1. Introduction
Since the emergence of image face verification and recognition, especially in recent years, the cost of image acquisition has been greatly reduced with the development of multi-media technology. Video face verification and recognition have been important research directions in the field of computer vision and pattern recognition. It is not only an absolute premise in human social life, but an important verification basis for realizing human–computer interaction. Moreover, it has rich application requirements, so it is a research field with practical significance and commercial value.
The common application scenario of video face verification can be roughly divided into the following aspects:
Security verification based on human–computer interactions. The development of artificial intelligence liberates human labor to a greater extent, and the security of a human–computer interaction must rely on the restriction of authority. As a basic yet complex biological characteristic of human beings, the face is the most convenient feature that is difficult to fabricate.
Identification and authentication. In social activities, such as working or gathering, attendance or check-in is essential. Facial features meet the needs of identification and authentication, which show excellent performance compared with other biological characteristics.
Entertainment interaction. In recent years, the development of image modeling and rendering technology has made the pictures and colors in films, television and games more colorful and cooler. As for face and expression recognition, face verification and recognition technology will be the research foundation. It brings high-level semantic information for video scenes or content analysis.
As basic biological features, facial features are more difficult to fabricate than fingerprint features and palm print features. These kinds of samples are easier to collect compared with wrist vein features, iris recognition and other technologies. They have become the most valuable subject and technology in biological characteristics’ recognition.
In recent years, the development of convolutional neural networks (CNNs) [
1,
2] has greatly promoted the development of computer vision, which pushed the face verification and recognition of static images into an upsurge [
3]. However, the research work of video face recognition and verification is still in the early stage [
4], which can be seen from the benchmark evaluation indexes of COX [
5] and LFW [
6]. COX is a video database, while LFW is a static image database.
2. Related Work
The research methods of face verification and recognition can be divided into two categories: the face description methods based on key points and the methods based on global statistics. The methods based on key points are mainly dependent on facial landmark detection [
7], and the features are selected by hand. These methods extract personalized features of each person’s face by key points [
8]. They belong to early facial recognition methods which simulate the human face description process.
The personalized information of these methods comes from specific geometric structure. The local image blocks of the same person’s nose have high similarity. The local images of the same key points of different persons have substantial divergence, and this personalized information can be used by the classifier to identify different categories. The disadvantages of these methods, including the accurate detection of the key points, are not so easy to fix; geometric characteristics are hard to remove in the situation of obscured or morphological changed, especially as the influence caused by these factors makes the individual differences between people more confused. What is more, the simple geometric features are insufficient to describe a facial image, while other useful original information of the image will be ignored.
The global statistical methods are based on classical statistical analysis techniques; they ignore the key points of the face (the center of the eyes, nostrils, mouth, etc.). Facial images can be treated as an ensemble and can be converted into feature vectors which are easier to process by a nonlinear transform, affine transform or linear subspace transform. Most advanced facial verification and recognition methods are based on static images, as even convolutional neural networks all belong to this category.
Li et al. [
9] were inspired by the success of the probabilistic elastic part (PEP) model [
10] and deep hierarchical structure in many visual tasks [
11]. They proposed a hierarchical-PEP model to solve unconstrained face recognition. The PEP model is a mixed model which is composed of local block models of key points in facial images. The PEP model with hierarchical structure is used to divide face images into local blocks of key points with different details. The model’s information is collected from the region near the key points of the face, which ignores the location of the key points. Thus, the facial representation, which is robust to expression, posture and angle, can be obtained.
Yu et al. [
12] proposed a video-based facial representation method based on joint manifold analysis. The multi-manifold model uses two manifolds to describe a segment of video: the manifold between-class and the manifold within-class. The manifold between-class contains each video’s average face information, which describes the difference and relations between image sets. While the manifold within-class contains all the information of the image sets, and the similarities and differences or relations between all the image sets.
The main advantage of the global statistical method is that it eliminates the work-load caused by manual selection. This kind of methods will be relatively portable and have low complexity. The disadvantage is that such methods often require large-scale computational consumption and have certain performance requirements for experimental equipment. Moreover, from the perspective of performance, they are sensitive to changes of light, direction and facial expressions.
Deep learning has received increasing interest in facial recognition recently, and a number of video facial recognition methods based on deep learning have been proposed. Guo et al. [
13] reviewed major deep learning concepts pertinent to face image analysis and facial recognition, and provided a concise overview of studies on specific facial recognition problems, including pose, age, illumination, expression and heterogeneous face matching. And a summary of databases used for deep facial recognition was given as well. But deep learning methods require massive numbers of calculations both in training and testing phases, which restrict their use in real environments.
