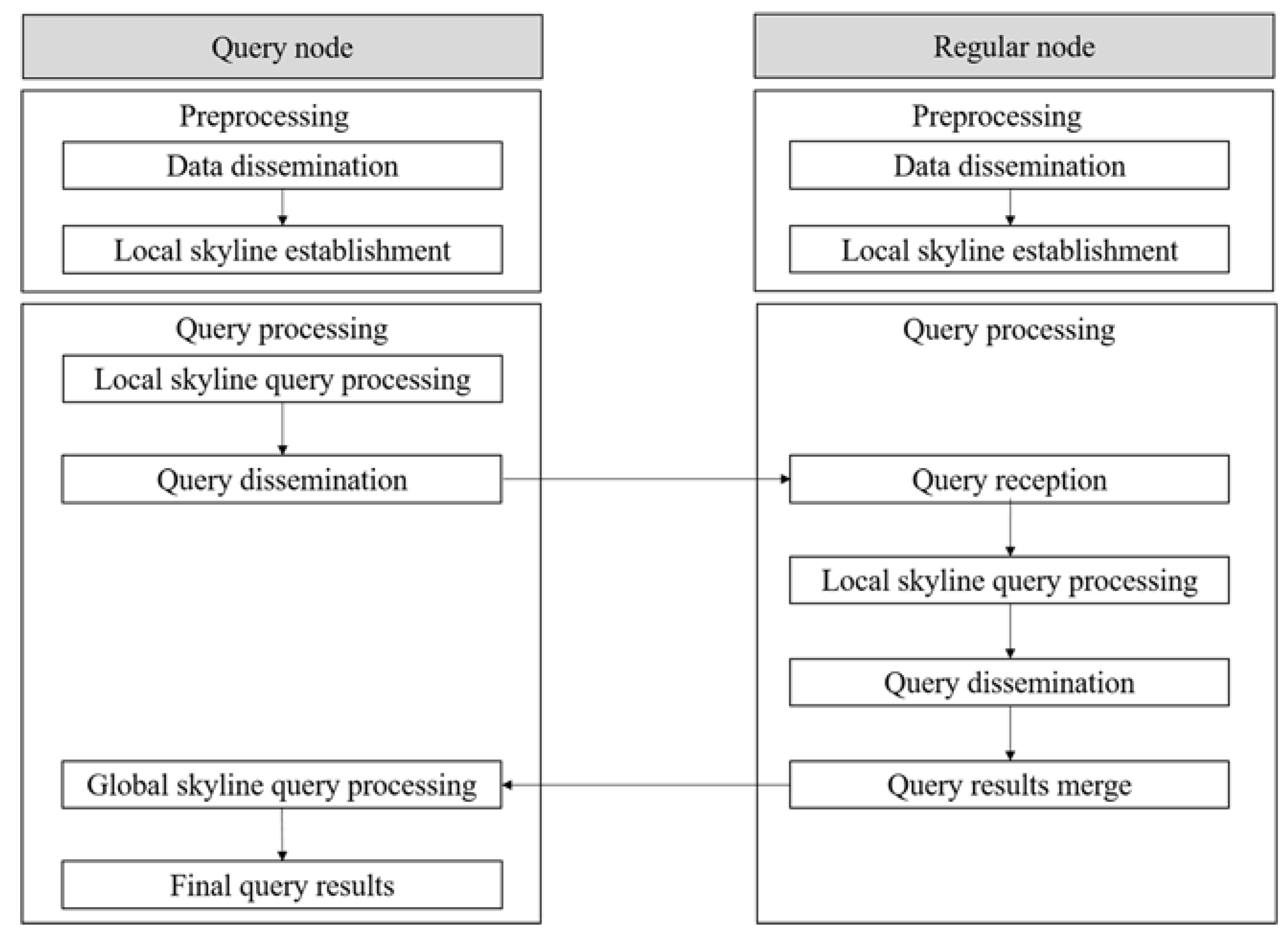
3.2. Data Structure
All nodes can become query nodes, and the remaining nodes have mobility and can thus receive new object data according to their movements. Each node manages different tables such as object data or query and processing results in its local storage, as shown in
Figure 3. Each node manages their queries and query data in the query table (QT), and the query results are managed in the query-processing results table (QRT). Data on nearby nodes are stored in the neighbor node table (NNT) through continuous communication with nearby nodes, and object data received from objects are stored in the owned object table (OT). Nodes establish a local skyline based on object data that they own, and acquired results are merged with candidate-filtering objects and stored in the candidate filtering object table (CFOT). The filtering object groups that are actually used are stored and managed in the filtering object table (FOT).
The QT is used to store query data that they themselves generated and query data that were received from other nodes. The query table is composed of <query_id, query_node_id, query_node_location, query_range, query_condition, parent_node_id, child_node_id>. The query_id is the query identifier, query_node_id is the query node identifier, query_node_location is the query node location, query_range is the query dissemination range, query_condition is the query condition, parent_node_id is the parent node identifier, and child_node_id is the child node identifier.
Local skyline query-processing results are stored in the QRT after each node processes the local skyline. The QRT is composed of <query_id, result_list>, where result_list stores the query results in list form and stores them as values of each condition that corresponds to query_condition. The NNT stores data on neighboring nodes. The proposed scheme enables the node to communicate with other nodes within their communication range and stores the data on communicating nodes in the NNT in order to assess who the neighboring nodes are. The NNT is composed of <node_id, node_location, node_vector, query_id_list>. The node_id is the neighboring node identifier, node_location is the neighboring node location, node_vector is the neighboring node’s movement speed, and query_id_list shows the query_id data that are currently saved.
