An Efficient Hardware Accelerator for the MUSIC Algorithm



Abstract
:1. Introduction
- Showing the details of an HFMA without the EVD of the covariance matrix, which is time consuming with high computational cost and complex for hardware implementations. The HFMA has far fewer computations compared with the classical MUSIC algorithm at the expense of a small performance decrease, but it proves to be efficient through theoretical analysis, simulation, and hardware implementation.
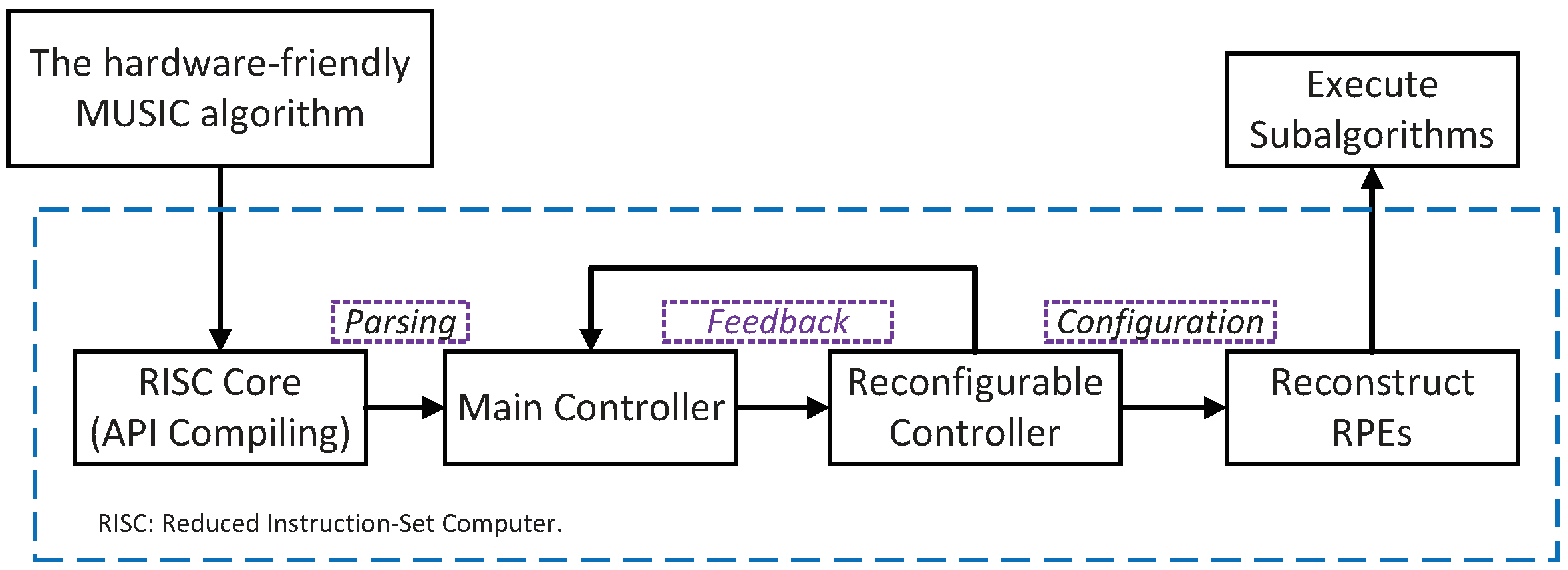
- Designing an efficient hardware accelerator to implement the HFMA. Based on a processing element (PE) array consisting of different functional units, multiple sub-algorithms can be implemented through the reconfigurable controller. Combining the sub-algorithms in the accelerator, we can implement the HFMA under the reconfigurable architecture.
- Using the CSP of the covariance matrix and the way of iterative storage to compute the correlation matrix estimation, which can reduce the computation and memory access time. It is a sub-algorithm in the accelerator and can support a matrix with arbitrary columns. Especially, compared with TMS320C6672 [20,21], which has similar computing resources, the computation period of the covariance matrix can be shortened by 3.5–5.8× after the resource normalization.