Above all, in order to reduce the calculation requirements of the training and the testing phases of video facial recognition methods, based on a global statistical method and a deep learning network, a facial verification algorithm based on local texture features and the 3D Siamese convolutional neural network is proposed in this paper.
3. The Proposed Algorithm
3.1. 3D Face Calibration
DeepFace is an important research achievement proposed by Taigman Y et al. in 2014 [
3], which achieved 97.35% accuracy in LFW database. It pushed the performance of facial recognition equivalent of human level by artificial intelligence method for the first time. Their work includes two major contributions: 3D face alignment and the DeepFace network. The subsequent face verification in this paper is based on the 3D face calibrated image, which provides rich positive face information for facial recognition.
Due to the nonplanar characteristics of human face, 3D shape modeling and affine transformation are required for rotation transform. A general 3D shape model and 3D affine camera model are used to paste the 2D alignment images onto the surface of the stereo model, and a 3D shape model can be created as shown in
Figure 1. The algorithm can also be used to rotate a face to any angle, such as the non-original angle transformation shown in
Figure 1h.
3.2. Texture Feature Extraction
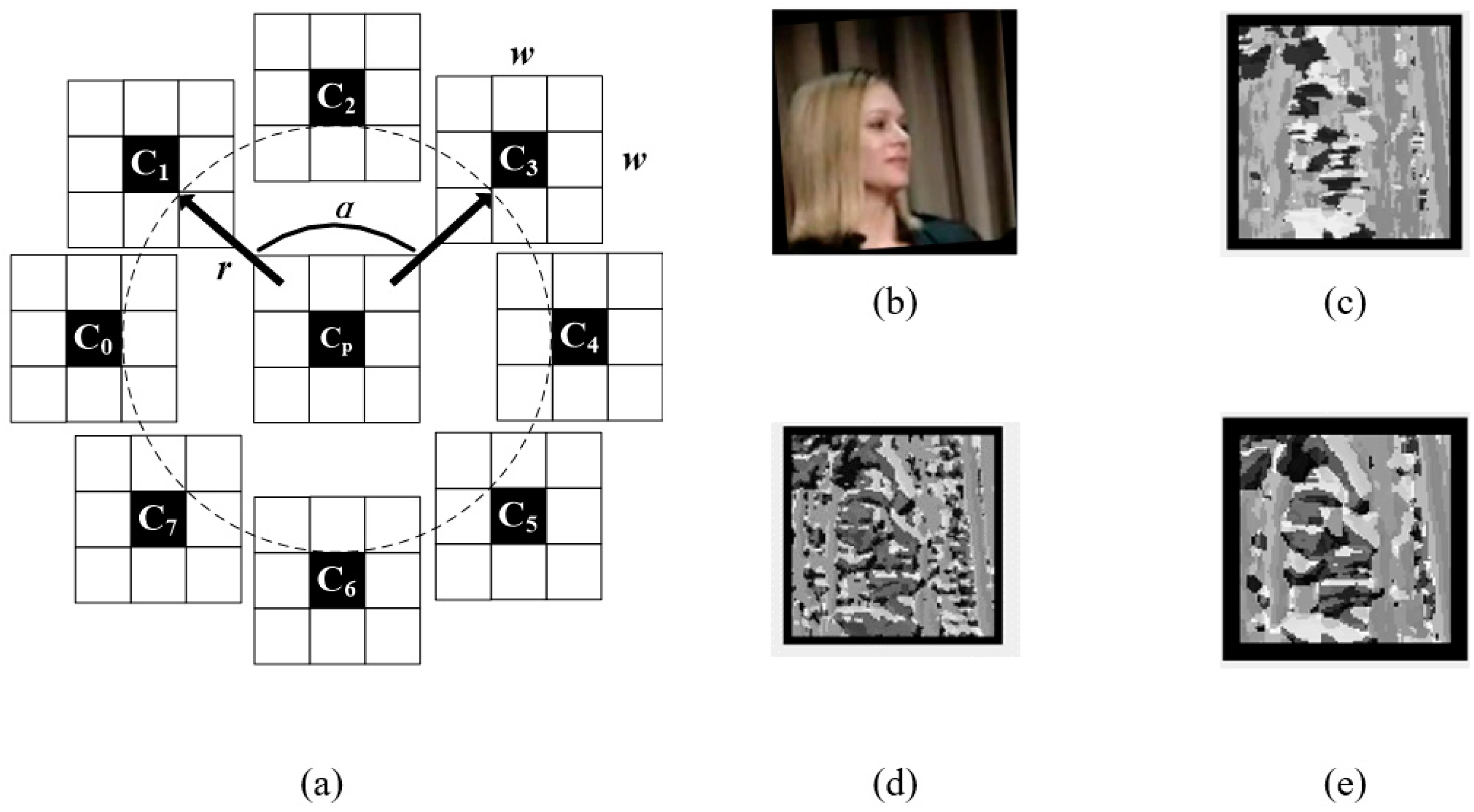
A three-patch local binary pattern (TPLBP) [
14] is a binary code composed by three LBP blocks, which can catch wider vision than LBP. TPLBP uses the relation of LBP codes from center patch and two local, neighboring (but not adjacent) patches to describe the textural information near the center pixel.
