EEG-Based 3D Visual Fatigue Evaluation Using CNN


Abstract
1. Introduction
2. Related Work
3. Method
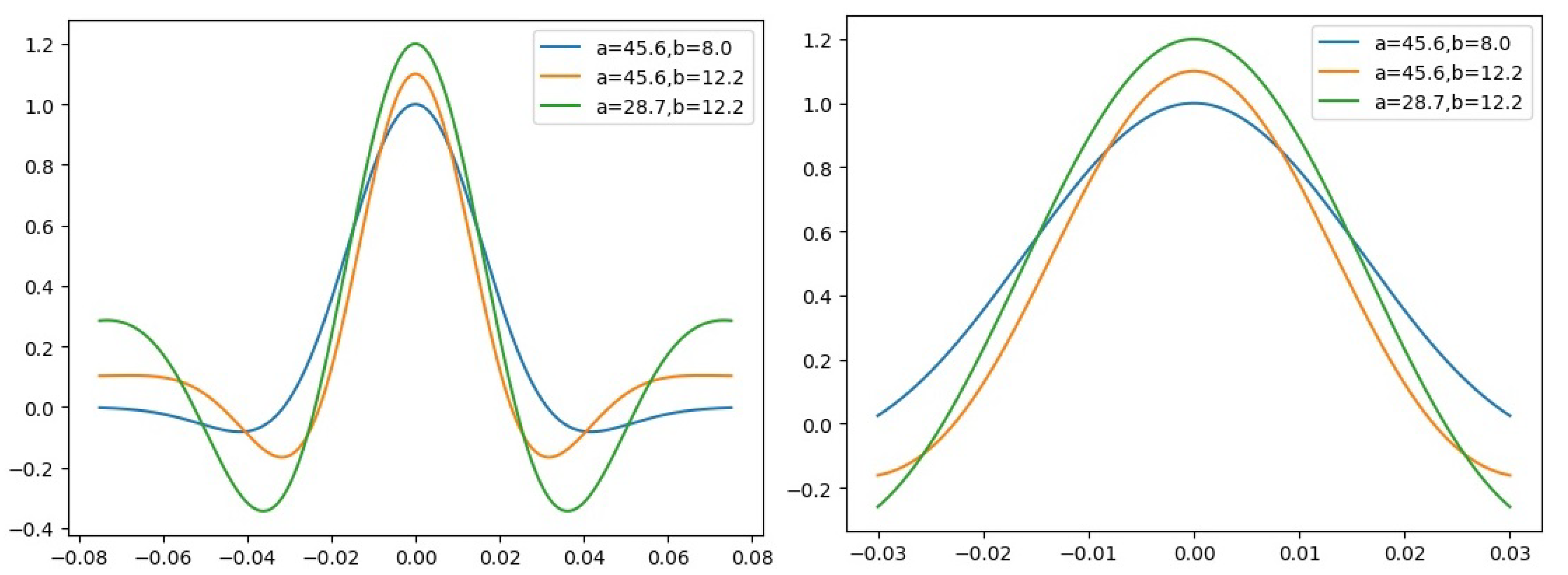
3.1. Motivation and High-Level Considerations
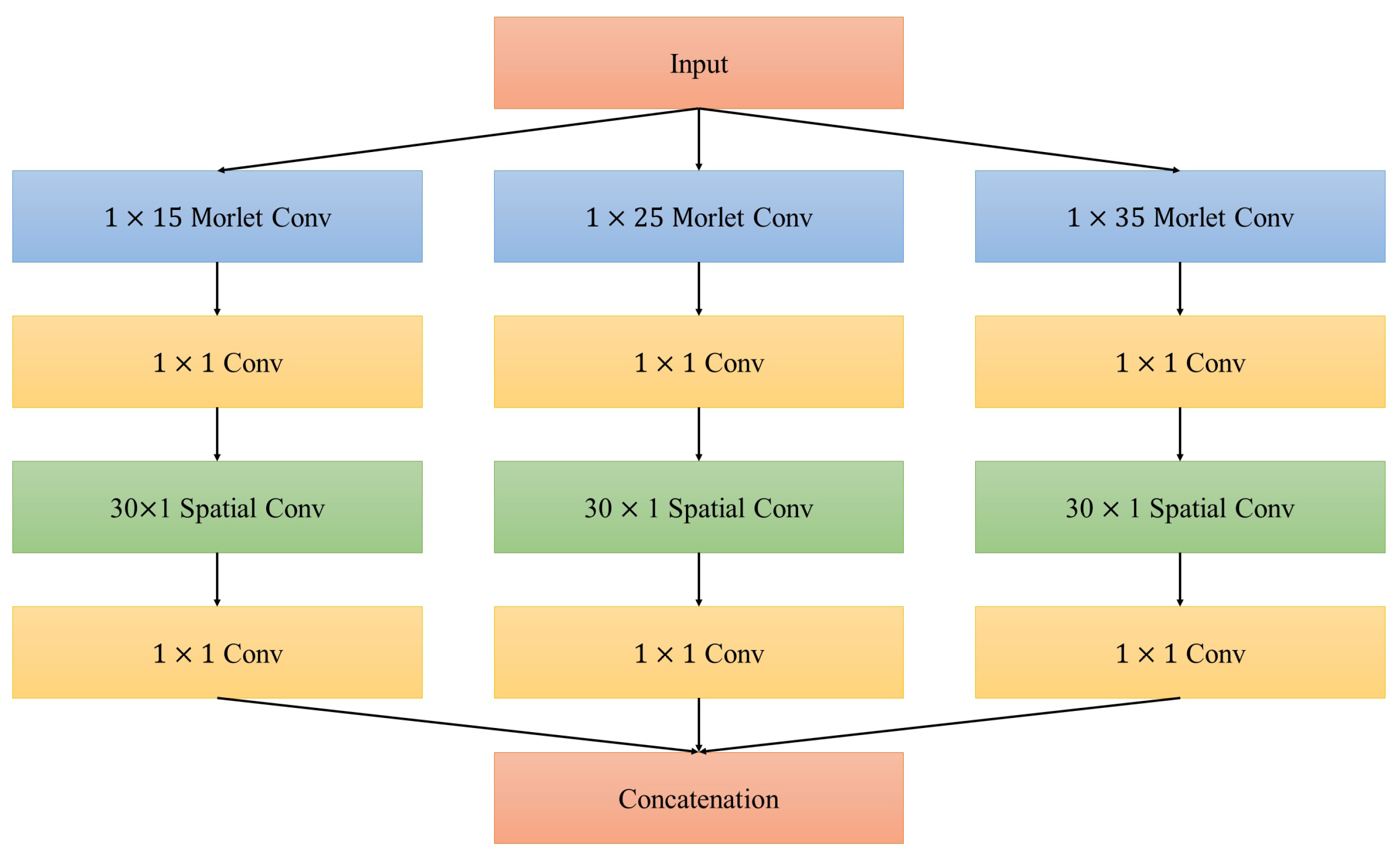
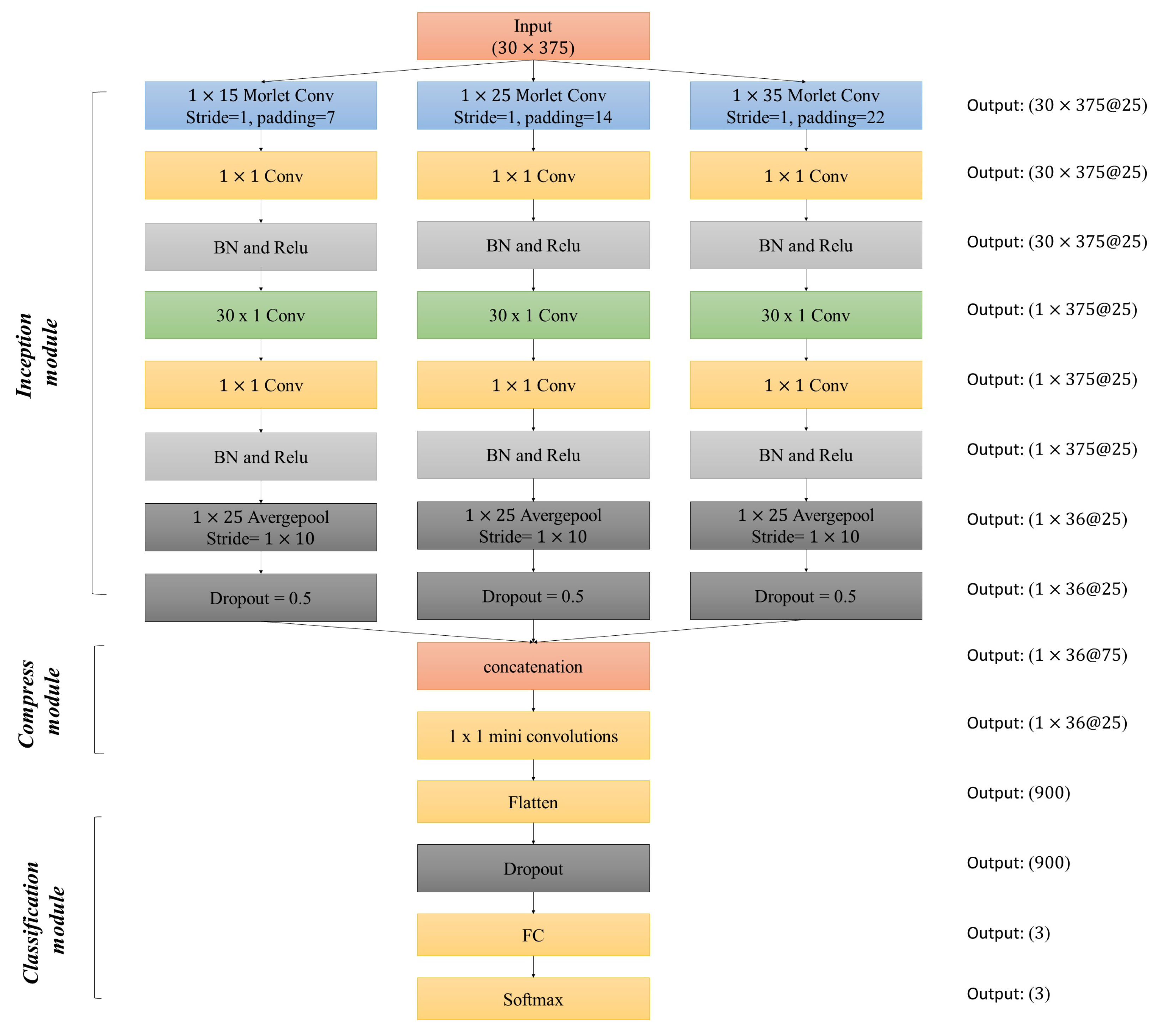
3.2. Architectural Details
3.3. Morletinceptionnet
4. Visual Fatigue Experiment
4.1. Subject
4.2. Experiment Protocol
4.3. Data Recording and Preprocessing
5. Results
5.1. Baseline Methods and Performance Metrics
- CNNInceptionNet: Replace the morlet layer in the proposed MorletInceptionNet with regular convolutional lay to validate the effectiveness of the morlet kernel.
