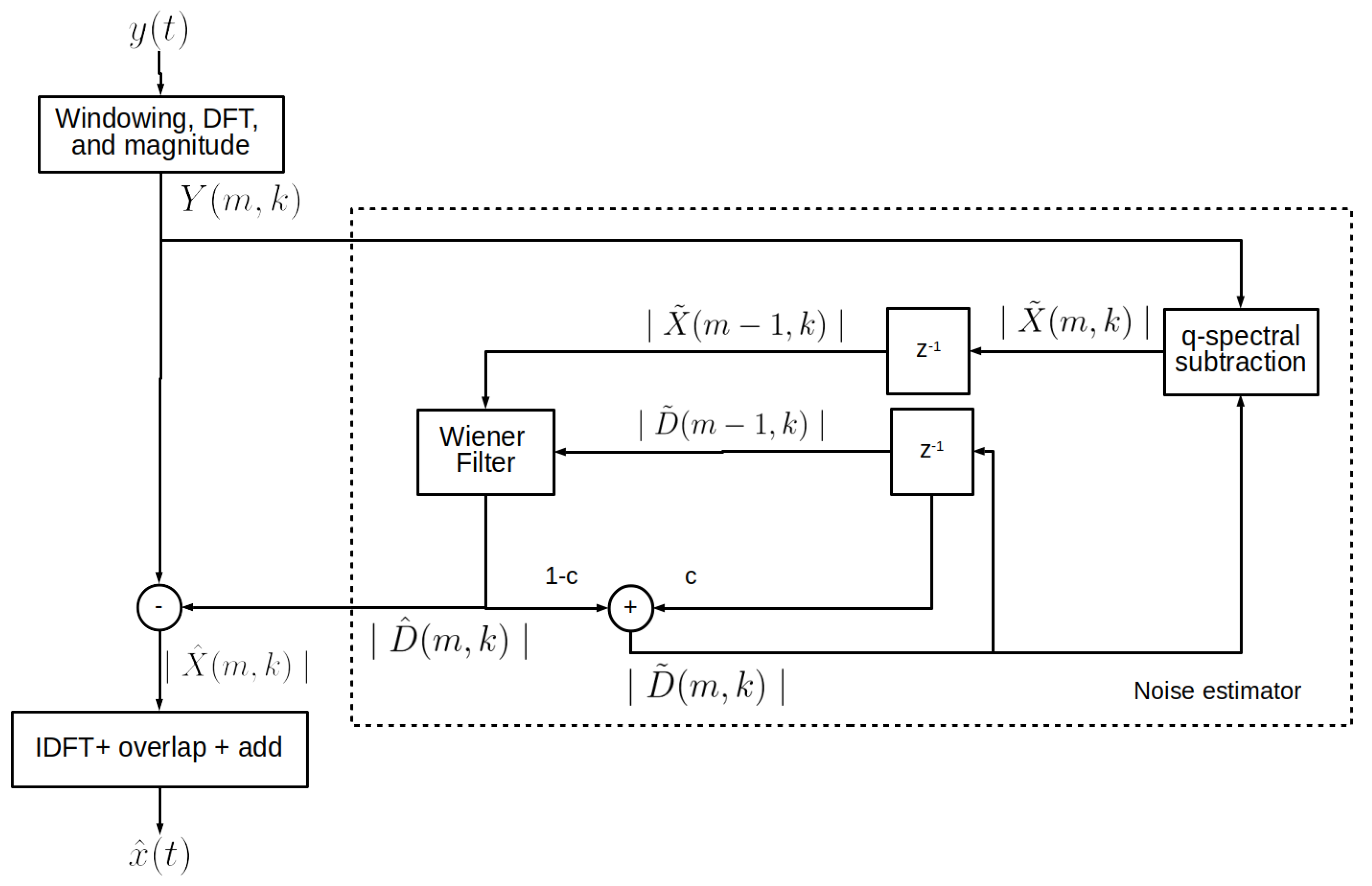
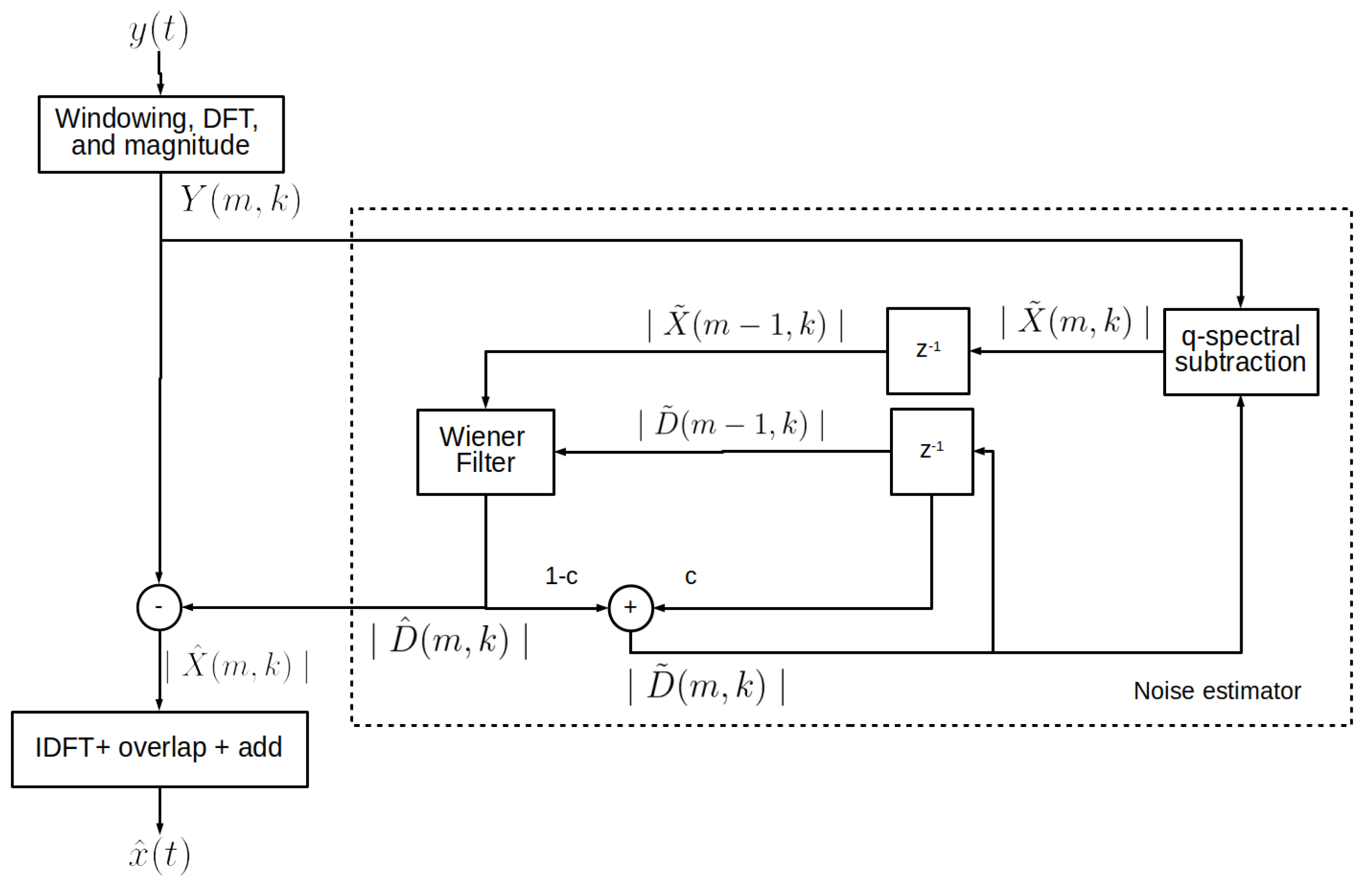
3. The Proposed Method
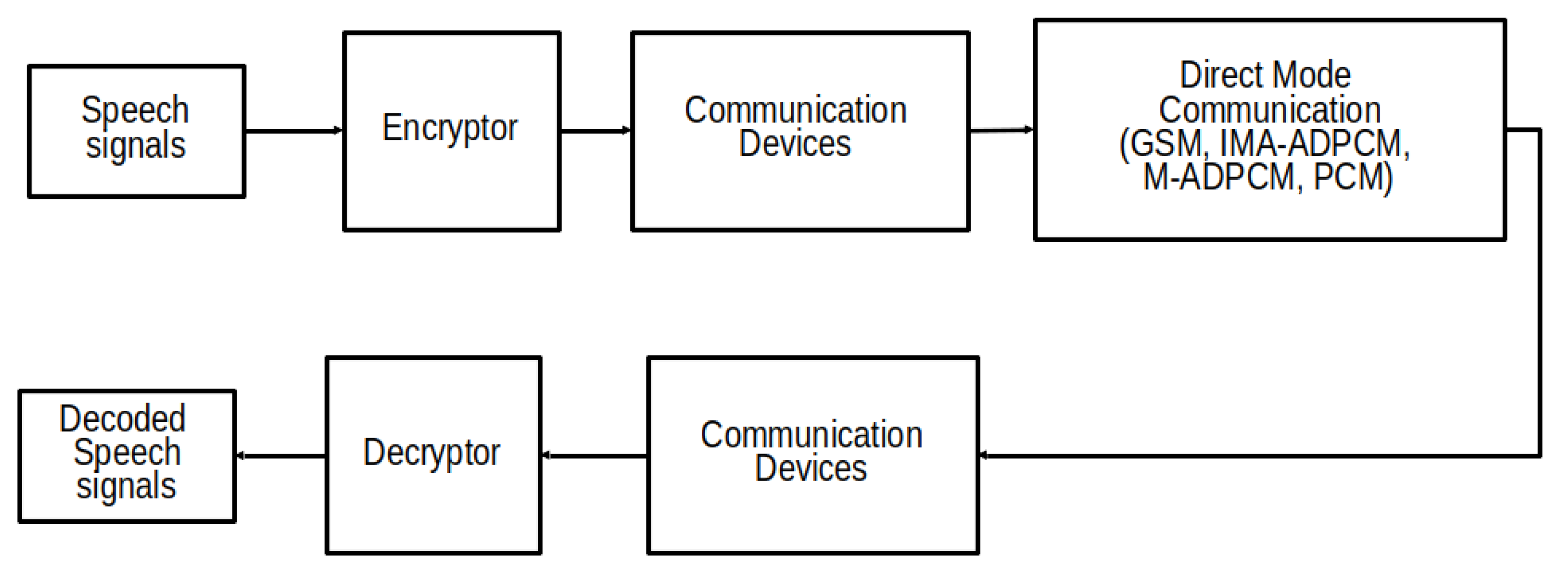
4. Experimental Setup
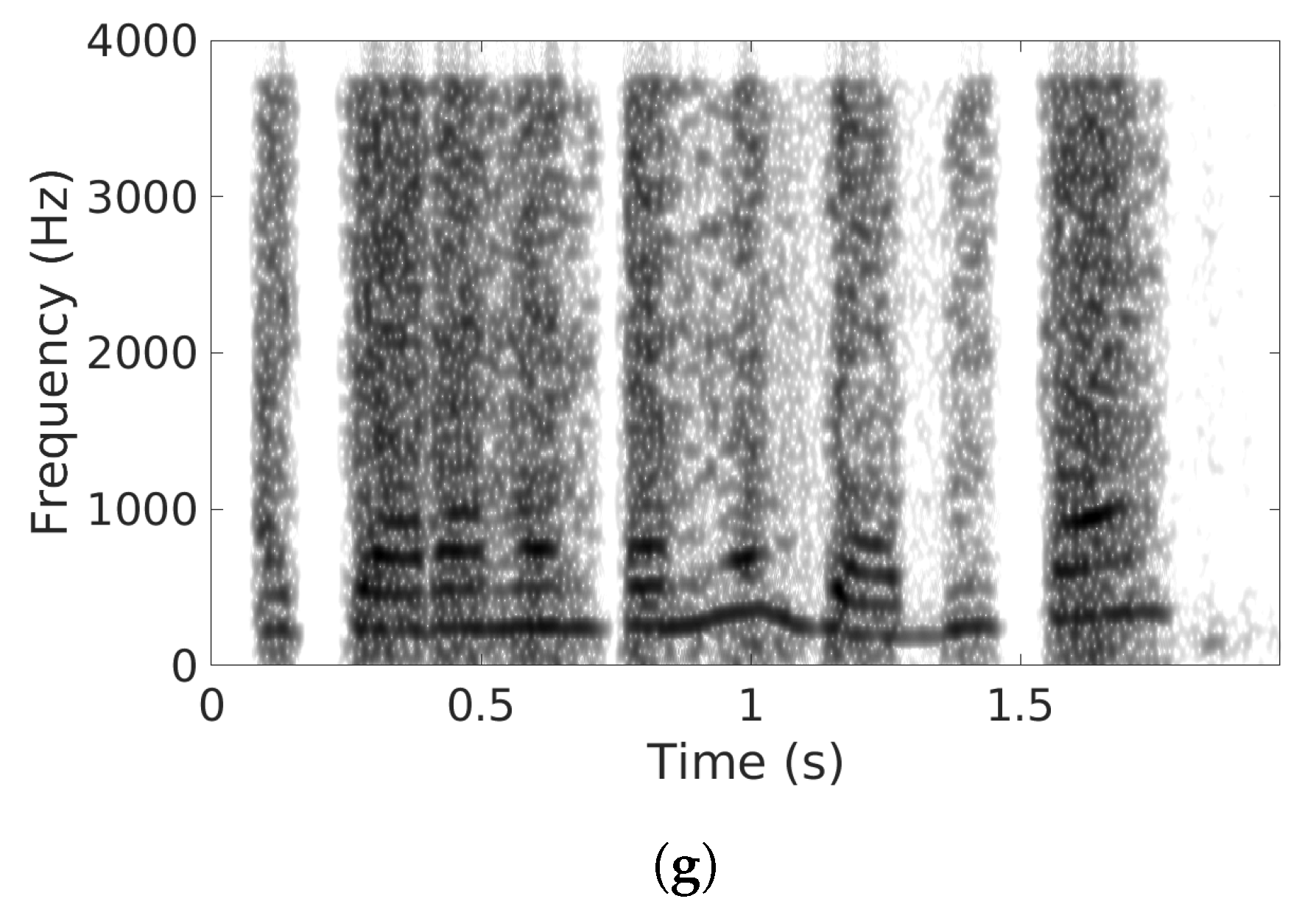
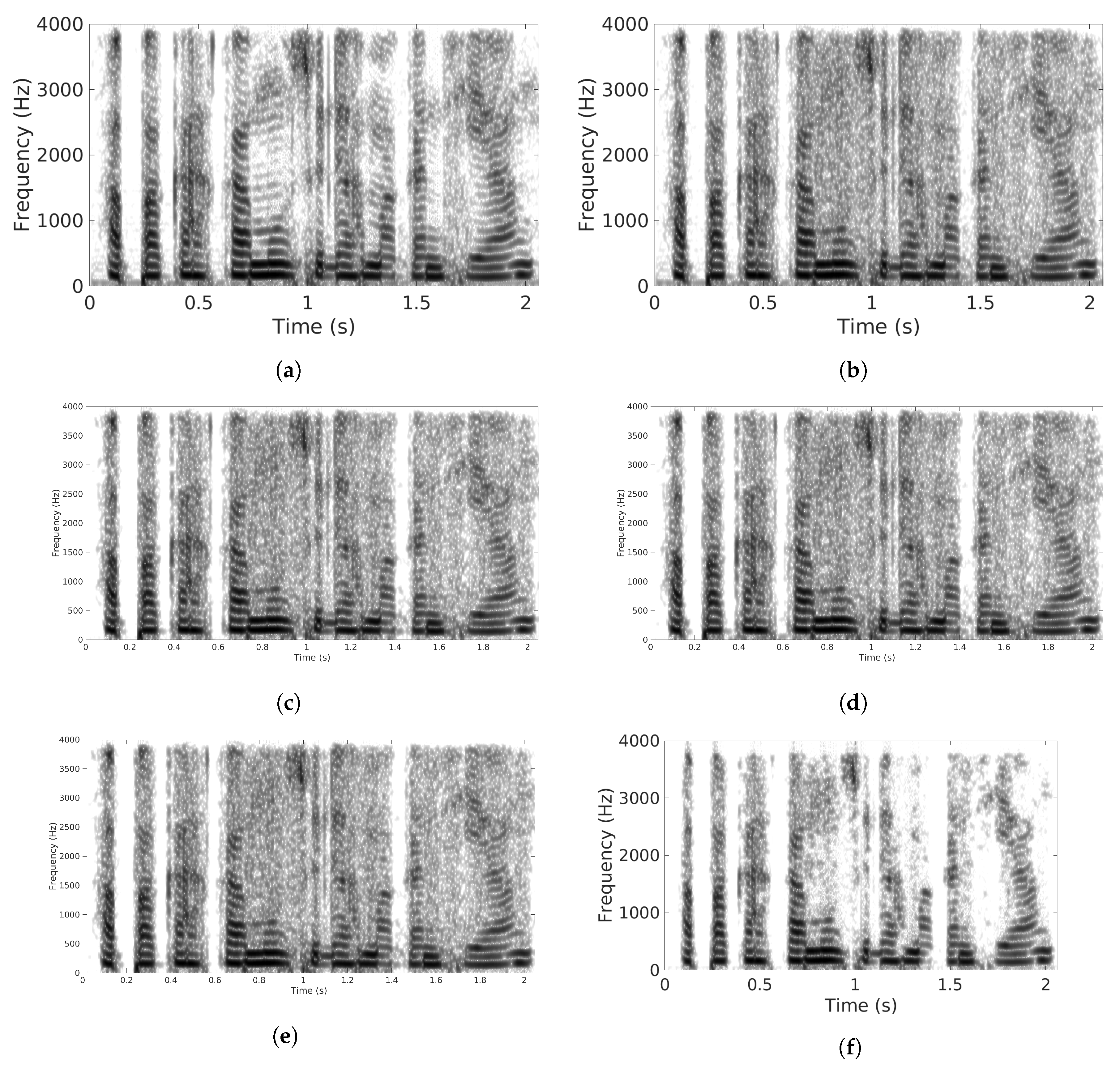
5. Results and Discussions
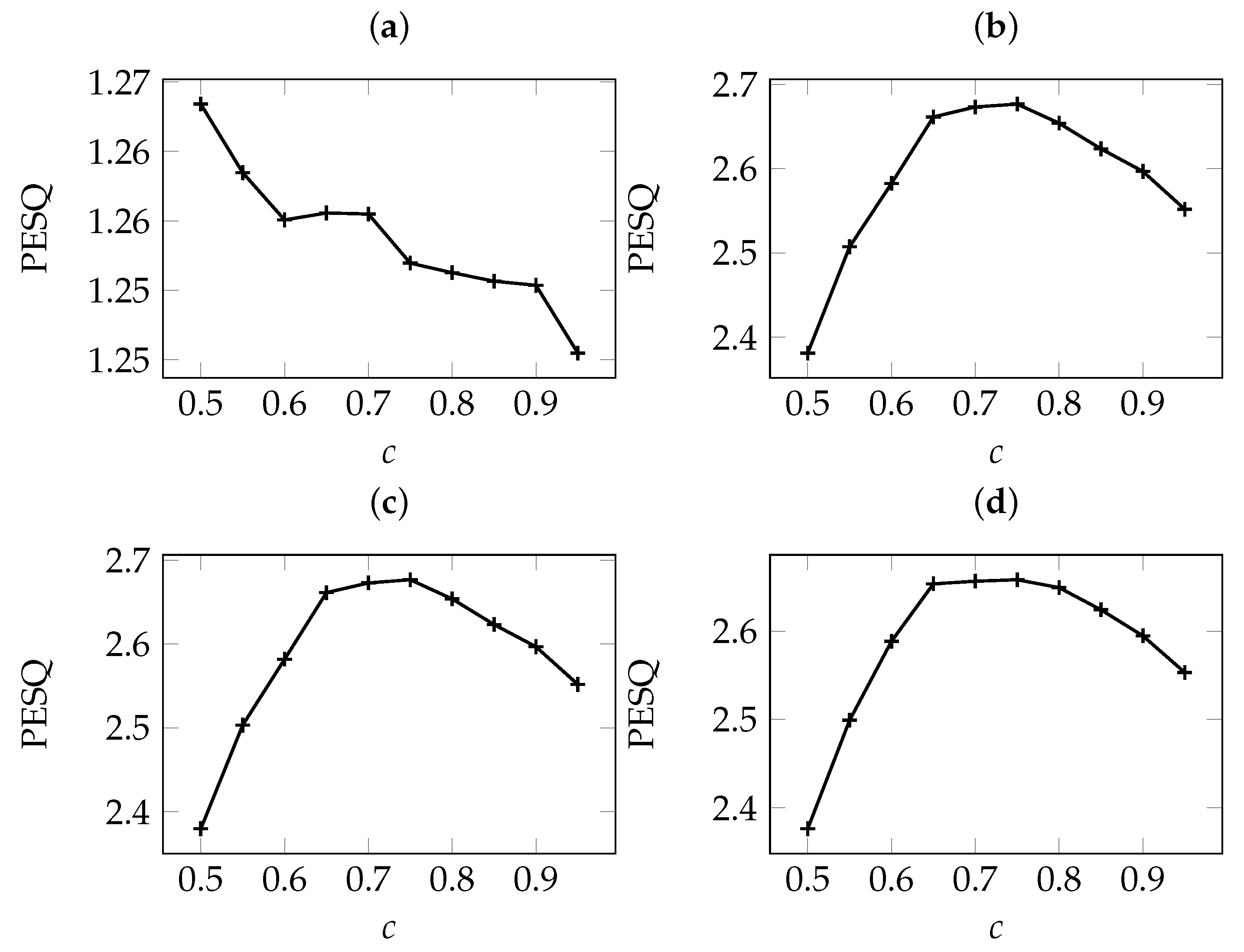
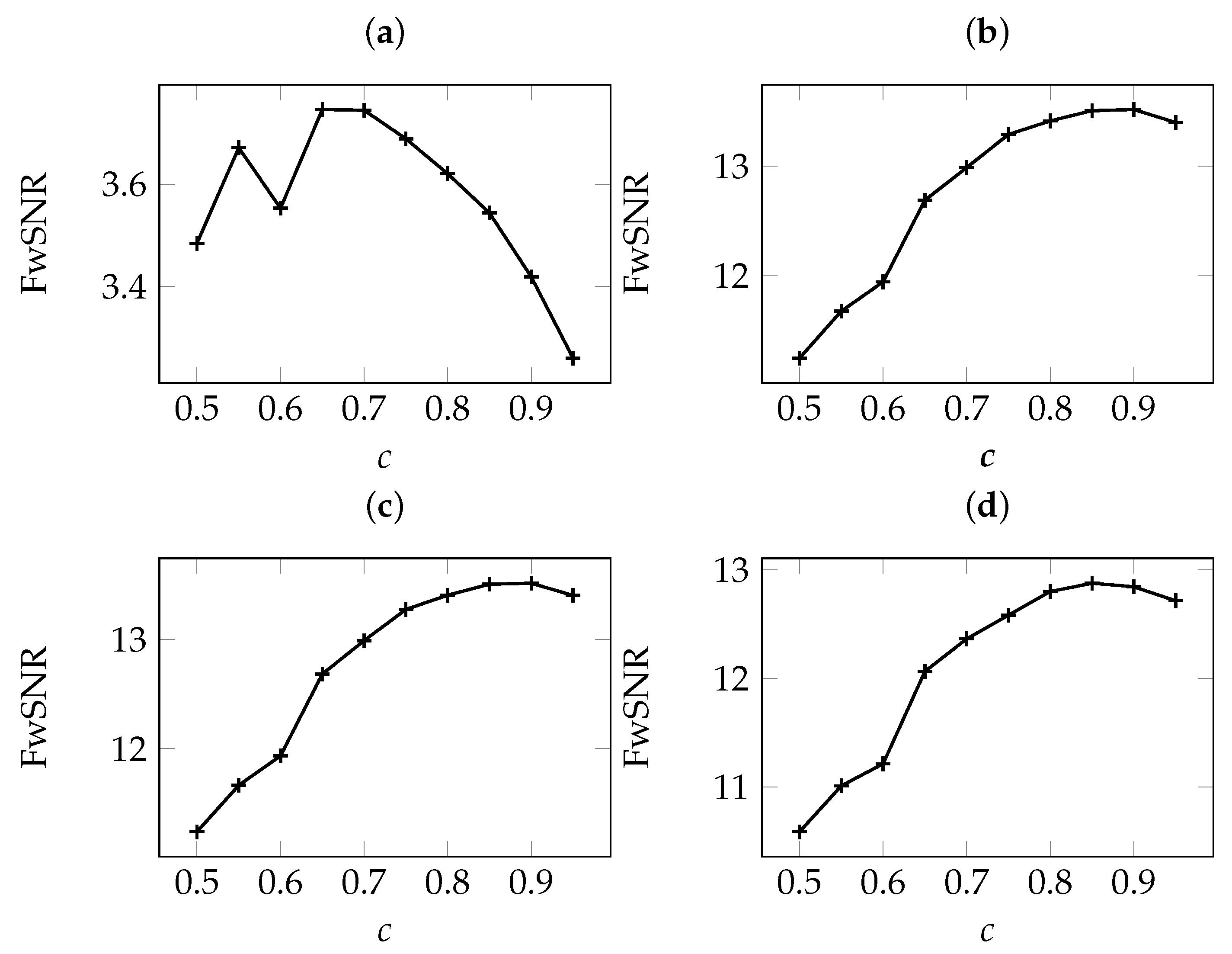
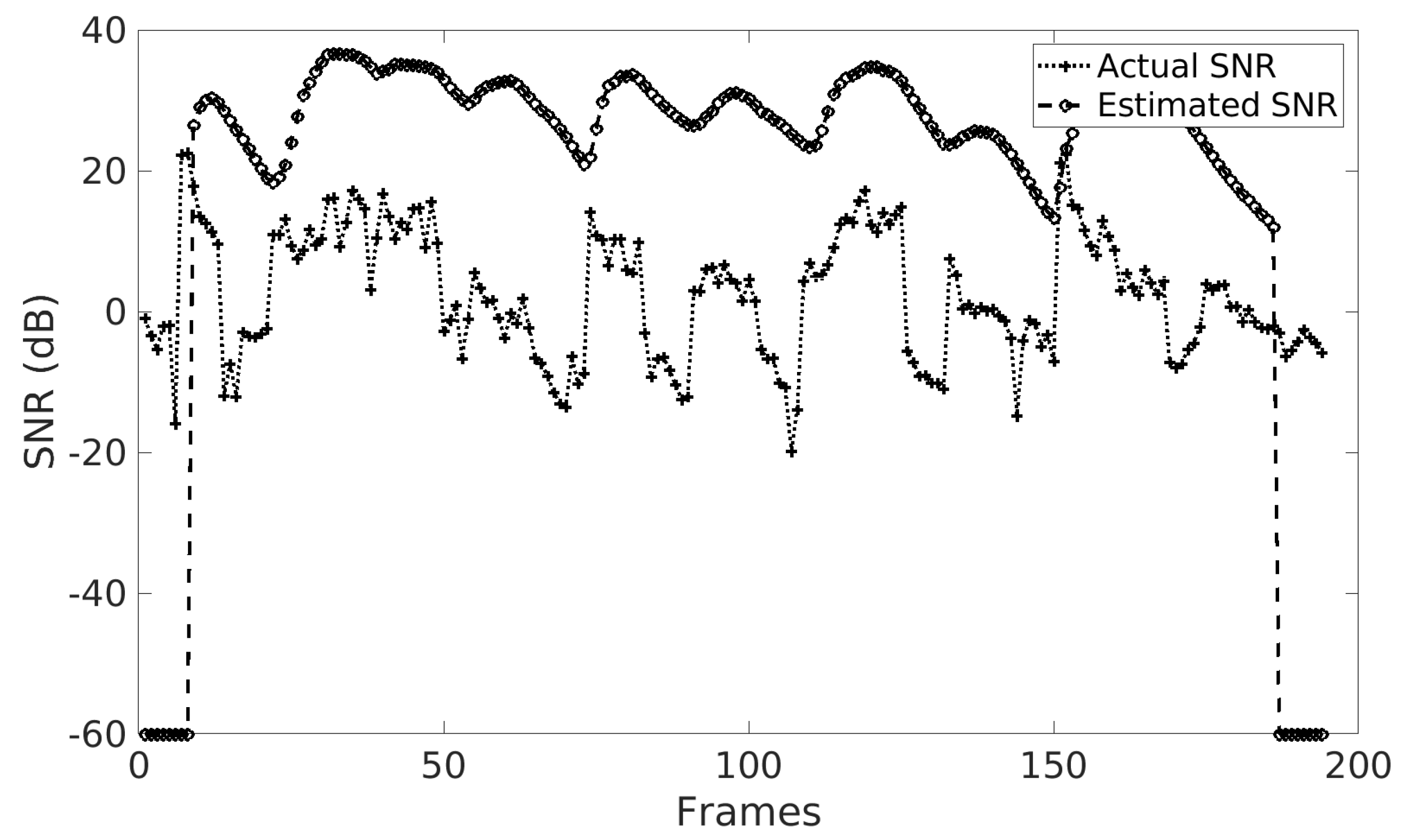
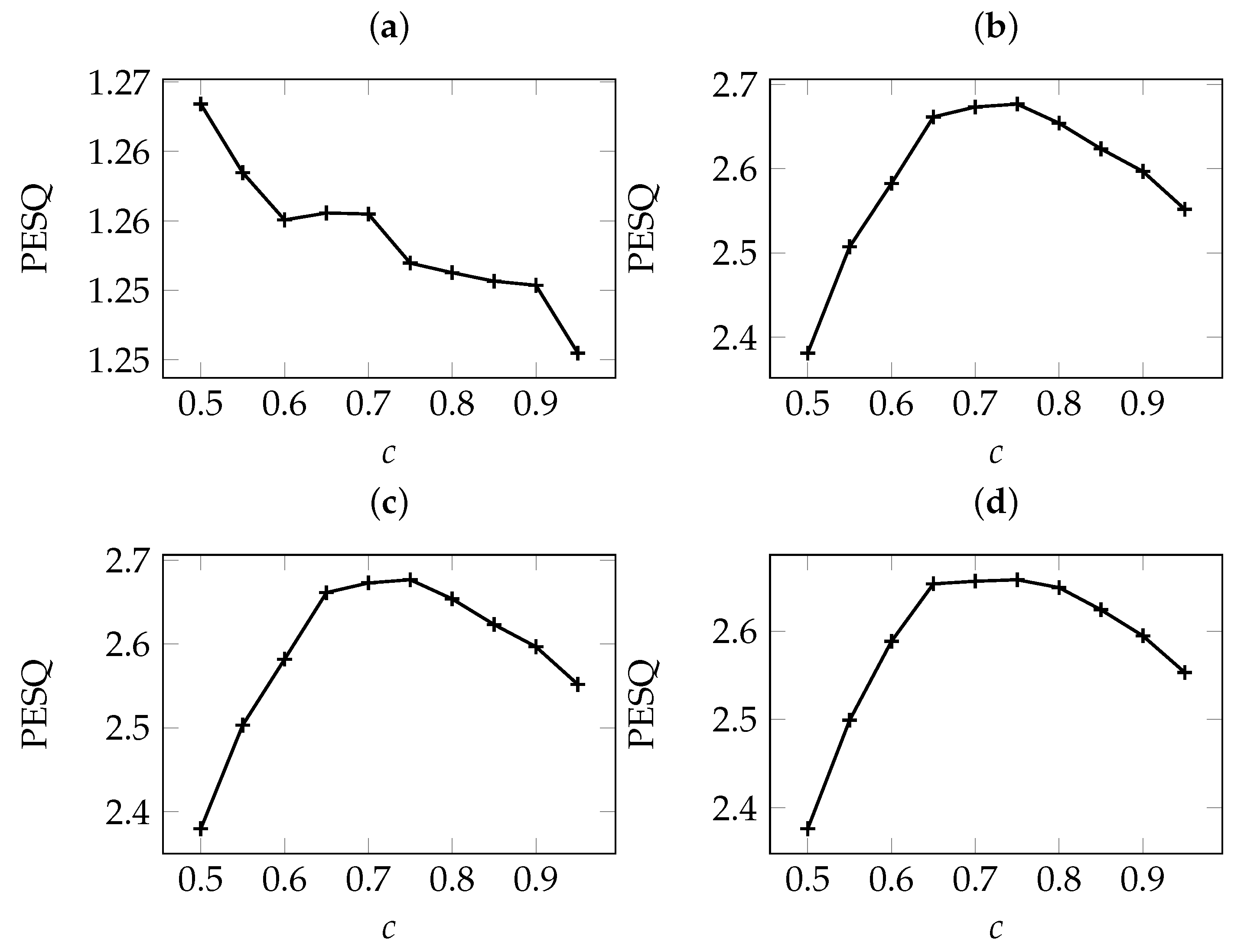
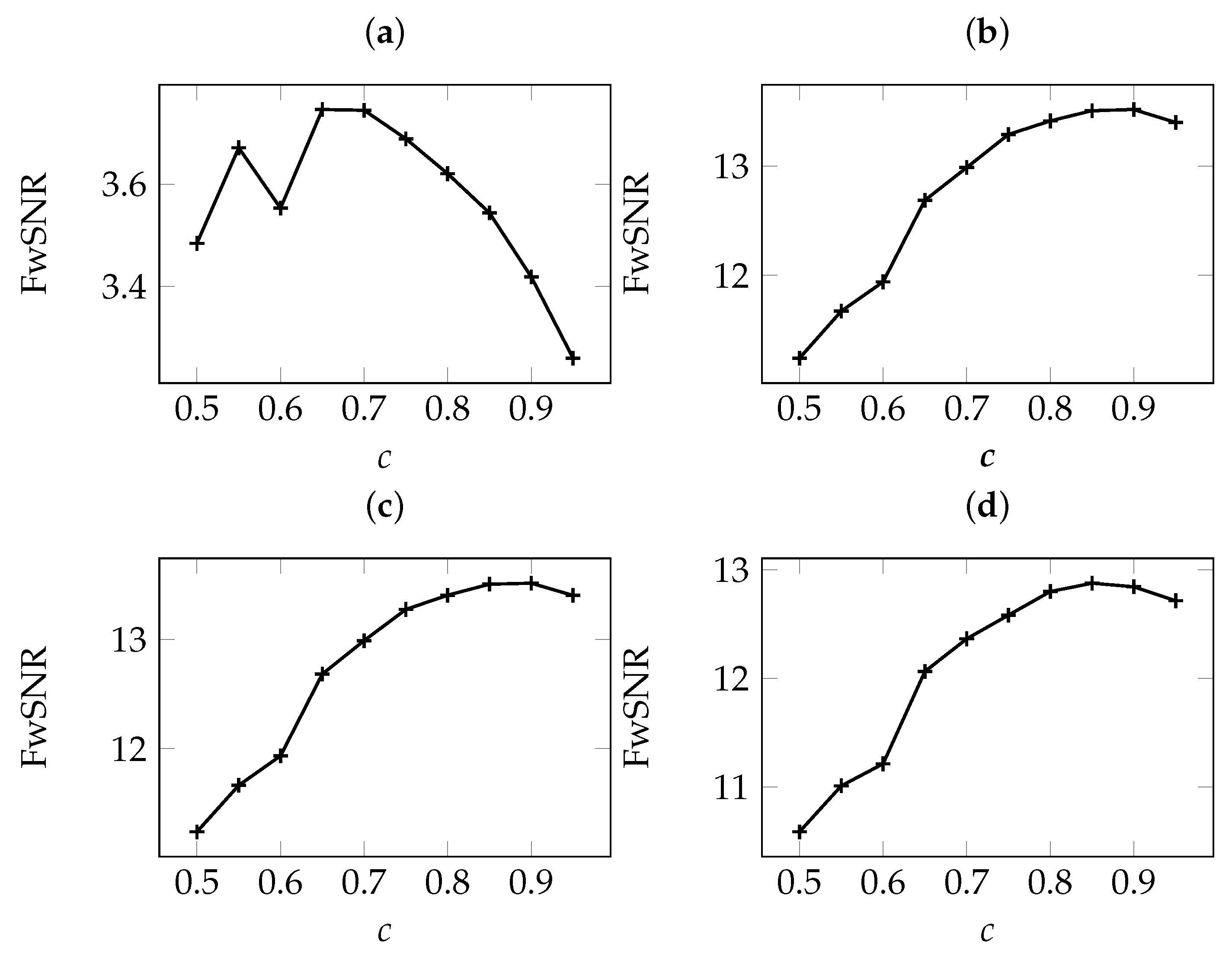
5.1. The Effect of Adaptation Speed
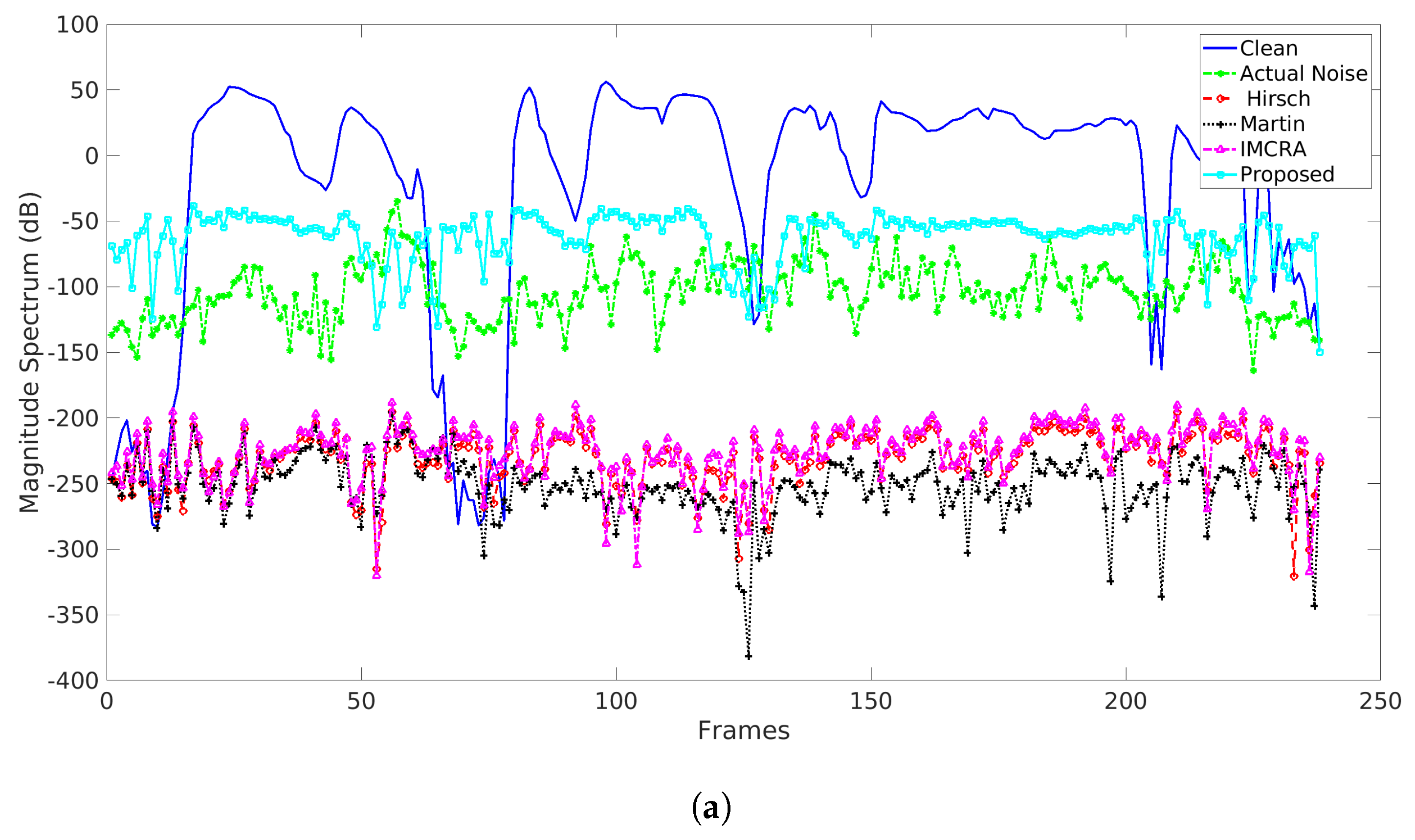
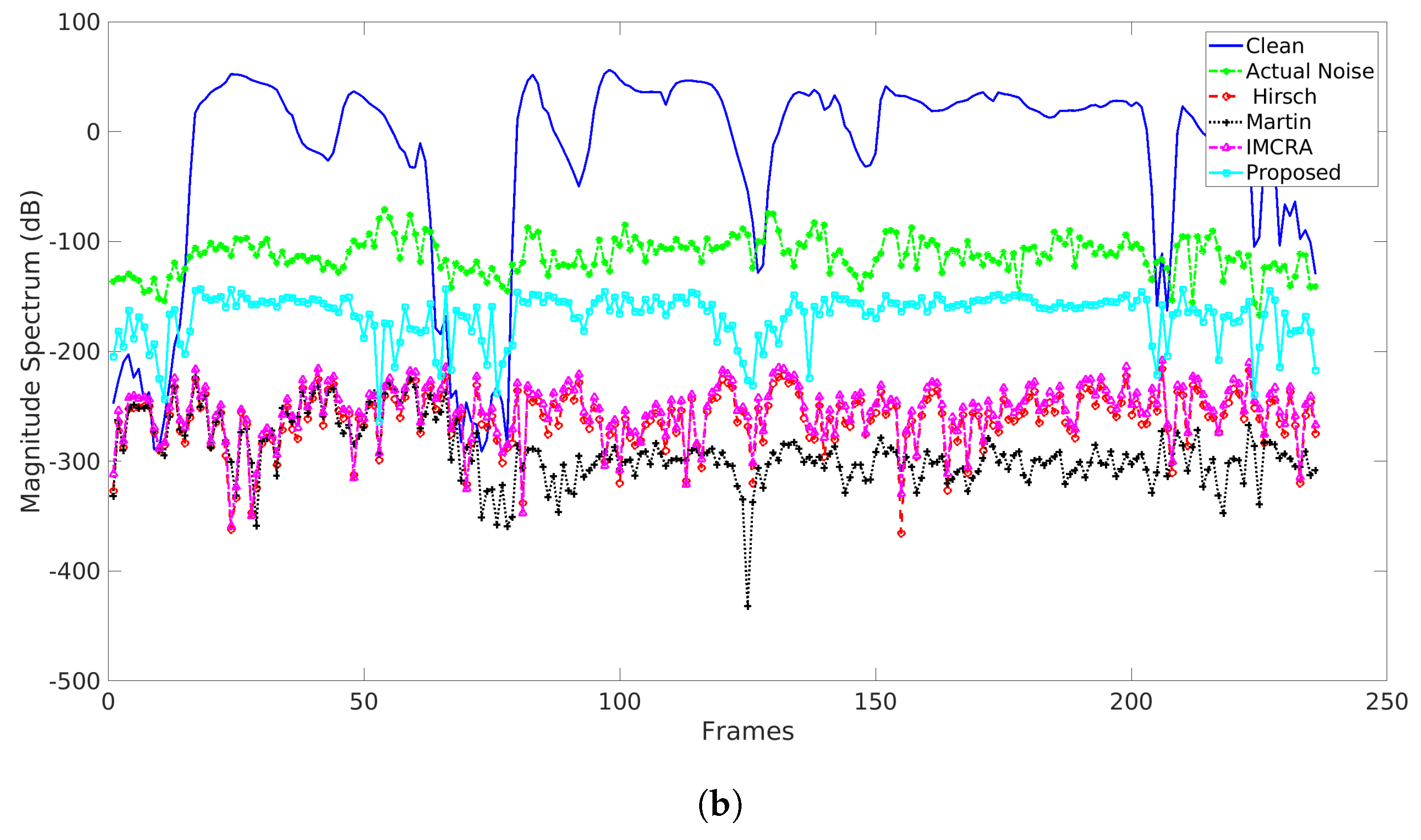
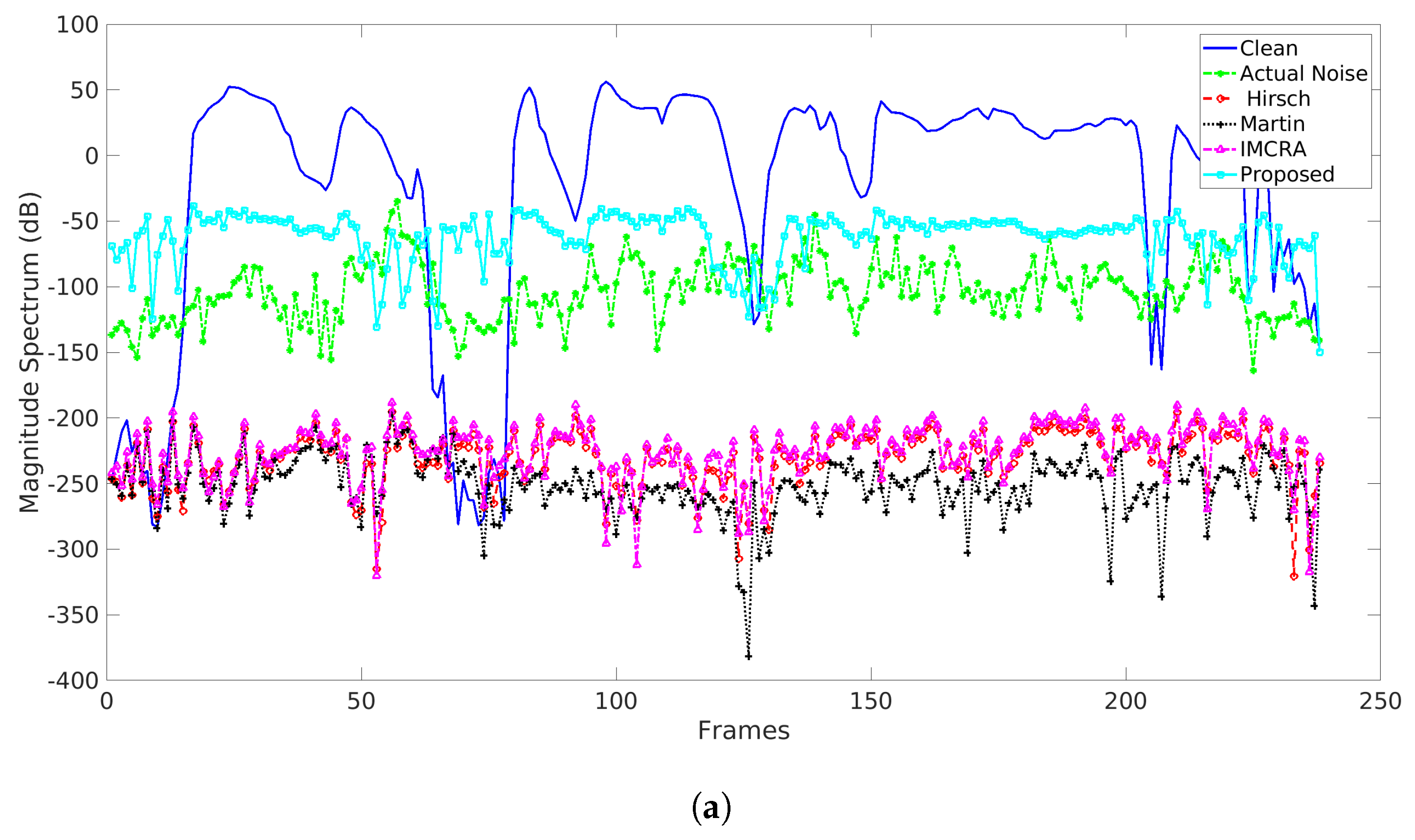
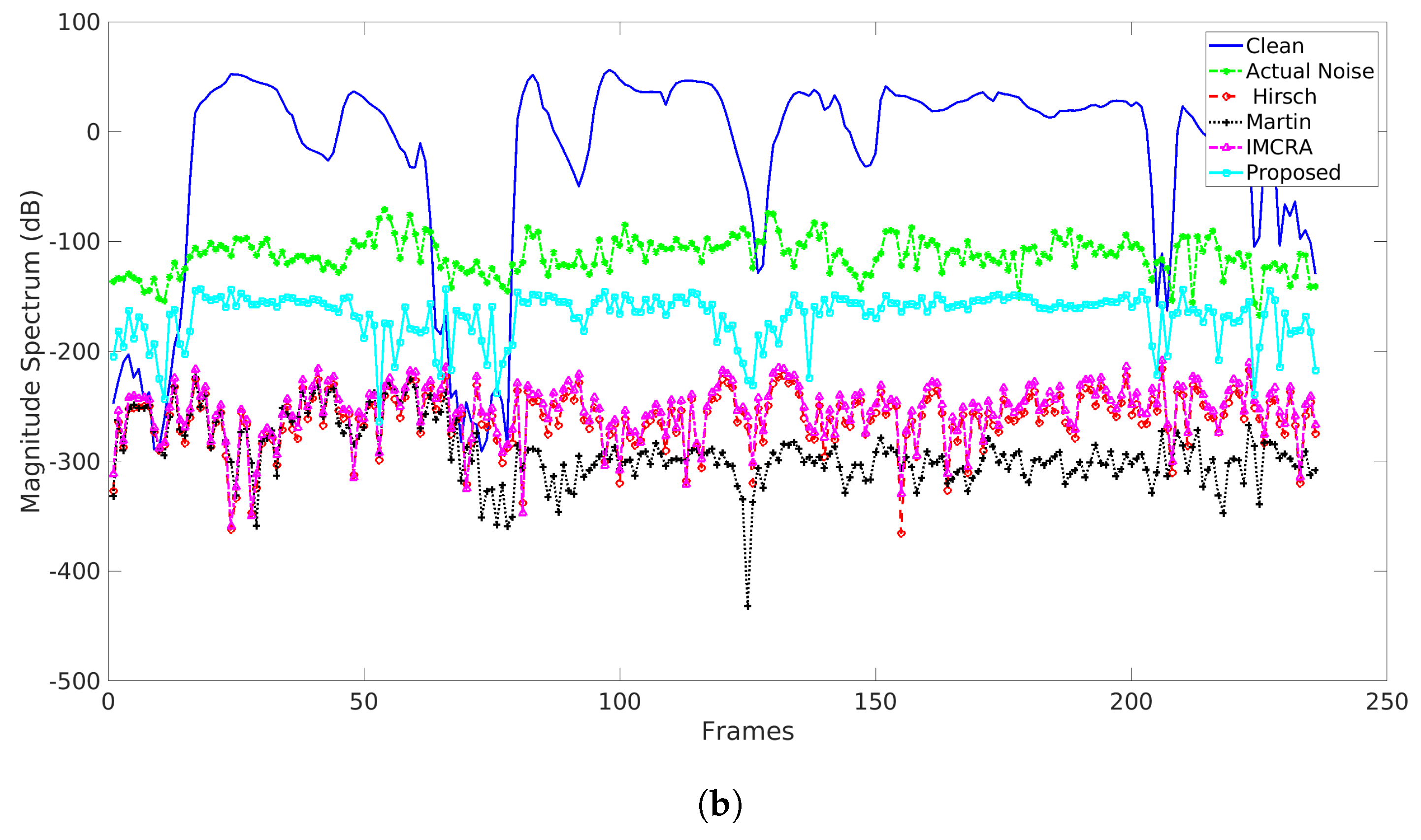
5.2. Comparison with Other Noise Estimators
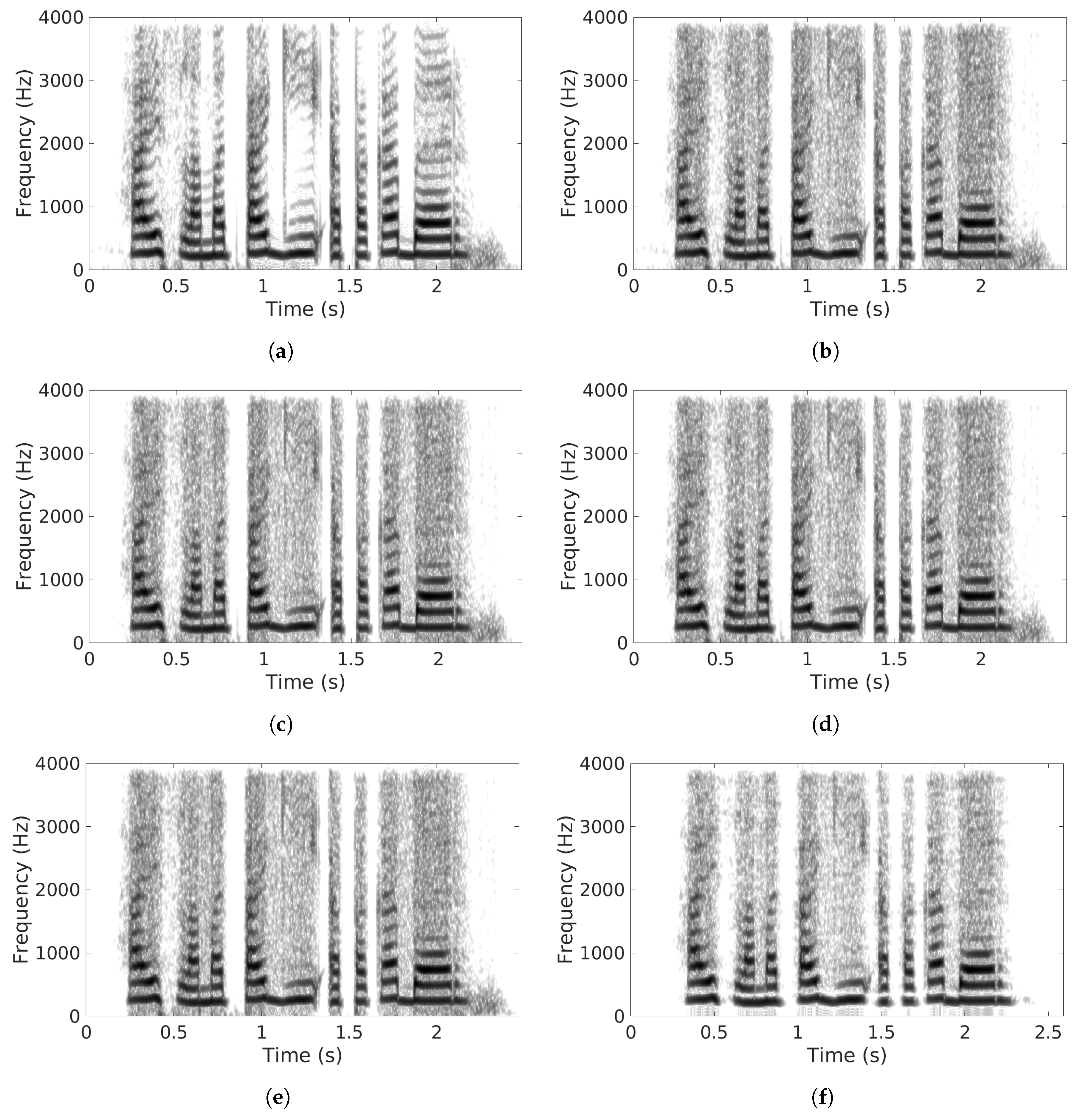
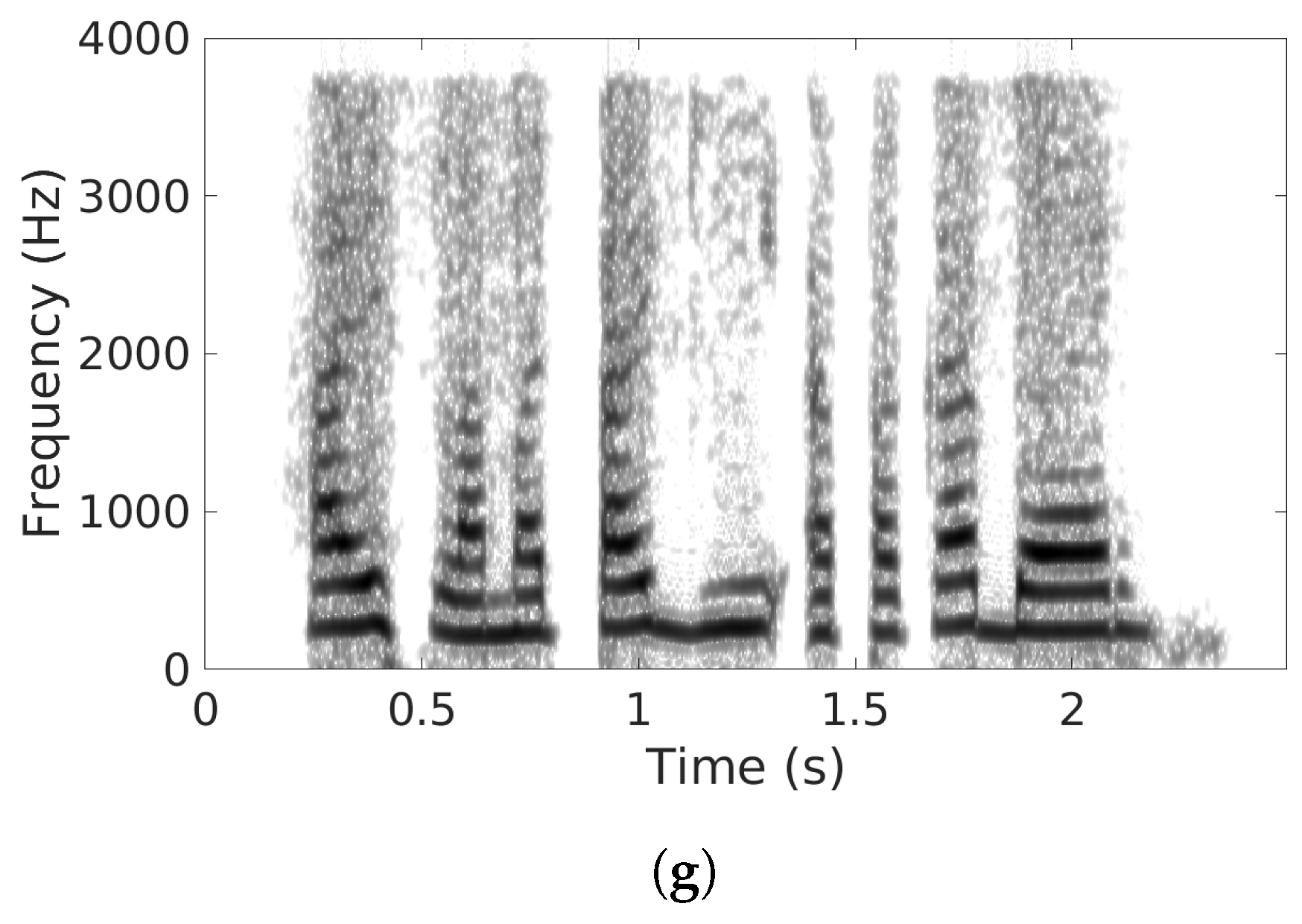
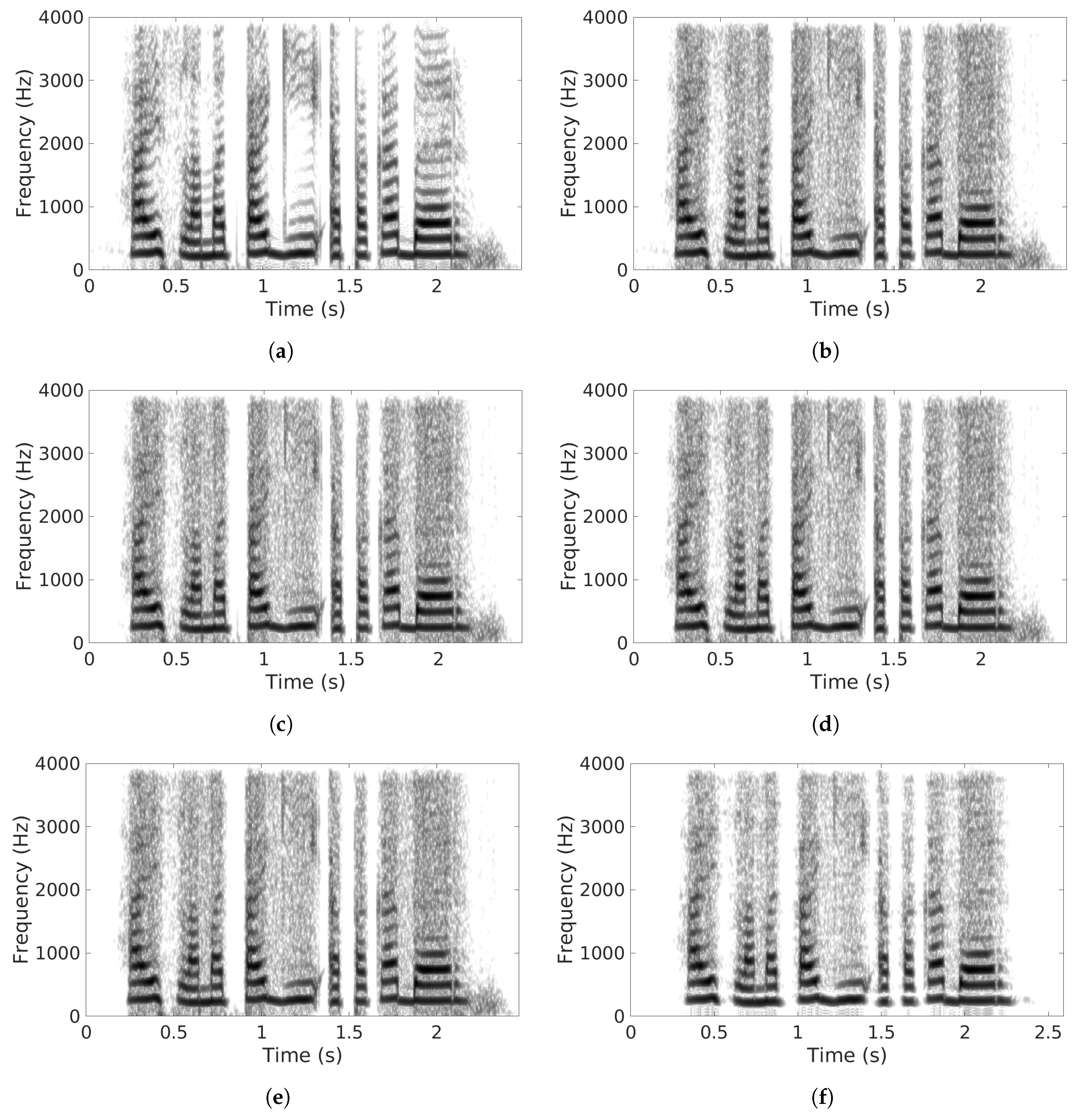
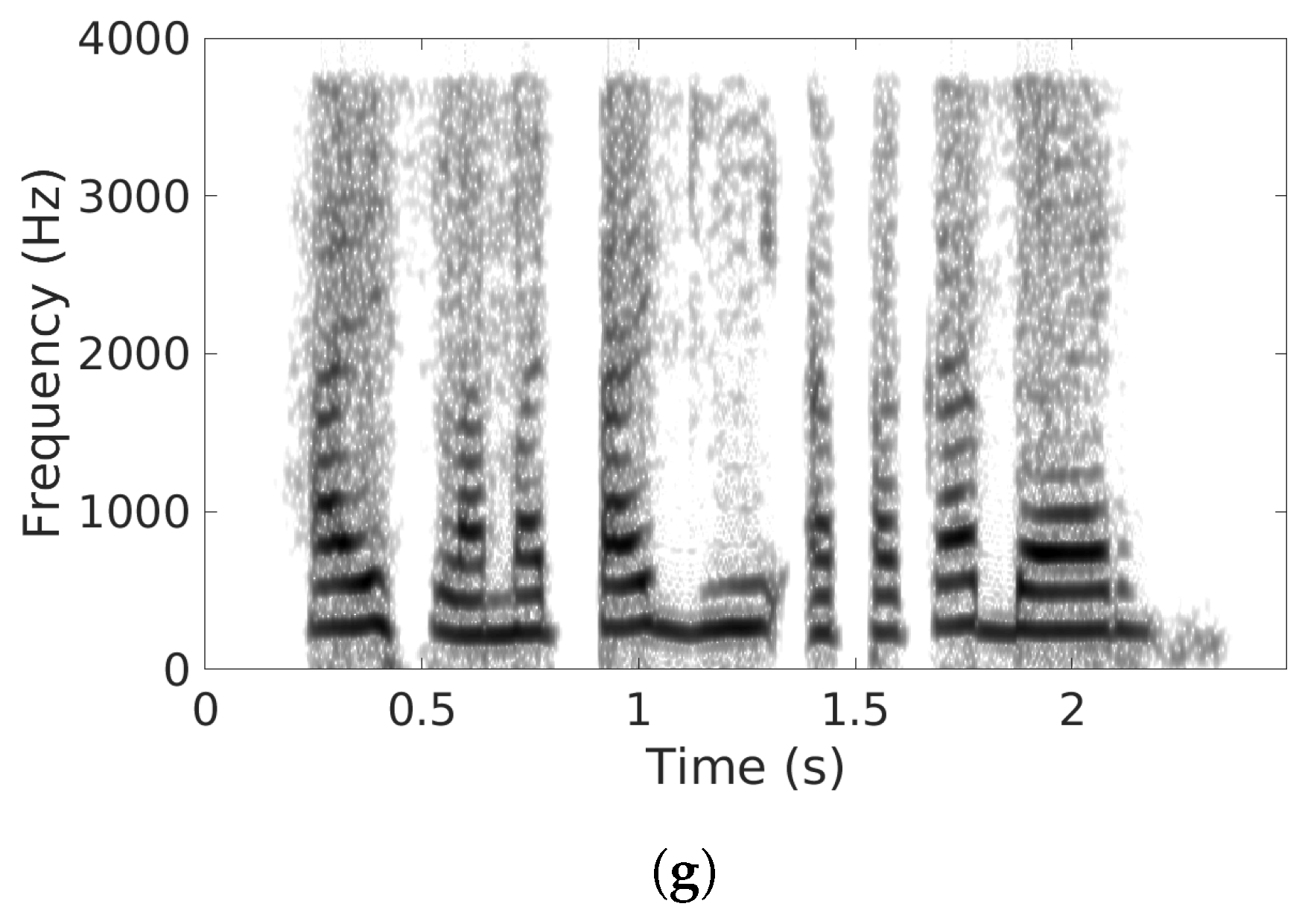
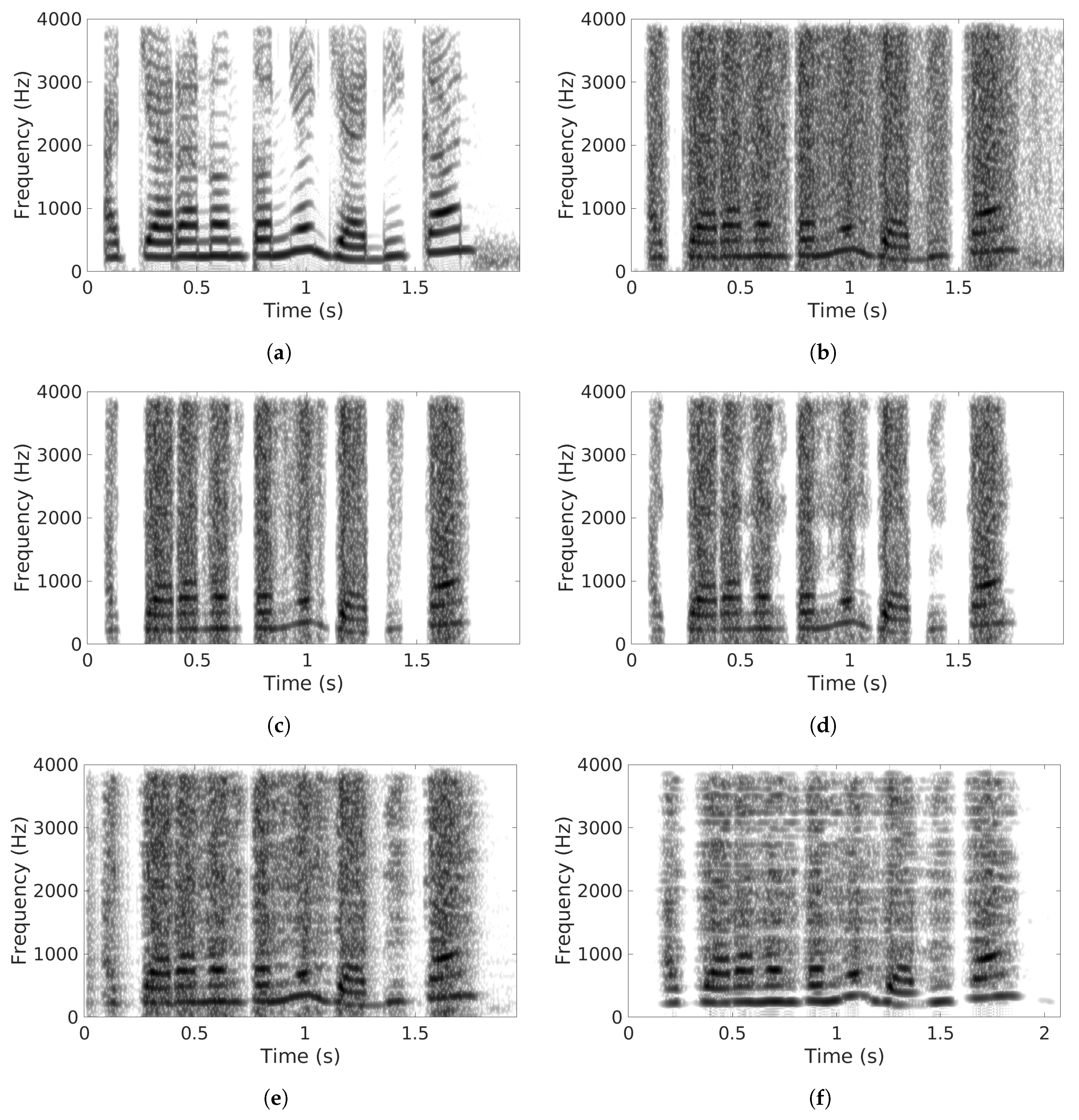
5.3. Comparisons with Other SE Methods
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Katugampala, N.N.; Al-Naimi, K.T.; Villette, S.; Kondoz, A.M. Real time data transmission over GSM voice channel for secure voice and data applications. In Proceedings of the 2nd IEEE Secure Mobile Communications Forum: Exploring the Technical Challenges in Secure GSM and WLAN, London, UK, 23–23 September 2004; pp. 7/1–7/4. [Google Scholar]
- Gong, Y. Speech recognition in noisy environments: A survey. Speech Commun. 1995, 16, 261–291. [Google Scholar] [CrossRef]
- Vincent, E.; Watanabe, S.; Nugraha, A.A.; Barker, J.; Marxer, R. An analysis of environment, microphone and data simulation mismatches in robust speech recognition. Comput. Speech Lang. 2017, 46, 535–557. [Google Scholar] [CrossRef] [Green Version]
- Levitt, H. Noise reduction in hearing aids: A review. J. Rehabil. Res. Dev. 2001, 38, 111–122. [Google Scholar] [PubMed]
