1. Introduction
Humanoid robots are an attractive topic in the field of robotics. A biped structure is designed for humanoid robots and is expected to facilitate human lives and even allow the robots to coexist with humans. Therefore, bipedal locomotion is an important ability of humanoid robots that is widely researched. Some gait patterns are motivated by biologically inspired control concepts to achieve bipedal locomotion. Rhythmic movements in animals are realized via an interaction between the dynamics of a musculoskeletal system and the rhythmic signals from central pattern generators (CPGs) [
1,
2]. In robotics, CPGs were formulated as a set of neural oscillators to produce the gait pattern of oscillations necessary for rhythmic movements [
3,
4]. Based on the neural oscillator, a set of coupled-phase oscillators were presented using sinusoidal functions for the gait pattern [
5]. However, the neural oscillator and the coupled-phase oscillator are modulated in the joint space for each joint of the humanoid robot, resulting in too many parameters needing to be adjusted. Based on the Cartesian coordinate system, the simplified coupled linear oscillators were extended from the abovementioned methods to produce the gait pattern [
6,
7] with trajectory planning in the workspace [
8,
9]. The simplified coupled linear oscillators can be divided into a balance oscillator and two movement oscillators which have a direct correlation between the oscillator parameters and the gait pattern. The center of mass (CoM) trajectory can be designed through the balance oscillator and its oscillator parameters. Similarly, the left and right ankle trajectories can be designed through the movement oscillator and its oscillator parameters. Hence, these oscillator parameters all affect the gait pattern for the humanoid robot. This gait pattern for the humanoid robot can achieve high flexibility through adjustment of the parameters of the oscillator-based gait pattern. Inverse kinematics [
10] was performed to transform trajectory planning into the desired joint position, and the gait pattern of the humanoid robot can be implemented to achieve bipedal locomotion.
The ability to improve the desired behavior of the robot is a significant technical challenge. The dynamic motion problems could be solved for unmanned aerial vehicles (UAVs) [
11], quadruped robots [
12], and even high-dimensional humanoid robots [
13] using the Q-learning algorithm [
14,
15,
16]. Most gait patterns are designed for humanoid robots, assuming an ideal situation. However, in the long-term operation of the humanoid robot, some errors may accumulate owing to mechanism error and motor backlash. Moreover, the real environment may also result in the humanoid robot exhibiting some unexpected behaviors. In order to adapt environmental changes through the gait pattern of the humanoid robot, sensors are needed to obtain environmental information [
17,
18,
19]. The desired behavior of the robot can be learned to appropriately modulate the observed gait pattern [
20,
21,
22,
23]. Hence, some studies were developed to adjust the joints [
24,
25] of the humanoid robot based on the interaction between the robot and the environment. The angle at each joint can be calculated and rotated to simulate the straightforward gait pattern. Furthermore, some studies were developed to adjust the poses [
26] of the humanoid robot in order to speed up the learning process. The robot poses are formed by a set of gait patterns to avoid the complex adjustment of multiple joints and to further implement the straightforward gait pattern. Hence, the straightforward gait pattern is learned for the humanoid robot by adjusting the gait pattern with environmental information.
In most cases, for humanoid robots, the simulation results are adequate, but it is difficult to directly apply the calculated data to real humanoid robots owing to the possibility of mechanism error and motor backlash. Therefore, this paper focuses on an experiment to allow a real robot to successfully learn the desired behavior. In this paper, a learning framework is proposed for the humanoid robot to efficiently learn a straightforward walking gait in a real-life situation. In order to reduce the number of learning parameters, an oscillator-based gait pattern with sinusoidal functions is designed so that it can simultaneously speed up the learning process and make the gait pattern more flexible to achieve bipedal locomotion. In this paper, only the turning direction (the parameter of the gait