- Shallow ConvNet [13]: Inspired by FBCSP algorithm, Shallow ConvNet extract features in a similar way. But Shallow ConvNet uses a convolutional neural network to do all the computations and all the steps are optimized in an end-to-end manner.
- Deep ConvNet [13]: It has four convolution-pooling blocks and is much deeper than Shallow ConvNet.
- EEGNet [15]: It has two convolution-pooling blocks. The difference between EEGNet and ConvNets introduced above is that EEGNet uses depth-wise and separable convolution.
- MorletNet: Replace the first layer of Shallow ConvNet with morlet layer. The sub-architecture of inception module proposed in this paper is similar with Shallow ConvNet. This network is used to validate the effectiveness of morlet kernel by comparing with Shallow ConvNet, as well as the effectiveness of proposed inception architecture by comparing with MorletInceptionNet.
- FBCSP-SVM [23]: A traditional augmented-CSP algorithm using overlapping frequency bands. The log-energy features are extracted for each frequency band in spatial transformed EEG signal. The extracted features are then passed into SVM for classification. We adopt one-vs-rest strategy for multi-class classification.
- 2DRCNN [16]: It has 3 stacked convolutional layers to extract spatial information and then the feature maps are passed into a single LSTM layer with 32 memory cells to extract temporal information in EEG.
5.2. Classification Performances
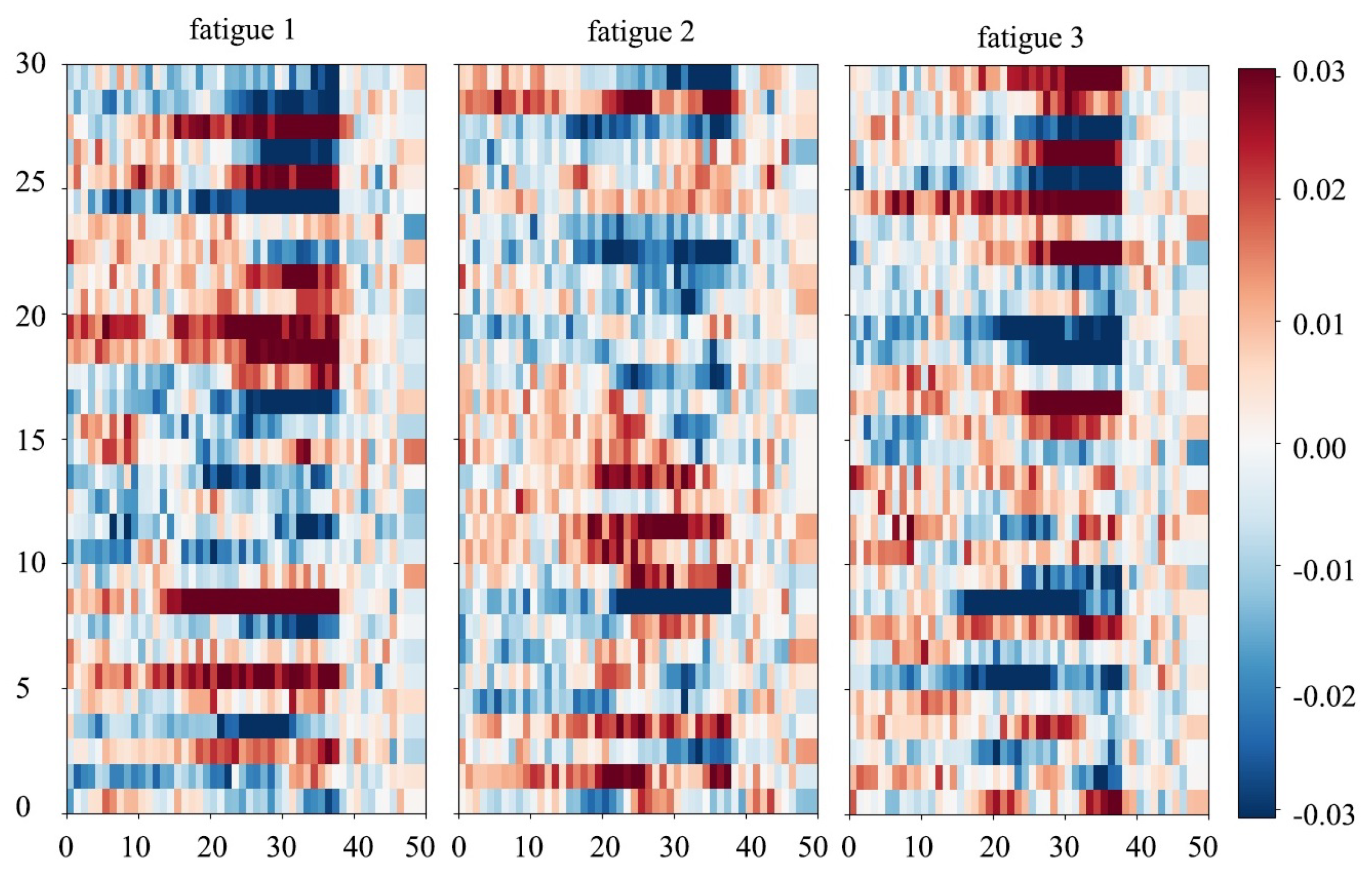
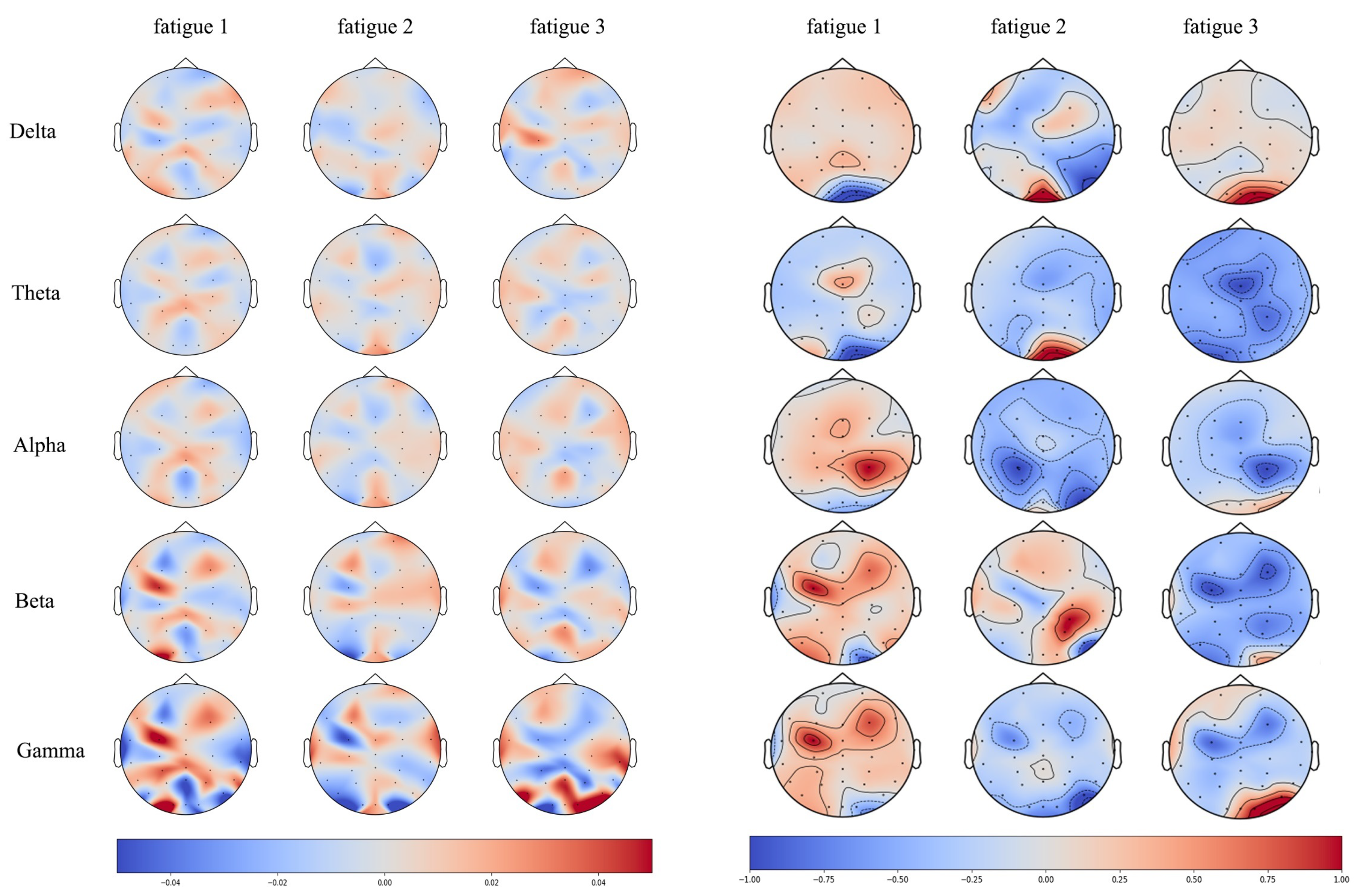
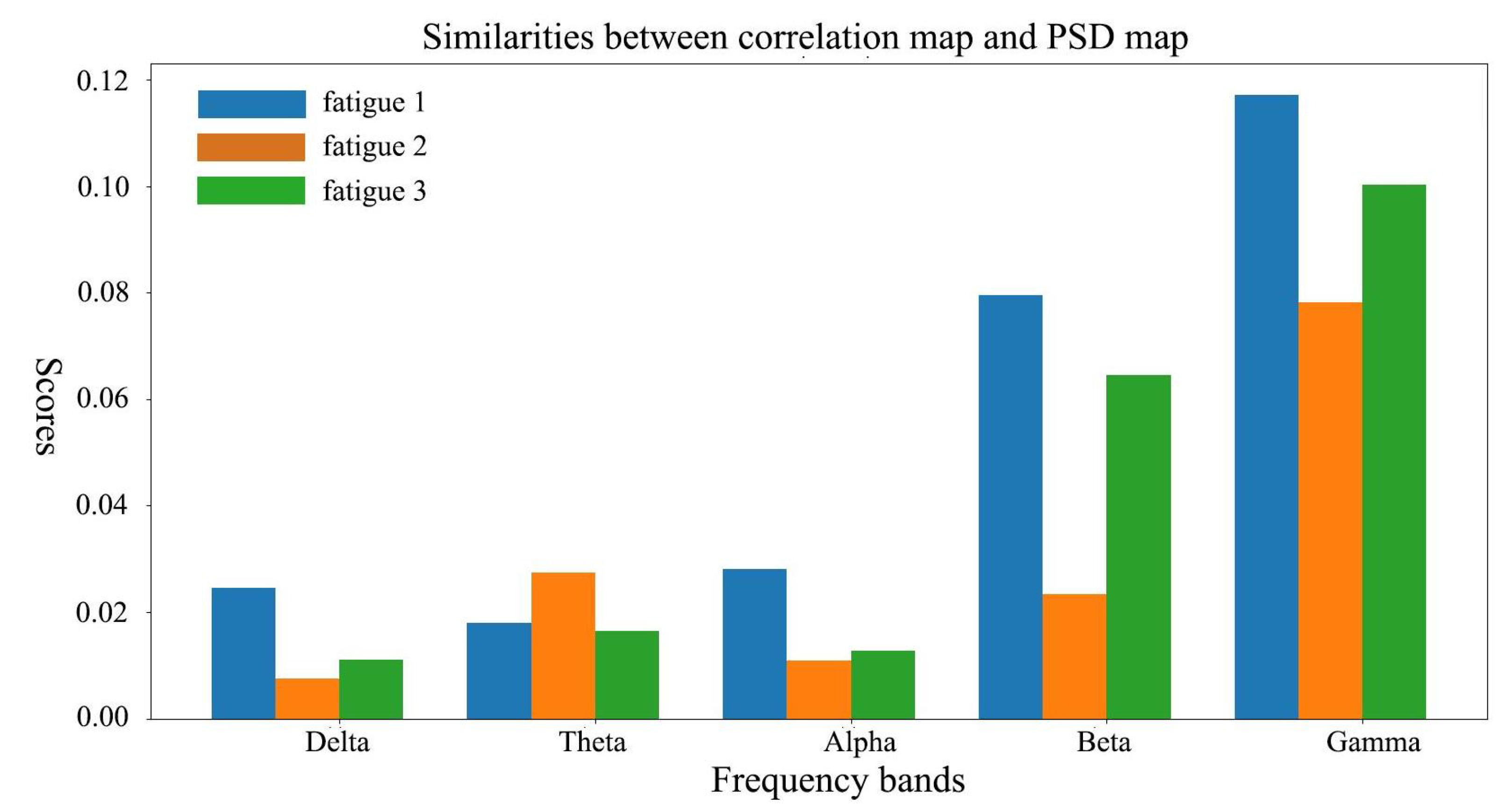
5.3. Visualizing the Learned Representation
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lambooij, M.; Fortuin, M.; Heynderickx, I.; IJsselsteijn, W. Visual discomfort and visual fatigue of stereoscopic displays: A review. J. Imaging Sci. Technol. 2009, 53, 30201-1–30201-14. [Google Scholar] [CrossRef]
- Zhang, L.; Ren, J.; Xu, L.; Qiu, X.J.; Jonas, J.B. Visual comfort and fatigue when watching three-dimensional displays as measured by eye movement analysis. Br. J. Ophthalmol. 2013, 97, 941–942. [Google Scholar] [CrossRef] [PubMed]
- Wook Wee, S.; Moon, N.J. Clinical evaluation of accommodation and ocular surface stability relavant to visual asthenopia with 3D displays. BMC Ophthalmol. 2014, 14, 29. [Google Scholar]