- Kam, A.C.S.; Sung, J.K.K.; Lee, T.; Wong, T.K.C.; van Hasselt, A. Improving mobile phone speech recognition by personalized amplification: Application in people with normal hearing and mild-to-moderate hearing loss. Ear Hear 2017, 38, e85–e92. [Google Scholar] [CrossRef] [PubMed]
- Goulding, M.M.; Bird, J.S. Speech enhancement for mobile telephony. IEEE Trans. Veh. Technol. 1990, 39, 316–326. [Google Scholar] [CrossRef] [Green Version]
- Juang, B.; Soong, F. Hands-free telecommunications. In Proceedings of the International Workshop on Hands-Free Speech Communication, Kyoto, Japan, 9–11 April 2001. [Google Scholar]
- Jin, W.; Taghizadeh, M.J.; Chen, K.; Xiao, W. Multi-channel noise reduction for hands-free voice communication on mobile phones. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 506–510. [Google Scholar]
- Lu, X.; Tsao, Y.; Matsuda, S.; Hori, C. Speech enhancement based on deep denoising autoencoder. In Proceedings of the Interspeech, 14th Annual Conference of the International Speech Communication Association, Lyon, France, 25–29 August 2013; pp. 436–440. [Google Scholar]
- Xu, Y.; Du, J.; Dai, L.; Lee, C. A Regression Approach to Speech Enhancement Based on Deep Neural Networks. IEEE/ACM IEEE Trans. Audio Speech Lang. Process. 2015, 23, 7–19. [Google Scholar]
- Weninger, F.; Erdogan, H.; Watanabe, S.; Vincent, E.; Le Roux, J.; Hershey, J.R.; Schuller, B. Speech enhancement with LSTM recurrent neural networks and its application to noise-robust ASR. In Proceedings of the International Conference on Latent Variable Analysis and Signal Separation, Liberec, Czech Republic, 25–28 August 2015; pp. 91–99. [Google Scholar]
- Pascual, S.; Bonafonte, A.; Serrà, J. SEGAN: Speech Enhancement Generative Adversarial Network. In Proceedings of the Interspeech, 18th Annual Conference of the International Speech Communication Association, Stockholm, Sweden, 20–24 August 2017; pp. 3642–3646. [Google Scholar]
