A Feature Integrated Saliency Estimation Model for Omnidirectional Immersive Images


Abstract
1. Introduction
- We primarily focus on the geometry-based features of an image. It has been observed in many studies that the geometry of the physical world helps in visual perception of a scene [19,20]. Taking this into consideration, we extract a set of image features that depicts the geometry of an image stimuli. In addition, artifacts caused by spherical projections of a 360° image are taken into account;
- the image foreground is considered as a feature. Human perception is highly influenced by objects located in the foreground regions [9]. Therefore, we perform a foreground/background separation. To the best of our knowledge this is the first approach that exploits image foreground as a feature for saliency estimation of omnidirectional images.
2. Proposed Methodology
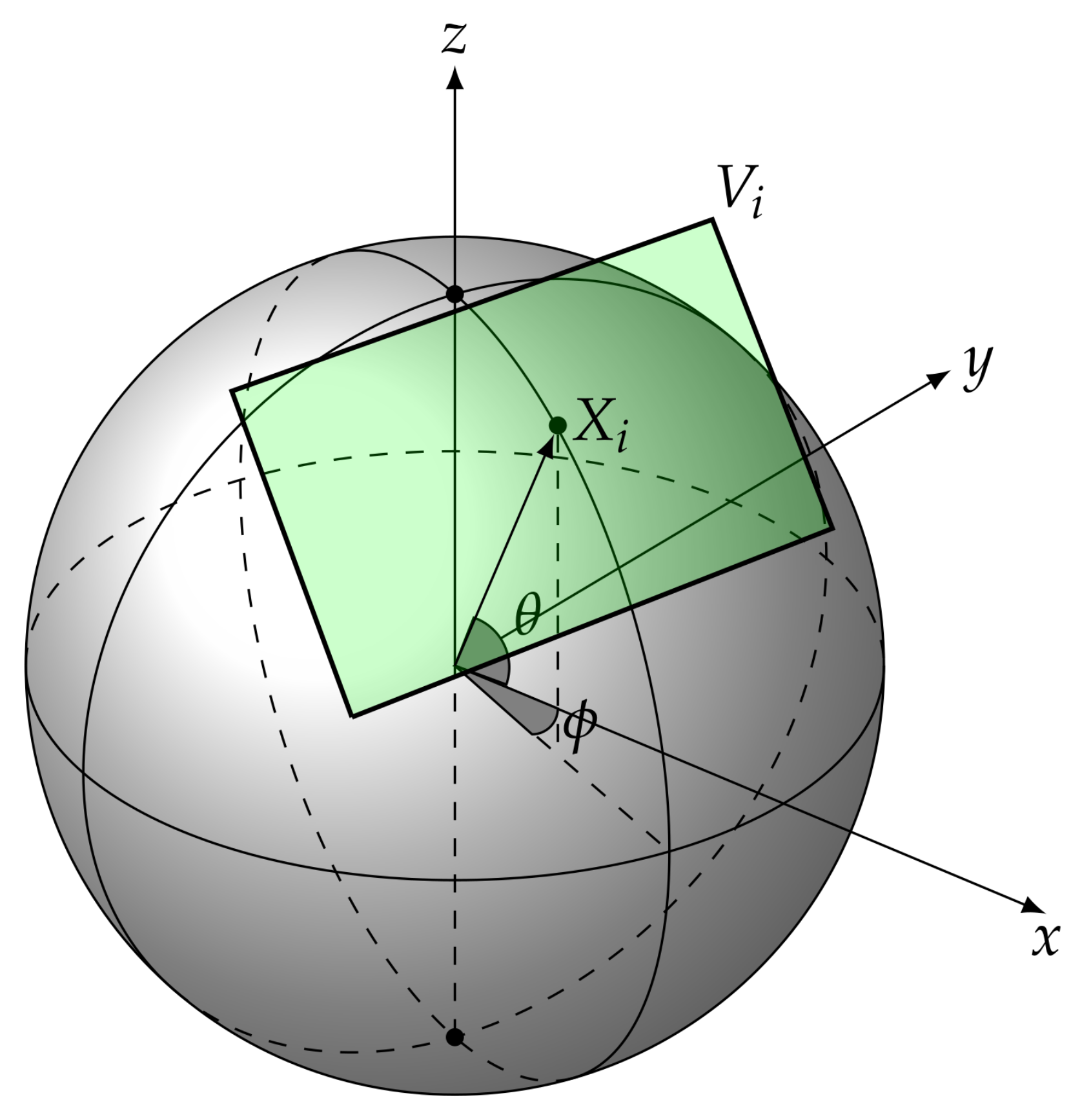
2.1. Viewport Extraction
2.2. Illumination Normalization
| Algorithm 1: HDWT: Illumination Normalization |
 |
2.3. Feature Extraction
- Color (), Intensity () and Contrast (): first we convert the RGB viewport () into the CIE color space to find the three components: Lightness (L), color weight between green and red channels (a) and color weight between blue and yellow channels (b). We compute as the average value of the L, a and b componentsThe viewport image intensity map is generated in two steps. First, the highest pixel value along the three components L, a and b is considered for generating a preliminary intensity map . Second, Prewitt gradient operator is used to generate the gradient map of the intensity imageVariation in image contrast affects human visual perception [27]. We accounted for this aspect by using as feature a gray level map obtained from a contrast enhanced version of the viewport . The contrast enhancement is performed by saturating the bottom and the top 30% of all pixel values:where and are the smallest and the largest pixel values in , and and are, respectively, the of and the of .