- Neveu, P.; Roumes, C.; Philippe, M.; Fuchs, P.; Priot, A.E. Stereoscopic Viewing Can Induce Changes in the CA/C Ratio. Investig. Ophthalmol. Vis. Sci. 2016, 57, 4321–4326. [Google Scholar] [CrossRef]
- Yu, J.H.; Lee, B.H.; Kim, D.H. EOG based eye movement measure of visual fatigue caused by 2D and 3D displays. In Proceedings of the 2012 IEEE-EMBS International Conference on Biomedical and Health Informatics, Hong Kong, China, 5–7 January 2012; pp. 305–308. [Google Scholar]
- Park, S.; Won, M.J.; Mun, S.; Lee, E.C.; Whang, M. Does visual fatigue from 3D displays affect autonomic regulation and heart rhythm. Int. J. Psychophysiol. 2014, 92, 42–48. [Google Scholar] [CrossRef]
- Park, S.; Won, M.J.; Lee, E.C.; Mun, S.; Park, M.C.; Whang, M. Evaluation of 3D cognitive fatigue using heart–brain synchronization. Int. J. Psychophysiol. 2015, 97, 120–130. [Google Scholar] [CrossRef]
- Ma, X.; Huang, X.; Shen, Y.; Qin, Z.; Ge, Y.; Chen, Y.; Ning, X. EEG based topography analysis in string recognition task. Phys. A Stat. Mech. Its Appl. 2017, 469, 531–539. [Google Scholar] [CrossRef]
- Sanei, S.; Chambers, J.A. EEG Signal Processing; John Wiley Sons, Ltd.: Hoboken, NJ, USA, 2007; pp. 127–156. [Google Scholar]
- Chen, C.; Li, K.; Wu, Q.; Wang, H.; Qian, Z.; Sudlow, G. EEG-based detection and evaluation of fatigue caused by watching 3DTV. Displays 2013, 34, 81–88. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Abdel-Hamid, O.; Mohamed, A.R.; Jiang, H.; Deng, L.; Penn, G.; Yu, D. Convolutional neural networks for speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef]
- Schirrmeister, R.T.; Springenberg, J.T.; Fiederer, L.D.J.; Glasstetter, M.; Eggensperger, K.; Tangermann, M.; Hutter, F.; Burgard, W.; Ball, T. Deep learning with convolutional neural networks for EEG decoding and visualization. Hum. Brain Mapp. 2017, 38, 5391–5420. [Google Scholar] [CrossRef]
- Zhang, D.; Yao, L.; Chen, K.; Wang, S.; Chang, X.; Liu, Y. Making Sense of Spatio-Temporal Preserving Representations for EEG-Based Human Intention Recognition. IEEE Trans. Cybern. 2019. [Google Scholar] [CrossRef] [PubMed]
- Lawhern, V.J.; Solon, A.J.; Waytowich, N.R.; Gordon, S.M.; Hung, C.P.; Lance, B.J. EEGNet: A compact convolutional neural network for EEG-based brain–computer interfaces. J. Neural Eng. 2018, 15, 056013. [Google Scholar] [CrossRef] [PubMed]