pattern) needs to be learned by the Q-learning algorithm to obtain a straightforward gait pattern. Moreover, in order to reduce the level of human resources and to protect the humanoid robot, an automatic training platform, as an auxiliary function, is designed to effectively assist and supervise the intrinsically unstable humanoid robot. The automatic training platform can also be applied to collect environmental information for the humanoid robot to adjust the turning direction. The oscillator-based gait pattern and the Q-learning algorithm are deployed on a field-programmable gate array (FPGA) chip. Hence, it can be integrated with an automatic training platform in the proposed learning framework such that the adaptability of the humanoid robot can be improved and the straightforward gait pattern can also be learned.
The rest of this paper is organized as follows: in
Section 2, the structure and specification of a small-sized humanoid robot and the automatic training platform used in the experiment are described. In
Section 3, the system architecture and system process of the proposed learning framework based on the FPGA chip and the automatic training platform are described. In
Section 4, an oscillator-based gait pattern is designed for the humanoid robot using trajectory planning. A balance oscillator and two movement oscillators are generated, allowing a direct correlation between oscillator parameters and the gait pattern. In
Section 5, the Q-learning algorithm is presented with the proposed automatic training platform for the humanoid robot to learn the straightforward gait pattern. In
Section 6, some experimental results are presented to validate the proposed learning framework. Finally, the conclusions are summarized in
Section 7.
3. System Overview
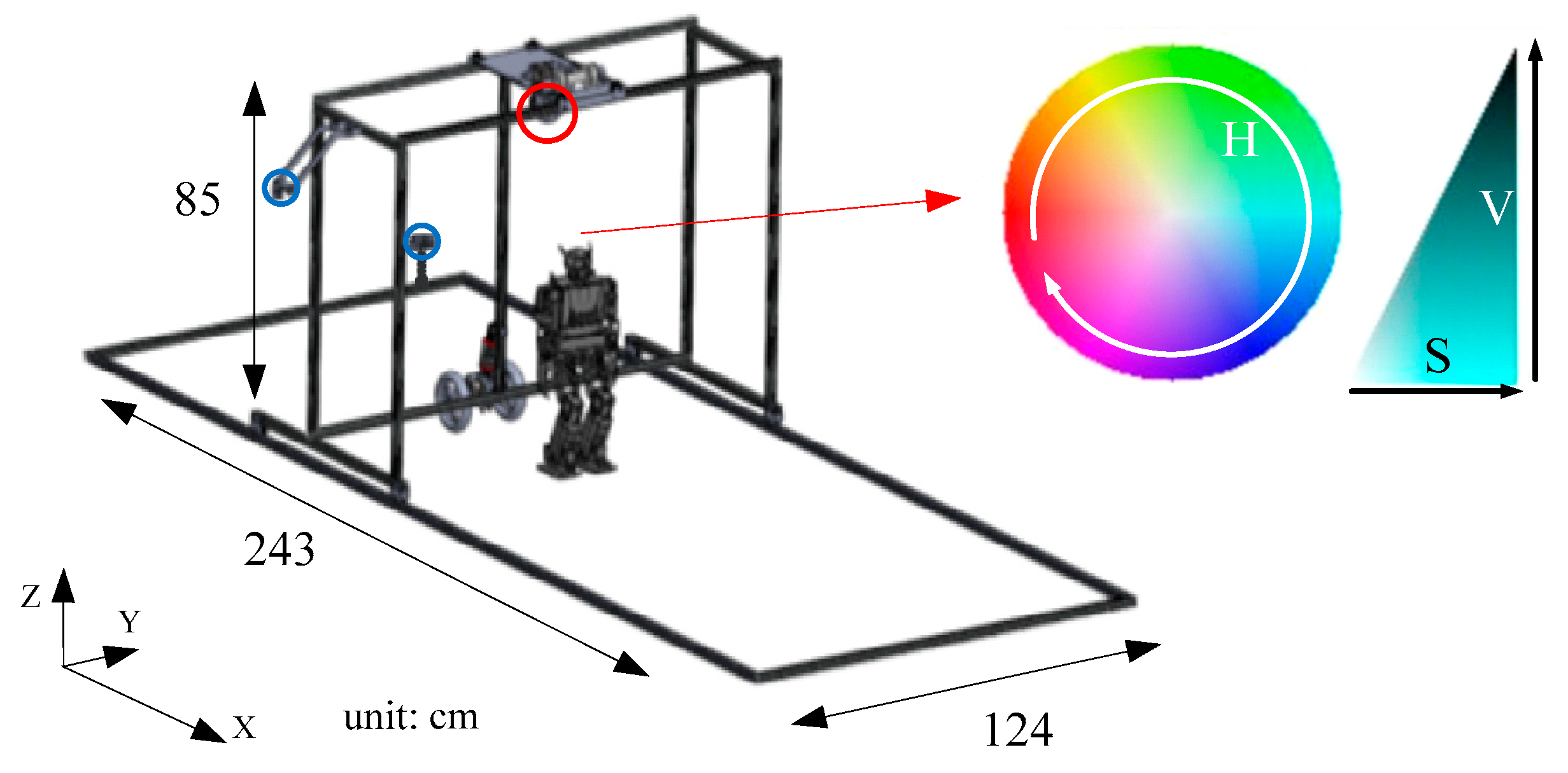
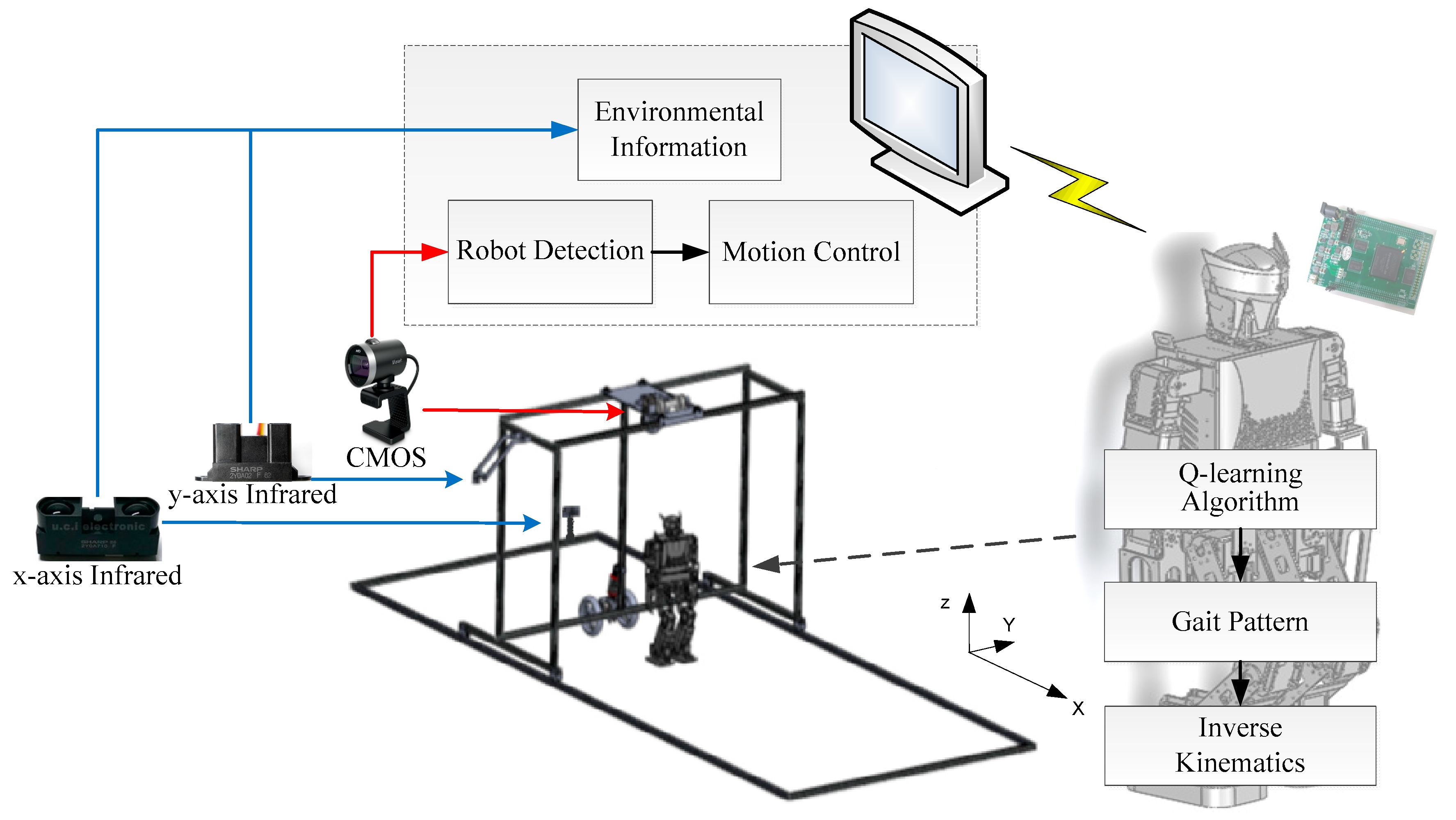
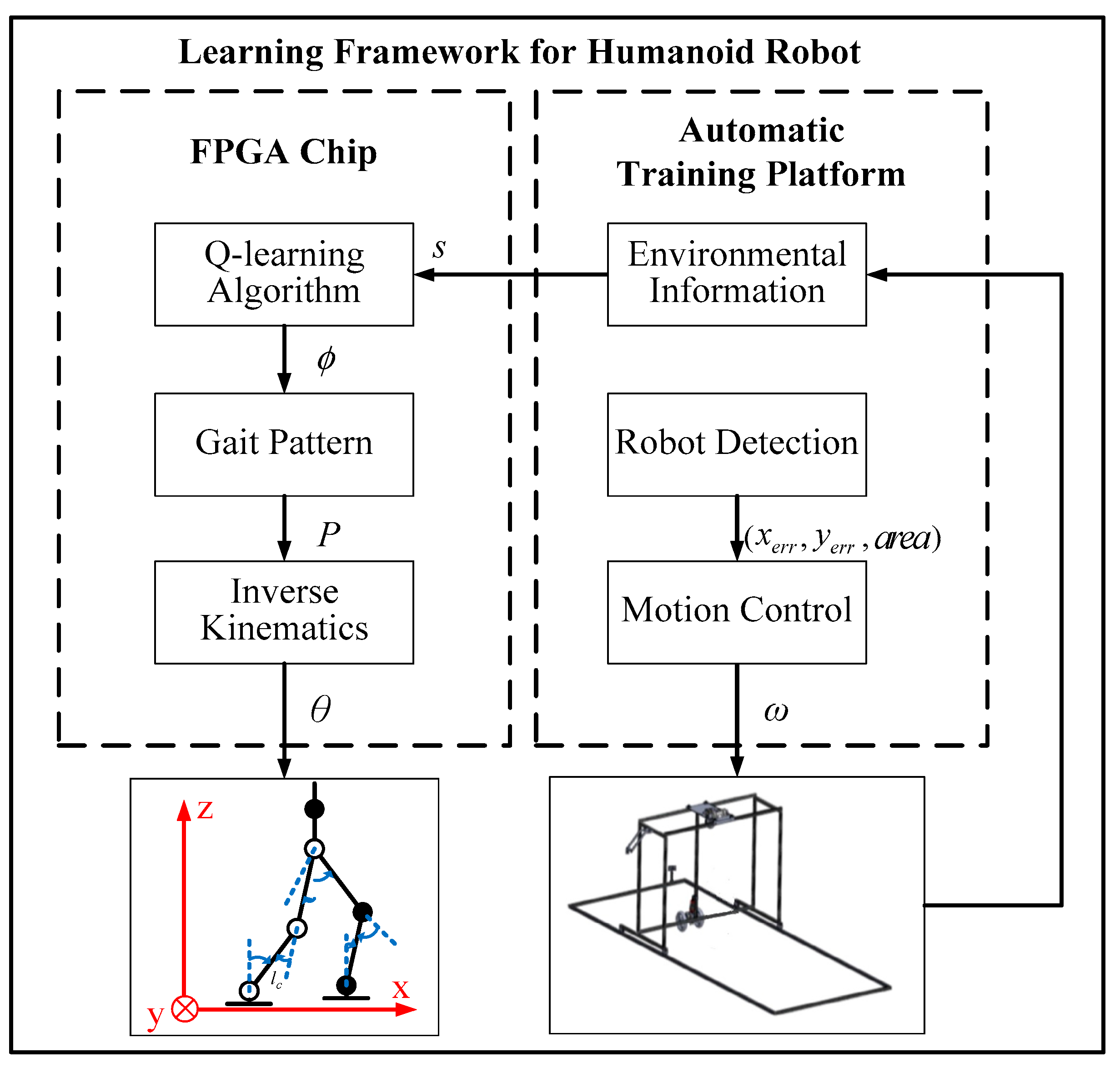
In order to allow the humanoid robot to learn a straightforward gait pattern in the automatic training platform, the proposed learning framework was developed using the system architecture illustrated in
Figure 7 and described in
Figure 8. The three modules (Q-learning algorithm, gait pattern, and inverse kinematics) were designed and implemented in the FPGA chip to speed up the learning process and to produce real-time bipedal locomotion. In addition, three additional modules (environmental information, robot detection, and motion control) were designed and implemented in the automatic training platform to assist and supervise the humanoid robot in the automatic learning process. Their functions are described below.
Firstly, the robot’s mark was placed above it to be detected by the CMOS sensor. Pixel errors in the x-axis and y-axis and the area of the robot’s mark were obtained to follow the robot using the detection module. Secondly, the velocities were required by the automatic training platform to control the motors and to follow the robot from the motion control module. Thirdly, when the humanoid robot walked with its mechanism error and motor backlash in the real environment, its position in the training field could be obtained based on the measured data from the environmental information module via the x-axis and y-axis infrared sensors. Fourthly, the turning direction , a parameter of the gait pattern, could be calculated according to to learn the straightforward gait pattern from the Q-learning algorithm module. Fifthly, the trajectory planning , which depended on the turning direction , could be generated from the gait pattern module. Finally, the angle of each joint was determined from the inverse kinematics module based on so that the robot could exhibit bipedal locomotion.
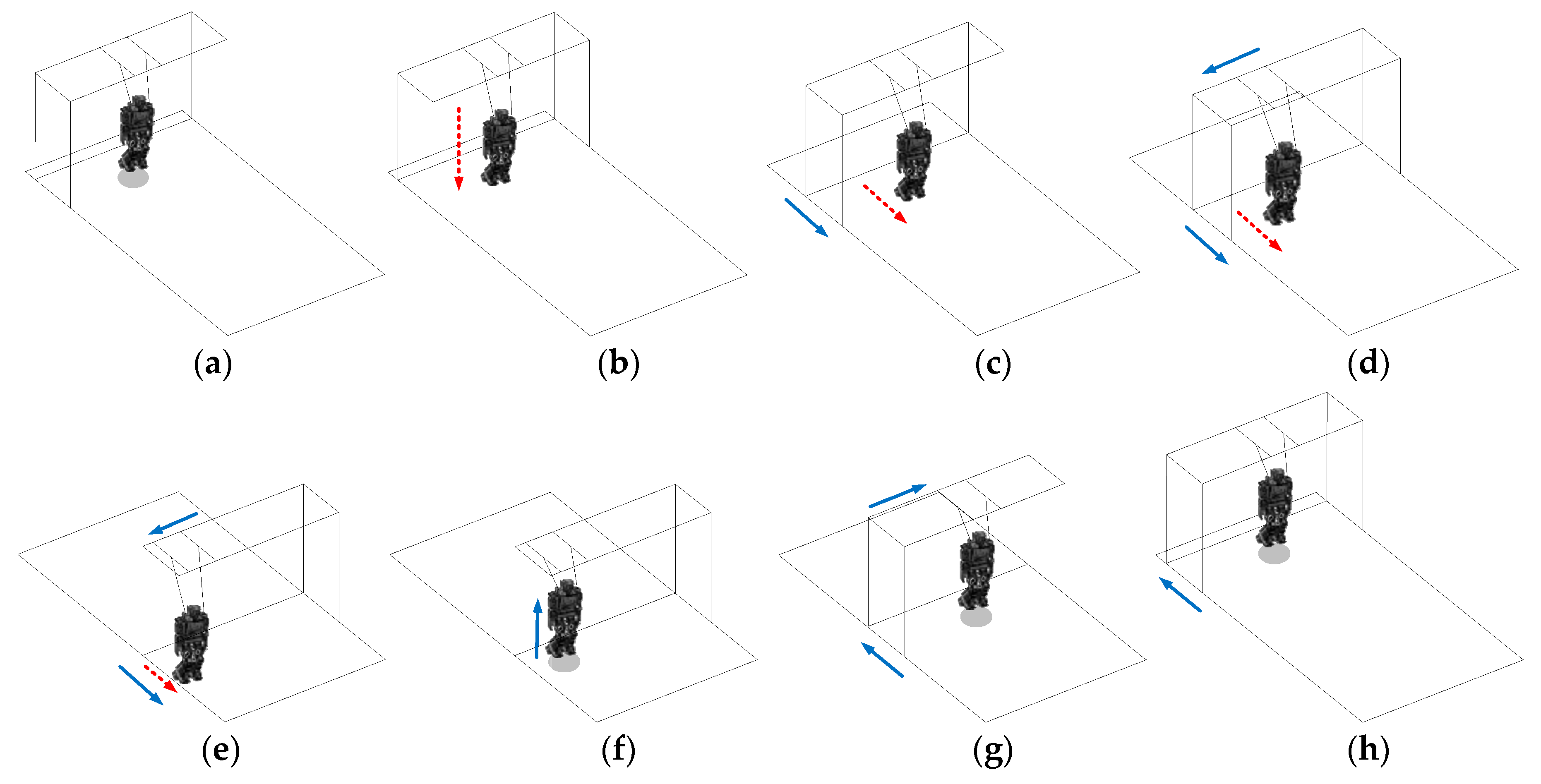
The process of the proposed automatic training platform is described in
Figure 9 which consists of several states. In the beginning, the humanoid robot was suspended and then slowly lowered onto the training field, which served as the initial position (the start state), as shown in
Figure 9a,b. Next, the straightforward gait pattern was learned while the automatic training platform followed the robot at the same time (the operation state), as shown in
Figure 9c,d. Then, once the robot was in danger or once it reached the target region, the humanoid robot was pulled up by the automatic training platform (the end state), as shown in
Figure 9e,f. Finally, the automated training platform could return to the initial position and restart the learning process (the return state), as shown in
Figure 9g,h.
