FT-GAN: Face Transformation with Key Points Alignment for Pose-Invariant Face Recognition

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
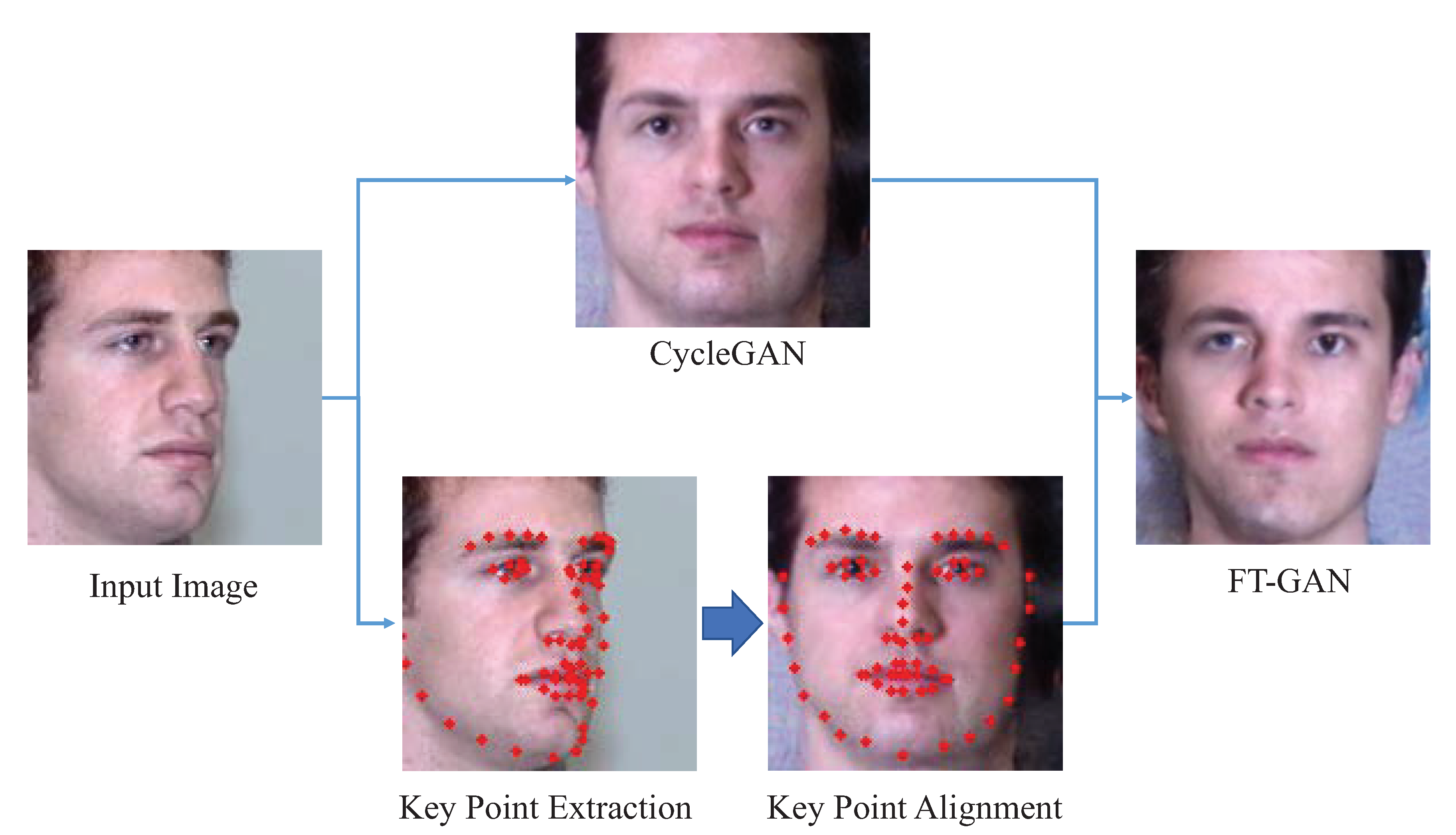
- First, CycleGAN is introduced to frontal face transformation. The mapping relationship from unconstrained faces to frontal faces is computed by pixel-to-pixel transformation.
- Second, key point alignment in introduced to refine the transformed results of CycleGAN. The positions of key points are extracted, and their spatial relationship is retained.
- Finally, based on FT-GAN, pose-invariant face recognition can be achieved. We conducted comprehensive experiments on two challenging benchmark datasets to validate the effectiveness of the proposed method.