- Maddula, R.; Stivers, J.; Mousavi, M.; Ravindran, S.; de Sa, V. Deep Recurrent Convolutional Neural Networks for Classifying P300 BCI signals. In Proceedings of the 7th Graz Brain-Computer Interface Conference (GBCIC 2017), Graz, Austria, 18–22 September 2017. [Google Scholar]
- Bashivan, P.; Rish, I.; Yeasin, M.; Codella, N. Learning representations from EEG with deep recurrent-convolutional neural networks. arXiv 2015, arXiv:1511.06448. [Google Scholar]
- Kim, Y.J.; Lee, E.C. EEG based comparative measurement of visual fatigue caused by 2D and 3D displays. In Proceedings of the International Conference on Human-Computer Interaction, Orlando, FL, USA, 9–14 July 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 289–292. [Google Scholar]
- Yin, J.; Jin, J.; Liu, Z.; Yin, T. Preliminary study on EEG-based analysis of discomfort caused by watching 3D images. In Advances in Cognitive Neurodynamics (IV); Springer: Dordrecht, The Netherlands, 2015; pp. 329–335. [Google Scholar]
- Guo, M.; Liu, Y.; Zou, B.; Wang, Y. Study of electroencephalography-based objective stereoscopic visual fatigue evaluation. In Proceedings of the 2015 International Symposium on Bioelectronics and Bioinformatics (ISBB), Beijing, China, 14–17 October 2015; pp. 160–163. [Google Scholar]
- Hsu, B.W.; Wang, M.J.J. Evaluating the effectiveness of using electroencephalogram power indices to measure visual fatigue. Percept. Motor Skills 2013, 116, 235–252. [Google Scholar] [CrossRef] [PubMed]
- Ramoser, H.; Muller-Gerking, J.; Pfurtscheller, G. Optimal spatial filtering of single trial EEG during imagined hand movement. IEEE Trans. Rehabil. Eng. 2000, 8, 441–446. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.; Sakhavi, S.; Ang, K.K.; Guan, C. On the use of convolutional neural networks and augmented CSP features for multi-class motor imagery of EEG signals classification. In Proceedings of the 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Milan, Italy, 25–29 August 2015; pp. 2620–2623. [Google Scholar]
- Croce, P.; Zappasodi, F.; Marzetti, L.; Merla, A.; Pizzella, V.; Chiarelli, A.M. Deep Convolutional Neural Networks for feature-less automatic classification of Independent Components in multi-channel electrophysiological brain recordings. IEEE Trans. Biomed. Eng. 2018. [Google Scholar] [CrossRef]
- Chiarelli, A.M.; Croce, P.; Merla, A.; Zappasodi, F. Deep learning for hybrid EEG-fNIRS brain–computer interface: Application to motor imagery classification. J. Neural Eng. 2018, 15, 036028. [Google Scholar] [CrossRef]
