This section results from a detailed literature review, gathering the concepts connected with interpretable machine learning and explaining their details and how they connect with each other.
4.1. Interpretability
There is no mathematical definition of interpretability. A (nonmathematical) definition given by Miller is “Interpretability is the degree to which a human can understand the cause of a decision” [
95]. In the context of machine learning (ML) systems, Kim et al. describe interpretability as “the degree to which a human can consistently predict the model’s result” [
96]. This means that the interpretability of a model is higher if it is easier for a person to reason and trace back why a prediction was made by the model. Comparatively, a model is more interpretable than another model if the prior’s decisions are easier to understand than the decisions of the latter [
95].
More recently, Doshi-Velez and Kim define interpretability as the “ability to explain or to present in understandable terms to a human” [
41]. Molnar notes that “interpretable machine learning refers to methods and models that make the behavior and predictions of machine learning systems understandable to humans” [
70]. Consequently, interpretability is evidently related to the ability of how well humans grasp some information by looking and reasoning about it.
Roughly speaking, one could argue that there are two different broad paths towards interpretability: creating accurate interpretable-by-nature models, either by imposing constraints or not, and creating explanation methods which are applicable to existing (and future) black box, opaque models.
4.2. Importance of Interpretability in Machine Learning
Many reasons make interpretability a valuable and, sometimes, even indispensable property. Notwithstanding, it is worth to note that, as seen in
Section 3.1, not all ML systems need interpretability, since, in some cases, it is sufficient to have an acceptable predictive performance. Otherwise, interpretability can provide added value in different ways.
Firstly, interpretability is a means to satisfy human curiosity and learning [
95]. Obviously, humans do not need an explanation for everything they see, e.g., most people do not want or need to know how their computer works. However, the situation is quite different when humans are dealing with unexpected events, as they make humans curious, urging the need to know the reasons
why they happened.
Humans have a mental model of their environment that is updated when an unexpected event happens, and this update is performed by finding an explanation for such event. In the same way, explanations and, thus, interpretability are crucial to facilitate learning and to satisfy curiosity as to why certain predictions are performed by algorithms. On top of that, it is important to take into consideration that when opaque machine learning models are used in research, scientific findings remain completely hidden if the model is a black box that only gives predictions without explanations [
70].
Another advantage of interpretability is that it helps to find meaning in the world [
95]. Decisions based on ML models have increasing impact in peoples’ lives, which means it is of increasing importance for the machine to explain its behavior. If an unexpected event happens, people can only reconcile this inconsistency between expectation and reality with some kind of explanation. for example, if a bank’s ML model rejects a loan application, the applicant will probably want to know, at least, the main causes for such a decision (or what needs to be changed).
However, as seen in
Section 3.4, under the new European General Data Protection Regulation (GDPR), the applicant effectively has the so-called
right to be informed [
89] and a list of all the decision factors might be required. Another example where explanations provide meaningful information is in products or movie recommendations, which usually are accompanied by the motive of recommendation, i.e., a certain movie was recommended because other users who liked the same movies also appreciated the recommended movie [
70].
The above example leads towards another benefit of interpretability: social acceptance, which is required for the process of integrating machines and algorithms into our daily lives. A few decades ago, Heider and Simmel [
97] have shown that people attribute beliefs and intentions to abstract objects. Therefore, it is intuitive that people will more likely accept ML models if their decisions are interpretable. This is also argued by Ribeiro et al. [
98], who state that “if the users do not trust a model or a prediction, they will not use it”. Interpretability is, thus, essential to increase human trust and acceptance on machine learning.
It is also worth noting that explanations are used to manage social interactions. By creating a shared meaning of something, the explainer influences the actions, emotions, and beliefs of the recipient of the explanation. More specifically, for a machine to successfully interact with people, it may need to shape people’s emotions and beliefs through persuasion, so that they can achieve their intended goal [
70].
Another crucial value empowered by interpretability is safety [
95]. Interpretability enables MLs models to be tested, audited, and debugged, which is a path towards increasing their safety, especially for domains where errors can have severe consequences. For example, in order to avoid self-driving cars running over cyclists, an explanation might show that the most important learned feature to identify bicycles is the two wheels, and this explanation helps to think about edge cases, such as when wheels are covered by side bags [
70].
Interpretability also enables detection of faulty model behavior, through debugging and auditing. An interpretation for an erroneous prediction helps to understand the cause of the error. It delivers a direction for how to fix the system and, thereby, increase its safety. For example, in a husky vs. wolf image classifier, interpretability would allow to find out that misclassification occurred because the model learned to use snow as a feature for detecting wolves [
70].
