4.1. Dataset
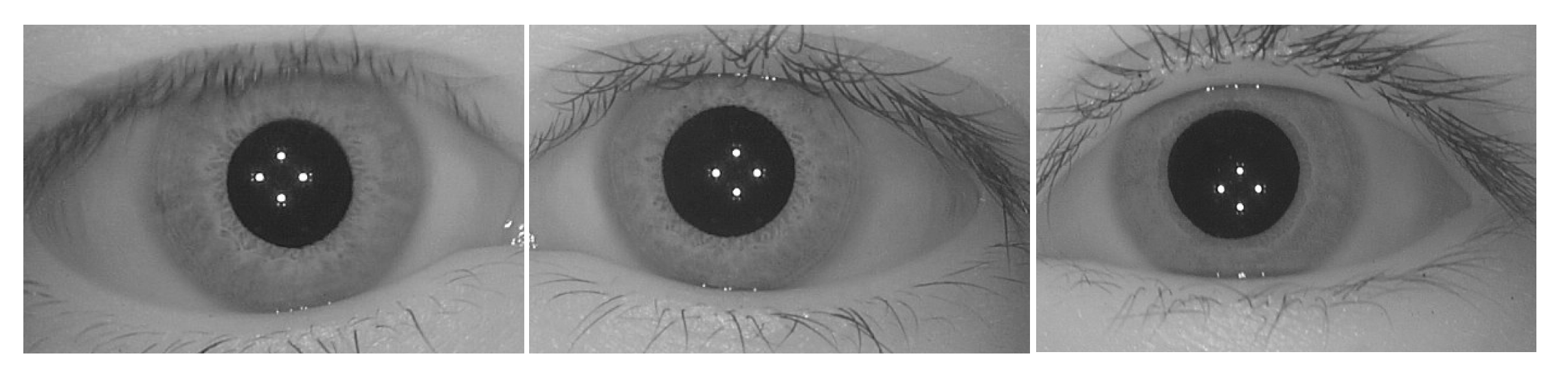
In order to carry out experiments on the classification of genetically identical left–right irises using the above VGG16 architecture, two independent datasets were used. The iris images of the first dataset were collected by the authors using a home-developed hand-held iris capture device in near-infrared illumination. This dataset, referred to as the CAS-SIAT-Iris dataset (here “CAS-SIAT” stands for Chinese Academy of Sciences’ Shenzhen Institutes of Advanced Technology), contains 3365 pairs of left and right iris images taken from 3365 subjects. These images went through quality assessment and careful screening before saving in 8-bit greyscale BMP format at
pixels resolution, as shown in
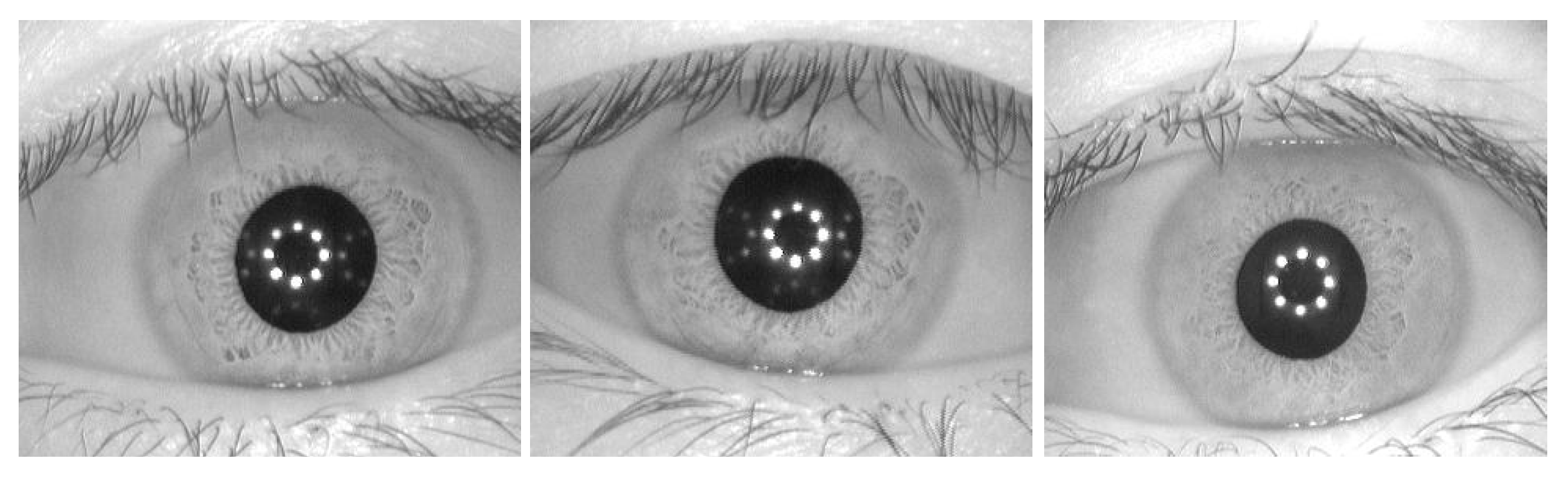
Figure 2. The other is the CASIA-Iris-Interval dataset (here “CASIA” stands for Chinese Academy of Sciences’ Institute of Automation) [
27], which contains 2655 iris images in 8-bit grayscale JPEG format of
pixels taken from 249 subjects, as illustrated by
Figure 3. We note that there is more than one image taken from the same iris for the CASIA-Iris-Interval dataset.
