
Automatic Pruning and Quality Assurance of Object Detection Datasets for Autonomous Driving




Abstract
1. Introduction
2. Methodology
- Automated quality assurance of the AI training dataset.
- Calculation of data quality indicators through prediction results of the trained model.
- Calculation of statistical indicators to satisfy statistical diversity and eliminate bias.
- Reducing the amount of data required for training.
- Automatic classification of data requiring re-annotating.
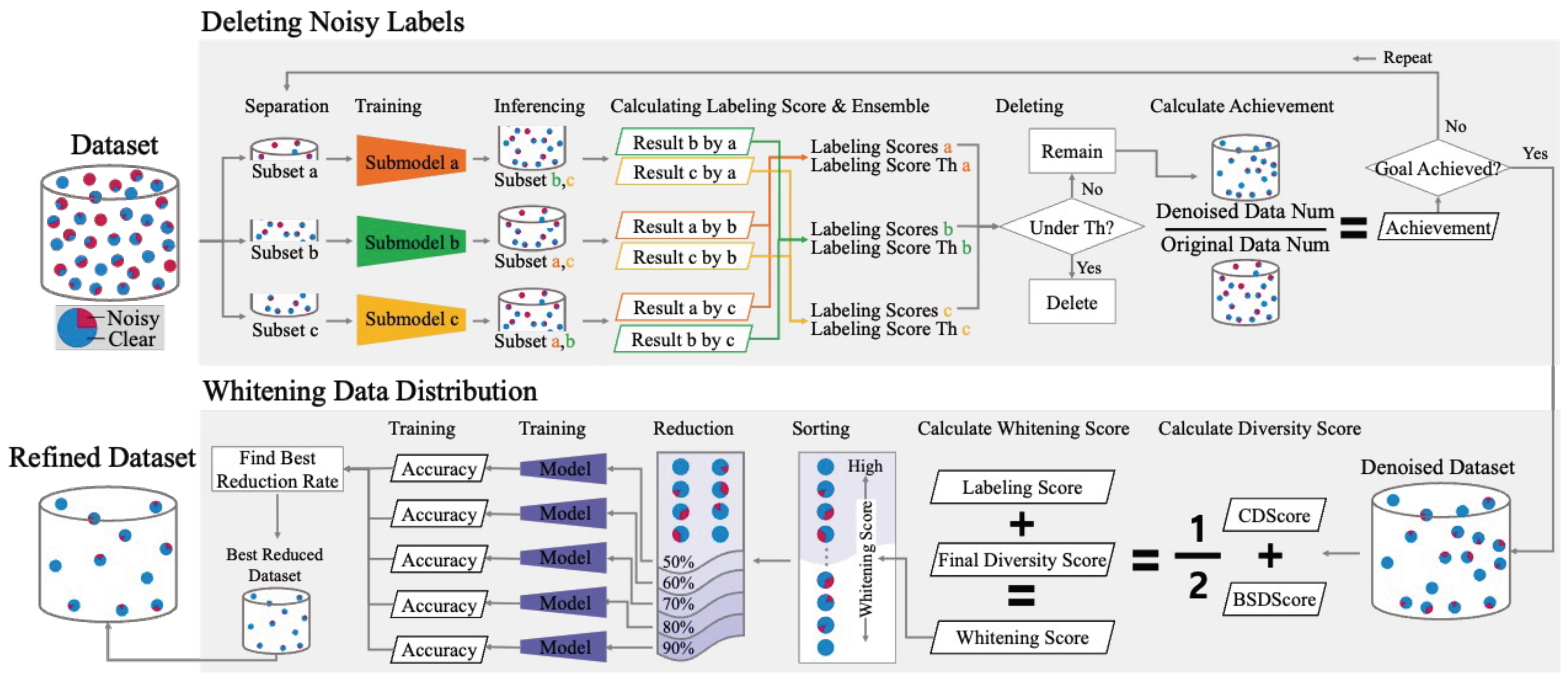
3. Proposed System: Deleting Noisy Labels
3.1. Overview
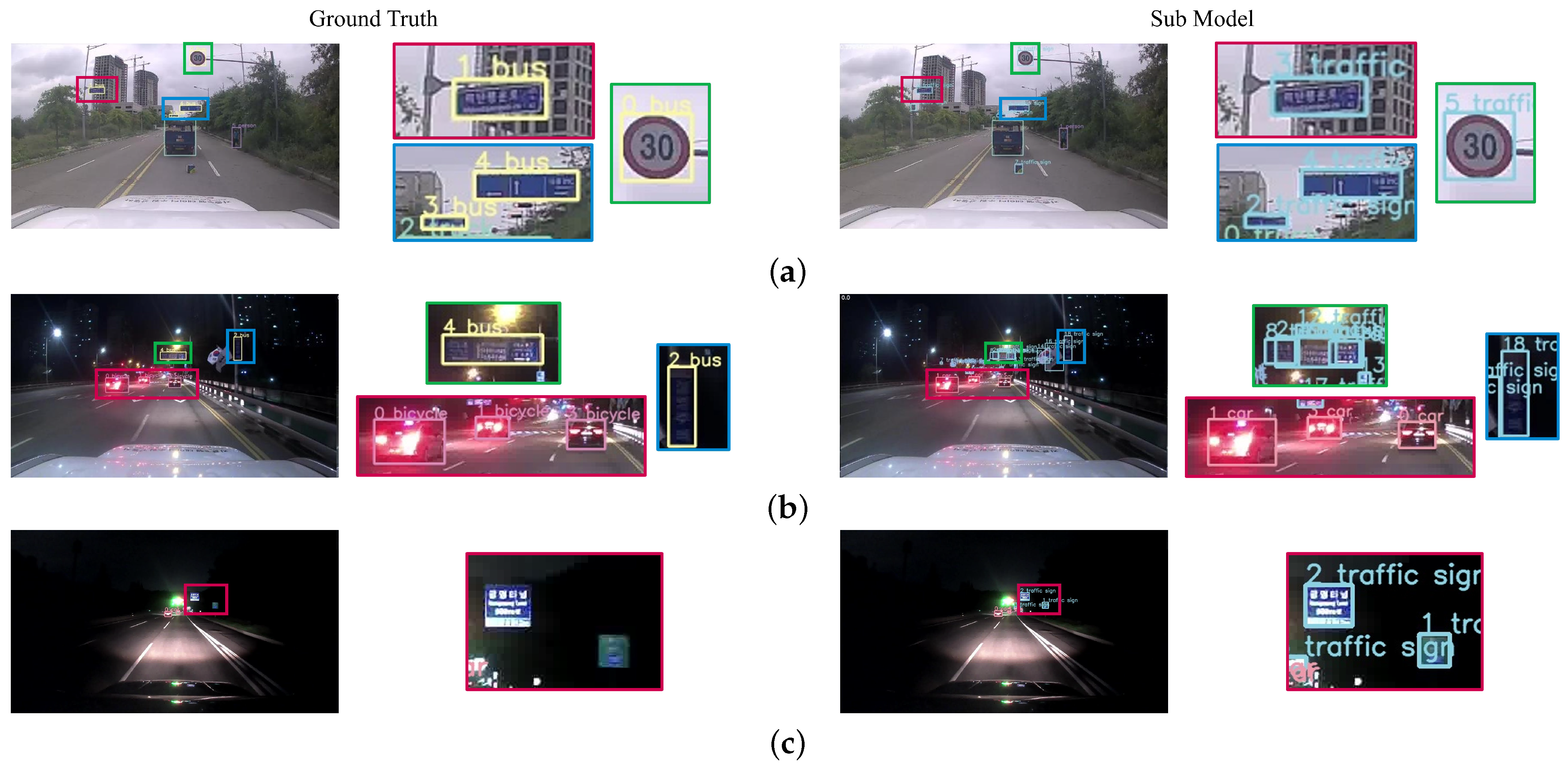
3.2. Defining LScore
3.3. Model Training
3.4. LScore Ensemble
3.4.1. Calculation of the E’LScore Threshold
3.4.2. Calculation of the E’LScore