According to Doshi-Velez et al. [
41], explaining a ML model’s decisions provides a way to check the desiderata of ML systems, as noted in
Section 3.3, including fairness, privacy, and trust. In other words, interpretability enables, for example, the detection of bias that ML models learned either from the data or due to wrong parameterization, which arised from the incompleteness of the problem definition. For example, a bank’s ML model main goal is to grant loans only to people who will eventually repay them; however, the bank not only wants to minimize loan defaults but also is obliged not to discriminate on the basis of certain demographics [
70].
Finally, it is also noteworthily the goal of science, which is to acquire new knowledge. In spite of that, many problems are solved with big datasets and black box ML models. The model itself becomes the source of knowledge instead of the data. Interpretability makes it possible to extract this additional knowledge captured by the model [
70].
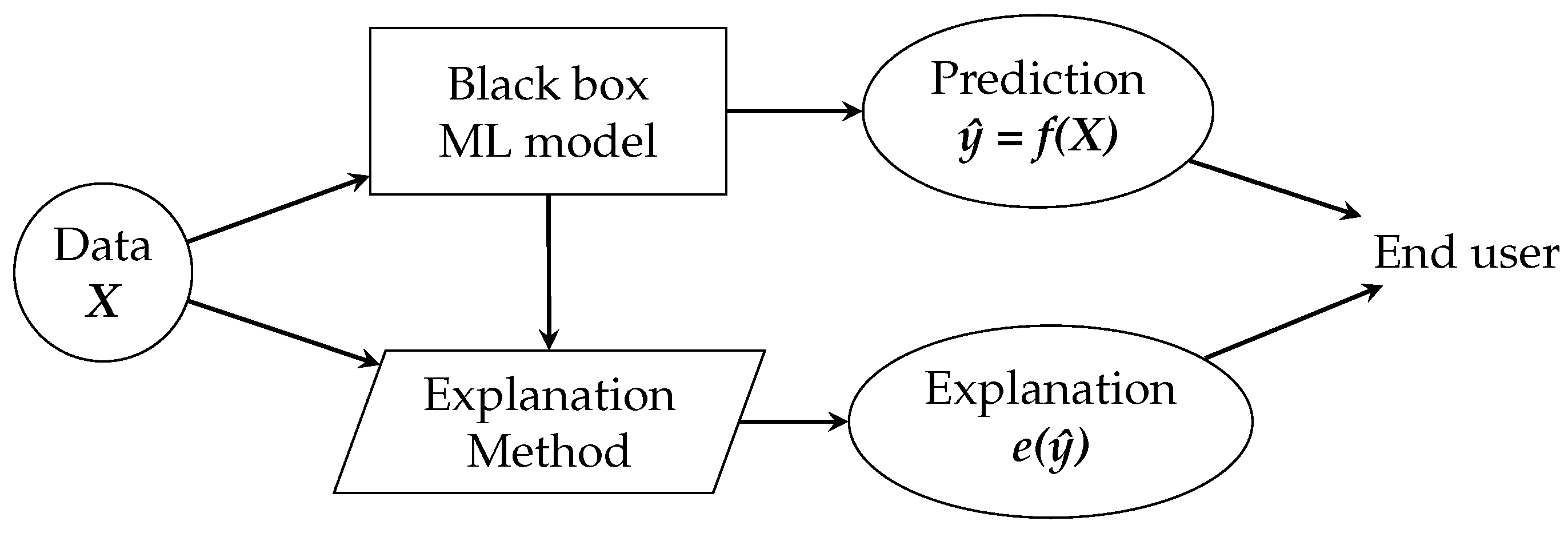
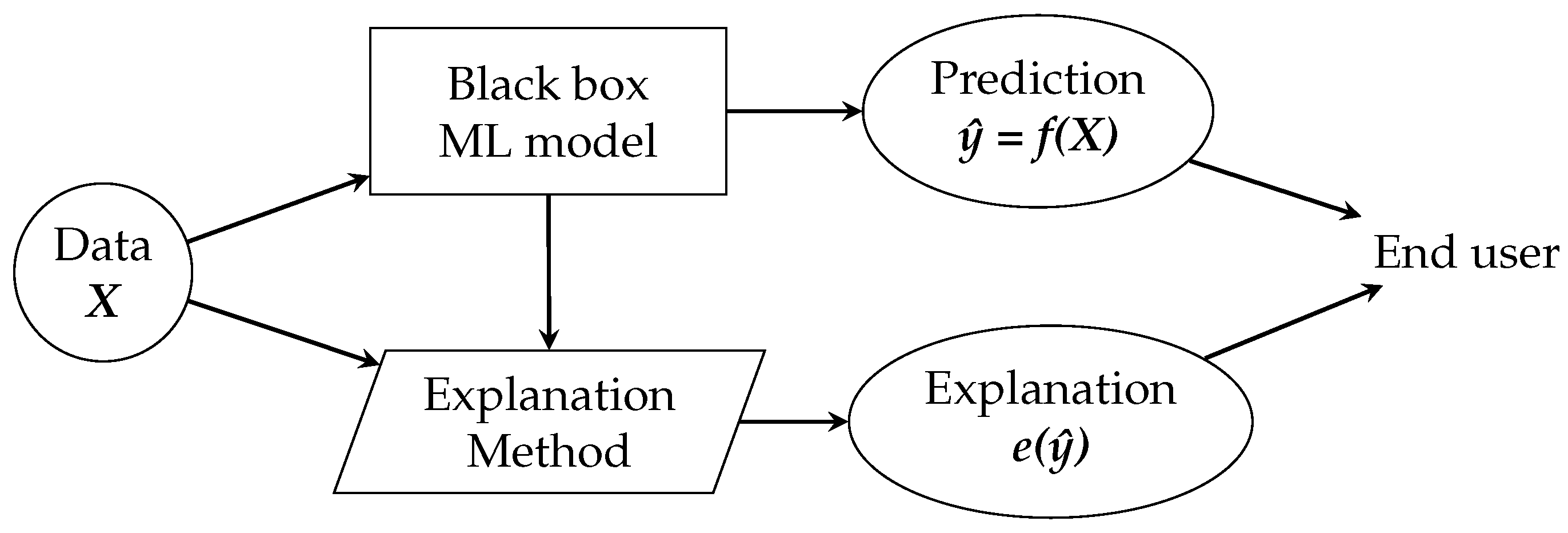
4.5. Explanations
The goal is to make the user understand the predictions of ML models, which is achieved through explanations. For this, we make use of an explanation method, which is nothing more than an algorithm that generates explanations. The role of the explanation methods and generated explanations within the ML pipeline is shown in
Figure 2.
What is an explanation? There have been various attempts to define the concept of an explanation across different disciplines, including philosophy and mathematics. An appropriate definition for the term is, thereby, dependent on the application domain and should be formulated regarding the context of use [
79]. Miller gives a simple, goal-oriented definition [
95], stating that “an explanation is the answer to a why-question”. Indeed, generally speaking, the goal of an explanation is to make something clear, understandable, transparent, and interpretable.
Taking into consideration the abovementioned, explanations can be considered as the means by which ML model decisions are explained. Therefore, interpretability is the end-goal that we want to achieve and explanations are the tools to reach interpretability [
