1. Introduction
The ongoing progression of computer technology has rendered machine learning increasingly pivotal throughout diverse research domains, including data analysis [
1,
2], data mining [
3,
4], and pattern recognition [
5,
6]. Kernel methods have become a significant research focus in the field of machine learning [
7]. Recently, the concepts of implicit kernel mapping (IKM) and empirical kernel mapping (EKM) have been introduced consecutively. IKM implicitly transforms samples into feature space via inner product representation; nevertheless, its dependence on inner products constrains the applicability of certain approaches and may diminish separability due to inadequate feature selection [
8]. Consequently, EKM, as a direct mapping technique, facilitates the direct mapping of samples to the empirical feature space, thereby streamlining the kernelization process and circumventing intricate inner product computations.
While choosing an appropriate kernel function is essential for addressing certain issues, researchers have identified this task as exceedingly difficult. Various methods for kernel selection have been proposed to overcome this issue, including support vector machine parameter selection based on inter-class distances [
9], grid search [
10], and evolutionary algorithms [
11], all intended to optimize kernel parameters. Nonetheless, the constraints of a singular kernel diminish its efficacy in addressing intricate issues, resulting in the development of multiple kernel learning (MKL) [
12], which facilitates the optimization of kernel weights during training by amalgamating various candidate kernels, thereby improving flexibility and performance.
In the study of MKL, many algorithms have been introduced to tackle the selection of kernel weights, including approaches that formulate convex quadratic constrained quadratic programming (QCQP) [
13] and semidefinite programming (SDP) [
14]. Moreover, Multiple Empirical Kernel Learning (MEKL) [
15] integrates the benefits of EKM and can reconstruct the empirical feature space, thereby enhancing the applications of kernel methods. Significant contributions, including collaborative and geometric multi-kernel learning (CGMKL) [
16] and Multiple Partial Empirical Kernel Learning with Instance Weighting and Boundary Fitting (IBMPEKL) [
17] introduced by Zhu et al., exhibit efficacy in multi-class classification challenges. On the other hand, the authors of [
18] introduce SA-nODE, a novel supervised classification method that utilizes ordinary differential equations with predefined stable attractors, to guide system dynamics toward specific points corresponding to input categories.
Despite its effectiveness, MEKL suffers from high computational demands due to the need to construct multiple empirical feature spaces, limiting its scalability to large datasets. To address this, researchers have explored ways to reduce training time. For instance, Fan [
19] proposed the Multiple Random Empirical Kernel Learning Machine (MREKLM), which applies random projection techniques [
20] to reduce computational cost by building empirical kernels using only a randomly selected subset of the data. However, MREKLM does not consider the distribution of samples, which can lead to suboptimal feature representations and decreased accuracy. To overcome these limitations, this study introduces Fast Multiple Empirical Kernel Learning Incorporating Data Distribution Information (FMEKL-DDI), which enhances empirical kernel construction by incorporating within-class distribution data. Additionally, to further reduce the sample selection time, FMEKL-DDI employs a boundary-aware sample selection strategy using the BPLSH algorithm [
21], allowing the efficient identification of informative samples near decision boundaries. Together, these improvements result in faster training and more discriminative feature spaces, making FMEKL-DDI suitable for large-scale learning tasks.
