The comparison among multi-objective optimization algorithms cannot be performed by analyzing the resulting objective function, since the output is not a single solution, but a set of efficient solutions. Therefore, it is necessary to compare the algorithms through specific metrics that evaluate the quality of a given approximation front. In this work, we considered four of the most extended multi-objective metrics [
35]: coverage, hypervolume,
-indicator, and inverted generational distance. The coverage metric,
, evaluates the proportion of solutions of the approximation front
that dominates the solutions from the front
B. In our experiments, we evaluate the quality of an approximation front
derived from the proposed algorithm as
, where
R is the front of reference (i.e., the best approximation front of the experiment, constructed by the union of all the approximation fronts of the algorithms under evaluation) in the preliminary experiments, and the optimal Pareto front in the final competitive testing. Therefore, the smaller the value of
, the better. The hypervolume (
) evaluates the volume in the objective space, which is covered by the approximation front under evaluation. Then, the larger the
value, the better the set of efficient solutions obtained by the algorithm. The
-indicator (
) measures the smallest distance needed to transform every point of the approximation front under evaluation in the closest point of the optimal Pareto front of reference. Therefore, the smaller the
-indicator, the better. Finally, the inverted generational distance (IGD+) is an inversion of the well known generational distance metric with the aim of measuring the distance from the Pareto front to the set of efficient solutions. The smaller the value of IGD+, the better. Finally, the computing time of all the algorithms is also presented, with the aim of evaluating the efficiency of the procedures.
4.1. Preliminary Experimentation
For the preliminary experiments, a subset of 30 instances with different sizes and p-values was selected. This preliminary experimentation demonstrated the improvement given by each step in the algorithm, allowing us to test the best values for the different parameters that take part in it. Specifically, we started fine tuning the parameter involved in the construction and, then, and maxNonImprove, the percentage of solution destructed and the maximum number of iterations without improvements inside iterated greedy, respectively.
The aim of the first preliminary experiment was to determine the best value for the
parameter for the constructive procedure presented in
Section 3.1. In order to explore a wide range of values, we tested
, where
RND indicates that the value is selected at random from the range
in each construction.
Table 2 shows the results derived from generating 500 solutions with each constructive procedure.
Analyzing these results,
was the best option for generating the initial solutions in all the metrics. In particular, the coverage value of 0.1187 indicated that most of the solutions of the reference front belonged to this variant. Furthermore, the hypervolume value was considerably larger than the second best variant. Analogously, the
-indicator was also the smallest one in the comparison, being considerably smaller than its competitors. Regarding the inverted generational distance,
again obtained the best results, closely followed by
. If we focus on the computational time, there were no significant differences among the different
values, but
was slightly smaller. It was expected that
would obtain the best results, since constructing with a different level of greediness in each construction allowed the algorithm to produce a more diverse set of solutions, resulting in a higher quality set of non-dominated solutions. However, when coupling a local search method to the generated solution, the best constructive procedure might not remain as the best one, and therefore, it is necessary to analyze the results of each variant when considering the local search procedure.
Table 3 presents the results obtained with the local search procedure.
As can be derived from the results, still remained as the best constructive variant, although the differences among the variants were reduced in all the metrics but IGD+, mainly due to the local optimization performed by the local search method. With respect to IGD+, coupling the local search with the best constructive led the algorithm to find an efficient set of solutions that were closer to the Pareto front than the other ones. Notice that, analyzing the other variants, it can be concluded that small values of performed better, thus highlighting the relevance of a good greedy criterion to select the facilities to be opened. Although the difference in terms of computing time was negligible, remained as the fastest one. Therefore, the initial approximation front for our MoPIG algorithm would be generated with .
