M3C: Multimodel-and-Multicue-Based Tracking by Detection of Surrounding Vessels in Maritime Environment for USV

 , and
, and
Abstract
1. Introduction
2. Related Work
2.1. Deep Learning for Generic Target Detection
2.2. Deep Learning for Generic Target Tracking
2.3. Visible Vessel Detection and Tracking
3. The Proposed Tracking by Detection Approach
3.1. The Detector Based on YOLOv3
3.2. Multimodel for Tracking by Detection.
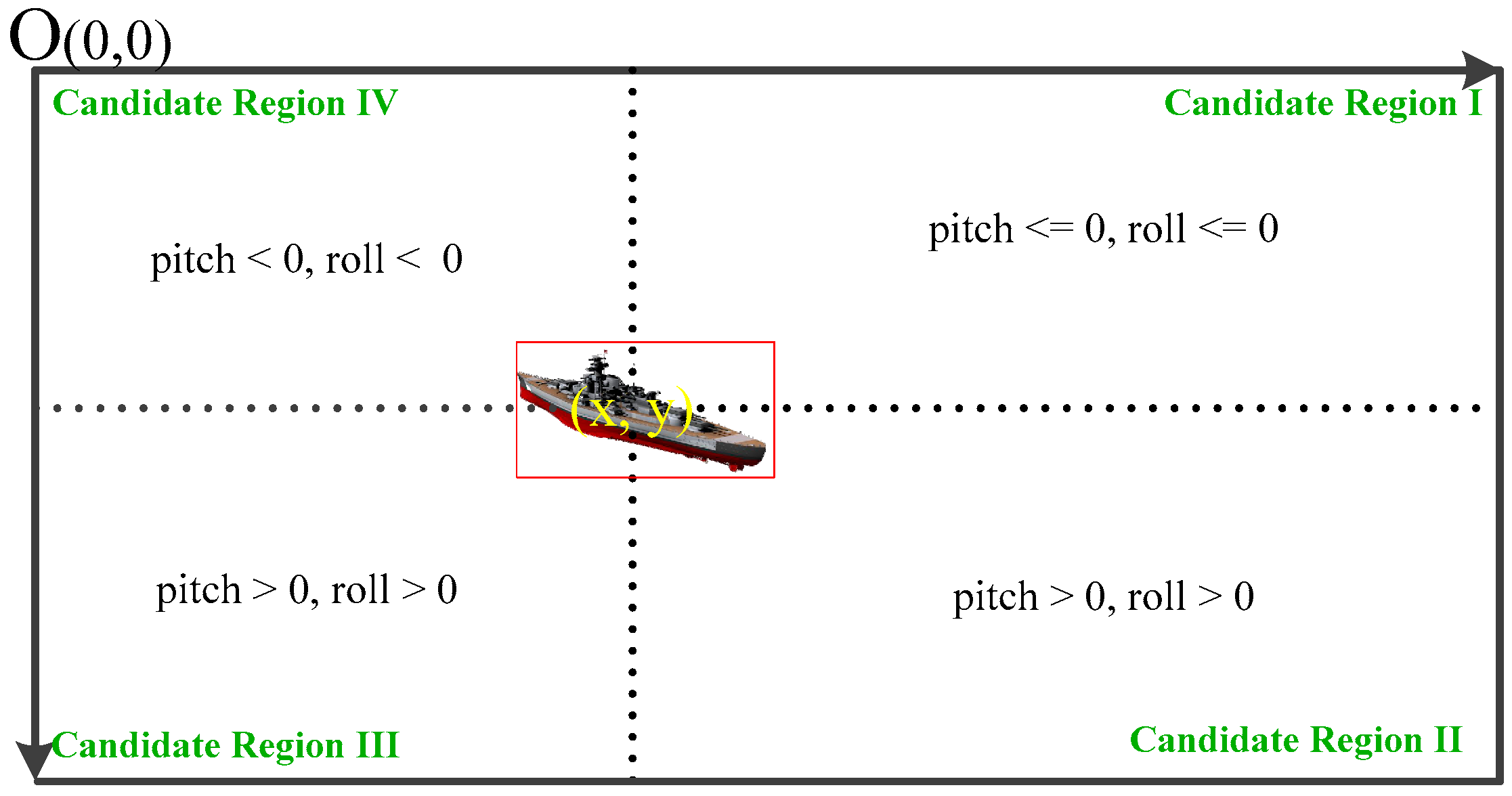
3.2.1. Maneuvering Model of Vessels
3.2.2. Encoder-Decoder Model of GRU-Attention
3.2.3. Multimodel Filter
3.3. Multicue for Data Association
3.3.1. Adaptive Association Gate of Appearance
3.3.2. Long-Term Cues
3.3.3. Data Association and Fusion Method
3.4. The Proposed M3C Tracking by Detection
| Algorithm 1: The proposed M3C tracking by detection |
| Inputs: The sequential frames of surrounding vessels , pre-trained GRU model , Darknet53 model , Ship-Reid model , and periodic attitude data of the ego vessel |
| Initialization: , , , |
| Outputs: Continuous tracklets of surrounding vessels |
| Procedure: |
| foreach frame at current time |
| detect all potential vessels from the frame using |
| foreach tracklet of vessel // Association gate generated from prior time |
| Predict the kinematic track gate from MM filter from time |
| & adaptive association gate of appearance |
| endfor |
| MC data association using simulated annealing algorithm |
| foreach pair of matched detection and tracklet |
| tracklet update by MM filter |
| endfor |
| foreach detection vessel not associated with any tracklets in |
| if //Three-frame tracklet initiation |
| initialize a new tracklet |
| end |
| endfor |
| foreach vessel tracklet not associated with any detection in |
| tracklet extrapolation |
| if // Extrapolation times exceeding the pre-set value |
| terminate the tracklet |
| end |
| endfor |
| endfor //reach the end of the video sequence |
4. Experiment and Results Analysis
4.1. Experimental Setup
4.1.1. Datasets
4.1.2. Implementation Details
4.2. Performance Evaluation
4.2.1. Evaluation Metric
4.2.2. Qualitative Results
4.2.3. Visual Tracking Results
4.3. Ablation Study and Analysis
4.3.1. Effect of Multimodel Fusion Filter
4.3.2. Effect of Detector
4.3.3. Effect of Multicue Data Association
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Prasad, D.K.; Rajan, D.; Rachmawati, L.; Rajabally, E.; Quek, C. Video Processing from Electro-Optical Sensors for Object Detection and Tracking in a Maritime Environment: A Survey. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1993–2016. [Google Scholar] [CrossRef]
- Bloisi, D.; Iocchi, L. ARGOS—A video surveillance system for boat traffic monitoring in venice. Int. J. Pattern Recognit. Artif. Intell. 2009, 23, 1477–1502. [Google Scholar] [CrossRef]
- Kang, Y.T.; Chen, W.J.; Zhu, D.Q.; Wang, J.H.; Xie, Q.M. Collision avoidance path planning for ships by particle swarm optimization. J. Mar. Sci. Technol. 2018, 26, 777–786. [Google Scholar]
