Melody Extraction and Encoding Method for Generating Healthcare Music Automatically



Abstract
:1. Introduction
- Automatically melody extraction: In the automatic music generation research based on MIDI files, a melody track is required as the learning data when generating the melody. This research utilizes the TFIDF algorithm and feature-based filters to automatically extract melody tracks from MIDI files.
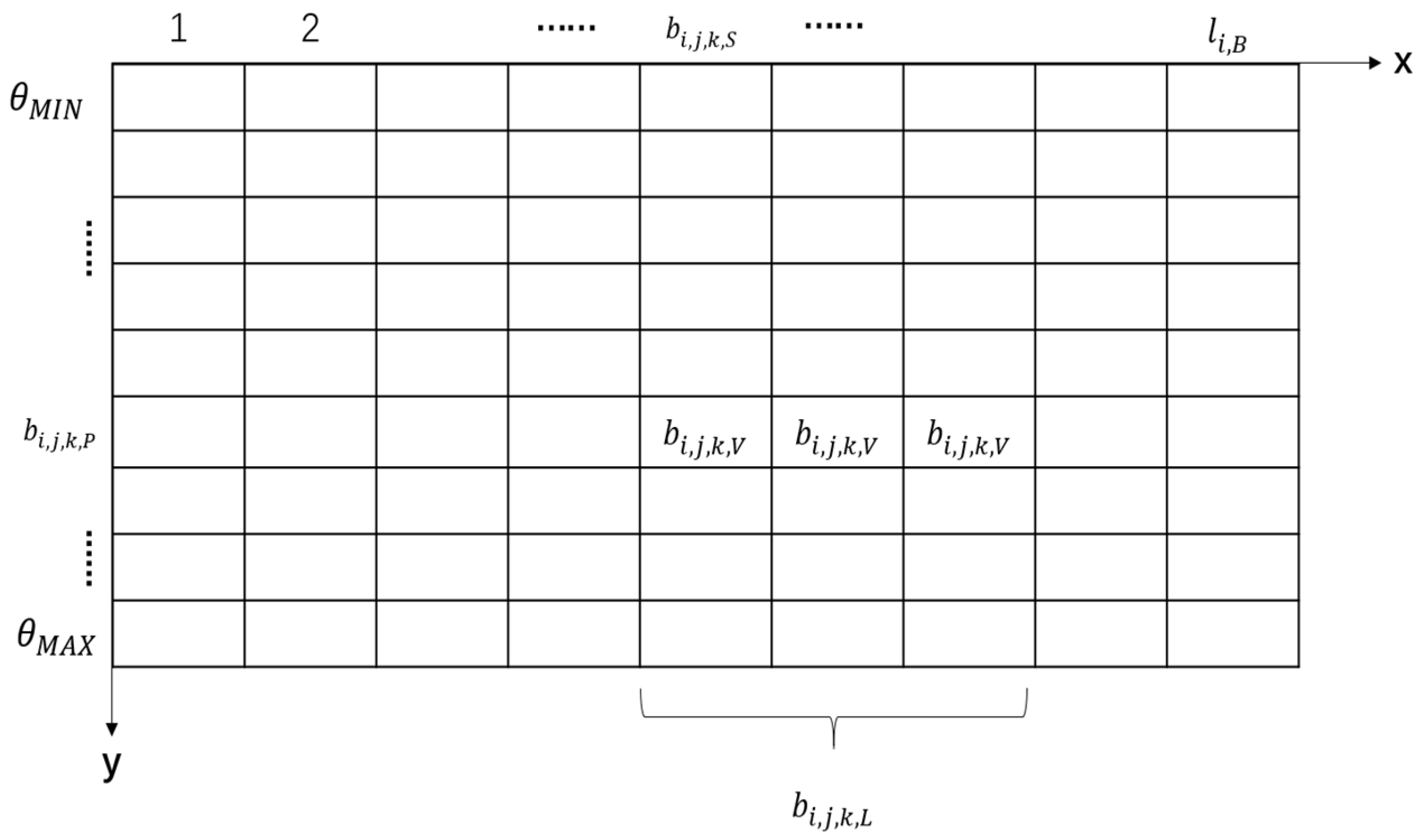
- Bar encoding method for more features: Bar encoding encodes the start time, duration, pitch, and intensity of the notes contained in the bar into the bar matrix. The bar matrix can accurately represent the detailed features of each note.
- Improved preprocessing for music generation based on deep learning: Automatic melody extraction and bar encoding can enable the deep learning neural network to train the composition method better.
