
Achieving Low-Latency, High-Throughput Online Partial Particle Identification for the NA62 Experiment Using FPGAs and Machine Learning †

 , , , , , , , , , and
, , , , , , , , , and
Abstract
1. Introduction
2. Materials and Methods
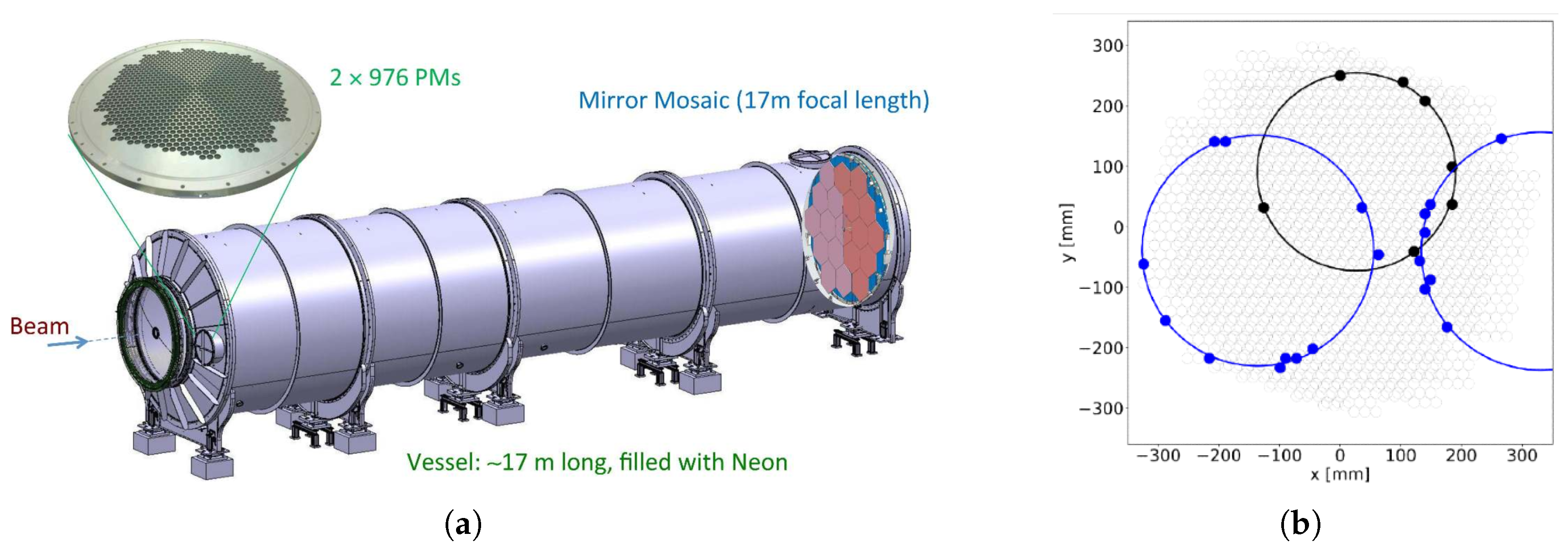
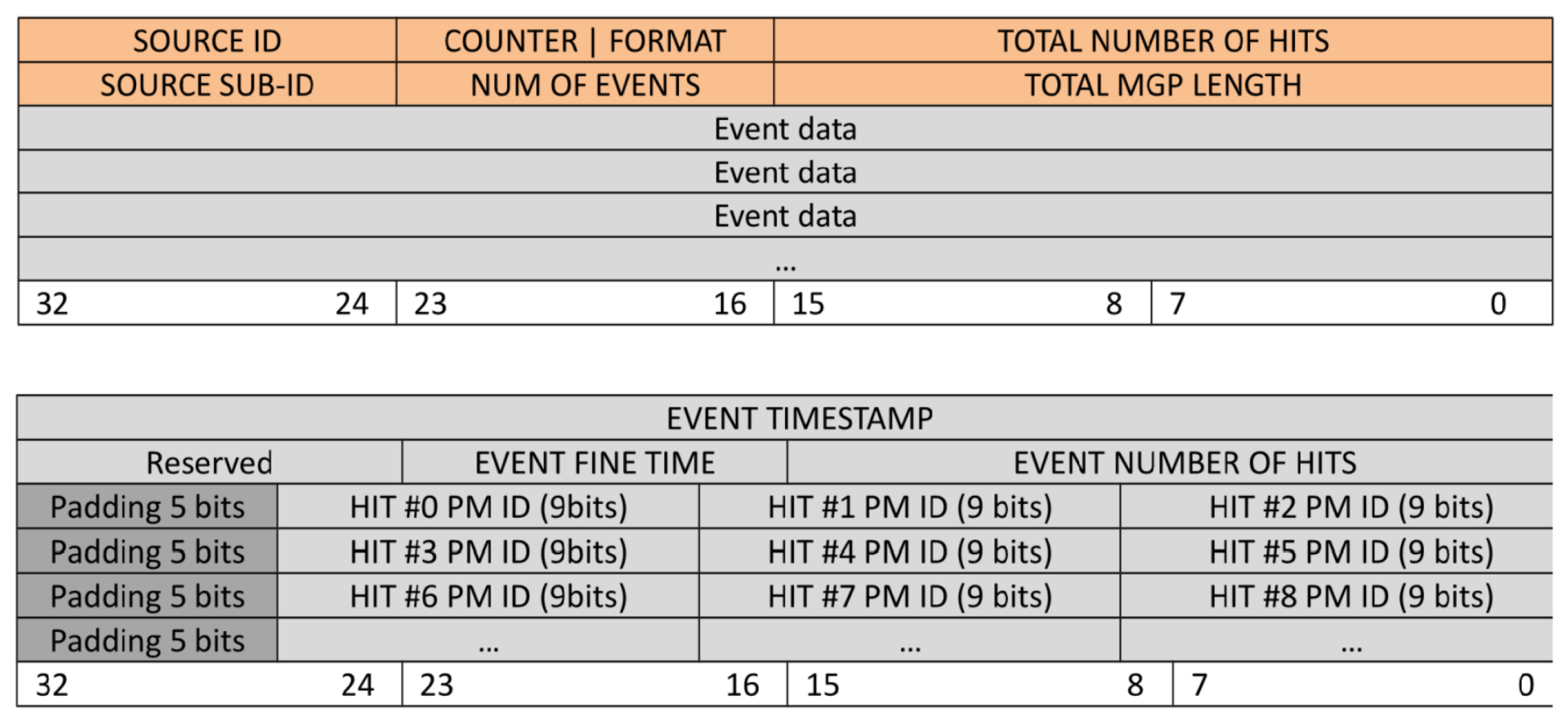
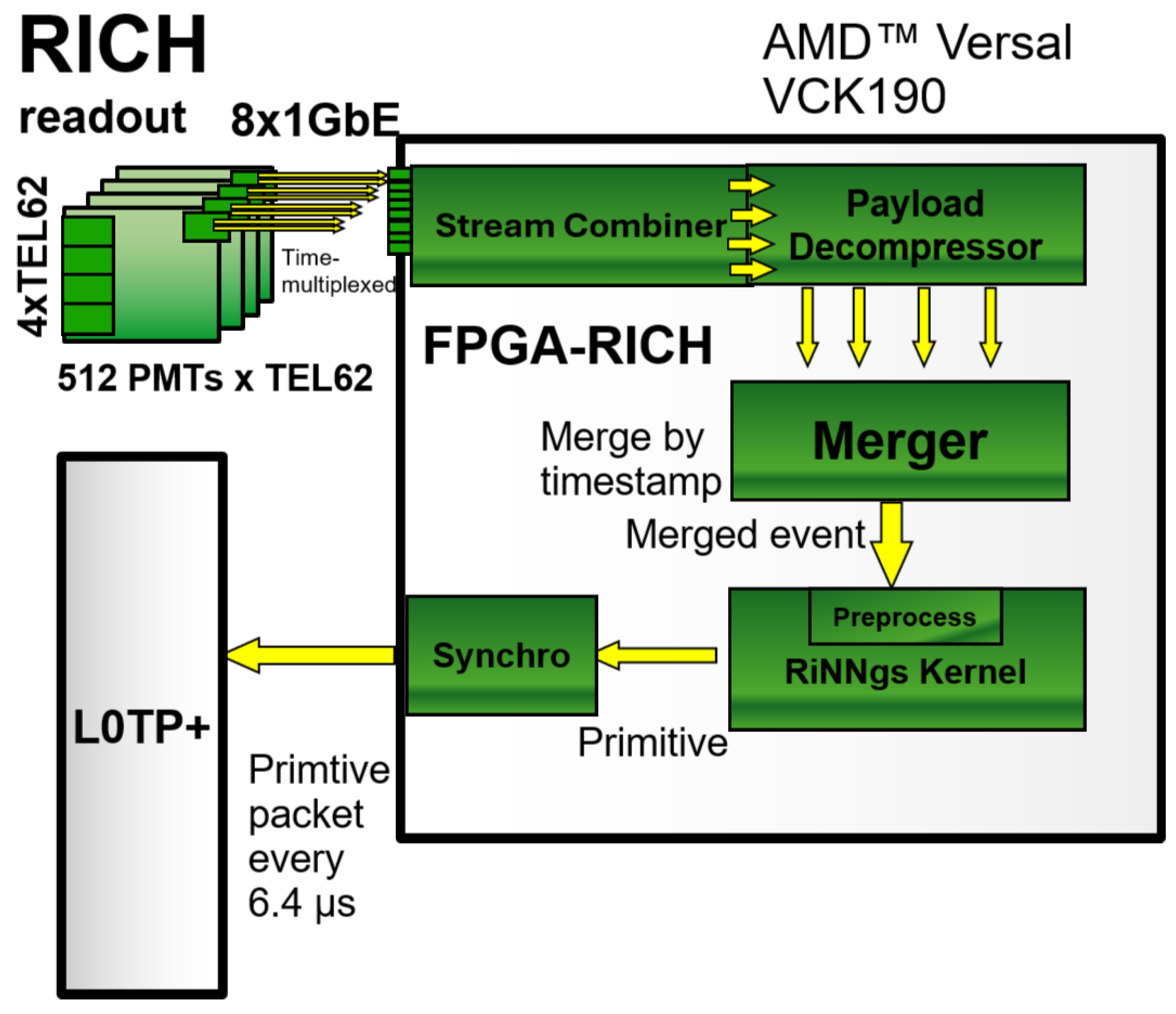
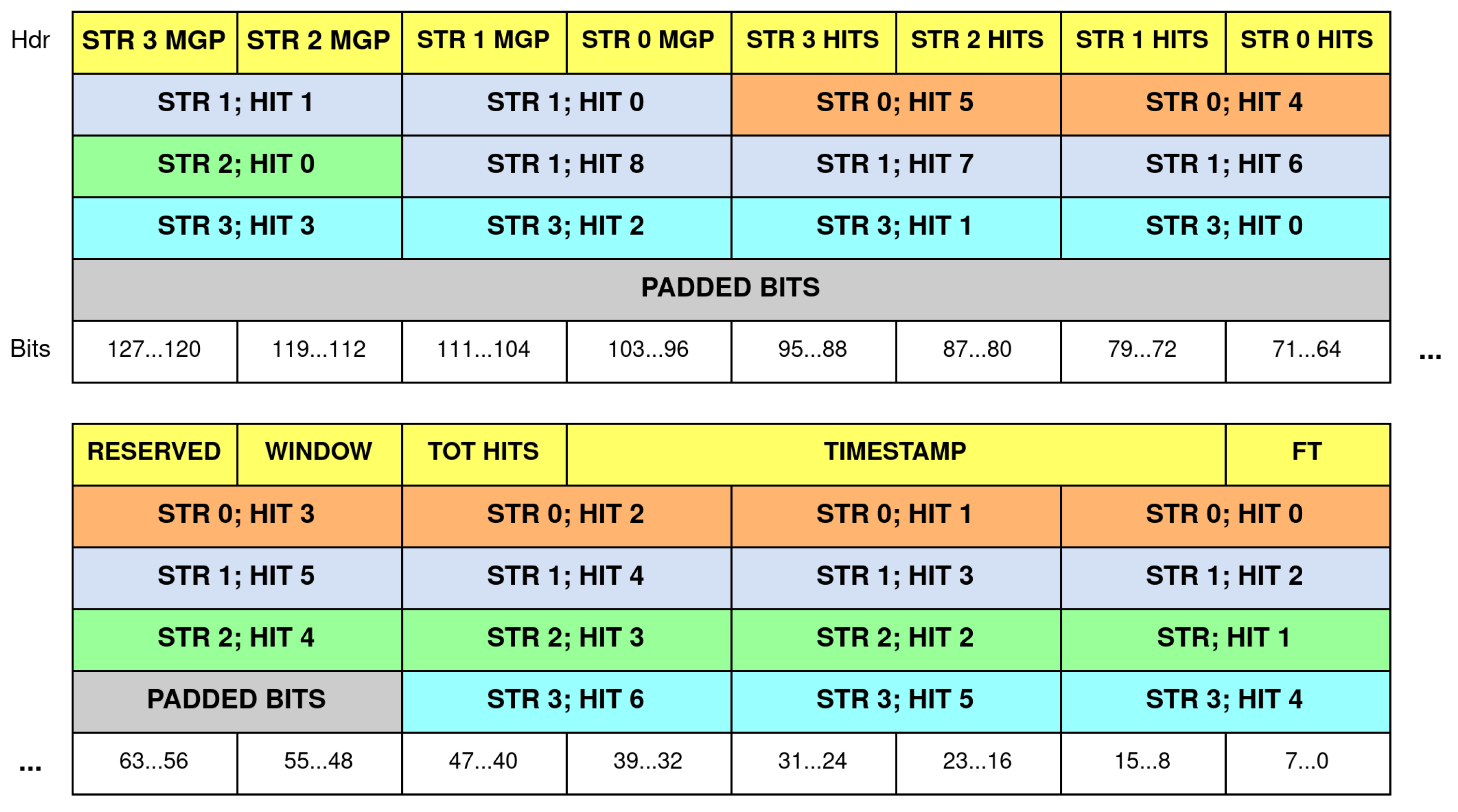
2.1. The FPGA-RICH Streaming Pipeline
2.2. The Rings Neural Network IP (RiNNgs) Development Workflow
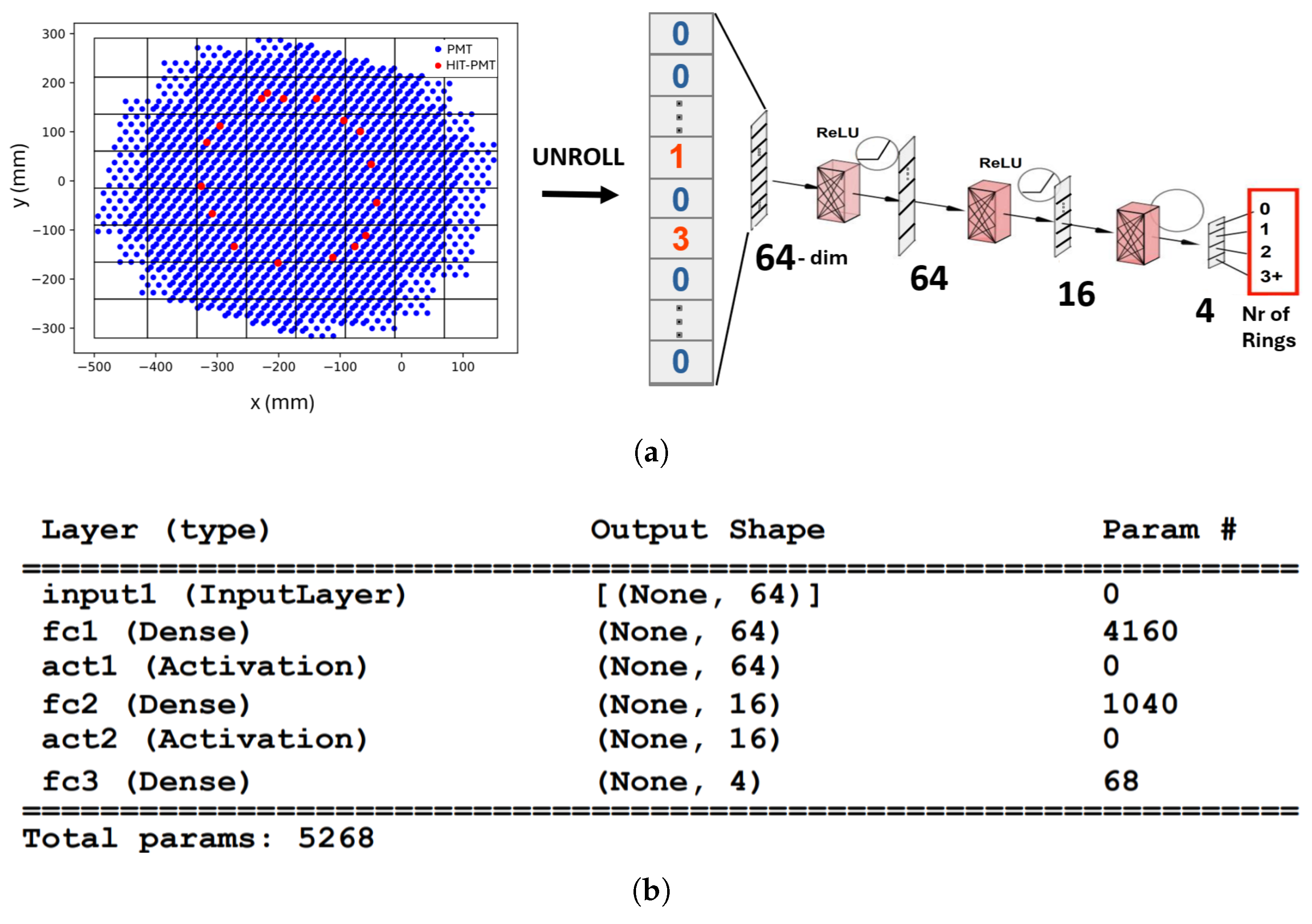
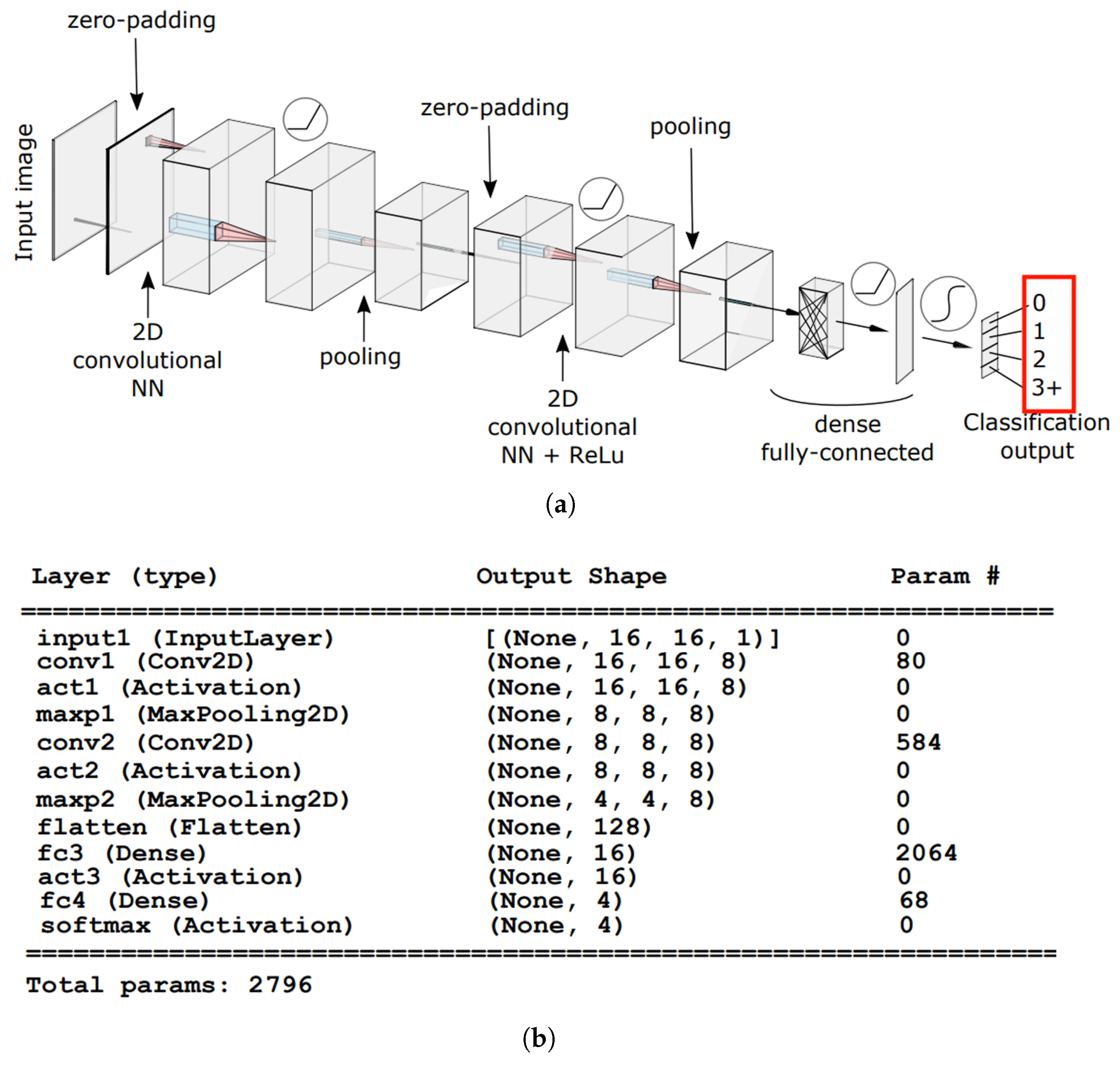
2.3. The RiNNgs Neural Network Models Architecture
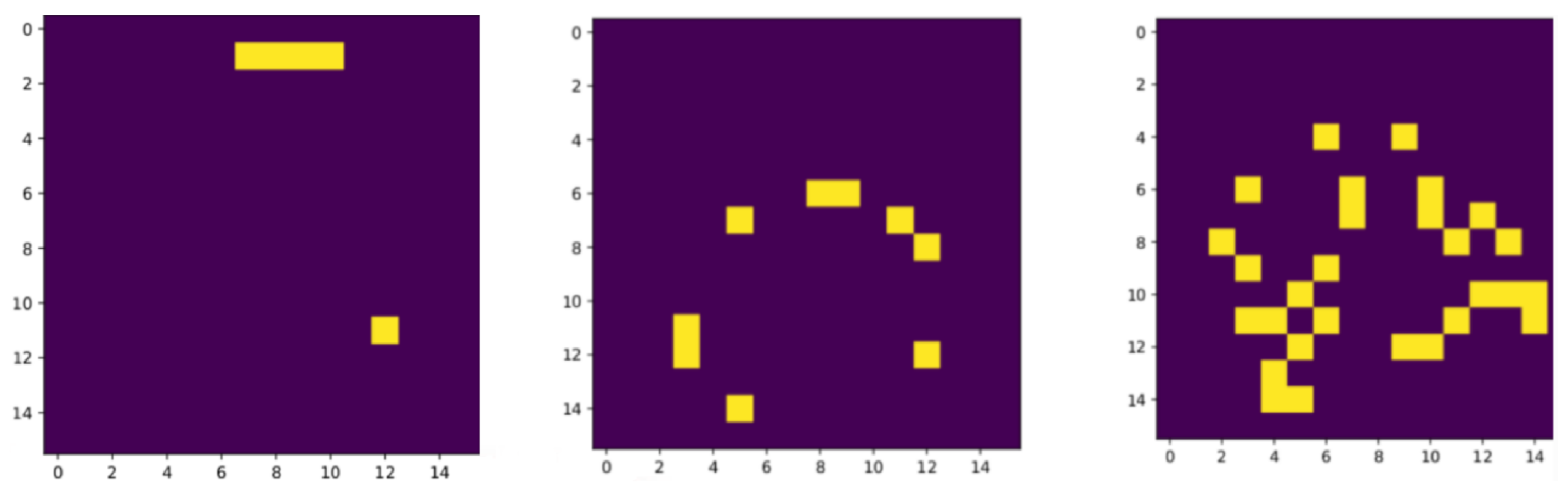
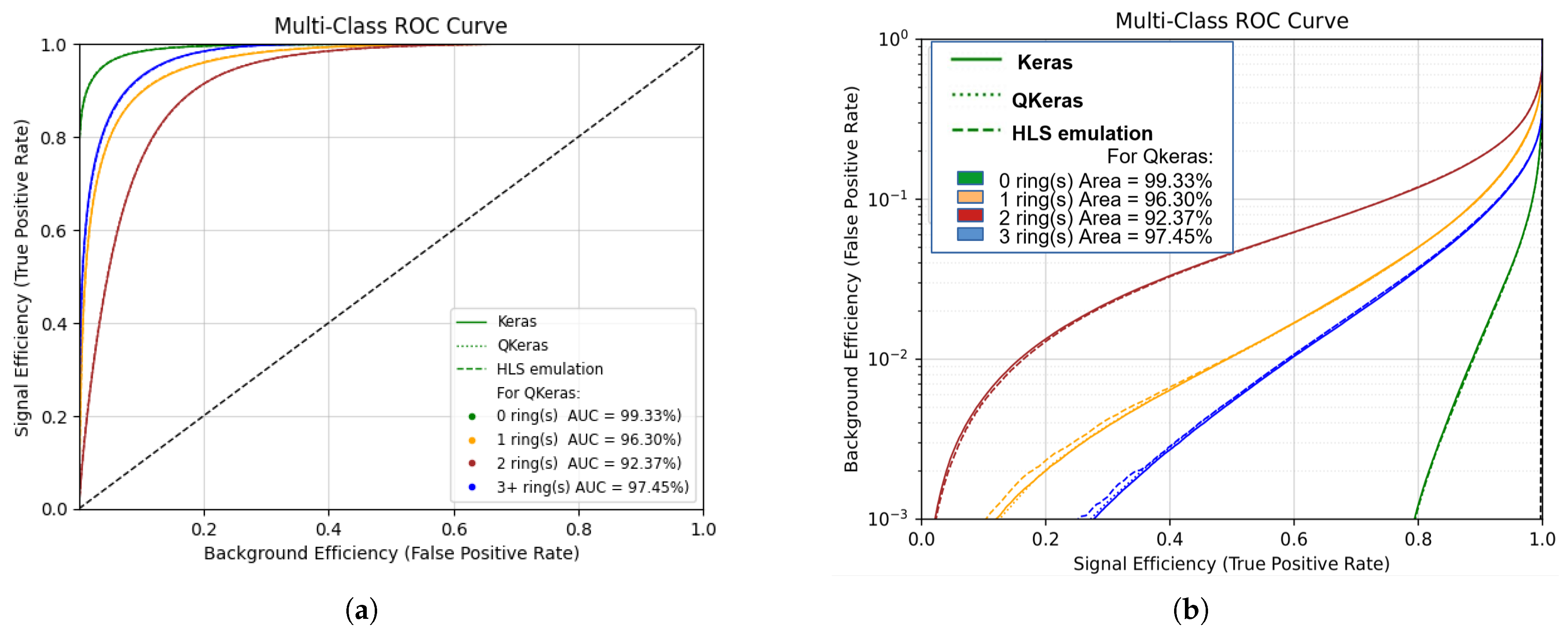
2.4. Functional and Performance Validation Methodology of the Full FPGA-RICH Pipeline
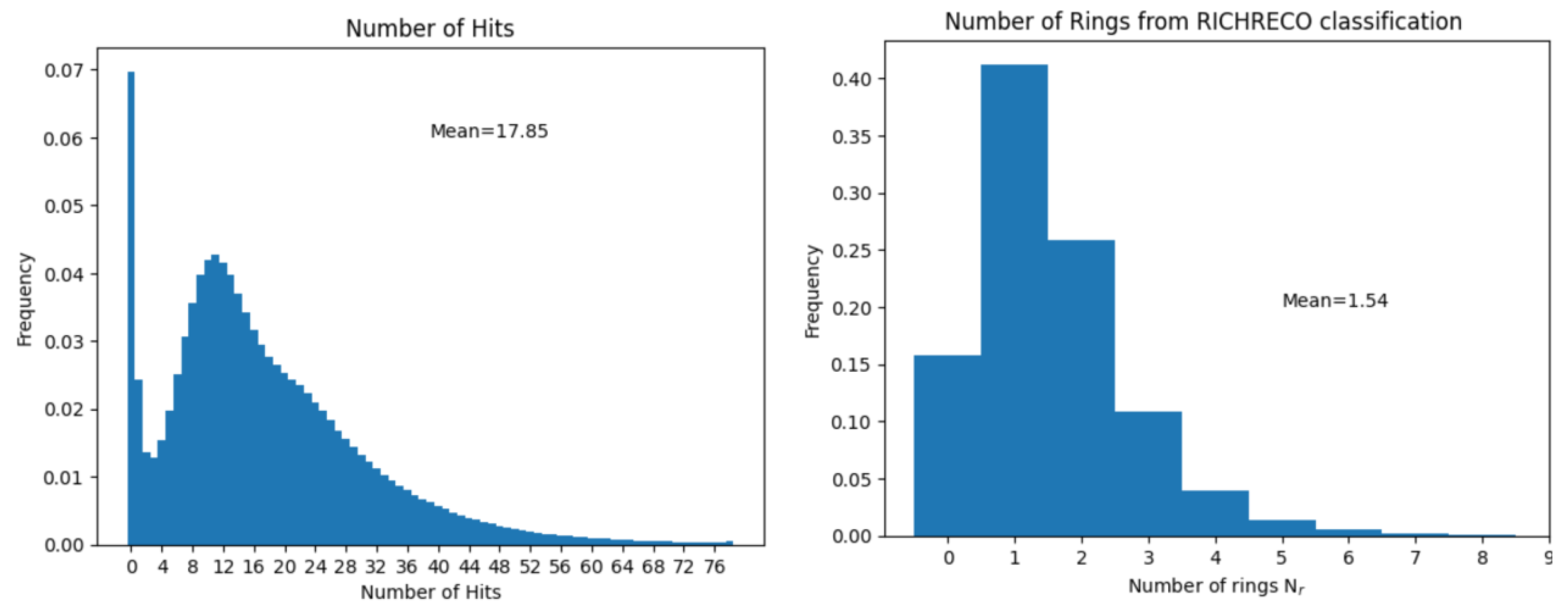
3. Results
The Validation of the Full FPGA-RICH Pipeline
4. Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| FPGA | Field Programmable Gate Array |
| RICH | Ring Imaging Cherenkov Detector |
| L0TP | Level 0 Trigger Processor |
| TDAQ | Trigger and Data Acquisition |
| HLS | High-Level Synthesis |
| NN | Neural Network |
| PMT | Photo-Multiplier Tube |
| CNN | Convolutional Neural Network |
| FC | Fully Connected |
| RiNNgs | Rings Neural Network |
| MGP | Multi-event GPU Packet |