2. FT-GAN for Pose-Invariant Face Recognition
2.1. Overview of FT-GAN
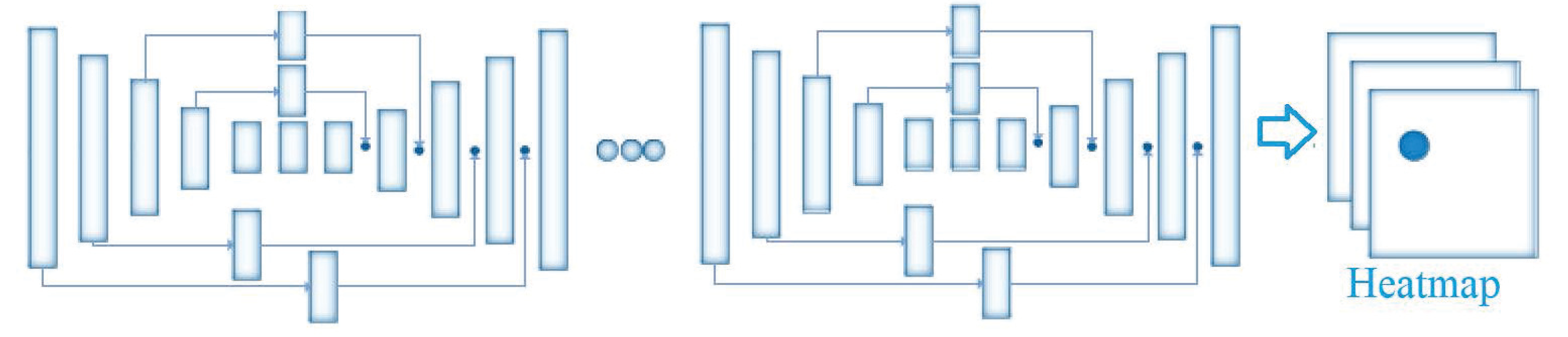
2.2. Face Transformation with Key Points Alignment
2.3. Pose-Invariant Face Recognition
2.3.1. Network Architecture
2.3.2. Implementation Details
| Algorithm 1 Details of Pose-invariant face recognition with FT-GAN. |
| Input: Unconstrained face images for training X, frontal face images for training Y, unconstrained face images for testing Output: Face recognition results 1: Detect faces in X, Y, and 2: Extract key points of X, Y, and 3: Train FT-GAN with X, Y, and the corresponding key points according to Equation (3) 4: Map unconstrained face images to frontal face images with the corresponding key points 5: Obtain with and face recognition methods (Dlib or FaceNet) 6: return Face recognition results |
3. Experimental Results
3.1. Datasets and Settings
3.2. Results of Frontal Face Synthesis
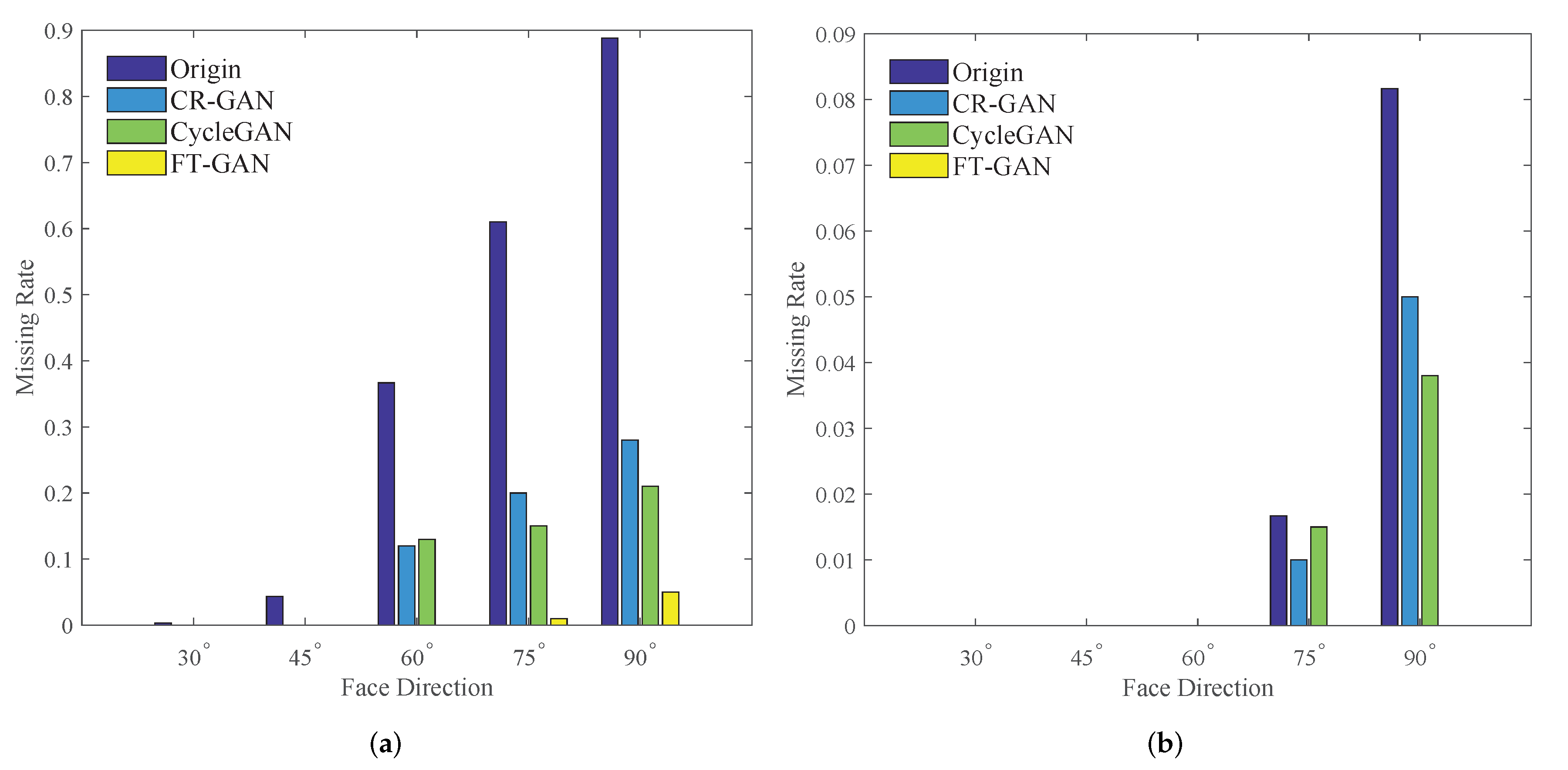
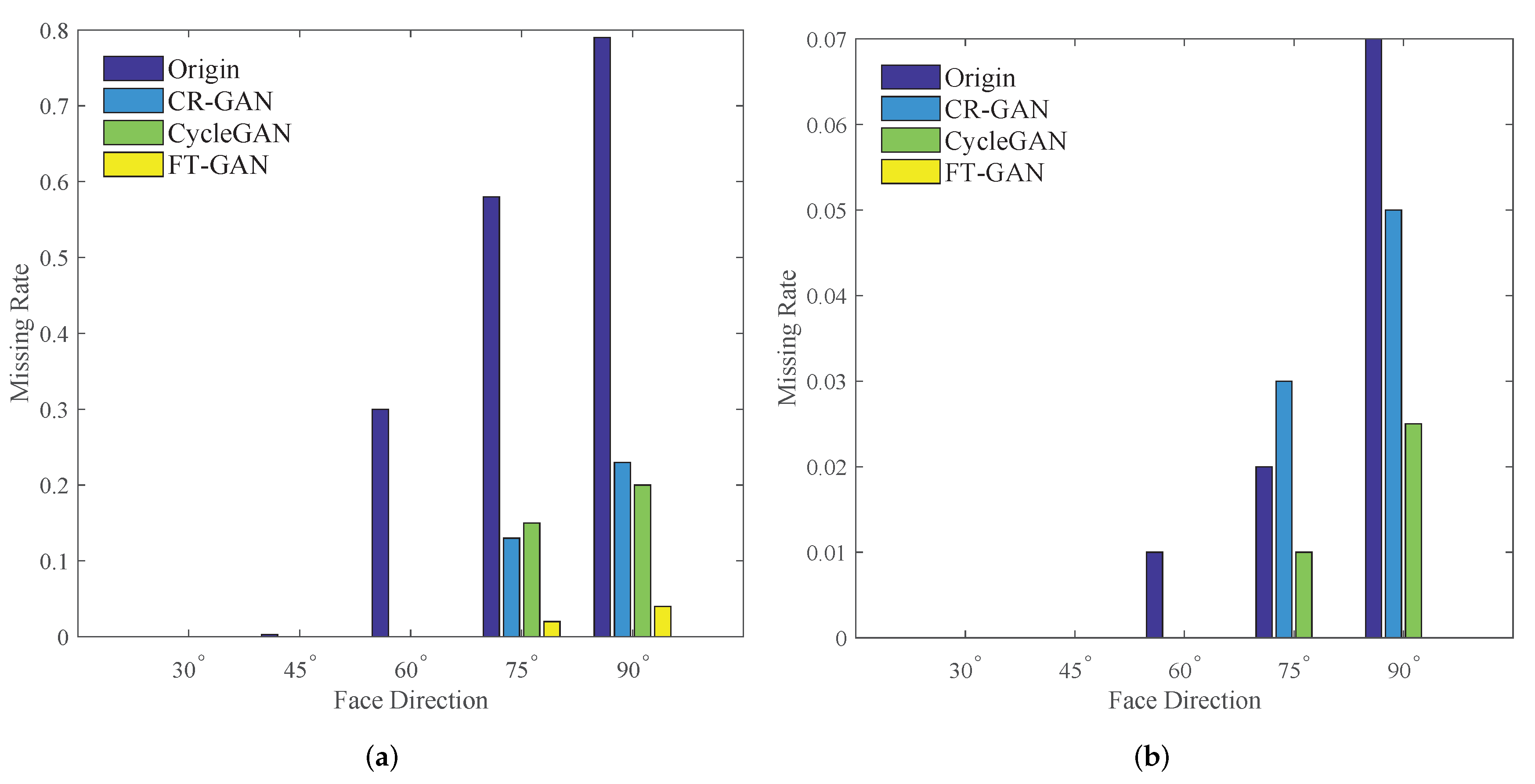
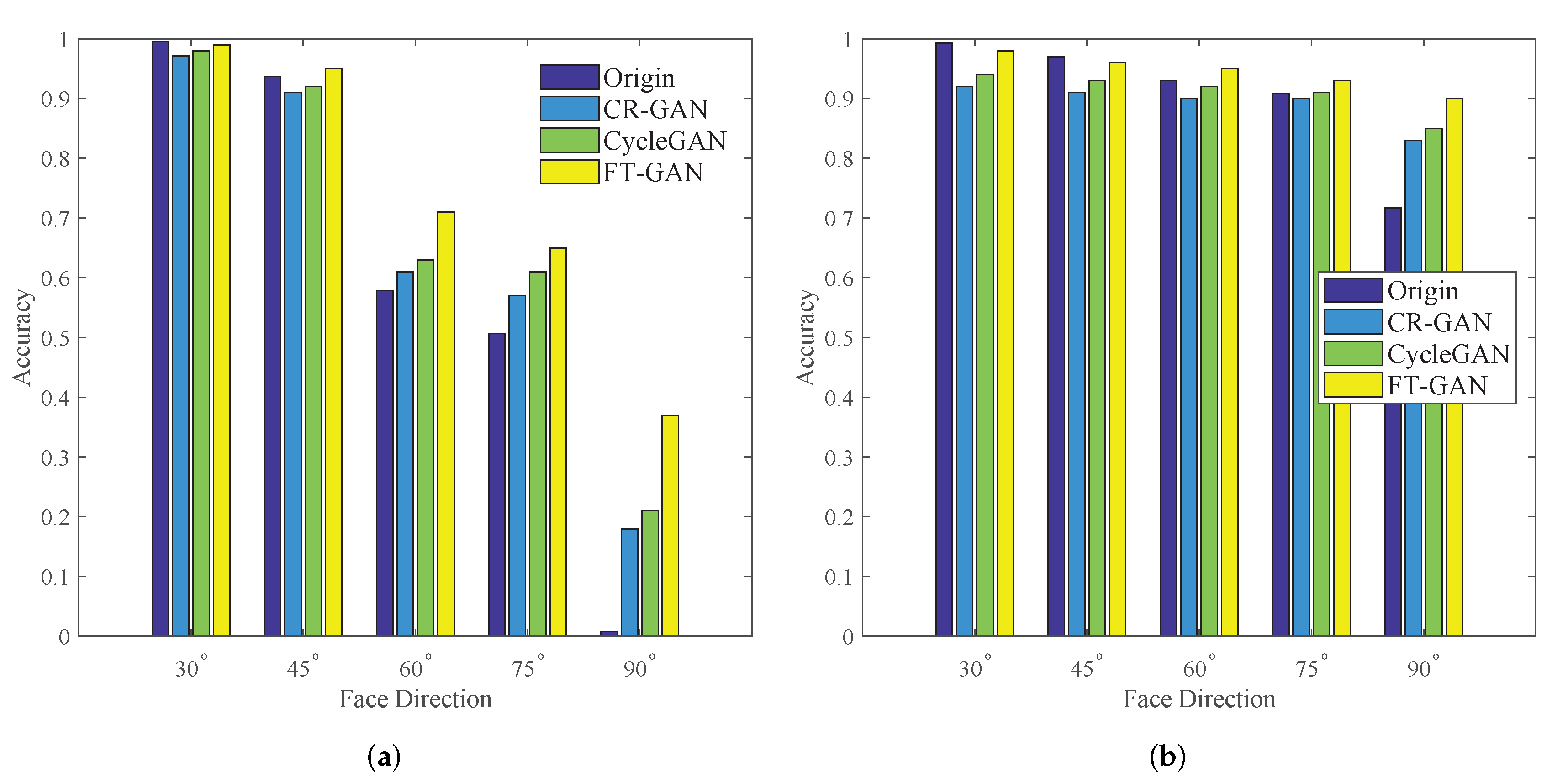
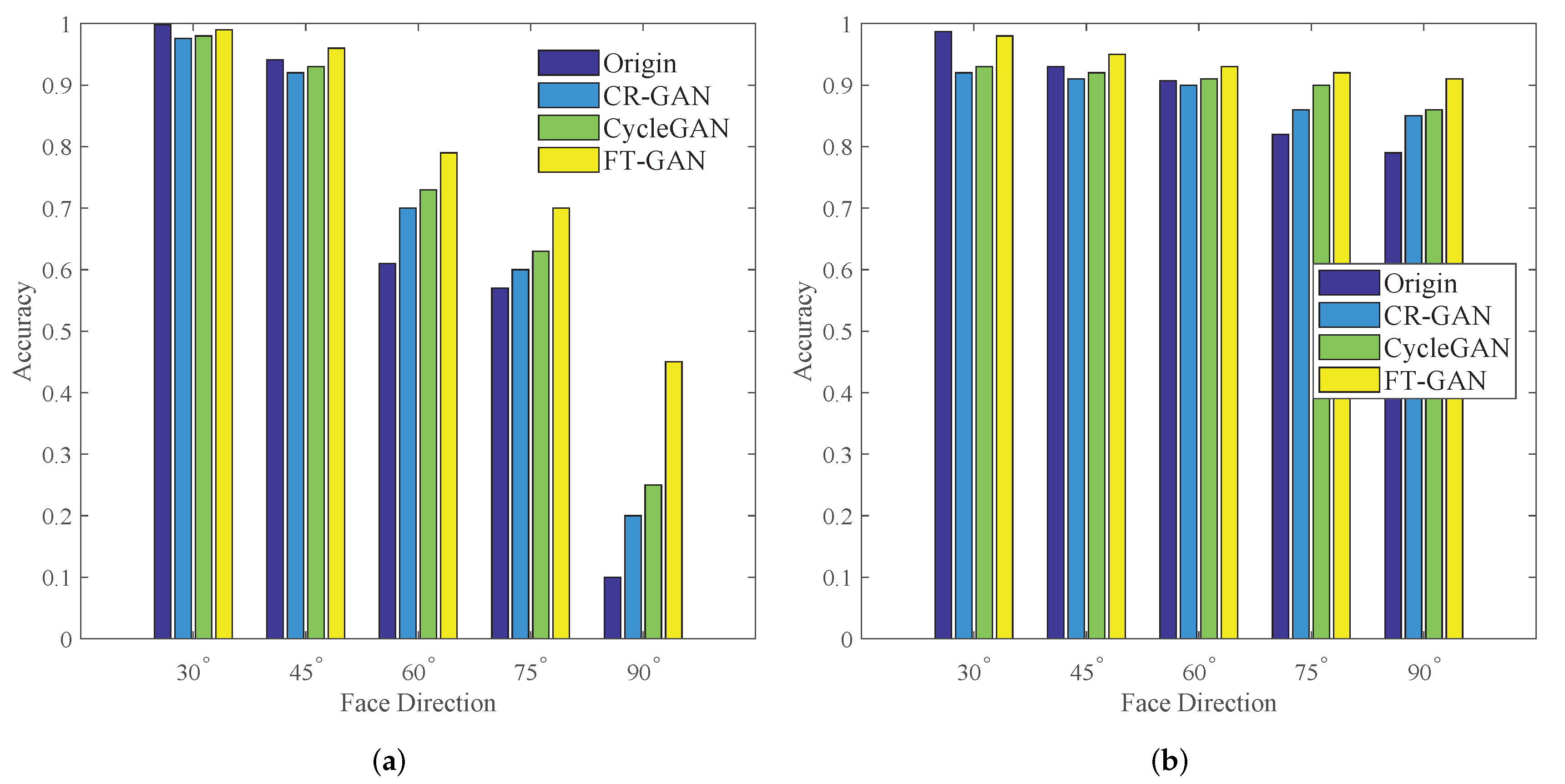
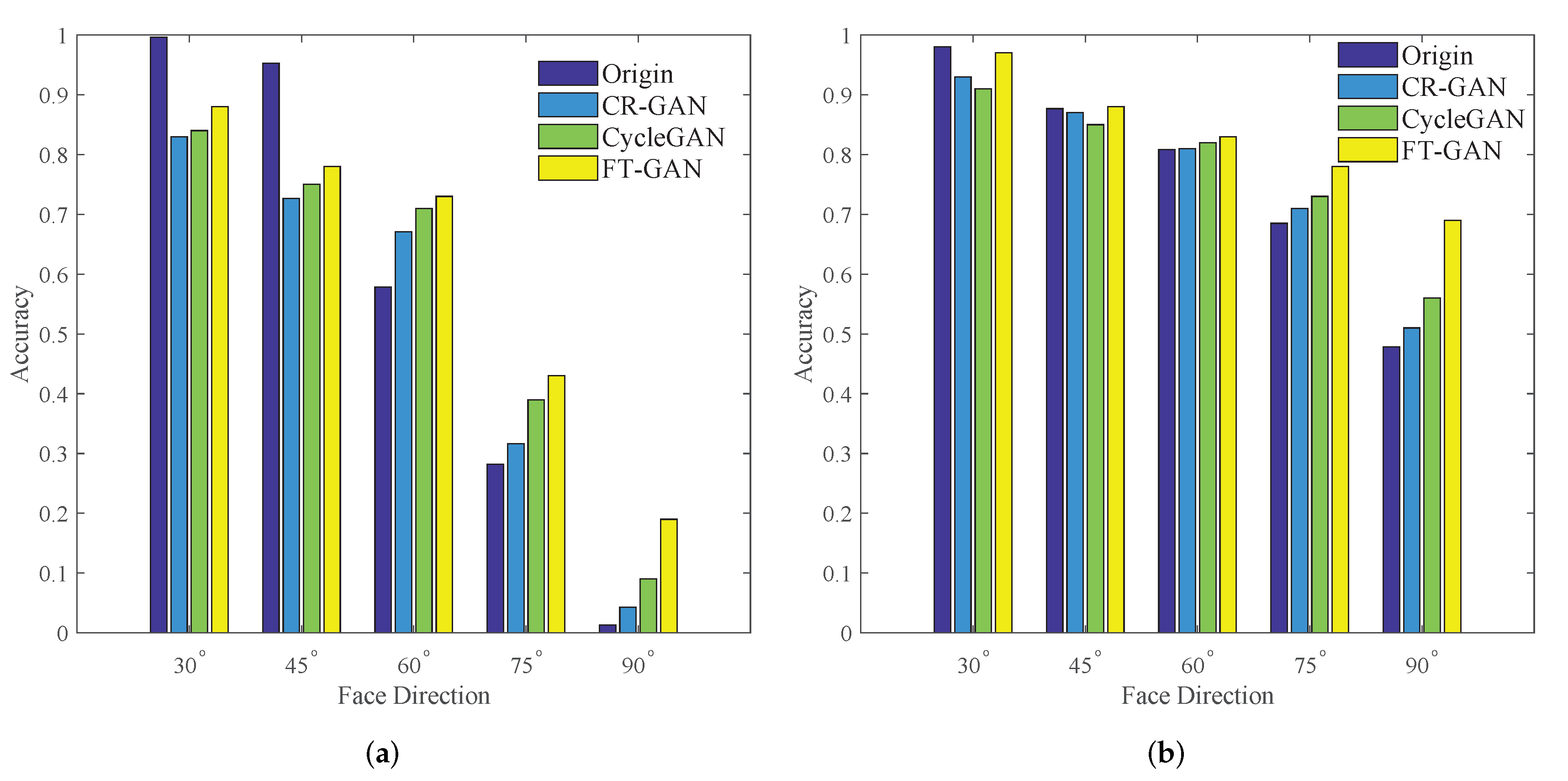