2. Related Literature
3. Proposed Method
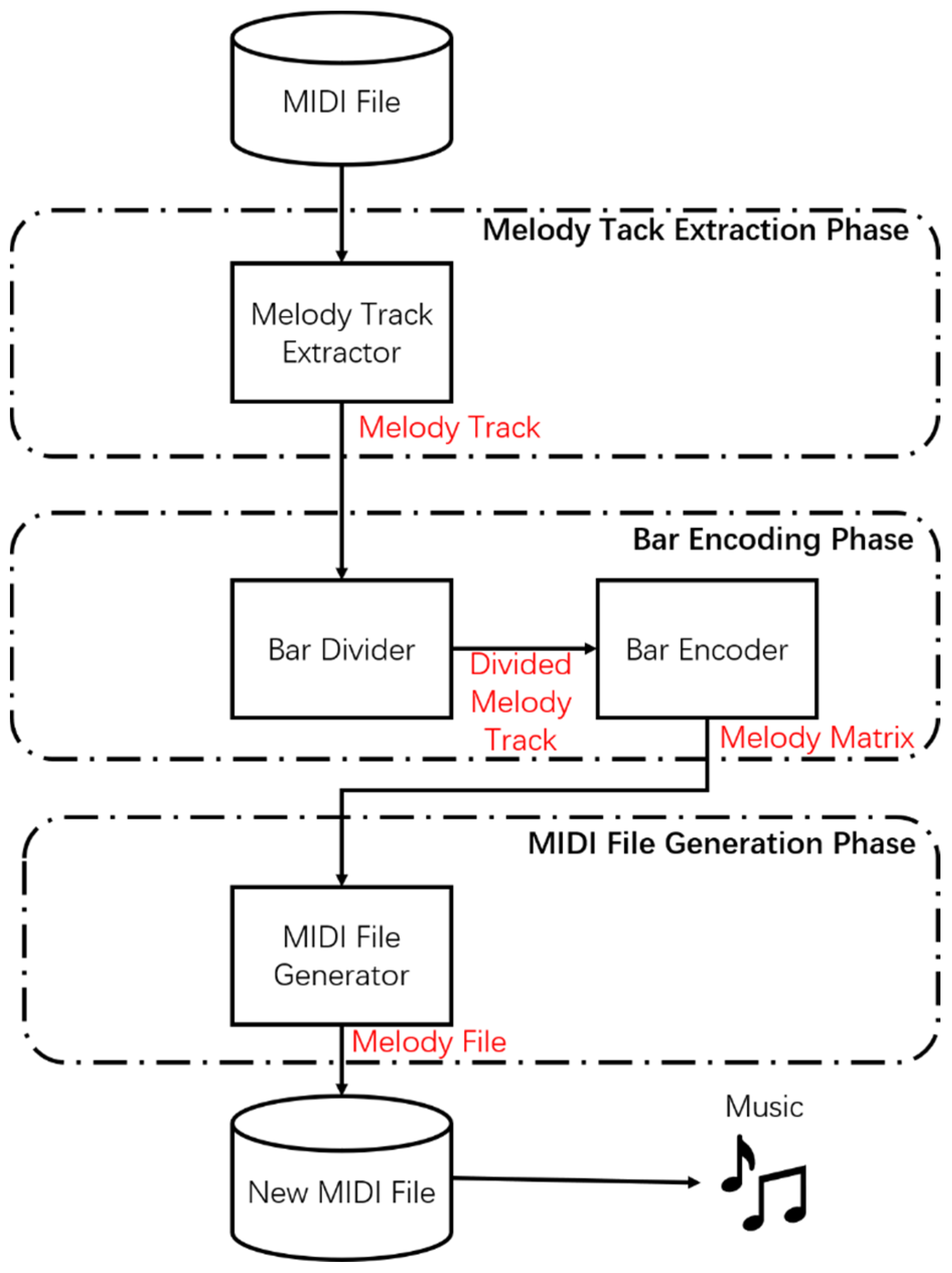
3.1. Music Generation Process of the Proposed Method
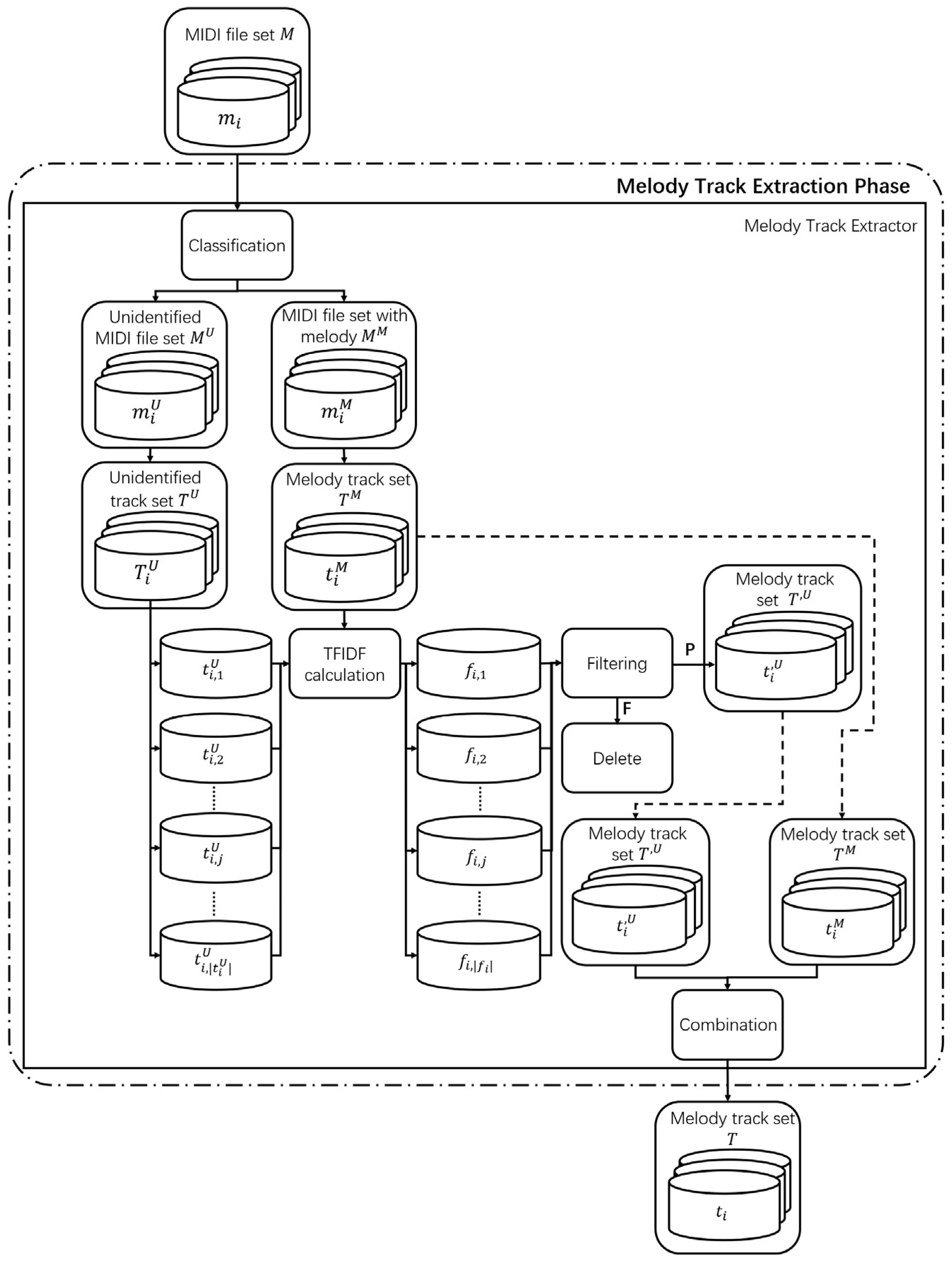
3.2. TFIDF-Based Melody Track Extraction
| Algorithm 1. Term frequency–inverse document frequency (TFIDF) value calculation algorithm. |
| FUNCTION Calculate TFIDFvalue(, ) OUTPUT //TFIDF value of BEGIN FOR ← to SIZE() ← Calculate frequency of track containing in END FOR ← Size of FOR ← to SIZE() ← Calculate frequency of p in END FOR ← Calculate average of END |
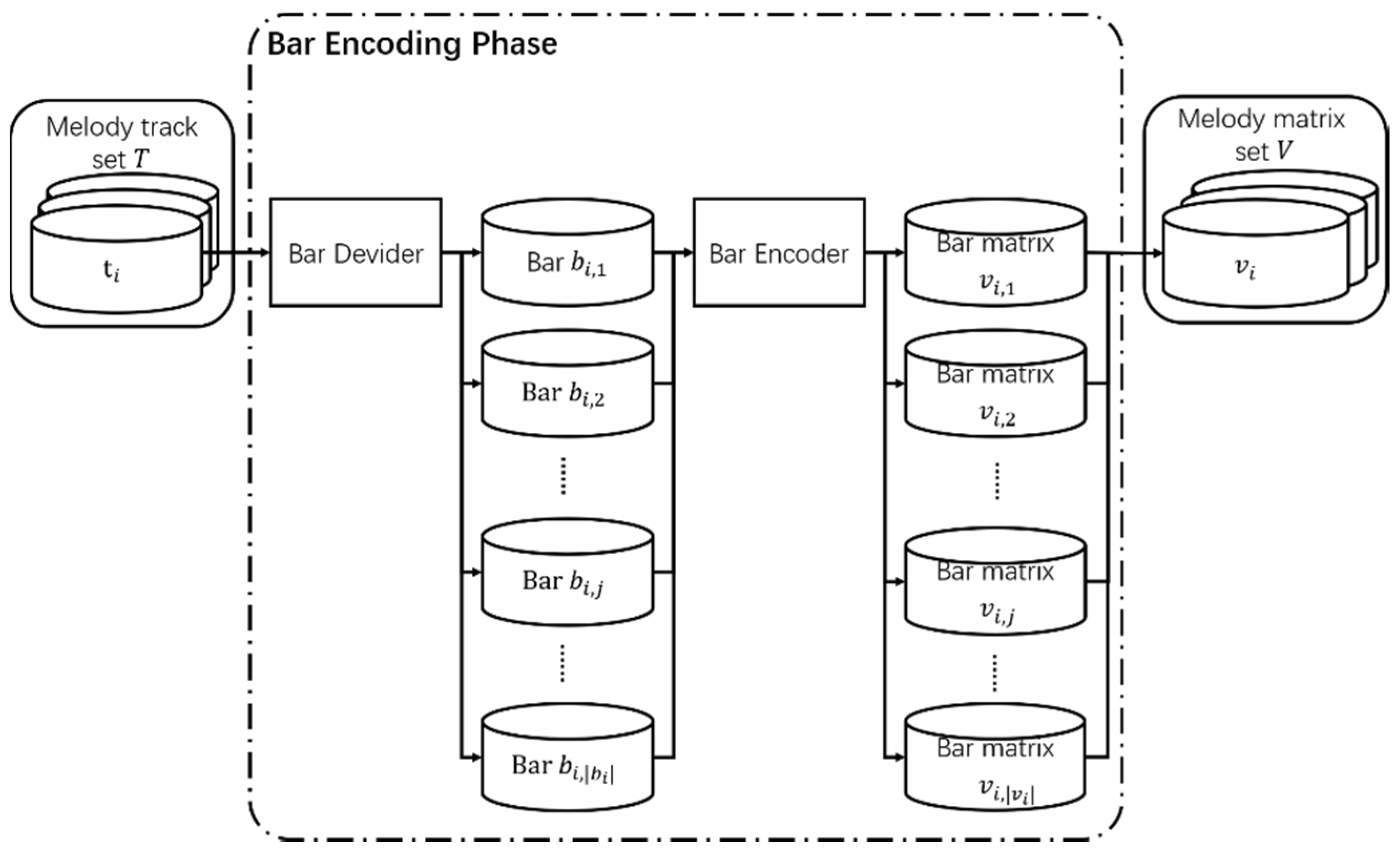
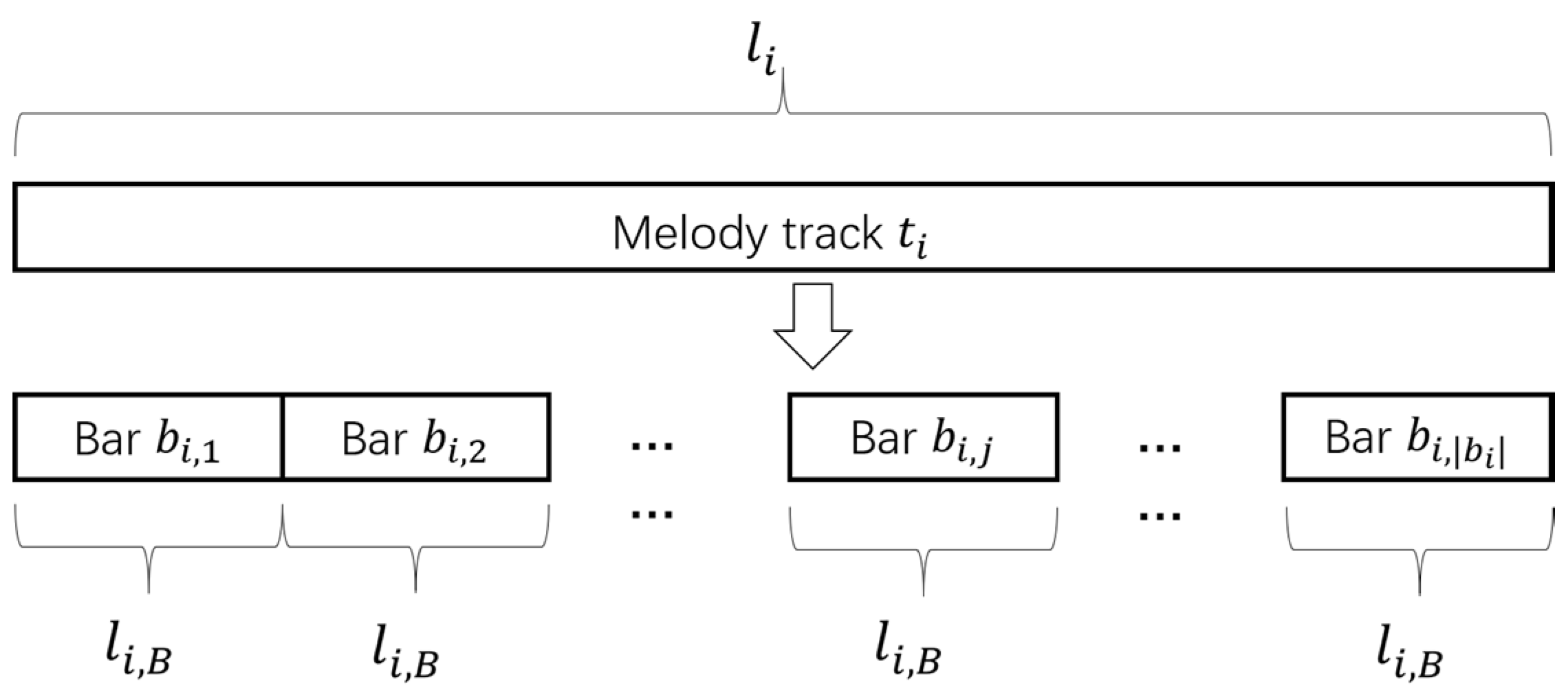
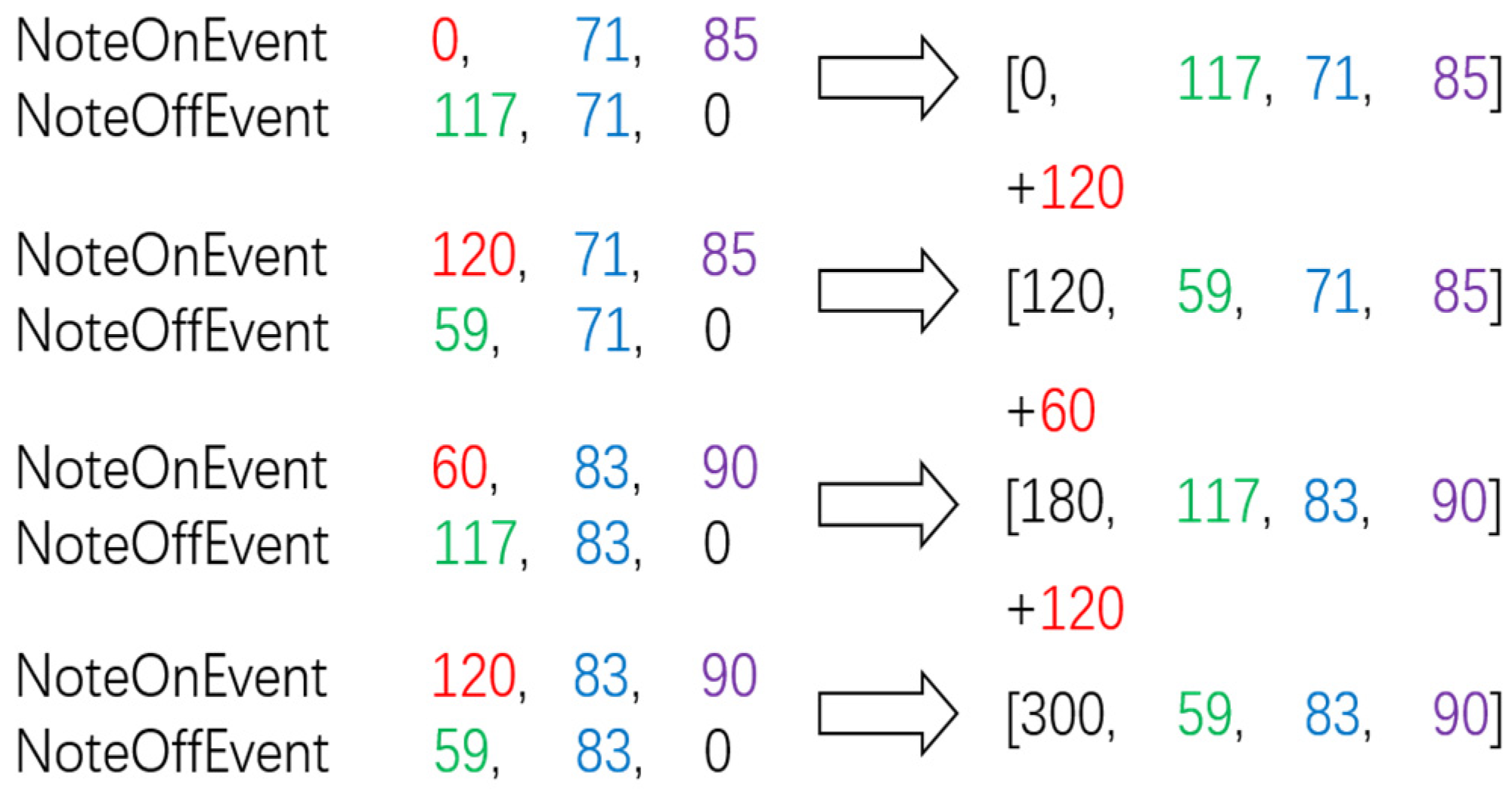
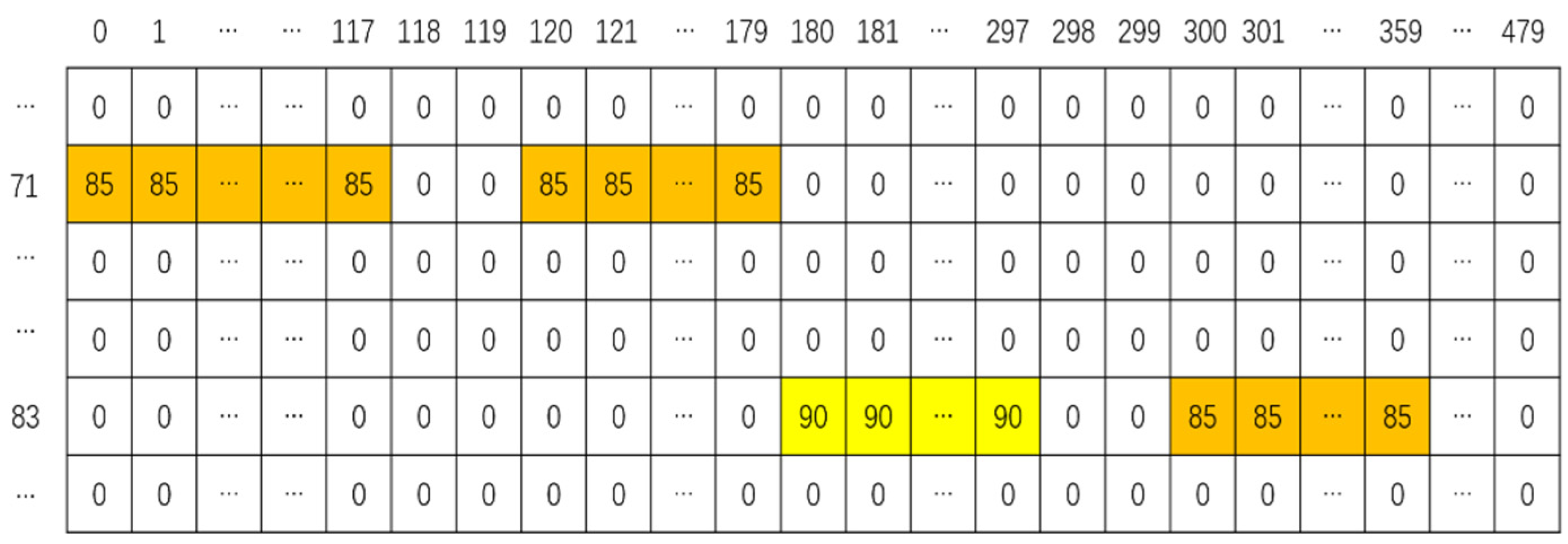
3.3. Bar Encoding
4. Experiments and Results
4.1. Experimental Objectives
4.2. Experimental Data
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Westen, D. Clinical assessment of object relations using the TAT. J. Personal. Assess. 1991, 56, 56–74. [Google Scholar] [CrossRef] [PubMed]
- Arnon, S.; Shapsa, A.; Forman, L.; Regev, R.; Litmanovitz, I.; Dolfin, T. Live music is beneficial to preterm infants in the neonatal intensive care unit environment. Birth 2006, 33, 131–136. [Google Scholar] [CrossRef] [PubMed]
- Jancke, L. Music, memory and emotion. J. Biol. 2008, 7, 82–86. [Google Scholar] [CrossRef] [PubMed]
- Cepeda, M.S.; Carr, D.B.; Lau, J.; Alvarez, H. Music for pain relief. Cochrane Database Syst. Rev. 2006, 2. [Google Scholar] [CrossRef]
- Trappe, H.J. The effects of music on the cardiovascular system and cardiovascular health. Heart 2010, 96, 1868–1871. [Google Scholar] [CrossRef] [PubMed]