The procedure of the proposed learning framework based on the automatic training platform can be described as follows:
- Step 1:
(Setting State) The robot’s mark is put above the humanoid robot and is detected by a CMOS sensor installed on the automatic training platform.
- Step 2:
(Initial State) Pixel errors in the x-axis and y-axis and the area of the robot’s mark are obtained from the robot detection module tallow the platform to follow the robot.
- Step 3:
(Initial State) The velocities are determined from the motion control module to control the motors, allowing the automatic training platform to follow the robot.
- Step 4:
(Initial State) The position of the humanoid robot in the training field is obtained from the environmental information module based on the measured data via the x-axis and y-axis infrared sensors.
- Step 5:
(Start State) The humanoid robot is suspended and then slowly placed on the training field, which serves as the initial position.
- Step 6:
(Operation State) The turning direction is calculated from the Q-learning algorithm module based on the position to learn the straightforward gait pattern.
- Step 7:
(Operation State) The trajectory planning , which depends on the turning direction , is generated from the gait pattern module.
- Step 8:
(Operation State) The angle of each joint is determined from the inverse kinematics module based on , allowing the robot to exhibit bipedal locomotion.
- Step 9:
(End State) When the robot is in danger or when it reaches the target region, the humanoid robot is pulled up by the automatic training platform.
- Step 10:
(Return State) The automated training platform returns to Step 5 (Start State) and restarts the learning process.
4. Oscillator-Based Gait Pattern
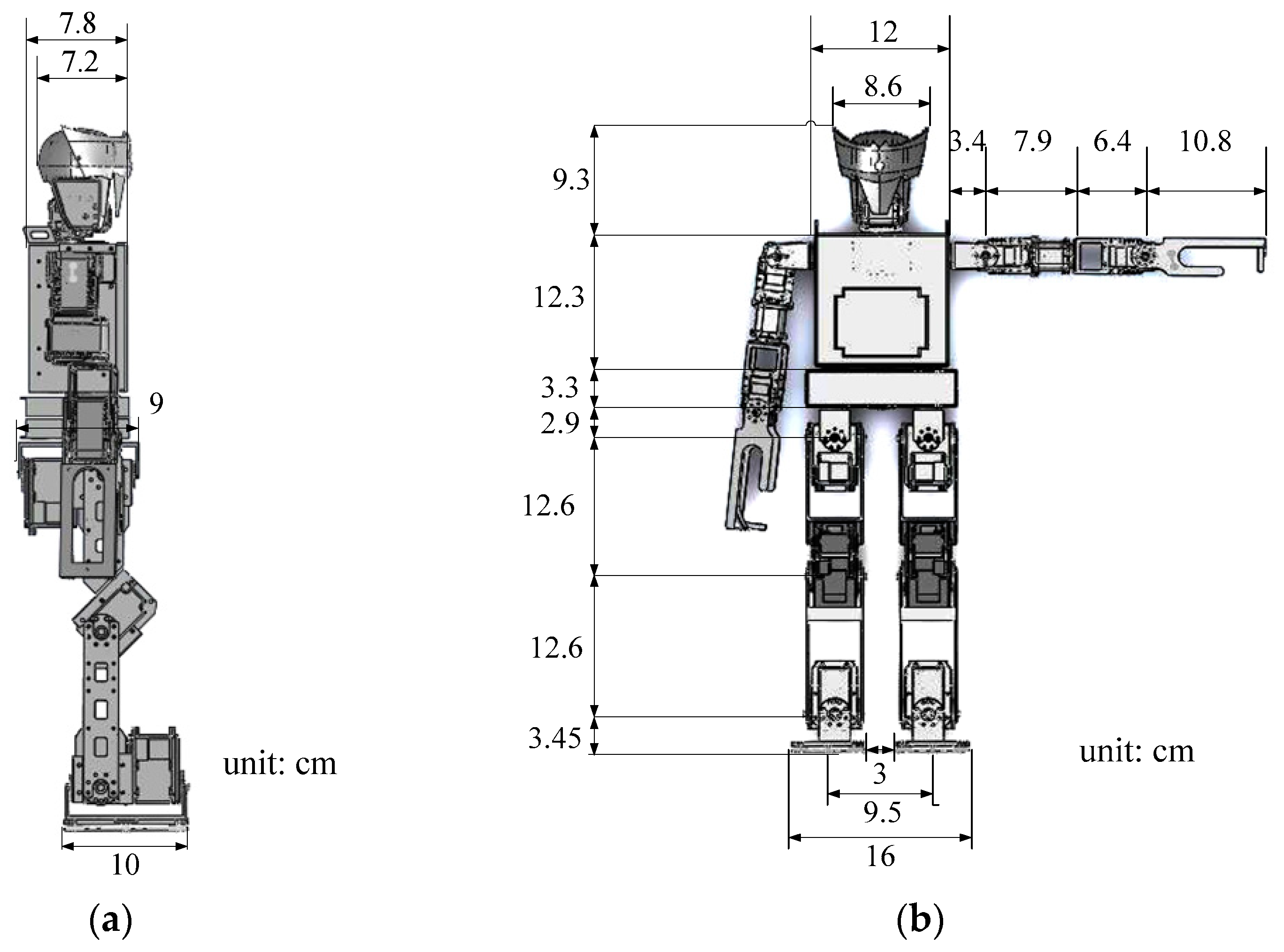
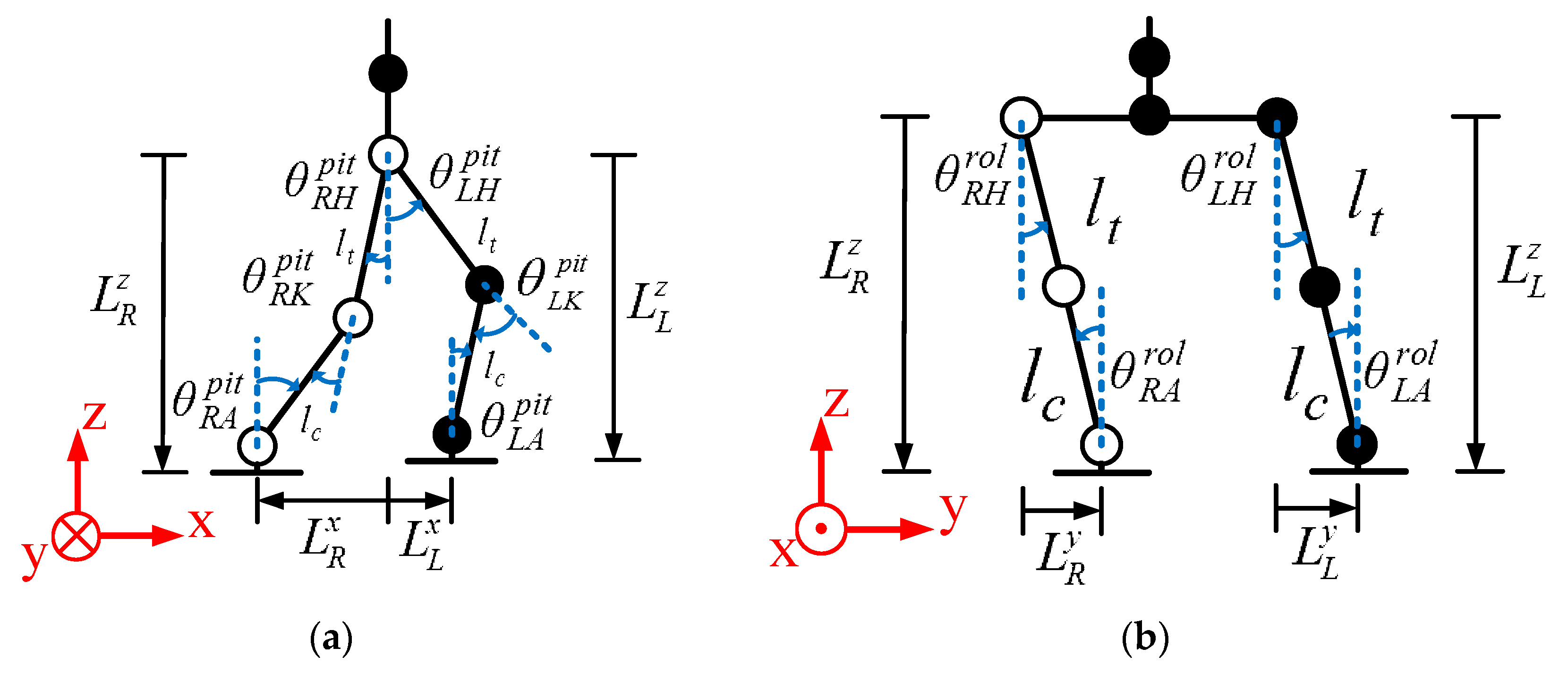
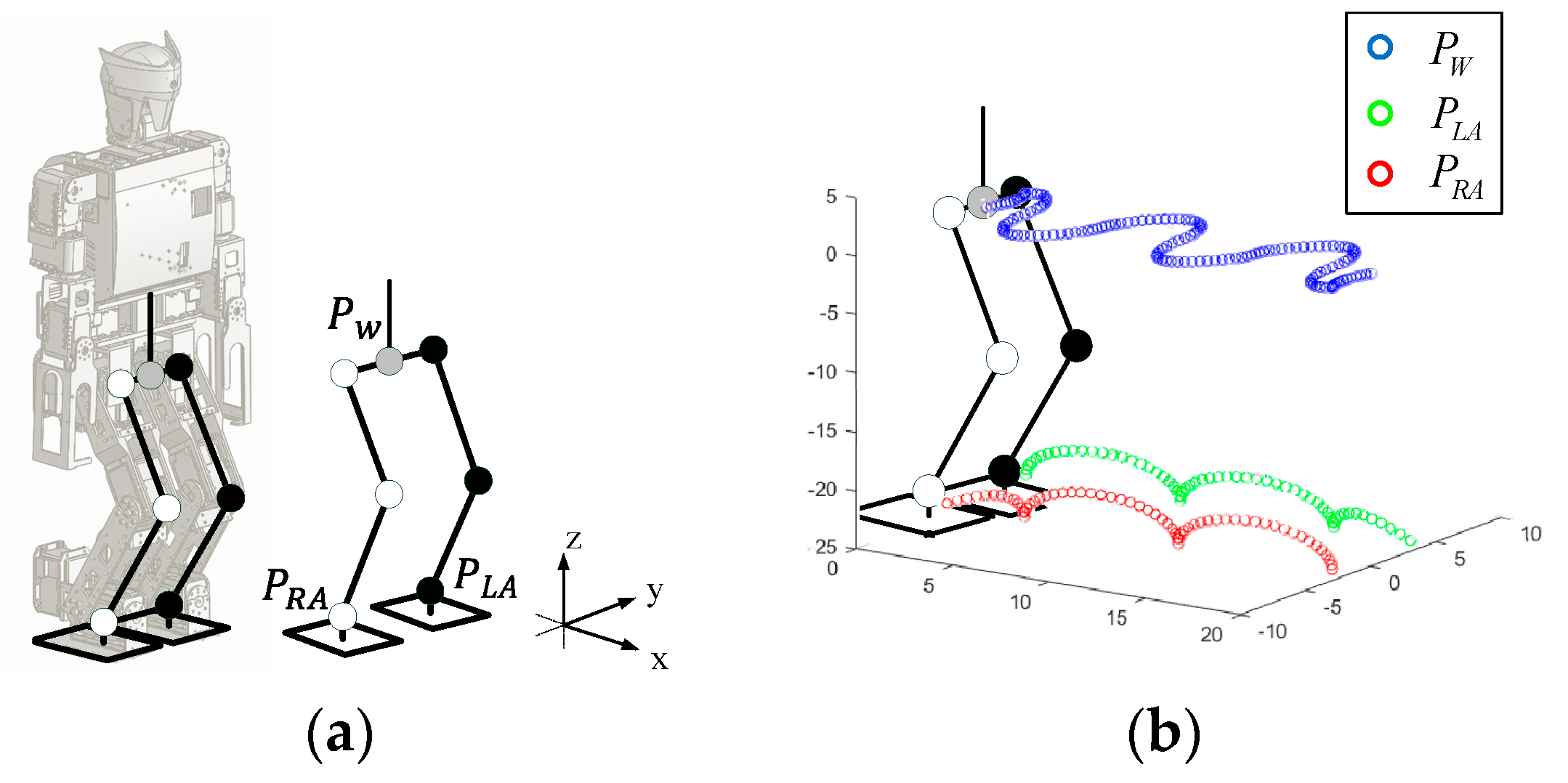
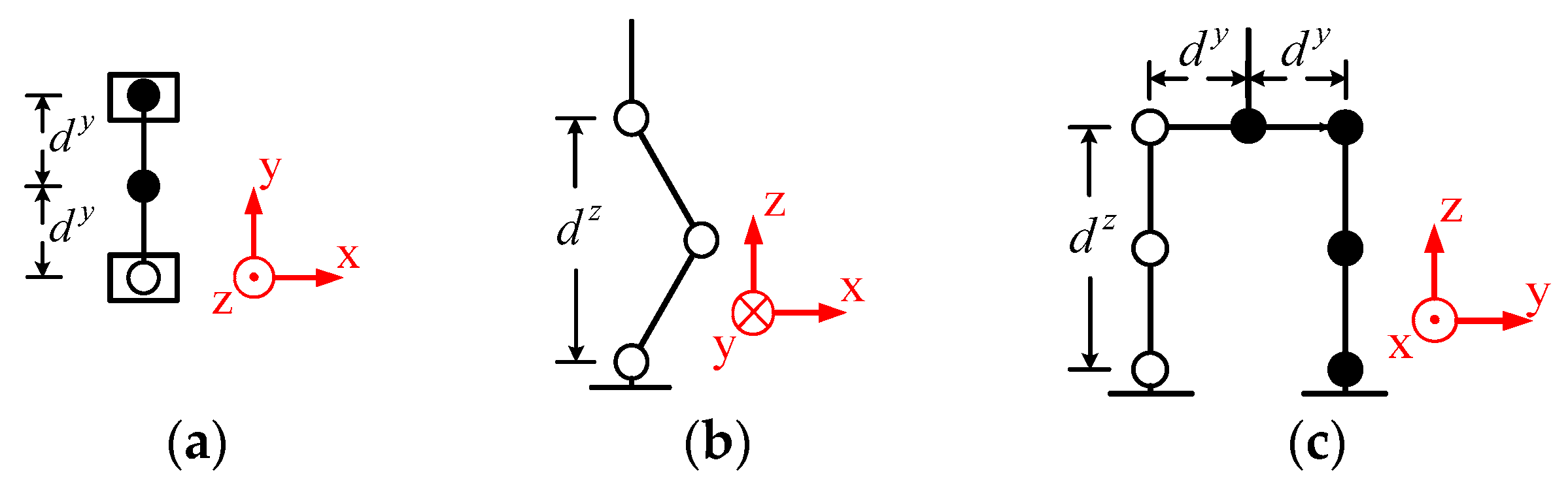
In order to implement a flexible and adaptable gait pattern, oscillators were adopted for the humanoid robot in this paper. Hence, the legs of the humanoid robot and their coordinate system needed to be defined for the gait pattern, as shown in
Figure 10a.
represents the position of the waist, which was considered to be the center of mass (CoM).
and
represent the positions of the left and right ankles, respectively. The right and left legs interchanged as the support leg to obtain the walking ability of the humanoid robot. Hence, the three-dimensional gait pattern could be described by the position of the waist, and left and right ankles
, as shown in
Figure 10b. The standing posture of the robot and its leg parameters are shown in
Figure 11, where
is the distance between the waist
and the hip, and
is the distance between the hip and the ankle.
The humanoid robot was a high-dimensional complex structure; thus, three-dimensional trajectory planning
