Pano-RSOD: A Dataset and Benchmark for Panoramic Road Scene Object Detection

 , , , ,
, , , ,  and
and
Abstract
1. Introduction
- A lack of panoramic object detection datasets for deep learning. A panoramic image usually contains more objects and some distorted objects due to its special imaging mechanism, which is different from the ordinary. Therefore, an object detection task for panoramic images needs a new panoramic dataset to train and test for the purpose of adapting the differences.
- Although the existing object detection methods of common images can be transferred to the panoramic object detection, there is a lack of model, evaluation statistics and benchmarks specifically for the panoramic object detection.
- We present a novel and promising topic for panoramic road scene object detection, which will have potential applications in ADAS, UAV and panoramic mapping. Compared with the normal view, a panoramic view can cover a larger perspective and contain more objects in one single image. It could be possible to cover some complicated situations which are not covering in the most existing datasets. And the object detection on the online panoramic map is challenging. Thus, a panoramic road scene dataset is needed and important. In order to provide more research foundation for solving the object detection in panoramic image problems, related object detection methods and datasets are compressively overviewed (Section 2).
- We construct a high-resolution, panoramic road scene object detection dataset (Pano-RSOD) with more annotations and small object diversity. The data set is, to the best of our knowledge, the first high-resolution panoramic road scene dataset and the images are with high intraclass diversity. The dataset can provide a better experimental dataset for the object detection algorithm based on the panoramic image. Besides, the dataset can also evaluate the advantages and disadvantages of object detection algorithms, which aimed at small and deformed objects (Section 3).
2. Related Works
2.1. Existing Object Detection Dataset of Road Scene
- Pascal VOC Dataset [7]: This dataset is used as a standardized dataset for image detection and classification. There are two versions of voc2007 and voc2012. voc2007 has a total of 9963 images, and voc2012 has a total of 17,125 images. They include 20 categories to be detected, e.g., cars, pedestrians and etc. The image size in the dataset is different, and the horizontal image size is about 500 × 375 pixels, and the vertical image size is about 375 × 500 pixels. Each image corresponds to an xml format label file, which records the image size, ground-truth of object coordinates and other information. This dataset is widely used as an evaluation criterion in various object detection algorithms [18,20,21,22,24,25].
- Object Detection Evaluation 2012 [10]: This is a dataset for 2D object detection and azimuth estimation in the KITTI database. It consists of 7481 training images and 7518 test images. A total of 80,256 objects are marked, covering the car, pedestrian and cyclist. Among them, the precision-recall (PR) curve is used for object detection evaluation. The dataset has a wide range of applications in vehicle detection and pedestrian detection due to a large number of car and pedestrian samples in the dataset.
- Pedestrian Detection Dataset: Pedestrian detection is one of the important tasks in the fields of video surveillance and automatic driving. Therefore, the pedestrian detection dataset also plays an important role in evaluating various object detection algorithms. The INRIA person dataset [26] was created by Daal, where the training set contains 614 positive samples (including 2416 pedestrians) and 1218 negative samples, and the test set contains 288 positive samples (including 1126 pedestrians) and 453 negative samples. The dataset is currently used widely in static pedestrian detection. The NICTA Pedestrian Dataset [27] is a larger static pedestrian detection dataset at present. There are 25,551 images containing single pedestrian, 5207 high-resolution images containing non-pedestrian. The training set and test set have been divided to facilitate the comparison of different classifiers in the database. The Caltech pedestrian dataset [11] is currently a large pedestrian database, which is captured by a car camera in the urban traffic environment. The dataset is a video about 10 h, and the resolution is 640 × 480, 30 frames per second. The dataset labels about 250,000 bounding boxes (including 350,000 rectangles and 2300 pedestrians). In addition, there are other pedestrian detection datasets, such as ETH [28] and CVC [29].
- Vehicle Detection Dataset: Vehicle detection is a key step in vehicle analysis, and it is the basis for subsequent vehicle identification and vehicle feature recognition. Earlier, there is CBCL Car Database [30] created by MIT, which contains 516 images in ppm format with a resolution of 128 × 128, mainly using for vehicle detection. The UA-DETRAC dataset [12] is a larger vehicle detection and tracking dataset. It contains 10 h of video taken at different locations in Beijing and Tianjin, China. The resolution of video is 960 × 540, and the frame ratio is 25 frames per second. The dataset labels 8250 vehicles and 1.21 million object bounding boxes. BIT-Vehicle Dataset [31] covers 9850 images of bus, microbus, minivan, sedan, SUV, and truck, which can be used to evaluate the performance of multi-class vehicle detection algorithms.