As shown in
Figure 2, for each pixel
Cp in the image, we consider a
w ×
w patch centered on the pixel, and
S additional patches distributed uniformly in a circle with pixel
Cp as the center and
r as the radius; and the center of the
i-th patch is
Ci (i = 0, 1, 2...,
N − 1).
Assuming that
Ci and
Cp are selected, LBP(
Ci) represents the LBP code of
Ci, and
s() is the binarization function.
where, the binarization function
s() is defined as Equation(3). The value of τ can be set slightly larger than zero (e.g., τ = 0.01) to provide some stability in uniform regions.
3.3. The Proposed 3D Siamese Structure
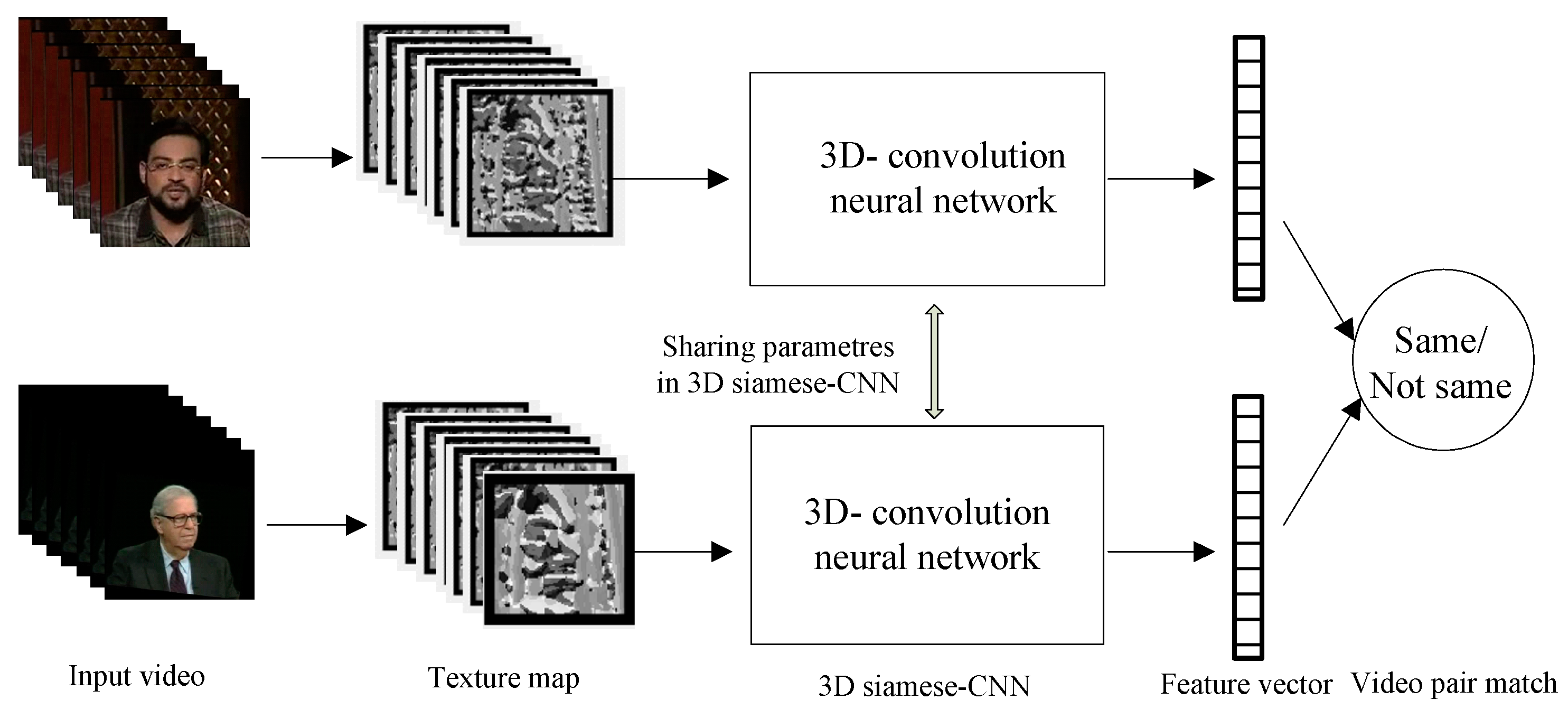
We proposed a video face verification algorithm based on TPLBP feature and Siamese-CNN in this paper. In order to reduce the excessive computational consumption of the equipment and platform, this algorithm takes the local texture feature TPLBP, as the input of the network. It aims to extract the inter-frame information of the video; the textural features maps of the multi-frames are stacked; and then, a shallow Siamese 3D convolutional network is used to realize feature reduction. The similarities of high-level features of the video pair are solved by the shallow Siamese 3D convolutional network. Each similarity is mapped to the interval of 0 to 1 by linear transformation, and the classification result can be obtained with the threshold of 0.5.