- Emami, A.; Kunii, N.; Matsuo, T.; Shinozaki, T.; Kawai, K.; Takahashi, H. Seizure detection by convolutional neural network-based analysis of scalp electroencephalography plot images. NeuroImage Clin. 2019, 22, 101684. [Google Scholar] [CrossRef]
- Fahimi, F.; Zhang, Z.; Goh, W.B.; Lee, T.S.; Ang, K.K.; Guan, C. Inter-subject transfer learning with end-to-end deep convolutional neural network for EEG-based BCI. J. Neural Eng. 2019, 16, 2. [Google Scholar] [CrossRef]
- Zhao, D.; Tang, F.; Si, B.; Feng, X. Learning joint space–time–frequency features for EEG decoding on small labeled data. Neural Netw. 2019, 114, 67–77. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26–30 June 2016; pp. 2818–2826. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Mullen, T.R.; Kothe, C.A.; Chi, Y.M.; Ojeda, A.; Kerth, T.; Makeig, S.; Jung, T.P.; Cauwenberghs, G. Real-time neuroimaging and cognitive monitoring using wearable dry EEG. IEEE Trans. Biomed. Eng. 2015, 62, 2553–2567. [Google Scholar] [CrossRef] [PubMed]
- Kravitz, D.J.; Saleem, K.S.; Baker, C.I.; Mishkin, M. A new neural framework for visuospatial processing. Nat. Rev. Neurosci. 2011, 12, 217. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Wang, J.; Liu, Y.; Chen, X. Using Bold-fMRI to detect cortical areas and visual fatigue related to stereoscopic vision. Displays 2017, 50, 14–20. [Google Scholar] [CrossRef]
- Kim, D.; Jung, Y.J.; Han, Y.J.; Choi, J.; Kim, E.W.; Jeong, B.; Ro, Y.; Park, H. fMRI analysis of excessive binocular disparity on the human brain. Int. J. Imaging Syst. Technol. 2014, 24, 94–102. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Net | Number of Parameters |
|---|---|
| CNNInceptionNet | 67,078 |
| Shallow ConvNet | 51,403 |
| Deep ConvNet | 163,478 |
| EEGNet | 2115 |
| MorletNet | 54,703 |
| 2DRCNN | over 130,000,000 |
| MorletInceptionNet | 65,278 |
| Subject | Deep4 ConvNet | EEGNet4 | Shallow ConvNet | MorletNet | MorletInceptionNet | CNNInceptionNet | FBCSP-SVM | 2DRCNN |
|---|---|---|---|---|---|---|---|---|
| s1 | 0.21 ± 0.03 | 0.20 ± 0.04 | 0.33 ± 0.06 | 0.40 ± 0.04 | 0.41 ± 0.05 | 0.39 ± 0.06 | 0.36 ± 0.04 | 0.30 ± 0.03 |
| s2 | 0.15 ± 0.03 | 0.42 ± 0.05 | 0.51 ± 0.06 | 0.55 ± 0.08 | 0.54 ± 0.02 | 0.53 ± 0.06 | 0.52 ± 0.05 | 0.46 ± 0.04 |
| s3 | 0.72 ± 0.05 | 0.73 ± 0.09 | 0.71 ± 0.03 | 0.72 ± 0.05 | 0.76 ± 0.04 | 0.76 ± 0.04 | 0.71 ± 0.03 | 0.68 ± 0.05 |