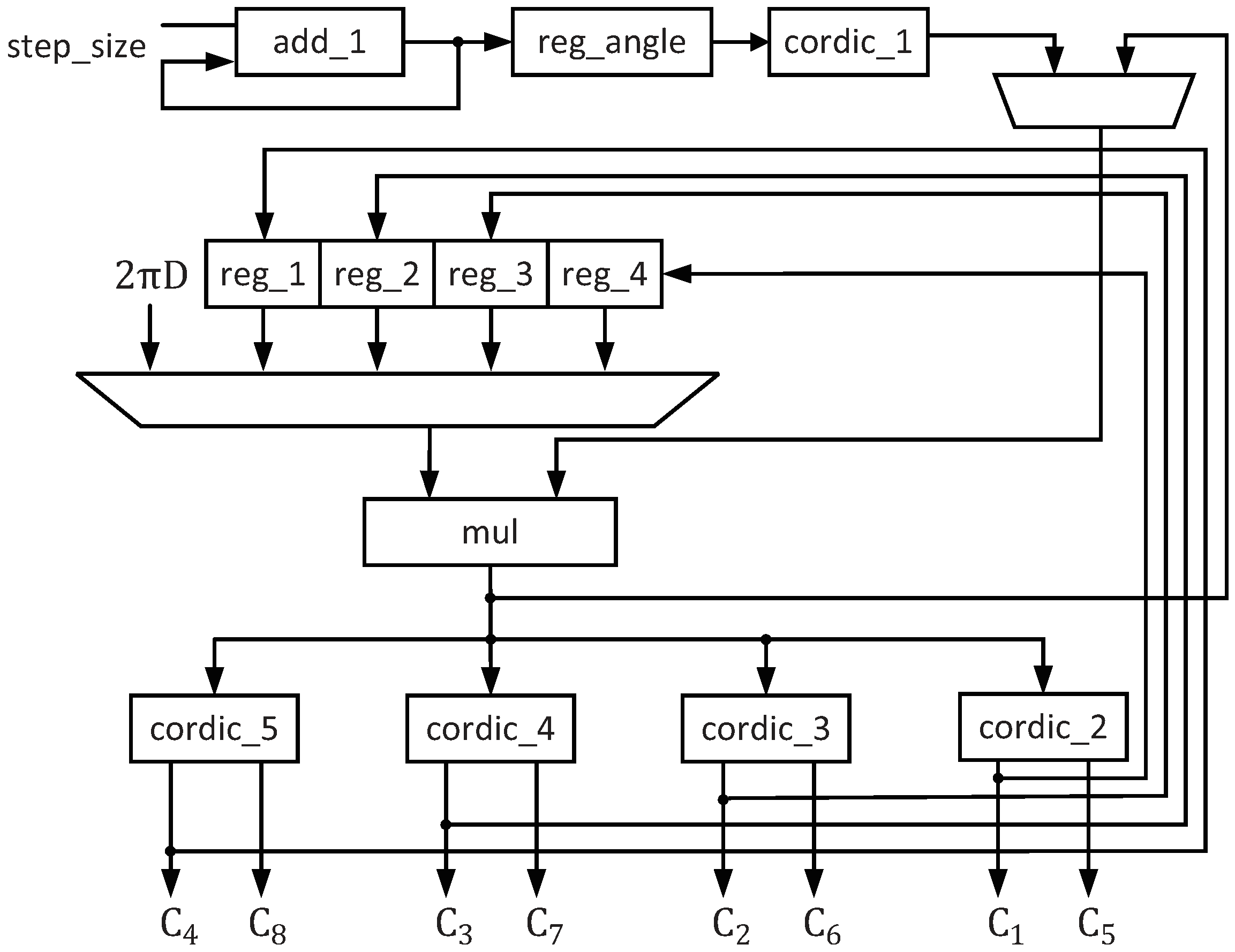
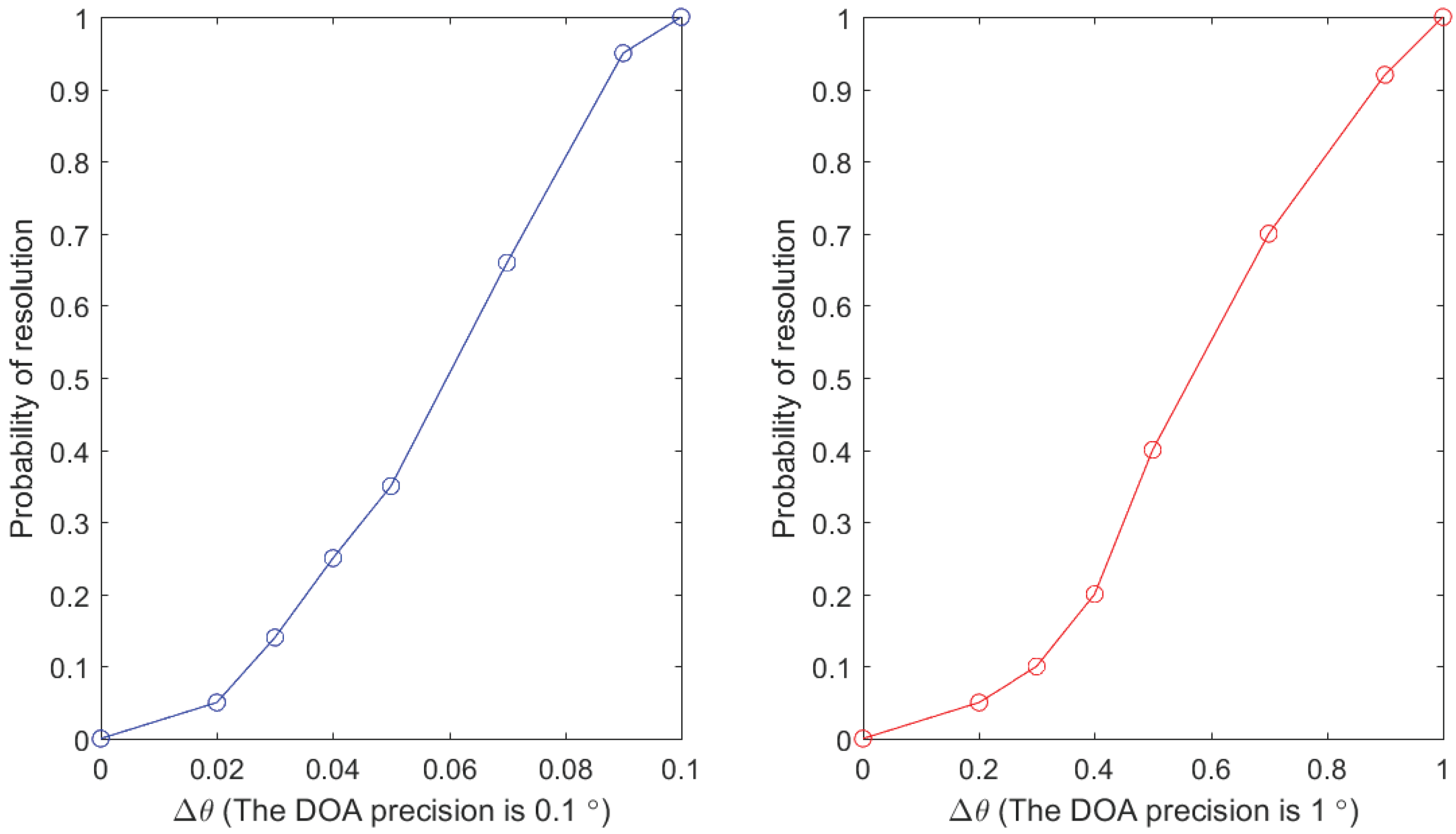
- Utilizing the reconfigurable method to decompose the spectral peak search into several sub-algorithms and also using a stepwise search method to implement the spectral peak search. When high precision is required, the larger step size is first set for the rough search in the whole range, and then, the search precision is taken as the second step size for the precise search near the first search result. The spectrum peak search in this paper is compatible with both the 1° and 0.1° accuracy requirements.