| M2EGP | Multi Merged Event Packet |
References
- Gil, E.C.; Albarrán, E.M.; Minucci, E.; Nüssle, G.; Padolski, S.; Petrov, P.; Szilasi, N.; Velghe, B.; Georgiev, G.; Kozhuharov, V.; et al. The beam and detector of the NA62 experiment at CERN. J. Instrum. 2017, 12, P05025. [Google Scholar] [CrossRef]
- Cortina Gil, E.; Jerhot, J.; Lurkin, N.; Numao, T.; Velghe, B.; Wong, V.W.S.; Bryman, D.; Hives, Z.; Husek, T.; Kampf, K.; et al. Observation of the K+ → π+ν decay and measurement of its branching ratio. J. High Energy Phys. 2025, 2025. [Google Scholar] [CrossRef]
- Cortina Gil, E.; Kleimenova, A.; Minucci, E.; Padolski, S.; Petrov, P.; Shaikhiev, A.; Volpe, R.; Numao, T.; Petrov, Y.; Velghe, B.; et al. Performance of the NA62 trigger system. JHEP 2023, 03, 122. [Google Scholar] [CrossRef]
- Ammendola, R.; Biagioni, A.; Ciardiello, A.; Cretaro, P.; Frezza, O.; Lamanna, G.; Lo Cicero, F.; Lonardo, A.; Martinelli, M.; Piandani, R.; et al. Progress report on the online processing upgrade at the NA62 experiment. J. Instrum. 2022, 17, C04002. [Google Scholar] [CrossRef]
- Anzivino, G.; Barbanera, M.; Bizzeti, A.; Brizioli, F.; Bucci, F.; Cassese, A.; Cenci, P.; Ciaranfi, R.; Duk, V.; Engelfried, J.; et al. Light detection system and time resolution of the NA62 RICH. J. Instrum. 2020, 15, P10025. [Google Scholar] [CrossRef]