The OT stores the object data received from objects near the node. The object table is composed of <object_id, object_location, object_condition, object_update_time>, where object_id is the object identifier, object_location is the object location, object_condition is the object’s property value, and object_update_time is the time when the object data were received. The CFOT stores objects that were acquired by establishing a local skyline. The CFOT is composed of <object_id, object_location, object_condition, object_update_time>, where object_id is the object identifier, object_location is the object location, object_condition is the object’s property value, and object_update_time is the time when the object data were received. The FOT stores objects merged with existing initial filtering objects and local skyline query-processing results after processing the local skyline queries. The FOT is composed of <object_id, object_location, object_condition, object_update_time>, where object_id is the object identifier, object_location is the object location, object_condition is the object’s property value, and object_update_time is the time when the object data were received.
3.3. Local Skyline Processing
Each node receives new objects data based on their movements, and data dissemination begins when the new object data are received. The proposed scheme can maintain accuracy during data dissemination because the object data from a disconnected node are indirectly owned by the other nodes. Therefore, its object data can be reflected during query processing through nodes who once received the data from nearby even if the node gets disconnected while a query is being processed.
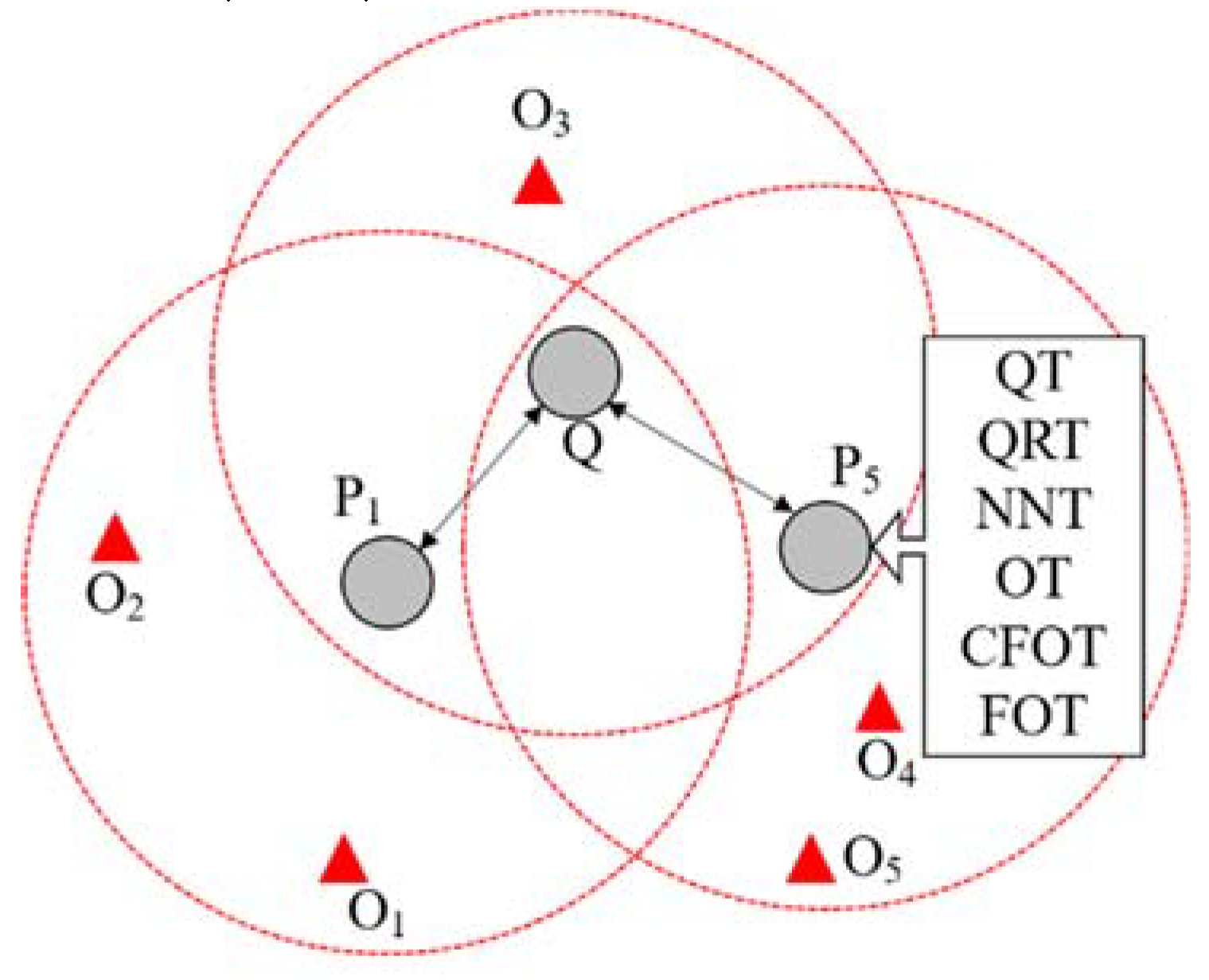
Figure 4 shows how
and
that are nearby each other disseminate the object data that they own. In the proposed scheme, when nodes first communicate with a specific node, all the object data that they own are disseminated. After the initial data dissemination to a specific node, new object data are disseminated to that node only when the previous data have been received. When
and
communicate for the first time, they transmit the object data that each of them owns. However, when each node transmits object data to another node, this may lead to an issue where duplicate data are stored because the object data already owned were transmitted. To solve this problem, the node that is transmitting the object data will compare the data acquired through the data dissemination with the object data that the node already owns, and only non-duplicate object data are stored. When the data dissemination is complete, because the node that was distributing data has now received new object data, these new objects are disseminated as the node re-disseminates data to all nearby nodes.