| s4 | 0.32 ± 0.02 | 0.33 ± 0.08 | 0.46 ± 0.02 | 0.54 ± 0.06 | 0.52 ± 0.04 | 0.52 ± 0.03 | 0.48 ± 0.03 | 0.46 ± 0.02 |
| s5 | 0.26 ± 0.08 | 0.37 ± 0.06 | 0.54 ± 0.04 | 0.48 ± 0.06 | 0.50 ± 0.04 | 0.52 ± 0.05 | 0.51 ± 0.04 | 0.43 ± 0.04 |
| s6 | 0.07 ± 0.05 | 0.10 ± 0.07 | 0.30 ± 0.02 | 0.24 ± 0.08 | 0.32 ± 0.05 | 0.30 ± 0.07 | 0.30 ± 0.02 | 0.26 ± 0.05 |
| s7 | 0.25 ± 0.08 | 0.26 ± 0.09 | 0.50 ± 0.05 | 0.42 ± 0.07 | 0.45 ± 0.09 | 0.41 ± 0.07 | 0.48 ± 0.03 | 0.39 ± 0.04 |
| s8 | 0.10 ± 0.07 | 0.29 ± 0.05 | 0.43 ± 0.13 | 0.38 ± 0.05 | 0.44 ± 0.05 | 0.44 ± 0.07 | 0.41 ± 0.04 | 0.36 ± 0.06 |
| s9 | 0.09 ± 0.02 | 0.18 ± 0.02 | 0.25 ± 0.03 | 0.27 ± 0.07 | 0.28 ± 0.07 | 0.27 ± 0.05 | 0.27 ± 0.05 | 0.19 ± 0.04 |
| s10 | 0.20 ± 0.04 | 0.17 ± 0.13 | 0.28 ± 0.08 | 0.29 ± 0.10 | 0.31 ± 0.09 | 0.30 ± 0.09 | 0.30 ± 0.06 | 0.29 ± 0.07 |
| s11 | 0.55 ± 0.10 | 0.55 ± 0.09 | 0.44 ± 0.14 | 0.44 ± 0.06 | 0.52 ± 0.08 | 0.52 ± 0.10 | 0.48 ± 0.03 | 0.45 ± 0.03 |
| s12 | 0.01 ± 0.03 | 0.01 ± 0.06 | 0.04 ± 0.04 | 0.10 ± 0.05 | 0.18 ± 0.10 | 0.13 ± 0.08 | 0.15 ± 0.09 | 0.16 ± 0.04 |
| s13 | 0.27 ± 0.03 | 0.41 ± 0.07 | 0.52 ± 0.05 | 0.55 ± 0.07 | 0.58 ± 0.04 | 0.52 ± 0.03 | 0.56 ± 0.04 | 0.47 ± 0.04 |
| s14 | 0.17 ± 0.06 | 0.19 ± 0.05 | 0.51 ± 0.04 | 0.47 ± 0.05 | 0.52 ± 0.05 | 0.49 ± 0.05 | 0.50 ± 0.05 | 0.46 ± 0.05 |
| s15 | 0.46 ± 0.10 | 0.40 ± 0.06 | 0.47 ± 0.05 | 0.49 ± 0.08 | 0.51 ± 0.09 | 0.51 ± 0.04 | 0.47 ± 0.04 | 0.44 ± 0.03 |
| s16 | 0.34 ± 0.07 | 0.35 ± 0.08 | 0.45 ± 0.05 | 0.46 ± 0.01 | 0.42 ± 0.05 | 0.47 ± 0.02 | 0.41 ± 0.01 | 0.36 ± 0.01 |
| AVG | 0.26 ± 0.05 | 0.31 ± 0.07 | 0.42 ± 0.06 | 0.43 ± 0.06 | 0.45 ± 0.06 | 0.44 ± 0.06 | 0.43 ± 0.04 | 0.38 ± 0.04 |
| Cross-subject | 0.31 ± 0.04 | 0.35 ± 0.05 | 0.50 ± 0.05 | 0.50 ± 0.04 | 0.61 ± 0.06 | 0.57 ± 0.07 | 0.52 ± 0.05 | 0.48 ± 0.06 |
| Subject | Deep4 ConvNet | EEGNet4 | Shallow ConvNet | MorletNet | MorletInceptionNet | CNNInceptionNet | FBCSP-SVM | 2DRCNN |
|---|---|---|---|---|---|---|---|---|
| s1 | 0.42 ± 0.02 | 0.45 ± 0.02 | 0.58 ± 0.02 | 0.65 ± 0.01 | 0.63 ± 0.03 | 0.62 ± 0.03 | 0.57 ± 0.02 | 0.48 ± 0.03 |
| s2 | 0.39 ± 0.05 | 0.63 ± 0.01 | 0.76 ± 0.03 | 0.78 ± 0.01 | 0.77 ± 0.02 | 0.79 ± 0.02 | 0.73 ± 0.02 | 0.64 ± 0.01 |
| s3 | 0.84 ± 0.01 | 0.86 ± 0.02 | 0.86 ± 0.02 | 0.85 ± 0.02 | 0.86 ± 0.02 | 0.86 ± 0.00 | 0.84 ± 0.01 | 0.84 ± 0.02 |
| s4 | 0.54 ± 0.03 | 0.53 ± 0.02 | 0.66 ± 0.01 | 0.69 ± 0.02 | 0.71 ± 0.02 | 0.69 ± 0.02 | 0.54 ± 0.03 | 0.51 ± 0.02 |