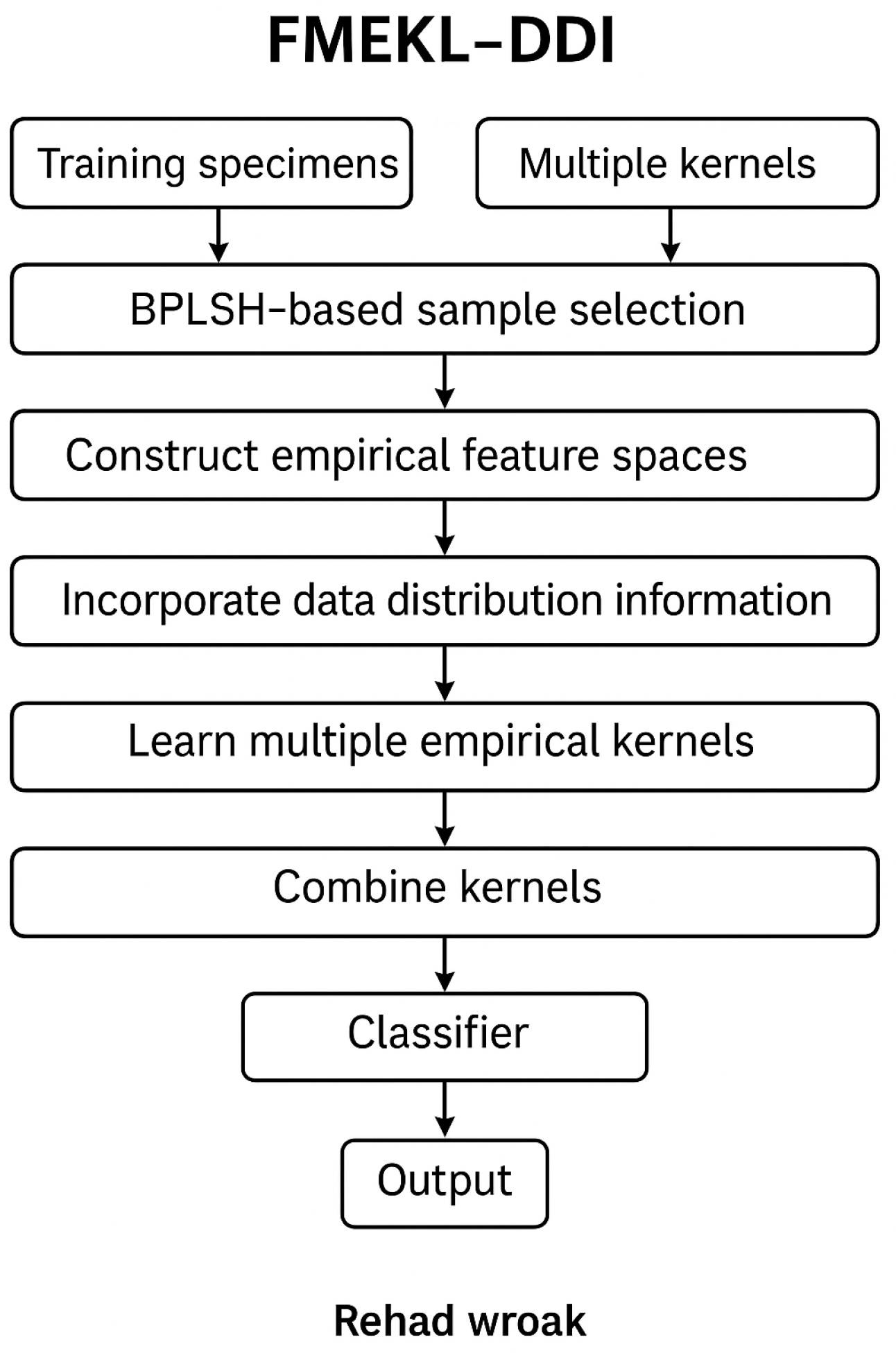
To simplify the distinctions among the related models, Multiple Empirical Kernel Learning (MEKL) builds several feature spaces from the data to improve classification, but it is computationally intensive. Multiple Random Empirical Kernel Learning Machine (MREKLM) improves speeds by randomly selecting a small set of samples to create those spaces, although it ignores the distribution of data, which can hurt accuracy. Our proposed method, Fast Multiple Empirical Kernel Learning with Data Distribution Information (FMEKL-DDI), addresses this by selecting samples more intelligently—using the BPLSH algorithm—and by considering how data points are spread within each class. This allows it to strike a better balance between accuracy and efficiency.