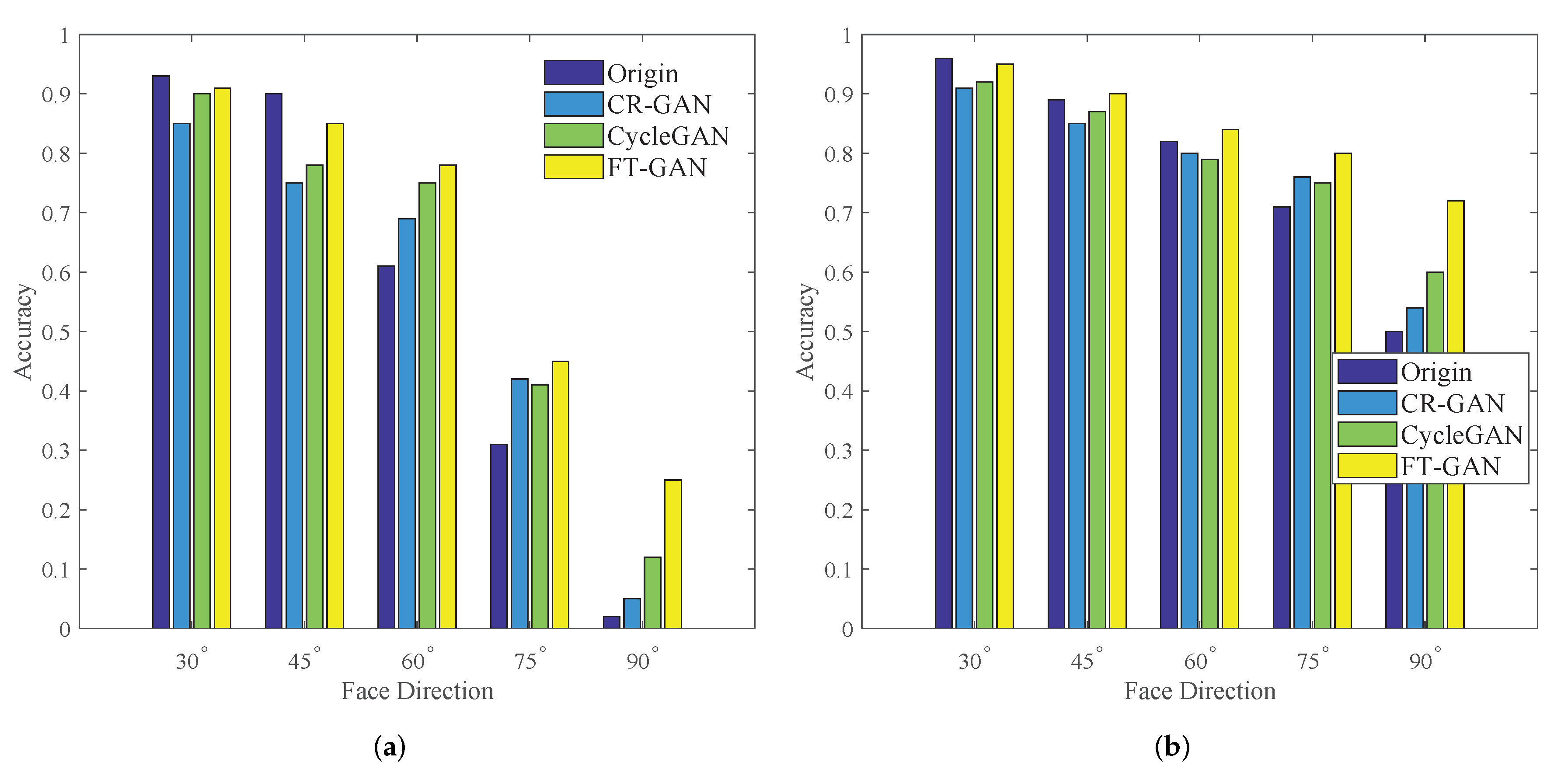
3.3. Results of Face Recognition with Complex Poses
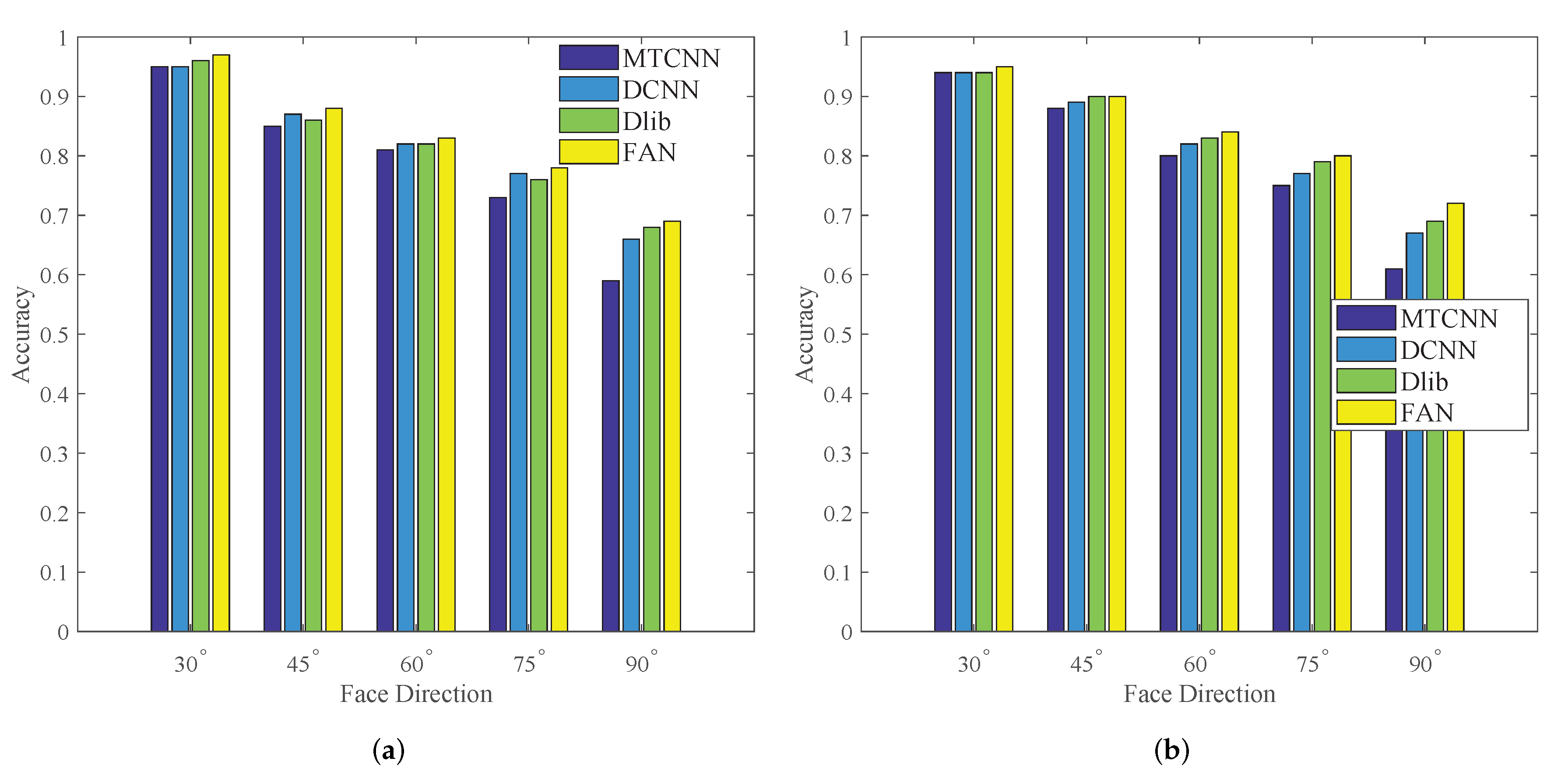
3.4. Influences of Key Point Extraction
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| GAN | Generative Adversarial Networks |
| CCA | Canonical Correlation Analysis |
| LDA | Linear Discriminant Analysis |
| DNN | Deep Neural Network |
References
- Learned-Miller, E.; Huang, G.B.; Roychowdhury, A.; Li, H.; Gang, H. Labeled Faces in the Wild: A Survey; Springer: Berlin, Germany, 2016. [Google Scholar]
- Yu, J.; Zhang, B.; Kuang, Z.; Dan, L.; Fan, J. iPrivacy: Image Privacy Protection by Identifying Sensitive Objects via Deep Multi-Task Learning. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1005–1016. [Google Scholar] [CrossRef]
- Li, A.; Shan, S.; Chen, X.; Wen, G. Maximizing intra-individual correlations for face recognition across pose differences. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 605–611. [Google Scholar]
- Akaho, S. A kernel method for canonical correlation analysis. arXiv 2006, arXiv:abs/cs/0609071. [Google Scholar]