- Anghinolfi, F.; Jarron, P.; Krummenacher, F.; Usenko, E.; Williams, M. NINO, an ultra-fast, low-power, front-end amplifier discriminator for the Time-Of-Flight detector in ALICE experiment. In Proceedings of the 2003 IEEE Nuclear Science Symposium. Conference Record (IEEE Cat. No.03CH37515), Portland, OR, USA, 19–25 October 2003; Volume 1, pp. 375–379. [Google Scholar] [CrossRef]
- Spinella, F.; Angelucci, B.; Lamanna, G.; Minuti, M.; Pedreschi, E.; Pinzino, J.; Piandani, R.; Sozzi, M.; Venditti, S. The TEL62: A real-time board for the NA62 Trigger and Data AcQuisition. Data flow and firmware design. In Proceedings of the 2014 19th IEEE-NPSS Real Time Conference, Nara, Japan, 26–30 May 2014; pp. 1–2. [Google Scholar] [CrossRef]
- Christiansen, J. HPTDC High Performance Time to Digital Converter, Technical report; Version 2.2 for HPTDC version 1.3.; CERN: Geneva, Switzerland, 2004. [Google Scholar]
- Ammendola, R.; Angelucci, B.; Barbanera, M.; Biagioni, A.; Cerny, V.; Checcucci, B.; Fantechi, R.; Gonnella, F.; Koval, M.; Krivda, M.; et al. The integrated low-level trigger and readout system of the CERN NA62 experiment. Nucl. Instruments Methods Phys. Res. Sect. A Accel. Spectrometers Detect. Assoc. Equip. 2019, 929, 1–22. [Google Scholar] [CrossRef]