3.5. Deleting Ratio Score
4. Proposed System: Data Distribution Whitening
4.1. Overview
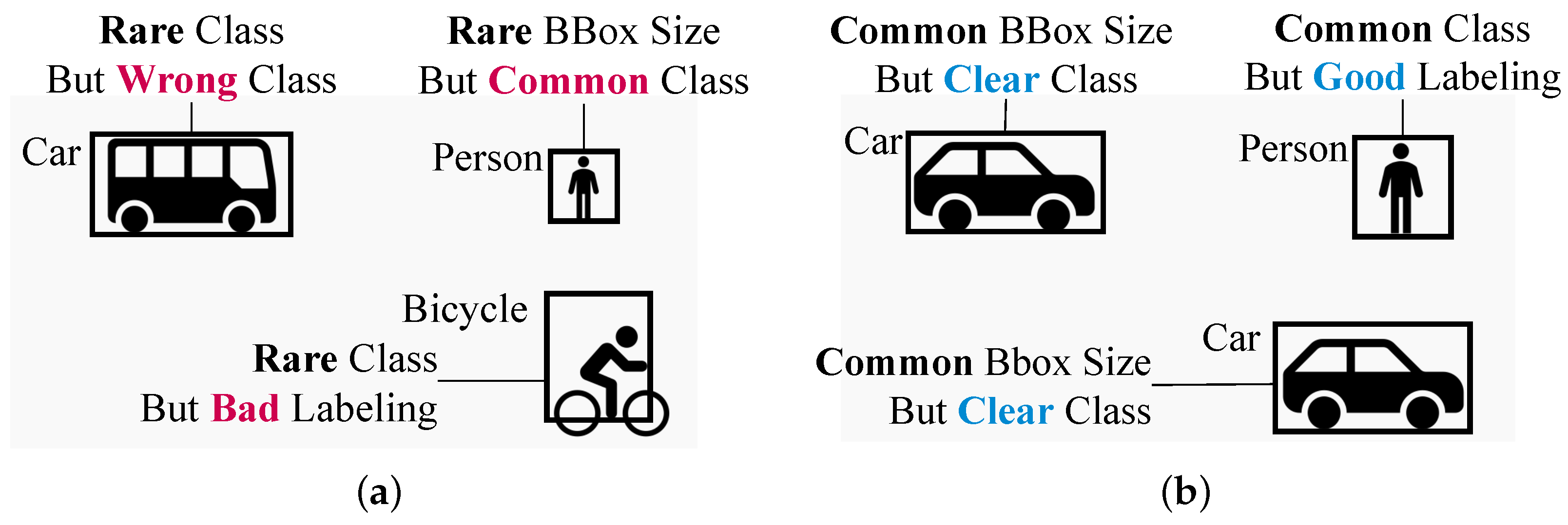
4.2. Diversity Score
4.2.1. Calculation of the CDScore
| Algorithm 1 Normalized Deviation List Generator |
|
4.2.2. Calculating BSDScore
4.3. Calculating the Whitening Score
5. Experiments and Results
5.1. Experimental Setup
5.2. Results of Deleting Noisy Labels
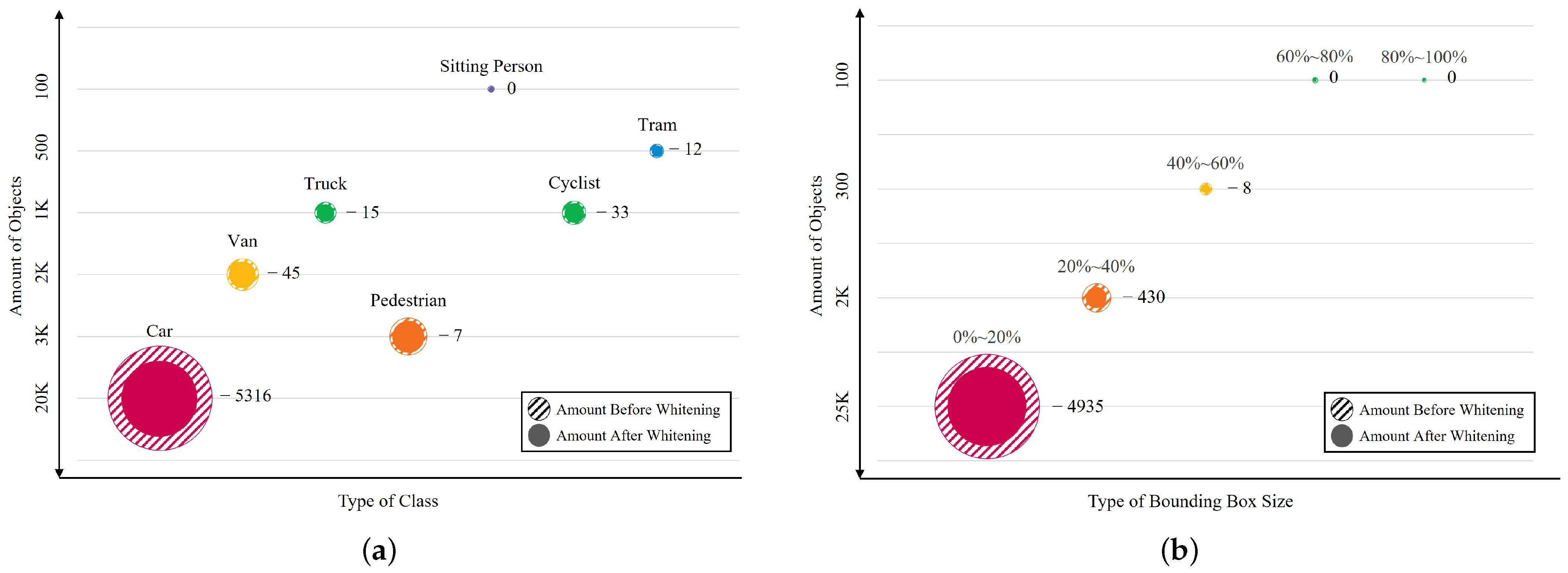
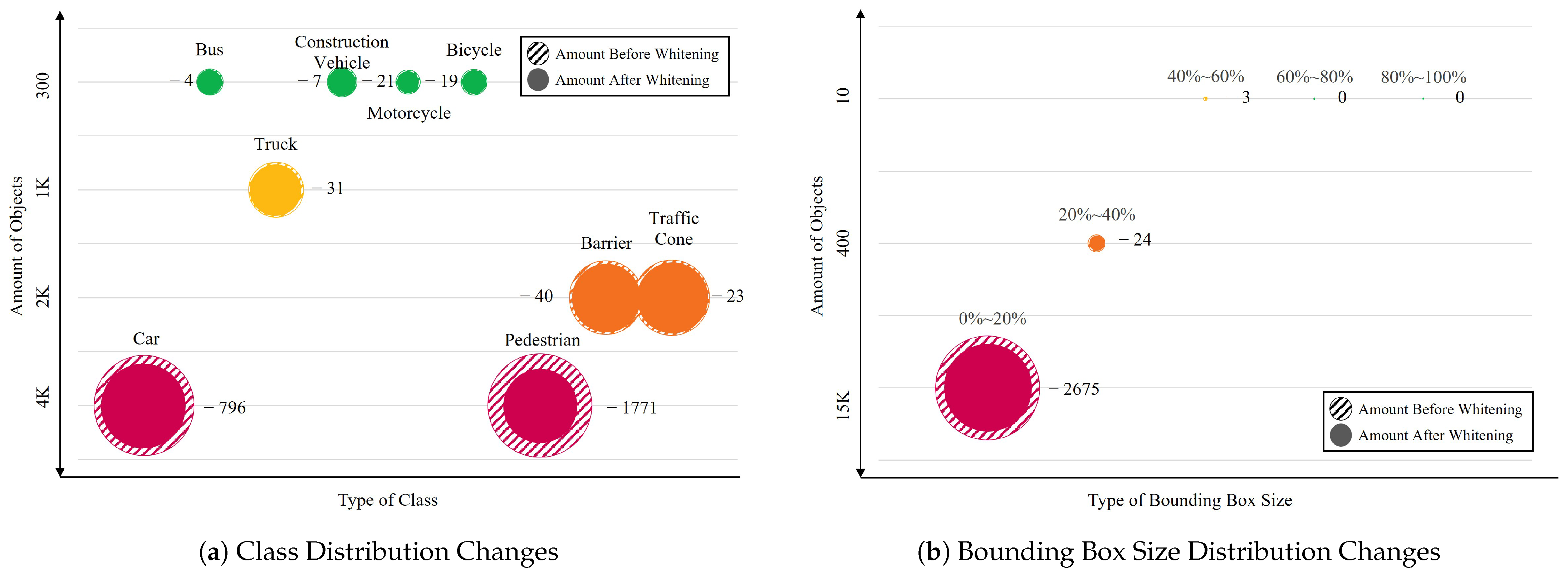
5.3. Results of Data Distribution Whitening
6. Discussion and Future Scope
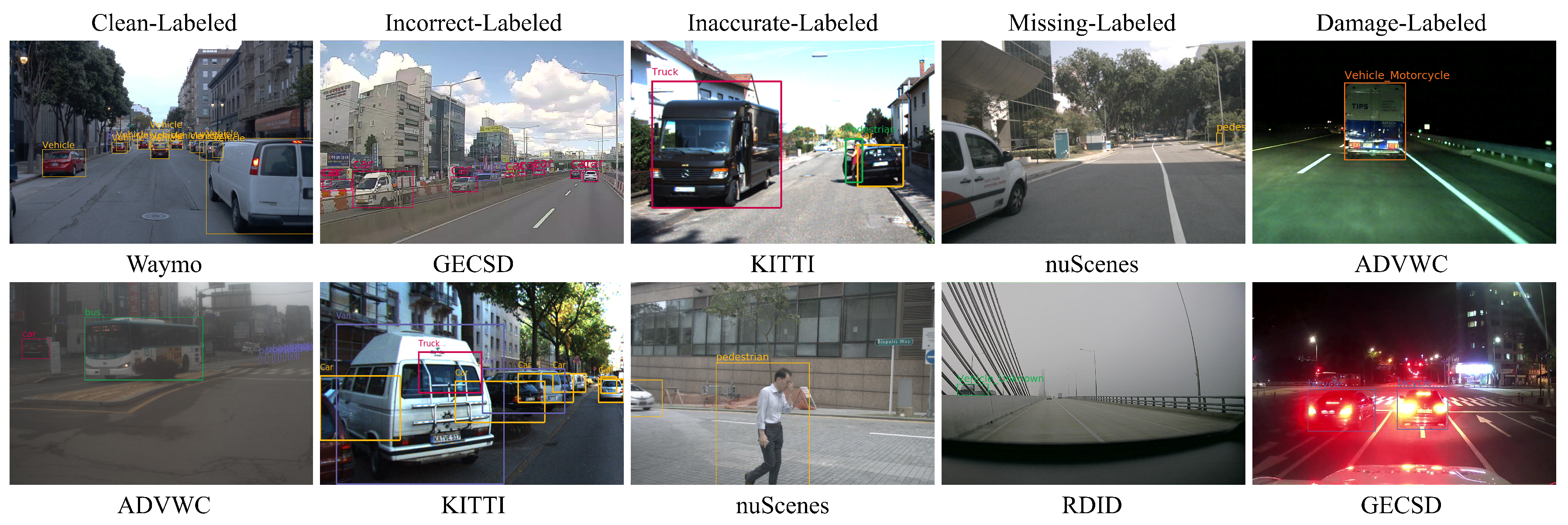
- It automatically finds incorrect, inaccurate, missed, and damaged labels generated during the human annotation process.