The next experiment was devoted to testing the two parameters involved in the iterated greedy algorithm: , the percentage of solution destructed; and maxNonImprove, the maximum number of iterations without improvements inside the iterated greedy algorithm. Since both parameters were related, we opted for testing them in the same experiment. On the one hand, the percentage of solution destructed was selected from , where the number of nodes removed from the solution was . Values larger than 0.5 were not considered since this implied the destruction of more than half of the solution, which was equivalent to restart the search with a complete new solution. On the other hand, the maximum number of iterations without improvement was selected from . We did not test larger values due to the increment in the computing time. This experiment was divided into three tables (one for each metric under evaluation). Each one of the following tables evaluates the performance of the algorithm when combining specific and maxNonImprove values. In particular, we represented them as a heat map, where the better the value, the darker the cell.
Table 4 shows the results when considering the coverage. As expected, the larger the value of
maxNonImprove, the better the quality, since the algorithm had more opportunities to reach further regions of the solution space. The literature of the iterated greedy framework states that it provides better results when considering small
values. This hypothesis was confirmed in this experiment, where the algorithm started to result in worse solutions when the
value was larger than 0.3. The rationale behind this was that larger values implied the destruction of nearly half of the solution, which was equivalent to restarting the search from a completely different solution, without leveraging the structure of the one under construction. The best results were given by
and
.
Table 5 presents the results in terms of the hypervolume. The behavior was similar to the one obtained in
Table 5, although the values were closer than in the coverage table. Again, the best results were obtained with larger values of
maxNonImprove and small values of
.
Table 6 provides the results regarding the epsilon indicator. The distribution of the heat map was similar to the ones of the previous tables, but the differences between the values were more pronounced,
and
emerging as the best values.
Table 7 shows the results obtained when evaluating the inverted generational distance varying the
and
maxNonImprove parameters. The results provided were similar to those depicted for
Table 4,
Table 5 and
Table 6, again suggesting that the most adequate values were
and
.
Analyzing these results, we can conclude that the best results were obtained when considering and , values that will be used in the competitive testing against the best previous method found in the state-of-the-art. It is worth mentioning that we were not considering values larger than 10 for maxNonImprove since it drastically affected the performance of the algorithm in terms of computing time.
4.2. Competitive Testing
The competitive testing was designed to evaluate the performance of the proposal when comparing it with the best methods found in the state-of-the-art for BpCD. This problem has been mainly ignored from a heuristic point of view, so we considered three extended evolutionary algorithms in the context of multi-objective optimization that had already been used for solving facility location problems: MOEA/D [
36], NSGA-II [
37], and SPEA2 [
38].
The Multiobjective Evolutionary Algorithm based on Decomposition (MOEA/D) [
39] decomposes the problem under consideration into scalar optimization subproblems. Then, it simultaneously solves those subproblems with the corresponding population of solutions. For each generation, the population conforms to the best solution for each subproblem. The Non-dominated Sorting Genetic Algorithm II (NSGA-II) [
40] uses the parent population to create the offspring population. Then, to increase the spread of the generated front, it uses a strategy to select a diverse set of solutions with crowded tournament selection. Finally, Strength Pareto Evolutionary Algorithm 2 (SPEA2) [
41] is an extension of the original SPEA, where each iteration copies to an archive all non-dominated solutions, removing the dominated and replicated ones. Then, if the size of the new archive is larger than a threshold, more solutions are removed following a clustering technique.
The three considered evolutionary algorithms were implemented with the MOEA framework (
http://moeaframework.org), which is an open source distribution of multi-objective algorithms that allows us to define the main parts of the genetic algorithm without implementing it from scratch, with the ability to execute the algorithms also in parallel. The maximum number of evaluations was set to 900,000 in order to have a compromise between quality and computing time. For the NSGA-II and MOEA/D algorithms, two more parameters needed to be adjusted: crossing and mutation probability. In order to do so, a preliminary experiment was performed considering the subset of instances described in
Section 4.1. The values tested for the crossing probability
C were 0.7, 0.8, and 0.9, while the values for mutation probability
M were 0.1, 0.2, and 0.3, as it is recommended for these kinds of algorithms.
The preliminary experiments for the evolutionary algorithms were analyzed by considering as a reference front the one generated by the union of all the fronts involved in the comparison.