- Edge (): The Canny edge detector [28] is adopted for identifying the horizontal and vertical edges in an image
- Corner (): Corners are regions in which we observe a very high variation in intensity in all directions. Therefore we apply the Harris corner detector [29] which is robust to illumination, rotation, and translation.
- Ridge (): As multiple objects reside in an image scene, ridge ending and bifurcations (Figure 5) can be a significant feature source for saliency estimation since they allow to detect points in the image when a change happens. In this work we adopt the ridge extraction technique proposed in [30]. The viewport image is first binarized and subsequently, a morphology-based thinning operation is performed.
2.4. Foreground Extraction
- Superpixels with large values in the foreground map are salient;
- superpixels with large values in the background map are non-salient;
- superpixels that are similar and adjacent should have the same saliency values.
2.5. Feature Integration
2.6. Post-Processing
3. Experimental Results
Experimental Results and Analysis
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Itti, L. Automatic foveation for video compression using a neurobiological model of visual attention. IEEE Trans. Image Process. 2004, 13, 1304–1318. [Google Scholar] [CrossRef] [PubMed]
- Yamada, Y.; Kobayashi, M. Detecting mental fatigue from eye-tracking data gathered while watching video: Evaluation in younger and older adults. Artif. Intell. Med. 2018, 91, 39–48. [Google Scholar] [CrossRef] [PubMed]
- Castronovo, A.M.; De Marchis, C.; Bibbo, D.; Conforto, S.; Schmid, M.; D’Alessio, T. Neuromuscular adaptations during submaximal prolonged cycling. In Proceedings of the International Conference of the IEEE Engineering in Medicine and Biology Society, San Diego, CA, USA, 28 August–1 September 2012; pp. 3612–3615. [Google Scholar]
- Proto, A.; Fida, B.; Bernabucci, I.; Bibbo, D.; Conforto, S.; Schmid, M.; Vlach, K.; Kasik, V.; Penhaker, M. Wearable PVDF transducer for biomechanical energy harvesting and gait cycle detection. In Proceedings of the EMBS Conference on Biomedical Engineering and Sciences, Kuala Lumpur, Malaysia, 4–8 December 2016; pp. 62–66. [Google Scholar]
- Chang, T.; Hsu, M.; Hu, G.; Lin, K. Salient corporate performance forecasting based on financial and textual information. In Proceedings of the International Conference on Systems, Man, and Cybernetics, Budapest, Hungary, 9–12 October 2016; pp. 959–964. [Google Scholar]
- Itti, L.; Koch, C.; Niebur, E. A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 1254–1259. [Google Scholar] [CrossRef]
- Harel, J.; Koch, C.; Perona, P. Graph-based visual saliency. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2007; pp. 545–552. [Google Scholar]
- Rubin, E. Figure and ground. In Readings in Perception; Beardslee, D.C., Werthimer, M., Eds.; D. van Nostrand: Princeton, NJ, USA, 1958. [Google Scholar]
- Mazza, V.; Turatto, M.; Umilta, C. Foreground–background segmentation and attention: A change blindness study. Psychol. Res. 2005, 69, 201–210. [Google Scholar] [CrossRef]
- Zhang, J.; Sclaroff, S. Saliency detection: A boolean map approach. In Proceedings of the International Conference on Computer Vision, Coimbatore, India, 20–21 December 2013; pp. 153–160. [Google Scholar]
- Zhang, J.; Sclaroff, S. Exploiting surroundedness for saliency detection: A Boolean map approach. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 889–902. [Google Scholar] [CrossRef]
- Fang, Y.; Zhang, X.; Imamoglu, N. A novel superpixel-based saliency detection model for 360-degree images. Signal Process. Image Commun. 2018, 69, 1–7. [Google Scholar] [CrossRef]
- Biswas, S.; Fezza, S.A.; Larabi, M. Towards light-compensated saliency prediction for omnidirectional images. In Proceedings of the IEEE International Conference on Image Processing Theory, Tools and Applications, Montreal, QC, Canada, 28 November–1 December 2017; pp. 1–6. [Google Scholar]