was generated by the oscillators based on the Cartesian coordinate system to simplify the gait pattern of the humanoid robot. The oscillators could be divided into a balance oscillator and two movement oscillators, located at the CoM
, and left and right ankles
, respectively, to generate the trajectories. The purpose of the balance oscillator was to maintain the balance of the robot and to generate the CoM trajectory. The purpose of the movement oscillators was to support and move the body of the robot and to generate the left and right ankle trajectories. Since the gait pattern was a periodic behavior, a sinusoidal function was adopted for the oscillators, which was adjusted by the walking phase
to simplify the design method. The equations of the oscillators at the CoM
, and left and right ankles
can be expressed as follows:
and
where
,
, and
are the oscillators at the CoM, and left and right ankles, respectively,
,
, and
are the starting points of the CoM, and left and right ankles, respectively, and (
,
,
) are the amplitude, angular velocity, and phase shift of the oscillator parameters. All oscillators involved three axes of the sub-oscillator (
x-axis,
y-axis, and
z-axis) in three-dimensional space, and the two movement oscillators additionally included one sub-oscillator for the turning direction
.
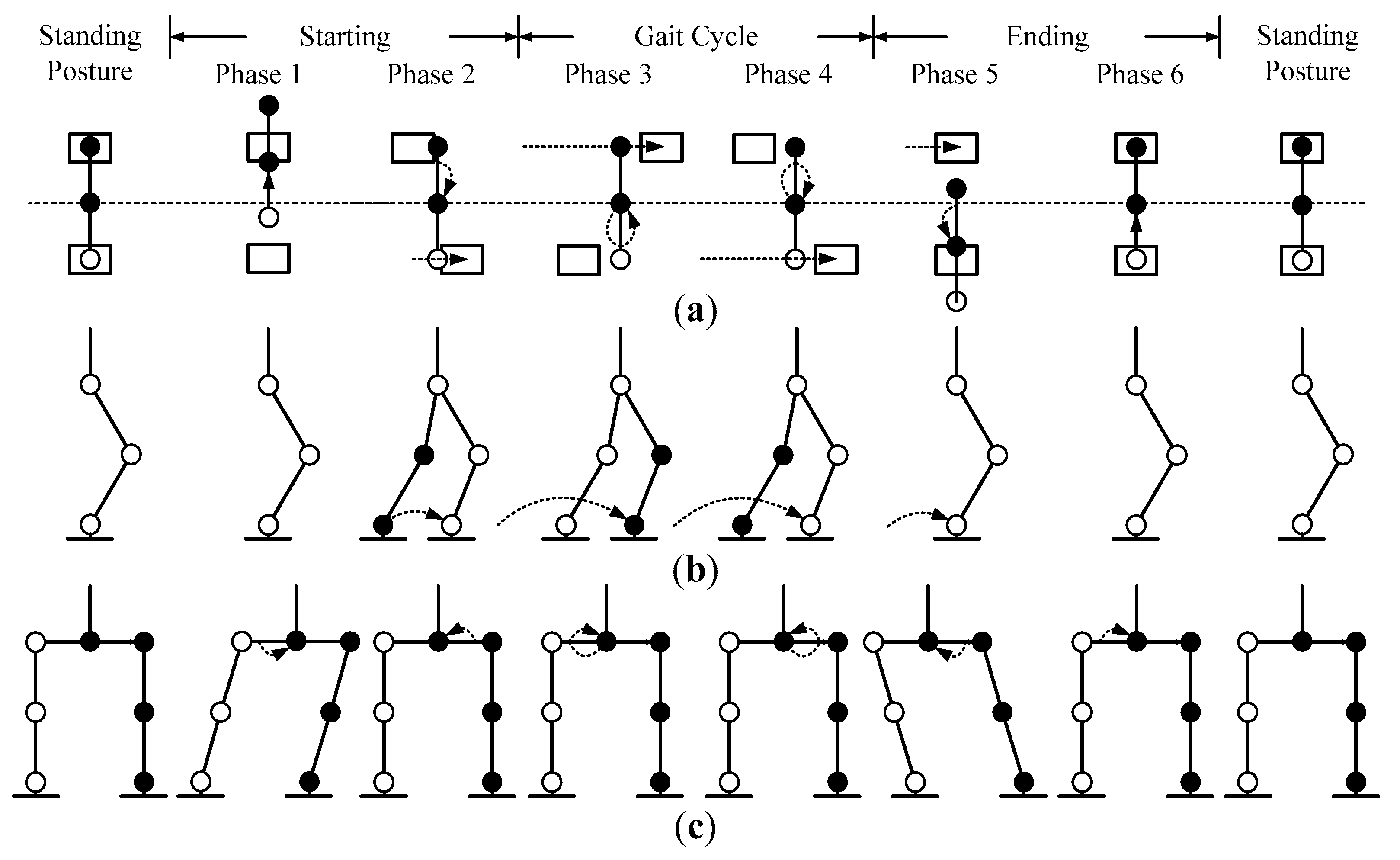
The gait pattern could be described as three modes: starting mode, gait cycle mode, and ending mode, and each mode was divided into two phases. Hence, a complete walking process consisted of six phases: Phase 1–6 (
–
) [
7], as shown in
Figure 12. The leftmost (initial posture) and the rightmost (final posture) postures were both standing postures. In these six phases, the parameters of the CoM in terms of the
x-axis,
y-axis, and
z-axis (
SWx,
SWy,
HW) were the same as those involved in the walking process. Phase 1 (
) and Phase 2 (
) were classified as the starting mode, which only worked once at the beginning of the walking process. The CoM swung from the middle to the left, and both feet remained on the floor in Phase 1. The CoM swung from the left back to the middle, with the left foot still on the floor, and the right foot lifted a height
to move one step forward
in Phase 2. Phase 3 (
) and Phase 4 (
) were classified as the gait cycle mode, which worked repeatedly in the middle of the walking process. The CoM swung in a circular motion on the right side, with the right foot on the floor, and the left foot lifted a height
to move one stride forward
in Phase 3. The CoM swung in a circular motion on the left side, with the left foot on the floor, and the right foot lifted a height
to move one stride forward
in Phase 4. Phase 5 (
) and Phase 6 (
) were classified as the ending mode, which also only worked once at the end of the walking process. The CoM swung to the right side, with the right foot on the floor, and the left foot lifted a height
to move one step forward
in Phase 5. The CoM swung from the right back to the middle, with both feet on the floor, in Phase 6.