| s5 | 0.56 ± 0.04 | 0.57 ± 0.05 | 0.70 ± 0.01 | 0.69 ± 0.02 | 0.73 ± 0.02 | 0.71 ± 0.01 | 0.71 ± 0.02 | 0.69 ± 0.02 |
| s6 | 0.51 ± 0.02 | 0.53 ± 0.04 | 0.67 ± 0.01 | 0.63 ± 0.03 | 0.63 ± 0.03 | 0.59 ± 0.04 | 0.63 ± 0.01 | 0.58 ± 0.01 |
| s7 | 0.64 ± 0.04 | 0.65 ± 0.03 | 0.78 ± 0.01 | 0.74 ± 0.02 | 0.74 ± 0.01 | 0.74 ± 0.02 | 0.74 ± 0.02 | 0.65 ± 0.03 |
| s8 | 0.84 ± 0.01 | 0.84 ± 0.02 | 0.87 ± 0.02 | 0.86 ± 0.02 | 0.88 ± 0.02 | 0.87 ± 0.02 | 0.85 ± 0.02 | 0.85 ± 0.03 |
| s9 | 0.52 ± 0.02 | 0.48 ± 0.03 | 0.58 ± 0.01 | 0.58 ± 0.02 | 0.62 ± 0.01 | 0.59 ± 0.02 | 0.58 ± 0.04 | 0.53 ± 0.04 |
| s10 | 0.75 ± 0.02 | 0.74 ± 0.04 | 0.86 ± 0.01 | 0.85 ± 0.01 | 0.85 ± 0.02 | 0.85 ± 0.01 | 0.76 ± 0.02 | 0.82 ± 0.01 |
| s11 | 0.88 ± 0.05 | 0.90 ± 0.01 | 0.89 ± 0.01 | 0.86 ± 0.01 | 0.88 ± 0.02 | 0.90 ± 0.02 | 0.84 ± 0.05 | 0.88 ± 0.02 |
| s12 | 0.59 ± 0.02 | 0.58 ± 0.02 | 0.68 ± 0.01 | 0.74 ± 0.02 | 0.74 ± 0.01 | 0.74 ± 0.02 | 0.74 ± 0.02 | 0.73 ± 0.01 |
| s13 | 0.50 ± 0.03 | 0.56 ± 0.02 | 0.63 ± 0.02 | 0.65 ± 0.01 | 0.69 ± 0.03 | 0.63 ± 0.03 | 0.65 ± 0.02 | 0.63 ± 0.02 |
| s14 | 0.41 ± 0.03 | 0.46 ± 0.03 | 0.67 ± 0.03 | 0.67 ± 0.02 | 0.68 ± 0.01 | 0.67 ± 0.02 | 0.66 ± 0.01 | 0.64 ± 0.02 |
| s15 | 0.79 ± 0.01 | 0.71 ± 0.03 | 0.77 ± 0.01 | 0.78 ± 0.02 | 0.80 ± 0.01 | 0.80 ± 0.02 | 0.77 ± 0.03 | 0.77 ± 0.02 |
| s16 | 0.56 ± 0.03 | 0.59 ± 0.07 | 0.63 ± 0.03 | 0.64 ± 0.01 | 0.69 ± 0.01 | 0.65 ± 0.02 | 0.65 ± 0.02 | 0.62 ± 0.04 |
| AVG | 0.61 ± 0.03 | 0.63 ± 0.03 | 0.73 ± 0.02 | 0.73 ± 0.01 | 0.74 ± 0.02 | 0.73 ± 0.02 | 0.70 ± 0.02 | 0.67 ± 0.02 |
| Cross-subject | 0.67 ± 0.02 | 0.68 ± 0.02 | 0.73 ± 0.04 | 0.71 ± 0.02 | 0.74 ± 0.03 | 0.72 ± 0.03 | 0.73 ± 0.03 | 0.71 ± 0.02 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yue, K.; Wang, D. EEG-Based 3D Visual Fatigue Evaluation Using CNN. Electronics 2019, 8, 1208. https://doi.org/10.3390/electronics8111208
Yue K, Wang D. EEG-Based 3D Visual Fatigue Evaluation Using CNN. Electronics. 2019; 8(11):1208. https://doi.org/10.3390/electronics8111208
Chicago/Turabian StyleYue, Kang, and Danli Wang. 2019. "EEG-Based 3D Visual Fatigue Evaluation Using CNN" Electronics 8, no. 11: 1208. https://doi.org/10.3390/electronics8111208
APA StyleYue, K., & Wang, D. (2019). EEG-Based 3D Visual Fatigue Evaluation Using CNN. Electronics, 8(11), 1208. https://doi.org/10.3390/electronics8111208