The data dissemination step involves distributing objects that the node owns to other nearby nodes. Each time a node receives objects from a nearby node, the newly received object data are sent through MSG_OBJECT_DISSEMINATION in order to disseminate the received object to nearby nodes. The node receiving the MSG_OBJECT_DISSEMINATION will determine whether the node already owns the disseminated data. If there are object data that the node does not own from among the disseminated objects, they are stored in the OBJECT_TABLE. Algorithm 1 shows the node processing algorithm when the MSG_OBJECT_DISSEMINATION is received during the data-dissemination process. When nodes receive the MSG_OBJECT_DISSEMINATION message as shown in the algorithm, they will first assess whether or not they are within the query-dissemination range. If they are not within the query-dissemination range, they will send MSG_QUERY_BROADCAST_FAIL to the node who sent the query to them. They will then compare the object_id of all objects in their OBJECT_TABLE with the object_id of MSG_OBJECT_DISSEMINATION, and determine if the same object_id exists. If there is an object that does not exist, it will be stored in their OBJECT_TABLE.
| Algorithm 1. receive_MSG_OBJECT_DISSEMINATION() |
{
if (Node_Location<Query_Range)
for (OBJECT_TABLE.size()){
if (MSG_OBJECT_DISSEMINATION.object_id does not exist in OBJECT_TABLE)
store the received object information in OT}
} |
In the proposed scheme, query-processing costs are reduced by establishing a local skyline before queries are processed. This will reduce filtering costs that are incurred during query processing. When all nodes complete the data distribution, they generate a candidate filtering object group by establishing a local skyline based on the object data that they own.
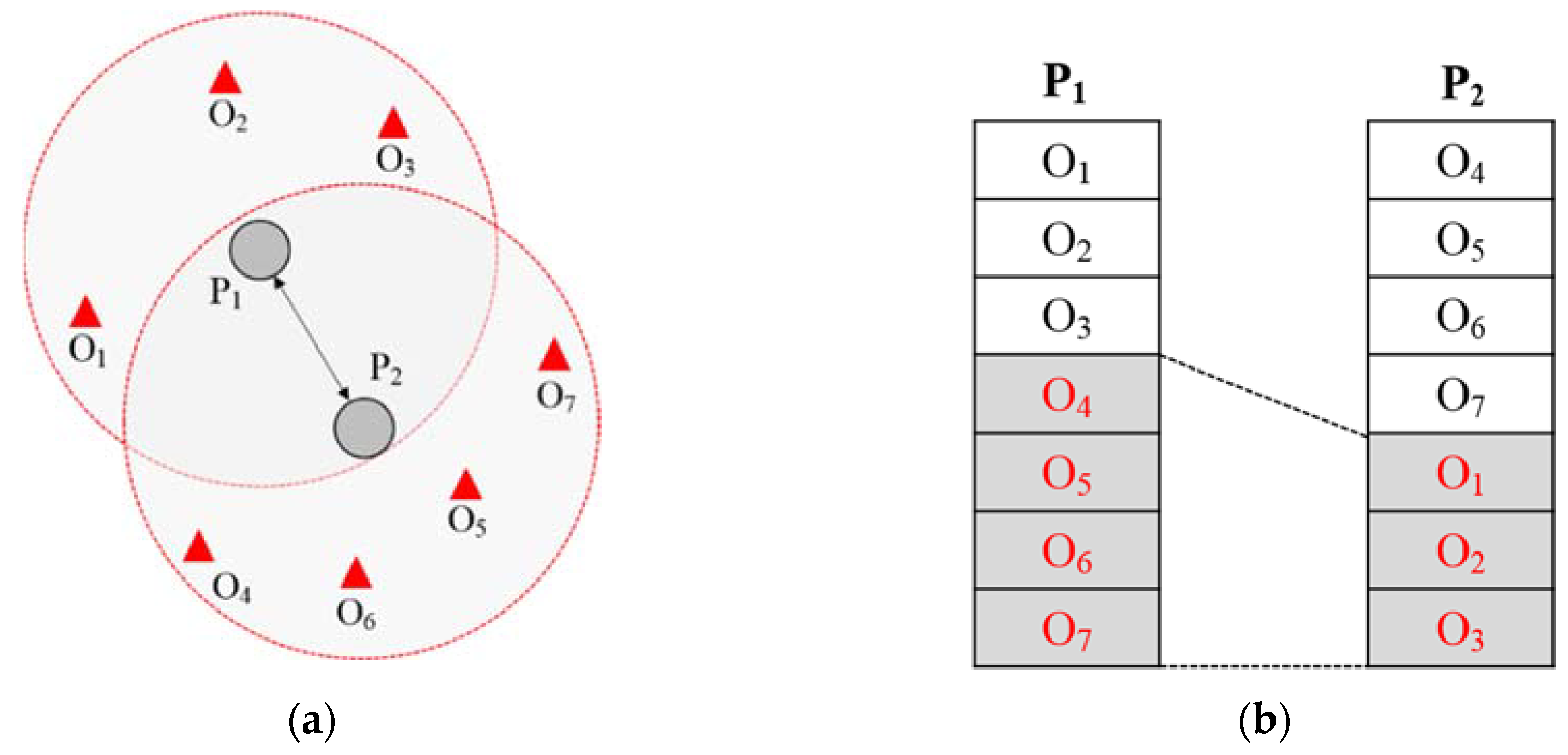
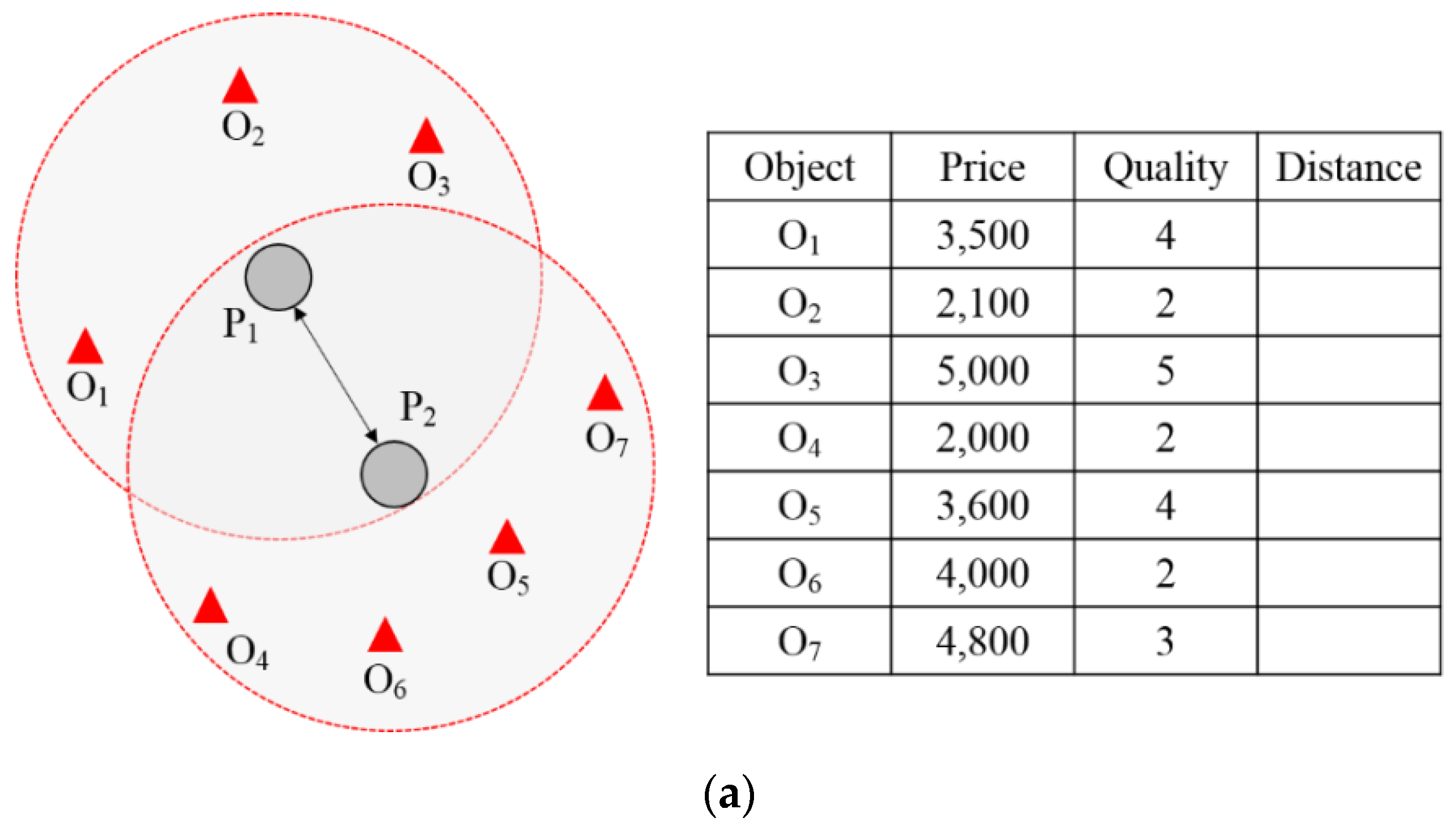
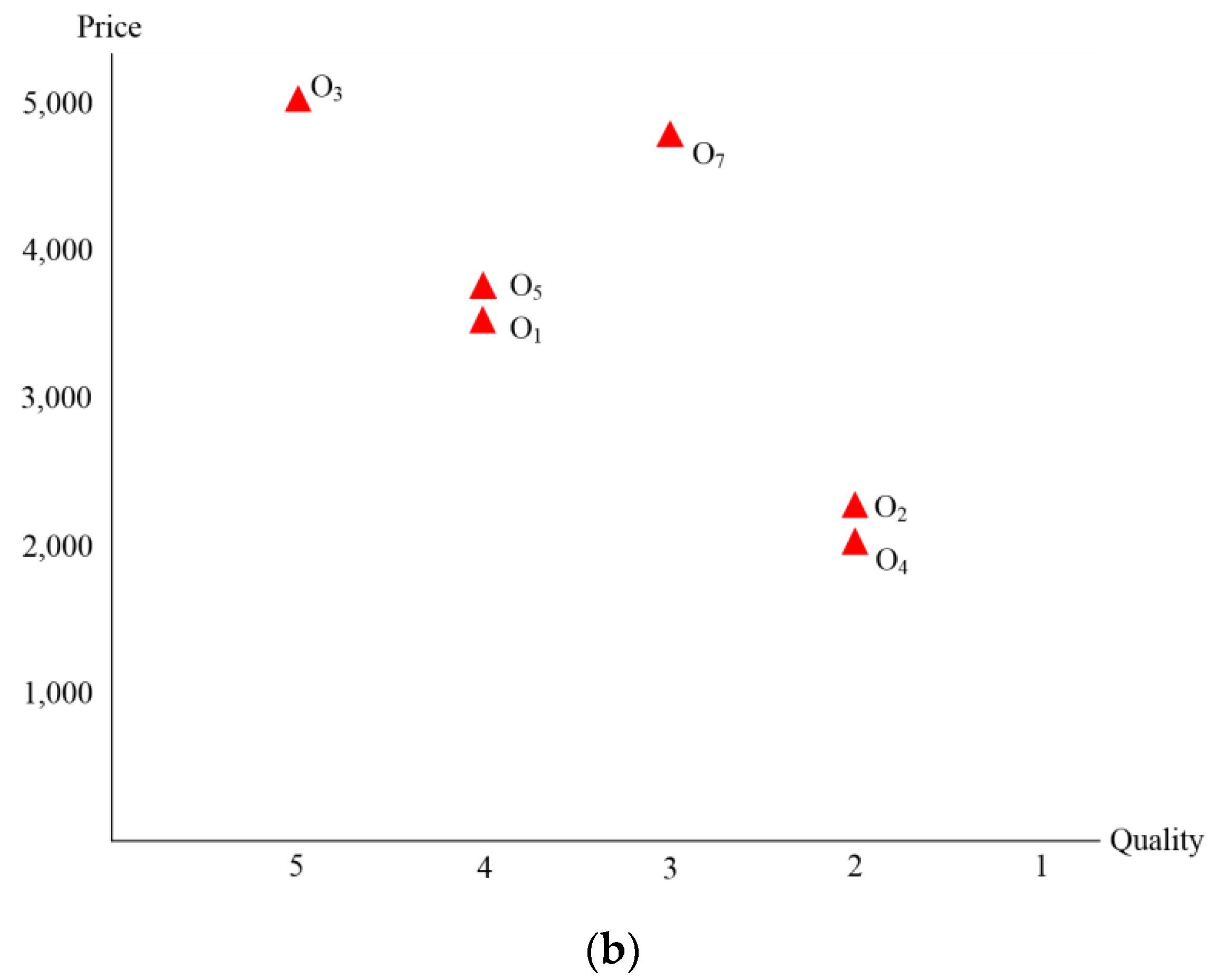
Figure 5 shows how candidate object groups are generated by building a local skyline.