2.2. Object Detection Methods
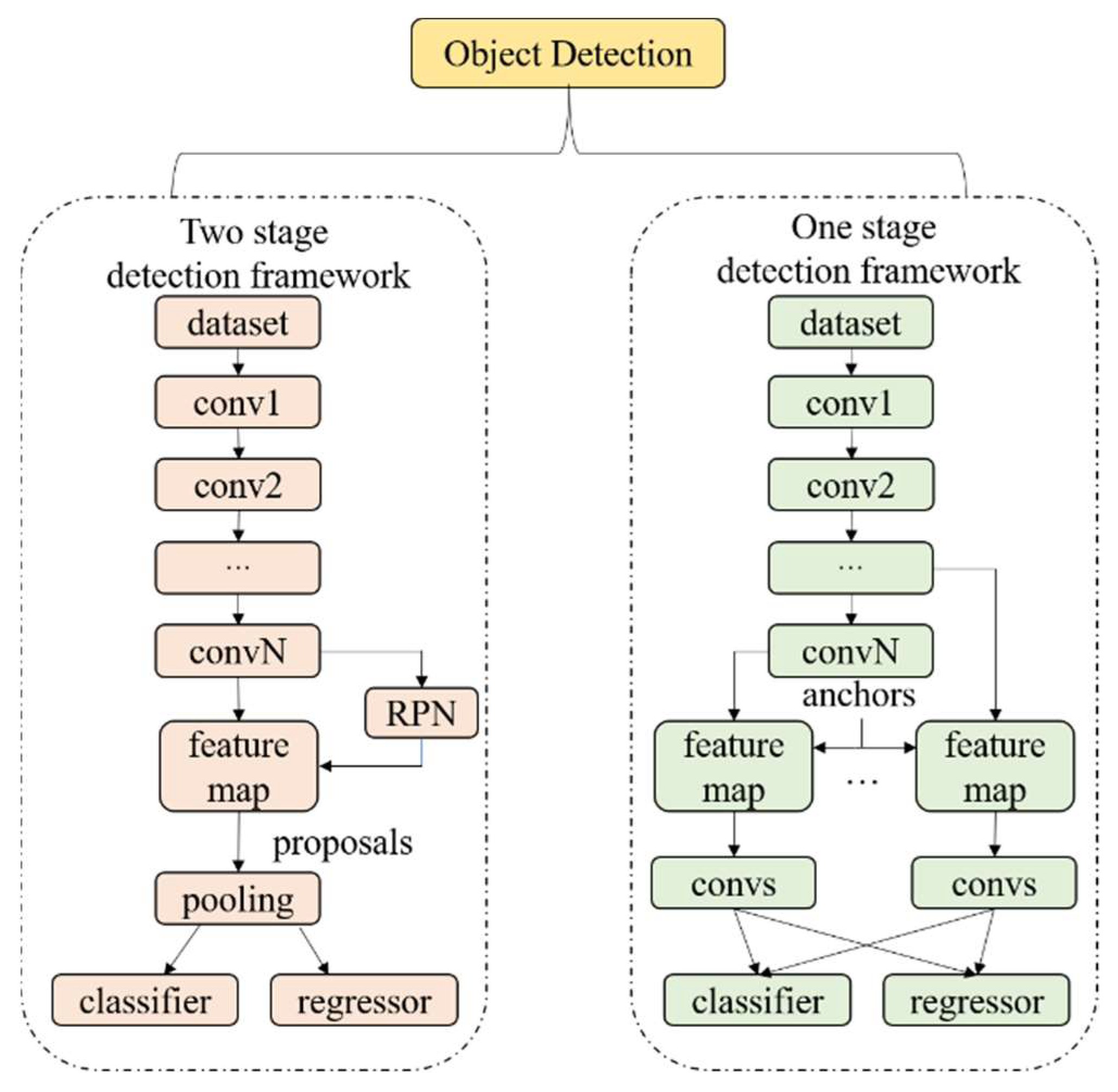
3. Panoramic Road Scene Object Detection Dataset
3.1. New Dataset for Object Detection of Road Scene (Pano-RSOD)
3.2. Dataset Construction
3.2.1. Panoramic Image Acquisition
3.2.2. Dataset Labeling
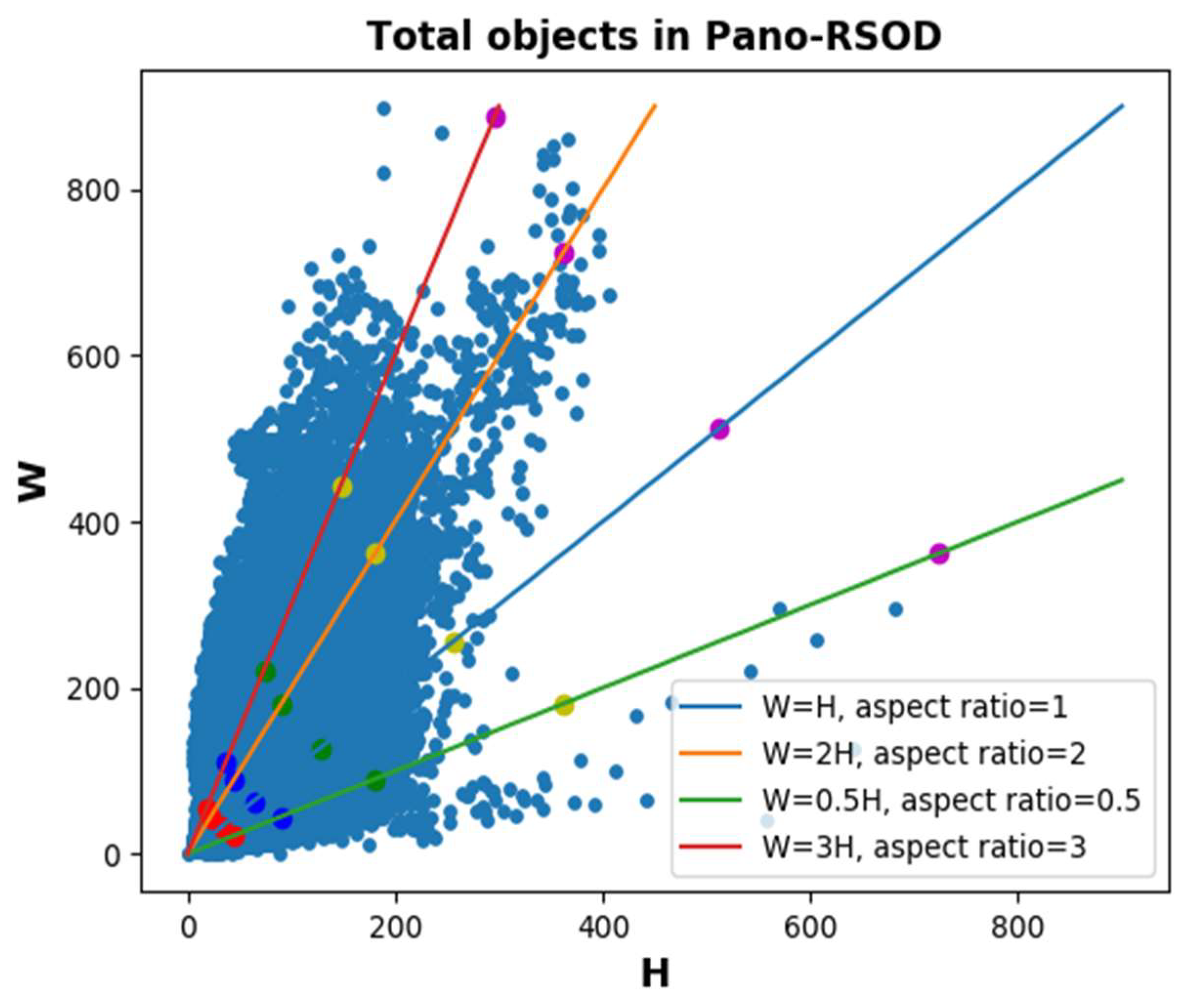
3.2.3. Dataset Statistics and Analysis
- Panorama: According to the information collected from the Internet, the current public object detection datasets are basically not panoramic images, but our road scene panoramic dataset can provide a good reference for the panoramic technology applied in the