1. Introduction
Distributed cooperative control of multi-agent systems has been studied extensively in the past decade. Compared with its centralized counterpart, distributed control has many advantages such as low cost, easy maintenance, and high adaptivity. As a fundamental problem in distributed cooperative control, the consensus problem has attracted much attention. For a group of agents, consensus means reaching an agreement on a quantity of interest. The consensus problem can be classified into leaderless consensus and leader-following consensus, according to the absence or presence of a leader. Recently, much progress has been made on both leaderless and leader-following consensus problems (see [
1,
2,
3,
4,
5] and references therein).
Although the leader-following consensus problem for multi-agent systems with single leader is interesting, it is sometimes more meaningful to study the leader-following problem for multi-agent systems with multiple leaders. This problem is called the containment problem, the objective of which is to steer all the followers into the convex hull spanned by the leaders. In recent years, researchers have paid much attention to the containment control problem owing to its wide applications in swarm robotics [
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16]. In [
17], the containment control problem is investigated in both continuous-time and discrete-time domain. A
-Type containment control algorithm is proposed, which allows the followers to be of any-order integral dynamics.
In the aforementioned results, it is assumed that the agents can access their neighbors’ states continuously or with a fixed frequency. This is unnecessary or unrealistic in many applications. On one hand, it is a waste of communication resource to access the neighbors’ states frequently when the system states nearly approach their equilibriums or there are no disturbances imposed on the system [
18,
19,
20]. On the other hand, too much communication may lead to rising power costs and network congestion, which may degrade the performance of the system [
21,
22,
23]. The event-triggered control is a good strategy to solve this problem [
24,
25,
26]. Compared with the traditional sampled-data-based control, where the measurement or control is triggered by time, the main feature of the event-triggered control is that the measurement or control action is triggered by an event condition. The event-triggered control strategy was applied in both leaderless and leader-following consensus problems for multi-agent systems in [
27,
28,
29]. For more details, one can refer to [
30] and references therein. More recently, the authors in [
31,
32,
33] have proposed some event-triggered containment control algorithms for multi-agent systems with multiple leaders.
Time-delay exists in most practical systems. So, it is very meaningful to investigate the stability of time-delay systems [
34,
35,
36,
37,
38,
39,
40]. For multi-agent systems, the effect of time-delay is also an important problem to be considered. There are two sources of time-delay in multi-agent systems. One source is the communication among agents, which is called communication delays. The other source is the processing time for the information arrived at each agent, which is called input delays. The consensus problem for multi-agent system with communication/input delays has been extensively investigated in the literature (see [
41] and references therein). For second-order multi-agent systems with time-varying delays, the containment control problem is considered in [
42]. Recently, Miao et al. addressed the containment problem for second-order multi-agent systems with constant input delays [
43]. An event-triggered containment control algorithm was proposed, together with conditions under which the followers will converge to the convex hull spanned by the leaders.
In this paper, we consider the event-triggered containment control problem for multi-agent systems with high-order dynamics and input delay. Motivated by [
29], model-based approach is developed to avoid continuous communications among followers, and edge-based estimators are designed to predict state differences to neighbors. New event-triggered containment control algorithms are proposed for multi-agent systems without and with input delay, respectively. Sufficient conditions are derived under which the followers will move into the convex hull formed by the leaders. Compared with existing literatures on the containment control problem for multi-agent systems, our contribution is summarized as follows.
A delay compensation-based event-triggered containment controller is developed. It is proved that for arbitrarily large but bounded constant input delays, the proposed controller can drive all the followers into the convex hull formed by the leaders. In contrast, the controller in [
43] can deal with input delays below an upper bound only.
The proposed algorithms are distributed, while the algorithms in [
31,
32,
33,
43] are centralized. Using the algorithms proposed in this paper, every follower can decide whether the event should be triggered based on its own control input. However, using algorithms in [
31,
32,
33,
43], all agents need their neighbors’ states to trigger the next communication.
Compared with the containment control algorithms with continuous [
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16] or periodic communications [
17], the proposed event-triggered containment control algorithms has the potential to reduce the communication burden of multi-agent systems.
Notations: Throughout this paper, denotes the l dimensional Euclidean space, denotes a matrix with all the elements to be zero. Given a vector , denotes the Euclidean norm of . Given a matrix A, means that A is a positive definite matrix, is the induced norm of A. The superscript T denotes the transpose of a vector or matrix. We use to denotes the diagonal matrix of all , ⋯, .
2. Problem Formulation
2.1. Algebraic Graph Theory
Consider a group of agents consisted of M leaders and N followers. The leaders do not need to access information from the followers, while the followers are guided by the leaders. We assume that only a part of the followers can access information from some leaders. These followers are called informed followers. The rest of the followers cannot receive information from the leaders directly.
We use graph to denote the communication topology among the leaders and the followers, where is the node set and is the edge set. A directed edge denotes that node i can receive information from node j but not necessarily vice versa. An undirected edge denotes that node i and node j can access information from each other. A graph is undirected if all the edges in the graph are undirected. The neighbor set denotes the set of nodes from which node i can access information. A directed path is a sequence of directed edges of the form , ,..., where .
The adjacency matrix
is defined as
if
and
otherwise. The Laplacian matrix
is defined as
and
,
. We use
and
to denote node set of the leaders and the followers, respectively. Notice that
for all
and
, because the leaders have no neighbors. Therefore, the Laplacian matrix
L can be rewritten as
In this paper, for the sake of convenience, we assume that , if .
2.2. System Models and Control Objectives
Consider a network of
M leaders and
N followers with the following linear dynamics:
where
and
are the state and the control input of agent
i, respectively; A and B are constant matrices with appropriate dimensions.
When there exists a constant input delay
, (3) becomes
Definition 1. Let . The set is said to be convex if for any x and y in , the point is in for any . The convex hull of a set of points is the minimal convex set containing all points in X.
Definition 2. We say algorithm asymptotically solves the containment problem if, under algorithm , the followers move into the convex hull formed by the leaders asymptotically.
The following assumptions and lemmas are used later.
Assumption 1. The communication graph among the followers is undirected. For each follower, there exists at least one leader that has a path to it.