4.2. Data Preprocessing
In order to extract the iris texture feature, an iris image as illustrated by
Figure 4a needs to be preprocessed. The iris texture region outlined by the red inner and green outer circles is first segmented from the iris image. This process is known as the iris localization. The annular region of the iris is then unwrapped into an isolated rectangular image of fixed
pixels, as shown by
Figure 4b. This process known as iris normalization is performed based on Daugman’s rubber-sheet model [
4]. Finally, the contrast of the normalized iris image is further enhanced by histogram equalization so as to improve the clarity of the iris texture, as shown by
Figure 4c.
To classify whether two irises (left and right) are from the same or different individuals using the as-modified VGG16 model, we carried out feature fusion of a left and a right greyscale irises so as to form an RGB image as the model input. We combined left and right iris images and a blank image (all pixels have a value of zero), all of which are 8-bit greyscale, into an RGB24 image, as illustrated in
Figure 5.
In order to examine the robustness and versatility of the model, we performed classification experiments using both the CAS-SIAT-Iris and the CASIA-Iris-Interval datasets as well as cross datasets, in both the person-disjoint and non-person-disjoint manners, and with and without image augmentation. Here, the person-disjoint manner means that there is no overlap of the subjects in the training, validation and test sets. In other words, if an iris image of a subject is used in the training set, any iris image of that subject will no longer be used in the validation set or the test set. For the non-person-disjoint manner, however, although there are no repeated iris images in the training, validation and test sets, there are overlapped subjects. The image augmentation is performed by image translations, horizontal reflections and zooms, so as to enlarge the database for achieving better performance.
We first performed experiments by training the network using the CAS-SIAT-Iris dataset. We constructed 3365 positive samples, each corresponds to a subject, and 2500 negative samples, which are randomly selected. Here, a positive or negative sample indicates that the input two irises (left and right) are from the same or different individuals. Both the positive and negative samples were partitioned in a person-disjoint manner into the training, validation and test sets with an approximate ratio of 7:2:1. Moreover, we further tested the as-trained network using the CASIA-Iris-Interval dataset, from which 215 positive samples and 200 negative samples were constructed. The numbers of partitioned samples are shown in
Table 1.
We also performed similar experiments by first training the network with the CASIA-Iris-Interval dataset, and then testing with both datasets. Since the CASIA-Iris-Interval dataset containing only 2655 iris images from 249 subjects is relatively small, we artificially enlarged the database using label-preserving transformations to improve the model accuracy and to keep from over-fitting. In this way, we constructed 4075 positive samples and 4115 negative samples, which were partitioned in a non-person-disjoint manner into the training, validation and test sets with approximate ratios of 85.6%, 7.1% and 7.3%, respectively. Moreover, the as-trained network was further tested using the CAS-SIAT-Iris dataset, from which the 600 positive and 400 negative samples were constructed. The numbers of samples are shown in
Table 2.
4.3. Results and Discussion
The as-modified VGG16 model was implemented using the Keras library. A learning rate of 0.0001, a batch-size of 128, the SGD optimizer, the categorical_crossentropy loss, and a strategy of 50 epochs per round until convergence were adopted for the training. Classification experiments were carried out on a high-performance computer with two Intel® Xeon® E5-2699 V4 processors (2.20 GHz), 256 GB RAM and a NVIDIA® Quadro GP100 GPU.