- Wang, W.; Cui, Z.; Chang, H.; Shan, S.; Chen, X. Deeply Coupled Auto-encoder Networks for Cross-view Classification. arXiv 2014, arXiv:1402.2031. [Google Scholar]
- Sharma, A.; Kumar, A.; Daume, H.; Jacobs, D.W. Generalized Multiview Analysis: A discriminative latent space. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2160–2167. [Google Scholar]
- Dong, C.; Cao, X.; Fang, W.; Jian, S. Blessing of Dimensionality: High-Dimensional Feature and Its Efficient Compression for Face Verification. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3025–3032. [Google Scholar]
- Ding, C.; Choi, J.; Tao, D.; Davis, L.S. Multi-Directional Multi-Level Dual-Cross Patterns for Robust Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 518–531. [Google Scholar] [CrossRef] [PubMed]
- Dong, L.; Huiling, Z.; Kin-Man, L. High-resolution face verification using pore-scale facial features. IEEE Trans. Image Process. 2015, 24, 2317–2327. [Google Scholar]
- Zhang, Y.; Shao, M.; Wong, E.K.; Fu, Y. Random faces guided sparse many-to-one encoder for pose-invariant face recognition. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 2416–2423. [Google Scholar]
- Kan, M.; Shan, S.; Hong, C.; Chen, X. Stacked Progressive Auto-Encoders (SPAE) for Face Recognition Across Poses. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1883–1890. [Google Scholar]
- Hassner, T.; Harel, S.; Paz, E.; Enbar, R. Effective face frontalization in unconstrained images. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4295–4304. [Google Scholar]
- Yin, X.; Yu, X.; Sohn, K.; Liu, X.; Chandraker, M. Towards Large-Pose Face Frontalization in the Wild. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4010–4019. [Google Scholar]
- Hong, S.; Im, W.; Ryu, J.; Yang, H.S. SSPP-DAN: Deep domain adaptation network for face recognition with single sample per person. In Proceedings of the International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 825–829. [Google Scholar]
- Tian, Y.; Peng, X.; Zhao, L.; Zhang, S.; Metaxas, D.N. CR-GAN: Learning Complete Representations for Multi-view Generation. In Proceedings of the International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 942–948. [Google Scholar]
- Tran, L.; Yin, X.; Liu, X. Disentangled Representation Learning GAN for Pose-Invariant Face Recognition. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1283–1292. [Google Scholar]