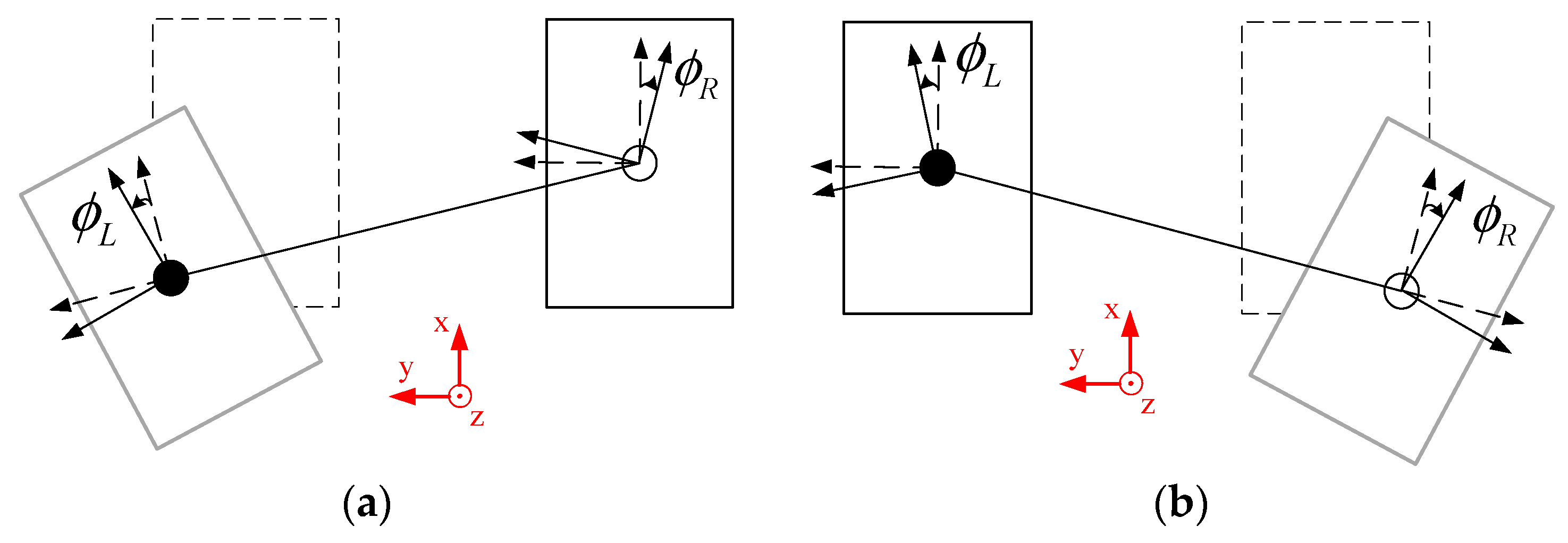
The turning direction
was also involved in the designed gait pattern to increase the flexibility of the humanoid robot. When humans change direction, it is natural for them to rotate their legs. Hence, the movement oscillators were related to the turning direction of the humanoid robot to generate the trajectories. The turning direction of the humanoid robot is shown in
Figure 13 and it could also be assigned a starting mode, gait cycle mode, and ending mode, which in total contained six phases (
–
). If the left foot moved forward and the right foot was on the floor in the complete walking process, the turning left direction could be executed as shown
Figure 13a. Similarly, if the right foot moved forward and the left foot was on the floor in the complete walking process, the turning right direction could be executed as shown
Figure 13b. The turning direction was distributed to both feet, the moving foot and the foot on the floor, to rotate the legs (
,
) in a ratio of three to seven. In the turning left direction, it is expressed by
In the turning right direction, it is expressed by
In this way, the designated region could be effectively reached using the turning direction. The parameter set of the oscillator-based gait pattern with the period of a walking step
T in the walking process is shown in
Table 3. Trajectories and footprints with turning direction are shown in
Figure 14.
5. Learning the Straightforward Gait Pattern
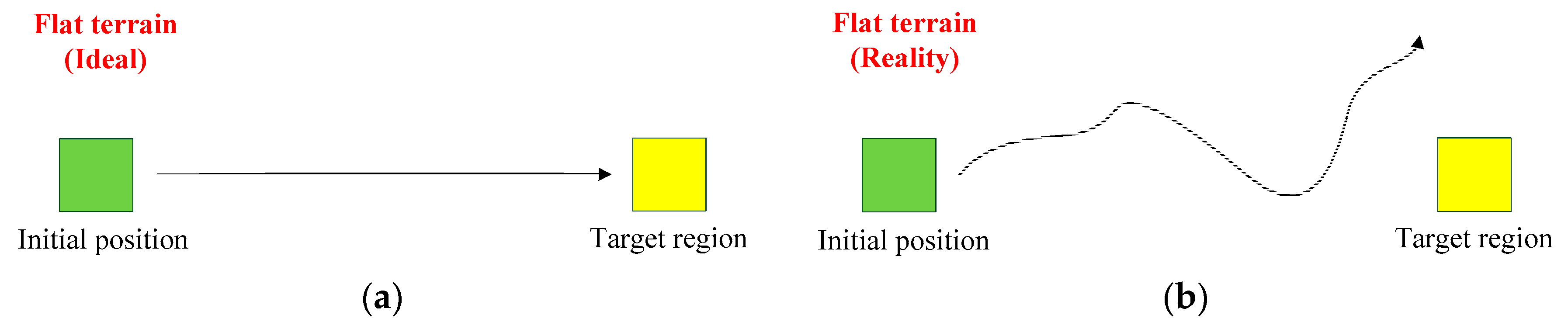
In this paper, a flat terrain was adopted for the humanoid robot to learn the straightforward gait pattern. Most gait patterns are designed assuming an ideal situation, where the mechanism and motors are working well. However, the long-term operation of the humanoid robot may result in mechanism error and motor backlash. Moreover, the real environment also cause the humanoid robot to exhibit some unexpected behaviors. As shown in
Figure 15, the target region (yellow area) was placed in front of the robot and the robot started from the initial position (green area). In an ideal situation, the humanoid robot could walk straight to reach the target region, as shown in
Figure 15a. In a realistic situation, the humanoid robot could not walk straight and could not reach the target region, as shown in
Figure 15b. Hence, the Q-learning algorithm was adopted to adjust the turning direction
, allowing the robot to walk straight to reach the target region from the initial position according to the environmental information.
The Q-learning algorithm is a well-known model-free reinforcement learning method, and it employs the concept of the Markov decision process (MDP) with finite state and action [
15,
22]. An optimal policy can be learned by using Q-learning to maximize the expected reward [
14]. During the learning process, an action is taken by an agent and interacts with the environment for one state to another state. After taking an action
for state
, the policy can be updated through an action-value function
. A Q-table is composed of Q-values which are designed and evaluated by the action-value function
for the agent. The Q-values with state
and action
are updated as follows [
12,
14,
16]:
where
and
are the learning rate and discount factor, respectively,
is the reward, which can be evaluated after taking action
for state
,
is the next state after taking action
for state
, and
denotes the maximum future Q-value, while
-greedy is set to choose a random action. The pseudo-code of the Q-learning algorithm is shown in
Table 4.
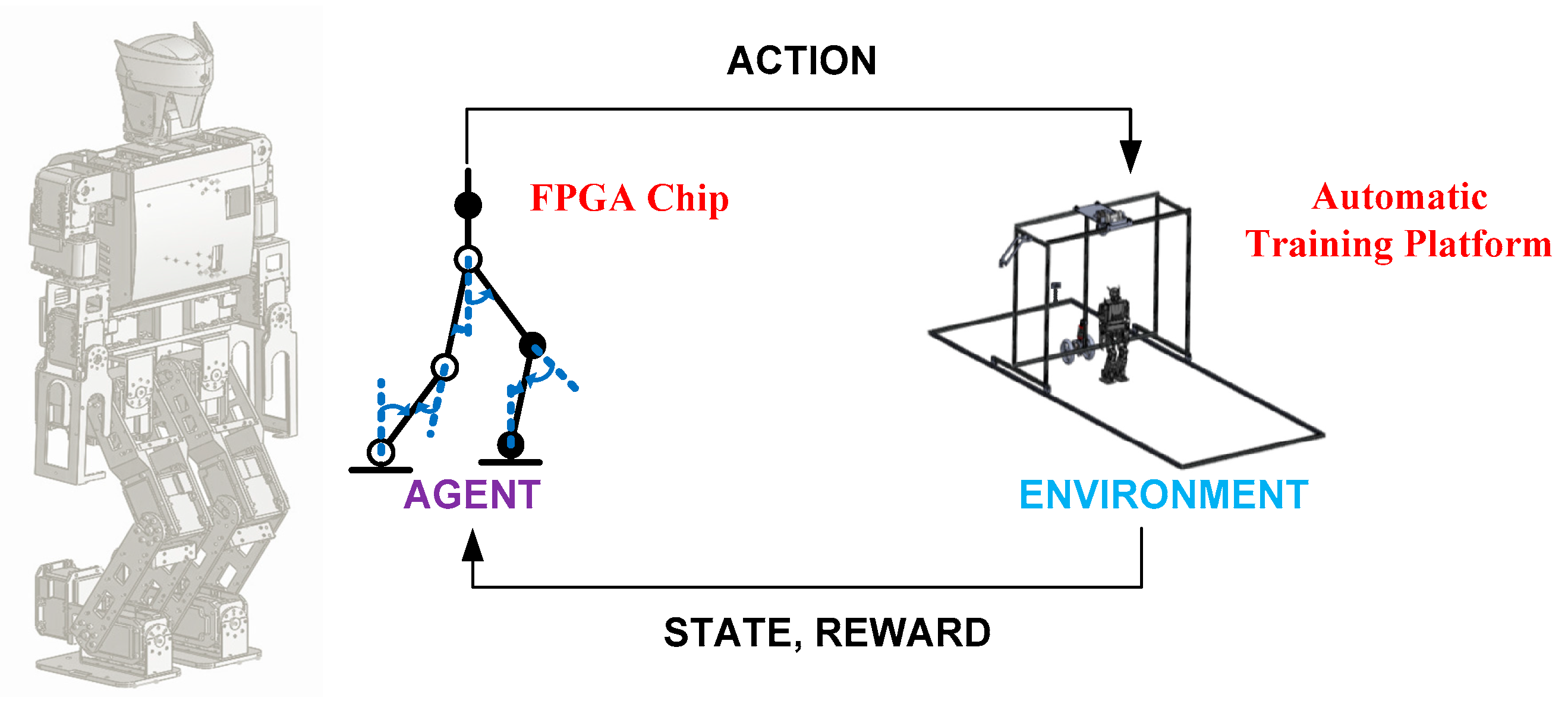
The proposed learning framework with the Q-learning algorithm is shown in
Figure 16. The FPGA chip allowed the agent to learn the straightforward gait pattern, and the automatic training platform worked to follow and train the robot. In order to adjust the turning direction
using the Q-learning algorithm, three elements of the Q-learning algorithm were defined and designed to update the Q-values of the Q-table: (1) state (
), the environmental information measured by the infrared sensors installed on the automatic training platform to offer the position of the humanoid robot in the training field; (2) action (
), the turning direction
selected according to state
for the gait pattern of the humanoid robot; (3) reward (
), the learning guideline dependent on state
and action
to strengthen or weaken the selected action.