2. Backgrounds
2.1. The Array Model and the MUSIC Algorithm
2.2. The Hardware-Friendly MUSIC Algorithm
3. Implementation of the HFMA
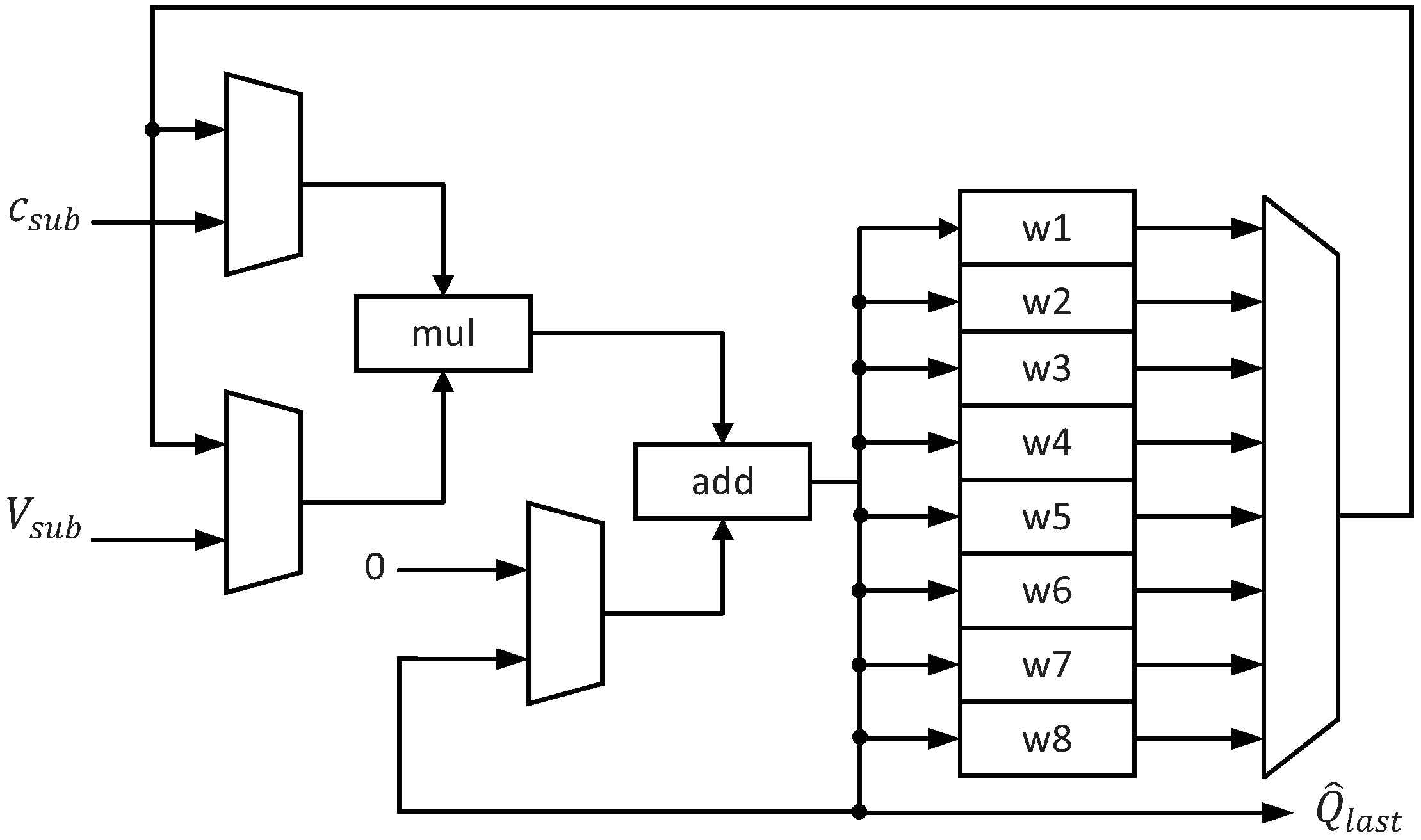
3.1. The Architecture of the Accelerator
3.2. Implementation of Correlation Matrices’ Estimation
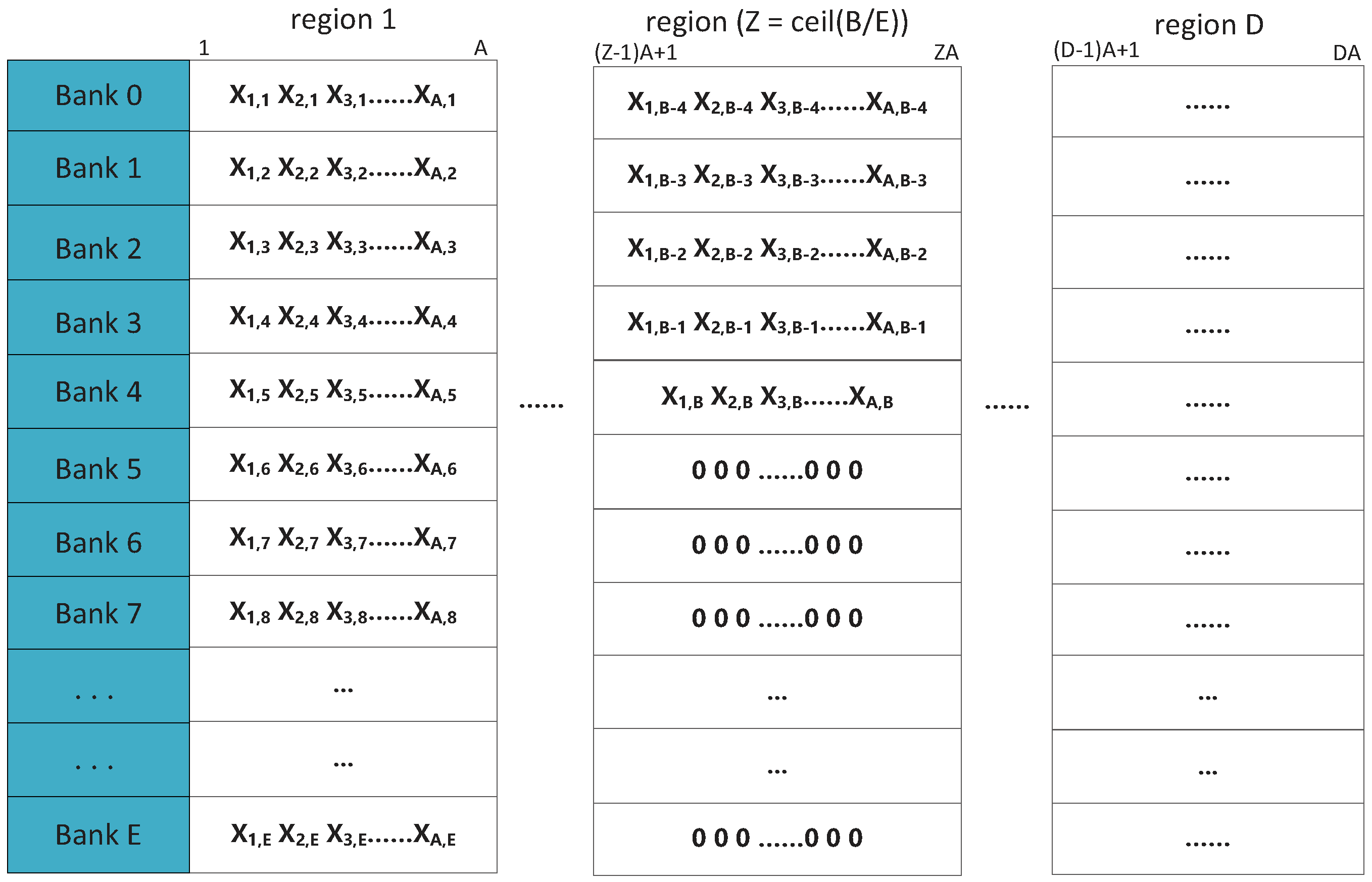
- Source data storage: The data of the matrix to be solved will be numbered from left to right and from top to bottom. Then, the data will be transmitted to the banks in order of increasing number. The address mapping formula is:where is the number of data and is the column number of the matrix to be solved.
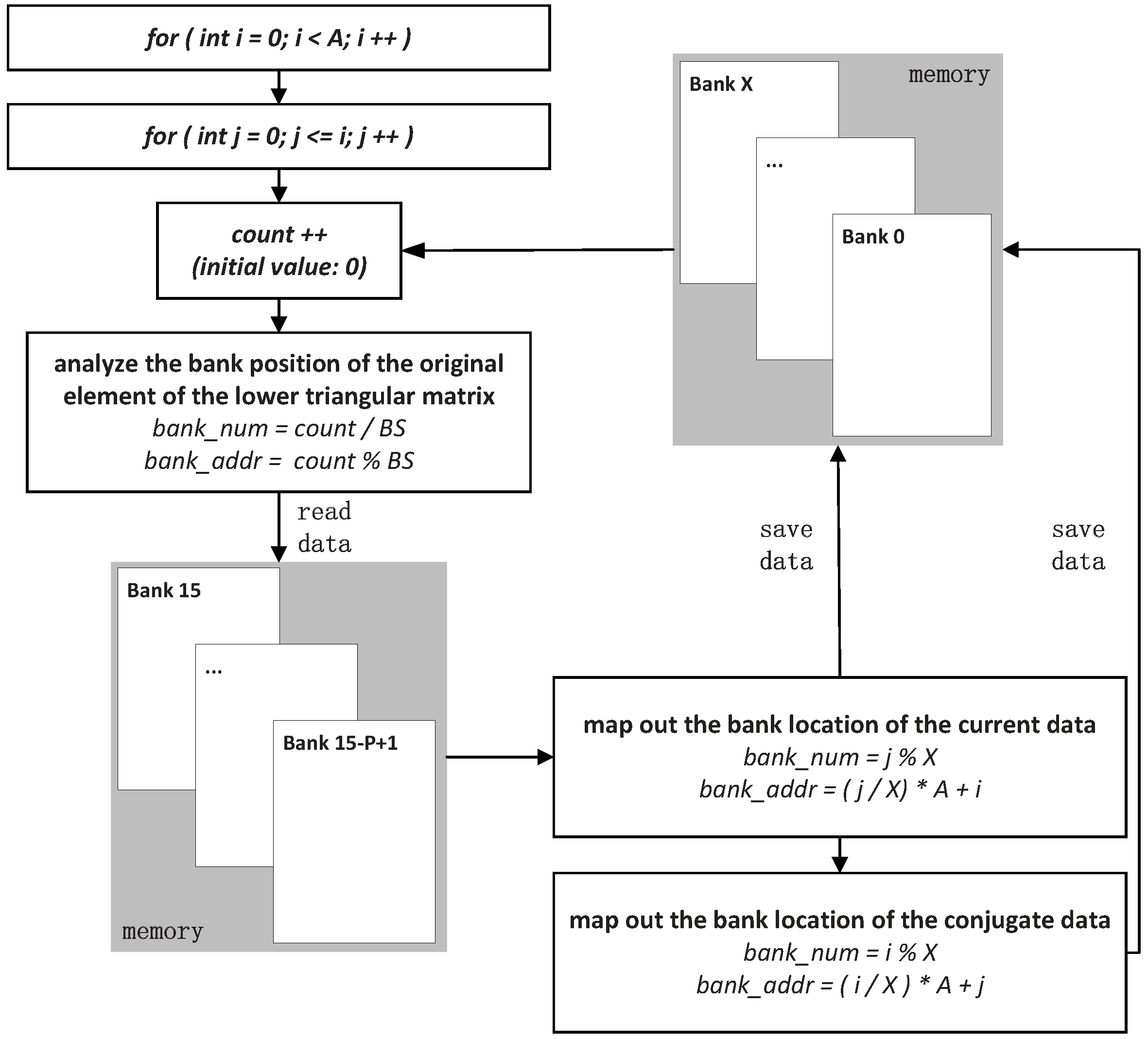
- Conjugate symmetry of the lower triangular matrix: The data of the lower triangular matrix are saved into banks according to the number from top to down and from left to right. In order to obtain the upper triangular matrix, it is necessary to determine the specific location of the original lower triangular matrix in the bank first and then extract the data. The data and its conjugate data are stored in new banks in a manner similar to the mapping mechanism of source data storage. The so-called new banks are actually the original banks of storing the source data, and their reuse scope is from Bank 0 to bank . The specific mapping mechanism is shown in Figure 5.
3.3. Implementation of Spectral Peak Search
4. The Experimental Results and Analysis