The main contributions of this work are summarized as follows:
We propose FMEKL-DDI, a novel empirical kernel learning method that integrates within-class distribution information through the use of the within-class scatter matrix, enhancing the quality of the empirical feature space.
We introduce an efficient boundary-preserving sample selection mechanism based on the BPLSH algorithm, which effectively identifies informative training samples while reducing redundancy and computational overhead.
Extensive experiments on benchmark and real-world datasets demonstrate that MEKL-DDI achieves superior accuracy and significantly lower training time compared to several state-of-the-art kernel learning approaches.
The remainder of this paper is organized as follows.
Section 2 provides a review of related work, including implicit kernel mapping and the MREKLM algorithm.
Section 3 presents the proposed FMEKL-DDI algorithm, detailing the incorporation of data distribution information and the construction of the classifier.
Section 4 discusses the experimental setup; evaluates the performance of the proposed method through various experiments; and includes comparisons, ablation studies, and real-world dataset validations. Finally,
Section 5 concludes the paper and outlines future directions for this research.
2. Related Work and Preliminaries
Kernel learning has emerged as a fundamental technique in machine learning, enabling algorithms to handle non-linear data by implicitly mapping inputs into high-dimensional feature spaces through kernel functions. Traditional methods such as Support Vector Machines and Kernel Principal Component Analysis leverage fixed kernels, but their performance is highly sensitive to kernel choice [
22]. To address this, multiple kernel learning frameworks were developed, combining several base kernels to improve flexibility and adaptability to complex data structures. Over time, variants such as nonlinear MKL, data-dependent MKL, and empirical kernel learning have evolved to enhance expressiveness, efficiency, and generalization [
23]. Recent advances have focused on improving computational scalability and incorporating data distribution awareness, laying the groundwork for more robust and adaptive kernel-based models [
24,
25].
2.1. Implicit Kernell Mapping
This section introduces implicit kernels, expressed through the inner product form of a mapping function, in contrast to the direct computational expression of empirical kernels. Implicit kernels are primarily designed for nonlinear classifiers, in contrast to linear classifiers.
Let
denote the training dataset, where
is the
i-th input sample and
is its corresponding class label. Let
P denote the number of selected samples via the BPLSH algorithm for constructing the empirical feature space. The kernel function is denoted by
, and the kernel matrix is
with entries
. The empirical kernel mapping is represented as
, where
r is the reduced dimensionality after eigen-decomposition. The within-class scatter matrix is defined as
, where
is the mean of class
c and
is the set of samples in class
c. The weight matrix
has entries
if
and
belong to the same class
c; otherwise, it has 0. The diagonal matrix
D has entries
. The classifier is a linear combination of mapped kernels
, where
is the augmented empirical feature vector, and
is the corresponding weight vector learned using the least-squares method. We summarize all frequently used notations in
Table 1.