- Leard, S.; Pietroletti, R.; Angeloni, G.; Necozione, S.; Ranalletta, G.; Gusto, B.D. Randomized clinical trial examining the effect of music therapy in stress response to day surgery. Br. J. Surg. 2007, 94, 943–947. [Google Scholar] [CrossRef] [PubMed]
- Spintge, R. Clinical Use of Music in Operating Theatres; Oxford University Press: Oxford, UK, 2012; pp. 277–286. [Google Scholar]
- Miranda, D.; Gaudreau, D.; Debrosse, D.; Morizot, D.; Kirmayer, L.J. Music listening and mental health: Variations on internalizing psychopathology. Music. Health Wellbeing 2012, 513–529. [Google Scholar] [CrossRef]
- Wiggins, G.A. Searching for computational creativity. New Gener. Comput. 2006, 24, 209–222. [Google Scholar] [CrossRef]
- Noaman, H.M.; Sarhan, S.S.; Rashwan, M.A.A. Enhancing recurrent neural network-based language models by word tokenization. Hum. Cent. Comput. Inf. Sci. 2018, 8, 12–24. [Google Scholar] [CrossRef]
- Ghrabat, M.J.J.; Ma, G.; Maolood, I.Y.; Alresheedi, S.S.; Abduljabbar, Z.A. An effective image retrieval based on optimized genetic algorithm utilized a novel SVM-based convolutional neural network classifier. Hum. Cent. Comput. Inf. Sci. 2019, 9, 31–59. [Google Scholar] [CrossRef]
- You, S.D.; Liu, C.H.; Chen, W.K. Comparative study of singing voice detection based on deep neural networks and ensemble learning. Hum. Cent. Comput. Inf. Sci. 2018, 8, 34–51. [Google Scholar] [CrossRef]
- De Prisco, R.; Malandrino, D.; Zaccagnino, G.; Zaccagnino, R. An Evolutionary Composer for Real-Time Background Music; Springer: Cham, Switzerland, 2016; pp. 135–151. [Google Scholar]