Lemma 1 ([13]).Under assumption 1, the matrix defined in (1) is symmetric positive definite. From Lemma 1 we have all the eigenvalues of are positive. Assume that the eigenvalues of are .
Lemma 2. Each entry of is nonnegative and each row sum of is equal to one.
Lemma 3. Assume that the matrix pair is controllable, and all the poles of A are on the imaginary axis. For any constant scalar , the parametric Riccati equationhas a unique positive definite matrix , where is the unique positive definite solution to the following Lyapunov equation . Moreover, , , , , , . Moreover, if all the eigenvalues of A are zero, then . 2.3. Event-Triggered Communication Mechanisms
As will be explained later, since control inputs of the leaders are zero, the informed followers can estimate states of the leaders based on their initial states. Therefore, the event-triggered mechanism is not needed for the communication between the leaders and the informed followers.
Assume that followers
i and
j are two linked agents, and they exchange information at event instants
. To exchange information based on the event-triggering communication mechanism, event trigging functions
and
should be designed for each edge
. The event instants between followers
i and
j are determined according to
where
. Once
reaches zero, an event is triggered. Follower
i will send
to follower
j, and then receive
from follower
j. Conversely, if
reach zero first, follower
j will send
to follower
i, and then receive
from follower
i.
The objective of this paper is to design the event-triggering functions and the control algorithms for system (
2) and (3) without input delay, and the input delay system (
2) and (
4), respectively, such that all the followers can move to the convex hull formed by the leaders.
3. Event-Triggered Containment Control without Input Delay
In this section, we consider the containment control problem without input delay. Define
, and
. Note from Lemma 2 that if
then all the followers are in the convex hull formed by the leaders. For follower
i, define
If
for
, one has
which implies that (
7) holds. Therefore, all the followers lie in the convex hull formed by the leaders if
holds for
.
Let
be the state difference between follower
i and leader
j, and
be the state difference between followers
i and
j. Equation (
8) can be rewritten as
For informed followers, to drive to zero, and are needed. For other followers, is needed. However, when the event-triggering communication mechanism is adopted, such information is available only at the event instants. To solve this problem, we need the following state difference estimators to estimate and during the inter-event intervals.
3.1. Leader Edge State Difference Estimators
Suppose that informed follower
i can access leader
j’s state. In this case, edge
is called leader edge of follower
i. From (
2) and (3) and the definition of
we have
Follower
i can construct the following estimator to estimate
where
. The solution of (
12) is
Remark 1. It is trivial to prove that , for all . So, the informed followers can estimate based on the initial state , i.e., they only need to communicate with the leaders one time. This is because the leaders’ control inputs are assumed to be zero. If the leaders’ control inputs are nonzero, the informed followers need to communicate with their leader neighbors frequently. Tracking dynamic leaders with an event-triggered controller is a tough problem, which will be considered in our future work.
3.2. Neighbor Edge State Difference Estimators
Suppose that follower
i can access follower
j’s state. In this case, edge
is called neighbor edge of follower
i. From (3) we have
In the inter-event interval
,
is not available for follower
i. Follower
i can adopt the following estimator to estimate
where
and
. The solution of (
15) in inter-event interval
is
Define
. Notice that followers
i can correcting
at the event instants. Therefore,
at the event instants. Denote
the last event instant of edge
before time
t. If
t is the event instant, then
. From (
14) and (
15) we have
3.3. Event-Triggering Functions
Same to [
29], we use the following event trigging function for edge
where
for
,
is a continuous threshold function. In the following of this paper, we set the threshold function as
, where
and
c are constant positive scalars.
Remark 2. Notice that and are not related to any information about other agents. So, follower i can detect the event dependently. In contrast, triggering functions in [31,32,33] are related to neighbors’ states. When these triggering functions are used, a centralized detector is needed. 3.4. Event-Triggered Containment Control Algorithms
Based on the aforementioned state difference estimators and event-triggering function, we consider the following containment control algorithm
where
, and
K is a parametric matrix to be designed. The derivative of
along the solution of (
2) and (3) is
Define
,
. Equation (
21) can be rewritten in a compact form as
where
. From (
6) , (
17) and (
18) we have
From (
21) and (
23) we have
where
is the largest eigenvalue of
.
The proposed containment control algorithm is summarized in Algorithm 1, where T is the lifespan of the system.
| Algorithm 1 Event-Triggered Containment Control Algorithm for follower i: without input delay. |
Initiation:; fordo receive from leader j; ; end for fordo send to follower j and receive from follower j ; ; ; ; end for compute the controller as in ( 20);
|
Iteration:- 1:
whiledo - 2:
for do - 3:
compute as in ( 13); - 4:
end for - 5:
for do - 6:
compute as in ( 18); - 7:
if then - 8:
send to follower j and receive from follower j; ; - 9:
end if - 10:
compute as in ( 16); - 11:
end for - 12:
compute the controller as in ( 20). - 13:
end while
|
Theorem 1. Consider a network with M leaders (2) and N followers (3). Suppose that is controllable, the communication graph satisfies Assumption 1, and the event-triggered communication mechanism is adopted with triggering function (18). Let , where P is the solution of the following Riccati equalitywhere is the smallest eigenvalue of , is a constant scalar. With control algorithm (20), all the followers will converge to the convex hull formed by the leaders. Proof. Assume that the communication graph satisfied Assumption 1. From Lemma 1 we have
. Suppose that
is controllable. For any
, Riccati equality (27) has a solution
P. Let
, then
in (
25) is equal to
. Since
is a symmetric positive definite matrix, we can find an orthogonal matrix
U such that
. It follows that
, which implies that
. It then follows that
Because
, we have
By a similar process with Section 4 in [
29] we can find positive scalars
and
such that
From (
25) and (
27) we have
Therefore, converge to zero exponentially. Based on the analysis above we have that all the followers will converge to the convex hull formed by the leaders, which complete the proof. □
Next, we show that the Zeno behavior can be excluded by the control algorithm (
20) and triggering function (
8).
Theorem 2. Suppose that . The inter-event intervals are lower bounded bywhere . Proof. With control algorithm (
20), from (
23) and (
29) we have
where
.