- Cretaro, P.; Biagioni, A.; Frezza, O.; Cicero, F.L.; Lonardo, A.; Martinelli, M.; Paolucci, P.S.; Pontisso, L.; Simula, F.; Vicini, P.; et al. NaNet: A Reconfigurable PCIe Network Interface Card Architecture for Real-time Distributed Heterogeneous Stream Processing in the NA62 Low Level Trigger. PoS 2019, TWEPP2018, 118. [Google Scholar] [CrossRef]
- Nottbeck, N.; Schmitt, D.C.; Büscher, P.D.V. Implementation of high-performance, sub-microsecond deep neural networks on FPGAs for trigger applications. J. Instrum. 2019, 14, P09014. [Google Scholar] [CrossRef]
- Iiyama, Y.; Cerminara, G.; Gupta, A.; Kieseler, J.; Loncar, V.; Pierini, M.; Qasim, S.R.; Rieger, M.; Summers, S.; Van Onsem, G.; et al. Distance-Weighted Graph Neural Networks on FPGAs for Real-Time Particle Reconstruction in High Energy Physics. Front. Big Data 2021, 3, 598927. [Google Scholar] [CrossRef] [PubMed]
- Bortolato, G.; Cepeda, M.; Heikkilä, J.; Huber, B.; Leutgeb, E.; Rabady, D.; Sakulin, H.; on behalf of the CMS collaboration. Design and implementation of neural network based conditions for the CMS Level-1 Global Trigger upgrade for the HL-LHC. J. Instrum. 2024, 19, C03019. [Google Scholar] [CrossRef]
- Migliorini, M.; Pazzini, J.; Triossi, A.; Zanetti, M.; Zucchetta, A. Muon trigger with fast Neural Networks on FPGA, a demonstrator. J. Phys. Conf. Ser. 2022, 2374, 012099. [Google Scholar] [CrossRef]