5.1. State for the Straightforward Gait Pattern
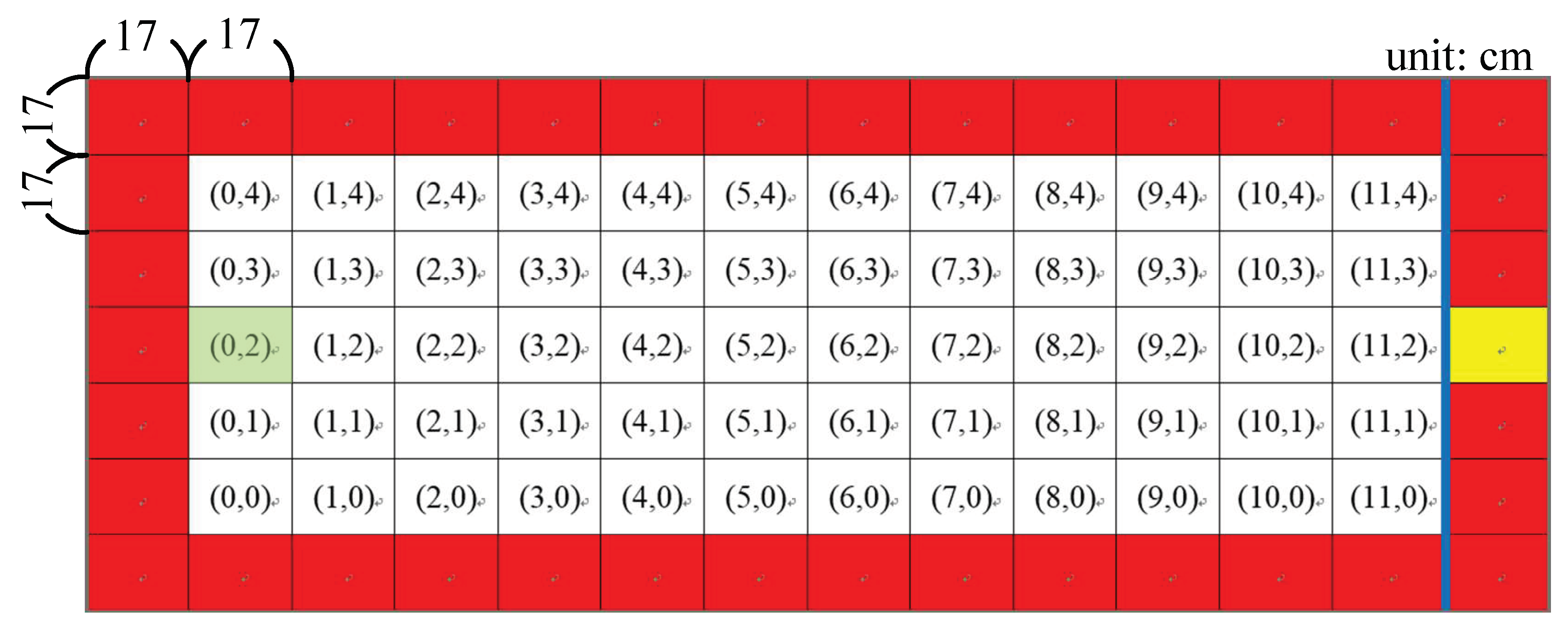
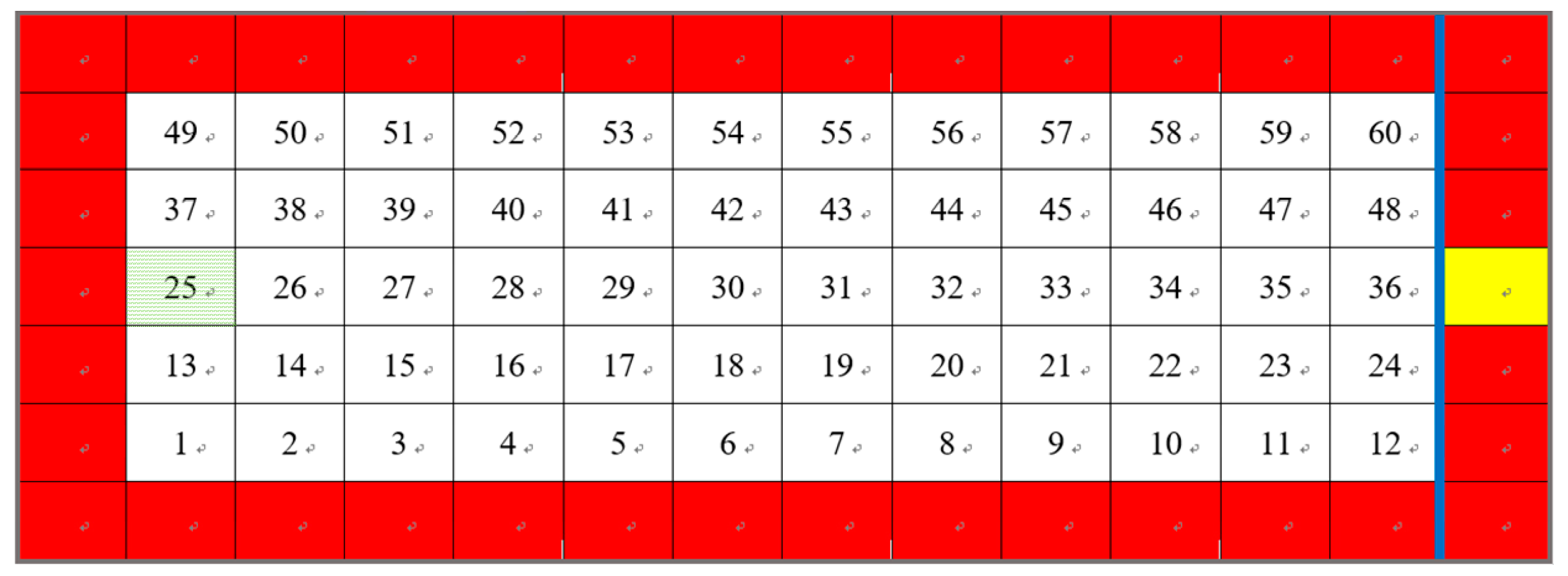
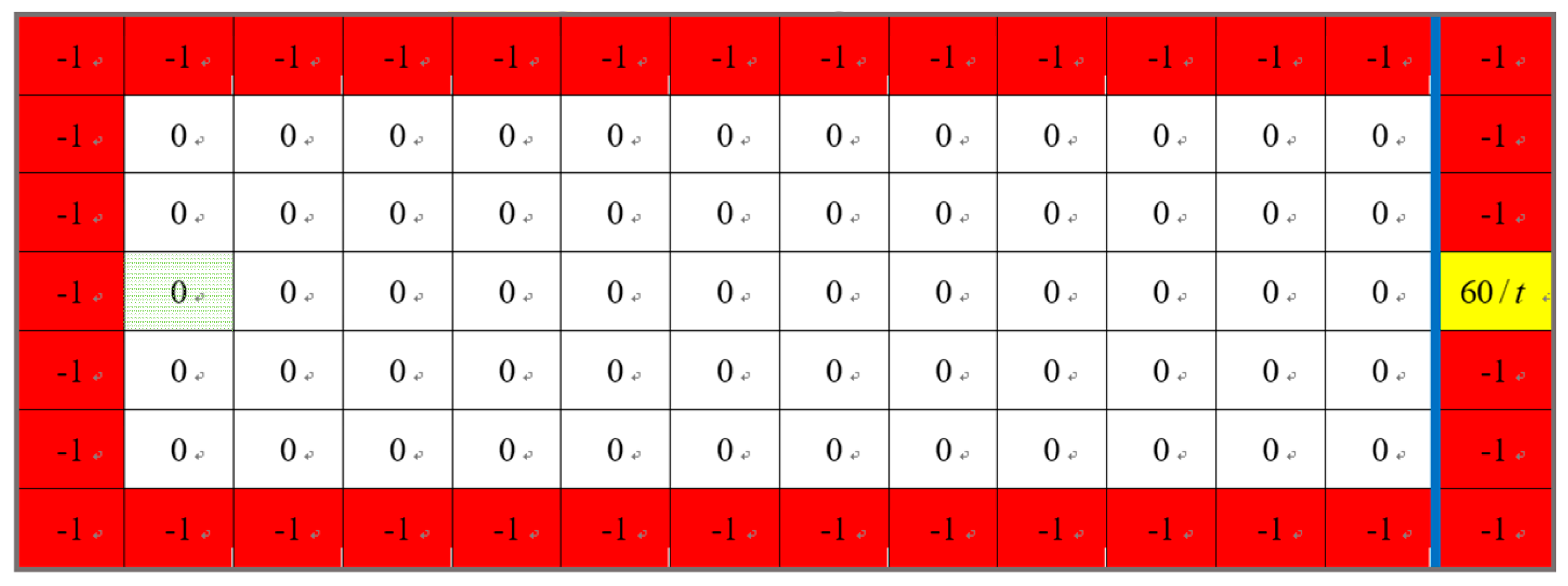
In the learning process, the automatic training platform was adopted not only for supervision to protect the humanoid robot, but also to obtain the current environmental information of state
required by the Q-learning algorithm. As shown in
Figure 17, there were 60 total states of the coordinate system in the training field. The green area denotes the initial position, i.e., the start point of the robot. The yellow region denotes the target region that needs to be reached from the initial position after passing the blue line, which denotes the target distance. Similarly, the red color denotes the danger regions or the boundary of the automatic training platform which the robot cannot reach. These 60 states can be used to present the current position of the robot in the training field. The states can be obtained as follows:
where
and
are the
x-axis and
y-axis distances of the robot in the training field measured using the two infrared sensors.
