A Novel Modular Radiation Hardening Approach Applied to a Synchronous Buck Converter





Abstract
:1. Introduction
2. Motivation
2.1. The Base Architecture
2.2. Modified Triplex–Duplex Architecture
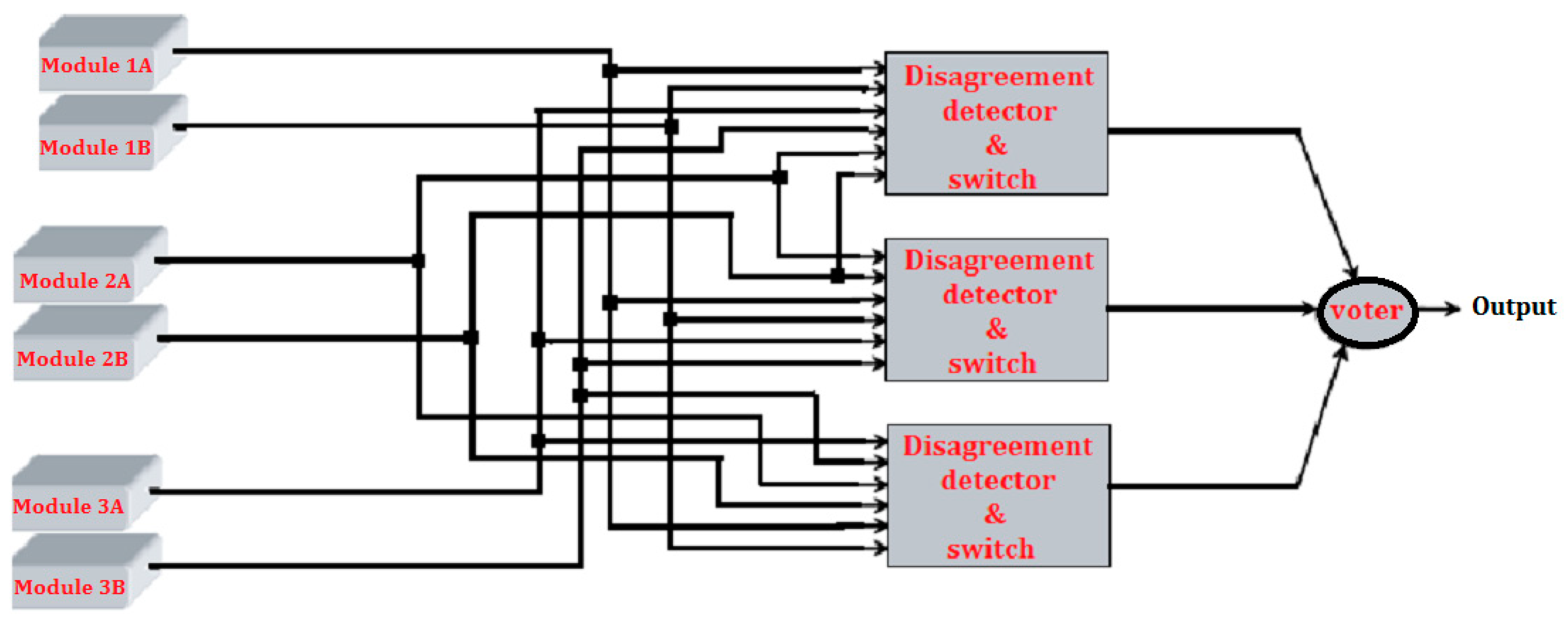
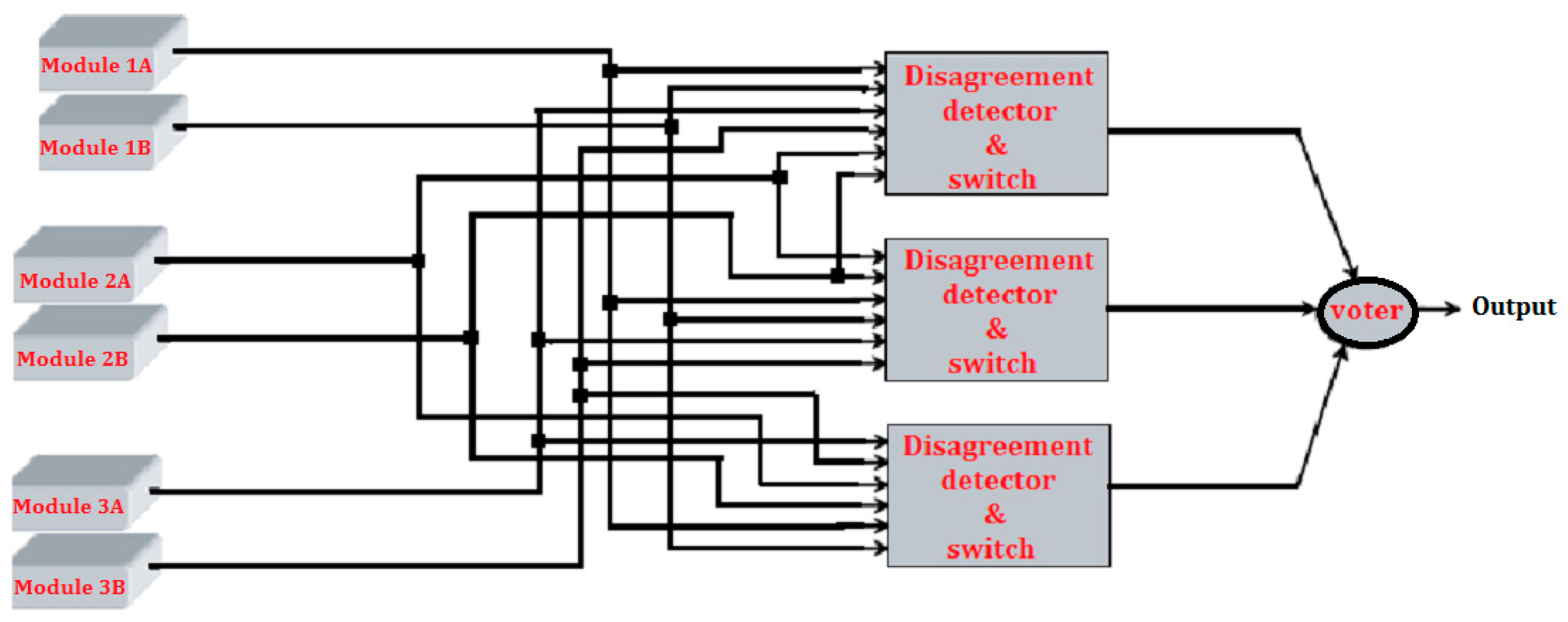
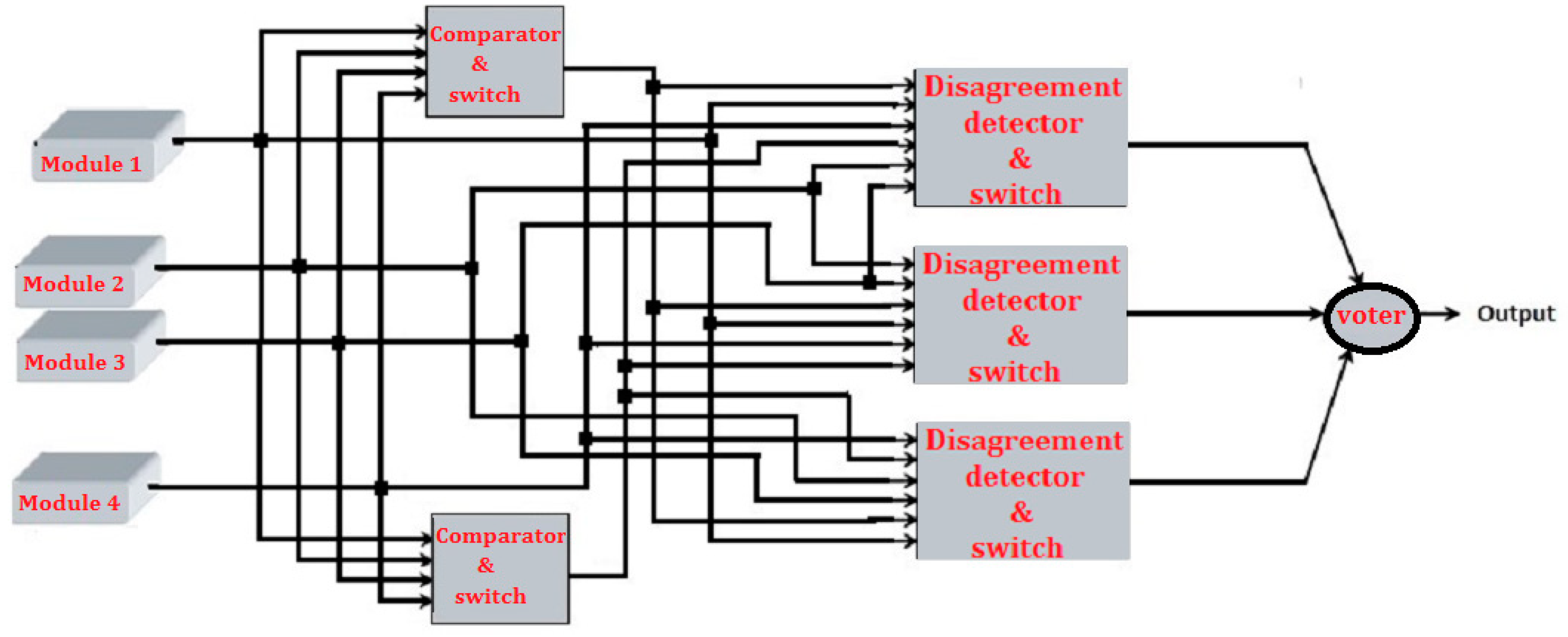
3. Proposed Four Modules Architecture
- Authors proposed a highly reliability redundancy technique called the modified triplex–duplex redundancy, which has 61% and 66% longer expected life than TMR and FMR techniques, respectively, although its hardware utilization is the highest compared to both methods.
- To rectify the hardware consumption drawback of the modified triplex–duplex technique, authors proposed a novel four module redundancy technique derived from the modified triplex–duplex method with the following advantages:
- ○
- It is comparable in reliability to the four modules self-purging redundancy with threshold of 2 and to TMR with one spare with the additional advantages of tolerating simultaneous failure of two modules and reducing complexity, which both of the above two techniques lack.
- ○
- It gives 30% higher MTTF compared to FMR while utilizing lower hardware resources.