- Kumar, A.; Florencio, D. Speech Enhancement in Multiple-Noise Conditions Using Deep Neural Networks. In Proceedings of the Interspeech, San Francisco, CA, USA, 8–12 Sepember 2016; pp. 3738–3742. [Google Scholar]
- Shekokar, S.; Mali, M. A brief survey of a DCT-based speech enhancement system. Int. J. Sci. Eng. Res 2013, 4, 1–3. [Google Scholar]
- Boll, S. A spectral subtraction algorithm for suppression of acoustic noise in speech. In Proceedings of the 1979 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Washington, DC, USA, 2–4 April 1979; Volume 4, pp. 200–203. [Google Scholar]
- Nasu, Y.; Shinoda, K.; Furui, S. Cross-Channel Spectral Subtraction for meeting speech recognition. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Process (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 4812–4815. [Google Scholar]
- Furuya, K.; Kataoka, A. Robust speech dereverberation using multichannel blind deconvolution with spectral subtraction. IEEE Trans. Audio Speech Lang. Process. 2007, 15, 1579–1591. [Google Scholar] [CrossRef]
- Berouti, M.; Schwartz, R.; Makhoul, J. Enhancement of speech corrupted by acoustic noise. In Proceedings of the 1979 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Washington, DC, USA, 2–4 April 1979; Volume 4, pp. 208–211. [Google Scholar]
- Lockwood, P.; Boudy, J. Experiments with a nonlinear spectral subtractor (NSS), hidden Markov models and the projection, for robust speech recognition in cars. Speech Commun. 1992, 11, 215–228. [Google Scholar] [CrossRef]
- Cappé, O. Elimination of the musical noise phenomenon with the Ephraim and Malah noise suppressor. IEEE Trans. Speech Audio Process. 1994, 2, 345–349. [Google Scholar] [CrossRef]
- Kamath, S.; Loizou, P. A multi-band spectral subtraction method for enhancing speech corrupted by colored noise. In Proceedings of the 2002 IEEE International Conference on Acoustics, Speech, and Signal Processing, Orlando, FL, USA, 13–17 May 2002; Volume 4, p. 44164. [Google Scholar]