- Chou, H.; Chen, M.T.; Chi, T.S. A hybrid neural network based on the duplex model of pitch perception for singing melody extraction. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Danayi, A.; Seyedin, S. A novel algorithm based on time-frequency analysis for extracting melody from human whistling. In Proceedings of the 2018 4th Iranian Conference on Signal Processing and Intelligent Systems (ICSPIS), Tehran, Iran, 25–27 December 2018. [Google Scholar]
- Chen, L.; Ma, Y.J.; Zhang, J.; Wan, G.C.; Tong, M.S. A Novel Extraction Method for Melodic Features from MIDI Files Based on Probabilistic Graphical Models. In Proceedings of the 2018 Progress in Electromagnetics Research Symposium (PIERS-Toyama), Toyama, Japan, 1–4 August 2018. [Google Scholar]
- Lu, W.T.; Su, L. Deep Learning Models for Melody Perception: An Investigation on Symbolic Music Data. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018. [Google Scholar]
- Chenchen, K.; Yu, Y. Main Melody Extraction Using the Auditory Scene Analysis for the Humming Music Retrieval. In Proceedings of the 2018 14th IEEE International Conference on Signal Processing (ICSP), Beijing, China, 12–16 August 2018. [Google Scholar]
- Young, H. A categorial grammar for music and its use in automatic melody generation. In Proceedings of the 5th ACM SIGPLAN International Workshop on Functional Art, Music, Modeling, and Design, Oxford, UK, 9 September 2017. [Google Scholar]
- Prudente, L.; Coronel, A. Towards Automated Counter-Melody Generation for Monophonic Melodies. In Proceedings of the 2017 International Conference on Machine Learning and Soft Computing, Ho Chi Minh City, Vietnam, 13–16 January 2017. [Google Scholar]
- Zhu, H.; Liu, Q.; Yuan, N.J.; Qin, C.; Li, J.; Zhang, K.; Zhou, G.; Wei, F.; Xu, Y.; Chen, E. Xiaoice band: A melody and arrangement generation framework for pop music. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018. [Google Scholar]