- ○
- It gives 25%higher MTTF compared to TMR method.
- ○
- Unlike self-purging redundancy that requires a specialized threshold voter, the proposed method is used with both single and triplicated majority voter architectures, since it is based on the modified triplex–duplex architecture.
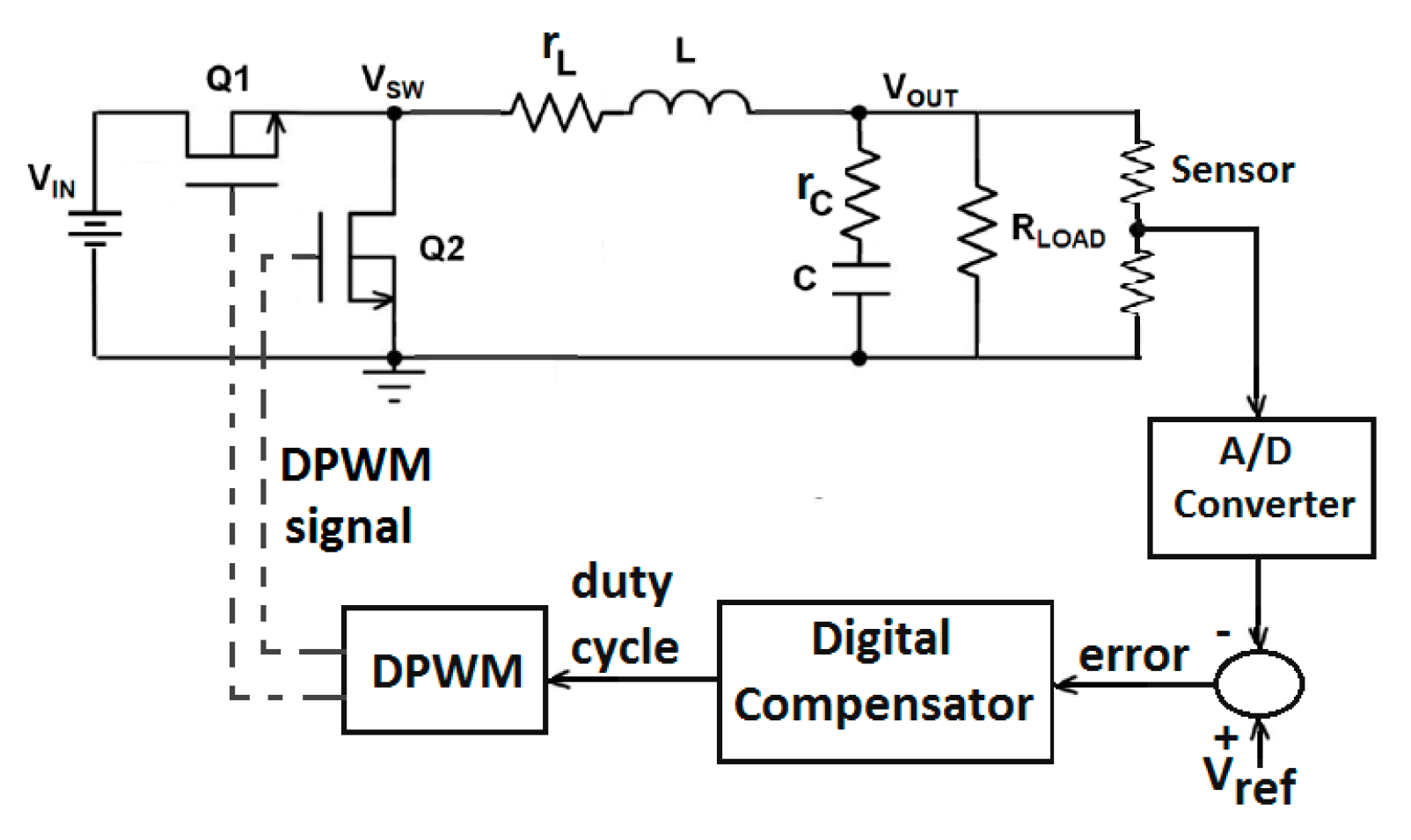
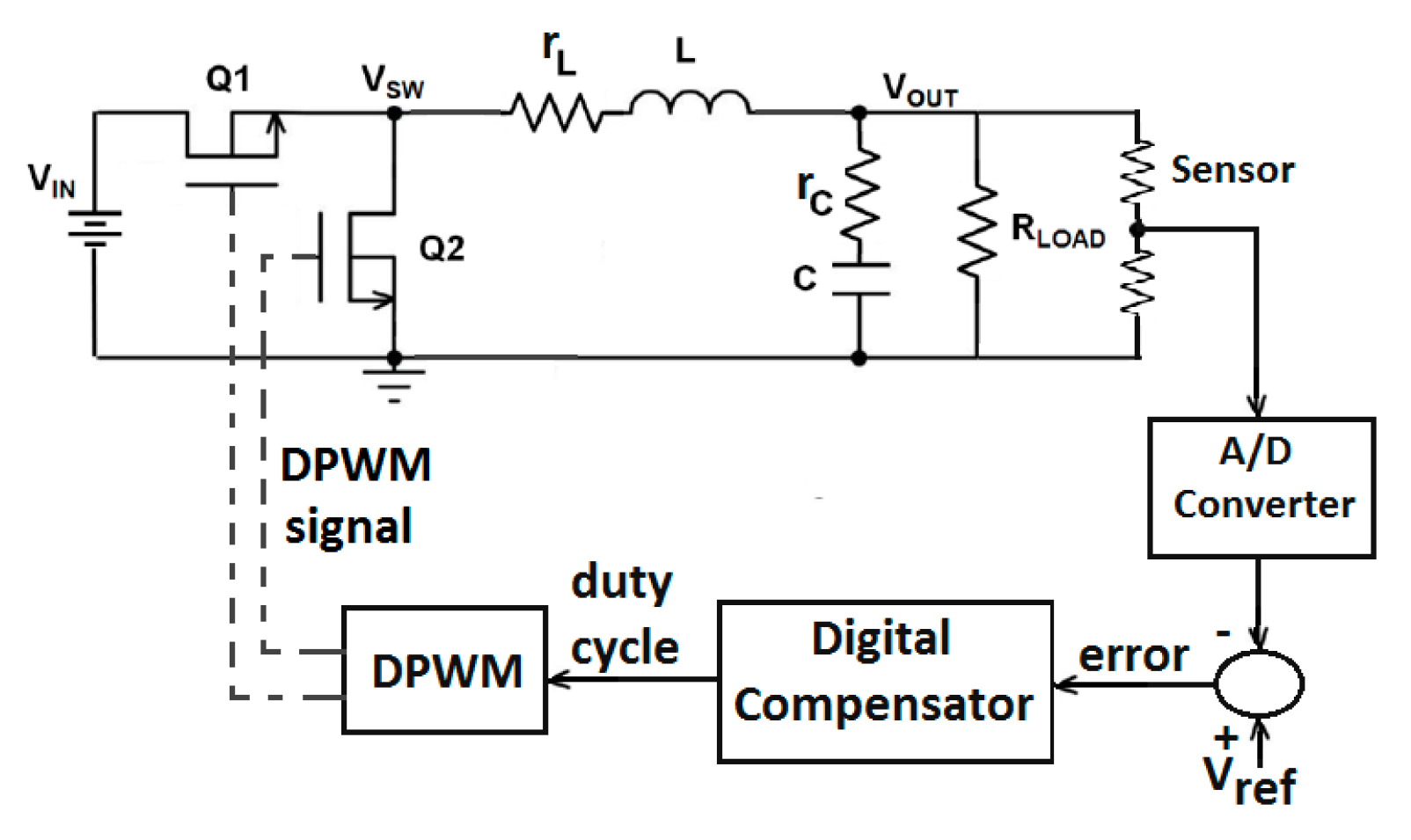
4. Synchronous Buck Converter Controller Design
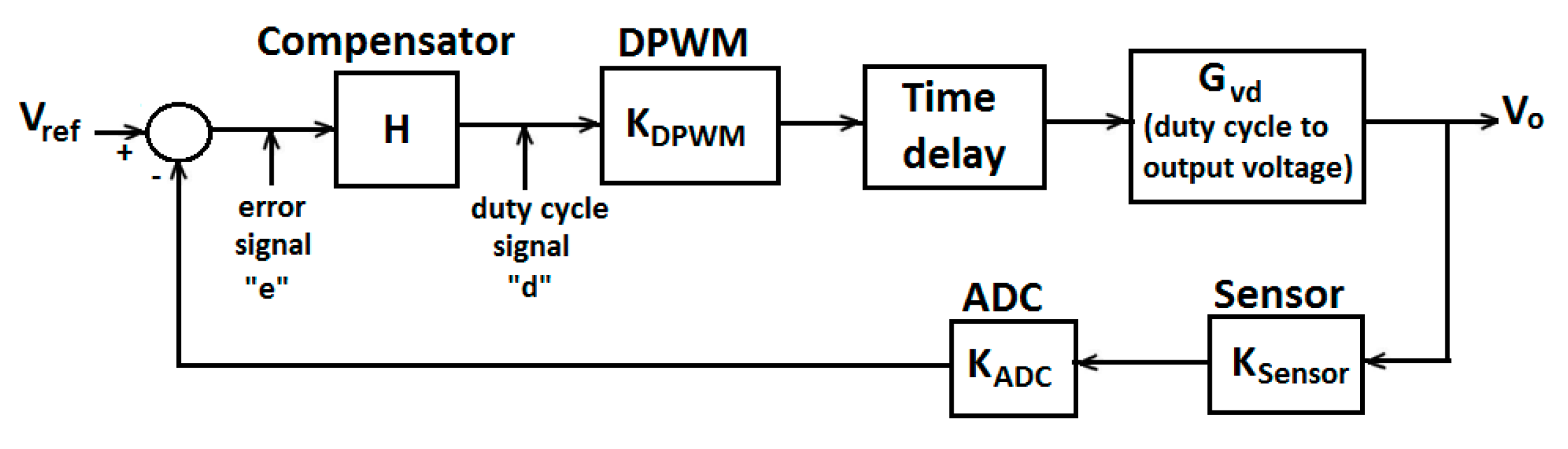
4.1. Closed-loop Control System
4.2. Digital PID Compensator Design