- Govorkova, E.; Puljak, E.; Aarrestad, T.; James, T.; Loncar, V.; Pierini, M.; Pol, A.A.; Ghielmetti, N.; Graczyk, M.; Summers, S.; et al. Autoencoders on field-programmable gate arrays for real-time, unsupervised new physics detection at 40 MHz at the Large Hadron Collider. Autoencoders on FPGAs for real-time, unsupervised new physics detection at 40 MHz at the Large Hadron Collider. Nat. Mach. Intell. 2022, 4, 154–161. [Google Scholar] [CrossRef]
- Aberle, O.; Béjar Alonso, I.; Brüning, O.; Fessia, P.; Rossi, L.; Tavian, L.; Zerlauth, M.; Adorisio, C.; Adraktas, A.; Ady, M.; et al. High-Luminosity Large Hadron Collider (HL-LHC): Technical Design Report; CERN Yellow Reports: Monographs; CERN: Geneva, Switzerland, 2020. [Google Scholar] [CrossRef]
- Peters, A.; Sindrilaru, E.; Adde, G. EOS as the present and future solution for data storage at CERN. J. Phys. Conf. Ser. 2015, 664, 042042. [Google Scholar] [CrossRef]
- NA62 Collaboration. 2017 NA62 Status Report to the CERN SPSC; Technical report; CERN: Geneva, Switzerland, 2017. [Google Scholar]
- Coelho, C.N.; Kuusela, A.; Li, S.; Zhuang, H.; Ngadiuba, J.; Aarrestad, T.K.; Loncar, V.; Pierini, M.; Pol, A.A.; Summers, S. Automatic heterogeneous quantization of deep neural networks for low-latency inference on the edge for particle detectors. Nat. Mach. Intell. 2021, 3, 675–686. [Google Scholar] [CrossRef]