- Chen, K.; Zhang, W.; Dubnov, S.; Xia, G.; Li, W. The effect of explicit structure encoding of deep neural networks for symbolic music generation. In Proceedings of the 2019 International Workshop on Multilayer Music Representation and Processing (MMRP), Milano, Italy, 23–24 January 2019. [Google Scholar]
- Sandred, O.; Laurson, M.; Kuuskankare, M. Revisiting the Illiac Suite—A rule-based approach to stochastic processes. Sonic Ideas Ideas Sonicas 2009, 2, 42–46. [Google Scholar]
- Cope, D. Experiments in musical intelligence (EMI): Non-linear linguistic-based composition. J. New Music. Res. 1989, 18, 117–139. [Google Scholar] [CrossRef]
- Mogren, O. C-RNN-GAN: Continuous recurrent neural networks with adversarial training. In Proceedings of the Constructive Machine Learning Workshop (CML) at NIPS 2016, Barcelona, Spain, 10 December 2016. stage of accepted. [Google Scholar]
- Kim, S.W.; Gi, M.J. Research paper classification systems based on TF-IDF and LDA schemes. Hum. Cent. Comput. Inf. Sci. 2019, 9, 30–50. [Google Scholar] [CrossRef]
- Pearce, M.T.; Wiggins, G.A. Towards a framework for the evaluation of machine compositions. In Proceedings of the AISB’01 Symposium on Artificial Intelligence and Creativity in the Arts and Sciences, York, UK, 21–24 March 2001. [Google Scholar]
- Yang, L.C.; Chou, S.Y.; Yang, Y.H. MidiNet: A convolutional generative adversarial network for symbolic-domain music generation. In Proceedings of the ISMIR Conference 2017, Suzhou, China, 23–27 October 2017. [Google Scholar]
- Uitdenbogerd, A.; Zobel, J. Melodic matching techniques for large music databases. In Proceedings of the Seventh ACM International Conference on Multimedia (Part 1), Orlando, FL, USA, 30 October–5 November 1999; pp. 57–66. [Google Scholar]