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Schmidt, R. Multiple Emitter Location and Signal Parameter Estimation. IEEE Trans. Antennas Propag. 1986, 3, 276–280. [Google Scholar] [CrossRef]
- Zoltowski, M.D.; Kautz, G.M.; Silverstein, S.D. Beamspace Root-MUSIC. IEEE Trans. Signal Process. 1993, 41, 344. [Google Scholar] [CrossRef]
- Ren, Q.S.; Willis, A.J. Fast root MUSIC algorithm. Electron. Lett. 1997, 33, 450–451. [Google Scholar] [CrossRef]
- He, Z.S.; Li, Y.; Xiang, J.C. A modified root-music algorithm for signal DOA estimation. J. Syst. Eng. Electron. 1999, 10, 42–47. [Google Scholar]
- Cheng, Q.; Lei, H.; So, H.C. Improved Unitary Root-MUSIC for DOA Estimation Based on Pseudo-Noise Resampling. IEEE Signal Process. Lett. 2014, 21, 140–144. [Google Scholar]
- Chen, Q.; Liu, R.L. On the explanation of spatial smoothing in MUSIC algorithm for coherent sources. In Proceedings of the International Conference on Information Science and Technology, Nanjing, China, 26–28 March 2011; pp. 699–702. [Google Scholar]
- Iwai, T.; Hirose, N.; Kikuma, N.; Sakakibara, K.; Hirayama, H. DOA estimation by MUSIC algorithm using forward-backward spatial smoothing with overlapped and augmented arrays. In Proceedings of the International Symposium on Antennas and Propagation Conference Proceedings, Kaohsiung, Taiwan, 2–5 December 2014; pp. 375–376. [Google Scholar]