Suppose that
. For any linked followers
i and
j, assume that the communication is triggered at event instant
. Then,
is the next event instant that satisfies
or
. Without loss of generality, we assume that
. Define
. For any
, we can obtain that
satisfies
It follows that
. Notice that
. We can obtain that there exists a time instant
such that
. From the definition of
we have
which implies that
□
5. Simulation Examples
This section gives a numerical example to show the effectiveness of the proposed algorithms. Consider a network with 10 followers and 4 leaders in the two-dimensional space. The parameter matrices
A and
B are
Suppose that , , and . Initial positions of the followers are chosen as , , , , , , , , , and . Initial velocities of the followers are chosen as zero.
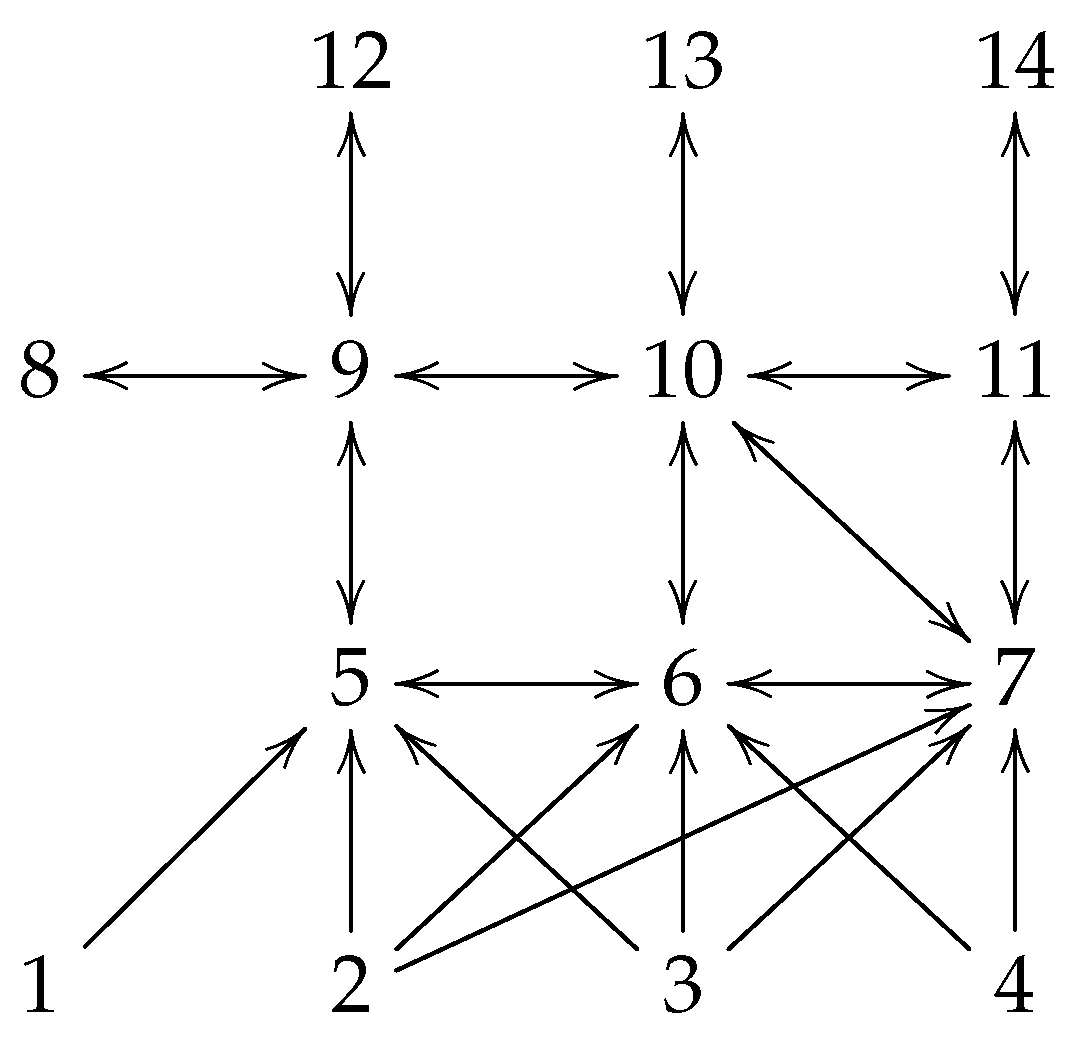
The network graph associated with the 14 agents is shown by
Figure 1, and the corresponding Laplacian matrices are as following
It is easy to obtain that the smallest eigenvalue of is .
Containment control without input delay. We verify the effectiveness of containment control algorithm (
20) and trigger function (
18) first. Chose
. By solving matrix equality (
25) we can obtain
. According to Theorem 1, we can set
K as
Let
,
.