generates a candidate object group through a skyline based on the static properties of the object data it owns, except for the distance property as shown in
Figure 5a. Although the distance property of each object is a property that is mapped through the distance from the query node corresponding to the user device transmitting the queries, that property is excluded because it cannot be determined, as local skylines are established before queries are even received. The other remaining properties are static properties that do not change. A local skyline is established by considering the following two static properties to process the skyline. Establishing a local skyline is a scheme that sorts only objects that are not dominated by other objects in the same way as in regular skyline processing.
,
, and
, which are objects that are not dominated as shown in
Figure 5b, comprise a candidate-filtering object group by establishing a local skyline.
In the existing filtering scheme, filtering objects are generated only after a query is received in order for filtering to occur. For this reason, filtering costs are added to processing costs and so query processing performance is reduced. By contrast, the proposed scheme reduces the cost of generating filtering objects because it generates candidate-filtering objects by establishing a local skyline before queries are received. Algorithm 2 shows the algorithm for establishing a local skyline. Nodes can establish a local skyline based on the object data in their own OBJECT_TABLE after the data distribution. Only the object’s static properties are considered in establishing a local skyline. Objects that are not dominated by the node’s other objects are acquired from the results of establishing the local skyline, and they are stored in Candidate_Filtering_Object_Table.
| Algorithm 2. process_Pre_Skyline() |
{
for (OBJECT_TABLE.size()){
if (all static properties of object i > all static properties of object j)
store i in candidate filtering object set;
}
} |
3.4. Global Skyline Processing
Global skyline processing generates the final query results by merging the local skyline generated by each node in the query-dissemination range. The query node disseminates the issuing query to the nodes within communication range to collect and merge the local skyline generated each node. When a query is received from the user, each node performs filtering by using specific objects from the candidate filtering object group that the node owns. The purpose of filtering is to reduce the number of messages that are generated when queries are processed because the number of calculations increases with the number of objects.
Table 1 provides the distance properties that were mapped by calculating the distance between query nodes based on the object data that are owned by the node. In the same way, the distance properties of each object are calculated and mapped in the candidate-filtering object group as given in
Table 2. Here, the distance property refers to the distance between the query node and the object it owns. The query node selects the farthest object out of the candidate-filtering object group as the first filtering object.
, which has the farthest distance, is selected as the first filtering object. The node selects the nearest
from the candidate filtering object groups as the first filtering object. This is because
was dominated by
during the process of establishing a local skyline, but it was no longer dominated by
after the query was received and the distance property was determined; hence, it became an object that could be selected as part of the global skyline query-processing results.
Table 3 shows the properties of
’s first filtering object. When the first filtering object is selected as such, the nodes begin filtering by including the distance properties based on the objects they own.
, which was selected as the first filtering object, filters
and
, which are objects with a lower value for all properties.
In the filtering and local skyline query processing step, after the node receives a query, the first filtering object is selected from the
Candidate_Filtering_Object_Table that was obtained from the local skyline. When the node receives a query, the distance property is first matched by calculating the distance between the query node and the object in order to determine the distance property of the object in
Object_Table. Equation (1) is used to calculate the distance between the query node and the object, and the distance property is determined by calculating the distance using this formula:
where,
and
respectively show the x and y coordinates corresponding to the query node’s location, while
and
show the x and y coordinates respectively, corresponding to the object’s location. This is the same as the general distance calculation formula between two coordinates. Because a normal node receives the query node’s location data along with the query itself, all nodes that receive the query can use Equation (1) to calculate the distance.
Algorithm 3 shows the algorithm for selecting the first filtering object. Each node determines the distance property of the objects that the node owns using Equation (1). The node selects the object with the largest distance property from the candidate-filtering object group as the first filtering object. The first filtering object is stored in the Filtering_Object_Table.
| Algorithm 3. select_First_Filtering_Object |
{
for (Candidate_Filtering_Object_Table.size()){
map to the distance property of each object;
if (the object i has the largest distance among the filtering objects
select the object i as the first filtering object;
}
} |
Algorithm 4 shows the algorithm for filtering through the first filtering object. When the first filtering object is selected, the nodes will filter the object that they have, which will take part in the query processing. The filtering target will be an object with property values including the distance property, which is a dynamic property, that are all lower than those of the first filtering object.