- Lu, Y.; Tai, Y.; Tang, C. Conditional CycleGAN for Attribute Guided Face Image Generation. arXiv 2017, arXiv:1705.09966. [Google Scholar]
- Goodfellow, I.J.; Pougetabadie, J.; Mirza, M.; Xu, B.; Wardefarley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems; MIT Press: Montreal, QC, Canada, 2014; pp. 2672–2680. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Zhou, E.; Fan, H.; Cao, Z.; Jiang, Y.; Qi, Y. Extensive Facial Landmark Localization with Coarse-to-Fine Convolutional Network Cascade. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 2–8 December 2013; pp. 386–391. [Google Scholar]
- Kazemi, V.; Sullivan, J. One Millisecond Face Alignment with an Ensemble of Regression Trees. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Zhang, Z.; Luo, P.; Loy, C.C.; Tang, X. Learning Deep Representation for Face Alignment with Auxiliary Attributes. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 918–930. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Zhang, Z.; Li, Z.; Yu, Q. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Wu, Y.; Hassner, T.; Kim, K.; Medioni, G.G.; Natarajan, P. Facial Landmark Detection with Tweaked Convolutional Neural Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 3067–3074. [Google Scholar] [CrossRef] [PubMed]
- Kowalski, M.; Naruniec, J.; Trzcinski, T.P. Deep Alignment Network: A Convolutional Neural Network for Robust Face Alignment. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 2034–2043. [Google Scholar]
- Bulat, A.; Tzimiropoulos, G. How far are we from solving the 2D & 3D Face Alignment problem? (and a dataset of 230,000 3D facial landmarks). In Proceedings of the International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1021–1030. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked Hourglass Networks for Human Pose Estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherland, 9 July 2016; pp. 483–499. [Google Scholar]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Gross, R.; Matthews, I.A.; Cohn, J.F.; Kanade, T.; Baker, S. Multi-PIE. Image Vis. Comput. 2010, 28, 807–813. [Google Scholar] [CrossRef] [PubMed]