- Dijk, J.; van der Stap, N.; van den Broek, B.; Pruim, R.; Schutte, K.; den Hollander, R.; van Opbroek, A.; Huizinga, W.; Wilmer, M. Maritime detection framework 2.0: A new approach of maritime target detection in electro-optical sensors. In Proceedings of the Electro-Optical and Infrared Systems: Technology and Applications XV, Berlin, Germany, 9 October 2018; Volume 10795, p. 1079507. [Google Scholar]
- Yazdi, M.; Bouwmans, T. New trends on moving object detection in video images captured by a moving camera: A survey. Comput. Sci. Rev. 2018, 28, 157–177. [Google Scholar] [CrossRef]
- Patino, L.; Nawaz, T.; Cane, T.; Ferryman, J. Pets 2016: Dataset and Challenge. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPR), Las Vegas, NV, USA, 1–26 June 2016; pp. 1–8. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 8–16 October 2016; Lecture Notes in Computer Science. pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Shi, J. FoveaBox: Beyond Anchor-based Object Detector. arXiv 2019, arXiv:1904.03797. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature Selective Anchor-Free Module for Single-Shot Object Detection. arXiv 2019, arXiv:1903.00621. [Google Scholar]
- Tonissen, S.M.; Evans, R.J. Performance of dynamic programming techniques for track-before-detect. IEEE Trans. Aerosp. Electron. Syst. 1996, 32, 1440–1451. [Google Scholar] [CrossRef]
- Kieritz, H.; Hübner, W.; Arens, M. Joint detection and online multi-object tracking. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1540–15408. [Google Scholar]
- Gordon, D.; Farhadi, A.; Fox, D. Re3: Real-time recurrent regression networks for visual tracking of generic objects. IEEE Robot. Autom. Lett. 2018, 3, 788–795. [Google Scholar] [CrossRef]
- Bae, S.H.; Yoon, K.J. Confidence-Based Data Association and Discriminative Deep Appearance Learning for Robust Online Multi-Object Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 595–610. [Google Scholar] [CrossRef] [PubMed]
- Arandjelović, O. Automatic vehicle tracking and recognition from aerial image sequences. In Proceedings of the 12th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Karlsruhe, Germany, 25–28 August 2015; pp. 1–6. [Google Scholar]
- Wojke, N.; Bewley, A. Deep cosine metric learning for person re-identification. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 748–756. [Google Scholar]
- Yang, X.; Tang, Y.; Wang, N.; Song, B.; Gao, X. An End-to-End Noise-Weakened Person Re-Identification and Tracking with Adaptive Partial Information. IEEE Access 2019, 7, 20984–20995. [Google Scholar] [CrossRef]
- Zhao, D.; Fu, H.; Xiao, L.; Wu, T.; Dai, B. Multi-object tracking with correlation filter for autonomous vehicle. Sensors 2018, 18, 2004. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Tian, Y.; Wang, Y.; Pang, L.; Huang, T. Deep Relative Distance Learning: Tell the Difference between Similar Vehicles. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2167–2175. [Google Scholar]