| Algorithm 4. process_Filtering |
{
for (OBJECT_TABLE.size()){
if (all properties of each object in OBJECT_TABLE are lower than Filtering_Object)
filter object;
}
} |
Algorithm 5 shows how the local skyline queries are processed. After filtering, the node will process the local skyline queries for the remaining objects that were not filtered. The results obtained from processing the local skyline queries are stored in the Query_Result_Table. Furthermore, the filtering object group is adjusted by merging the local skyline query-processing result with the filtering result group. The node removes the remaining objects after the filtering, except for those that are not dominated by the objects that the node owns. Objects that are not removed are stored in the Query_Result_Table.
| Algorithm 5. process_Local_Skyline |
{
for (OBJECT_TABLE.size()){
if (all properties of object i> all properties of object j)
remove j from OBJECT_TABLE;
}
store unremoved objects to Query_Result_Table;
} |
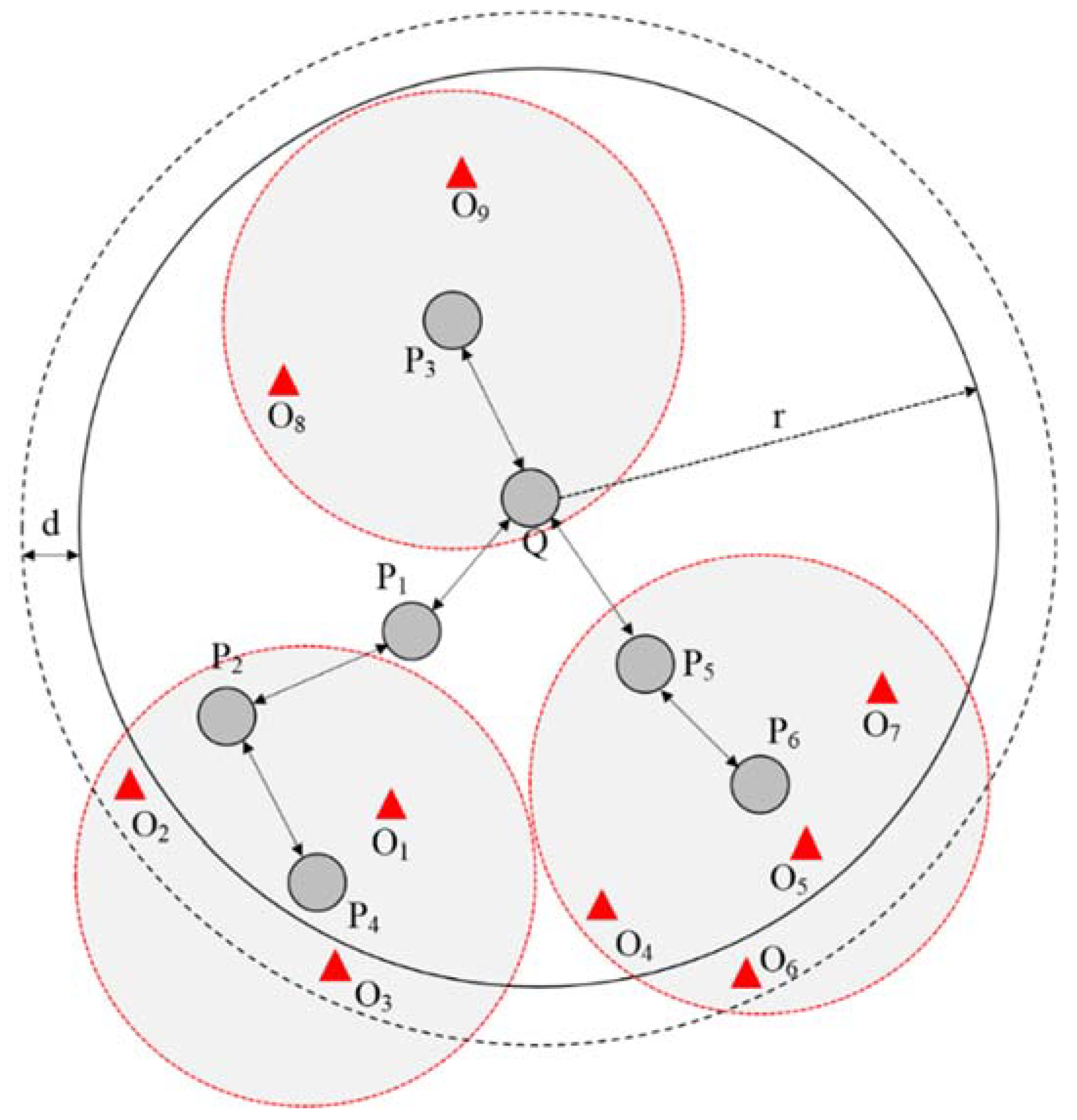
The proposed scheme also proposes a policy for expanding the query-dissemination range. In this policy, more objects can be included in the query processing by recalculating the query dissemination range to disseminate queries through an expanded query-dissemination range. This policy is for improving the accuracy. In the existing distribution range, even nodes within the range are unable to process queries because they are unable to communicate. However, expansion can allow such nodes to go beyond the existing query-dissemination range so that they will be able to communicate. For the query processing, the user specifies the query-dissemination range, and queries are processed within a specific range. Therefore, although more objects are required to process queries from the perspective of accuracy, because nodes who are outside the query-dissemination range are unable to participate in processing queries, the accuracy of query processing will suffer. Each node processes local skyline queries for the object data that the node owns, and then generates a new filtering object group based on the results. Local skyline query processing means that skyline queries are processed based on the object data that are owned by the node. If the object with the farthest distance from the new filtering object group is outside the existing query dissemination range, the range will be reselected based on the distance property value of that object.