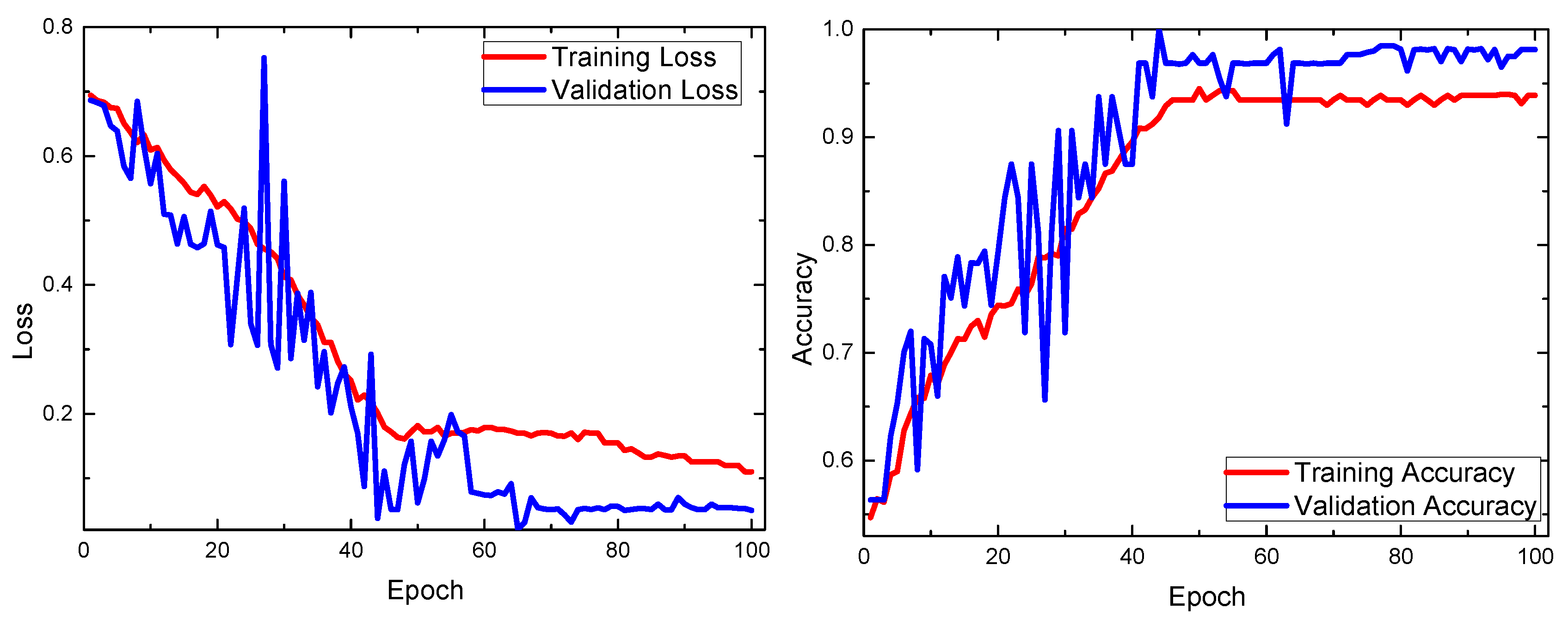
Figure 6 shows that the training and validation loss curves keep decreasing while the accuracy curves approach 100%. These model learning curves indicate that high accuracy and relatively fast convergence can be achieved within 100 epochs.
The confusion matrices for the networks trained by the CAS-SIAT-Iris dataset and by the CASIA-Iris-Interval dataset are summarized in
Table 3 and
Table 4, respectively. By using these confusion matrices, metrics of the classification, such as precision, recall and accuracy, can be calculated, as summarized in
Table 5 and
Table 6.
Table 5 shows that, by using the network trained with the CAS-SIAT-Iris dataset, the classification precision reaches 97.67%, recall is 94.25%, and accuracy reaches 94.25% for the CAS-SIAT-Iris test set, and these metrics are 94.71%, 91.63% and 93.01%, respectively, for the CASIA-Iris-Interval test set. By using the network trained with the CASIA-Iris-Interval dataset,
Table 6 shows that the classification precision reaches 94.28%, recall is 87.83%, and accuracy reaches 89.50% for positive samples, 95.59% for the CAS-SIAT-Iris test set, and these metrics are 95.67%, 94.10% and 94.83%, respectively, for the CASIA-Iris-Interval test set.
Note that for these two datasets we further examined other CNN architectures such as the VGG19 and DeepIris models, which were also initialized with zero biases and random weights with zero mean, and in which dropout is placed on the full-connected layers to reduce overfitting. The results summarized in
Table 7 show that the accuracy is up to 94% for the VGG16 model but is only about 63–69% for both the VGG19 and DeepIris models. In other words, the VGG16 model exhibits the best performance in terms of the classification accuracy.