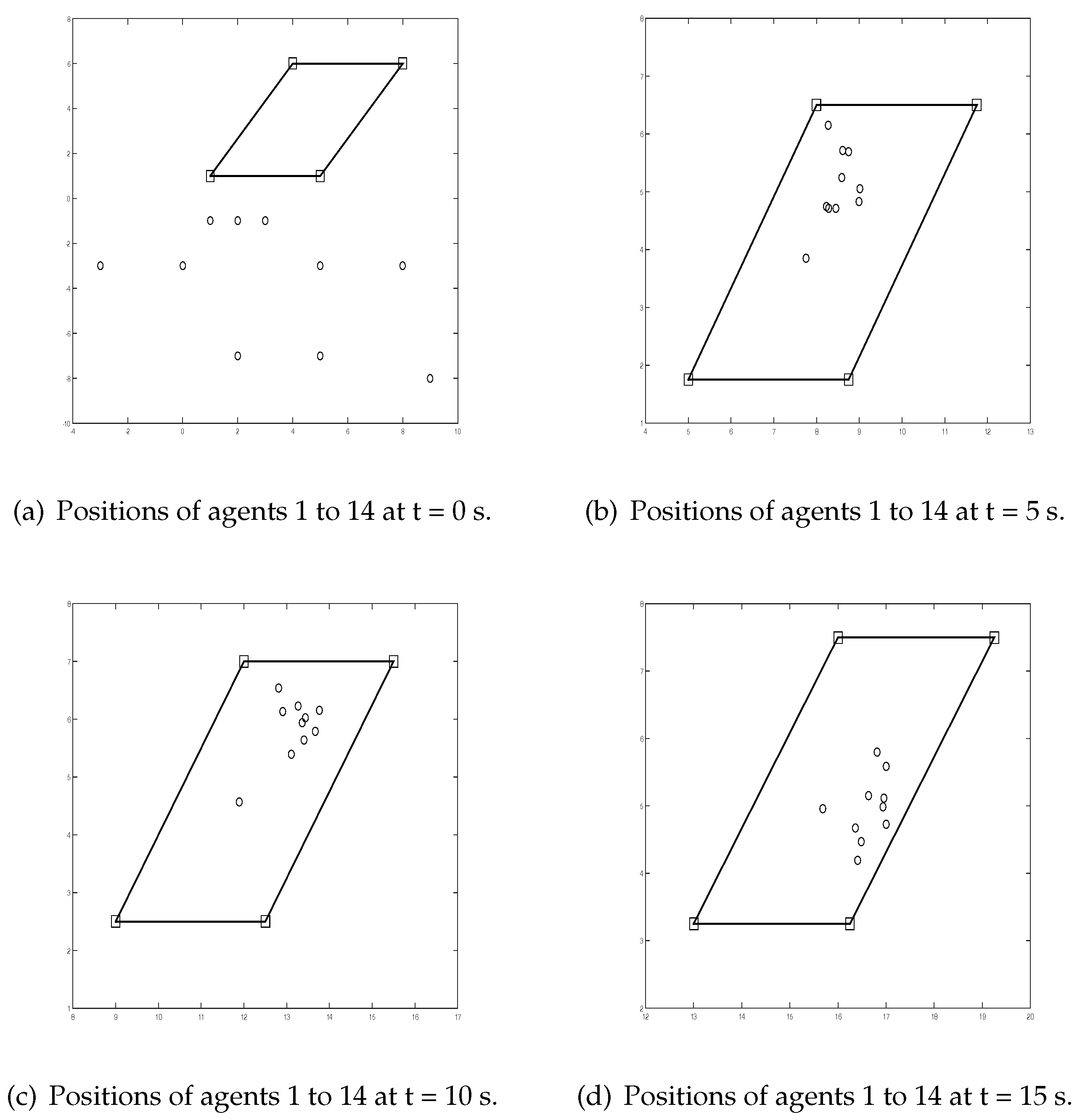
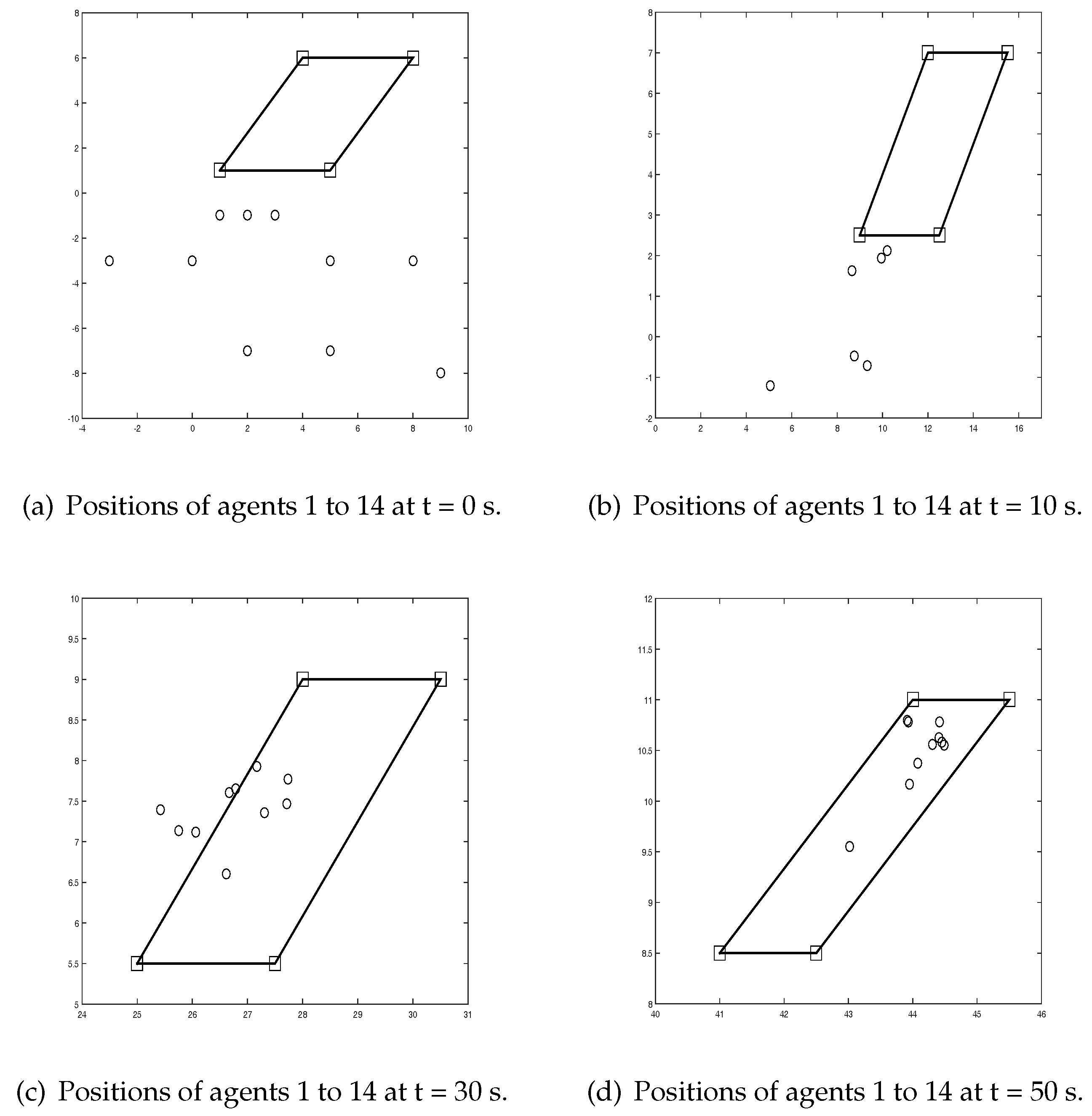
Figure 2 shows positions of vehicles 1 to 14 at time instants 0 s, 5 s, 10 s, and 15 s. It can be seen that agents 5 to 14 move into the convex hull spanned by agents 1 to 4.