- Isikhan, C.; Ozcan, G. A survey of melody extraction techniques for music information retrieval. In Proceedings of the 4th Conference on Interdisciplinary Musicology (SIM’08), Thessaloniki, Greece, 3–6 July 2008. [Google Scholar]
- Ozcan, G.; Isikhan, C.; Alpkocak, A. Melody extraction on MIDI music files. In Proceedings of the Seventh IEEE International Symposium on Multimedia (ISM’05), Irvine, CA, USA, 14 December 2005. [Google Scholar]
- Uitdenbogerd, A.L.; Zobel, J. Music ranking techniques evaluated. Aust. Comput. Sci. Commun. 2002, 24, 275–283. [Google Scholar]
- Shan, M.K.; Kuo, F.F. Music style mining and classification by melody. IEICE Trans. Inf. Syst. 2003, 86, 655–659. [Google Scholar]
- Velusamy, S.; Thoshkahna, B.; Ramakrishnan, K.A. A novel melody line identification algorithm for polyphonic MIDI music. In International Conference on Multimedia Modeling; Springer: Berlin, Germany, 2007. [Google Scholar]
- Madsen, S.T.; Widmer, G. A complexity-based approach to melody track identification in midi files. In Proceedings of the International Workshop on Artificial Intelligence and Music 2007, Valencia, Spain, 11–13 April 2007. [Google Scholar]
- Michael, T.; Lap, Y.C.; Kao, B. Selection of melody lines for music databases. In Proceedings of the 24th Annual International Computer Software and Applications Conference, COMPSAC2000, Taipei, Taiwan, 25–27 October 2000. [Google Scholar]
- Li, J.; Yang, X.; Chen, Q. MIDI melody extraction based on improved neural network. In Proceedings of the 2009 International Conference on Machine Learning and Cybernetics, Baoding, China, 12–15 July 2009; pp. 1133–1138. [Google Scholar]