- Fefilatyev, S.; Goldgof, D.; Shreve, M.; Lembke, C. Detection and tracking of ships in open sea with rapidly moving buoy-mounted camera system. Ocean Eng. 2012, 54, 1–12. [Google Scholar] [CrossRef]
- Jeong, C.Y.; Yang, H.S.; Moon, K.D. Fast horizon detection in maritime images using region-of-interest. Int. J. Distrib. Sens. Networks 2018, 14. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, Q.Z.; Zang, F.N. Ship detection for visual maritime surveillance from non-stationary platforms. Ocean Eng. 2017, 141, 53–63. [Google Scholar] [CrossRef]
- Sun, Y.; Fu, L. Coarse-fine-stitched: A robust maritime horizon line detection method for unmanned surface vehicle applications. Sensors 2018, 18, 2825. [Google Scholar] [CrossRef]
- Bovcon, B.; Perš, J.; Kristan, M. Stereo obstacle detection for unmanned surface vehicles by IMU-assisted semantic segmentation. Rob. Auton. Syst. 2018, 104, 1–13. [Google Scholar] [CrossRef]
- Cane, T.; Ferryman, J. Evaluating deep semantic segmentation networks for object detection in maritime surveillance. In Proceedings of the 15th IEEE International Conference on Advanced Video and Signal-Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Kim, K.; Hong, S.; Choi, B.; Kim, E. Probabilistic Ship Detection and Classification Using Deep Learning. Appl. Sci. 2018, 8, 936. [Google Scholar] [CrossRef]
- Marié, V.; Béchar, I.; Bouchara, F. Real-time maritime situation awareness based on deep learning with dynamic anchors. In Proceedings of the 15th IEEE International Conference on Advanced Video and Signal-Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–6. [Google Scholar]
- Cao, X.; Gao, S.; Chen, L.; Wang, Y. Ship recognition method combined with image segmentation and deep learning feature extraction in video surveillance. Multimed. Tools Appl. 2019, 1–16. [Google Scholar] [CrossRef]
- Leclerc, M.; Tharmarasa, R.; Florea, M.C.; Boury-Brisset, A.C.; Kirubarajan, T.; Duclos-Hindié, N. Ship Classification Using Deep Learning Techniques for Maritime Target Tracking. In Proceedings of the 2018 21st International Conference on Information Fusion (FUSION), Cambridge, UK, 10–13 July 2018; pp. 737–744. [Google Scholar]
- Kejriwal, L.; Singh, I. A Hybrid Filtering Approach of Digital Video Stabilization for UAV Using Kalman and Low Pass Filter. Procedia Comput. Sci. 2016, 93, 359–366. [Google Scholar] [CrossRef][Green Version]
- Best, R.A.; Norton, J.P. A new model and efficient tracker for a target with curvilinear motion. IEEE Trans. Aerosp. Electron. Syst. 1997, 33, 1030–1037. [Google Scholar] [CrossRef]
- Perera, L.P.; Oliveira, P.; Guedes Soares, C. Maritime Traffic Monitoring Based on Vessel Detection, Tracking, State Estimation, and Trajectory Prediction. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1188–1200. [Google Scholar] [CrossRef]