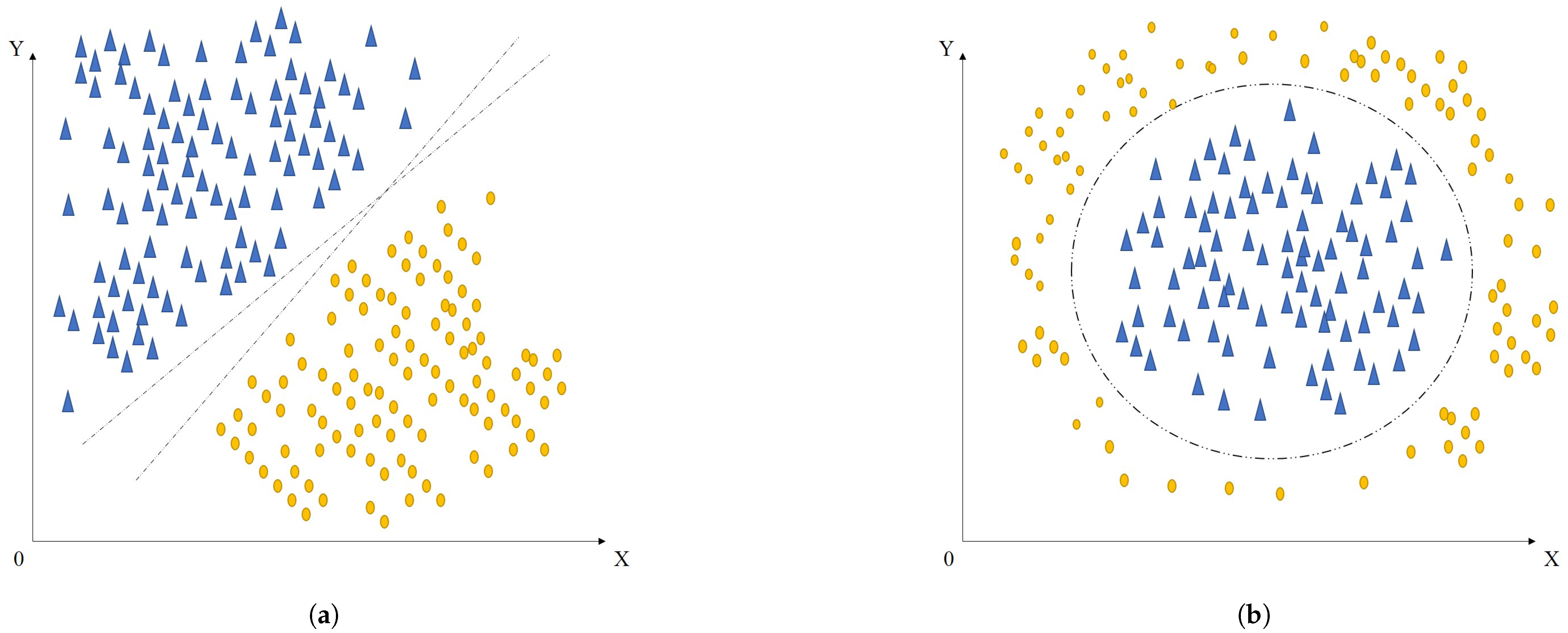
Figure 1a illustrates a scenario in which two-dimensional linearly separable samples can be effectively divided using a straight line. Consider a labeled dataset
, where each label
indicates the class of the corresponding sample
. Within linear classification, a sample can be expressed as
, where
and
represent the horizontal and vertical coordinates, respectively. A linear decision boundary defined by the equation
can separate the two classes. The associated decision function
assigns a class based on the sign of
: if
, the sample belongs to class
; if
, it is assigned to class
; if
, it lies on the decision boundary.
However, real-world data are often non-linearly separable, as shown in
Figure 1b, making linear classifiers insufficient. To address this, kernel-based methods have been introduced, which use implicit mappings to transform the data into higher-dimensional spaces where linear separation becomes feasible. These methods leverage the inner product form of kernel functions. For instance, mapping a two-dimensional point
to a three-dimensional space can be carried out as
. This transformation can be defined by a mapping function
. The inner product in the transformed space can be computed as follows:
Here, K is the kernel function, which defines an inner product in the higher-dimensional space without requiring the explicit computation of mapping —hence the term “implicit kernel”. This approach enables algorithms to operate in a transformed space where non-linear relationships can be addressed with linear classifiers, significantly boosting classification performance.
Nonetheless, directly applying kernel methods to certain linear discriminant analysis techniques, such as Kernel Direct Discriminant Analysis (KDDA) [
26], poses challenges. Methods like Orthogonal Linear Discriminant Analysis (OLDA) [
27] and Uncorrelated Linear Discriminant Analysis (ULDA) [
28] rely on singular value decomposition, which complicates their kernelization. As a result, implicit kernel approaches are often employed to overcome these limitations in extending linear models to non-linear scenarios.