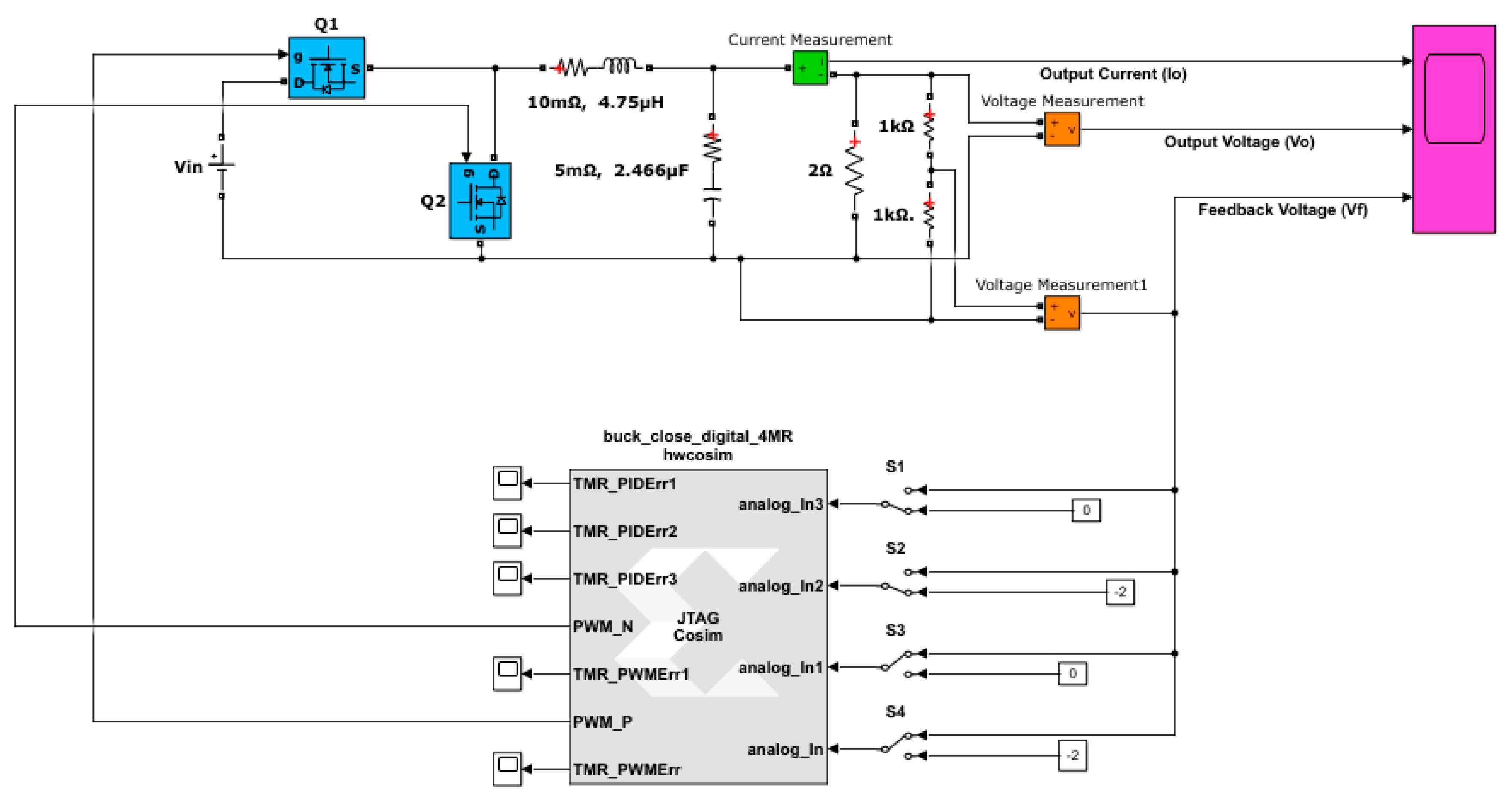
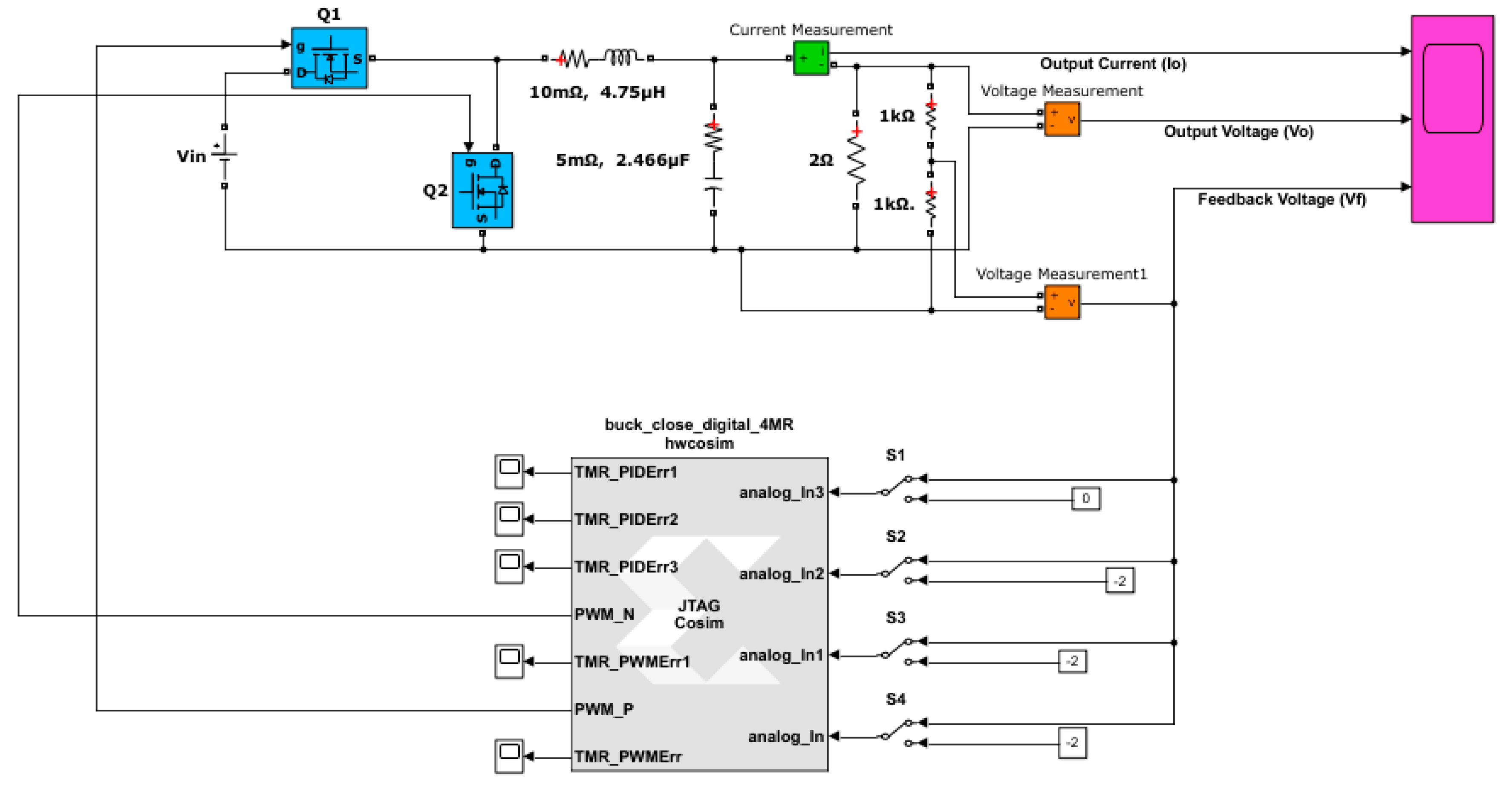
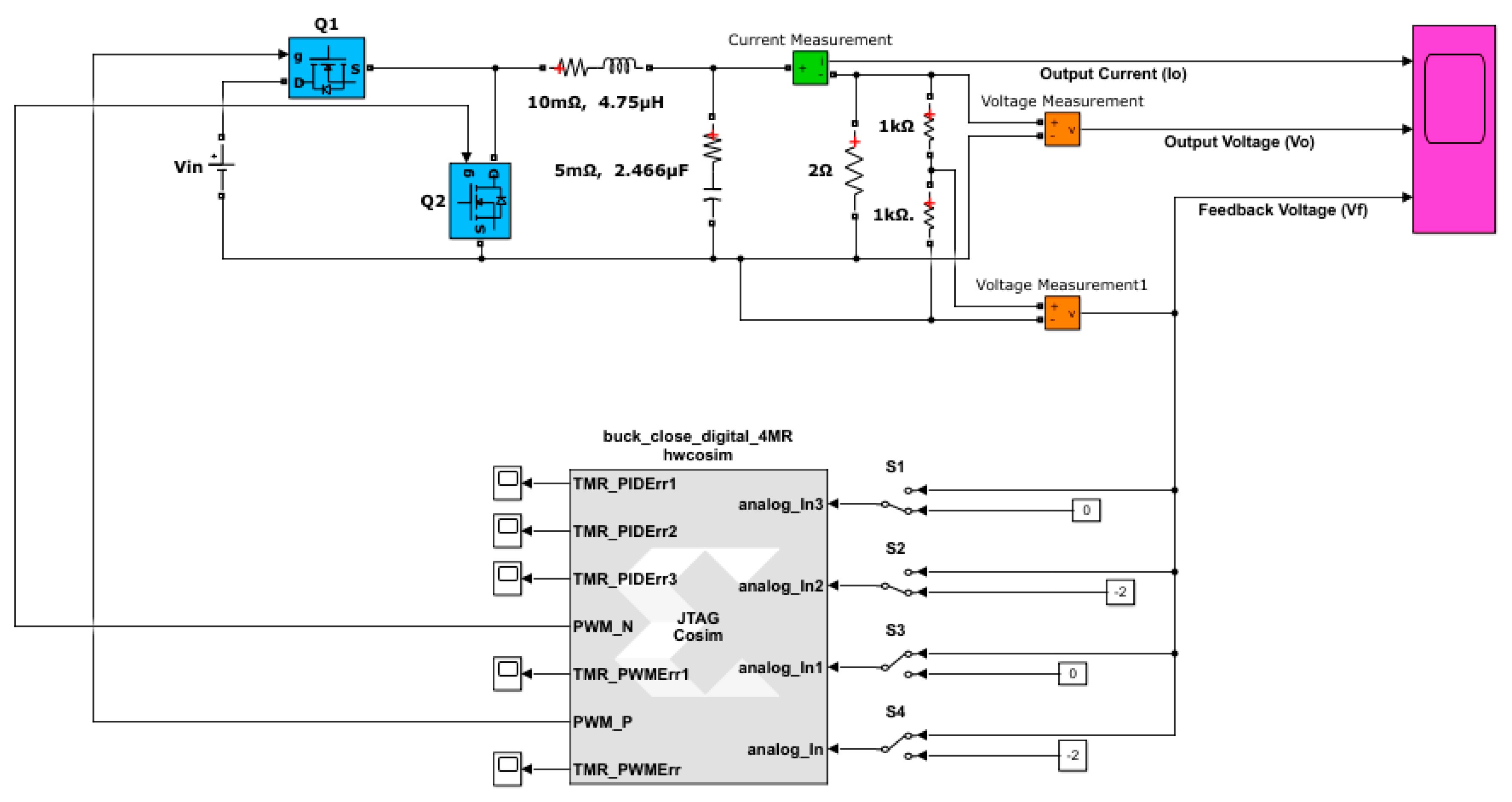
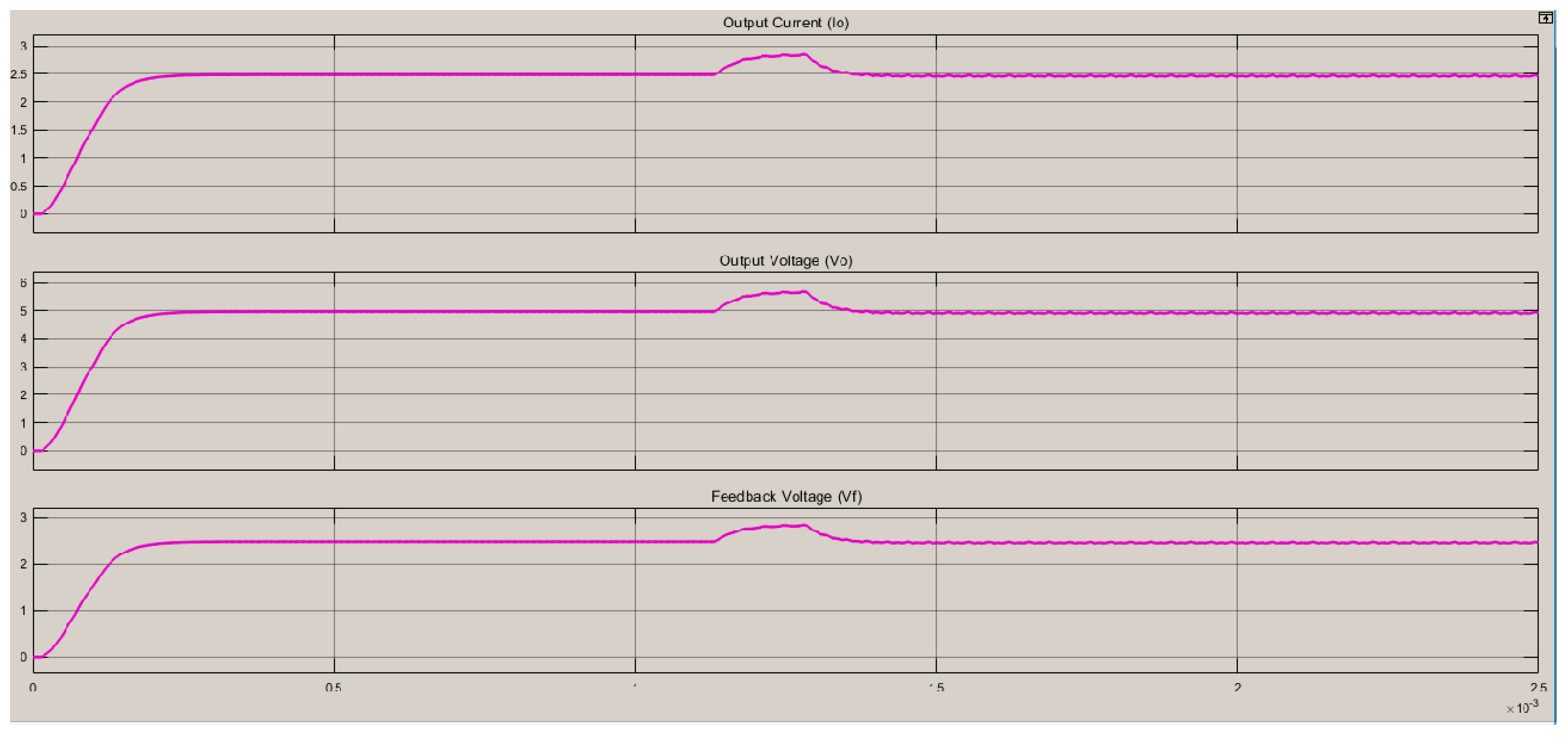
5. FPGA Implementation and Results Obtained
5.1. Hardware-in-the-Loop Simulation
5.2. Comparison of FPGA Resource Utilization and Reliability
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Maurer, R.H.; Freeman, M.E.; Martin, M.N.; Roth, D.R. Harsh Environments: Space Radiation Environment, Effects, and Mitigation; John Hopkins University: Baltimore, MD, USA, 2008. [Google Scholar]
- Leonard, C. Challenges for Electronic Circuits in Space Applications. Analog Devices, Inc. Available online: https://www.analog.com/media/en/technical-documentation/tech-articles/Challenges-for-Electronic-Circuits-in-Space-Applications.pdf (accessed on 1 July 2018).