The Siamese structure is proposed to verify the digital signature. It consists of two branches, which share the same structure parameters. This structure is used to realize feature extraction and enrichment, and is then followed by a similarity measurement, usually in the form of Euclidean distance. Therefore, the Siamese structure should learn a mapping function from sample space to the Euclidean space. After mapping the sample to Euclidean space, L1 distance or Euclidean distance is used to measure the similarity. Finally, similarity score is used to realize the recognition of the sample.
In order to reduce the scale of the model, a sub-branch network based on CNN is used to realize feature extraction. The sub-branch network of Siamese-CNN consists of input layer, batch normalization layer (BN), convolution layer (CONV), activation layer (ReLU), pooling layer and fully connection layer (FC). The schematic diagram of network structure is shown in
Figure 3.
The design of the feature extraction sub-network uses a convolution neural network. In order to capture inter-frame information, 2D convolution operation is replaced by a 3D convolution operation here. The specific structure is described as follows:
- (1)
In order to keep enough discriminative information and reduce the computational consumption of the proposed model, the input videos are normalized to 7 × 128 × 128. The texture information is calculated from the input video frames, and the size of texture map is consistent with the original frames.
- (2)
Convolution the texture maps with two 3D convolution layers (BN and ReLU activation are used) with eight kernels of sizes 2 × 7 × 7 in the first convolution layers and 32 kernels of size 2 × 5 × 5 in the second convolution layer. This layer used zero padding to ensure that the network retains as much information as possible at the shallow level on the basis of ensuring no large loss of scale, especially inter-frame information. Following the convolution layer, a 1 × 2 × 2 mean pooling layer is applied for sampling.
- (3)
Three 3D convolution layers—BN, ReLU activation and a mean pooling layer, are adopted. The sizes of convolution kernel are 2 × 3 × 3, with 128 channels, 256 channels and 512 channels respectively. The step sizes of mean pooling layers are 1 × 2 × 2, 1 × 2 × 2 and 3 × 4 × 4 respectively. There is no zero padding operation in this layer, so that gradually eliminates background elements irrelevant to character information around the face. The size of the feature map is reduced to 3 × 3 through these convolution layers.
- (4)
Flatten the feature map into the feature vectors. Using the two branches of one-dimensional feature vectors, DropOut [
15] with a ratio 0.5, probability weighting is conducted to obtain deep 4608-dimension features. The classification results are obtained by connecting the L1 distance of two eigenvectors of double branches and then using a full connection layer containing only one neuron:
where
f1 and
f2 are the output features of the two branch networks, and
is the
i-th feature value of the feature vector of sample 1;
is the parameter to be trained.
The structure of feature extraction sub-branch network is shown in
Table 1, while
Table 2 shows the information of Siamese network. The 3D Siamese-CNN consists of two input layers, two sub-branch networks, a connecting layer (a lambda layer) and a full connecting layer (a dense layer). For example, the sequence contains two sources, input_1 and input_2, representing two different layers’ (feature extraction sub-branch networks) sharing parameters, but with double the computation consumption.
4. Experiment and Analysis
4.1. Database and Preprocessing
The YouTube Face video database was proposed by Loir Wolf et al. in 2011; all the videos come from online social networking sites. After calibration, it contains a total of 3425 video segments, including 1595 characters and 2.15 image sets per person. To ensure enough information from the captured image set, the shortest duration of video is 48 frames and the longest is 6070 frames; the frame length is 181.3 for each video on average.