79]. An explanation usually relates the feature values of an instance to its respective prediction in a humanly understandable way [
70] and, thus, increasing interpretability.
When it comes to explanations, it is important to distinguish whether the aim is the correct explanation or the best explanation, which usually are not the same. Kim states that theories of explanation can be distinguished into two kinds [
107] and that these can be generically expressed as the following:
Non-pragmatic theory of explanation: The explanation should be the correct answer to the why-question.
Pragmatic theory of explanation: The explanation should be a good answer for an explainer to give when answering the why-question to an audience.
The most significant difference between the two types of theories is that there is no space for the audience in non-pragmatic theories. Non-pragmatic theories typically, but not always, follow a position where it is assumed there is only one true explanation. This means that the correctness of the answer has nothing to do with whether the audience is capable of understanding it or not. Pragmatic theories, in turn, argue that the definition of an explanation should necessarily have a place for the listener.
Since different listeners have different knowledge bases, pragmatic theories are naturally allied with a position where it is assumed that a phenomenon can have multiple explanations—which is a phenomenon called “Rashomon Effect” [
108]. Therefore, it is argued that, when it comes to XAI, pragmatic theories of explanation are more appropriate than non-pragmatic ones [
107]. The practical, legal, and ethical demands for companies and researchers to develop XAI largely come from the expectations that human users legitimately have. This means that the goal is not to achieve the most correct answer—it is to make the audience understand the reasoning behind a decision or prediction that was made by a ML model.
Miller emphasizes that an explanation is not only a product but also a process that involves a cognitive dimension and a social dimension [
95]:
The cognitive dimension is related to knowledge acquisition and involves deriving the actual explanation by a process of abductive inference, meaning that, first, the causes of an event are identified and, then, a subset of these causes are selected as the explanation.