- Rizo, D.; De León, P.J.P.; Pérez-Sancho, C.; Pertusa, A.; Quereda, J.M.I. A pattern recognition approach for melody track selection in MIDI files. In Proceedings of the ISMIR, Victoria, BC, Canada, 8–12 October 2006; pp. 61–66. [Google Scholar]
- De León PJ, P.; Pérez-Sancho, C.; Inesta, J.M. A shallow description framework for musical style recognition. In Proceedings of the Joint IAPR International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition (SSPR), Lisbon, Portugal, 18–20 August 2004; pp. 876–884. [Google Scholar]
- Liang, Y.; Li, C.; Tian, L. Melody extraction from polyphonic music based on the amplitude relation. In Proceedings of the 2019 4th International Conference on Multimedia Systems and Signal Processing, Guangzhou, China, 10–12 May 2019; pp. 84–88. [Google Scholar]
- Dong, H.W.; Hsiao, W.I.; Yang, L.C.; Yang, Y.H. MuseGAN: Multi-track sequential generative adversarial networks for symbolic music generation and accompaniment. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 34–41. [Google Scholar]
- Chu, H.; Urtasun, R.; Fidler, S. Song from PI: A musically plausible network for pop music generation. In Proceedings of the International Conference on Learning Representations (ICLR), Scottsdale, AZ, USA, 24–26 April 2017. [Google Scholar]
- Bryan, N.J.; Mysore, G.J.; Wang, G. Source Separation of Polyphonic Music with Interactive User-Feedback on a Piano Roll Display. In Proceedings of the International Society for Music Information Retrieval (ISMIR), Curitiba, Brazil, 4–8 November 2013; pp. 119–124. [Google Scholar]