- Duarte, J.; Han, S.; Harris, P.; Jindariani, S.; Kreinar, E.; Kreis, B.; Ngadiuba, J.; Pierini, M.; Rivera, R.; Tran, N.; et al. Fast inference of deep neural networks in FPGAs for particle physics. JINST 2018, 13, P07027. [Google Scholar] [CrossRef]
- Aarrestad, T.; Loncar, V.; Ghielmetti, N.; Pierini, M.; Summers, S.; Ngadiuba, J.; Petersson, C.; Linander, H.; Iiyama, Y.; Di Guglielmo, G.; et al. Fast convolutional neural networks on FPGAs with hls4ml. Mach. Learn. Sci. Technol. 2021, 2, 045015. [Google Scholar] [CrossRef]
- Vasudevan, A.; Anderson, A.; Gregg, D. Parallel Multi Channel convolution using General Matrix Multiplication. In Proceedings of the 2017 IEEE 28th International Conference on Application-specific Systems, Architectures and Processors (ASAP), Seattle, WA, USA, 10–12 July 2017; pp. 19–24. [Google Scholar] [CrossRef]
- Ammendola, R.; Biagioni, A.; Chiarini, C.; Cretaro, P.; Frezza, O.; Lo Cicero, F.; Lonardo, A.; Martinelli, M.; Perticaroli, P.; Piandani, R.; et al. The new hardware trigger processor at NA62 experiment: Status of the System and First Results. In Proceedings of the 27th Conference on Computing in High Energy and Nuclear Physics (CHEP 2024), Krakow, Poland, 21–25 October 2024. [Google Scholar]
