Some Structures of Parallel VLSI-Oriented Processing Units for Implementation of Small Size Discrete Fractional Fourier Transforms



Abstract
1. Introduction
2. Preliminary Remarks
3. Algorithm and Processing Unit Structure for Small Size DFrFTs
3.1. Computing the Two-Point DFrFT
3.2. Computing the Three-Point DFrFT
3.3. Computing the Four-Point DFrFT
3.4. Computing the Five-Point DFrFT
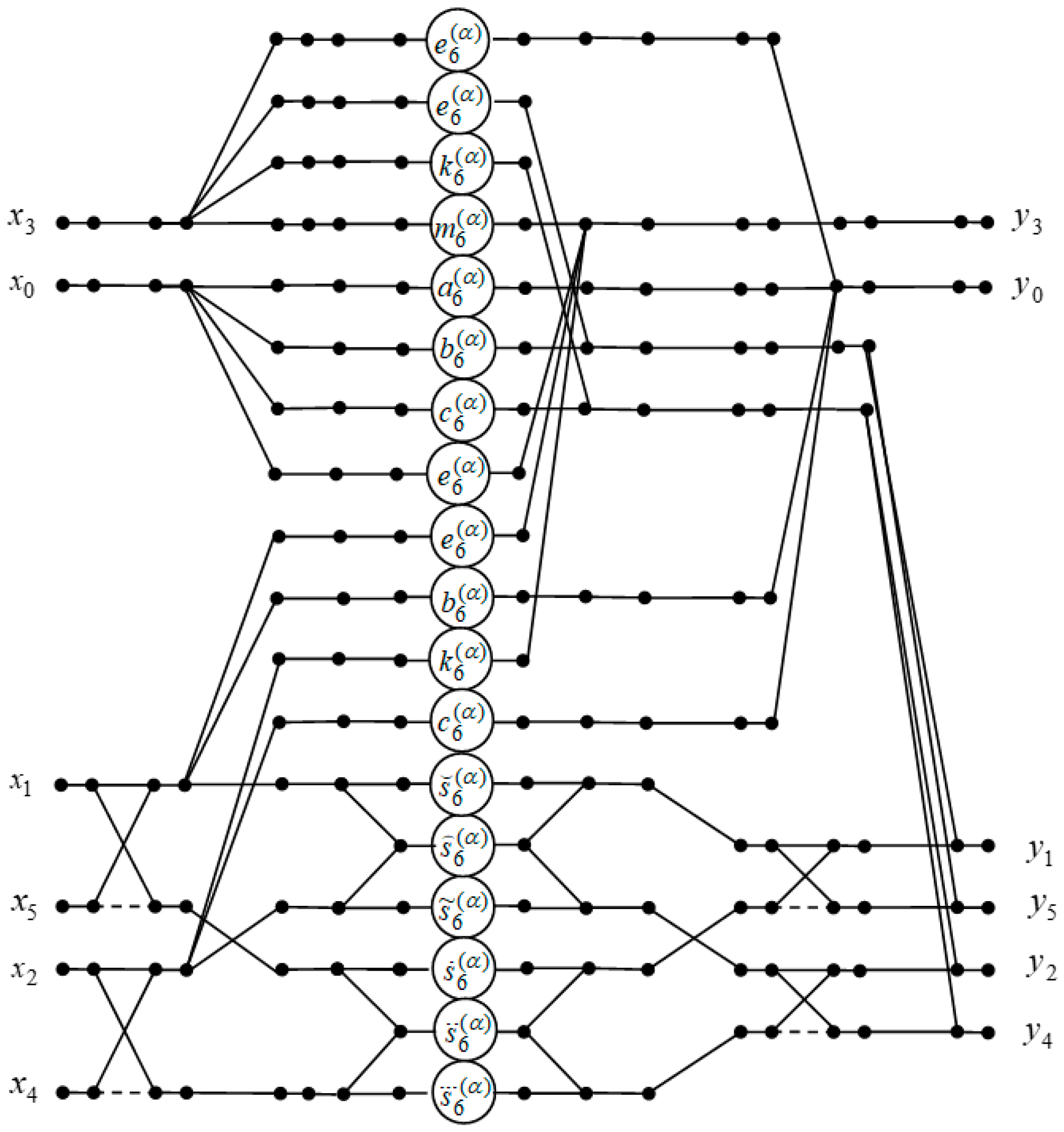
3.5. Computing the 6-Point DFrFT
3.6. Computing th eSeven-Point DFrFT
4. Implementation Complexity
5. Discussion
Author Contributions
Funding
Conflicts of Interest
References
- Pei, S.-C.; Yeh, M.-H. Improved discrete fractional Fourier transform. Opt. Lett. 1997, 22, 1047–1049. [Google Scholar] [CrossRef] [PubMed]
- Pei, S.-C.; Yeh, M.-H.; Tseng, C.-C. Discrete fractional Fourier transform based on orthogonal projections. IEEE Trans. Signal Process. 1999, 47, 1335–1348. [Google Scholar] [CrossRef]
- Candan, Ç.C.; Kutay, M.A.; Ozaktas, H.M. The discrete fractional Fourier transform. IEEE Trans. Signal Process. 2000, 48, 1329–1337. [Google Scholar] [CrossRef]
- Pei, S.-C.; Tseng, C.-C.; Yeh, M.-H.; Shyu, J.-J. Discrete fractional Hartley and Fourier transforms. IEEE Trans. Circuits Syst. II Analog Digit. Signal Process. 1998, 45, 665–675. [Google Scholar] [CrossRef]
- Pei, S.-C.; Yeh, M.H. The discrete fractional cosine and sine transforms. IEEE Trans. Signal Process. 2001, 49, 1198–1207. [Google Scholar] [CrossRef]
- Hennelly, B.; Sheridan, J.T. Fractional Fourier transform-based image encryption: Phase retrieval algorithm. Opt. Commun. 2003, 226, 61–80. [Google Scholar] [CrossRef]
- Liu, S.; Mi, Q.; Zhu, B. Optical image encryption with multistage and multichannel fractional Fourier-domain filtering. Opt. Lett. 2001, 26, 1242–1244. [Google Scholar] [CrossRef] [PubMed]
- Nishchal, N.K.; Joseph, J.; Singh, K. Fully phase encryption using fractional Fourier transform. Opt. Eng. 2003, 42, 1583–1588. [Google Scholar] [CrossRef]
- Djurović, I.; Stanković, S.; Pitas, I. Digital watermarking in the fractional Fourier transformation domain. J. Netw. Comput. Appl. 2001, 24, 167–173. [Google Scholar] [CrossRef]
- Ozaktas, H.M.; Ankan, O.; Kutay, M.A.; Bozdagi, G. Digital computation of the fractional Fourier transform. IEEE Trans. Signal Process. 1996, 44, 2141–2150. [Google Scholar] [CrossRef]
- Santhanam, B.; McClellan, J.H. Discrete rotational Fourier transform. IEEE Trans. Signal Process. 1996, 44, 994–998. [Google Scholar] [CrossRef]
- Dickinson, B.W.; Steiglitz, K. Eigenvectors and functions of the discrete Fourier transform. IEEE Trans. Acoust. Speech Signal Process. 1982, 30, 25–31. [Google Scholar] [CrossRef]