object detection. Besides, objects in panoramic image often have distortion which provides a challenge for object detection task.
- Large-scale and high resolution: According to the comparison results in Table 2, the Pano-RSOD has more labeled sample sizes, especially with the most abundant vehicle information. Besides, the Pano-RSOD has higher image resolution.
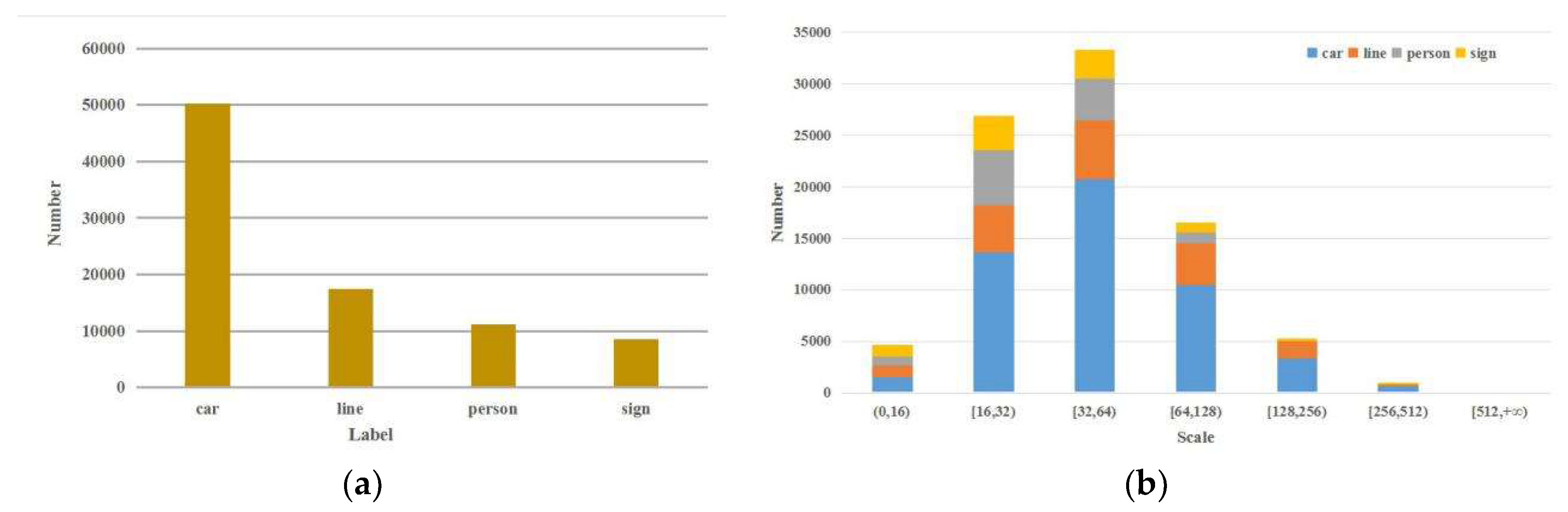
- Multi-scales and more small objects: As can be seen from Figure 4b, the Pano-RSOD has a wide range of scales. Especially for small objects, it has as many as 31,579 samples with a scale less than 32.