- Perticaroli, P.; Ammendola, R.; Biagioni, A.; Chiarini, C.; Ciardiello, A.; Cretaro, P.; Frezza, O.; Lo Cicero, F.; Martinelli, M.; Piandani, R.; et al. FPGA-RICH: A low-latency, high-throughput online particle identification system for the NA62 experiment. In Proceedings of the 27th Conference on Computing in High Energy and Nuclear Physics (CHEP 2024), Krakow, Poland, 19–25 October 2024. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Efficiency | 8×8- | 16×16- | 16×16- |
|---|---|---|---|
| 0 ring(s) | |||
| 1 ring(s) | |||
| 2 ring(s) | |||
| 3+ ring(s) | |||
| Purity | 8×8- | 16×16- | 16×16- |
| 0 ring(s) | |||
| 1 ring(s) | |||
| 2 ring(s) | |||
| 3+ ring(s) |
| NN Variant | LUT | Flip-Flop | DSP | BRAM | II(Cycles) | Latency (Cycles) | Clock (MHz) |
|---|---|---|---|---|---|---|---|
| 8×8- | 65k | 40k | 145 | 0 | 5 | 18 | 150 |
| 7.3% | 2.2% | 7.4% | 0.0% | ||||
| 16×16- | 118k | 94k | 230 | 244 | 12 | 26 | 150 |
| 13.2% | 5.2% | 11.7% | 25.2% | ||||
| 16×16- | 51k | 29k | 282 | 1 | 369 | 388 | 220 |
| 5.7% | 1.6% | 14.4% | 0.1% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Perticaroli, P.; Ammendola, R.; Biagioni, A.; Chiarini, C.; Ciardiello, A.; Cretaro, P.; Frezza, O.; Lo Cicero, F.; Martinelli, M.; Piandani, R.; et al. Achieving Low-Latency, High-Throughput Online Partial Particle Identification for the NA62 Experiment Using FPGAs and Machine Learning. Electronics 2025, 14, 1892. https://doi.org/10.3390/electronics14091892