- Wang, H.K.; Liao, G.S.; Xu, J.W.; Zhu, S.Q.; Zeng, C. Direction-of-Arrival Estimation for Circulating Space-Time Coding Arrays: From Beamspace MUSIC to Spatial Smoothing in the Transform Domain. Sensors 2018, 11, 3689. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Q.; Dong, M.; Liang, W.J. Research on modified MUSIC algorithm of DOA estimation. Comput. Eng. Appl. 2012, 48, 102–105. [Google Scholar]
- Hong, W. An Improved Direction-finding Method of Modified MUSIC Algorithm. Shipboard Electron. Countermeas. 2011, 34, 71–73. [Google Scholar]
- Wang, F.; Wang, J.Y.; Zhang, A.T.; Zhang, L.Y. The Implementation of High-speed parallel Algorithm of Real-valued Symmetric Matrix Eigenvalue Decomposition through FPGA. J. Air Force Eng. Univ. 2008, 6, 67–70. [Google Scholar]
- Kim, Y.; Mahapatra, R.N. Dynamic Context Compression for Low-Power CoarseGrained Reconfigurable Architecture. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2010, 18, 15–28. [Google Scholar] [CrossRef]
- Hwang, W.J.; Lee, W.H.; Lin, S.J.; Lai, S.Y. Efficient Architecture for Spike Sorting in Reconfigurable Hardware. Sensors 2013, 11, 14860–14887. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.J.; Liu, D.T.; Zhou, J.B.; Zhang, B.; Peng, Y. A Run-Time Dynamic Reconfigurable Computing System for Lithium-Ion Battery Prognosis. Energies 2016, 8, 572. [Google Scholar] [CrossRef]
- Li, M.; Zhao, Y.M. Realization of MUSIC Algorithm on TMS320C6711. Electron. Warf. Technol. 2005, 3, 36–38. [Google Scholar]
- Yan, J.; Huang, Y.Q.; Xu, H.T.; Vandenbosch, G.A.E. Hardware acceleration of MUSIC based DoA estimator in MUBTS. In Proceedings of the 8th European Conference on Antennas and Propagation, The Hague, The Netherlands, 6–11 April 2014; pp. 2561–2565. [Google Scholar]