2.2. Multiple Random Empirical Learning Machine (MREKLM)
Fan [
19] proposed the Multiple Random Empirical Kernel Learning Machine (MREKLM), which is a classic algorithm within the domain of empirical kernels. This section utilizes MREKLM as an illustrative example to introduce empirical kernels. MREKLM constructs the empirical feature space by randomly selecting a small subset of samples from the training data, and the model is presented below.
Assume the training samples
, where
and
. Randomly select
M subsets, each of size
P (where
), that are denoted as
for random projection [
20]. The idea is to avoid using the entire dataset to build feature spaces. Instead, smaller random subsets are used to speed up computation while still preserving meaningful structure.
For each random subset , the corresponding random empirical kernel mapping is constructed as follows:
First, compute the kernel matrix , where the kernel function is defined as with . This matrix captures the pairwise similarity between selected samples in the subset .
The kernel matrix
is a positive semidefinite matrix, which can be decomposed using the following:
Here, is a diagonal matrix containing the eigenvalues of , and is a matrix for which its columns are the corresponding eigenvectors. This decomposition allows us to understand the underlying structure of the kernel space and reduce dimensionality while preserving variance.
The random empirical kernel mapping function
is defined as follows:
This mapping projects a sample x into a new empirical feature space, where its coordinates are based on similarities to the reference samples in .
It is important to note that when the rank of
is
, it has
zero eigenvalues. Additionally, the eigenvector matrix
satisfies the following:
The eigenvalue matrix
can be expressed as follows:
Here, are the positive eigenvalues of , and the zero entries correspond to redundant or non-informative directions. We discard the zero components to reduce noise and computation, keeping only the meaningful directions in the space.
After removing the zero values, we obtain an
-dimensional empirical feature vector. The reduced empirical kernel is then denoted by
, and the mapping is as follows:
Here, contains positive eigenvalues, and is a matrix of the corresponding eigenvectors.
In essence, provides a compact, meaningful representation of x in the empirical feature space built from subset .
After constructing the M empirical kernels, all training samples are mapped into each of the M empirical feature spaces. The final transformed dataset is represented as . This gives us M different views of the data, each built from a random subset, which collectively capture diverse structural aspects of the dataset. These mapped features can then be used for efficient and robust classification.
4. Experimental Results
4.1. Experimental Settings
This section will outline the parameter design of the pertinent algorithms, which will be applicable to all experiments carried out here and subsequently. All alterations to the parameters will be clearly specified in each section. This paper will also incorporate the parameter designs of more comparable algorithms, specifically FMEKL-DDI, MREKLM, MEKL, IBMPEKL [
17], CGMKL [
16], and NLMKL [
31]. All previously stated algorithms are kernel-based, and the Gaussian kernel function
is chosen, where
;
N denotes the quantity of training samples and the kernel parameter
. The quantity of kernels is selected as
. The learning rate for IBMPEKL is established at 0.99, whereas for CGMKL, it is established at 1. The intervals for the regularization parameters
C and
are established as
. For BPLSH, the number of hash functions is designated as
, and the number of hash families is specified as
.
MREKLM entails the selection of
samples, characterized by a selection ratio of
, where
P signifies the number of selected samples and
N indicates the total number of training samples. Experimental data in reference [
19] indicate that when the ratio
surpasses 0.5, there is no notable enhancement in accuracy, while the training duration increases substantially. Consequently, this study chooses
. A five-fold cross-validation technique [
32] is utilized to determine the optimal combinations of the specified parameters. The experimental configuration includes an i5-10300H processor working at 2.50 GHz, with 16 GB of RAM, a Windows 10 operating system, and MATLAB version R2021a. All experiments are conducted using this device. All datasets are sourced from the UCI repository [
33].