- Diversity: Figure 5 lists the objects of different types of labels in the Pano-RSOD. As shown in Figure 5, the Pano-RSOD is rich in object types. For instance, vehicle samples cover different types (e.g., truck, sedan, bus, SUV, taxi, etc.), orientations and scales, person samples include cycling, walking, standing, crowded people, traffic sign samples contain different shapes, sizes, colors and contents, guide arrow samples have different shapes, colors, and directions of representation.
4. Baseline Methods
5. Experiments and Benchmark Statistics
5.1. Evaluation Metrics
5.2. Benchmark Statistics
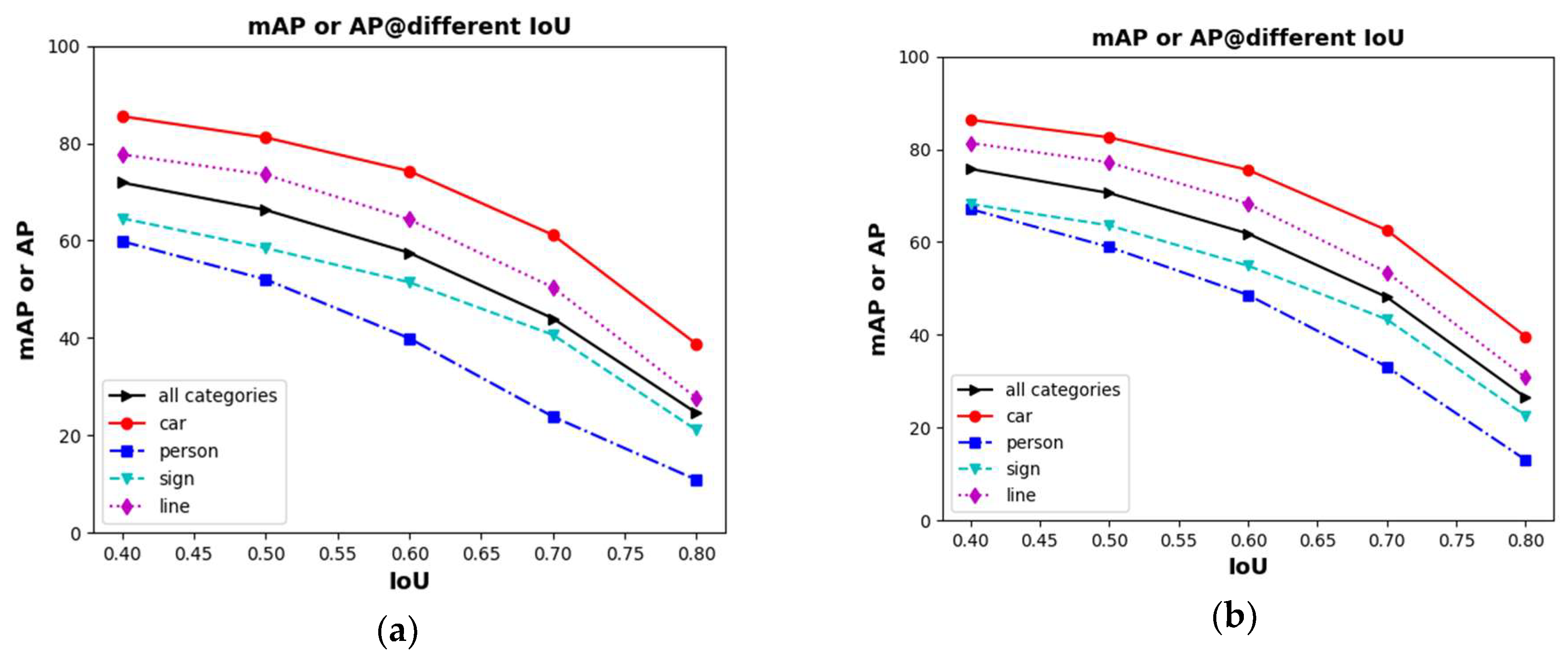
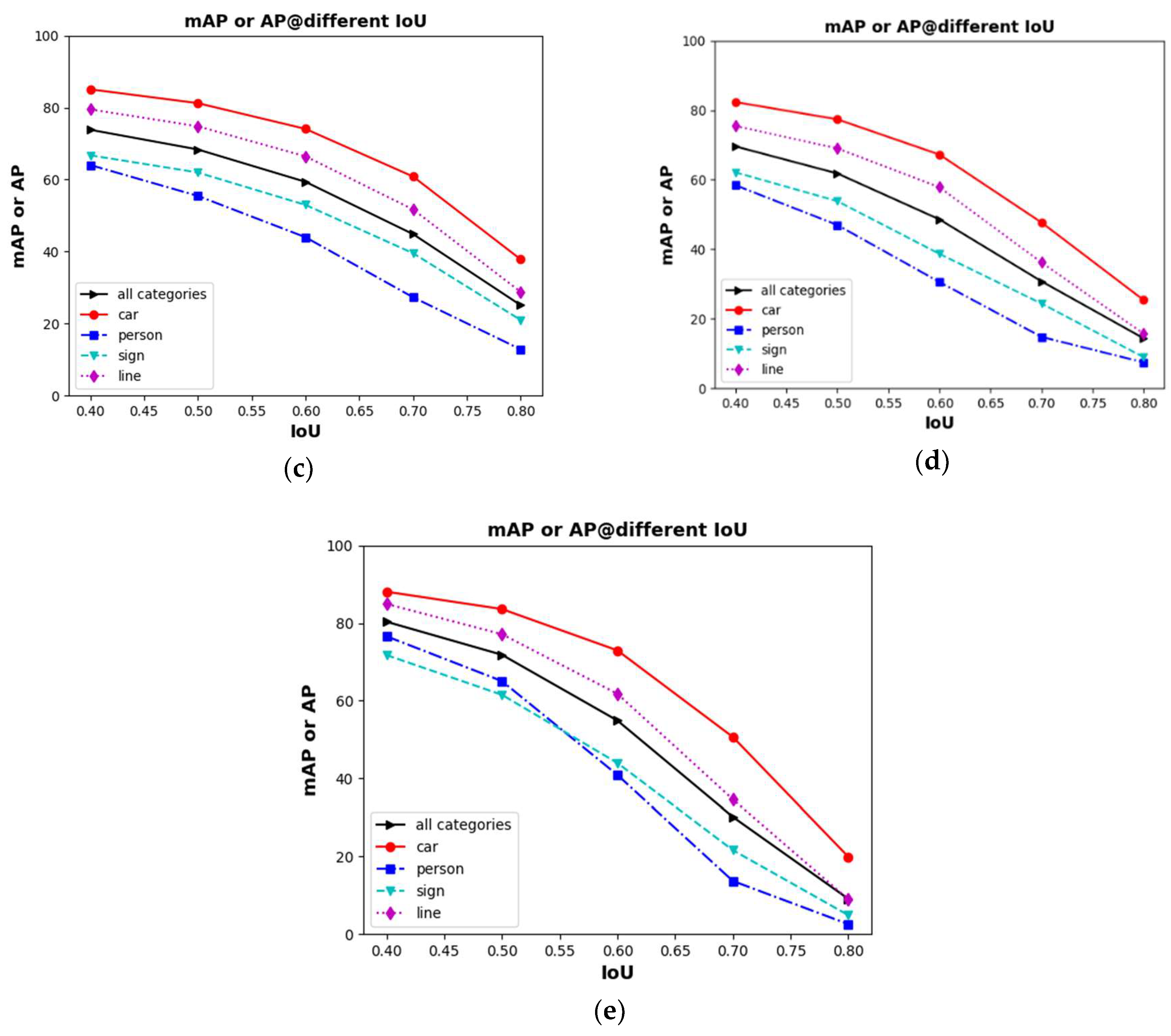
5.2.1. Qualitative Evaluation
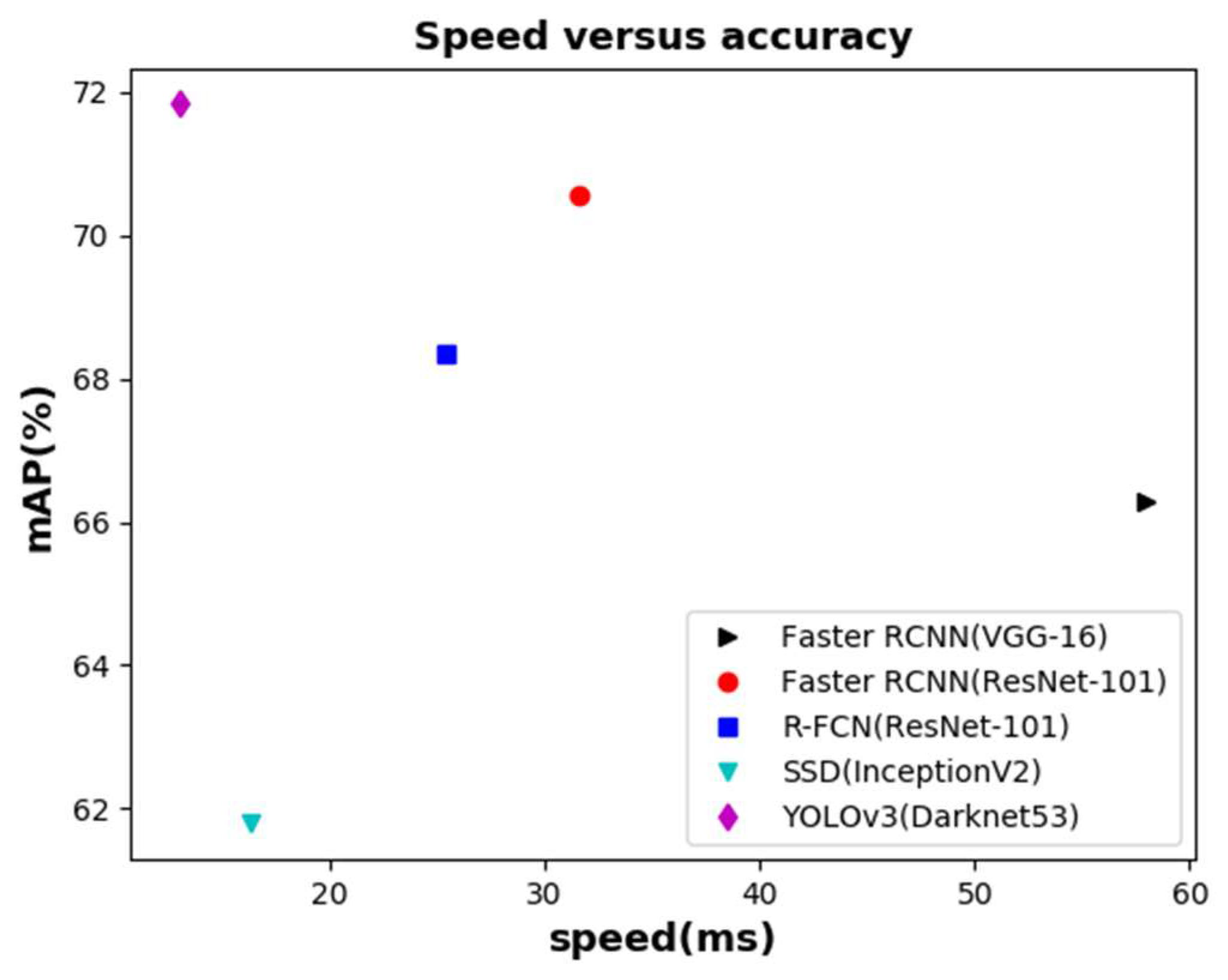
5.2.2. Quantitative Evaluation
5.2.3. Comparisons with a General Dataset
5.2.4. About Robustness of Detectors for Small Object
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Bertozzi, M.; Castangia, L.; Cattani, S.; Prioletti, A.; Versari, P. 360° Detection and tracking algorithm of both pedestrian