- Li, J.; Dai, B.; Li, X.; Xu, X.; Liu, D. A Dynamic Bayesian Network for Vehicle Maneuver Prediction in Highway Driving Scenarios: Framework and Verification. Electronics 2019, 8, 40. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Bar-Shalom, Y.; Blackman, S.S.; Fitzgerald, R.J. Dimensionless score function for multiple hypothesis tracking. IEEE Trans. Aerosp. Electron. Syst. 2007, 43, 392–400. [Google Scholar] [CrossRef]
- Hoiem, D.; Efros, A.A.; Hebert, M. Putting objects in perspective. Int. J. Comput. Vis. 2008, 80, 3–15. [Google Scholar] [CrossRef]
- Richardson, E.; Peleg, S.; Werman, M. Scene geometry from moving objects. In Proceedings of the Advanced Video and Signal-based Surveillance (AVSS), Seoul, South Korea, 26–29 August 2014; pp. 13–18. [Google Scholar]
- Racine, V.; Hertzog, A.; Jouanneau, J.; Salamero, J.; Kervrann, C.; Sibarita, J. Multiple-Target Tracking of 3D Fluorescent Objects Based on Simulated Annealing. In Proceedings of the 3rd IEEE International Symposium on Biomedical Imaging: Nano to Macro, Arlington, VA, USA, 6–9 April 2006; pp. 1020–1023. [Google Scholar]
- Osman, I.H. Heuristics for the generalised assignment problem: Simulated annealing and tabu search approaches. OR Spektrum 1995, 17, 211–225. [Google Scholar] [CrossRef]
- Gundogdu, E.; Solmaz, B.; Yücesoy, V.; Koc, A. MARVEL: A large-scale image dataset for maritime vessels. In Proceedings of the Asian Conference on Computer Vision (ACCV), Taipei, Taiwan, 21–23 November 2016; pp. 165–180. [Google Scholar]
- Nguyen, D.; Vadaine, R.; Hajduch, G.; Garello, R.; Fablet, R. A multi-task deep learning architecture for maritime surveillance using AIS data streams. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 331–340. [Google Scholar]
- Bernardin, K.; Stiefelhagen, R. Evaluating multiple object tracking performance: The clear mot metrics. Eurasip J. Image Video Proc. 2008, 2008, 246309. [Google Scholar] [CrossRef]
- Xiang, Y.; Alahi, A.; Savarese, S. Learning to track: Online multi-object tracking by decision making. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4705–4713. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the 2016 International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3464–3468. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef]
- Yu, F.; Li, W.; Li, Q.; Liu, Y.; Shi, X.; Yan, J. POI: Multiple object tracking with high performance detection and appearance feature. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; pp. 36–42. [Google Scholar]
- Chen, L.; Ai, H.; Zhuang, Z.; Shang, C. Real-Time Multiple People Tracking with Deeply Learned Candidate Selection and Person Re-Identification. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Labbe, R.R. Kalman and Bayesian Filters in Python. 2018. Available online: https://github.com/rlabbe/Kalman-and-Bayesian-Filters-in-Python (accessed on 20 May 2019).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Map | 19 × 19 | 38 × 38 | 76 × 76 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Receptive Field | Big | Medium | Small | ||||||
| Prior Anchors | 110 × 84 | 176 × 93 | 267 × 166 | 35 × 65 | 62 × 57 | 107 × 39 | 43 × 19 | 38 × 39 | 68 × 29 |