- Majorkowska–Mech, D.; Cariow, A. An Algorithm for Computing the True Discrete Fractional Fourier Transform. In Advances in Soft and Hard Computing; Pejaś, J., El Fray, I., Hyla, T., Kacprzyk, J., Eds.; Springer: Cham, Switzerland, 2019; Volume 889, pp. 420–432. [Google Scholar] [CrossRef]
- Majorkowska–Mech, D.; Cariow, A. A low-complexity approach to computation of the discrete fractional Fourier transform. Circuits Syst. Signal Process. 2017, 36, 4118–4144. [Google Scholar] [CrossRef][Green Version]
- Qureshi, F.; Garrido, M.; Gustafsson, O. Unified architecture for 2, 3, 4, 5, and 7-point DFTs based on Winograd Fourier transform algorithm. Electron. Lett. 2013, 49, 348–349. [Google Scholar] [CrossRef]
- De Oliveira, H.M.; Cintra, R.J.; Campello de Souza, R.M. A Factorization Scheme for Some Discrete Hartley Transform Matrices. arXiv 2015, arXiv:1502.01038, 1–10. [Google Scholar]
- Cariow, A. Strategies for the Synthesis of Fast Algorithms for the Computation of the Matrix-vector Products. J. Signal Process. Theory Appl. 2014, 3, 1–19. [Google Scholar] [CrossRef]
- Graham, A. Kronecker Products and Matrix Calculus: With Applications; Ellis Horwood Limited: Chichester, UK, 1981. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Size N | Numbers of Arithmetic Blocks | |||||
|---|---|---|---|---|---|---|
| Naive Method | Proposed Algorithm | |||||
| Multipliers | N-Input Adders | Multipliers | 2-Input Adders | 3-Input Adders | 4-Input Adders | |
| 2 | 4 | 2 | 3 | 3 | - | - |
| 3 | 9 | 3 | 5 | 7 | - | - |
| 4 | 16 | 4 | 10 | 7 | 2 | - |
| 5 | 25 | 5 | 11 | 18 | 1 | - |
| 6 | 36 | 6 | 18 | 20 | - | 2 |
| 7 | 49 | 7 | 19 | 24 | 6 | 1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cariow, A.; Papliński, J.; Majorkowska-Mech, D. Some Structures of Parallel VLSI-Oriented Processing Units for Implementation of Small Size Discrete Fractional Fourier Transforms. Electronics 2019, 8, 509. https://doi.org/10.3390/electronics8050509
Cariow A, Papliński J, Majorkowska-Mech D. Some Structures of Parallel VLSI-Oriented Processing Units for Implementation of Small Size Discrete Fractional Fourier Transforms. Electronics. 2019; 8(5):509. https://doi.org/10.3390/electronics8050509
Chicago/Turabian StyleCariow, Aleksandr, Janusz Papliński, and Dorota Majorkowska-Mech. 2019. "Some Structures of Parallel VLSI-Oriented Processing Units for Implementation of Small Size Discrete Fractional Fourier Transforms" Electronics 8, no. 5: 509. https://doi.org/10.3390/electronics8050509
APA StyleCariow, A., Papliński, J., & Majorkowska-Mech, D. (2019). Some Structures of Parallel VLSI-Oriented Processing Units for Implementation of Small Size Discrete Fractional Fourier Transforms. Electronics, 8(5), 509. https://doi.org/10.3390/electronics8050509