- The training efficiency is increased by lowering the priority of duplicate or complex data and excluding it from the training dataset.
- Quality assurance, previously performed by humans on a small number of random pieces of data, can be automated on the entire dataset, saving time and money.
- It is easy to select data that need to be modified and reorganized into a high-quality dataset.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| AP | Average Precision |
| ADVWC | Autonomous Driving Data in Various Weather Conditions |
| BSDScore | Bounding Box Size Diversity Score |
| CDScore | Class Diversity Score |
| CNN | Convolutional Neural Network |
| E’LScore | Ensembled Labeling Score |
| FPN | Feature Pyramid Network |
| GT | Ground Truth |
| GECSD | Generic and Edge Case Scenario Data |
| IoU | Intersection over Union |
| LScore | Labeling Score |
| RPN | Region Proposal Network |
| RDID | Road Driving Image Data |
References
- Ma, Y.; Wang, Z.; Yang, H.; Yang, L. AI applications in the dev. of autonomous vehicles: A survey. IEEE/CAA J. Autom. Sinica 2020, 7, 315–329. [Google Scholar] [CrossRef]
- Cunneen, M.; Mullins, M.; Murphy, F. Autonomous vehicles and embedded AI: The challenges of framing machine driving decisions. Appl. Artif. Intell. 2019, 33, 706–731. [Google Scholar] [CrossRef]
- Howard, J. AI: Implications for the future of work. Am. J. Ind. Med. 2019, 62, 917–926. [Google Scholar] [CrossRef] [PubMed]
- Roh, Y.; Heo, G.; Whang, S.E. A survey on data collection for ML: A big data-AI integration perspective. IEEE Trans. Knowl. Data Eng. 2019, 33, 1328–1347. [Google Scholar] [CrossRef]
- Mahmood, R.; Lucas, J.; Acuna, D.; Li, D.; Philion, J.; Alvarez, J.M.; Yu, Z.; Fidler, S.; Law, M.T. How much more data do I need? Estimating requirements for downstream tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognitio (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 275–284. [Google Scholar]
- Whang, S.E.; Roh, Y.; Song, H.; Lee, J.G. Data collection and quality challenges in deep learning: A data-centric AI perspective. VLDB J. 2023, 32, 791–813. [Google Scholar] [CrossRef]
- ISO/IEC 25012:2008; Systems and Software Engineering—Systems and Software Quality Requirements and Evaluation (SQuaRE)—Data Quality with Guidance for Use. International Organization for Standardization: Geneva, Switzerland, 2008.