and vehicle using fisheye images. In Proceedings of the 2015 IEEE Intelligent Vehicles Symposium (IV), Seoul, Korea, 28 June–1 July 2015; pp. 132–137. [Google Scholar]
- Lin, M.; Xu, G.; Ren, X.; Xu, K. Cylindrical panoramic image stitching method based on multi-cameras. In Proceedings of the 2015 IEEE International Conference on Cyber Technology in Automation, Control, and Intelligent Systems (CYBER), Shenyang, China, 8–12 June 2015; pp. 1091–1096. [Google Scholar]
- Fakour-Sevom, V.; Guldogan, E.; Kämäräinen, J.K. 360 panorama super-resolution using deep convolutional networks. In Proceedings of the 13th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications, Funchal, Portugal, 27–29 January 2018; pp. 159–165. [Google Scholar]
- Kart, U.; Kamarainen, J.K.; Fan, L.; Gabbouj, M. Evaluation of visual object trackers on equirectangular panorama. In Proceedings of the International Conference on Computer Vision Theory and Applications, Funchal, Portugal, 27–29 January 2018. [Google Scholar]
- Frome, A.; Cheung, G.; Abdulkader, A. Large-scale privacy protection in Google Street View. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009. [Google Scholar]
- Balali, V.; Ashouri, A.; Golparvar, F. Detection, classification, and mapping of U.S. traffic signs using google street view images for roadway inventory management. Vis. Eng. 2015, 3, 3–15. [Google Scholar] [CrossRef]
- Everingham, M.; VanGool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal visual object classes (VOC) challenge. Int. J. Comput. Vis. 2009, 88, 303–338. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are We Ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Dollár, P.; Wojek, C.; Schiele, B.; Perona, P. Pedestrian detection: An evaluation of the state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 743–761. [Google Scholar] [CrossRef] [PubMed]
- Wen, L.; Du, D.; Cai, Z.; Lei, Z.; Chang, M.C.; Qi, H.; Lim, J.; Yang, M.H.; Lyu, S. UA-DETRAC: A New Benchmark and Protocol for Multi-Object Detection and Tracking. 2015. Available online: https://arxiv.org/abs/1511.04136 (accessed on 4 September 2015).