- Sun, Y.; Zhang, D.L.; Li, P.P.; Jiao, R.; Zhang, B. The studies and FPGA implementation of spectrum peak search in MUSIC algorithm. In Proceedings of the International Conference on AntiCounterfeiting, Security and Identification, Macao, China, 12–14 December 2014. [Google Scholar]
- Deng, L.K.; Li, S.X.; Huang, P.K. Computation of the covariance matrix in MSNWF based on FPGA. Appl. Electron. Tech. 2007, 33, 39–42. [Google Scholar]
- Wu, R.B. A novel universal preprocessing approach for high-resolution direction-of-arrival estimation. J. Electron. 1993, 3, 249–254. [Google Scholar]
- TMS320C6672 Multicore Fixed and Floating-Point DSP (2014) Lit. No. SPRS708E; Texas Instruments Inc.: Dallas, TX, USA, 2014.
- TMS320C66x DSP Library (2014) Lit. No. SPRC265; Texas Instruments Inc.: Dallas, TX, USA, 2014.
- Yu, J.Z.; Chen, D.C. A fast subspace algorithm for DOA estimation. Mod. Electron. Tech. 2005, 12, 90–92. [Google Scholar]
- Huang, K.; Sha, J.; Shi, W.; Wang, Z.F. An Efficient FPGA Implementation for 2-D MUSIC Algorithm. Circuits Syst. Signal Process. 2016, 35, 1795–1805. [Google Scholar] [CrossRef]
- Wang, M.Z.; Nehorai, A. Coarrays, MUSIC, and the cramer–rao bound. IEEE Trans. Signal Process. 2017, 65, 933–946. [Google Scholar] [CrossRef]
- Virtex-6 Family Overview. Available online: http://www.xilinx.com/support/documentation/data_sheets/ds150.pdf (accessed on 8 May 2019).