Table 8 and
Table 9 show the results of the parameter adjustment for NSGA-II and MOEA/D. Notice that SPEA2 was not considered in this preliminary experimentation since it did not present any additional parameter. The best results for each metric are highlighted in bold font. As can be derived from the results, the best values for NSGA-II were
and for MOEA/D were
.
In the context of
, for the final competitive testing, the best approach was an exact algorithm based on the
-constraint presented in [
23]. This algorithm is able to generate the optimal Pareto front for
, but requiring large computing times, which makes it not suitable for problems that need to be solved quickly. Therefore, as the optimal Pareto front was known, it was selected as the reference front for the comparison.
In the context of evolutionary algorithms, one of the most extended stopping criteria is the number of evaluations. However, MoPIG is a trajectory based algorithm, a class of algorithms in which the computing time is one of the most relevant criteria to stop the algorithm. Nevertheless, the number of evaluations required by MoPIG was estimated, resulting in 900,000 evaluations on average. Therefore, the evolutionary algorithms was executed with 900,000 evaluations as the stopping criterion.
Table 10 shows the summary results of the aforementioned metrics over the complete set of 165 instances.
Analyzing the coverage, MoPIG was clearly the best algorithm. In particular, only 23% of the solutions were covered by the optimal Pareto front, indicating that the approximation front obtained by MoPIG was really close to the optimal one. The second best algorithm was MOEAD, having 76.5% of its front covered by the Pareto front. NSGA-II was close to MOEAD in terms of coverage (76.59%), while SPEA2 was the worst approach regarding this metric (90.9%), with almost all its front covered by the optimal one.
With respect to the hypervolume, MoPIG again emerged as the best algorithm, with an hypervolume of 0.5233. It is worth mentioning that the value for the optimal Pareto was 0.5555, which means that the hypervolume of the proposed algorithm was really close to the optimal one. Among the evolutionary algorithms, MOEAD presented the largest hypervolume value (0.3035), but it was still considerably smaller than the one obtained by MoPIG.
The -indicator for MoPIG (0.0980) highlighted that the efficient front obtained was very similar to the optimal Pareto. For the evolutionary algorithms, the smallest value was again obtained by MOEAD (1.0465), but it was still two orders of magnitude larger than the value obtained by MoPIG.
Finally, for the inverted generational distance, MoPIG was able to reach the minimum value (73.3176), followed by MOEAD (80.7989). Notice that the optimal value for this metric was 72.5176, obtained by the -constraint algorithm. It can be clearly seen that while MoPIG was close to the optimal value, the remaining evolutionary algorithms were far from it.
The computing time was another relevant factor when comparing optimization algorithms. First of all, it is important to remark that the -constraint, as an exact algorithm, required large computing times to solve most of the instances, exceeding in several cases 30,000 s of computing time. These results clearly indicate that the -constraint algorithm cannot be considered when small computing times are required. Regarding NSGA-II, it required 12,000 s on average to generate the approximation front, which is still not suitable for generating fast results. On the contrary, the proposed MoPIG was able to generate the approximation front in 250 s on average, being able to solve most of the small and medium instances in less than ten seconds and only requiring more than 1000 s in the most complex instances (those in which NSGA-II and -constraint required 15,000 and 30,000 s, respectively).
With the aim of graphically analyzing the differences between both algorithms, the approximation front obtained by MoPIG, NSGA-II, MOEA/D, SPEA2, and the -constraint of three representative instances are depicted.