- Udrea, R.M.; Oprea, C.C.; Stanciu, C. Multi-microphone Noise Reduction System Integrating Nonlinear Multi-band Spectral Subtraction. In Pervasive Computing Paradigms for Mental Health; Oliver, N., Serino, S., Matic, A., Cipresso, P., Filipovic, N., Gavrilovska, L., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 133–138. [Google Scholar]
- McAulay, R.; Malpass, M. Speech enhancement using a soft-decision noise suppression filter. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 137–145. [Google Scholar] [CrossRef]
- Scalart, P. Speech enhancement based on a priori signal to noise estimation. In Proceedings of the 1996 IEEE International Conference on Acoustics, Speech, and Signal Processing Conference Proceedings, Atlanta, GA, USA, 9 May 1996; Volume 2, pp. 629–632. [Google Scholar]
- Hu, Y.; Loizou, P.C. Speech enhancement based on wavelet thresholding the multitaper spectrum. IEEE Trans. Speech Audio Process. 2004, 12, 59–67. [Google Scholar] [CrossRef]
- Ephraim, Y.; Malah, D. Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 1109–1121. [Google Scholar] [CrossRef] [Green Version]
- Lyubimov, N.; Kotov, M. Non-negative matrix factorization with linear constraints for single-channel speech enhancement. In Proceedings of the Interspeech, 14th Annual Conference of the International Speech Communication Association, Lyon, France, 25–29 August 2013; pp. 446–450. [Google Scholar]
- Duan, Z.; Mysore, G.J.; Smaragdis, P. Speech enhancement by online non-negative spectrogram decomposition in nonstationary noise environments. In Proceedings of the Interspeech, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Ephraim, Y.; Malah, D. Speech enhancement using a minimum mean-square error log-spectral amplitude estimator. IEEE Trans. Acoust. Speech Signal Process. 1985, 33, 443–445. [Google Scholar] [CrossRef]
- Mahmmod, B.M.; Ramli, A.R.; Abdulhussian, S.H.; Al-Haddad, S.A.R.; Jassim, W.A. Low-Distortion MMSE Speech Enhancement Estimator Based on Laplacian Prior. IEEE Access 2017, 5, 9866–9881. [Google Scholar] [CrossRef]