- Devaney, A.J. Time reversal imaging of obscured targets from multistatic data. IEEE Trans. Antennas Propag. 2005, 53, 1600–1610. [Google Scholar] [CrossRef]
- Ciuonzo, D.; Romano, G.; Solimene, R. On MSE performance of time-reversal MUSIC. In Proceedings of the IEEE 8th Sensor Array and Multichannel Signal Processing Workshop (SAM), A Coruna, Spain, 22–25 June 2014. [Google Scholar]
- Ciuonzo, D.; Romano, G.; Solimene, R. Performance analysis of time-reversal MUSIC. IEEE Trans. Signal Process. 2015, 63, 2650–2662. [Google Scholar] [CrossRef]
- Ciuonzo, D.; Rossi, P.S. Noncolocated time-reversal MUSIC: high-SNR distribution of null spectrum. IEEE Signal Process. Lett. 2017, 24, 397–401. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| Q | the number of input signals |
| the qth narrowband non-coherent signal | |
| M | the number of the array element |
| d | the distance between two contiguous array elements |
| the wavelength of the source signal | |
| the angle between the qth incident wave and the array | |
| the received signal of the mth array element | |
| the zero-mean white noise of the mth array element | |
| the formed matrix | |
| the directional vector of the array | |
| C | the array manifold |
| the incident signal vector | |
| the incident noise vector | |
| the kth array input sampling | |
| K | the snapshot number |
| R | the estimate of the array covariance matrix |
| the power of noise | |
| the Mth order unit matrix | |
| the estimate of the DOA of the qth incident signal | |
| the mth normalized orthogonal eigenvector | |
| the subspace of the estimated signal | |
| the subspace of the estimated noise | |
| the MUSIC spatial spectrum | |
| the row and column number of the matrix, respectively | |
| D | the zones of the partitioned banks |
| the depth of each bank | |
| P | the number of banks to store the lower triangular matrix |
| E | the number of banks to store the source data |
| the number of data | |
| the column number of the matrix | |
| the row of the data in the matrix | |
| the column of the data in the matrix | |
| the number of the data in the bank | |
| the address of the data in the bank | |
| the value of spatial spectral function after deformation | |
| the balanced performance ratio | |
| the computation periods of the reference and this paper, respectively | |
| the slices of the reference and this paper, respectively | |
| the computation period ratio | |
| the slice ratio |
| Exp # | The Azimuth Angle (°) | or | The Pitch Angle (°) | |||||
|---|---|---|---|---|---|---|---|---|
| Input | Output | Error () | Input | Output | Error () | |||
| 1 | ||||||||
| 2 | ||||||||
| 3 | ||||||||
| 4 | ||||||||
| 5 | ||||||||
| 6 | ||||||||
| 7 | ||||||||
| 8 | ||||||||
| 9 | ||||||||
| 10 | ||||||||
| Item | ECM 1 | FDCM 2 | SPS 3 | Total Periods | ||
|---|---|---|---|---|---|---|
| Computation Period | ||||||
| Components | ||||||
| (DSP) Reference [15]/(MHz) | 28,000/(124.3) | 110,000/(124.3) | 36,000/(124.3) | 174,000/(124.3) | ||
| (FPGA) Reference [16]/(MHz) | 8032/(160) | 8064/(160) | 4464/(160) | 20,560/(160) | ||
| (FPGA) Reference [23]/(MHz) | 4096/(119.8) | 52,000/(105.4) | 31,500/(128.6) | 87,596/(105.4) | ||
| (FPGA) This paper/(MHz) | 2800/(145) | / | 22,700/(145) | 25,500/(145) | ||
| First Speed-up Ratio 4 | 90.0% | / | 36.9% | 85.3% | ||
| Second Speed-up Ratio 5 | 65.1% | / | −80.3% | −19.3% | ||
| Third Speed-up Ratio 6 | 31.6% | / | 11.4% | 74.5% | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Chen, K.; Cheng, K.; Chen, Q.; Fu, Y.; Li, L. An Efficient Hardware Accelerator for the MUSIC Algorithm. Electronics 2019, 8, 511. https://doi.org/10.3390/electronics8050511
Chen H, Chen K, Cheng K, Chen Q, Fu Y, Li L. An Efficient Hardware Accelerator for the MUSIC Algorithm. Electronics. 2019; 8(5):511. https://doi.org/10.3390/electronics8050511
Chicago/Turabian StyleChen, Hui, Kai Chen, Kaifeng Cheng, Qinyu Chen, Yuxiang Fu, and Li Li. 2019. "An Efficient Hardware Accelerator for the MUSIC Algorithm" Electronics 8, no. 5: 511. https://doi.org/10.3390/electronics8050511
APA StyleChen, H., Chen, K., Cheng, K., Chen, Q., Fu, Y., & Li, L. (2019). An Efficient Hardware Accelerator for the MUSIC Algorithm. Electronics, 8(5), 511. https://doi.org/10.3390/electronics8050511