- Ministry of Science and ICT of Korea, NIA of Korea. Data Quality Management Guidelines and Construction Guidelines for AI Learning 3—Quality Management Guideline. 2023. Available online: https://aihub.or.kr/aihubnews/qlityguidance/view.do?pageIndex=1&nttSn=10125&currMenu=135&topMenu=103&searchCondition=&searchKeyword= (accessed on 26 October 2024).
- Gualo, F.; Rodríguez, M.; Verdugo, J.; Caballero, I.; Piattini, M. Data quality certification using ISO/IEC 25012: Industrial experiences. J. Syst. Softw. 2021, 176, 110938. [Google Scholar] [CrossRef]
- Lytvyn, V.; Vysotska, V.; Demchuk, A.; Bublyk, M.; Demkiv, L.; Shpak, Y. Method of ontology quality assessment for knowledge base in intellectual systems based on ISO/IEC 25012. In Proceedings of the IEEE 15th International Conference on Computer Sciences and Information Technologies (CSIT), Zbarazh, Ukraine, 23–26 September 2020; IEEE: Piscataway, NJ, USA, 2020; Volume 1, pp. 109–113. [Google Scholar]
- Guerra-García, C.; Nikiforova, A.; Jiménez, S.; Perez-Gonzalez, H.G.; Ramírez-Torres, M.; Ontañon-García, L. ISO/IEC 25012-based methodology for managing data quality requirements in the development of information systems: Towards Data Quality by Design. Data Knowl. Eng. 2023, 145, 102152. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Zaidi, S.S.A.; Ansari, M.S.; Aslam, A.; Kanwal, N.; Asghar, M.; Lee, B. A survey of modern deep learning based object detection models. Digit. Signal Process. 2022, 126, 103514. [Google Scholar] [CrossRef]
- Li, J.; Socher, R.; Hoi, S.C. DivideMix: Learning with noisy labels as semi-supervised learning. arXiv 2020, arXiv:2002.07394. [Google Scholar]
- Mnih, V.; Hinton, G.E. Learning to label aerial images from noisy data. In Proceedings of the 29th International Conference on Machine Learning (ICML-12), Edinburgh, Scotland, 26 June–1 July 2012; pp. 567–574. [Google Scholar]
- Kim, Y.; Kim, J.M.; Akata, Z.; Lee, J. Large loss matters in weakly supervised multi-label classification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14156–14165. [Google Scholar]
- Ghosh, A.; Manwani, N.; Sastry, P. On the robustness of decision tree learning under label noise. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD), Jeju, Republic of Korea, 23–26 May 2017; pp. 685–697. [Google Scholar]
- Zha, D.; Bhat, Z.P.; Lai, K.H.; Yang, F.; Jiang, Z.; Zhong, S.; Hu, X. Data-centric Artificial Intelligence: A Survey. arXiv 2023, arXiv:2303.10158. [Google Scholar] [CrossRef]
- Zhou, X.; Chai, C.; Li, G.; Sun, J. Database meets AI: A survey. IEEE Trans. Knowl. Data Eng. 2020, 34, 1096–1116. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 2446–2454. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11621–11631. [Google Scholar]
- Wang, W.; Li, Y.; Li, A.; Zhang, J.; Ma, W.; Liu, Y. An Empirical Study on Noisy Label Learning for Program Understanding. In Proceedings of the IEEE/ACM International Conference on Software Engineering (ICSE), Lisbon, Portugal, 14–20 April 2024; pp. 1–12. [Google Scholar]
- Deng, L.; Yang, B.; Kang, Z.; Wu, J.; Li, S.; Xiang, Y. Separating hard clean samples from noisy samples with samples’ learning risk for DNN when learning with noisy labels. Complex Intell. Syst. 2024, 10, 4033–4054. [Google Scholar] [CrossRef]
- Zhang, J.; Song, B.; Wang, H.; Han, B.; Liu, T.; Liu, L.; Sugiyama, M. Badlabel: A robust perspective on evaluating and enhancing label-noise learning. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 4398–4409. [Google Scholar] [CrossRef]
- Natarajan, N.; Dhillon, I.S.; Ravikumar, P.K.; Tewari, A. Learning with noisy labels. Adv. Neural Inf. Process. Syst. 2013, 26, 1–9. [Google Scholar]
- Song, H.; Kim, M.; Park, D.; Shin, Y.; Lee, J.G. Learning from noisy labels with DNNs: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 1–19. [Google Scholar]
- He, H.; Garcia, E.A. Learning from imbalanced data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Liu, D.; Tsang, I.W.; Yang, G. A convergence path to deep learning on noisy labels. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef]
- Oleghe, O. A predictive noise correction methodology for manufacturing process datasets. J. Big Data 2020, 7, 1–27. [Google Scholar] [CrossRef]