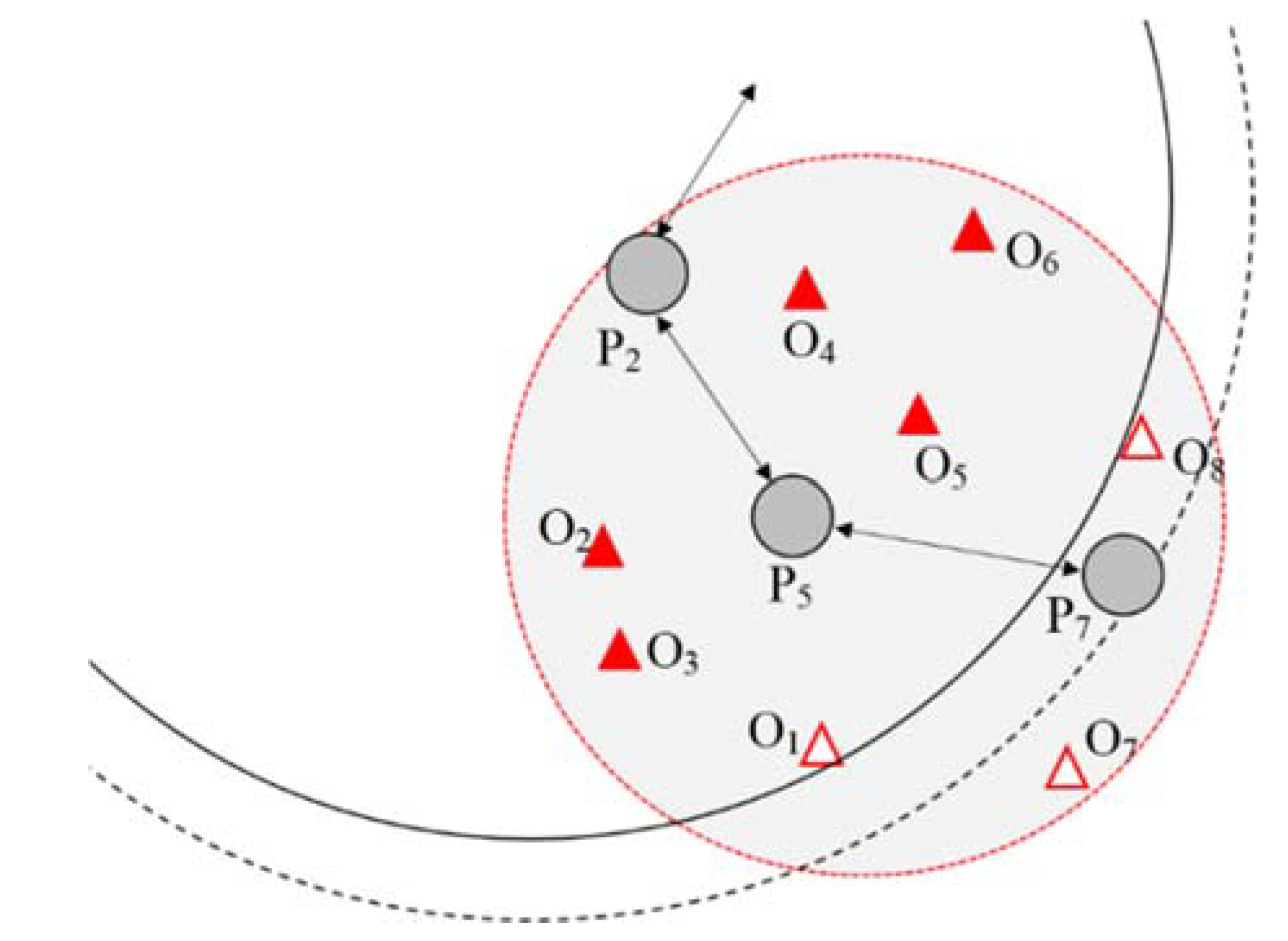
Figure 6 shows how the query dissemination range is expanded.
merges
,
, and
, which are part of the local skyline query-processing results, with the existing filtering objects after processing the local skyline queries. Because
, which has the farthest distance among the newly generated filtering object group, is farther outside of the existing query-dissemination range, this range will be increased by
based on
. In the existing query-dissemination range, even if
disseminates a query to
,
does not need to process the query because it is not within the query dissemination range. Thus, if
has an object that can influence the skyline query-processing results, the accuracy will be decreased. However, if the query-dissemination range is expanded through
, which is an object owned by
,
will thus be included in the query, and the issue of reduced accuracy will be resolved.
Table 4 shows the filtering object group after the local skyline query of
is processed.
is able to participate in the query when the query-dissemination range expands from
, and it can perform filtering and local skyline query-processing accordingly.
The query-dissemination range expansion and query dissemination is the step where queries are transmitted to neighboring nodes after the Query_Result_Table is generated. After processing the local skyline query, the node assesses whether there is an object from the local skyline query-processing results with a distance property that is larger than the existing query-dissemination range. If such object exists, the query-dissemination range is reselected to match the distance property of that object. Algorithm 6 shows the algorithm for expanding the query-dissemination range based on the local skyline query-processing results. Each node reselects the query dissemination range based on the distance property of an object in the Query_Result_Table, which is greater than the Query_Range.
| Algorithm 6. process_Expend_Query_Range |
{
for (Query_Result_Table.size()){
if (distance of the Query_Result >Query_Range)
re-select the range of query dissemination;
}
} |
After the query dissemination range is expanded, the node will disseminate MSG_QUERY_BROADCAST to neighboring nodes in the Neighbor_Node_Table. MSG_QUERY_BROADCAST is composed of <node_id, query_id, query_node_id, Query_Result_Table, query_range>.
In the proposed scheme, not all the local skyline results of each node are returned to query nodes by merging the results. However, the results are merged by returning them to the parent node instead. Through this process, only the optimized results are returned to the query node. Hence, the query node can merge only the optimized results to process the global skyline queries, thereby preventing device load. Furthermore, this reduces the number of messages that are generated as the results are returned, and therefore, the query-processing performance is improved.