The social dimension concerns the social interaction, in which knowledge is transferred from the explainer to the explainee (the person for which the explanation is intended and produced). The primary goal is that the explainee receives enough information from the explainer in order to understand the causes of some event or decision. The explainer can be either a human or a machine.
These dimensions emphasize the subjectivity of explanations, highlighting the need to adapt the explanation to the audience. In other words, there is no such thing as a single explanation that solves all the interpretability problems. For each situation, it needs to take into account the problem domain, the use case, and the audience for which the explanation is aimed to.
4.5.1. Properties of Explanation Methods
Robnik-Sikonja et al. [
109] defined some properties of explanation methods, which are stated below. These properties can be used to assess and make a comparison between different explanation methods.
Expressive power—It is the language or structure of the explanations the method is able to generate. These could be, e.g., rules, decision trees, and natural language.
Translucency—It represents how much the explanation method relies on looking into the inner workings of the ML model, such as the model’s parameters. For example, model-specific explanation methods are highly translucent. Accordingly, model-agnostic methods have zero translucency.
Portability—It describes the range of ML models to which the explanation method can be applied. It is inversely proportional to translucency, meaning that highly translucent methods have low portability and vice-versa. Hence, model-agnostic methods are highly portable.
Algorithmic complexity—It is related to computational complexity of the explanation method. This property is very important to consider regarding feasibility, especially when computation time is a bottleneck in generating explanations.
Additionally, there are other properties that might be useful to assess in certain situations. For instance, regarding randomness, some explanation methods have non-deterministic components, resulting in low stability of explanations. For example, LIME (Local Interpretable Model-agnostic Explanations) includes a random data sampling process, meaning that the explanation results will not be stable, i.e., repeating the explanation generation for the same instance and model with the same configuration arguments will result in different explanations. There are other methods in which the explanation results depend on some choices, such as the number of intervals (e.g., accumulated local effects), data sampling (e.g., Shapley values estimation) and shuffling (e.g., feature importance).
4.5.2. Properties of Individual Explanations
Robnik-Sikonja et al. [
109] have also defined some properties for the explanations (i.e., the result generated by the explanation methods). Nevertheless, it is neither clear for all these properties how to measure them correctly nor how useful they are to specific use cases, so one of the challenges is to formalize how they could be calculated.
Accuracy—It is related to the predictive accuracy of the explanation regarding unseen data. In some cases where the goal is to explain what the black box model does, low accuracy might be fine if the accuracy of the machine learning model is also low.
Fidelity—It is associated with how well the explanation approximates the prediction of the black box model. High fidelity is one of the most important properties of an explanation because an explanation with low fidelity is essentially useless.
Accuracy and fidelity are closely related: if the black box model has high accuracy and the explanation has high fidelity, the explanation consequently has high accuracy. Moreover, some explanations only provide local fidelity, meaning that the explanation only approximates well to the model prediction for a group or a single instance.
Consistency—Regarding two different models that have been trained on the same task and that output similar predictions, this property is related to how different are the explanations between them. If the explanations are very similar, the explanations are highly consistent.
However, it is noteworthy that this property is somewhat tricky [
70], since the two models could use different features but could get similar predictions, which is described by the “Rashomon Effect” [
108]. In this specific case, high consistency is not desirable because the explanations should be very different, as the models use different relationships for their predictions. High consistency is desirable only if the models really rely on similar relationships; otherwise, explanations should reflect the different aspects of the data that the models rely on.
Stability—It represents how similar are the explanations for similar instances. While consistency compares explanations between different models, stability compares explanations between similar instances for a fixed model. High stability means that slight variations in the feature values of an instance do not substantially change the explanation, unless these slight variations also strongly change the prediction.
Nonetheless, a lack of stability can also be created by non-deterministic components of the explanation method, such as a data sampling step (as noted in the end of the previous
Section 4.5.1). Regardless of that, high stability is always desirable.
Comprehensibility—This property is one of the most important but also one of the most difficult to define and measure. It is related to how well humans understand the explanations. Interpretability being a mainly subjective concept, this property depends on the audience and the context.
The comprehensibility of the features used in the explanation should also be considered, since a complex transformation of features might be less comprehensible than the original features [
70].
Certainty—It reflects the certainty of the ML model. Many ML models only provide prediction values, not including statement about the model’s confidence on the correctness of the prediction.
Importance—It is associated with how well the explanation reflects the importance of features or of parts of the explanation. For example, if a decision rule is generated as an explanation, is it clear which of the conditions of the rule was the most important?