In particular, the selection of key parameters such as the kernel bandwidth
, the balancing factor
in distributional alignment, and the number of hash functions used in BPLSH was guided by both empirical tuning and theoretical insights. The kernel bandwidth
was chosen based on principles from kernel density estimation, where an appropriately scaled bandwidth ensures a smooth yet discriminative kernel matrix, preventing over-smoothing or overfitting [
34]. The parameter
controls the trade-off between projection fidelity and distributional regularization; it was tuned empirically across datasets to maintain stability while capturing within-class scatter effectively. For BPLSH, the number of hash functions determines the sensitivity to local boundary structures. A moderate number of hashes ensures the accurate identification of informative boundary samples while avoiding excessive overlap or noise [
35]. Together, these parameter choices reflect a balance between the theoretical guarantees of representation quality and practical performance observed in validation experiments.
All experiments were conducted on a system with an Intel Core i9 processor, 64 GB RAM, and an NVIDIA RTX 3090 GPU. The operating system was Ubuntu 22.04 LTS.
4.2. The Influence of the Number of Hash Functions and Hash Families on FMEKL-DDI
The BPLSH algorithm serves as the sample selection mechanism for the FMEKL-DDI algorithm, and it is characterized by two primary parameters: the quantity of hash functions
q and the count of hash families
m. This section of the experiment focuses on analyzing the impact of the two parameters of BPLSH on the FMEKL-DDI algorithm. The variable
q is selected from the set
, and the variable
m is chosen from the range
. The results from the experiments are detailed in
Table 2 and
Table 3. In particular, the authors of [
36] demonstrate that training two-layer neural networks exhibits sharp phase transitions in generalization performance based on mini-batch size, with learning failing below a critical threshold and succeeding above it.
The results of the experiments indicate that the number of hash functions and hash families does not significantly impact the training time. It can be concluded that as long as these parameters fall within a certain range, they do not adversely affect the experimental results.
Nevertheless, this experiment faced occurrences where certain settings did not produce results.
Table 2 and
Table 3 illustrate that when the number of hash families is 110 and the number of hash functions is 50 or more, no pertinent experimental findings were produced, suggesting a software anomaly. Upon excluding program-related difficulties, it was concluded that the categorization inconsistencies stemmed from an inadequate number of samples chosen in the final stage. Moreover, the consistently strong performance of FMEKL-DDI is largely due to its ability to align with the underlying data distribution through the within-class scatter matrix and its focus on boundary sample selection via BPLSH, which enhances class separation. These mechanisms enable the better adaptation of kernel learning relative to both linear and non-linear class structures. The variations in performance across datasets can be explained by how well each algorithm captures critical decision boundaries—FMEKL-DDI performs especially well when boundary samples and distribution alignment significantly impact classification, whereas other methods that rely on random or uniform sampling tend to underperform in such cases.
In conclusion, the performance of the FMEKL-DDI algorithm is significantly affected by the parameters m and q. On both the Iono and Twonorm datasets, higher values of m typically sustain high accuracy; however, in some instances, excessively high values of q can result in reductions in accuracy and increases in computational time. Therefore, the ranges and are regarded as appropriate.
4.3. Training Time Comparison
This segment of the experiment examines the efficacy of the FMEKL-DDI algorithm in relation to training duration. The comparable algorithms still under consideration in the experiment are NLMKL, MREKLM, MEKL, IBMPEKL, and CGMEKL. Furthermore, prior studies have demonstrated that the quantities of hash functions and hash families for FMEKL-DDI need not be excessive; hence, we established (q = 30) and (m = 20) for this investigation. This section includes eighteen datasets: Wdbc, Wpbc, Iris, Wine, Knowledge, EEG, Letter, Pendigits, and Polish; all were obtained from the UCI repository. Of these, ten datasets are classified as small-scale, whilst eight are designated as relatively larger datasets, with comprehensive details presented in
Table 4. The experimental findings are presented in
Table 5. The experimental result for each dataset is the average value derived from ten experiments.