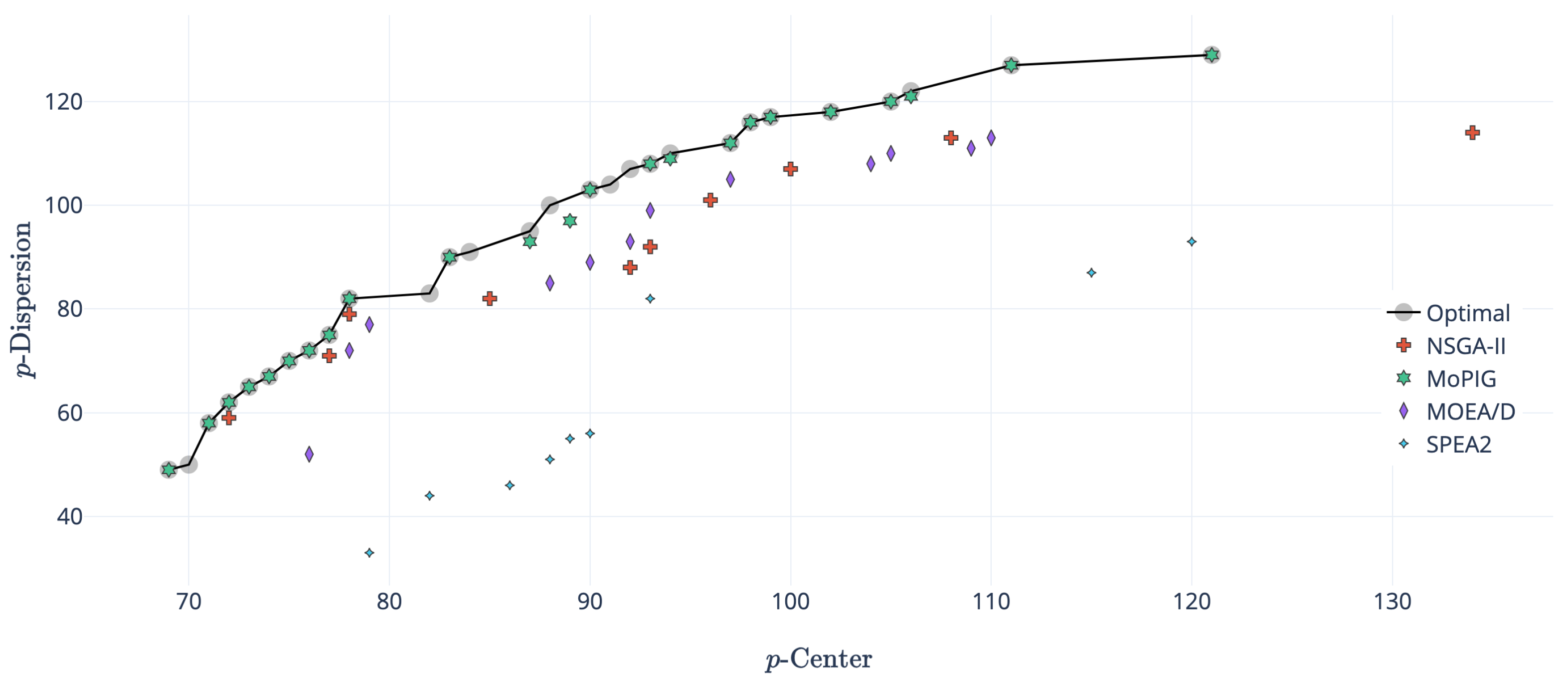
Figure 3 shows an example of an instance where MoPIG was able to reach the optimal Pareto front. As can be seen in the figure, MOEA/D was able to reach a near-optimal approximation front, but there were some solutions that were covered by the optimal front (those located under the curve of the optimal front). The approximation front of NSGA-II was close to the one provided by MOEA/D, but reaching a smaller number of solutions of the Pareto front. Finally, SPEA2 was the worst performing algorithm, being unable to reach any solution of the optimal front.