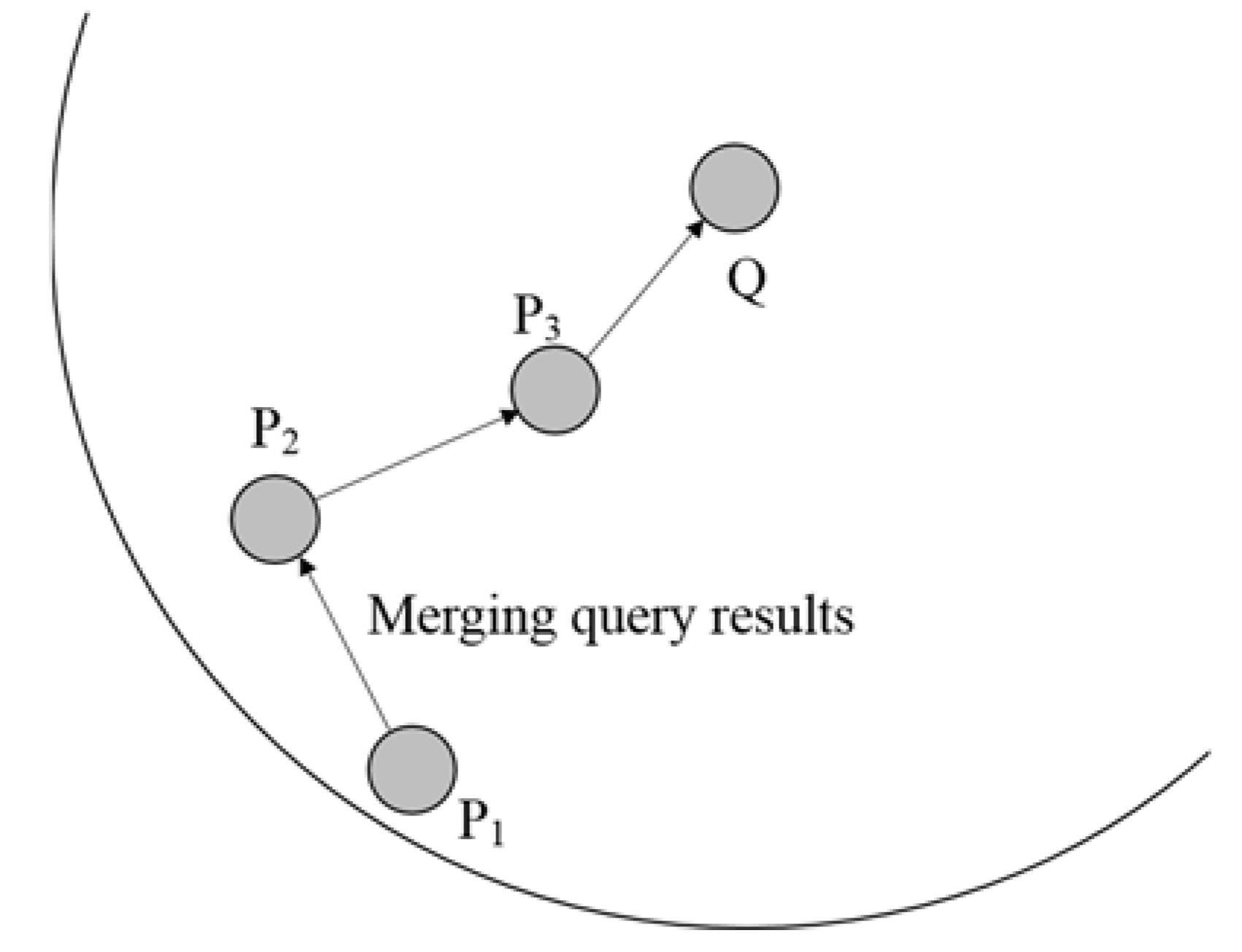
Figure 7 shows how the results are merged and returned. The node’s local skyline query processing results from
to
are returned to the parent node. The parent node then merges the results obtained from the child node with its own local skyline query-processing results, and the new results are returned to its own parent node. The results are merged in the same way as in the local skyline query processing. Here, the child node refers to the node who received the query that was disseminated, and parent node refers to the node who transmitted the query. When the global skyline queries are processed, the local skyline query-processing results from all nodes involved in the query are returned to the query node. The query node then generates the initial skyline query-processing results by processing the global skyline queries based on the local skyline query-processing results from all nodes involved in the query. Here, the global skyline query is processed in the same way as processing a local skyline query, but the object that is the target of query processing is one that is part of the local skyline query-processing results of the nodes that took part in the query.
Algorithm 7 shows the algorithm for merging and returning the results. The node who received the results from the child node stores all the results into the node’s Query_Result_Table. The local skyline queries are processed for the stored results, and new result groups are generated. The local skyline query-processing results that were obtained based on the returned results and its own results replace the results in the Query_Result_Table. The node delivers these results to the parent node through a MSG_RESULT_BROADCAST message.
| Algorithm 7. process_Result_Merge_and_Return |
{
if (MSG_RESULT_BROADCAST is received from the child node)
store the returned object in Query_Result_Table;
for (Query_Result_Table.size()){
if (all properties of object i> all properties of new object j)
remove j from OBJECT_TABLE;
}
replace unremoved objects with results from Queries_result_Table;
send MSG_RESULT_BROADCAST to a parent node;
} |
When the query node receives all the local skyline query-processing results through the MSG_RESULT_BROADCAST message, the final global skyline query is processed and the first query-processing results are generated in this step. When the query node receives all objects from the child nodes, the global skylines are performed just as how normal nodes would re-perform a local skyline by merging the results. The final results obtained through the global skyline are sent to the user.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}