- Jagannathan, S.; Herbison, D.R.; Holman, W.T.; Massengill, L.W. Behavioral Modeling Technique for TID Degradation of Complex Analog Circuits. IEEE Trans. Nucl. Sci. 2010, 57, 3708–3715. [Google Scholar] [CrossRef]
- Schmidt, F.H., Jr. Fault Tolerant Design Implementation on Radiation Hardened by Design SRAM-Based FPGAs. Master’s Thesis, Massachusetts Institute of Technology, Boston, MA, USA, 2013. [Google Scholar]
- Jain, M.; Gupta, R. Redundancy Issues in Software and Hardware Systems—An Overview. Int. J. Reliab. Qual. Saf. Eng. 2011, 18, 61–98. [Google Scholar] [CrossRef]
- Kolte, P.P.; Maheshwari, R.; Ajankar, S. Triple modular redundacny using fault tolerant technique—A review. In Proceedings of the International Conference on Emanations in Modern Technology and Engineering ICEMTE-2017, Maharashtra, India, 4–5 March 2017; Volume 5. [Google Scholar]
- Istiyanto, J.E.; Harjoko, A.; Putra, A.E. Five modular redundancy with mitigation technique to recover the error module. Int. J. Adv. Stud. Comput. Sci. Eng. 2014, 3, 1–6. [Google Scholar]
- Quintana, J.M.; Avedillo, J.M.; Huertas, J.L. Efficient Realization of a Threshhold voter for Self-purging Redundancy. J. Electron. Test. 2001, 17, 69–73. [Google Scholar] [CrossRef]
- Losq, J. A highly Efficient Redundancy Scheme: Self-purging Redundancy. IEEE Trans. Comput. 1976, C-25, 569–578. [Google Scholar] [CrossRef]
- Choudhury, S. Designing the Digital Compensator for a UCD91XX-Based Digital Power Supply; Texas Instruments Application Notes; Texas Instruments: Dallas, TX, USA, 2007. [Google Scholar]
- Carcheri, J.C. N-Modular Redundancy Techniques for Fault Tolerance in Reconfigurable Logic Devices; Master’s Project Report; UCF: Orlando, FL, USA, 2007. [Google Scholar]
- Uznanski, S.; Brugger, M.; Schramm, V.; Thurel, Y.; Todd, B. Radiation Tolerant Power Converter Design for the LHC; CERN CH-1211: Genève, Switzerland, 2012. [Google Scholar]
- Van Vonno, N.W.; Pearce, L.G. Total dose and single event effect testing of hardened point of load regulator. In Proceedings of the Radiation Effects Workshop (REDW), Denver, CO, USA, 20–23 July 2010; pp. 80–88. [Google Scholar]
- Wang, J.J. Radiation Effects in FPGAs; Actel Corporation: Mountain View, CA, USA, 2008. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Rating Value |
|---|---|
| Input Voltage (Vi) | 12 V, (11–16 V) |
| Output Voltage (Vo) | 5 V |
| Output Current (Io) | 2.5 A, (1.25–5 A) |
| Inductor (L), ESR | 4.75 µH, 10 mΩ |
| Capacitor (C), ESR | 2.466 µF, 5 mΩ |
| Load (R) | 2 Ω, (1–4 Ω) |
| Switching Frequency (Fsw) | 1.5 MHz |
| Methods | DSPs | LUTs | Registers | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mission Time t | |||||||||||
| Available | Used | Percentage | Available | Used | Percentage | Available | Used | Percentage | t = 1 year | t = 5 Years | |
| Simplex | 80 | 1 | 1.25 | 17,600 | 647 | 3.68 | 35,200 | 301 | 0.86 | 0.9 | 0.6 |
| TMR | 3 | 3.75 | 1934 | 10.99 | 874 | 2.48 | 0.9746 | 0.6574 | |||
| Proposed Four Module Method | 4 | 5 | 2710 | 15.4 | 1189 | 3.38 | 0.9968 | 0.8282 | |||
| FMR | 5 | 6.25 | 3195 | 18.15 | 1446 | 4.11 | 0.9926 | 0.6938 | |||
| Modified Triplex–duplex | 6 | 7.5 | 4053 | 23.03 | 1729 | 4.91 | 1.0 | 0.9620 | |||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Banteywalu, S.; Khan, B.; De Smedt, V.; Leroux, P. A Novel Modular Radiation Hardening Approach Applied to a Synchronous Buck Converter. Electronics 2019, 8, 513. https://doi.org/10.3390/electronics8050513
Banteywalu S, Khan B, De Smedt V, Leroux P. A Novel Modular Radiation Hardening Approach Applied to a Synchronous Buck Converter. Electronics. 2019; 8(5):513. https://doi.org/10.3390/electronics8050513
Chicago/Turabian StyleBanteywalu, Solomon, Baseem Khan, Valentijn De Smedt, and Paul Leroux. 2019. "A Novel Modular Radiation Hardening Approach Applied to a Synchronous Buck Converter" Electronics 8, no. 5: 513. https://doi.org/10.3390/electronics8050513
APA StyleBanteywalu, S., Khan, B., De Smedt, V., & Leroux, P. (2019). A Novel Modular Radiation Hardening Approach Applied to a Synchronous Buck Converter. Electronics, 8(5), 513. https://doi.org/10.3390/electronics8050513