- Gerhard, N.; Tobias, O.; Samuel, R.B.; Peter, K. The Mapillary Vistas Dataset for Semantic Understanding of Street Scenes. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4990–4999. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Huang, X.Y.; Cheng, X.J.; Geng, Q.C.; Cao, B.B.; Zhou, D.F.; Wang, P.; Lin, Y.Q.; Yang, R.G. The ApolloScape Dataset for Autonomous Driving. CoRR. 2018. Available online: https://arxiv.org/abs/1803.06184 (accessed on 26 September 2018).
- Hazelhoff, L.; Creusen, I.; de with, P.H.N. Robust detection, classification and positioning of traffic signs from street-level panoramic images for inventory purposes. In Proceedings of the 2012 IEEE Workshop on the Applications of Computer Vision (WACV), Breckenridge, CO, USA, 9–11 January 2012; pp. 313–320. [Google Scholar]
- Deng, F.; Zhu, X.; Ren, J. Object Detection on Panoramic Images Based on Deep Learning. In Proceedings of the 2017 3rd International Conference on Control, Automation and Robotics (ICCAR), Nagoya, Japan, 24–26 April 2017; pp. 375–380. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region based fully convolutional networks. In Proceedings of the Advances in Neural Information Processing Systems 29 (NIPS 2016), Barcelona, Spain, 5–10 December 2016; pp. 379–387. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An Incremental Improvement. 2018. Available online: https://arxiv.org/abs/1804.02767 (accessed on 8 April 2018).
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conferences on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Hong, S.; Roh, B.; He, K.; Kim, Y.; Cheon; Park, M. Pvanet: Lightweight deep neural networks for real-time object detection. arXiv, 2016; arXiv:1611.08588. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv, 2017; arXiv:1701.06659. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Overett, G.; Petersson, L.; Brewer, N.; Andersson, L.; Pettersson, N. A new pedestrian dataset for supervised learning. In Proceedings of the IEEE Intelligent Vehicles Symposium, Eindhoven, The Netherlands, 4–6 June 2008; pp. 373–378. [Google Scholar]
- Ess, A.; Leibe, B.; Gool, L.V. Depth and appearance for mobile scene analysis. In Proceedings of the IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Gerónimo, D.; Sappa, A.; López, A.; Ponsa, D. Adaptive image sampling and windows classication for on-board pedestrian detection. In Proceedings of the International Conference on Computer Vision Systems, Bielefeld, Germany, 21–24 March 2007. [Google Scholar]
- Leung, B. Component-Based Car Detection in Street Scene Images. Master’s Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, May 2004. [Google Scholar]
- Dong, Z.; Wu, Y.; Pei, M.; Jia, Y. Vehicle type classification using a semisupervised convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2247–2256. [Google Scholar] [CrossRef]
- Razavian, A.S.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN features off-the-shelf: An astounding baseline for recognition. In Proceedings of the IEEE Conferences on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 806–813. [Google Scholar]
- Girshick, R.B.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the IEEE Conferences on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R.B. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conferences on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conferences on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Sermanet, P.; Eigen, D.; Zhang, X.; Mathieu, M.; Fergus, R.; LeCun, Y. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv, 2013; arXiv:1312.6229. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolo9000: Better, faster, stronger. In Proceedings of the IEEE Conferences on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Jeong, J.; Park, H.; Kwak, N. Enhancement of SSD by concatenating feature maps for object detection. arXiv, 2017; arXiv:1705.09587. [Google Scholar]
- Li, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. arXiv, 2018; arXiv:1809.02165. [Google Scholar]
- Uijlings, J.R.R.; van de Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Shrivastrava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conferences on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Two-Stage | One-Stage | ||||||
|---|---|---|---|---|---|---|---|---|
| Fast RCNN | Faster RCNN | PVAnet | R-FCN | YOLO | YOLOv3 | SSD | DSSD | |