Perticaroli P, Ammendola R, Biagioni A, Chiarini C, Ciardiello A, Cretaro P, Frezza O, Lo Cicero F, Martinelli M, Piandani R, et al. Achieving Low-Latency, High-Throughput Online Partial Particle Identification for the NA62 Experiment Using FPGAs and Machine Learning. Electronics. 2025; 14(9):1892. https://doi.org/10.3390/electronics14091892
Chicago/Turabian StylePerticaroli, Pierpaolo, Roberto Ammendola, Andrea Biagioni, Carlotta Chiarini, Andrea Ciardiello, Paolo Cretaro, Ottorino Frezza, Francesca Lo Cicero, Michele Martinelli, Roberto Piandani, and et al. 2025. "Achieving Low-Latency, High-Throughput Online Partial Particle Identification for the NA62 Experiment Using FPGAs and Machine Learning" Electronics 14, no. 9: 1892. https://doi.org/10.3390/electronics14091892
APA StylePerticaroli, P., Ammendola, R., Biagioni, A., Chiarini, C., Ciardiello, A., Cretaro, P., Frezza, O., Lo Cicero, F., Martinelli, M., Piandani, R., Pontisso, L., Raggi, M., Rossi, C., Simula, F., Turisini, M., Vicini, P., & Lonardo, A. (2025). Achieving Low-Latency, High-Throughput Online Partial Particle Identification for the NA62 Experiment Using FPGAs and Machine Learning. Electronics, 14(9), 1892. https://doi.org/10.3390/electronics14091892