Compared with other video databases such as Honda and Yale, the source of YTF is the network. On the one hand, different shooting scenes and environments determine the rich change of video background and illumination, which includes a large number of out-of-focus and motion blur obstacles caused by non-professional photographers and equipment. These factors will inevitably bring great challenges to the performance of the video facial recognition algorithm. On the other hand, this database is more alike the actual usage scenarios, and can better simulate the real scenarios. Finally, the number of the videos is large enough.
To facilitate a comparison with other algorithms, we adopted standard, ten-fold, cross validation, pair-matching tests in the experiment, and the YTF subset calibrated by 3D align was used in this paper. The subset of the data set contains 1963 video segments, belonging to 920 different characters, and each character contains 0.13 segments on average. As shown in
Table 3, all of the samples are divided into positive and negative. The selection of a positive sample is divided into from the same video or from different videos (belongs to same character). The positive samples from the same video have their first seven frames from the beginning and last seven frames from the end of their videos selected. The positive samples from different videos have the first seven frames from the combination of all the videos belongs to the same character selected. The selection of negative samples is generated from a random combination of videos, and 8676 positive and negative samples are selected in total.
The number of parameters in the proposed network is 104, according to the experience. Five to ten rounds of training sets are required; that is, the size of training sets should be around 105. Since the negative sample comes from random combinations of characters, and the dataset contains 90 different characters, enough to produce 50,000 combinations of characters. However, the sources of positive samples are limited, so we rotated and cropped the video frames to obtain a larger number of positive samples to train the proposed network.
4.2. Experiment Environment and Configuration
Feature analysis and data preprocessing were implemented in Matlab R2014b under the Windows 7 platform. LibSVM 3.23 was selected as the implementation of support vector machine used in feature analysis [
16]. The processor of the hardware platform was Intel(R) Core (TM) i7-4791 CPU, 3.60GHz, with 4GB of memory. The dataset generation, training, testing and tuning of the network was implemented on ubuntu 5.4.0-6 server platform.
The construction, training and testing of the network was implemented by Python 3.5.2+ keras 2.1.5 + tensorflow 1.9.0 [
17,
18]. Jupyter notebook 5.4.1 + IPython 6.3.1 and pycharm 2017.2.4 were used as development tools, and MobaXterm 10.9 was used to realize remote control of the server. The hardware platform included two NVIDIA 1080Ti, and the driver version of graphics card was NVIDIA UNIX x86_64 Kernel Module 390.87.
4.3. Model Analysis and Comparison
The parameters and floating point operations (FLOPs) of the model are the main measures of model’s scale. The parameters refer to the total number of weights which the network contains, and FLOPs count the number of floating calculation times needed to perform a forward propagation.
The 3D convolution layer used in this paper is implemented by a sliding window, so the FLOPs are:
where
H,
W and
T refer to video size (length, width and frame numbers);
Cin and
Cout refer to the number of channels related to the input and output; and
K refers to the width of convolution kernel. The computation of FLOPs at the full connection layer is:
where
I and
O are the numbers of input and output neurons, which are the dimensions [
19]. Since no parameters are generated in the pooling layer, the parameters of the pooling layer are 0. However, floating calculation is still needed for the pooling layer, which is implemented by a sliding window similar to convolution. Therefore, the FLOPs of the pooling layer are similar to the convolution layer:
Table 4 and
Table 5 are the scale details of the proposed model, and the calculation of parameters and floating operation refer to the calculation mode above.
Table 6 shows the scale of the models which is commonly used in face verification and recognition in recent years. As can be seen from the table, the number of parameters is about one hundred times smaller when the floating calculation is not greatly increased in the proposed model, which reduces the difficulty of training and the requirement of computational consumption of test platform.