5.2. Action for the Straightforward Gait Pattern
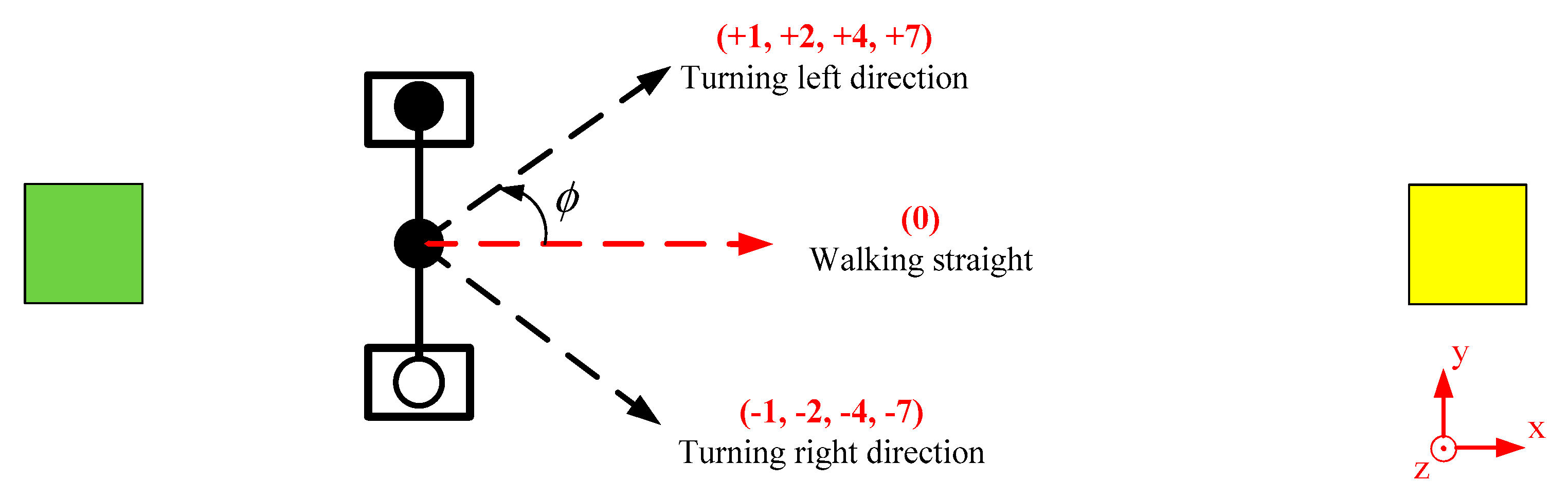
In order to reach the target region from the initial position, the turning direction
of the humanoid robot was designated as action
by the Q-learning algorithm. There were a total of 9 actions that could be selected, as shown in
Table 5. Instead of the value 0, four levels labeled minor (value 1), middle (value 2), major (value 4), and urgent (value 7) were designed to allow the robot to walk straight to the target region. These four levels included positive (+) and negative (−) values to realize the turning left direction and turning right direction for the robot, as shown in
Figure 18, while the value 0 represented walking straight. However, only one action
could be selected based on the obtained state
to estimate an appropriate policy in the training field.
5.3. Reward for the Straightforward Gait Gattern
In the learning process, after a selected action
is taken by an agent and interacts with the environment, a reward
can be returned to the agent. The learning guideline offered a reward to implement the straightforward gait pattern. If a good reward was returned, the selected action was strengthened. Similarly, if a bad reward was returned, the selected action was weakened. Hence, the reward was used to update the policy. The positive and negative rewards were respectively designated in the target region and danger region. In this way, the humanoid robot was attracted or repelled to achieve the straightforward gait pattern. In addition, the time of one learning process
was involved in the reward for the humanoid robot to walk approximately in a straight line and reach the target region, as shown in
Figure 19. The reward can be established as follows:
where
is the time of one learning process and it is greater than 0.
6. Experimental Results
The performance of the proposed learning framework is illustrated in this section. The straightforward gait pattern was learned for the humanoid robot using an FPGA chip and an automatic training platform in a training field. The real learning process of the proposed learning framework is demonstrated with four states in
Figure 20. In the start state, the humanoid robot was suspended and then slowly lowered by the automatic training platform in the initial position, as shown in
Figure 20a,b. In the operation state, the humanoid robot was followed by the automatic training platform when walking from the initial position to the front coordinate of the training field, as shown in
Figure 20c,d. In the end state, the humanoid robot reached the end position and then was pulled up by the automatic training platform, as shown in
Figure 20e,f. In the return state, the humanoid robot was returned by the automatic training platform to the initial position, as shown in
Figure 20g,h. The turning direction was adjusted by the Q-learning algorithm and the walking path of the humanoid robot could also be recorded in this learning process.
Based on the proposed learning framework, there were a total of 594 episodes executed to learn the straightforward gait pattern for the humanoid robot. The target region, with a center of 229.5 cm, 59.5 cm, was located in front of the initial position (25.5 cm, 59.5 cm) where the humanoid robot began walking in each episode. The target distance was where the
x-coordinate of the training field was 221 cm. In the learning process, an episode was terminated when the humanoid robot reached the danger region or the target region. The Q-table could be updated by selecting the turning direction according to the position of the robot in the training field. The walking paths of the humanoid robot in these 594 episodes were recorded to analyze the learning process, and they could be divided into three stages: (1) initial stage, (2) middle stage, and (3) final stage, as shown in
Figure 21,
Figure 22 and
Figure 23.
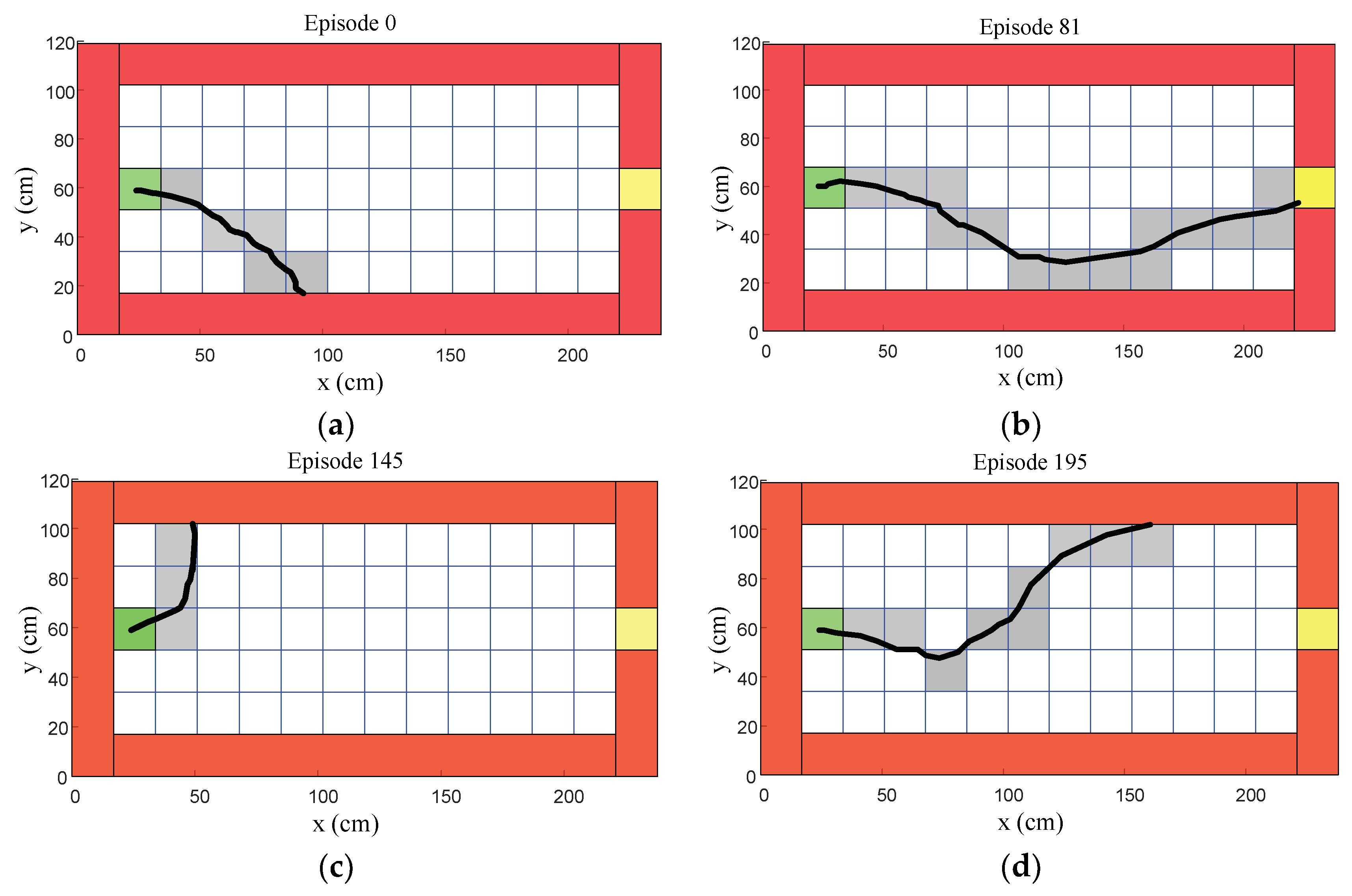
6.1. Initial Stage of the Learning Process
Episodes 0 to 200 represented the initial stage of the learning process, as shown in
Figure 21. Episode 0 shows that the humanoid robot could only walk in a straight line to approximately half of the target distance, as shown in
Figure 21a. After a few learning processes, episode 81 shows that the humanoid robot could reach the target region, as shown in
Figure 21b. However, most episodes in the initial stage, such as episodes 145 and 195, show that the humanoid robot still could not reach the target distance, as shown in
Figure 21c,d.