- Battisti, F.; Baldoni, S.; Brizzi, M.; Carli, M. A feature-based approach for saliency estimation of omni-directional images. Signal Process. Image Commun. 2018, 69, 53–59. [Google Scholar] [CrossRef]
- Mazumdar, P.; Battisti, F. A Content-Based Approach for Saliency Estimation in 360 Images. In Proceedings of the IEEE International Conference on Image Processing, Guangzhou, China, 10–13 May 2019; pp. 3197–3201. [Google Scholar]
- Zhu, Y.; Zhai, G.; Min, X. The prediction of head and eye movement for 360 degree images. Signal Process. Image Commun. 2018, 69, 15–25. [Google Scholar] [CrossRef]
- Startsev, M.; Dorr, M. 360-aware saliency estimation with conventional image saliency predictors. Signal Process. Image Commun. 2018, 69, 43–52. [Google Scholar] [CrossRef]
- Ardouin, J.; Lécuyer, A.; Marchal, M.; Marchand, E. Stereoscopic rendering of virtual environments with wide Field-of-Views up to 360. In Proceedings of the IEEE International Symposium on Virtual Reality, Shenyang, China, 30–31 August 2014; pp. 3–8. [Google Scholar]
- Ogmen, H.; Herzog, M.H. The geometry of visual perception: Retinotopic and nonretinotopic representations in the human visual system. Proc. IEEE 2010, 98, 479–492. [Google Scholar] [CrossRef]
- Assadi, A.H. Perceptual geometry of space and form: Visual perception of natural scenes and their virtual representation. In Vision Geometry X; International Society for Optics and Photonics: Bellingham, WA, USA, 2001; Volume 4476, pp. 59–72. [Google Scholar]
- Aiba, T.; Stevens, S. Relation of brightness to duration and luminance under light-and dark-adaptation. Vis. Res. 1964, 4, 391–401. [Google Scholar] [CrossRef]
- Purves, D.; Williams, S.M.; Nundy, S.; Lotto, R.B. Perceiving the intensity of light. Psychol. Rev. 2004, 111, 142. [Google Scholar] [CrossRef] [PubMed]
- Van de Weijer, J.; Gevers, T.; Bagdanov, A.D. Boosting color saliency in image feature detection. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 28, 150–156. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Xu, M.; Zhang, S.; Le Callet, P. State-of-the-art in 360° Video/Image Processing: Perception, Assessment and Compression. arXiv 2019, arXiv:1905.00161. [Google Scholar]
- Ye, Y.; Alshina, E.; Boyce, J. Algorithm descriptions of projection format conversion and video quality metrics in 360Lib (Version 5). In Proceedings of the Joint Video Exploration Team of ITU-T SG16 WP3 and ISO/IEC JTC1/SC29/WG11, JVET-H1004, Geneva, Switzerland, 12–20 January 2017. [Google Scholar]
- Kim, Y.T. Contrast enhancement using brightness preserving bi-histogram equalization. IEEE Trans. Consum. Electron. 1997, 43, 1–8. [Google Scholar]
- Ma, Y.F.; Zhang, H.J. Contrast-based image attention analysis by using fuzzy growing. In Proceedings of the ACM International Conference on Multimedia, Berkeley, CA, USA, 2–8 November 2003; pp. 374–381. [Google Scholar]
- John, C. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 679–698. [Google Scholar]
- Harris, C.G.; Stephens, M. A combined corner and edge detector. In Proceedings of the Alvey Vision Conference, Manchester, UK, 31 August–2 September 1988; Volume 15, pp. 10–5244. [Google Scholar]
- Bhargava, N.; Bhargava, R.; Mathuria, M.; Cotia, M. Fingerprint matching using ridge-end and bifurcation points. In Proceedings of the International Conference on Recent Trends in Information Technology and Computer Science (IJCA), Mumbai, India, 17–18 December 2012; pp. 1–12. [Google Scholar]
- Hong, L.; Wan, Y.; Jain, A. Fingerprint image enhancement: Algorithm and performance evaluation. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 777–789. [Google Scholar] [CrossRef]
- Duda, R.; Hart, P. Use of the Hough Transformation to Detect Lines and Curves in Pictures. ACM Commun. 1972, 15, 11–15. [Google Scholar] [CrossRef]
- Gupta, S.; Singh, Y.J. Object detection using shape features. In Proceedings of the IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, India, 18–20 December 2014; pp. 1–4. [Google Scholar]