- Available online: http://www.classicalmidi.co.uk/ (accessed on 31 October 2019).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| C-RNN-GAN [25] | MidiNet [28] | MuseGAN [41] | Proposed Method | |
|---|---|---|---|---|
| Data representation | MIDI | MIDI | Piano-roll | MIDI |
| Encoding | Based notes | Based bars | Based notes | Based bars |
| Index | TFIDF (Minimum) | Average Pitch | Average Lasting Time | Average Intensity | Y/N |
|---|---|---|---|---|---|
| 1 | 0.045 | 71.285 | 0.810 | 83.027 | Y |
| 2 | 0.041 | 71.285 | 0.350 | 103.163 | Y |
| 3 | 0.025 | 68.694 | 0.501 | 79.956 | Y |
| 4 | 0.054 | 73.078 | 0.520 | 106.039 | Y |
| 5 | 0.037 | 71.651 | 0.681 | 100 | Y |
| 6 | 0.044 | 72.291 | 0.835 | 90 | Y |
| 7 | 0.045 | 67.778 | 0.679 | 100 | N |
| 8 | 0.079 | 73.914 | 0.530 | 100 | Y |
| … | … | … | … | … | … |
| 150 | 0.049 | 71.953 | 0.696 | 90 | Y |
| MIDI File Number | True | False | Accuracy |
|---|---|---|---|
| 150 | 142 | 8 | 94.7% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Jang, S.; Sung, Y. Melody Extraction and Encoding Method for Generating Healthcare Music Automatically. Electronics 2019, 8, 1250. https://doi.org/10.3390/electronics8111250
Li S, Jang S, Sung Y. Melody Extraction and Encoding Method for Generating Healthcare Music Automatically. Electronics. 2019; 8(11):1250. https://doi.org/10.3390/electronics8111250
Chicago/Turabian StyleLi, Shuyu, Sejun Jang, and Yunsick Sung. 2019. "Melody Extraction and Encoding Method for Generating Healthcare Music Automatically" Electronics 8, no. 11: 1250. https://doi.org/10.3390/electronics8111250
APA StyleLi, S., Jang, S., & Sung, Y. (2019). Melody Extraction and Encoding Method for Generating Healthcare Music Automatically. Electronics, 8(11), 1250. https://doi.org/10.3390/electronics8111250