Novelty—It describes if the explanation reflects whether an instance, of which the prediction is to be explained, comes from a region in the feature space that is far away from the distribution of the training data. In such cases, the model may be inaccurate and the explanation may be useless. One way of providing this information is to locate the data instance to be explained in the distribution of the training data.
Furthermore, the concept of novelty is related to the concept of certainty: the higher the novelty, the more likely it is that the model will have low certainty due to lack of data.
Representativeness—It describes how many instances are covered by the explanation. Explanations can cover the entire model (e.g., interpretation of weights in a linear regression model) or represent only an individual prediction.
There might be other properties that could be taken into consideration, such as the basic units of the explanation and the number of basic units that each explanation is composed of. These can be seen as qualitative interpretability indicators and are better explored and defined in
Section 5.1.
4.5.3. Human-Friendly Explanations
Taking into account that, regarding ML interpretability, the recipient of the explanations are humans; it is of evident importance to analyze what makes an explanation human-friendly because explanations, as correct as they might be, are not necessarily presented in a way that is easily understandable, in other words, checking which attributes are necessary to produce explanations that are more preferable and comprehensible to humans.
With reference to humanities research, Miller [
95] conducted a huge survey of publications on explanations. He claimed that most of the existing work in ML interpretability uses solely the researchers’ intuition of what constitutes an appropriated explanation for humans. From his survey, the following human-friendly characteristics of explanations are provided:
Contrastiveness [
110]—Humans usually do not ask why a certain prediction was made but rather
why this prediction was made instead of another prediction. In other words, there is a tendency for people to think in counterfactual cases. This means that people are not specifically interested in all the factors that led to the prediction but instead in the factors that need to change (in the input) so that the ML prediction/decision (output) would also change, implying a reference point, which is an hypothetical instance with the needed changes in the input and, consequently, with a different prediction (output).
Explanations that present some contrast between the instance to explain and a reference point are preferable. However, this makes the explanation application-dependent because of the requirement of a reference object [
70]. This concept is also designated as
counterfactual faithfulness [
78,
87].
Selectivity—People do not expect explanations that cover the actual and complete list of causes of an event. Instead, they prefer selecting one or two main causes from a variety of possible causes as the explanation. As a result, explanation methods should be able to provide selected explanations or, at least, make explicit which ones are the main causes for a prediction.
The “Rashomon Effect” describes this situation, in which different causes can explain an event [
108]—since humans prefer to select some of the causes, the selected causes may vary from person to person.
Social—Explanations are part of a social interaction between the explainer and the explainee. As seen in the beginning of
Section 4.5, this means that the social context determines the content, the communication, and the nature of the explanations.
Regarding ML interpretability, this implies that, when assessing the most appropriate explanation, one should take into consideration the social environment of the ML system and the target audience. This means that the best explanation varies according to the application domain and use case.
Focus on the abnormal—People focus more on abnormal causes to explain events [
111]. These are causes that had a small probability but, despite everything, happened. The elimination of these abnormal causes would have greatly changed the outcome (counterfactual faithfulness).
In terms of ML interpretability, if one of the input feature values for a prediction was abnormal in any sense (e.g., a rare category) and the feature influenced the prediction outcome, it should be included in the explanation, even if other more frequent feature values have the same influence on the prediction as the abnormal one [
70].
Truthful—Good explanations are proven to be true in the real world. This does not mean that the whole truth must be in the explanation, as it would interfere with the explanation being selected or not and selectivity is a more important characteristic than truthfulness. With respect to ML interpretability, this means that an explanation must make sense (plausible) and be suitable to predictions of other instances.
Consistent with prior beliefs of the explainee—People have a tendency to ignore information that is inconsistent with their prior beliefs. This effect is called confirmation bias [
112]. The set of beliefs varies subjectively from person to person, but there are also group-based prior beliefs, which are mainly of a cultural nature, such as political worldviews.
Notwithstanding, it is a trade-off with truthfulness, as prior knowledge is often not generally applicable and only valid in a specific knowledge domain. Honegger [
79] argues that it would be counterproductive for an explanation to be simultaneously truthful and consistent with prior beliefs.
General and probable—A cause that can explain a good number of events is very general and could, thus, be considered a good explanation. This seems to contradict the claim that abnormal causes make good explanations. However, abnormal causes are, by definition, rare in the given scenario, which means that, in the absence of an abnormal cause, a general explanation can be considered a good explanation.
Regarding ML interpretability, generality can easily be measured by the feature’s support, which is the ratio between the number of instances to which the explanation applies and the total number of instances [
70].