4.4. Experiment Results and Analysis
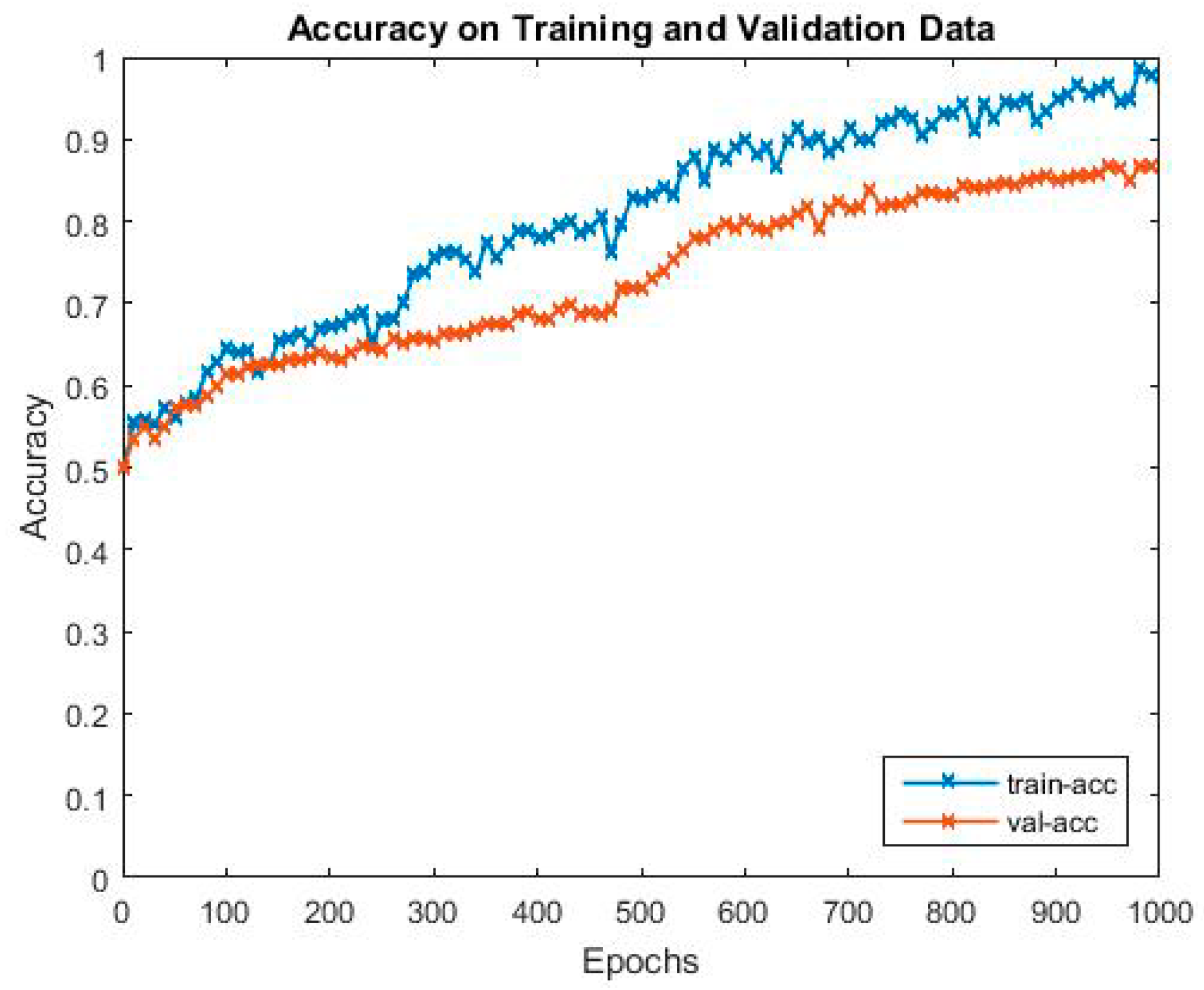
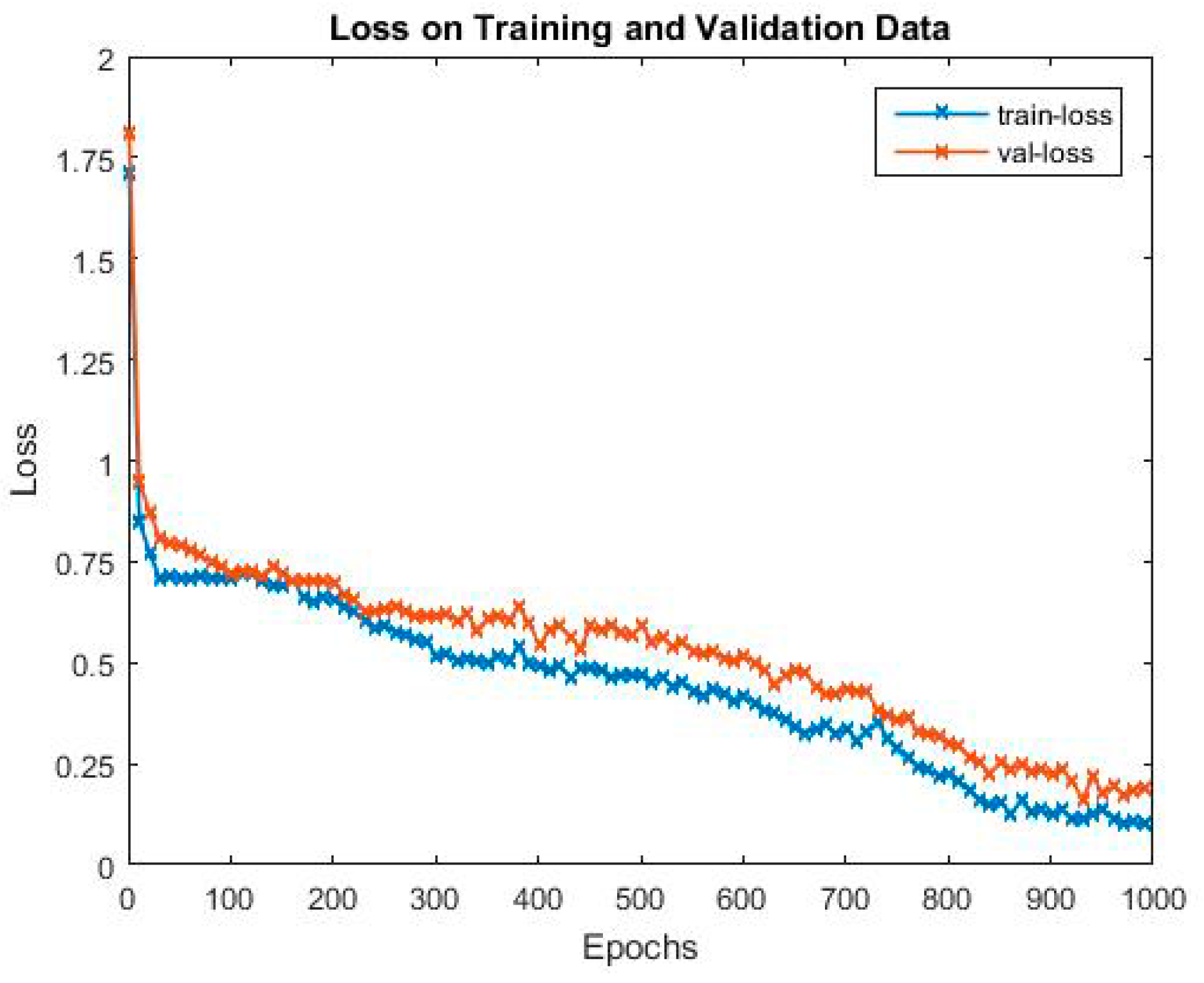
Figure 4 and
Figure 5 show the curve of accuracy and loss of the proposed model. As can be seen from the figures, in the early stage of training and validating, when the loss drops sharply, the accuracy gradually climbs up to around 0.6, and gradually converges to 0.83 around when the loss drops sharply for the second time. The first sharp drop of the loss function in the first 50 iterations indicates that the initial value of the learning rate is accurately selected. In the first bottleneck near 290 iterations, there is no obvious rebound and the decline trend is maintained, which indicates that the attenuation strategy of the learning rate is reasonable.
Table 7 shows the comparison with the baseline on the YouTube Face database; the proposed algorithm gets higher accuracy than other algorithms, indicating that the proposed algorithm is effective and feasible. The proposed model lacks enough stability, which may be caused by the information loss, while the scale of the sub-branch network is too large for some samples.
5. Conclusions
Video facial recognition based on deep learning method needs a high capacity platform, especially in the training phase. To solve this problem, a novel face verification algorithm based on TPLBP and 3D Siamese convolutional neural network is proposed in this paper. The proposed algorithm applied TPLBP on the input video frames, and used the TPLBP texture feature maps as the input of the network. Then, a shallow Siamese 3D convolutional network is used to realize feature reduction. The similarity of high-level features of the video pair is solved by the shallow 3D Siamese convolutional network. Through the analysis and comparison of different models, the proposed algorithm was shown to have less FLOPs than GoogLeNet, AlexNet and VGG. As illustrated in the video facial verification experiment on the YouTube Face database, the proposed algorithm gets higher accuracy with less computational consumption. Our future work will focus on how to improve the stability of the proposed model.
Author Contributions
Conceptualization, methodology, and writing—review and editing, Y.W.; validation and formal analysis, S.M.; supervision, project administration, and funding acquisition, X.S.