- Chen, B.; Loizou, P.C. Speech enhancement using a MMSE short time spectral amplitude estimator with Laplacian speech modeling. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing, Philadelphia, PA, USA, 23–23 March 2005; Volume 1. [Google Scholar]
- Wang, Y.; Brookes, M. Speech enhancement using an MMSE spectral amplitude estimator based on a modulation domain Kalman filter with a Gamma prior. In Proceedings of the 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5225–5229. [Google Scholar]
- Martin, R. Speech enhancement using MMSE short time spectral estimation with gamma distributed speech priors. In Proceedings of the 2002 IEEE International Conference on Acoustics, Speech and Signal Process (ICASSP), Orlando, FL, USA, 13–17 May 2002; Volume 1, pp. I-253–I-256. [Google Scholar]
- Andrianakis, I.; White, P.R. Mmse Speech Spectral Amplitude Estimators With Chi and Gamma Speech Priors. In Proceedings of the 2006 IEEE International Conference on Acoustics, Speech and Signal Process (ICASSP), Toulouse, France, 14–19 May 2006; Volume 3. [Google Scholar]
- Pardede, H.F.; Koichi, S.; Koji, I. Q-Gaussian based spectral subtraction for robust speech recognition. In Proceedings of the Interspeech, 13th Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012; pp. 1255–1258. [Google Scholar]
- Pardede, H.; Iwano, K.; Shinoda, K. Spectral subtraction based on non-extensive statistics for speech recognition. IEICE Trans. Inf. Syst. 2013, 96, 1774–1782. [Google Scholar] [CrossRef]
- Martin, R. Noise power spectral density estimation based on optimal smoothing and minimum statistics. IEEE Trans. Speech Audio Process. 2001, 9, 504–512. [Google Scholar] [CrossRef] [Green Version]
- Barnov, A.; Bracha, V.B.; Markovich-Golan, S. QRD based MVDR beamforming for fast tracking of speech and noise dynamics. In Proceedings of the 2017 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 15–18 October 2017; pp. 369–373. [Google Scholar]