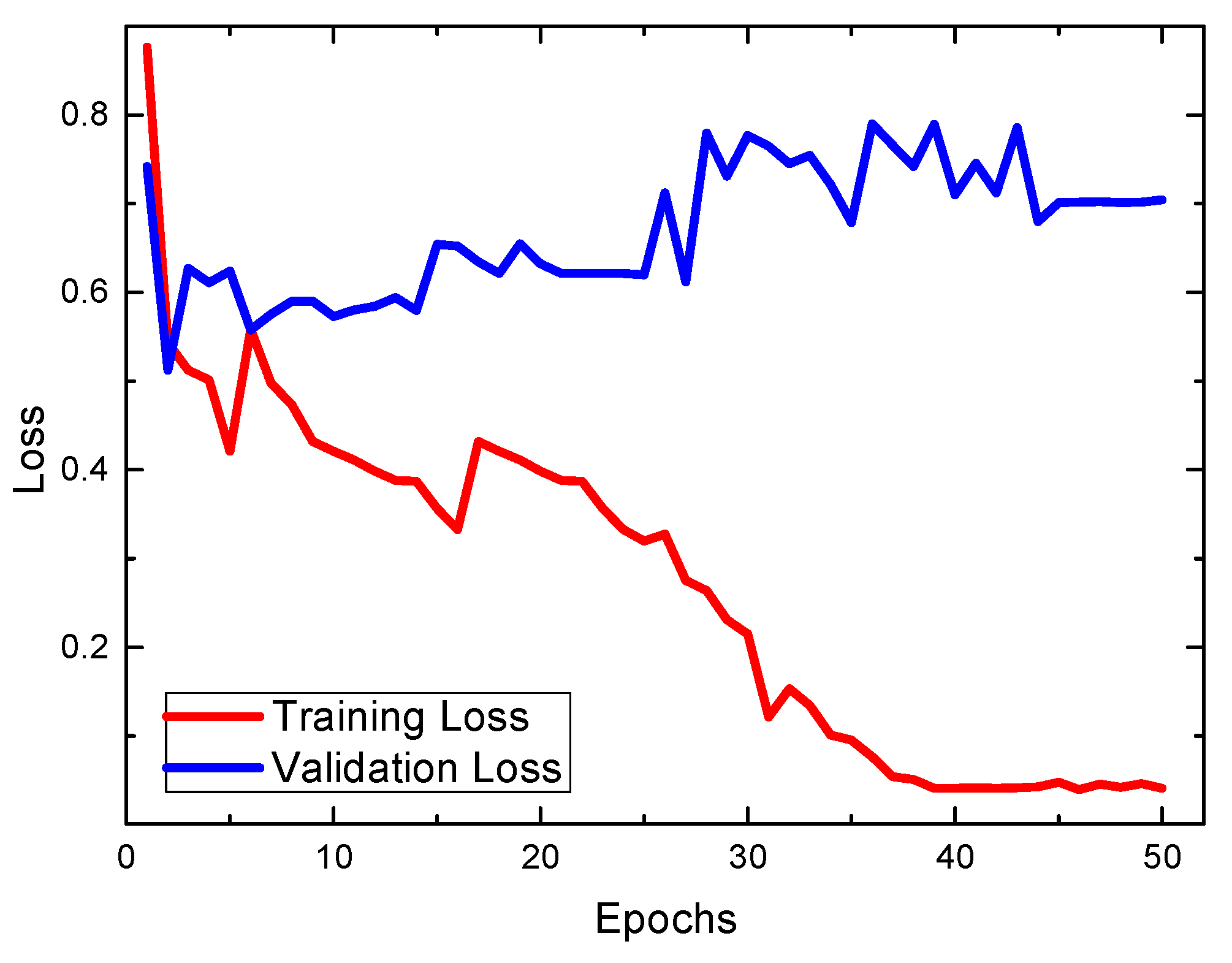
We also tried to make use of the conventional VGG16 architecture, which was initialized using pre-trained weights taken from a model in ImageNet [
28]. In that model, the input image is of
pixels, thus we further performed image cutting, splicing, and resizing so that the preprocessed iris images are now of
pixels. Note that the dropout method has been used in that model. Our experimental results in
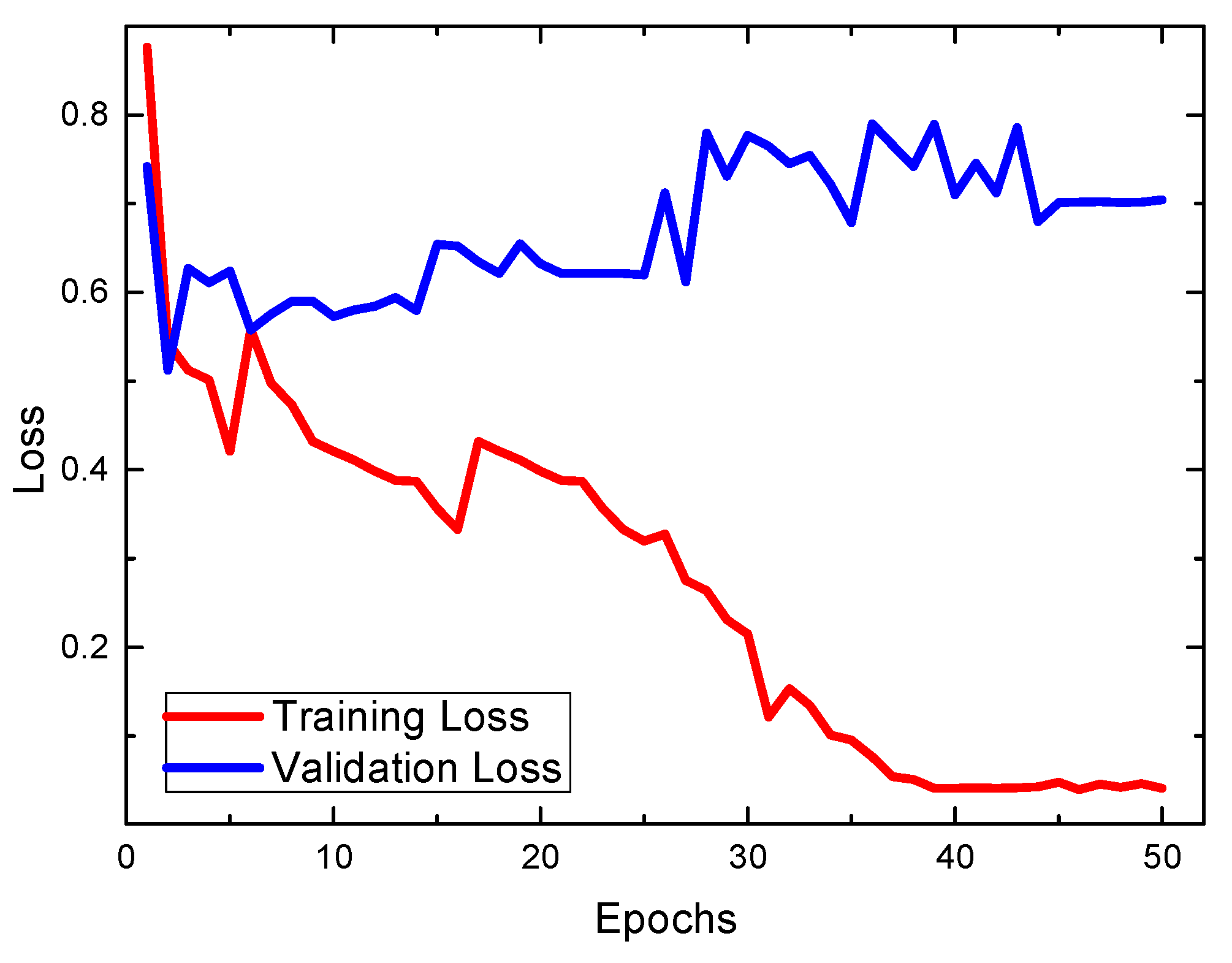
Figure 7 showed that the conventional VGG16 architecture with pre-trained weights, which was widely used for general image classification, is not suitable for the classification of the left–right iris images.
We note that, by using the traditional Daugman’s approach, it is impossible to distinguish whether two irises (left and right) are from the same or different individuals.
Figure 8 shows that comparisons between left and right irises from the same person (blue solid curve) yield similar Hamming distances as comparisons between left and right irises from two individuals (red dashed curve). In other words, from an iris recognition perspective, each iris is so distinct that even the left and right irises from an individual are distinguishable. These results obtained from the CAS-SIAT-Iris dataset are similar to those from the CASIA-Iris-Interval dataset (not shown for clarity), and are consistent with the literature [
3].

 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}