Table 5 indicates that the training duration of FMEKL-DDI has been markedly diminished relative to other algorithms. For specific small datasets, while the training duration of FMEKL-DDI is diminished, the variation is not markedly significant. Nonetheless, with comparatively bigger datasets, it is apparent that the training duration of FMEKL-DDI has markedly diminished, consequently illustrating its efficacy in terms of training time.
In particular, while methods such as MEKL and IBMPEKL can achieve competitive accuracy, they often do so at the cost of significantly longer training times due to complex kernel computations and iterative optimization procedures. Conversely, MREKLM reduces training times through random sampling but may sacrifice accuracy due to suboptimal feature space representation. FMEKL-DDI effectively balances this trade-off by leveraging distribution-aware sample selection and efficient empirical kernel construction, achieving high accuracy with minimal computational cost. Understanding and explicitly managing this trade-off is crucial, particularly in real-world applications where resources are limited and timely decision-making is critical.
4.4. Classification Accuracy Comparison
This segment of the experiment mostly evaluates the classification accuracy of FMEKL-DDI in comparison to other algorithms. The algorithm parameter settings are unchanged from the previous section, and the datasets comprise eighteen datasets obtained from the UCI repository. The algorithms evaluated alongside FMEKL-DDI comprise NLMKL, MREKLM, MEKL, IBMPEKL, and CGMEKL.
The experimental outcomes are illustrated in
Table 2, with the height of the bar graph indicating the classification accuracy of each technique across various datasets; taller bars signify greater accuracy. The results indicate that FMEKL-DDI attains the highest classification accuracy when compared to the evaluated methods. Additionally,
Table 2 demonstrates that FMEKL-DDI consistently outperforms in classification across all eighteen datasets, highlighting its exceptional classification effectiveness.
4.5. Ablation Experiments Conducted to Validate the Functions of the Intra-Class Variance and BPLSH Modules
FMEKL-DDI consists of two modules: Intra-Class Variance
and BPLSH. This section seeks to assess the impact of the two modules on five datasets: Iono, Iris, CMC, Twonorm, and EEG. This validation utilizes several algorithms: the original empirical kernel (EKM), the empirical kernel enhanced with Intra-Class Variance (EKM+
), the empirical kernel integrated with BPLSH (EKM+BPLSH), and the empirical kernel that combines both Intra-Class Variance and BPLSH (EKM+
+BPLSH). The statistical data compare the training durations and classification accuracies of each algorithm across the datasets (
Figure 3). Training utilizes 50% of the data, with the remaining 50% allocated for testing, and results are averaged accordingly (
Table 6). The entries highlighted in
Table 7 represent the highest accuracy, whereas those in
Table 8 signify the shortest training time. Notably, we used a 50/50 train–test split to ensure a balanced evaluation between training efficiency and generalization performance. This ratio was consistently applied to maintain comparability across experiments and to avoid bias from overly skewed training or testing proportions.
Table 7 illustrates that the integration of EKM and
achieves the best accuracy, signifying that the inclusion of Intra-Class Variance substantially boosts the accuracy of the empirical kernel and affirming that
contributes to accuracy improvement. The isolated introduction of BPLSH results in a little decrease in EKM accuracy, indicating that BPLSH’s effect on categorization accuracy has diminished. This signifies that inside the amalgamation of EKM+
+BPLSH, solely
is employed to enhance accuracy.
Table 8 demonstrates that the amalgamation of BPLSH with EKM results in the minimal training time, indicating that BPLSH significantly decreases training duration. Conversely, employing only the empirical kernel with
leads to a slight extension of training time, indicating that
does not contribute to reducing training duration. Utilizing both
and BPLSH yields favorable outcomes in classification accuracy and training duration for the empirical kernel.