These properties are fundamental to enable the importance of interpretability in machine learning (
Section 4.2), although some might be more relevant than others depending on the context. No matter how correct an explanation is, if it is not reasonable and appealing for humans (human-friendly), the value of ML interpretability vanishes.
4.6. Interpretable Models and Explanation Methods
4.6.1. Interpretable Models
The easiest way to achieve interpretability is to use only a subset of algorithms that create interpretable models [
70], including linear regression, logistic regression, and decision trees. These are global interpretable models on a modular level (
Section 4.4.2), meaning that they have meaningful parameters (and features) from which useful information can be extracted in order to explain predictions.
Having different possibilities of choice, it is important to have some kind of assessment on which thw interpretable model is better suited for the problem at hand. Molnar [
70] considered the following properties:
Linearity—A model is linear if the association between feature values and target values is modelled linearly.
Monotonicity—Enforcing monotonicity constraints on the model guarantees that the relationship between a specific input feature and the target outcome always goes in the same direction over the entire feature domain, i.e., when the feature value increases, it always leads to an increase or always leads to a decrease in the target outcome. Monotonicity is useful for the interpretation because it makes it easier to understand the relationship between some features and the target.
Interaction—Some ML models have the ability to naturally include interactions between features to predict the target outcome. These interactions can be incorporated in any type of model by manually creating interaction features through feature engineering. Interactions can improve predictive performance, but too many or too complex interactions will decrease interpretability.
Not going into detail on how each interpretable model might be interpreted or what is the meaning of each of the models’ parameters regarding the performed predictions, this analysis will not go further than a general overview. As so,
Table 3 presents an overview between intrinsically interpretable models regarding their properties, with information gathered by Molnar [
70].
This table shows the prediction task for which each interpretable model is suited as well as which of the aforementioned properties each model has. Some models may be more fit for certain tasks than others, as they may have different predictive accuracies for different prediction tasks.
Additionally, although not as popular as the previously mentioned models, there are other classes of intrinsically interpretable models, which are considered to have greater simplicity. These include decision sets [
113], rule-based classifiers [
114,
115,
116,
117], and scorecards [
37,
118]. The latter is typically used in regulated domains, such as credit score systems.
In addition to existent intrinsically interpretable models, there has also been some research on creating interpretable models by imposing some kind of interpretability constraint. These include, for example, classifiers that are comprised of a small number of short rules [
119], Bayesian case-based reasoning models [
120], and neural networks with L1 penalties to their input gradients for sparse local explanations [
121]. Lage et al. [
122] have gone even further by optimizing for interpretability by directly including human feedback in the model optimization loop.
It is also worth mentioning existing works that make use of tensor product representation to perform knowledge encoding and logical reasoning based on common-sense inference [
123], which is useful for increasing interpretability through question-answering with the model [
124].
4.6.2. Model-Specific Explanation Methods
Although it is not the focus of this work, there has been some research in creating (post hoc) explanation methods that leverage intrinsic properties of specific types of models in order to generate explanations. The drawback is that using this type of methods limits the model choice to specific model classes.
Many model-specific methods are designed for Deep Neural Networks (DNN), which is a class of models that is widely used because of its predictive performance in spite of being very opaque in terms of interpretability, a typical example of black box model. There are many notorious examples of such DNN explanation methods [
7], most of which are used in computer vision [
125], including guided backpropagation [
126], integrated gradients [
127], SmoothGrad saliency maps [
128], Grad-CAM [
129], and more recently, testing with Concept Activation Vectors (TCAV) [
130].
One type of post hoc model-specific explanation methods is knowledge distillation, which is about extracting knowledge from a complex model to a simpler model (which can be from a completely different class of models). This can be achieved, for example, through model compression [
131] or tree regularization [
132] or even by combining model compression with dimension reduction [
133]. Research in this type of methods exists for some years [
134] but recently increased along with the ML interpretability field [
135,
136,
137].
Moreover, the increasing interest in model-specific explanation methods that focus on specific applications can be seen, for example, in the recent 2019 Conference on Computer Vision and Pattern Recognition (CVPR), which featured an workshop on explainable AI [
61]. There are CVPR 2019 papers with a great focus on interpretability and explainability for computer vision, such as explainability methods for graph CNNs [
138], interpretable and fine-grained visual explanations for CNNs [
139], interpreting CNNs via Decision Trees [
140], and learning to explain with complemental examples [
141].