- Cohen, I.; Berdugo, B. Noise estimation by minima controlled recursive averaging for robust speech enhancement. IEEE Signal Process Lett. 2002, 9, 12–15. [Google Scholar] [CrossRef]
- Lu, C.T.; Lei, C.L.; Shen, J.H.; Wang, L.L.; Tseng, K.F. Estimation of noise magnitude for speech denoising using minima-controlled-recursive-averaging algorithm adapted by harmonic properties. Appl. Sci. 2017, 7, 9. [Google Scholar] [CrossRef]
- Lu, C.T.; Chen, Y.Y.; Shen, J.H.; Wang, L.L.; Lei, C.L. Noise Estimation for Speech Enhancement Using Minimum-Spectral-Average and Vowel-Presence Detection Approach. In Proceedings of the International Conference on Frontier Computing, Bangkok, Thailand, 9–11 September 2016; pp. 317–327. [Google Scholar]
- He, Q.; Bao, F.; Bao, C.; He, Q.; Bao, F.; Bao, C. Multiplicative update of auto-regressive gains for codebook-based speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 457–468. [Google Scholar] [CrossRef]
- Faubel, F.; Mcdonough, J.; Klakow, D. A phase-averaged model for the relationship between noisy speech, clean speech and noise in the log-mel domain. In Proceedings of the Interspeech, 9th Annual Conference of the International Speech Communication Association, Brisbane, Australia, 22–26 September 2008. [Google Scholar]
- Zhu, Q.; Alwan, A. The effect of additive noise on speech amplitude spectra: A quantitative analysis. IEEE Signal Process Lett. 2002, 9, 275–277. [Google Scholar]
- Sovka, P.; Pollak, P.; Kybic, J. Extended spectral subtraction. In Proceedings of the 1996 8th European Signal Processing Conference (EUSIPCO 1996), Trieste, Italy, 10–13 September 1996; pp. 1–4. [Google Scholar]
- Lestari, D.P.; Iwano, K.; Furui, S. A large vocabulary continuous speech recognition system for Indonesian language. In Proceedings of the 15th Indonesian Scientific Conference in Japan Proceedings, Hiroshima, Japan, 4–7 August 2006; pp. 17–22. [Google Scholar]