- Gourier, N.; Hall, D.; Crowley, J.L. Estimating Face Orientation from Robust Detection of Salient Facial Features. In Proceedings of the International Workshop on Visual Observation of Deictic Gestures, Cambridge, UK, 23–26 August 2004. [Google Scholar]

© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhuang, W.; Chen, L.; Hong, C.; Liang, Y.; Wu, K. FT-GAN: Face Transformation with Key Points Alignment for Pose-Invariant Face Recognition. Electronics 2019, 8, 807. https://doi.org/10.3390/electronics8070807
Zhuang W, Chen L, Hong C, Liang Y, Wu K. FT-GAN: Face Transformation with Key Points Alignment for Pose-Invariant Face Recognition. Electronics. 2019; 8(7):807. https://doi.org/10.3390/electronics8070807
Chicago/Turabian StyleZhuang, Weiwei, Liang Chen, Chaoqun Hong, Yuxin Liang, and Keshou Wu. 2019. "FT-GAN: Face Transformation with Key Points Alignment for Pose-Invariant Face Recognition" Electronics 8, no. 7: 807. https://doi.org/10.3390/electronics8070807
APA StyleZhuang, W., Chen, L., Hong, C., Liang, Y., & Wu, K. (2019). FT-GAN: Face Transformation with Key Points Alignment for Pose-Invariant Face Recognition. Electronics, 8(7), 807. https://doi.org/10.3390/electronics8070807