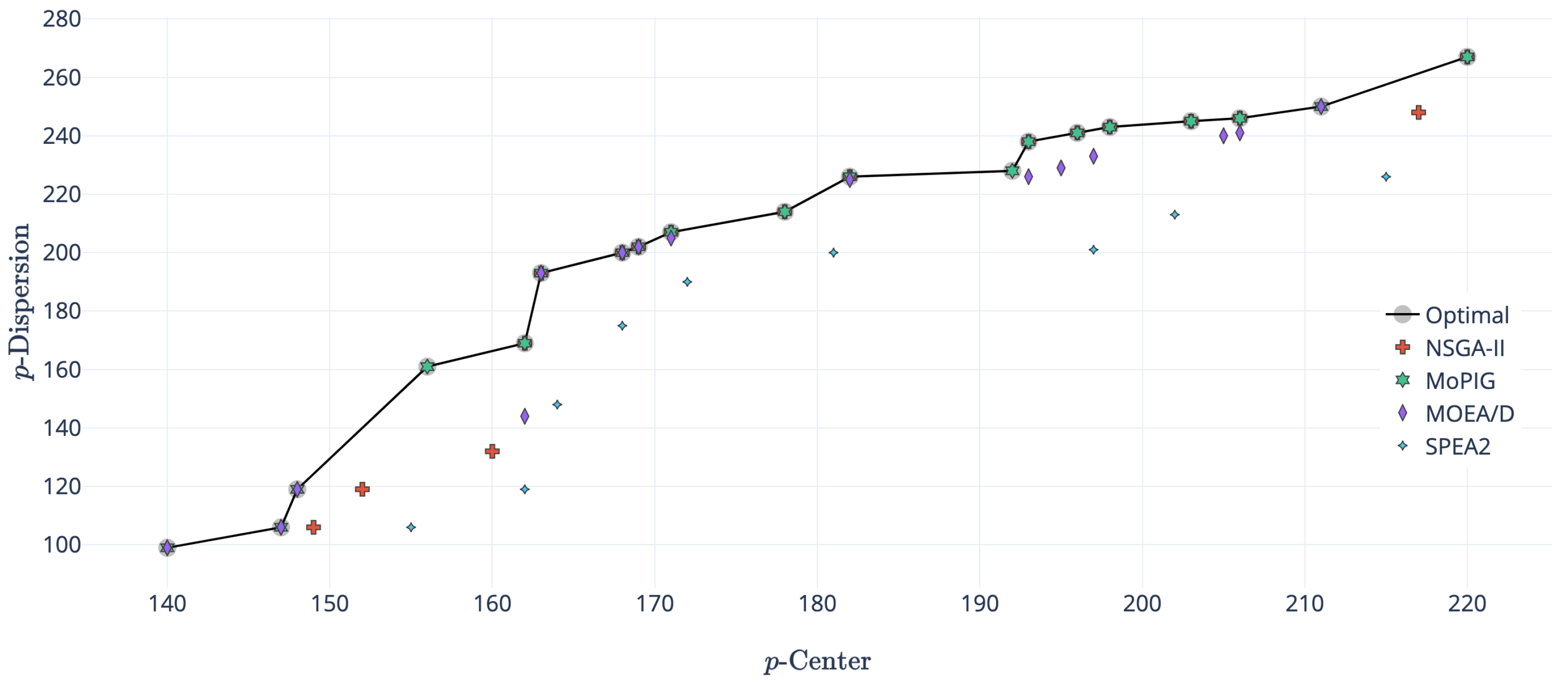
On the contrary,
Figure 4 shows an example in which the complete optimal front was not reached by any of the algorithms. However, the figure shows how MoPIG missed only seven solutions, staying pretty close to two of them. On the contrary, neither MOEA/D nor NSGA-II were able to reach any solution of the optimal front, but staying reasonably close to it. Again, the approximation front of SPEA2 was far away from the Pareto front.
Finally,
Figure 5 shows one of those instance where the optimal front was hard to find for all the compared algorithms. Even in this case, MoPIG was able to find an approximation front very similar to the optimal one. Although MOEA/D showed its superiority with respect to both NSGA-II and SPEA2, its front was completely dominated by the optimal one.
Having analyzed these results, MoPIG emerged as the most competitive heuristic algorithm for solving , balancing the quality of the solutions obtained and the computing time required for solving them.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}