The training time differences among the compared algorithms primarily stem from the sample selection and kernel evaluation strategies. FMEKL-DDI achieves superior efficiency by leveraging the BPLSH algorithm to intelligently select a smaller, boundary-representative subset of samples, significantly reducing unnecessary computations. Additionally, the use of reduced kernel evaluations in smaller, well-structured empirical feature spaces contributes to faster processing. In contrast, while MREKLM also reduces training time by using random subsets, it occasionally incurs higher overhead due to the unpredictability of random sampling, which may select less informative or redundant data, requiring more iterations or larger projections to achieve acceptable performance.
4.6. Experiments on the Protein Subcellular Localization Dataset
To further validate the practicality and generalizability of the proposed algorithm, this section selects three datasets focused on protein subcellular localization to evaluate its performance. The three datasets analyzed are Plant, PsortPos, and PsortNeg. The Plant dataset consists of four classes and a total of 940 samples; PsortPos includes four classes with 541 samples, while PsortNeg comprises five classes with 1441 samples. Fifty percent of the data is utilized for training, while the remaining fifty percent is reserved for testing.
As illustrated in
Figure 4, it is evident that FMEKL-DDI demonstrates strong performance in practical applications. Notably, FMEKL-DDI achieves the highest classification accuracy, consistent with the results obtained in previous experimental sections. Furthermore, the classification accuracy of FMEKL-DDI is markedly higher than that of the other algorithms.
5. Conclusions
This paper proposed an efficient algorithm—Fast Multiple Empirical Kernel Learning Incorporating Data Distribution Information (FMEKL-DDI)—that integrates within-class distribution characteristics and boundary-aware sample selection to improve classification performance and computational efficiency. The experimental results across 18 benchmark datasets and 3 protein subcellular localization datasets demonstrated that FMEKL-DDI consistently outperformed comparable methods in terms of both classification accuracy and training time. Our proposal is well suited for large-scale, high-dimensional tasks where accuracy and efficiency are critical. It is particularly useful in bioinformatics, medical diagnostics, and security applications—such as protein classification, disease detection, and fraud or intrusion detection—where preserving class boundaries and fast model training are essential for real-time decision-making.
The observed improvements are largely attributed to two main components of the method: (1) the use of the within-class scatter matrix (), which enables the model to preserve class-specific sample distributions in the empirical kernel space, and (2) the application of the BPLSH algorithm, which selects informative border samples while significantly reducing the size of the training set. This combination allows FMEKL-DDI to strike an effective balance between accuracy and efficiency, especially on large-scale and high-dimensional datasets.
Comparative analysis showed that FMEKL-DDI surpasses state-of-the-art algorithms such as MEKL, MREKLM, IBMPEKL, CGMKL, and NLMKL in both predictive power and computational scalability. While some baseline methods achieved acceptable accuracy, they often incurred higher computational costs. In contrast, FMEKL-DDI maintained competitive accuracy with substantially lower training times, making it more practical for real-world applications.
An interesting direction for enhancing the training efficiency of FMEKL-DDI, especially on large-scale datasets, lies in leveraging virtual threads—such as Java Virtual Threads or user-level threading in C++. These lightweight threads offer low-overhead concurrency, enabling fine-grained parallelism during computationally intensive tasks like kernel matrix construction and BPLSH-based boundary sample selection. By parallelizing kernel evaluations across multiple subspaces or concurrently processing similarity computations in BPLSH, the algorithm could significantly reduce wall-clock training time without increasing memory consumption. Integrating virtual threads into the existing framework would allow the more efficient utilization of multi-core architectures, making FMEKL-DDI even more scalable for high-dimensional or streaming data applications.
Despite these advances, several opportunities for future development remain. One area involves exploring adaptive strategies for selecting the number and type of empirical kernels based on dataset characteristics. Another promising direction is the integration of class imbalance handling techniques and robust noise filtering, which could further enhance model generalization in complex or imbalanced datasets. Additionally, extending FMEKL-DDI to semi-supervised or online learning scenarios would broaden its applicability in dynamic and data-scarce environments.





{kind=link}
{kind=link}
{kind=link}
{kind=link}