| Region proposal | selective search [42] | RPN [18] | RPN | RPN | grid cells | anchor boxes | default boxes | default boxes |
| Prediction layer | One | one | One * | one | one | Multiple * | multiple | Multiple * |
| Dataset | Pascal VOC 2007 | Object Detection Evaluation 2012 | BIT-Vehicle | Pano-RSOD | UA-DETRAC | Cityscapes (Semantic) | Mapillary Vistas (Semantic) |
|---|---|---|---|---|---|---|---|
| Panorama | No | No | No | Yes | No | No | No |
| Traffic Scene | No | Yes | Yes | Yes | Yes | Yes | Yes |
| Resolution | ~375 × 500 | 1240 × 376 | 1600 × 1200 1920 × 1080 | 2048 × 1024 | 960 × 540 | 2048 × 1024 | 1920 × 1080 |
| Number of Categories | 20 | 3 | 6 | 4 | 4 | 30 | 18 (object) |
| Number of Cars | 2500 | Unknown | 10,053 | 50,255 | 8250 | Unknown | ~200 thousand |
| Number of Images | 9963 | 14,999 | 9850 | 9402 | 140 thousand | 25,000 | 25,000 |
| Number of Samples | 24,640 | 80,256 | 10,053 | 87,542 | 1.21 million | Unknown | Unknown |
| Terms | H | W | Aspect Ratio | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Classes | Car | Sign | Line | Person | Car | Sign | Line | Person | Car | Sign | Line | Person |
| First | 61 | 26 | 129 | 32 | 98 | 24 | 465 | 18 | 1.6 | 0.9 | 3.6 | 0.6 |
| Second | 118 | 146 | 81 | 114 | 211 | 135 | 239 | 63 | 1.8 | 0.9 | 1.7 | 0.6 |
| Third | 28 | 187 | 26 | 139 | 41 | 396 | 39 | 245 | 1.5 | 2.1 | 1.5 | 1.8 |
| Fourth | 182 | 67 | 68 | 64 | 435 | 57 | 114 | 33 | 2.4 | 0.9 | 1.8 | 0.5 |
| Methods | Scale | Aspect Ratio | Anchor Type Number |
|---|---|---|---|
| Faster RCNN (VGG-16) | {32,64,128,256,512} | {0.5,1,2,3} | 20 |
| Faster RCNN (ResNet-101) | {32,64,128,256,512} | {0.5,1,2,3} | 20 |
| R-FCN (ResNet-101) | {32,64,128,256,512} | {0.5,1,2,3} | 20 |
| SSD (InceptionV2) | First layer:51.2 Second layer:102.4 Third layer:198.4 Fourth layer:294.4 Fifth layer:390.4 Sixth layer:486.4 | {0.5,1,1,2} {0.5,0.333,1,1,2,3} {0.5,0.333,1,1,2,3} {0.5,0.333,1,1,2,3} {0.5,1,1,2} {0.5,1,1,2} | 30 |
| YOLOv3 (DarkNet53) | {[14.96,13], [27.04,17], [21.1,32.06], [39.94,23.96], [38.1,51], [64.10,32.06], [80.08,52.02], [128,82.02], [291.02,142.04]} | 9 | |
| Hyper-Parameters | Faster RCNN (VGG-16) | Faster RCNN (ResNet-101) | R-FCN (ResNet-101) | SSD (InceptionV2) | YOLOv3 (Darknet53) |
|---|---|---|---|---|---|
| Steps | 100 k | 100 k | 100 k | 150 k | 150 k |
| Initial learning rate | 0.01 | 0.001 | 0.001 | 0.004 | 0.001 |
| Batch size | 1 | 1 | 1 | 4 | 4 |
| Momentum | 0.9 | 0.9 | 0.9 | 0.9 | 0.9 |
| IoU threshold | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 |
| Method | Car | Person | Sign | Line | mAP | Speed(ms) |
|---|---|---|---|---|---|---|
| Faster RCNN (VGG-16) | 81.17 | 52.02 | 58.46 | 73.52 | 66.29 | ~58 |
| Faster RCNN (ResNet-101) | 82.56 | 58.93 | 63.59 | 77.15 | 70.56 | 31.58 |
| R-FCN (ResNet-101) | 81.22 | 55.46 | 61.96 | 74.79 | 68.36 | 25.41 |
| SSD (InceptionV2) | 77.36 | 48.96 | 51.82 | 69.00 | 61.79 | 16.38 |
| YOLOv3 (Darknet53) | 83.60 | 65.06 | 61.53 | 77.13 | 71.83 | ~13 |
| Training | Test | Vehicle (AP) | Pedestrian (AP) |
|---|---|---|---|
| COCO | Pano-RSOD | 40.75 | 28.92 |
| KITTI | Pano-RSOD | 62.18 | 47.53 |
| Pano-RSOD | KITTI | 64.46 | 39.25 |
| Pano-RSOD | UA-DETRAC | 57.21 | - |
| Pano-RSOD | Pano-RSOD | 83.60 | 65.06 |
| Method | Faster RCNN (VGG-16) | Faster RCNN (ResNet-101) | R-FCN (ResNet-101) | SSD (InceptionV2) | YOLOv3 (Darknet53) |
|---|---|---|---|---|---|
| AP@0.5:0.95 | 35.70 | 38.80 | 37.00 | 26.10 | 29.48 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Tong, G.; Gao, H.; Wang, Y.; Zhang, L.; Chen, H. Pano-RSOD: A Dataset and Benchmark for Panoramic Road Scene Object Detection. Electronics 2019, 8, 329. https://doi.org/10.3390/electronics8030329
Li Y, Tong G, Gao H, Wang Y, Zhang L, Chen H. Pano-RSOD: A Dataset and Benchmark for Panoramic Road Scene Object Detection. Electronics. 2019; 8(3):329. https://doi.org/10.3390/electronics8030329
Chicago/Turabian StyleLi, Yong, Guofeng Tong, Huashuai Gao, Yuebin Wang, Liqiang Zhang, and Huairong Chen. 2019. "Pano-RSOD: A Dataset and Benchmark for Panoramic Road Scene Object Detection" Electronics 8, no. 3: 329. https://doi.org/10.3390/electronics8030329
APA StyleLi, Y., Tong, G., Gao, H., Wang, Y., Zhang, L., & Chen, H. (2019). Pano-RSOD: A Dataset and Benchmark for Panoramic Road Scene Object Detection. Electronics, 8(3), 329. https://doi.org/10.3390/electronics8030329