- Hayati, N.; Suryanto, Y.; Ramli, K.; Suryanegara, M. End-to-End Voice Encryption Based on Multiple Circular Chaotic Permutation. In Proceedings of the 2019 2nd International Conference on Communication Engineering and Technology (ICCET), Nagoya, Japan, 12–15 April 2019. [Google Scholar]
- Rix, A.W.; Beerends, J.G.; Hollier, M.P.; Hekstra, A.P. Perceptual evaluation of speech quality (PESQ)—A new method for speech quality assessment of telephone networks and codecs. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing, Salt Lake City, UT, USA, 7–11 May 2001; Volume 2, pp. 749–752. [Google Scholar]
- Tribolet, J.; Noll, P.; McDermott, B.; Crochiere, R. A study of complexity and quality of speech waveform coders. In Proceedings of the ICASSP’78. IEEE International Conference on Acoustics, Speech, and Signal Processing, Tulsa, OK, USA, 10–12 April 1978; Volume 3, pp. 586–590. [Google Scholar]
- Hu, Y.; Loizou, P.C. Evaluation of objective quality measures for speech enhancement. IEEE Trans. Audio Speech Lang. Process. 2008, 16, 229–238. [Google Scholar] [CrossRef]
- Hirsch, H.G.; Ehrlicher, C. Noise estimation techniques for robust speech recognition. In Proceedings of the 1995 International Conference on Acoustics, Speech, and Signal Processing, Detroit, MI, USA, 9–12 May 1995; Volume 1, pp. 153–156. [Google Scholar]
- Cohen, I. Noise spectrum estimation in adverse environments: Improved minima controlled recursive averaging. IEEE Trans. Speech Audio Process. 2003, 11, 466–475. [Google Scholar] [CrossRef]
- Hu, Y.; Loizou, P.C. A generalized subspace approach for enhancing speech corrupted by colored noise. IEEE Trans. Speech Audio Process. 2003, 11, 334–341. [Google Scholar] [CrossRef] [Green Version]
- Loizou, P.C. Speech Enhancement: Theory and Practice, 2nd ed.; CRC Press, Inc.: Boca Raton, FL, USA, 2013. [Google Scholar]
- NMFdenoiser. 2014. Available online: https://github.com/niklub/NMFdenoiser (accessed on 11 March 2019).