Funding
This research was funded by the National Natural Science Foundation of China (61876070), Key Projects of Jilin Province Science and Technology Development Plan (20180201064SF), Outstanding Young Talent Foundation of Jilin Province (20180520020JH) and a subproject of the National Key and Development Plan (2018YFC0830103).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems-Volume 1, NIPS’12, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Kumar, A.; Chellappa, R. Disentangling 3D Pose in A Dendritic CNN for Unconstrained 2D Face Alignment. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 430–439. [Google Scholar]
- Taigman, Y.; Ming, Y.; Ranzato, M.; Wolf, L. DeepFace: Closing the Gap to Human-Level Performance in Face Verification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, IEEE Computer Society, CVPR’14, Washington, DC, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Best-Rowden, L.; Klare, B.; Klontz, J.; Jain, A.K. Video-to-video face matching: Establishing a baseline for unconstrained face recognition. In Proceedings of the 2013 IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 29 September–2 October 2013; pp. 1–8. [Google Scholar]
- Huang, Z.; Shan, S.; Wang, R.; Haihong, Z.; Shihong, L.; Alifu, K.; Xilin, C. A Benchmark and Comparative Study of Video-Based Face Recognition on COX Face Database. IEEE Trans. Image Process. 2015, 24, 5967–5981. [Google Scholar] [CrossRef] [PubMed]
- Learned-Miller, E.; Huang, G.B.; Roychowdhury, A.; Li, H.; Hua, G. Labeled Faces in the Wild: A Survey. In Advances in Face Detection and Facial Image Analysis; Springer International Publishing: Cham, Switzerland, 2016; pp. 189–248. [Google Scholar]
- Wu, Y.; Hassner, T.; Kim, K.; Medioni, G.; Natarajan, P. Facial landmark detection with tweaked convolutional neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 3067–3074. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Yang, J.; Qian, J. Recurrent Neural Network for Facial Landmark Detection. Neurocomputing 2016, 219, 26–38. [Google Scholar] [CrossRef]
- Li, H.; Hua, G. Hierarchical-PEP model for real-world face recognition. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE Computer Society, Boston, MA, USA, 7–12 June 2015; pp. 4055–4064. [Google Scholar]
- Li, H.; Hua, G.; Lin, Z.; Brandt, J.; Yang, J. Probabilistic Elastic Matching for Pose Variant Face Verification. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, IEEE Computer Society, CVPR’13, Washington, DC, USA, 23–28 June 2013; pp. 3499–3506. [Google Scholar]
- Li, H.; Hua, G.; Shen, X.; Lin, Z.; Brandt, J. Eigen-PEP for Video Face Recognition.in Asian Conference on Computer Vision. ACCV 2014, 17–33. [Google Scholar] [CrossRef]
- Yu, Q.; Gao, Y.; Huo, J.; Zhuang, Y.K. Discriminative joint multi-manifold analysis for video-based face recognition. Ruan Jian Xue Bao/J. Softw. 2015, 26, 2897–2911. (In Chinese) [Google Scholar]
- Guo, G.; Zhang, N. A survey on deep learning based face recognition. Comput. Vis. Image Underst. 2019, 189, 102805. [Google Scholar] [CrossRef]
- Wolf, L.; Hassner, T.; Taigman, Y. Descriptor Based Methods in the Wild. In Post ECCV Workshop on Faces in ‘Real-Life’ Images: Detection, Alignment, and Recognition; Erik Learned-Miller and Andras Ferencz and Frédéric Jurie: Marseille, France, 2008; pp. 121–128. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 27. [Google Scholar] [CrossRef]
- Seo, B.; Shin, M.; Mo, Y.J.; Kim, J. Top-down parsing for Neural Network Exchange Format (NNEF) in TensorFlow-based deep learning computation. In Proceedings of the 2018 International Conference on Information Networking (ICOIN, Chiang Mai, Thailand, 10–12 January 2018; pp. 522–524. [Google Scholar]
- Zeng, Z.; Gong, Q.; Zhang, J. CNN Model Design of Gesture Recognition Based on Tensorflow Framework. In Proceedings of the 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019; pp. 1062–1067. [Google Scholar]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G. Temporal Convolutional Networks for Action Segmentation and Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1003–1012. [Google Scholar]
- Wang, Y.; Shen, X.J.; Chen, H.P. Video Face Recognition Based on the Convex Hull Model of Kernel Subspace Sample Selection. J. Comput. Theor. Nanosci. 2016, 13, 1436–1441. [Google Scholar] [CrossRef]
- Wolf, L.; Hassner, T.; Maoz, I. Face recognition in unconstrained videos with matched background similarity. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 529–534. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}