4.6.3. Model-Agnostic Explanation Methods
Model-agnostic explanation methods are not dependent on the model. Although, for a specific model, in particular cases, some model-specific explanation methods might be more useful than model-agnostic explanation methods; the latter have the advantage of being completely independent from the original model class, persisting the possibility to reuse these methods in completely different use cases where the predictive model is also different.
It is worth asserting that method-agnostic explanation methods are also post hoc, since they are mostly decoupled from the black box model, as seen in
Section 4.3. Some of the explanation methods are example-based, which means they return a (new or existent) data point.
Table 4 presents an overview of the existing model-agnostic (post hoc) explanation methods, regarding the scope and the result criteria (explained in
Section 4.3).
As a side note, some of these methods might be referred to by other names. Feature importance is the same as feature attribution. LIME stands for Local Interpretable Model-agnostic Explanations. Shapley Values is sometimes called by SHAP. Prototypes and Criticisms might be referred to as MMD-Critic, which is the name of the main algorithm behind this explanation method.
Many of the considered explanation methods return feature summary statistics which can be visualized, as stated in
Section 4.3.4. Only with proper visualization and compositionality are some of these explanations considered interpretable, e.g., the relationship between a feature and the target outcome is better grasped with a plot and the feature importance values are more meaningful if features are ordered from the most important to the least important. It is also worth noting that some explanation methods have both global and local scopes, depending on if they are applied to explain the whole model or a specific prediction, e.g., the most influential instances for the whole model might be different than the most influential instances for a specific prediction.
Although these model-agnostic explanation methods provide the impactful advantage of being theoretically applicable to any model, most of them do not leverage intrinsic properties of specific types of models in order to generate explanations, meaning that, regarding some models, they may be more limited when compared to model-specific explanation methods.
4.7. Evaluation of Interpretability
As seen in
Section 4.1, there is no single definition that suits what interpretability is regarding ML. This ambiguity also applies to the interpretability measurement, being unclear which way is the most appropriate one [
70,
151]. Nevertheless, existing research has shown attempts to formulate some approaches for interpretability assessments, as described in this
Section 4.7 and in
Section 5.
Doshi-Velez and Kim [
41] propose three main levels of experiments for the evaluation of interpretability. These levels are ordered by descending order regarding cost of application and validity of results:
Application-grounded evaluation (end task)—Requires conducting end-user experiments within a real application. This experiment is performed by using the explanation in a real-world application and having it tested and evaluated by the end user, who is also a domain expert. A good baseline for this is how good a human would be at explaining the same decision [
70].
Human-grounded evaluation (simple task)—Refers to conducting simpler human–subject experiments that maintain the essence of the target application. The difference is that these experiments are not carried out with the domain experts but with laypersons. Since no domain experts are required, experiments are cheaper and it is easier to find more testers.
Functionally grounded evaluation (proxy task)—Requires no human experiments. In this type of evaluation, some formal definition of interpretability serves as a proxy to evaluate the explanation quality, e.g., the depth of a decision tree. Other proxies might be model sparsity or uncertainty [
70]. This works best when the class of model being used has already been evaluated by someone else in a human-level evaluation.
Application-grounded evaluation is definitely the most appropriate evaluation, since it assesses interpretability in the end goal with the end users. In spite of this, it is very costly and it is difficult to compare results in different domains. Functionally grounded evaluation appears on the other end of the spectrum, since it requires no human subjects and the defined proxies for this evaluation are usually comparable in different domains. Nevertheless, the results that come from functionally grounded evaluation have low validity, since the proxies that might be defined are not real measures of interpretability and there is no human feedback. Human-grounded evaluation comes as an intermediate solution, having lower cost than application-grounded evaluation but higher validity than functionally grounded evaluation—the results come from human feedback but disregard the domain in which the assessed interpretability would be applied.
4.7.1. Goals of Interpretability
Although there is no consensus on how to exactly measure interpretability [
70,
151], there is still room to define what are the goals for which interpretability aims. Rüping et al. [
91] argued that interpretability is composed of three goals, which are connected and often competing:
Accuracy—Refers to the actual connection between the given explanation by the explanation method and the prediction from the ML model [
151]. Not achieving this goal would render the explanation useless, as it would not be faithful to the prediction it aims to explain. This goal is a similar concept to the
fidelity property mentioned in
Section 4.5.2.
Understandability—Is related to the easiness of how an explanation is comprehended by the observer. This goal is crucial because, as accurate as an explanation can be, it is useless if it is not understandable [
151]. This is similar to the
comprehensibility property mentioned in
Section 4.5.2.