| Dataset | Tracker | MOTA↑ | MOTP↑ | MT↑ | ML↓ | IDS↓ | FPS↑ |
|---|---|---|---|---|---|---|---|
| SMD (onshore) + PETS 2016 | MDP | 30.3% | 71.3% | 13.2% | 38.4% | 426 | 1 |
| SORT | 59.8% | 79.6% | 25.4% | 22.7% | 631 | 56 | |
| KCF | 70.3% | 80.2% | 37.8% | 22.3% | 382 | 25 | |
| POI | 66.1% | 79.5% | 34.6% | 20.8% | 453 | 10 | |
| M3C (Ours) | 72.8% | 80.4% | 37.4% | 21.2% | 254 | 20 | |
| SMD (onboard) | DeepSORT | 60.4% | 79.1% | 32.8% | 18.2% | 56 | 36 |
| MOTDT | 57.6% | 70.9% | 34.2% | 28.7% | 49 | 23 | |
| M3C (Ours) | 63.4% | 74.6% | 26.2 | 17.9% | 34 | 16 |
| Motion Scenarios | Algorithm | Averaged RMSE (L2 Norm) | Averaged MAE (L1 Norm) | ||
|---|---|---|---|---|---|
| X pos. | Y pos. | X pos. | Y pos. | ||
| Straight line, constant velocity | Kalman () | 14.71 | 16.06 | 11.47 | 14.53 |
| IMM () | 15.10 | 15.87 | 12.03 | 14.28 | |
| MM(Proposed) | 9.10 | 9.58 | 5.75 | 6.02 | |
| Acceleration | Kalman () | 27.71 | 21.29 | 25.38 | 20.54 |
| IMM () | 21.17 | 18.26 | 18.67 | 15.88 | |
| MM(Proposed) | 13.93 | 12.21 | 8.04 | 7.04 | |
| Turning | Kalman () | 20.99 | 15.85 | 19.54 | 15.03 |
| IMM () | 15.10 | 13.11 | 12.93 | 10.98 | |
| MM (Proposed) | 12.44 | 9.56 | 8.80 | 6.67 | |
| Tracker | Detector | mAP | FPS | Averaged RMSE (L2 Norm) | Averaged MAE (L1 Norm) | ||
|---|---|---|---|---|---|---|---|
| X pos. | Y pos. | X pos. | Y pos. | ||||
| M3C | SSD300 (Mobilenet) | 41.2 | 46 | 20.22 | 17.59 | 9.54 | 16.37 |
| YOLOv3 (Darknet53) | 57.9 | 20 | 9.10 | 9.58 | 7.75 | 6.02 | |
| Faster R-CNN (Resnet50) | 59.1 | 4 | 8.94 | 6.39 | 8.44 | 5.83 | |
| Tracker | Detector | MOTA↑ | MOTP↑ | MT↑ | ML↓ | IDS↓ | FPS↑ |
|---|---|---|---|---|---|---|---|
| MM | YOLOv3 | 46.2% | 44.5% | 12.9% | 43.2% | 74 | 28 |
| MM + Attention | YOLOv3 | 47.1% | 43.8% | 13.1% | 44.7% | 73 | 32 |
| SM+ReID | YOLOv3 | 59.8% | 64.5% | 21.4% | 23.6% | 62 | 20 |
| MM+ReID (M3C) | YOLOv3 | 63.4% | 74.6% | 36.2% | 17.9% | 24 | 16 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiao, D.; Liu, G.; Zhang, J.; Zhang, Q.; Wu, G.; Dong, F. M3C: Multimodel-and-Multicue-Based Tracking by Detection of Surrounding Vessels in Maritime Environment for USV. Electronics 2019, 8, 723. https://doi.org/10.3390/electronics8070723
Qiao D, Liu G, Zhang J, Zhang Q, Wu G, Dong F. M3C: Multimodel-and-Multicue-Based Tracking by Detection of Surrounding Vessels in Maritime Environment for USV. Electronics. 2019; 8(7):723. https://doi.org/10.3390/electronics8070723
Chicago/Turabian StyleQiao, Dalei, Guangzhong Liu, Jun Zhang, Qiangyong Zhang, Gongxing Wu, and Feng Dong. 2019. "M3C: Multimodel-and-Multicue-Based Tracking by Detection of Surrounding Vessels in Maritime Environment for USV" Electronics 8, no. 7: 723. https://doi.org/10.3390/electronics8070723
APA StyleQiao, D., Liu, G., Zhang, J., Zhang, Q., Wu, G., & Dong, F. (2019). M3C: Multimodel-and-Multicue-Based Tracking by Detection of Surrounding Vessels in Maritime Environment for USV. Electronics, 8(7), 723. https://doi.org/10.3390/electronics8070723