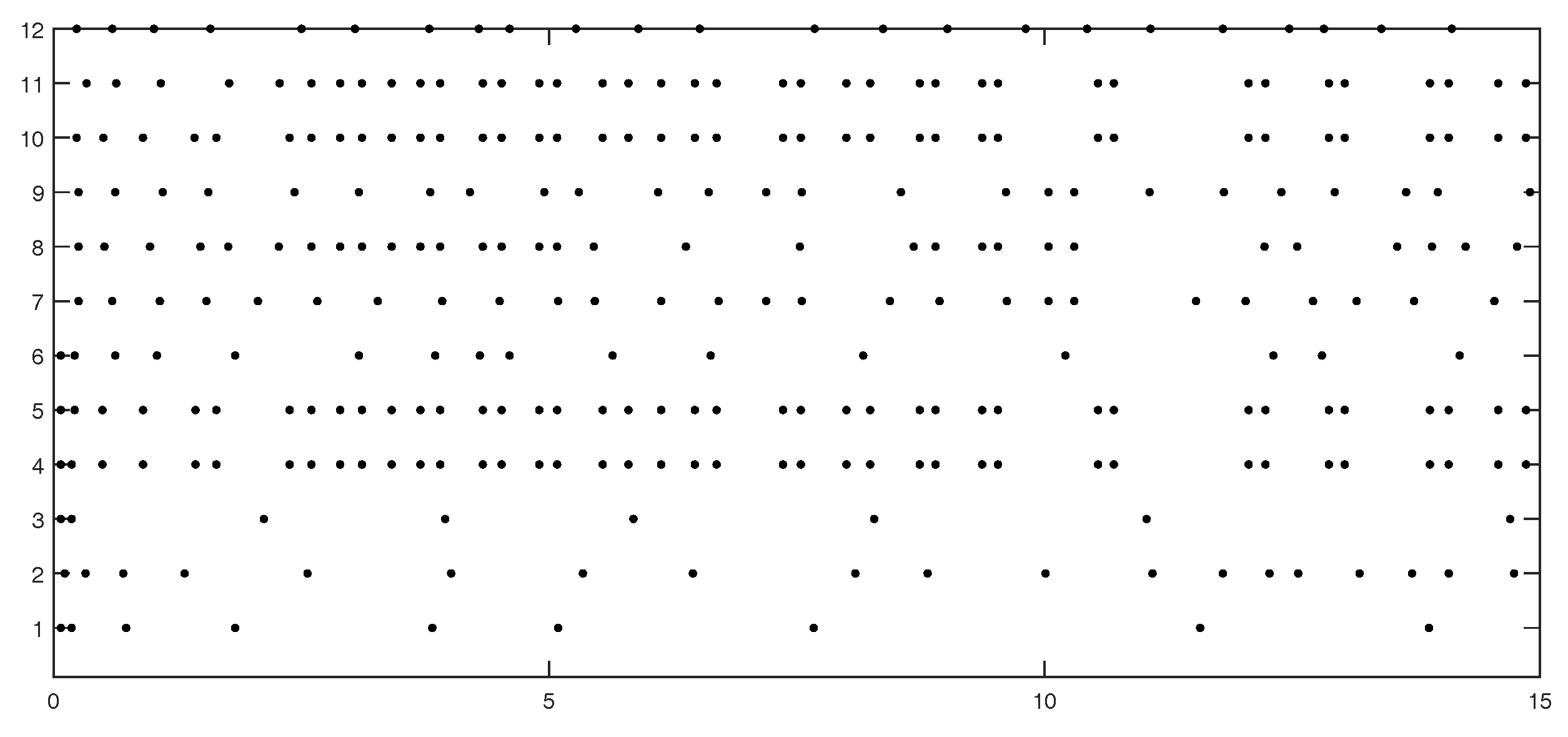
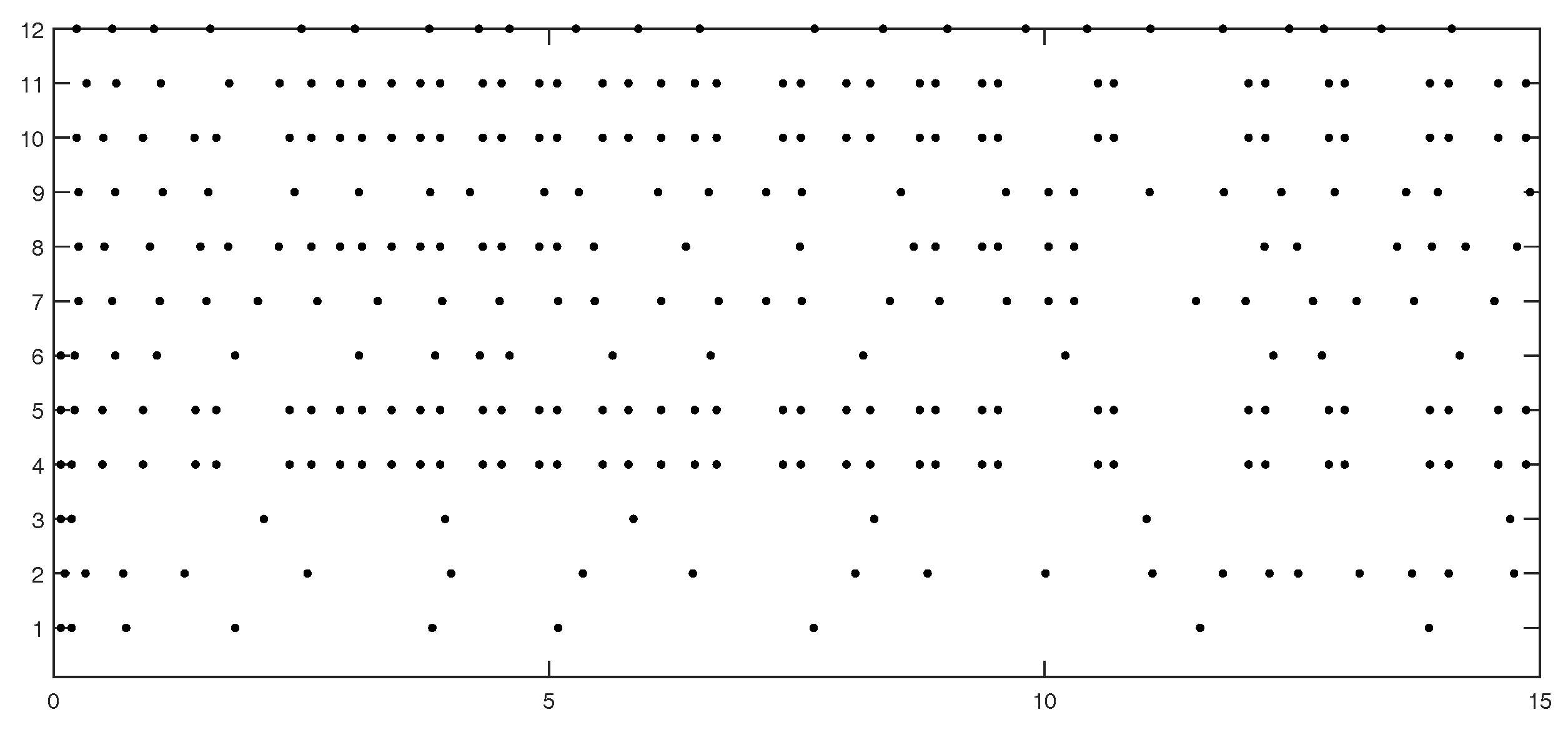
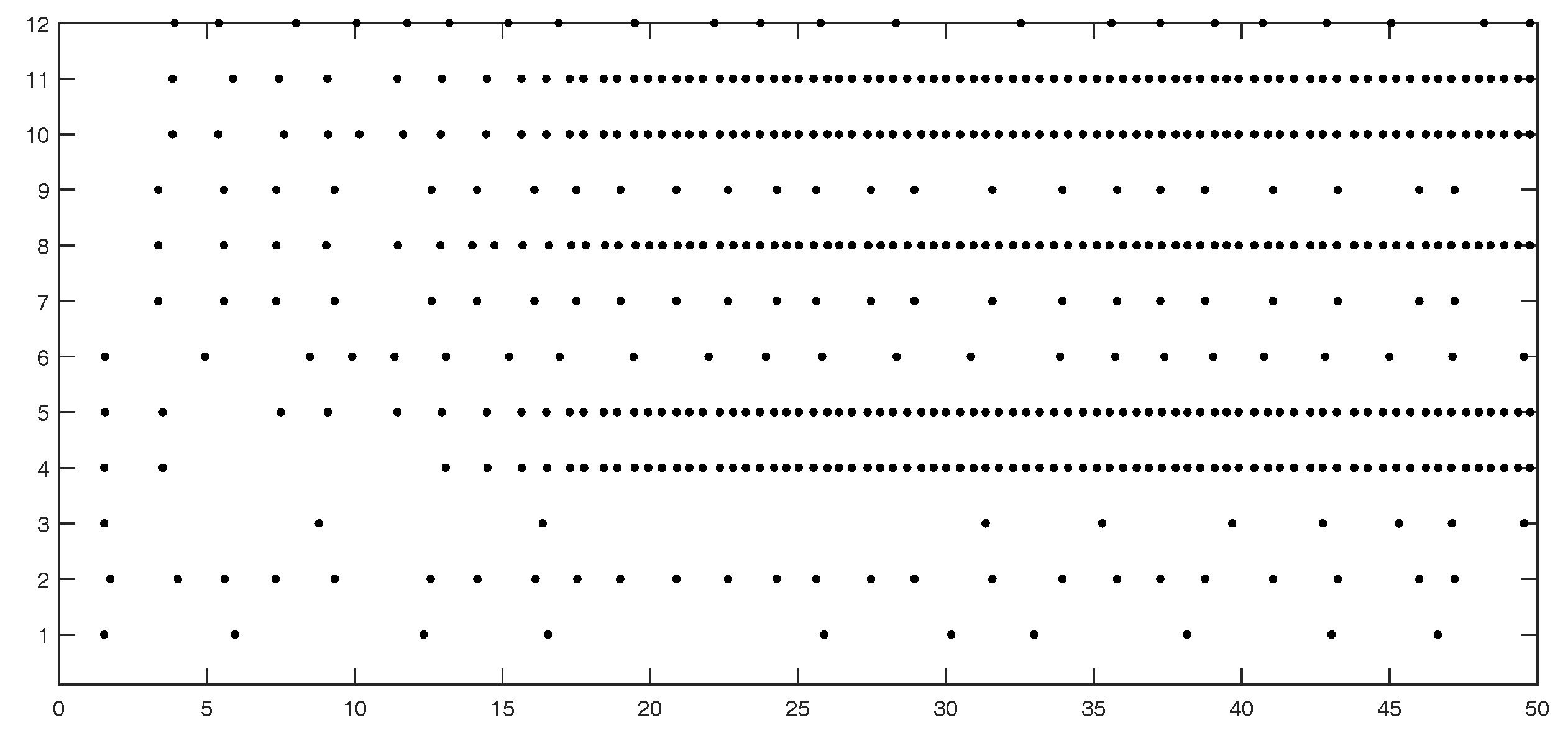
Figure 3 shows the event instants on edges 1 to 12.
Table 1 and
Table 2 show numbers of event instants counted by edge and agent, respectively. From
Table 2 we can see that for most agents, the communication burden is light. However, for agents with many neighbor edges (agents 9–11), their communication burdens are heavy.