- Xiong, H.; Pandey, G.; Steinbach, M.; Kumar, V. Enhancing data analysis with noise removal. IEEE Trans. Knowl. Data Eng. 2006, 18, 304–319. [Google Scholar] [CrossRef]
- Sun, Y.; Gu, Z. Using computer vision to recognize construction material: A Trustworthy Dataset Perspective. Resour. Conserv. Recycl. 2022, 183, 106362. [Google Scholar] [CrossRef]
- Zhang, J.; Wu, M.; Zhou, C.; Sheng, V.S. Active crowdsourcing for multilabel annotation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 3549–3559. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Sheng, V.S.; Li, T.; Wu, X. Improving crowdsourced label quality using noise correction. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 1675–1688. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, H.; Xie, W.; Liu, N.; Li, Q.; Jiang, D.; Lin, P.; Wu, K.; Chen, L. Cleaning uncertain data with crowdsourcing-a general model with diverse accuracy rates. IEEE Trans. Knowl. Data Eng. 2020, 34, 3629–3642. [Google Scholar] [CrossRef]
- Wu, X.; Jiang, L.; Zhang, W.; Li, C. Three-way decision-based noise correction for crowdsourcing. Int. J. Approx. Reason. 2023, 160, 108973. [Google Scholar] [CrossRef]
- Xu, N.; Li, J.Y.; Liu, Y.P.; Geng, X. Trusted-data-guided label enhancement on noisy labels. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 9940–9951. [Google Scholar] [CrossRef]
- Contardo, G.; Denoyer, L.; Artières, T. A meta-learning approach to one-step active learning. arXiv 2017, arXiv:1706.08334. [Google Scholar]
- Bernhardt, M.; Castro, D.C.; Tanno, R.; Schwaighofer, A.; Tezcan, K.C.; Monteiro, M.; Bannur, S.; Lungren, M.P.; Nori, A.; Glocker, B. Active label cleaning for improved dataset quality under resource constraints. Nat. Commun. 2022, 13, 1161. [Google Scholar] [CrossRef]
- Bachman, P.; Sordoni, A.; Trischler, A. Learning algorithms for active learning. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; PMLR: Breckenridge, CO, USA, 2017; pp. 301–310. [Google Scholar]
- Sener, O.; Savarese, S. Active learning for convolutional neural networks: A core-set approach. arXiv 2017, arXiv:1708.00489. [Google Scholar]
- Takezoe, R.; Liu, X.; Mao, S.; Chen, M.T.; Feng, Z.; Zhang, S.; Wang, X. Deep active learning for computer vision: Past and future. APSIPA Trans. Signal Inf. Process. 2023, 12, 1–18. [Google Scholar] [CrossRef]
- Khosla, A.; Zhou, T.; Malisiewicz, T.; Efros, A.A.; Torralba, A. Undoing the damage of dataset bias. In Proceedings of the European Conference on Computer Vision (ECCV), Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 158–171. [Google Scholar]
- Li, Y.; Vasconcelos, N. REPAIR: Removing representation bias by dataset resampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9572–9581. [Google Scholar]
- Chen, H.; Chen, J.; Ding, J. Data evaluation and enhancement for quality improvement of ML. IEEE Trans. Reliab. 2021, 70, 831–847. [Google Scholar] [CrossRef]
- Byerly, A.; Kalganova, T. Class density and dataset quality in high-dimensional, unstructured data. arXiv 2022, arXiv:2202.03856. [Google Scholar]
- Chen, K.; Chen, H.; Conway, N.; Hellerstein, J.M.; Parikh, T.S. Usher: Improving data quality with dynamic forms. IEEE Trans. Knowl. Data Eng. 2011, 23, 1138–1153. [Google Scholar] [CrossRef]
- Pičuljan, N.; Car, Ž. Machine learning-based label quality assurance for object detection projects in requirements engineering. Appl. Sci. 2023, 13, 6234. [Google Scholar] [CrossRef]
- Li, C.; Mao, Z.; Jia, M. A real-valued label noise cleaning method based on ensemble iterative filtering with noise score. Int. J. Mach. Learn. Cybern. 2024, 15, 1–26. [Google Scholar] [CrossRef]
- Fang, M.; Zhou, T.; Yin, J.; Wang, Y.; Tao, D. Data subset selection with imperfect multiple labels. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 2212–2221. [Google Scholar] [CrossRef]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. “Detectron2”. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 26 October 2024).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–9. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Korea Automobile Research Institute. Road Driving Image Data. 2020. Available online: https://www.aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=data&dataSetSn=180 (accessed on 26 October 2024).