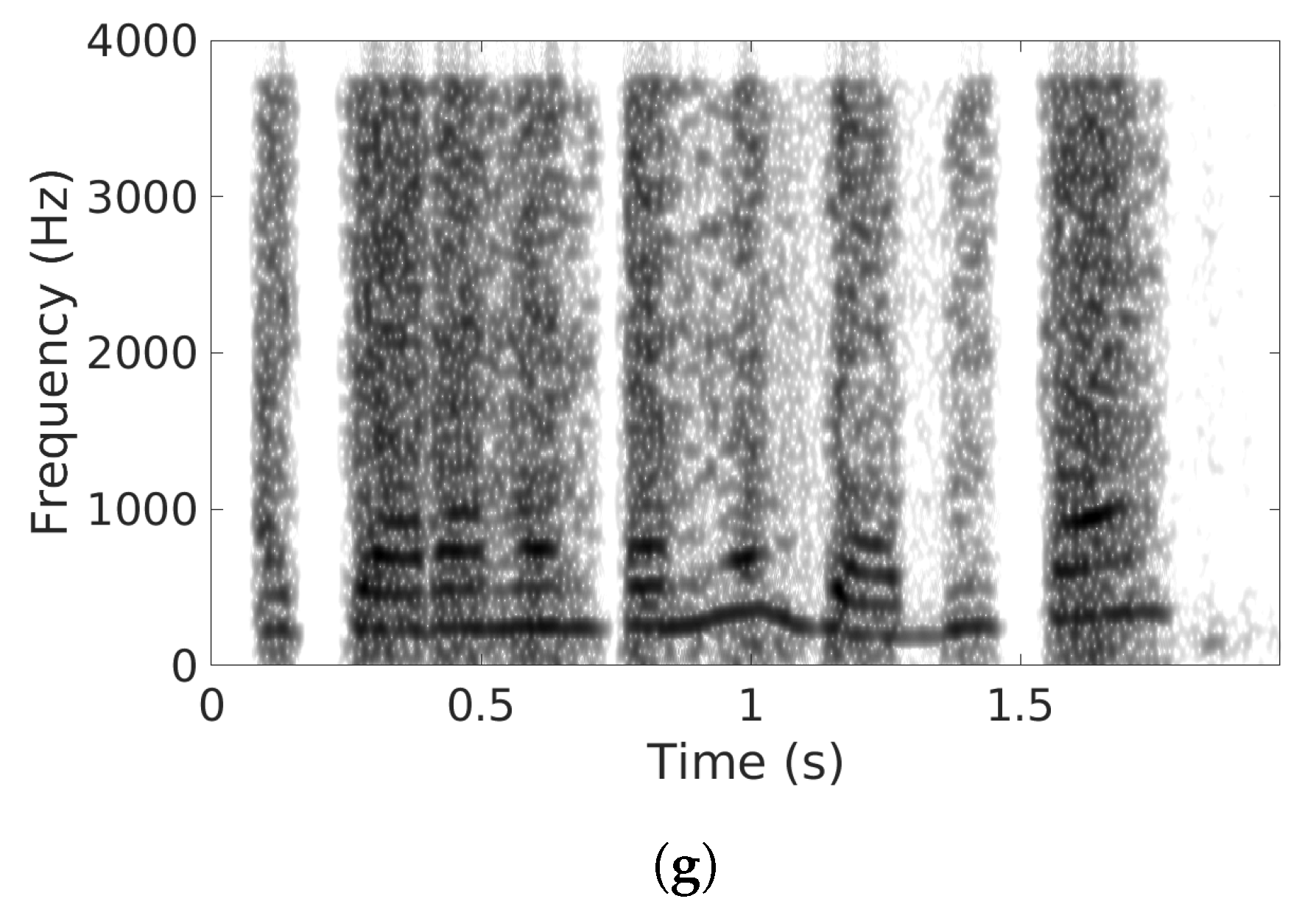
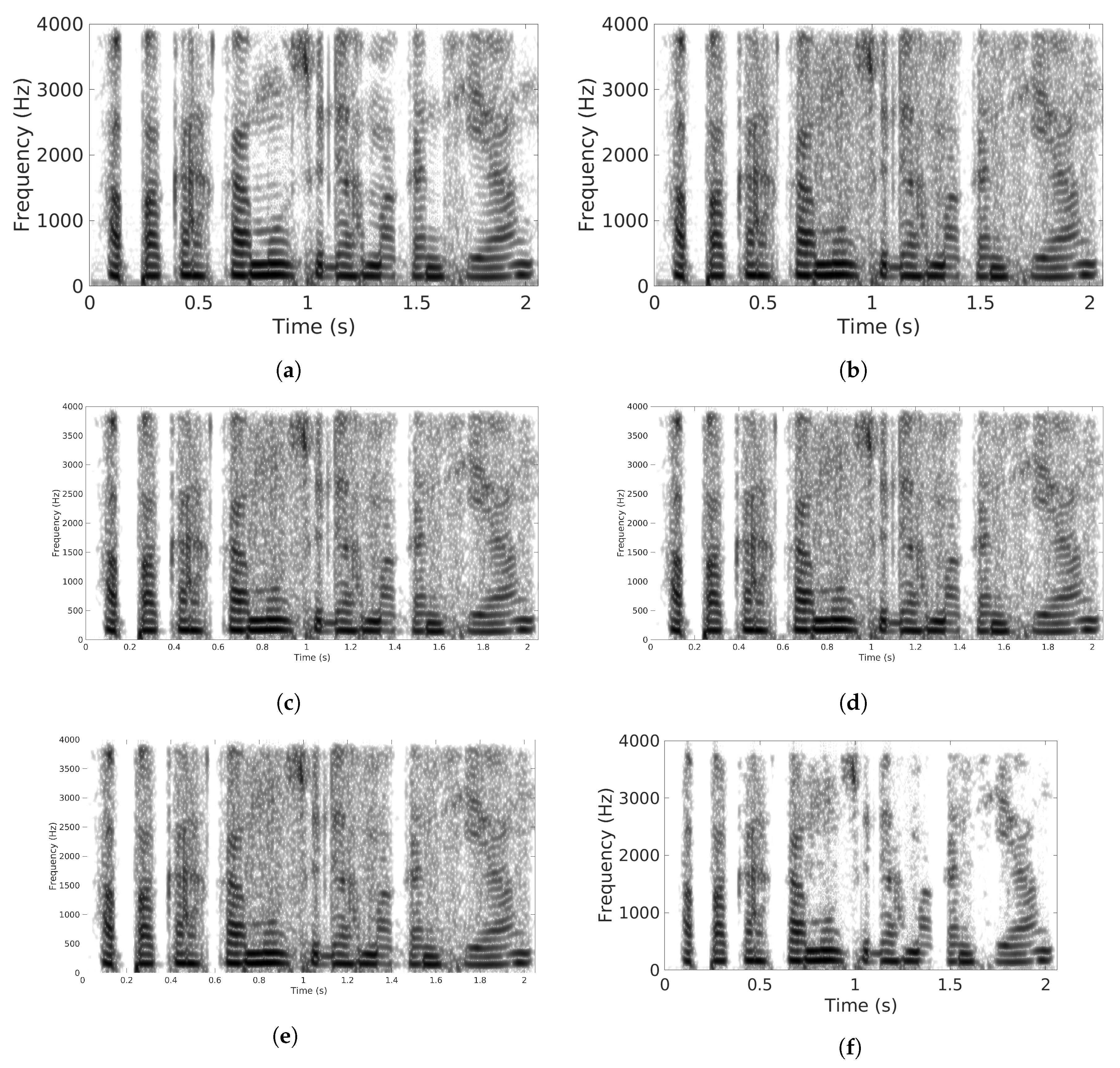

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Utterance | Phonetic Transcription |
|---|---|
| 1 | [h-ai] [s-ə-l-a:-m-a:-t] [p-a:-g-i] [a:-p-a:] [k-a:-b-a:-R] |
| 2 | [s-ə-m-ɔ:-g-a:] [u:-ʤ-i-a:-n-ɲ-a:] [b-ə-R-ʤ-a:-l-a:-n] [l-a:-n-ʧ-a:-R] |
| 3 | [a:-ʧ-a:-R-a:] [n-ɔ:-n-t-ɔ:-n-ɲ-a:] [ʤ-a:-d-i] [k-a:-n] |
| 4 | [a:-p-a:-k-a:-h] [k-a:-m-u:] [s-u:-d-a:-h] [m-a:-k-a:-n] [s-i-a:-ɲ] |
| 5 | [n-a:-n-t-i] [m-a:-l-a:-m] [p-u:-l-a:-ɲ] [ʤ-a:-m] [b-ə-R-a:-p-a:] |
| 6 | [ʤ-a:-ɲ-a:-n] [l-u:-p-a:] [s-a:-R-a:-p-a:-n] [j-a:] |
| 7 | [ʧ-ə-p-a:-t] [i-s-t-i-R-a:-h-a:-t] [d-a:-n] [m-i-m-p-i] [j-a:-ɲ] [i-n-d-a:-h] |
| 8 | [m-a:-a:-f] [s-a:-j-a:] [t-ə-R-l-a:-m-b-a:-t] [d-a:-t-a:-ɲ] [k-ə] [k-a:-n-t-o-R] |
| 9 | [d-i-a:] [t-i-d-a:-k] [d-a:-t-a:-ɲ] [k-ə] [s-ə-k-ɔ:-l-a:-h] |
| 10 | [a:-l-a:-s-a:-n-ɲ-a:] [b-ə-l-u:-m] [m-ə-ɲ-ə-R-ʤ-a:-k-a:-n] [p-ə-k-ə-R-ʤ-a:-a:-n] [R-u:-m-a:-h] |
| Methods | GSM | I-ADPCM | M-ADPCM | PCM |
|---|---|---|---|---|
| Hirsch | 43.89 | 40.50 | 43.25 | 40.47 |
| Martin | 43.88 | 41.65 | 46.06 | 41.52 |
| IMCRA | 41.20 | 37.34 | 39.26 | 37.28 |
| Proposed | 40.00 | 36.17 | 43.93 | 36.17 |
| Methods | PESQ | FwSNR | ||||||
|---|---|---|---|---|---|---|---|---|
| GSM | I-ADPCM | M-ADPCM | PCM | GSM | I-ADPCM | M-ADPCM | PCM | |
| Noisy speech | 1.234 | 2.303 | 2.346 | 2.303 | 2.501 | 15.300 | 13.533 | 15.309 |
| With OLAP only | 1.234 | 2.295 | 2.345 | 2.295 | 2.495 | 15.210 | 13.523 | 15.190 |
| SS | 1.229 | 2.308 | 2.351 | 2.308 | 2.431 | 13.148 | 12.575 | 13.155 |
| SS + Martin | 1.235 | 2.296 | 2.341 | 2.296 | 2.213 | 13.505 | 12.773 | 13.510 |
| SS + IMCRA | 1.234 | 2.295 | 2.339 | 2.295 | 2.185 | 13.207 | 12.613 | 13.200 |
| SS + Hirsch | 1.234 | 2.289 | 2.333 | 2.288 | 2.131 | 13.192 | 12.562 | 13.187 |
| WF | 1.163 | 1.963 | 1.989 | 1.963 | 2.535 | 11.918 | 11.328 | 11.919 |
| LogMMSE | 1.240 | 2.352 | 2.405 | 2.352 | 2.711 | 12.439 | 11.895 | 12.440 |
| KLT | 1.173 | 2.090 | 2.118 | 2.091 | 2.206 | 10.512 | 10.128 | 10.510 |
| NMF | 1.350 | 2.551 | 2.606 | 2.591 | 1.654 | 2.987 | 2.957 | 2.995 |
| Proposed method | 1.251 | 2.654 | 2.649 | 2.654 | 3.620 | 13.415 | 12.799 | 13.405 |
| No. | SS | KLT | LogMMSE | WF | NMF | Proposed |
|---|---|---|---|---|---|---|
| 1 | 12,945 | 43,157 | 27,170 | 255,627 | 205,544 | 37,139 |
| 2 | 13,131 | 41,292 | 28,038 | 256,006 | 204,908 | 37,268 |
| 3 | 13,022 | 41,753 | 27,171 | 255,987 | 206,773 | 37,117 |
| 4 | 13,420 | 41,885 | 27,477 | 256,151 | 207,229 | 37,103 |
| 5 | 13,470 | 41,003 | 27,405 | 255,775 | 205,974 | 36,644 |
| Average | 13,198 | 41,818 | 27,452 | 255,909 | 206,086 | 37,054 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pardede, H.; Ramli, K.; Suryanto, Y.; Hayati, N.; Presekal, A. Speech Enhancement for Secure Communication Using Coupled Spectral Subtraction and Wiener Filter. Electronics 2019, 8, 897. https://doi.org/10.3390/electronics8080897
Pardede H, Ramli K, Suryanto Y, Hayati N, Presekal A. Speech Enhancement for Secure Communication Using Coupled Spectral Subtraction and Wiener Filter. Electronics. 2019; 8(8):897. https://doi.org/10.3390/electronics8080897
Chicago/Turabian StylePardede, Hilman, Kalamullah Ramli, Yohan Suryanto, Nur Hayati, and Alfan Presekal. 2019. "Speech Enhancement for Secure Communication Using Coupled Spectral Subtraction and Wiener Filter" Electronics 8, no. 8: 897. https://doi.org/10.3390/electronics8080897
APA StylePardede, H., Ramli, K., Suryanto, Y., Hayati, N., & Presekal, A. (2019). Speech Enhancement for Secure Communication Using Coupled Spectral Subtraction and Wiener Filter. Electronics, 8(8), 897. https://doi.org/10.3390/electronics8080897