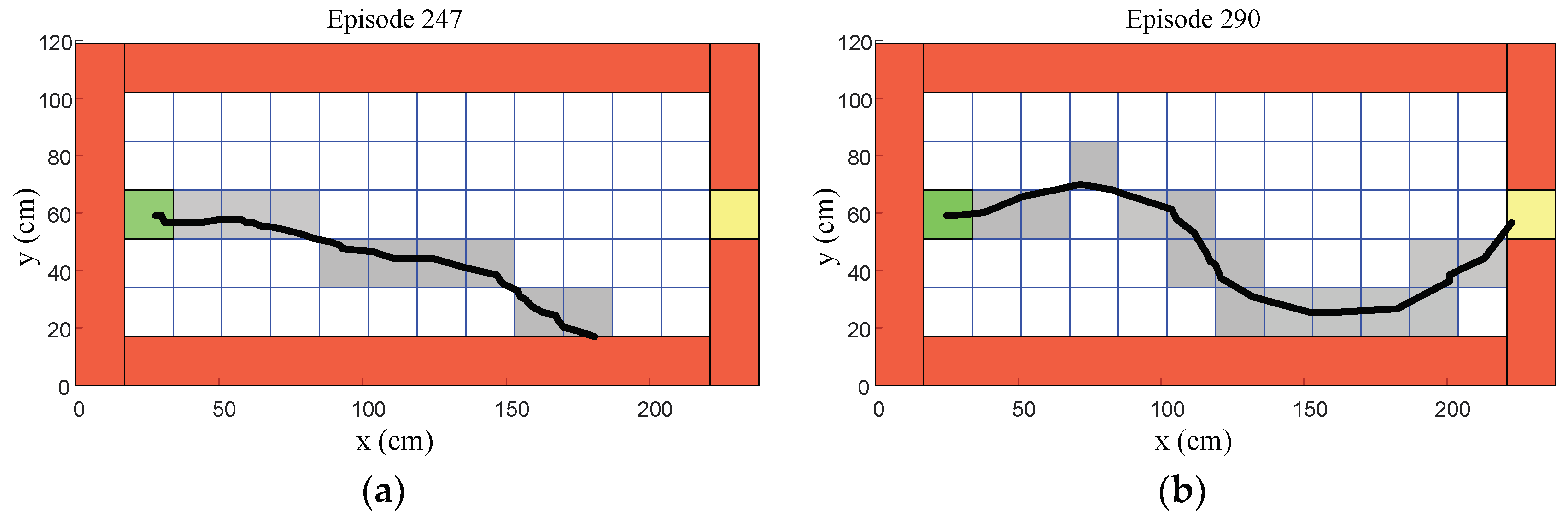
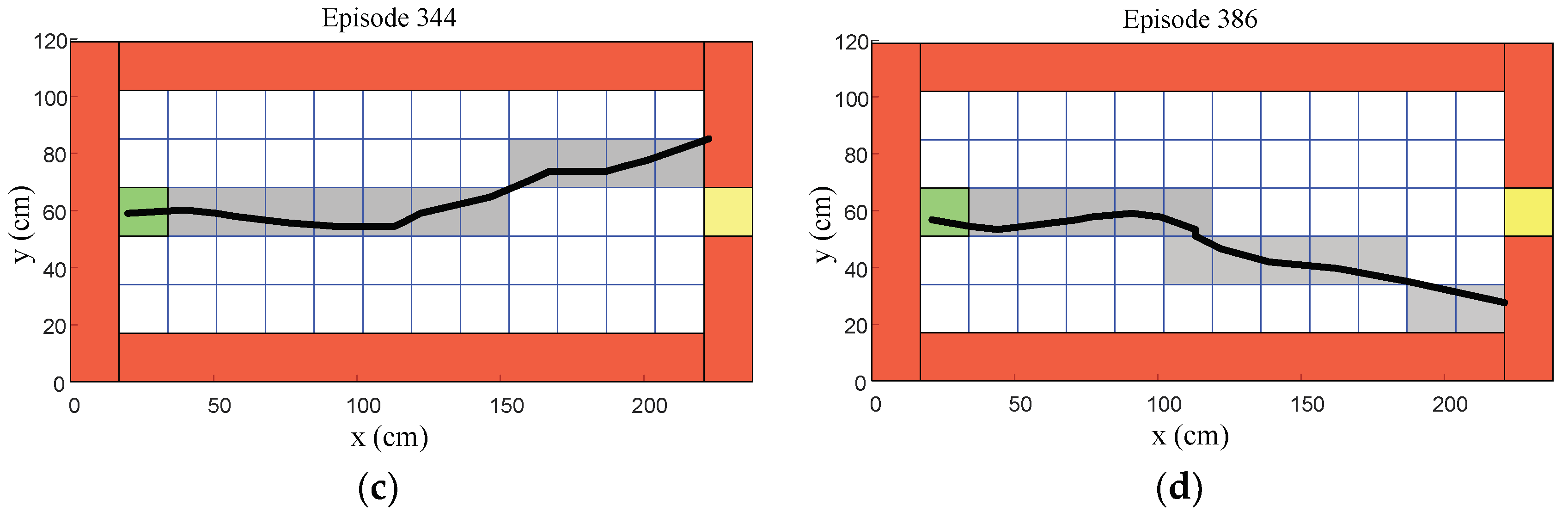
6.2. Middle Stage of the Learning Process
Episodes 201 to 400 represented the middle stage of the learning process, as shown in
Figure 22. Episode 247 shows that the humanoid robot could gradually reach over half of the target distance, as shown in
Figure 22a. After a few learning processes, episode 290 shows that the humanoid robot could reach the target region, as shown in
Figure 22b. However, most episodes in the middle stage, such as episodes 344 and 386, show that the humanoid robot still could not reach the target region, as shown in
Figure 22c,d.
6.3. Final Stage of the Learning Process
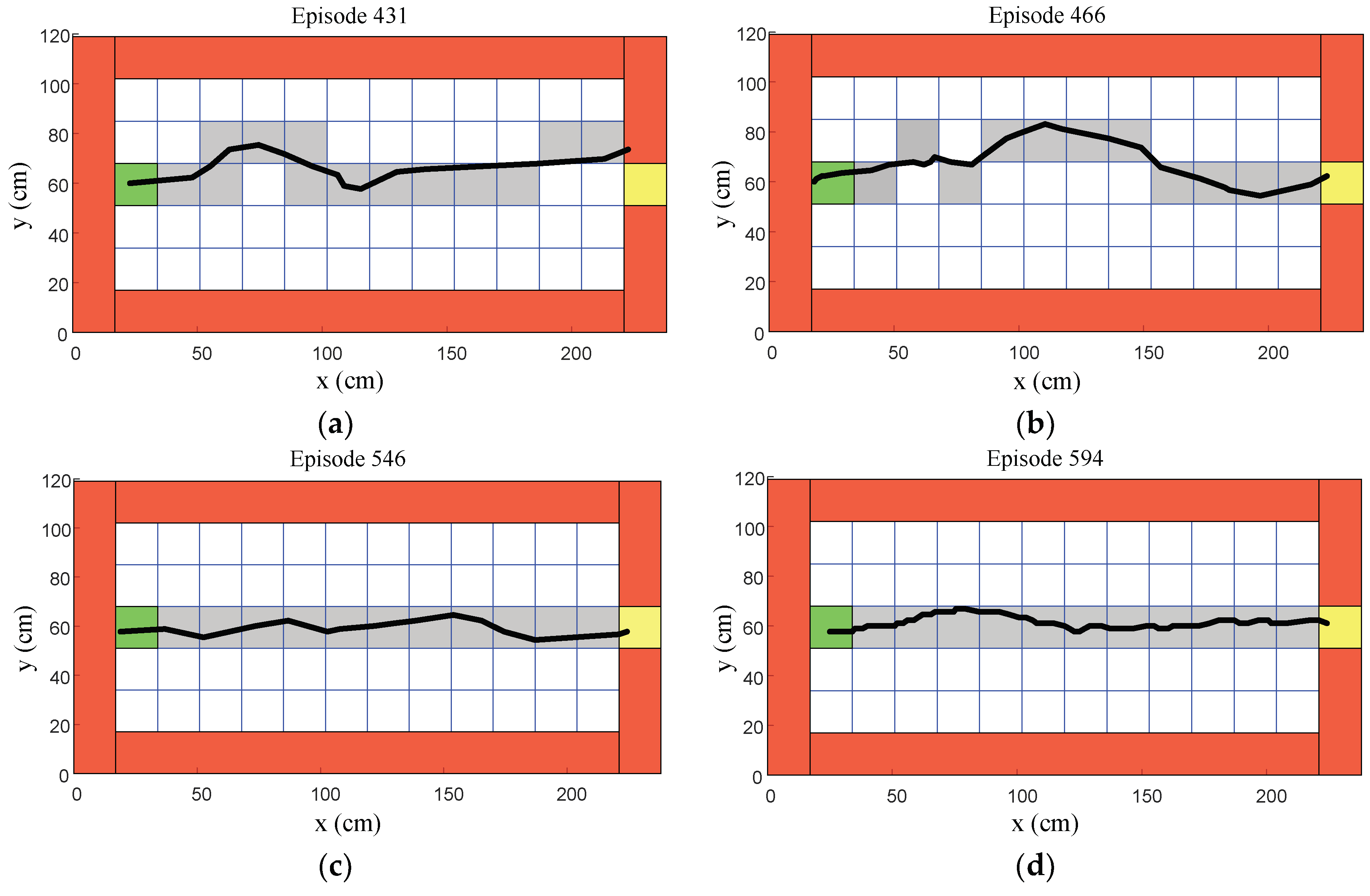
Episodes 401 to 594 represented the final stage of the learning process, as shown in
Figure 23. Episode 431 shows that the humanoid robot could gradually approach the target region, as shown in
Figure 23a. After a few learning processes, episode 466 shows that the humanoid robot could reach the target region, as shown in
Figure 23b. Moreover, most episodes in the final stage, such as episodes 546 and 594, show that the humanoid robot could not only reach the target region, but also walk approximately in a straight line, as shown in
Figure 23c,d. Hence, the straightforward gait pattern was learned in this stage.
The recorded walking path could be analyzed based on the walking distance and the lateral offset. The walking distance was denoted by the horizontal length along the
x-coordinate from the initial position to the end position. The lateral offset distance was the offset length compared with the straightforward line representing the walking distance. In the initial stage, the average walking distance was 95.4204 cm, which was far from the target region, and the average lateral offset distance was 22.8071 cm, which was also far from a straight line during this walking distance. In the middle stage, the average walking distance was 100.0183 cm, which approached the target region, and the lateral offset distance was 21.0969 cm, which also approached a straight line during this walking distance. In the final stage, the average walking distance was 148.7788 cm, which was closer to the target region, and the lateral offset distance was 14.8387 cm, which was closer to a straightforward line during this walking distance, within a unit coordinate of the training field. The detailed average experimental results are shown at each stage in
Table 6. The final Q-table of the straightforward gait pattern is shown in
Table 7.
7. Conclusions
In this paper, the Q-Learning algorithm was applied to learn a straightforward gait pattern for a humanoid robot based on an automatic training platform. There were four main contributions of this research. Firstly, an automatic training platform, which was an original idea, was proposed and implemented so that the humanoid robot could learn the straightforward walking gait in a real situation. Moreover, it could be used to reduce human resources and protect the humanoid robot in the training process. Secondly, a learning framework was proposed for the humanoid robot based on the proposed automatic training platform. Thirdly, an oscillator-based gait pattern was designed and combined with the proposed learning framework to reduce the number of learning parameters and speed up the learning process. Lastly, the Q-learning algorithm was applied in the proposed learning framework to allow the humanoid robot to learn the straightforward walking gait in a real situation. The proposed learning framework and automatic training platform were completely tested on a real small-sized humanoid robot, and an experiment was set up to verify its performance. In the learning process, the walking distance kept increasing, which shows that the humanoid robot could learn to walk toward the target region. Similarly, the lateral offset distance kept decreasing, which represents that the humanoid robot could walk in a straightforward pattern. From the experimental results of successful bipedal locomotion with a straightforward gait pattern, the feasibility of the proposed learning framework and automatic training platform could be validated. Hence, the desired behavior could be learned for the intrinsically unstable humanoid robot using the proposed learning framework, which could reduce human resources by using the automated learning process based on the proposed automatic training platform. The main purpose of this paper was to enable the robot to learn the straightforward gait pattern. When the robot is able to walk straight, it can then be combined with localization algorithms, such as Simultaneous Localization And Mapping (SLAM) and particle filter, in the future. The successfully learned straightforward gait pattern can be used in the localization algorithm to enable the robot to actually reach a specified position. Moreover, deep reinforcement learning can be designed and deployed in the proposed learning framework via the FPGA chip.


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}