Efficiency—Reflects the time necessary for a user to grasp the explanation. Evidently, without this condition, it could be argued that almost any model is interpretable, given an infinite amount of time [
151]. Thereby, an explanation should be understandable in a finite and preferably short amount of time. This goal is related to the previous one, understandability: in general, the more understandable is an explanation, the more efficiently it is grasped.
This means that high interpretability would, thus, be scored by an explanation that is accurate to the data and to the model, understandable by the average observer, and graspable in a short amount of time [
79]. Nonetheless, as stated by Rüping et al. [
91], there is usually a trade-off between these goals, e.g., the more accurate an explanation is, the less understandable it becomes.


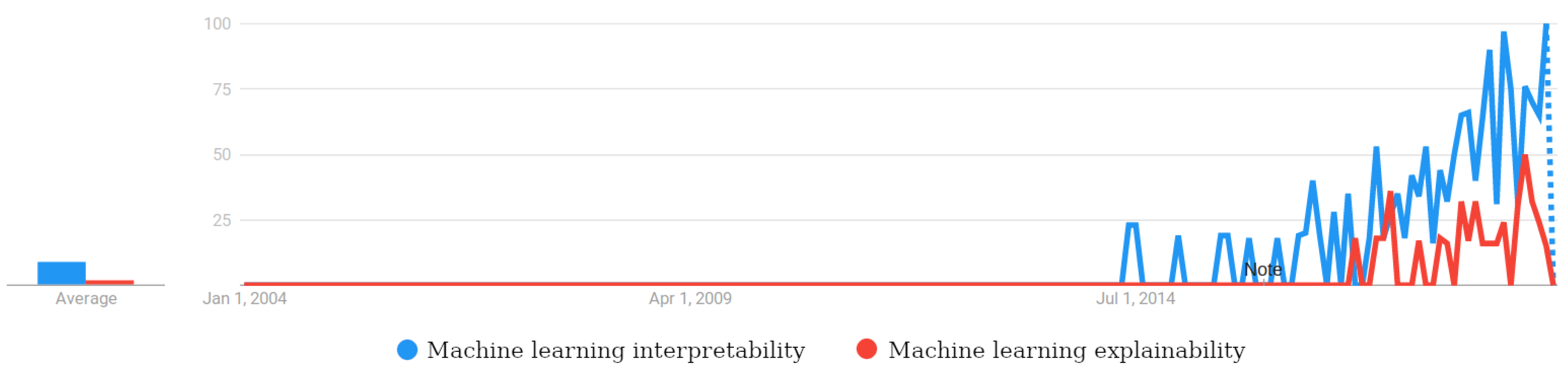

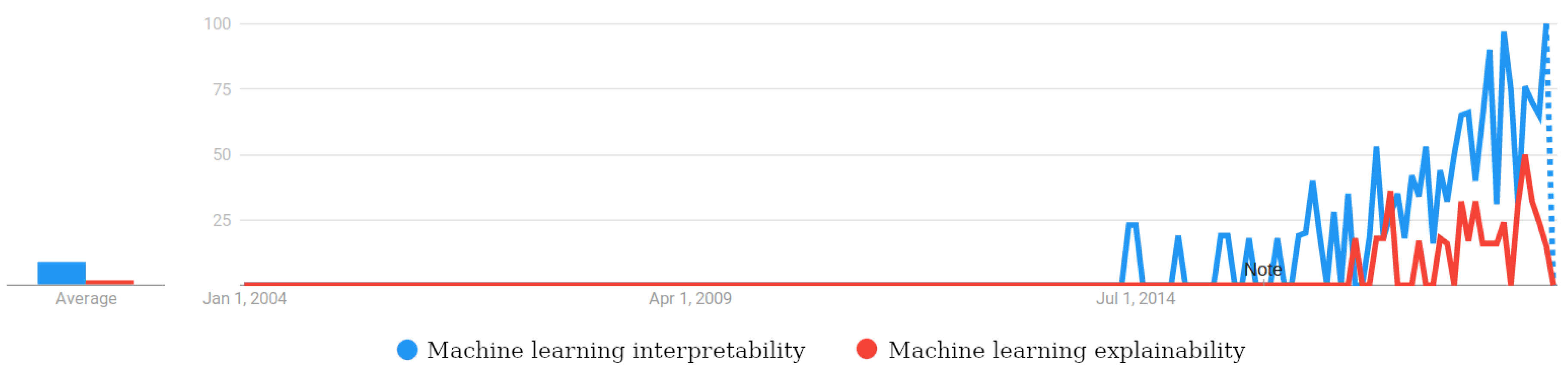{kind=link}
{kind=link}