Containment control with input delay. Let
s. By solving parametric Riccati Equation (
5) with
, we can obtain
. Let
. According to Theorem 3, we can set
K as
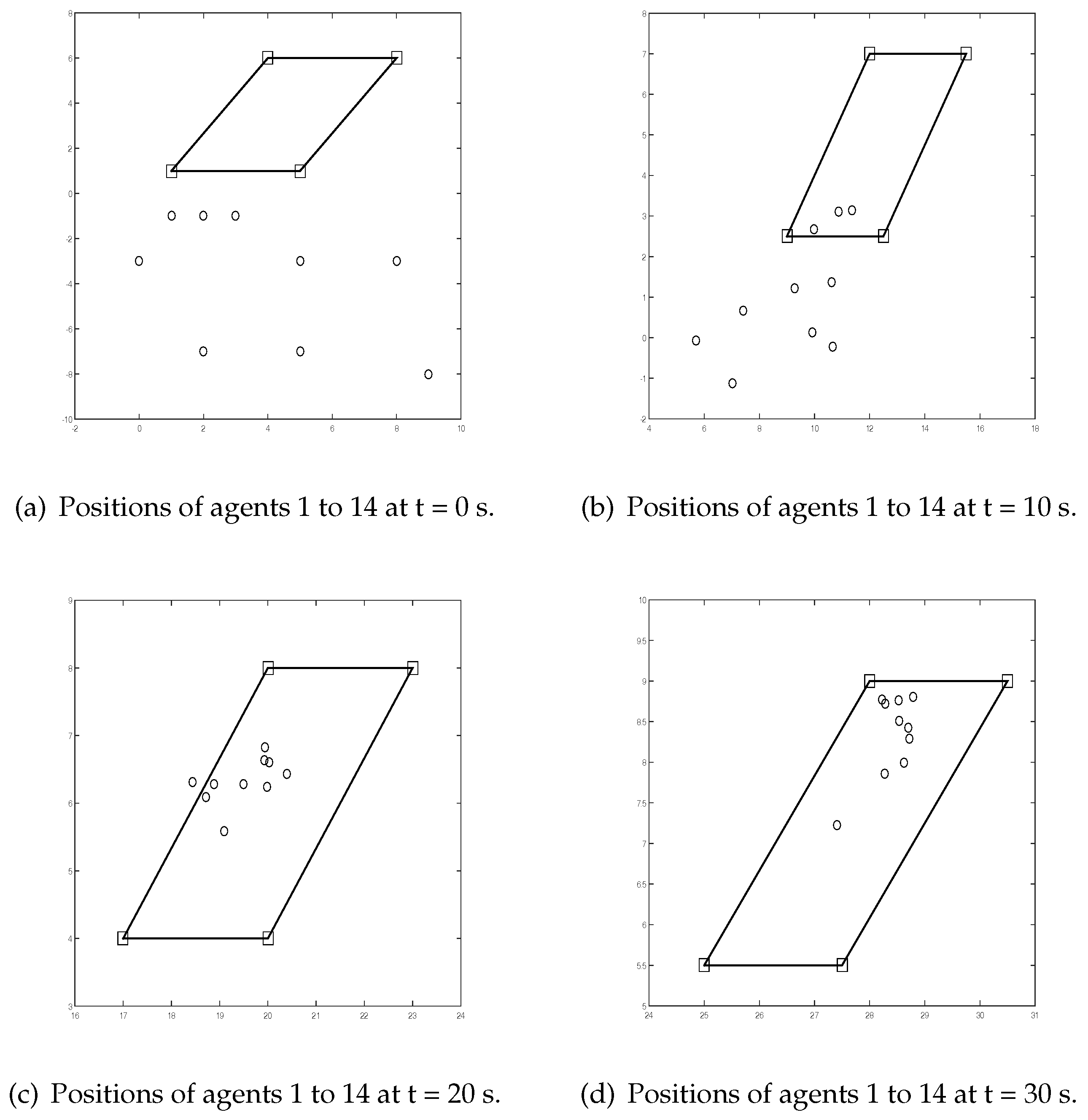
Figure 4 shows positions of agents 1 to 14 using Algorithm 2. It can be seen that agents 5 to 14 move into the convex hull spanned by vehicles 1 to 4.
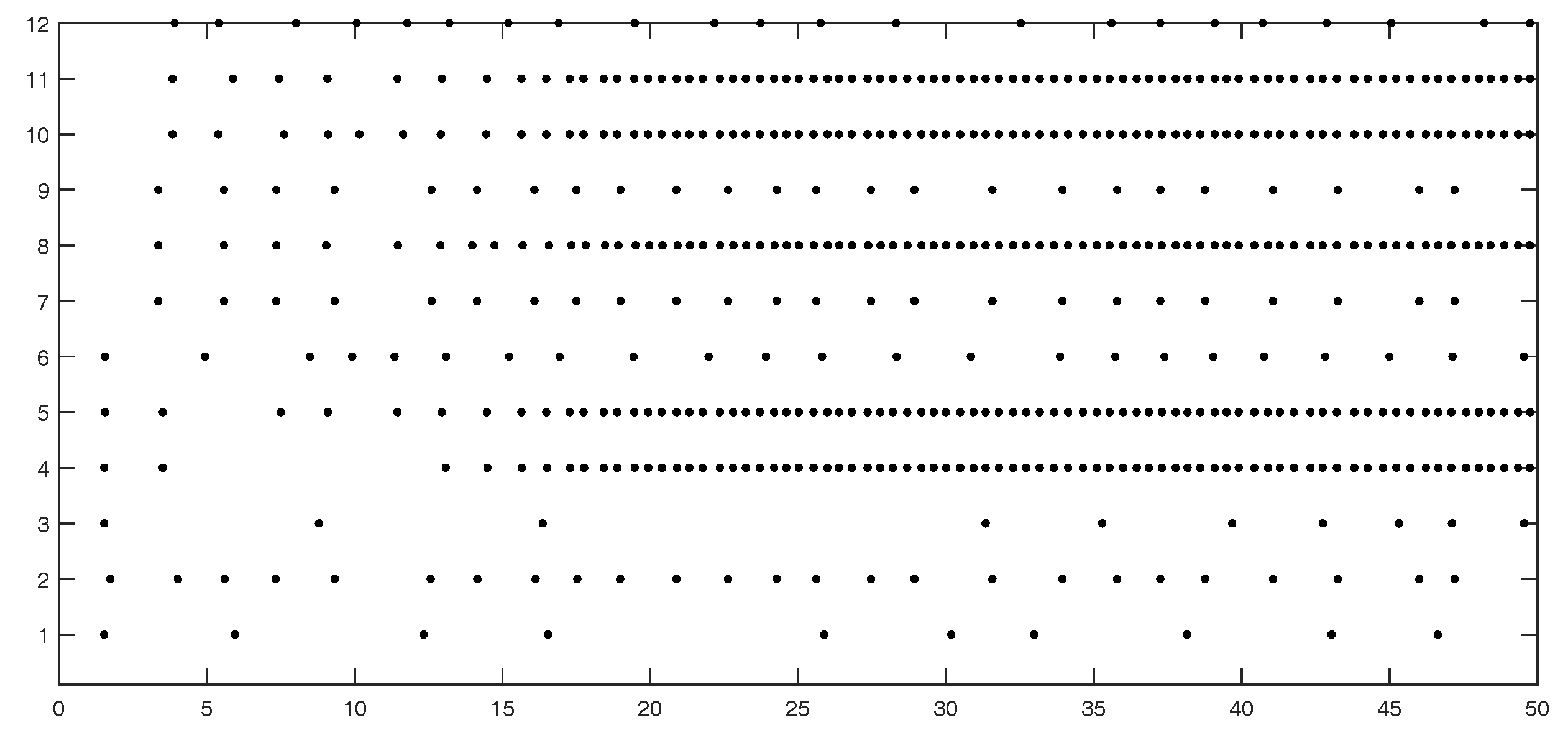
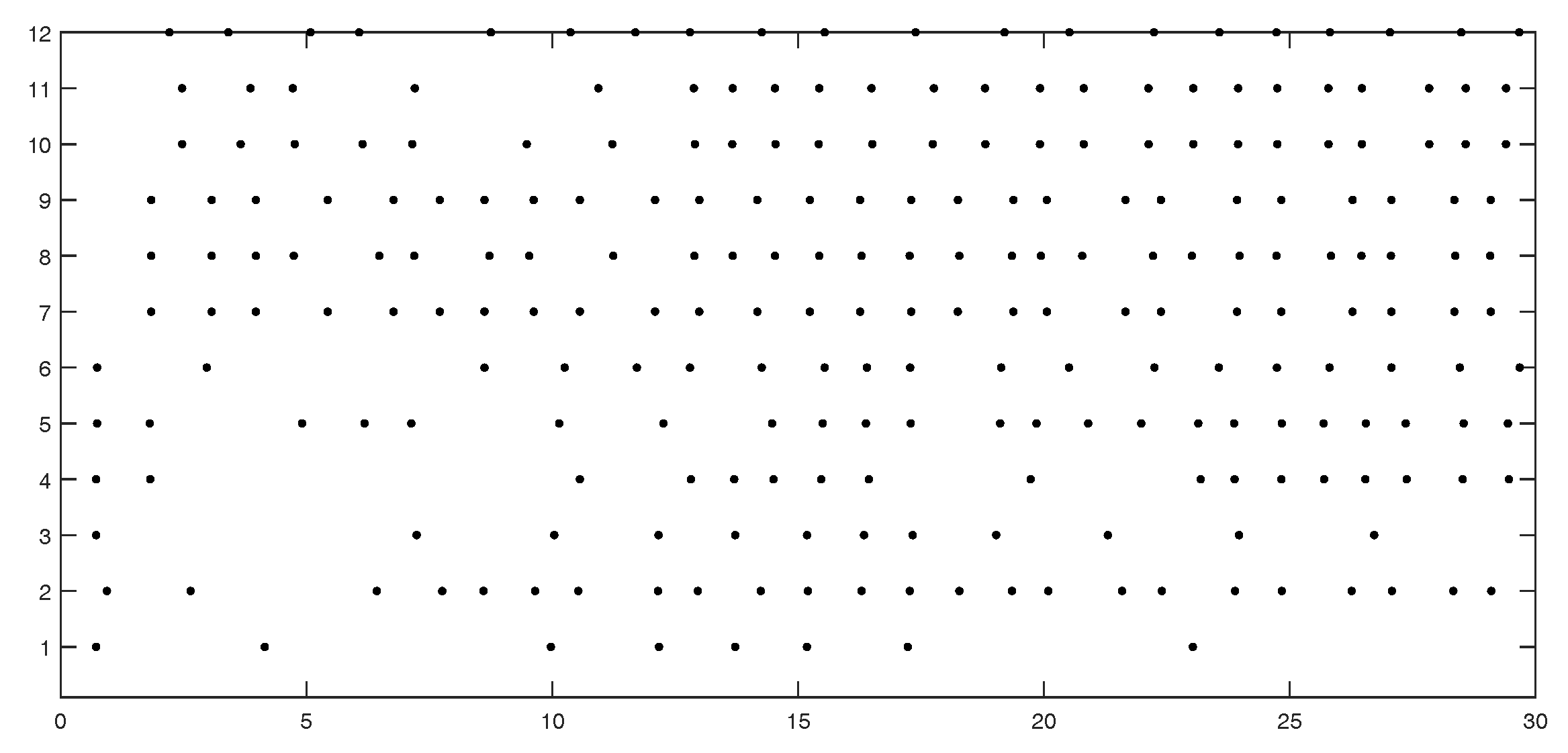
Figure 5 shows the event instants on edges 1 to 12.
Table 3 and
Table 4 show numbers of event instants counted by edge and by agent, respectively.
Suppose that
s. By solving parametric Riccati Equation (
5) with
, we can obtain
. Let
. According to Theorem 3, we can set
K as
Figure 6 shows positions of agents 1 to 14. It can be seen that agents 5 to 14 move into the convex hull spanned by vehicles 1 to 4.
Figure 7 shows the event instants on edges 1 to 12.
Table 5 and
Table 6 show numbers of event instants counted by edge and by agent, respectively.
Remark 5. From Figure 4 and Figure 6 we can see that the converge speed is lower when τ is larger. In fact, when the input delay τ is getting larger, according to Theorem 3, we should choose a smaller γ. From Lemma 3 we know that . So, when γ is small, the gain matrix K is small, which leads to low converge speed. 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}