- Korea National Information Society Agency. Autonomous Driving Data in Various Weather Conditions Dataset. 2021. Available online: https://www.aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=data&dataSetSn=630 (accessed on 26 October 2024).
- Korea Transportation Safety Authority. Generic and Edge Case Scenario Data. 2021. Available online: https://avds.kotsa.or.kr/open/normal/Open_Normal_List.do?bbs_seq=3010 (accessed on 4 November 2024).
- Chu, Z.; Zhang, R.; Yu, T.; Jain, R.; Morariu, V.; Gu, J.; Nenkova, A. Self-Cleaning: Improving a Named Entity Recognizer Trained on Noisy Data with a Few Clean Instances. In Proceedings of the Findings of the Association for Computational Linguistics (NAACL2024), Mexico City, Mexico, 16–21 June 2024; pp. 196–210. [Google Scholar]
- Chen, M.; Zhao, Y.; He, B.; Han, Z.; Huang, J.; Wu, B.; Yao, J. Learning with Noisy Labels Over Imbalanced Subpopulations. IEEE Trans. Neural Netw. Learn. Syst. 2024, 36, 6544–6555. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Owner | Image Resolution | Number of Images | Number of Classes |
|---|---|---|---|---|
| KITTI | Karlsruhe Institute of Technology | 1242 × 375 | 7481 | 7 |
| Waymo | Waymo LLC | 1920 × 1080 | 6330 | 4 |
| nuScenes | nuTonomy | 1600 × 900 | 3376 | 10 |
| RDID | Korea Automobile Research Institute | 1280 × 720 | 48,025 | 26 |
| ADVWC | Korea Electronics Technology Institute | 1920 × 1080 | 57,612 | 23 |
| GECSD | Korea Transportation Safety Authority | 1920 × 1080 | 207,068 | 9 |
| Dataset | Iteration (Best) | Accuracy Before | Accuracy After | Number of Data | Number of Deleted Data |
|---|---|---|---|---|---|
| KITTI | 2 (1) | 65.62 | 65.64 (+0.02) | 7481 | 410 (−5%) |
| Waymo | 1 (1) | 46.58 | 46.99 (+0.41) | 6330 | 76 (−1%) |
| nuScenes | 3 (3) | 59.19 | 59.70 (+0.51) | 3376 | 675 (−19%) |
| RDID | 3 (1) | 66.02 | 66.48 (+0.46) | 48,025 | 775 (−2%) |
| ADVWC | 3 (2) | 66.52 | 67.95 (+1.43) | 57,612 | 7541 (−13%) |
| GECSD | 3 (3) | 58.65 | 59.95 (+1.30) | 207,068 | 22,914 (−11%) |
| Dataset | Reduction (Best) | Accuracy Before | Accuracy After | Number of Data | Number of Deleted Data |
|---|---|---|---|---|---|
| KITTI | 30% | 65.64 | 67.96 (+2.32) | 7071 | 2123 |
| Waymo | 20% | 46.99 | 47.15 (+0.16) | 6254 | 1251 |
| nuScenes | 30% | 59.70 | 62.59 (+2.89) | 2701 | 805 |
| RDID | 20% | 66.48 | 66.40 (−0.08) | 47,250 | 9450 |
| ADVWC | 20% | 67.95 | 68.05 (+0.10) | 50,071 | 10,015 |
| GECSD | 30% | 59.95 | 60.55 (+0.60) | 184,154 | 55,245 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, K.; Kakani, V.; Kim, H. Automatic Pruning and Quality Assurance of Object Detection Datasets for Autonomous Driving. Electronics 2025, 14, 1882. https://doi.org/10.3390/electronics14091882
Kim K, Kakani V, Kim H. Automatic Pruning and Quality Assurance of Object Detection Datasets for Autonomous Driving. Electronics. 2025; 14(9):1882. https://doi.org/10.3390/electronics14091882
Chicago/Turabian StyleKim, Kana, Vijay Kakani, and Hakil Kim. 2025. "Automatic Pruning and Quality Assurance of Object Detection Datasets for Autonomous Driving" Electronics 14, no. 9: 1882. https://doi.org/10.3390/electronics14091882
APA StyleKim, K., Kakani, V., & Kim, H. (2025). Automatic Pruning and Quality Assurance of Object Detection Datasets for Autonomous Driving. Electronics, 14(9), 1882. https://doi.org/10.3390/electronics14091882