- Rebhi, A.; Benmhammed, I.; Abid, S.; Fnaiech, F. Fabric defect detection using local homogeneity analysis and neural network. J. Photonics 2015, 2015, 376163. [Google Scholar] [CrossRef]
- Chetverikov, D.; Hanbury, A. Finding defects in texture using regularity and local orientation. Pattern Recognit. 2002, 35, 2165–2180. [Google Scholar] [CrossRef]
- Abkenar, M.R.; Sadreazami, H.; Ahmad, M.O. Graph-Based Salient Object Detection using Background and Foreground Connectivity Cues. In Proceedings of the IEEE International Symposium on Circuits and Systems, Sapporo, Japan, 26–29 May 2019; pp. 1–5. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC superpixels compared to state-of-the-art superpixel methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Zhu, W.; Liang, S.; Wei, Y.; Sun, J. Saliency optimization from robust background detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2814–2821. [Google Scholar]
- Judd, T.; Ehinger, K.; Durand, F.; Torralba, A. Learning to predict where humans look. In Proceedings of the IEEE International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 2106–2113. [Google Scholar]
- Sitzmann, V.; Serrano, A.; Pavel, A.; Agrawala, M.; Gutierrez, D.; Masia, B.; Wetzstein, G. Saliency in VR: How Do People Explore Virtual Environments? IEEE Trans. Vis. Comput. Graph. 2018, 24, 1633–1642. [Google Scholar] [CrossRef] [PubMed]
- Perona, P.; Malik, J. Scale-space and edge detection using anisotropic diffusion. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 629–639. [Google Scholar] [CrossRef]
- Gutiérrez, J.; David, E.; Rai, Y.; Le Callet, P. Toolbox and dataset for the development of saliency and scanpath models for omnidirectional/360° still images. Signal Process. Image Commun. 2018, 69, 35–42. [Google Scholar] [CrossRef]
- Bylinskii, Z.; Judd, T.; Oliva, A.; Torralba, A.; Durand, F. What do different evaluation metrics tell us about saliency models? IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 740–757. [Google Scholar] [CrossRef]
- Azevedo, R.G.d.A.; Birkbeck, N.; De Simone, F.; Janatra, I.; Adsumilli, B.; Frossard, P. Visual Distortions in 360-Degree Videos. arXiv 2019, arXiv:1901.01848. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) Results on the test dataset. | ||||
| Model | CC↑ | KLD↓ | ||
| FISEM | 0.69 | 0.47 | ||
| SJTU [16] | 0.67 | 0.65 | ||
| COSE [15] | 0.65 | 0.72 | ||
| TU1 [17] | 0.62 | 0.75 | ||
| TU2 [17] | 0.56 | 0.64 | ||
| EBMS [11] | 0.57 | 0.8 | ||
| RM3 [14] | 0.52 | 0.81 | ||
| JU [12] | 0.57 | 1.14 | ||
| BMS [10] | 0.51 | 0.94 | ||
| LCSP [13] | 0.43 | 0.78 | ||
| TU3 [17] | 0.44 | 1.09 | ||
| (b) Best performing images. | ||||
| Metric | P28 | P76 | P95 | P85 |
| CC | 0.87 | 0.83 | 0.83 | 0.82 |
| KLD | 0.26 | 0.37 | 0.47 | 0.32 |
| Metric | P27 | P28 | P17 | P35 |
| KLD | 0.23 | 0.26 | 0.27 | 0.28 |
| CC | 0.66 | 0.87 | 0.67 | 0.77 |
| (c) Worst performing images. | ||||
| Metric | P15 | P10 | P23 | P31 |
| CC | 0.11 | 0.42 | 0.46 | 0.49 |
| KLD | 0.96 | 0.64 | 0.75 | 0.34 |
| Metric | P33 | P4 | P64 | P43 |
| KLD | 2.22 | 1.84 | 1.40 | 1.19 |
| CC | 0.67 | 0.62 | 0.6 | 0.68 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mazumdar, P.; Lamichhane, K.; Carli, M.; Battisti, F. A Feature Integrated Saliency Estimation Model for Omnidirectional Immersive Images. Electronics 2019, 8, 1538. https://doi.org/10.3390/electronics8121538
Mazumdar P, Lamichhane K, Carli M, Battisti F. A Feature Integrated Saliency Estimation Model for Omnidirectional Immersive Images. Electronics. 2019; 8(12):1538. https://doi.org/10.3390/electronics8121538
Chicago/Turabian StyleMazumdar, Pramit, Kamal Lamichhane, Marco Carli, and Federica Battisti. 2019. "A Feature Integrated Saliency Estimation Model for Omnidirectional Immersive Images" Electronics 8, no. 12: 1538. https://doi.org/10.3390/electronics8121538
APA StyleMazumdar, P., Lamichhane, K., Carli, M., & Battisti, F. (2019). A Feature Integrated Saliency Estimation Model for Omnidirectional Immersive Images. Electronics, 8(12), 1538. https://doi.org/10.3390/electronics8121538